
正则表达式
下表列出了所有的元字符和对它们的一个简短的描述。
| 元字符 |
描述 |
||||||||||||||||||||||||
| \ |
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
||||||||||||||||||||||||
| ^ |
匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
||||||||||||||||||||||||
| $ |
匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
||||||||||||||||||||||||
| * |
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 |
||||||||||||||||||||||||
| + |
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
||||||||||||||||||||||||
| ? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
||||||||||||||||||||||||
| { n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
||||||||||||||||||||||||
| { n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
||||||||||||||||||||||||
| { n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
||||||||||||||||||||||||
| ? |
当该字符紧跟在任何一个其他限制符(*,+,?,{ n},{ n,},{ n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
||||||||||||||||||||||||
| .点 |
匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
||||||||||||||||||||||||
| (pattern) |
匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
||||||||||||||||||||||||
| (?:pattern) |
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
||||||||||||||||||||||||
| (?=pattern) |
非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
||||||||||||||||||||||||
| (?!pattern) |
非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
||||||||||||||||||||||||
| (?<=pattern) |
非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 *python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
||||||||||||||||||||||||
| (?<!patte_n) |
非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 *python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
||||||||||||||||||||||||
| x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 |
||||||||||||||||||||||||
| [xyz] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
||||||||||||||||||||||||
| [^xyz] |
负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 |
||||||||||||||||||||||||
| [a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
||||||||||||||||||||||||
| [^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
||||||||||||||||||||||||
| \b |
匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
||||||||||||||||||||||||
| \B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
||||||||||||||||||||||||
| \cx |
匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
||||||||||||||||||||||||
| \d |
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
||||||||||||||||||||||||
| \D |
匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
||||||||||||||||||||||||
| \f |
匹配一个换页符。等价于\x0c和\cL。 |
||||||||||||||||||||||||
| \n |
匹配一个换行符。等价于\x0a和\cJ。 |
||||||||||||||||||||||||
| \r |
匹配一个回车符。等价于\x0d和\cM。 |
||||||||||||||||||||||||
| \s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
||||||||||||||||||||||||
| \S |
匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
||||||||||||||||||||||||
| \t |
匹配一个制表符。等价于\x09和\cI。 |
||||||||||||||||||||||||
| \v |
匹配一个垂直制表符。等价于\x0b和\cK。 |
||||||||||||||||||||||||
| \w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
||||||||||||||||||||||||
| \W |
匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
||||||||||||||||||||||||
| \xn |
匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
||||||||||||||||||||||||
| \num |
匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。
|
||||||||||||||||||||||||
| \n |
标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
||||||||||||||||||||||||
| \nm |
标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
||||||||||||||||||||||||
| \nml |
如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
||||||||||||||||||||||||
| \un |
匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,。
|
||||||||||||||||||||||||
| \p{P} |
小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。 其他六个属性:
*注:此语法部分语言不支持,例:javascript。 |
||||||||||||||||||||||||
| \< \> |
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 | ||||||||||||||||||||||||
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 | ||||||||||||||||||||||||
| | | 将两个匹配条件进行逻辑“或”(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |

特殊字符表达式
| 字符 | 字符解释 | 转义表达 | ASCII表达(大小写不敏感) |
控制符表达 |
| 空 | \x00 | ^@ | ||
| 头标开始 | \x01 | \cA | ||
| 正文开始 | \x02 | \cB | ||
| 正文结束 | \x03 | \cC | ||
| 传输结束 | \x04 | \cD | ||
| 查询 | \x05 | \cE | ||
| 确认 | \x06 | \cF | ||
| 震铃 | \x07 | \cG | ||
| 退格 | \x08 | \cH | ||
| 水平制表符 | \t | \x09 | \cI | |
| 换行\新行 | \r | \x0a | \cJ | |
| 竖直制表符 | \v | \x0b | \cK | |
| 换页\新页 | \f | \x0c | \cL | |
| 回车 | \n | \x0d | \cM | |
| 移出 | \x0e | \cN | ||
| 移入 | \x0f | \cO | ||
| 数据链路转义 | \x10 | \cP | ||
| 设备控制1 | \x11 | \cQ | ||
| 设备控制2 | \x12 | \cR | ||
| 设备控制3 | \x13 | \cS | ||
| 设备控制4 | \x14 | \cT | ||
| 反确认 | \x15 | \cU | ||
| 同步空闲 | \x16 | \cV | ||
| 传输块结束 | \x17 | \cW | ||
| 取消 | \x18 | \cX | ||
| 媒体结束 | \x19 | \cY | ||
| 替换 | \x1a | \cZ | ||
| 转意 | \x1b | \c[ | ||
| 文件分隔符 | \x1c | \c\ | ||
| 组分隔符 | \x1d | \c] | ||
| 记录分隔符 | \x1e | \c6 | ||
| 单元分隔符 | \x1f | \c- | ||
| 空格 | \x20 | |||
| ! | 叹号 | \x21 | ||
| " | 双引号 | \x22 | ||
| # | 井号 | \x23 | ||
| $ | 货币符号 | \$ | \x24 | |
| % | 百分号 | \x25 | ||
| & | and | \x26 | ||
| ' | 单引号 | \x27 | ||
| ( | 小括号-左 | \( | \x28 | |
| ) | 小括号-右 | \) | \x29 | |
| * | 星号 | \* | \x2a | |
| + | 加号 | \+ | \x2b | |
| , | 逗号 | \x2c | ||
| - | 减号 | \x2d | ||
| . | 点 | \. | \x2e | |
| / | 斜杆 | \x2f | ||
| 0 | 数字0 | \x30 | ||
| 1 | 数字1 | \x31 | ||
| 2 | 数字2 | \x32 | ||
| 3 | 数字3 | \x33 | ||
| 4 | 数字4 | \x34 | ||
| 5 | 数字5 | \x35 | ||
| 6 | 数字6 | \x36 | ||
| 7 | 数字7 | \x37 | ||
| 8 | 数字8 | \x38 | ||
| 9 | 数字9 | \x39 | ||
| : | 冒号 | \x3a | ||
| ; | 分号 | \x3b | ||
| < | 小于号 | \x3c | ||
| = | 等于号 | \x3d | ||
| > | 大于号 | \x3e | ||
| ? | 问号 | \? | \x3f | |
| @ | at | \x40 | ||
| A | 大写字母A | \x41 | ||
| B | 大写字母B | \x42 | ||
| C | 大写字母C | \x43 | ||
| D | 大写字母D | \x44 | ||
| E | 大写字母E | \x45 | ||
| F | 大写字母F | \x46 | ||
| G | 大写字母G | \x47 | ||
| H | 大写字母H | \x48 | ||
| I | 大写字母I | \x49 | ||
| J | 大写字母J | \x4a | ||
| K | 大写字母K | \x4b | ||
| L | 大写字母L | \x4c | ||
| M | 大写字母M | \x4d | ||
| N | 大写字母N | \x4e | ||
| O | 大写字母O | \x4f | ||
| P | 大写字母P | \x50 | ||
| Q | 大写字母Q | \x51 | ||
| R | 大写字母R | \x52 | ||
| S | 大写字母S | \x53 | ||
| T | 大写字母T | \x54 | ||
| U | 大写字母U | \x55 | ||
| V | 大写字母V | \x56 | ||
| W | 大写字母W | \x57 | ||
| X | 大写字母X | \x58 | ||
| Y | 大写字母Y | \x59 | ||
| Z | 大写字母Z | \x5a | ||
| [ | 中括号-左 | \[ | \x5b | |
| \ | 斜杆 | \\ | \x5c | |
| ] | 中括号-右 | \] | \x5d | |
| ^ | 脱字符号 | \^ | \x5e | |
| _ | 下横线 | \x5f | ||
| ` | 反单引号 |
\x60 |
||
| a | 小写字母a | \x61 | ||
| b | 小写字母b | \x62 | ||
| c | 小写字母c | \x63 | ||
| d | 小写字母d | \x64 | ||
| e | 小写字母e | \x65 | ||
| f | 小写字母f | \x66 | ||
| g | 小写字母g | \x67 | ||
| h | 小写字母h | \x68 | ||
| i | 小写字母i | \x69 | ||
| j | 小写字母j | \x6a | ||
| k | 小写字母k | \x6b | ||
| l | 小写字母l | \x6c | ||
| m | 小写字母m | \x6d | ||
| n | 小写字母n | \x6e | ||
| o | 小写字母o | \x6f | ||
| p | 小写字母p | \x70 | ||
| q | 小写字母q | \x71 | ||
| r | 小写字母r | \x72 | ||
| s | 小写字母s | \x73 | ||
| t | 小写字母t | \x74 | ||
| u | 小写字母u | \x75 | ||
| v | 小写字母v | \x76 | ||
| w | 小写字母w | \x77 | ||
| x | 小写字母x | \x78 | ||
| y | 小写字母y | \x79 | ||
| z | 小写字母z | \x7a | ||
| { | 大括号-左 | \x7b | ||
| | | 竖线 | \| | \x7c | |
| } | 大括号-右 | \x7d | ||
| ~ | 波浪号 | \x7e | ||
| Backspae | \x7f | \cBackspace |
常用匹配
示例
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; namespace System.Windows.Forms.Keyboard { /* * Regular Expression */ public class Regular { public const string sample1 = "you share rose get fun"; #region 一句话包含26个英文字母 /// <summary> /// 那只敏捷的棕色狐狸跳过一只懒狗。 /// </summary> public const string Words1 = "The quick brown fox jumps over a lazy dog."; /// <summary> /// 把我的箱子装上五打酒壶。 /// </summary> public const string Words2 = "Pack my box with five dozen liquor jugs."; /// <summary> /// 五个拳击奇才跳得很快。 /// </summary> public const string Words3 = "The five boxing wizards jump quickly."; /// <summary> /// 疾风拂面,惊动了勇敢的吉姆。 /// </summary> public const string Words4 = "Quick wafting zephyrs vex bold Jim."; /// <summary> /// 华尔兹女神,为了快速的跳跃激怒巴德 /// </summary> public const string Words5 = "Waltz nymph, for quick jigs vex Bud"; #endregion /// <summary> /// 予人玫瑰手留余香 /// 鱼香肉丝盖饭 /// </summary> public const string sample1 = "you share rose get fun"; } } 讯享网
1、字符 *
讯享网\x2a \x2A \*
2、换行回车
\r\n \cM\cJ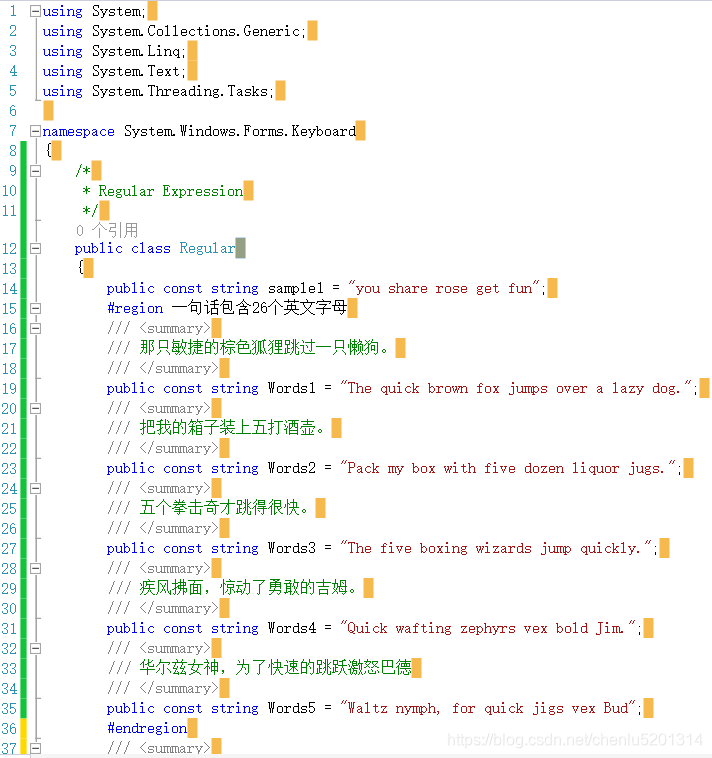
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/120388.html