
高斯核的卷积计算是可分离的,即高斯核的每一个维度可以分开处理。因此,一维卷积计算成为了实现3D高斯卷积的基础。一维卷积计算的性能直接影响了整个程序的性能。本篇将实现一维卷积功能,同时引出ICC编译器对多层嵌套循环场景的向量化优化倾向的调查结果。
Base版本实现
Base版本思路是依照滑窗算法,即卷积核依次移动并计算乘加和,更新到目标矩阵中。因为原始矩阵长度为432 * 4 Bytes,卷积核 31 * 4 Bytes,因此外层循环遍历更新目标矩阵,内层循环计算原始矩阵与卷积核的点积,可以充分利用原始矩阵数据和目标矩阵数据的空间局部性,避免内存的重复加载。
代码实现,这里为了增加结果的稳定性,重复执行次。
#define CONVREPEAT 讯享网
讯享网void Conv1D_base(float* pSrc, int iLength, float* pKernel, int kernelSize, float* pDst) {
for (int itDst = (kernelSize/2); itDst < iLength - (kernelSize/2); ++itDst) {
for (int itker = 0,itSrc = itDst - (kernelSize / 2); itker < kernelSize; ++itker,++itSrc) {
pDst[itDst] += pKernel[itker] * pSrc[itSrc]; } } }
其中参数说明
pSrc->原始一维矩阵指针 iLength->原始一维矩阵长度 pKernel->一维卷积核指针 kernelSize->一维卷积核长度 pDst->卷积结果指针 执行时间
讯享网TestConv1D(base) cost total Time 623 TestConv1D cost Time 0.00623
Base版本VTune分析性能瓶颈

讯享网
前面已经分析过,内存访问具有良好的空间局部性,从VTune整体分析结果可以很好的验证这一点。

程序整体CPI为0.436.

主要问题是程序没做向量化,没有充分利用向量寄存器。

定位代码中的热点位置,可以看到for循环执行的指令比实际做乘加运算的指令数多了一倍多。

查看2300行的反汇编,for循环判断循环结束的汇编指令cmp执行的太多次数,同时这个指令原则上是无法向量化的。

查看2302行的反汇编,使用了乘加运算fmaddss指令。但是ss标记表示是对浮点数标量运算,一次只计算一个浮点数。
关于指令fmaddss详细信息如下:

向量化优化
分析代码逻辑,最内层循环是做点积运算,是可以通过编译指导语句强制编译器做向量化。因此尝试在Base的基础上,添加向量化优化,同时点积运算是归约类型的计算,通过添加指导关键字reduction,合并计算结果。
代码实现

void Conv1D_opt(float* pSrc, int iLength, float* pKernel, int kernelSize, float* pDst) {
for (int itDst = (kernelSize / 2); itDst < iLength - (kernelSize / 2); ++itDst) {
#pragma omp simd reduction(+:pDst[itDst]) for (int itker = 0, itSrc = itDst - (kernelSize / 2); itker < kernelSize; ++itker, ++itSrc) {
pDst[itDst] += pKernel[itker] * pSrc[itSrc]; } } } 执行时间
讯享网TestConv1D(opt) cost total Time 116 TestConv1D cost Time 0.00116
向量化版本VTune分析

和Base版本对比,向量化程度增加,FPU指标升高。
FPU表示浮点数计算向量化的程度,关于FPU的解释:
This metric represents how the application code vectorization relates to the floating point computations. A value of 100% means that all floating point instructions are vectorized with the full vector capacity.

可以看到,指令数量上Base版本是优化版本的五倍左右,两个版本CPI相差不大,这可以解释速度提高的原因。
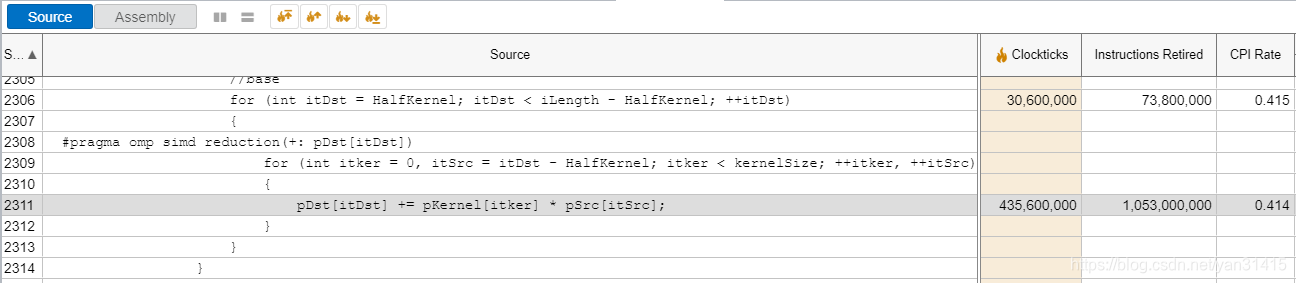
总指令数量10亿数量级。

对比Base版本,优化版本的的反汇编指令中多出了fmadd231ps vaddps等向量化指令,处理xmm寄存器中数据,因此向量化一次处理4个float单元。
fmaddps指令解释如下:

这里即便指定了向量化优化的指令集AVX2,最终生成的代码还是无法使用ymm寄存器,原因是AVX2指令集一次能够处理8float,最内层31个float数量太少,编译器认为使用AVX2指令集效率并非**。
编译器配置如下:

循环转换
void Conv1D_Opt_Cmb(float* pSrc, int iLength, float* pKernel, int kernelSize, float* pDst) {
int iConvSize = iLength - kernelSize + 1; float* pDstTemp = pDst + kernelSize / 2; for (int kx = 0, start = 0; kx < kernelSize; kx++, start++) {
#pragma omp simd for (int x = 0; x < iConvSize; x++) {
pDstTemp[x] += pSrc[start + x] * pKernel[kx]; } } } 执行时间
讯享网TestConv1D(Conv1D_Opt_Cmb) cost total Time 60 TestConv1D cost Time 0.0006
VTune分析循环转换性能

这里FPU已经不再是性能瓶颈。
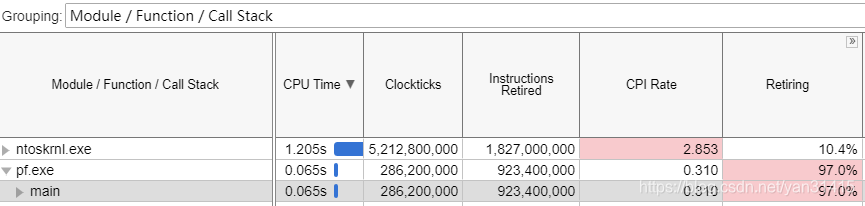
整体指令数量与CPI都得到了优化。

这里执行指令数量(循环+计算)为7亿,对比Conv1D_opt减少了百分之40多,同时CPI降低到0.316

这里fma指令使用了ymm寄存器。最内层循环长度400个float,因此编译器认为使用了256位的寄存器是更高校的向量化方法。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/120618.html