
写在前面:在做数据集的过程中需要使用到labelImg这个工具,找了许多的资料完成了安装和使用,写在这里供大家使用(2020.4.8亲测有用)
1.首先先下载这个工具的源代码(此处贴一个github上面的源代码)
labelImg
地址:https://github.com/tzutalin/labelImg
2.将获得的源代码的压缩包进行压缩(忽略前面的名字,随便找了个文件夹放位置)

3.进行补充包的下载,运行该代码需要一些第三方库。
1.lxml
2.pyqt5(这里使用pyqt4也是可以的,题主使用的是较新的)
很多教程里面提到的是需要使用Anocanda进行安装,题主这里使用比较简单的python第三方库下载安装工具 pip
注意:运行此代码需要使用的是python3,所以使用python2的用户需要改用python3,同时可以在cmd里面使用pip -V来查看下自己的pip版本,确保pip下载的库是给python3使用的
注意,在下载的过程中会出现速度过慢的情况,建议更换下载源(题主在使用原本的默认源的时候出现了read time out的问题),如何更换下载源可以参考题主的另一篇博客
链接在这里
当然不想看的,可以直接采用题主下面的安装代码。
lxml(这里题主已经安装完毕了,)
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple/ 

pyqt5
讯享网pip install pyqt5 -i https://pypi.tuna.tsinghua.edu.cn/simple/

4.移动文件夹里的文件
将我们刚刚的labelImg-master文件夹里面的resources.py文件移动到libs里面,不然会出现找不到模板的bug

5。运行代码
cmd移动到labelImg-master文件夹所在的文件夹,运行labelImg.py 文件(因为题主电脑有py2和py3,所以把python3的启动变成了python3),如果电脑只有一个python版本的话直接运行python labelImg.py就行了。
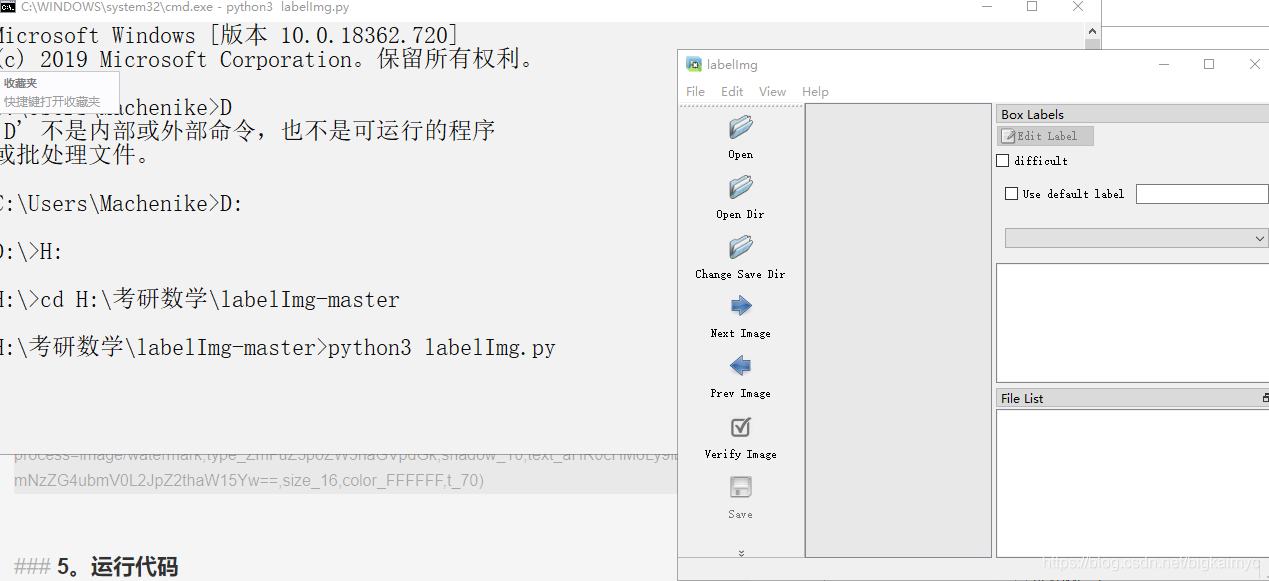
6.工具的使用方法
1.修改默认的XML文件保存位置,使用快捷键Ctrl+R,改为自己想要存储的自定义位置,注意,这里面的路径不能够含有中文,否则无法进行保存工作(代码中的编码不支持中文)
2."Open Dir"打开图片文件夹

3.打开的时候默认就会打开该文件夹的第一张图片,打开"Create\nRectBox"(题主认为这个地方可能是写这个代码的人写出了纰漏导致出现了\n,但是真的就是这个地方,在Edit里面),或者使用快捷键w,开始画框,点击结束画框,给该画框进行命名(一张图里面可以画很多个框)。完成一张图片后点击"Save"保存,这样生成的XML文件就已经保存到本地了,点击"Next Image"转到下一张图片。
7.想要其它类型的文件
在使用的过程中,不想要XML类型的文件,例如想要txt类型的文件。也是可以通过python代码来实现的,这里贴一个XML转换成为txt文件的代码
import xml.etree.ElementTree as ET import pickle import os from os import listdir, getcwd from os.path import join sets=['train', 'val'] #替换为自己的数据集 classes = ["person", "hat"] #修改为自己的类别 def convert(size, box): dw = 1./(size[0]) dh = 1./(size[1]) x = (box[0] + box[1])/2.0 - 1 y = (box[2] + box[3])/2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x*dw w = w*dw y = y*dh h = h*dh return (x,y,w,h) def convert_annotation(image_id): try: in_file = open('label/%06d.xml'%(image_id)) except: return 0 out_file = open('train2017/%06d.txt'%(image_id), 'w') tree=ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text #如果不是人或者是难以识别的人,跳过 if cls not in classes or int(difficult)==1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w,h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') return 1 wd = getcwd() if not os.path.exists('labels'): os.makedirs('labels') list_file = open('train.txt', 'w') for image_id in range(148,149): if (convert_annotation(image_id) == 1): list_file.write('../coco/images/train2017/%06d.jpg\n'%(image_id)) #print('train/%06d.jpg\n'%(i)) list_file.close() print('运行结束')
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/118765.html