
0 前言
有一段时间,Yogurt 比较沉迷数独游戏,所以在手机上下了一个叫『数独Sudoku益智脑训练软件』的 App。从初级到困难玩了个遍,困难级和专业级的比较花时间,所以也不怎么玩。但是玩久了之后就有点厌倦了,总会想有什么办法可以让数独自动玩,我就轻松了(歪,人家是让你训练脑子的好不好)。

讯享网
1 什么是数独(规则)
数独在百度百科上的介绍是这样的:
数独(shù dú)是源自18世纪瑞士的一种数学游戏。是一种运用纸、笔进行演算的逻辑游戏。玩家需要根据9×9盘面上的已知数字,推理出所有剩余空格的数字,并满足每一行、每一列、每一个粗线宫(3*3)内的数字均含1-9,不重复
数独盘面是个九宫,每一宫又分为九个小格。在这八十一格中给出一定的已知数字和解题条件,利用逻辑和推理,在其他的空格上填入1-9的数字。使1-9每个数字在每一行、每一列和每一宫中都只出现一次,所以又称 “九宫格” 。
简单的说就是每一行、每一列、以及每个小九宫格里的总共 81 个数字都要填满,但是每一行、每一列、以及每个小九宫格里的数字只能出现一次。规则还是相对比较简单的。
2 解题思路
从个人玩了一段时间的 “经验” 来看,就其实就两种方法,一是根据不重复的条件直观看出来的;二是隐藏比较深的需要标记候选词才能排查出来的。
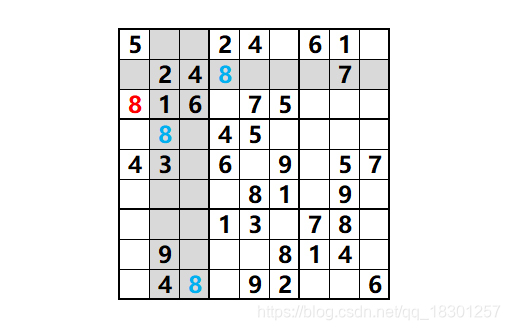
例如:红色的 8 填在这个位置是因为其他的 8 占用了行或者列中的一个单元格,根据不重复的要求,我们只能排除这些区域,剩下唯一空出来的单元格就 100% 是填 8 了。

候选词就是根据一个单元格里还能填什么数字为前提,根据现有条件一个个的备注在单元格中,通过比对,判断,尝试等多种方式来寻找那些通过只感官无法直接发现的数字。
比如上图中红框标注的 4。直接通过眼睛来看是看不出来的,但是通过对备选数字的排查,最终可以排除通过对其他的区域不符合规则的数字进行排除,进而证明红框标注的位置只能填 4。
3 如何用计算机来玩数独?
从某种程度上来说,计算机除了不能生孩子(现在也有用计算机来生产计算机了),啥事儿都能干。但,有个前提——首先是你知不知道要怎么做!
根据数独的填写规则,Yogurt 打算结合 直观出结果 和 候选数字出结果 这两种方法来对数独进行解答。
这里 Yogurt 用的是 Python 来解题。
标题中的『世界上号称最难数独居然没有坚持到 2 秒』的结论由以下环境下的 Jupyter Notebook 输出,经过多次测试,实际计算时间在 1.51 - 2.2 秒之间,如直接使用命令行调用 Python 来执行则为 2 - 3秒之间。
| 关键信息 | 说明 |
|---|---|
| 操作系统 | Windows 10 专业工作站版 |
| CPU | I5-10210U |
| 内存 | 16 GB |
| Python 版本 | 3.8.3 |
| IPython 版本 | 7.16.1 |
| Jupyter Notebook 版本 | 6.0.3 |
| 编辑器 | Visual Studio Code |
3.1 引入库
import numpy as np # 主要计算库 from datetime import datetime # 获取起止时间 from collections import Counter # 计算候选数字的出现频次 讯享网
3.2 导入题目
讯享网# 初始化 def Initialize(self, data: list): # 初始数据 dataArray = np.array(data) return dataArray
3.3 计算备选数字
从根本上讲,计算机根本不知道什么是直观,什么是不直观。因此我们需要告诉计算机判断的依据。

这里 Yogurt 直接对为空的单元格进行候选数字的计算,而最终计算结果有且仅有一个候选数字的就肯定是当前条件下的唯一解。因此这个单元格只能填这一个数字。
根据数独的填写规则,分别对 行、列、九宫格 等三种形式进行了计算,逐层排除多余候选词,最终结果为该单元格中当前条件下的所有候选数字。
又由于随着数独的难度增大后,可能无法通过一次计算直接得到所有的唯一候选数字,因此在排除到最后再也无法排除的情况下,我们需要选择候选结果最少的一个用来试填,尝试能不能解开题目。具体的后面会讲到。
# 备选数字 def BackupNumber(self, dataArray): # 初始备选数据 backupItem = ''.join([str(x) for x in range(1, 10)]) backupRow = [backupItem for x in range(9)] backupShape = [backupRow for x in range(9)] backupArray = np.array(backupShape) # 去除已填写数字的备选 backupArray = np.where(dataArray == 0, backupArray, '') # 计算备选数字 # 行备选 for rowIndex in range(9): dataItem = dataArray[rowIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) for item in usedDataList: for colIndex in range(9): backupItem = backupArray[rowIndex, colIndex] backupArray[rowIndex, colIndex] = backupItem.replace(item, '') # 列备选 for colIndex in range(9): dataItem = dataArray[:,colIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) for item in usedDataList: for rowIndex in range(9): backupItem = backupArray[rowIndex, colIndex] backupArray[rowIndex, colIndex] = backupItem.replace(item, '') # 九宫格备选 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): dataItem = dataArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list([*dataItem.flat])).replace('0', '')) for item in usedDataList: for bkRowIndex in range(rowIndex, rowIndex + 3): for bkColIndex in range(colIndex, colIndex + 3): backupItem = backupArray[bkRowIndex, bkColIndex] backupArray[bkRowIndex, bkColIndex] = backupItem.replace(item, '') # 选出备选数字中唯一结果 # 行 for rowIndex in range(9): bkItem = backupArray[rowIndex] bkData = ''.join(list(bkItem)) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for colIndex in range(9): backupItem = backupArray[rowIndex, colIndex] if len(backupItem) > 1: if item in backupItem: backupArray[rowIndex, colIndex] = item # 列 for colIndex in range(9): bkItem = backupArray[:,colIndex] bkData = ''.join(list(bkItem)) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for rowIndex in range(9): backupItem = backupArray[rowIndex, colIndex] if len(backupItem) > 1: if item in backupItem: backupArray[rowIndex, colIndex] = item # 九宫格 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): bkItem = backupArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] bkData = ''.join(list([*bkItem.flat])) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for bkRowIndex in range(rowIndex, rowIndex + 3): for bkColIndex in range(colIndex, colIndex + 3): backupItem = backupArray[bkRowIndex, bkColIndex] if len(backupItem) > 1: if item in backupItem: backupArray[bkRowIndex, bkColIndex] = item # 挑出第一个备选最少的结果 backupLeast = {
} for rowIndex in range(9): for colIndex in range(9): item = backupArray[rowIndex, colIndex] if backupLeast == {
}: backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } else: if item != '': if backupLeast['value'] == '': backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } if len(backupLeast['value']) > len(item): backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } return backupLeast, backupArray 3.4 验证计算结果
由于候选数字是根据当前未填数字计算出来的,因此如果题目本身有问题,或者在计算过程中出现填错的情况,例如试填的时候。当计算机发现填错的时候,需要终止当前计算,执行其他的操作,直到解题结束为止。
讯享网# 检验结果是否正确, 主要检验指定区域内是否存在重复数据 def NumberCheck(self, dataArray): # 行检验 for rowIndex in range(9): dataItem = dataArray[rowIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False # 列检验 for colIndex in range(9): dataItem = dataArray[:,colIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False # 九宫格检验 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): dataItem = dataArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list([*dataItem.flat])).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False return True
3.5 根据唯一备选结果填写数字
# 根据唯一备选结果填写数字 def WriteNumber(self, dataArray, backupArray): onlyBackupArray = backupArray.copy() onlyBackupArray = np.where(onlyBackupArray == '', 0, onlyBackupArray) onlyBackupArray = onlyBackupArray.astype(np.int) onlyBackupArray = np.where(onlyBackupArray <= 9, onlyBackupArray, 0) dataArray = np.where(dataArray == 0, onlyBackupArray, dataArray) dataCode = dataArray.astype(np.str) dataCode = ''.join([*dataCode.flat]) return dataCode, dataArray 3.6 试填数字
前面 3.3 有讲到,随着数独难度的提高,可能会出现没有唯一候选数字的情况。这时候我们就需要让计算机对多个候选词进行尝试性的填写,并以此为准,后面的计算均在此基础上进行,直到 3.4 的检查失败为止。
当试填数字出错的时候,我们需要将试填数字之后所填写的数字全部去除,回到试填前的样子。因此在试填之前就要保留当前的数独记录。当全部试填数字都用完的时候就要及时将其记录删除,表示已经无需再回退了,另一个试填数字再出错就只能从上一次试填开始计算了
讯享网# 填入测试数字 def TestWriteNumber(self, dataArray, backupLeast, parseHistoryDict, parseLocationList): rowIndex = backupLeast['rowIndex'] colIndex = backupLeast['colIndex'] value = backupLeast['value'] numberLocation = '{}{}'.format(str(rowIndex), str(colIndex)) if numberLocation not in parseLocationList: parseLocationList.append(numberLocation) parseHistoryDict[numberLocation] = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': value, 'dataArray': dataArray } if len(parseLocationList) > 0: numberLocation = parseLocationList[-1] testObj = parseHistoryDict[numberLocation] testRowIndex = testObj['rowIndex'] testColIndex = testObj['colIndex'] testValue = testObj['value'] testDataArray = testObj['dataArray'] if testObj['value'] == '': parseLocationList = parseLocationList[:-1] parseHistoryDict.pop(numberLocation) else: testNumber = testValue[0] testObj['value'] = testValue.replace(testNumber, '') dataArray = testDataArray.copy() dataArray[testRowIndex, testColIndex] = testNumber if testObj['value'] == '': parseLocationList = parseLocationList[:-1] parseHistoryDict.pop(numberLocation) return dataArray, parseHistoryDict, parseLocationList
3.7 还原执行历史
# 还原执行历史 def ResetDataArray(self, dataArray, parseHistoryDict, parseLocationList): if len(parseLocationList) > 0: numberLocation = parseLocationList[-1] testObj = parseHistoryDict[numberLocation] testDataArray = testObj['dataArray'] dataArray = testDataArray.copy() return dataArray, parseHistoryDict, parseLocationList 3.8 执行解题(完整代码)
上面的 7 步都是分解动作,将他们都连贯起来,就可以对世界上最难的数独发起进攻了。

讯享网import numpy as np # 主要计算库 from datetime import datetime # 获取起止时间 from collections import Counter # 计算候选数字的出现频次 class Soduku: # 初始化 def Initialize(self, data: list): # 初始数据 dataArray = np.array(data) return dataArray # 备选数字 def BackupNumber(self, dataArray): # 初始备选数据 backupItem = ''.join([str(x) for x in range(1, 10)]) backupRow = [backupItem for x in range(9)] backupShape = [backupRow for x in range(9)] backupArray = np.array(backupShape) # 去除已填写数字的备选 backupArray = np.where(dataArray == 0, backupArray, '') # 计算备选数字 # 行备选 for rowIndex in range(9): dataItem = dataArray[rowIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) for item in usedDataList: for colIndex in range(9): backupItem = backupArray[rowIndex, colIndex] backupArray[rowIndex, colIndex] = backupItem.replace(item, '') # 列备选 for colIndex in range(9): dataItem = dataArray[:,colIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) for item in usedDataList: for rowIndex in range(9): backupItem = backupArray[rowIndex, colIndex] backupArray[rowIndex, colIndex] = backupItem.replace(item, '') # 九宫格备选 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): dataItem = dataArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list([*dataItem.flat])).replace('0', '')) for item in usedDataList: for bkRowIndex in range(rowIndex, rowIndex + 3): for bkColIndex in range(colIndex, colIndex + 3): backupItem = backupArray[bkRowIndex, bkColIndex] backupArray[bkRowIndex, bkColIndex] = backupItem.replace(item, '') # 选出备选数字中唯一结果 # 行 for rowIndex in range(9): bkItem = backupArray[rowIndex] bkData = ''.join(list(bkItem)) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for colIndex in range(9): backupItem = backupArray[rowIndex, colIndex] if len(backupItem) > 1: if item in backupItem: backupArray[rowIndex, colIndex] = item # 列 for colIndex in range(9): bkItem = backupArray[:,colIndex] bkData = ''.join(list(bkItem)) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for rowIndex in range(9): backupItem = backupArray[rowIndex, colIndex] if len(backupItem) > 1: if item in backupItem: backupArray[rowIndex, colIndex] = item # 九宫格 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): bkItem = backupArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] bkData = ''.join(list([*bkItem.flat])) numberFrequency = sorted(dict(Counter(bkData)).items(), key = lambda x:x[1]) onlyNumberList = [] for item in numberFrequency: number, counts = item if counts == 1: onlyNumberList.append(number) else: break for item in onlyNumberList: for bkRowIndex in range(rowIndex, rowIndex + 3): for bkColIndex in range(colIndex, colIndex + 3): backupItem = backupArray[bkRowIndex, bkColIndex] if len(backupItem) > 1: if item in backupItem: backupArray[bkRowIndex, bkColIndex] = item # 挑出第一个备选最少的结果 backupLeast = {
} for rowIndex in range(9): for colIndex in range(9): item = backupArray[rowIndex, colIndex] if backupLeast == {
}: backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } else: if item != '': if backupLeast['value'] == '': backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } if len(backupLeast['value']) > len(item): backupLeast = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': item } return backupLeast, backupArray # 检验结果是否正确, 主要检验指定区域内是否存在重复数据 def NumberCheck(self, dataArray): # 行检验 for rowIndex in range(9): dataItem = dataArray[rowIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False # 列检验 for colIndex in range(9): dataItem = dataArray[:,colIndex] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list(dataItem)).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False # 九宫格检验 for rowIndex in range(0, 9, 3): for colIndex in range(0, 9, 3): dataItem = dataArray[rowIndex : rowIndex + 3, colIndex : colIndex + 3] dataItem = dataItem.astype(np.str) usedDataList = list(''.join(list([*dataItem.flat])).replace('0', '')) if len(usedDataList) > 0: if Counter(usedDataList).most_common()[0][1] > 1: return False return True # 根据唯一备选结果填写数字 def WriteNumber(self, dataArray, backupArray): onlyBackupArray = backupArray.copy() onlyBackupArray = np.where(onlyBackupArray == '', 0, onlyBackupArray) onlyBackupArray = onlyBackupArray.astype(np.int) onlyBackupArray = np.where(onlyBackupArray <= 9, onlyBackupArray, 0) dataArray = np.where(dataArray == 0, onlyBackupArray, dataArray) dataCode = dataArray.astype(np.str) dataCode = ''.join([*dataCode.flat]) return dataCode, dataArray # 填入测试数字 def TestWriteNumber(self, dataArray, backupLeast, parseHistoryDict, parseLocationList): rowIndex = backupLeast['rowIndex'] colIndex = backupLeast['colIndex'] value = backupLeast['value'] numberLocation = '{}{}'.format(str(rowIndex), str(colIndex)) if numberLocation not in parseLocationList: parseLocationList.append(numberLocation) parseHistoryDict[numberLocation] = {
'rowIndex': rowIndex, 'colIndex': colIndex, 'value': value, 'dataArray': dataArray } if len(parseLocationList) > 0: numberLocation = parseLocationList[-1] testObj = parseHistoryDict[numberLocation] testRowIndex = testObj['rowIndex'] testColIndex = testObj['colIndex'] testValue = testObj['value'] testDataArray = testObj['dataArray'] if testObj['value'] == '': parseLocationList = parseLocationList[:-1] parseHistoryDict.pop(numberLocation) else: testNumber = testValue[0] testObj['value'] = testValue.replace(testNumber, '') dataArray = testDataArray.copy() dataArray[testRowIndex, testColIndex] = testNumber if testObj['value'] == '': parseLocationList = parseLocationList[:-1] parseHistoryDict.pop(numberLocation) return dataArray, parseHistoryDict, parseLocationList # 还原执行历史 def ResetDataArray(self, dataArray, parseHistoryDict, parseLocationList): if len(parseLocationList) > 0: numberLocation = parseLocationList[-1] testObj = parseHistoryDict[numberLocation] testDataArray = testObj['dataArray'] dataArray = testDataArray.copy() return dataArray, parseHistoryDict, parseLocationList # 执行代码 # 世界上最难的数独 data = [ [ 8, 0, 0, 0, 0, 0, 0, 0, 0 ], [ 0, 0, 3, 6, 0, 0, 0, 0, 0 ], [ 0, 7, 0, 0, 9, 0, 2, 0, 0 ], [ 0, 5, 0, 0, 0, 7, 0, 0, 0 ], [ 0, 0, 0, 0, 4, 5, 7, 0, 0 ], [ 0, 0, 0, 1, 0, 0, 0, 3, 0 ], [ 0, 0, 1, 0, 0, 0, 0, 6, 8 ], [ 0, 0, 8, 5, 0, 0, 0, 1, 0 ], [ 0, 9, 0, 0, 0, 0, 4, 0, 0 ], ] sodukuObj = Soduku() print('-------- 解题开始 --------\n') startTime = datetime.now() # 初始化 dataArray = sodukuObj.Initialize(data) parseHistoryDict = {
} parseLocationList = [] stepIndex = 0 testIndex = 0 while stepIndex < 1000: # 计算备选 backupLeast, backupArray = sodukuObj.BackupNumber(dataArray) # 根据唯一结果填写数字 dataCode, dataArray = sodukuObj.WriteNumber(dataArray, backupArray) if sodukuObj.NumberCheck(dataArray) == False: dataArray, parseHistoryDict, parseLocationList = sodukuObj.ResetDataArray( dataArray = dataArray, parseHistoryDict = parseHistoryDict, parseLocationList = parseLocationList ) testIndex += 1 else: if len(dataCode.replace('0', '')) == 81: break else: dataArray, parseHistoryDict, parseLocationList = sodukuObj.TestWriteNumber( dataArray = dataArray, backupLeast = backupLeast, parseHistoryDict = parseHistoryDict, parseLocationList = parseLocationList ) stepIndex += 1 endTime = datetime.now() if stepIndex <= 1000: print('解题时长:', endTime - startTime) print('计算周期:', stepIndex) print('测试次数:', testIndex) print('解题结果:') print(dataArray) print('\n-------- 解题结束 --------') else: print('解题结果:') print(dataArray) print('\n-------- 解题失败 --------')
执行结果
-------- 解题开始 -------- 解题时长: 0:00:01. 计算周期: 644 测试次数: 90 解题结果: [[8 1 2 7 5 3 6 4 9] [9 4 3 6 8 2 1 7 5] [6 7 5 4 9 1 2 8 3] [1 5 4 2 3 7 8 9 6] [3 6 9 8 4 5 7 2 1] [2 8 7 1 6 9 5 3 4] [5 2 1 9 7 4 3 6 8] [4 3 8 5 2 6 9 1 7] [7 9 6 3 1 8 4 5 2]] -------- 解题结束 -------- 4 解题流程

这里呢 Yogurt 对执行过程做了循环周期的限制,限制了 1000 次,其目的是防止有些题目根本就是无解的,无限制的解题丝毫没有任何意义。同时,号称世界上最难的数独也不过是执行了 644 个周期而已,其他的数独又何德何能超过 1000 次周期呢?

(如果有,当我没说)
5 后记
说起来,做这个数独解题算法只不过是无聊时的一个乐子而已。但是在做这个算法的过程中,还是收获了不少。不在算法,而是一些思维方式上的东西。
因为 Yogurt 最近也在负责一个关于销售预测的项目,虽然不是很深入,但隐隐的感觉后期如果要将预测结果真正用到实处的话,这次做数独的经验也许能够有所帮助。一直以来,预测都是基于现有条件来得出未来某个时期内的结果或趋势将会是什么,但这样的预测只不过是被动地在接受未来可能会发生的一切而已,并不能带来什么实质性的改变。但在做这个数独算法时,采用了试填的概念,结果不合适就返回最初,再用下一个数字来尝试。相当于从结果出发,反推过程。
那么如果在实际的业务预测过程中,当预测结果与目标不一致时,我们为了达成这个目标还需要多少努力?此时我们其实是知道最终想要的结果的,就像我们知道数独的结果就是 81 个单元格全部填满,且行、列、九宫格内的数字不得重复一样。通过一定的规则,结合最终目标反推后面每一步应该达成哪些小目标,进而达成总目标。通过计算,可以得到比较确切的数字或指标,反向来指导业务,并推进达成。
目前为止可能还比较难,后面慢慢尝试看看能不能做到。
以上就是本期的全部内容,下期再见。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/121084.html