
目录
1 为什么要进行数据预处理?
2 标准化:
2.1 原理:
2.2 计算公式:
2.3 实战一:
2.4 实战二:
3 归一化:
3.1 原理:
3.1.1 均值方差归一化
3.1.2 向量归一化(单位范数归一化)
3.2 实战:(向量归一化)
4 缩放:
4.1 原理:
4.2 计算公式:
4.3 实战:
5 特征:
5.1 原理:
5.2 整数编码:
5.3 独热编码:
5.4 实战一(整数编码):
5.5 实战二(独热编码):
6 二值化:
6.1 原理:
6.2 实战:
7 多项式特征:
7.1 原理:
7.2 实战:

1 为什么要进行数据预处理?
我们有时候发现将我们的训练数据扔到模型中,发现结果并不是很好。 原因可能是模型不适合该类数据,而是可能数据很脏,没有经过处理。常见的一些处理方式有标准化 (Standardization) 、正则化(Normalizer)、缩放等。我们需要将数据进行一系列的处理让我们的模型可以更容易地拟合数据。
2 标准化:
2.1 原理:
我们经常会发现一般在训练数据之前都会将数据进行标准化。
- 这是因为有些机器学习算法的假设就是我们的数据符合正态分布,但显示中我们的数据不是这样的,所以我们就要将数据进行处理使他符合正态分布。
- 还有些原因就是统一量纲化,防止不同特征之间的量纲不统一,出现特征权重失衡的现象,就是那些数值很大的特征会起决定性的作用,而那些特征值小的特征就会不发挥作用,我们的学习器就不能够从所有的特征进行学习。
- 第三就是将数据缩放到0-1之间,会使我们的计算更加快速。
2.2 计算公式:
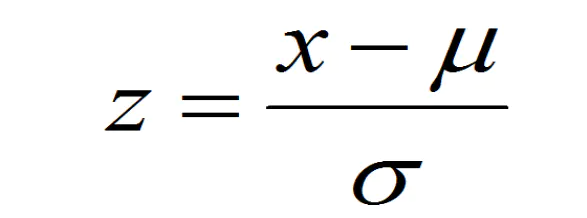
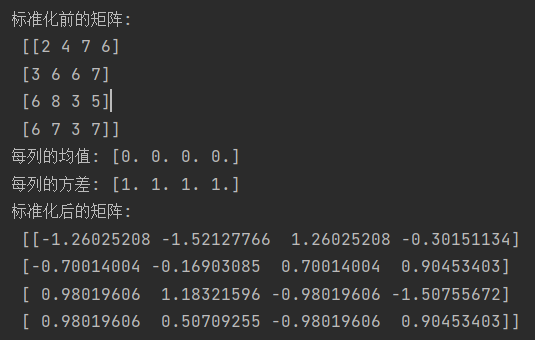
2.3 实战一:
# preprocessing模块用于数据预处理和特征工程的相关操作 from sklearn import preprocessing import numpy as np data = np.random.randint(1, 10, (4, 4))#随机生成一个4x4的数组,其中的元素从1-10中选取 print('标准化前的矩阵:\n',data) data_scaled = preprocessing.scale(data)#对数据进行均值化处理,使得每类的均值为0,方差为1 d_mean = data_scaled.mean(axis=0).round(2)#计算每列的均值 d_std = data_scaled.std(axis=0).round(2)#计算每列的方差 print('每列的均值:',d_mean) print('每列的方差:',d_std) print('标准化后的矩阵:\n',data_scaled)讯享网
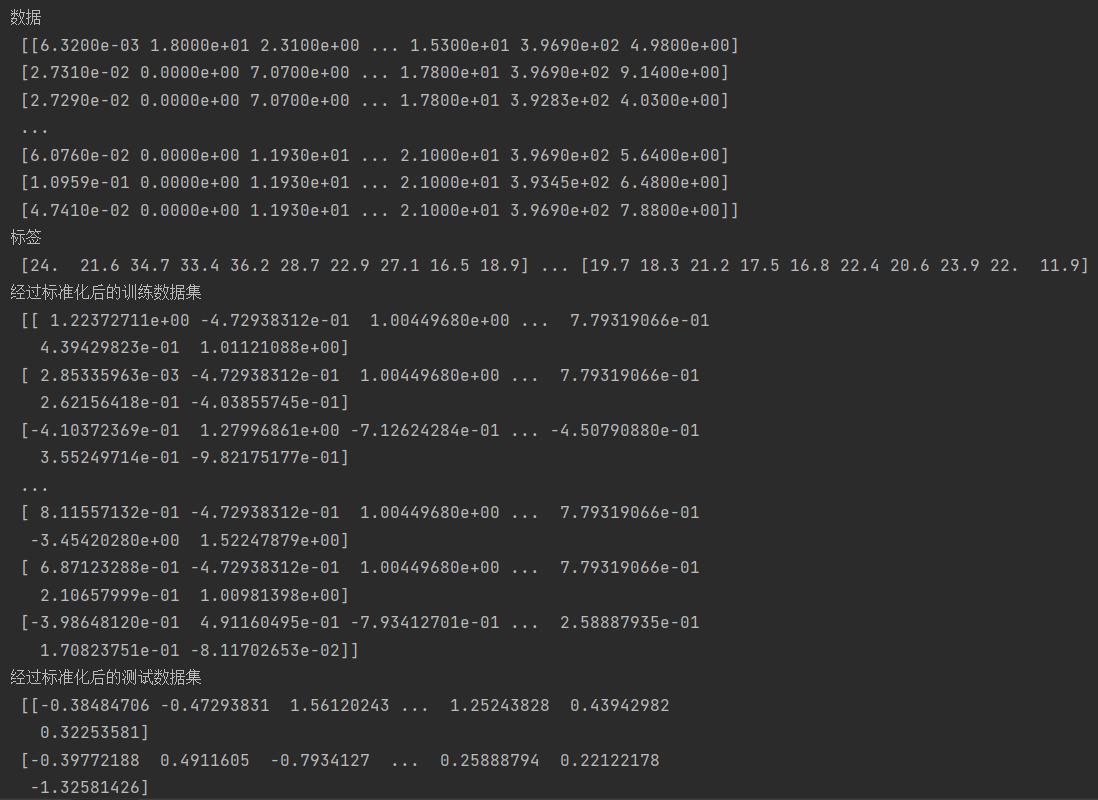
2.4 实战二:
讯享网from sklearn.preprocessing import StandardScaler#StandardScaler是一个用于对数据进行标准化处理的类 import pandas as pd import numpy as np data_url = "http://lib.stat.cmu.edu/datasets/boston"#数据源 #从指定的data_url读取CSV文件,sep="\s+"表示将多个连续空格作为分隔符,skiprows=22表示忽略前22行,header=None表示第一列是数据而非表头 raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None) #raw_df.values[::2, :]选择从第0行开始,每隔两行选择一次,并选择所有列,形成一个新的子数组。 #raw_df.values[1::2, :2]选择从第1行开始,每隔两行选择一次,并选择前两列,形成另一个新的子数组。 #np.hstack函数将两个子数组按水平方向进行堆叠,形成一个新的数组data。 data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]]) print('数据\n',data) target = raw_df.values[1::2, 2]#从第1行开始,每隔两行选择一次,并选择第2列(下标从0开始),用于存储目标变量 print('标签\n',target) X = data y = target X = X[y < 50.0]#只保留目标值小于50的样本和目标值 y = y[y < 50.0] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.2,random_state=666) standardScaler = StandardScaler() standardScaler.fit(X_train)#拟合操作,为了下一步在不同数据集上transform具备相同的缩放形式 X_train_standard = standardScaler.transform(X_train)#经过标准化后的训练数据集 X_test_standard = standardScaler.transform(X_test)#经过标准化后的测试数据集 print('经过标准化后的训练数据集\n',X_train_standard) print('经过标准化后的测试数据集\n',X_test_standard)
3 归一化:
3.1 原理:
注意这个不是按照特征列了,这个是按照样本,每一行进行操作。
它的原理是将每行数据求平方和开根号,然后用每个元素除以该值。
3.1.1 均值方差归一化
均值方差归一化=标准化?
在计算上,均值方差归一化和标准化是相同的。它们的区别主要在于术语的使用和应用的背景。在某些上下文中,人们更倾向于使用术语"均值方差归一化"来强调对数据的归一化处理,尤其是在统计学和数据分析领域。而在机器学习和数据预处理中,通常更倾向于使用术语"标准化"来描述这种线性变换。
3.1.2 向量归一化(单位范数归一化)
每个样本向量除以其L2范数,使得每个样本的特征向量都具有相同的长度。
L2范数的计算公式如下:

3.2 实战:(向量归一化)
from sklearn import preprocessing import numpy as np data = np.random.randint(1,10,(4,4)) data_normalized = preprocessing.normalize(data)#将矩阵的每行都执行归一化操作 print('归一化前的矩阵:\n',data) print('归一化后的矩阵:\n',data_normalized)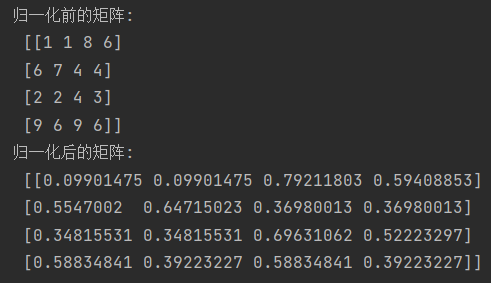
4 缩放:
4.1 原理:
将数据缩放到指定的区间,MinMaxScaler就是将我们的起始数据转化成0-1之间的数。
它就是让每个值减去最小值然后除以该特征下最大值和最小值的差,理解成数轴,区间内任何一个值距离最小值的距离一定小于最大值距离最小值的距离,然后做商,将它缩放到0-1之间。
但是这样也会有问题,如果某列中存在一个极值,非常大,那么在做除法时,得到的值会非常小。有别的做法可以解决,清除异常值,或者换一种对异常值不敏感的处理方法。
4.2 计算公式:
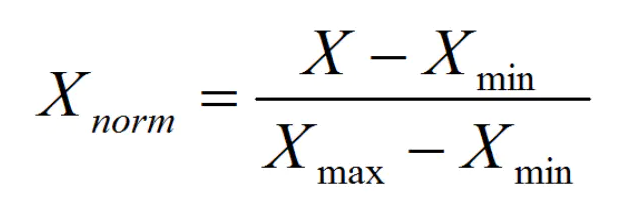
4.3 实战:
讯享网# MinMaxScaler把数据映射到0-1之间 from sklearn.preprocessing import MinMaxScaler import numpy as np x = np.random.randint(1,10,(5,5)) X = MinMaxScaler().fit_transform(x)#对每一列进行缩放 print('缩放前的数据:\n',x) print('缩放后的数据:\n',X)
5 特征:
5.1 原理:
在机器学习中,我们很多算法的要求是输入必须是数值型特征,但是我们遇到的很多数据都是那种文本类别的,所以我们就需要一种方式处理它,最简单就是对他进行编码,每一种类别对应一个数字,然后将该数字进行训练。例如:[male,female],这种我们就可以将它编码成 [0, 1]。
5.2 整数编码:
整数编码的作用机制就是将每一种类别特征与另外一个数字做映射。
对于这种映射也会存在问题,你比如说原来是男和女对立的,但是现在变成了0和1,变得可运算而且存在了大小关系,也就是转化后增添了许多原来不存在的关系因素。
所以就产生了另外一种编码方式Onehot。
5.3 独热编码:
它会将我们的数据变成二进制特征向量。比如现在有苹果、香蕉、梨,那么现在苹果的编码方式就是1,0,0香蕉就是0,1,0,梨也就对应0,0,1。显然这三个向量是非线性的,也就不存在之前说的大小和运算关系,它解决了类别独立的问题,但是他也产生了新的问题,就是如果我们某一列的类别特别多,那么产生的二进制向量维度会非常大,是我们的数据维度大大升高,同时矩阵还会变得很稀疏。
还有个问题就是如果我们transform的数据中的某些类别在fit时的数据中没有就会进行报错,说找不到该类别。这也对应如果我们的测试集和训练集的分布不同,就可能出现问题,比如说某个特征的某个类别在测试集中出现,而训练集中没有,这时转化拟合就会出现问题。但是如果独立处理的话就会没有意义,比如训练集中有一个列是水果,有苹果、香蕉,我们用整数编码变成了0和1,而在测试集中有一个西瓜,训练集中没有,我们也同样用整数编码变成了0,那这样两者的表达意思就不一样了,训练集中模型认为0是苹果,而现在0变成了西瓜,这就语意不对应了。
解决方法:在转化前将所有的类别指出,然后交给实类,让他们记住所有的分类,这样就不会产生上述现象了。
5.4 实战一(整数编码):
from sklearn.preprocessing import OrdinalEncoder #编码的顺序是根据字母顺序确定的 x = [['male', 'apple'], ['female', 'pear'], ['male', 'pear'],['transsexual', 'banana']] oe = OrdinalEncoder() oe.fit(x) X = oe.transform([['male', 'pear']]) print(X)![]()
5.5 实战二(独热编码):
讯享网from sklearn.preprocessing import OneHotEncoder #也是先按照字典序排序,然后编码 x = [['male', 'apple'], ['female', 'pear'], ['male', 'pear'],['transsexual', 'banana']] oe = OneHotEncoder() oe.fit(x) X = oe.transform([['female', 'pear']]).toarray() print(X)
- 第一个编码:1.
0.0,表示观测样本不是 'male'和'transsexual',而是’female'。 - 第二个编码同理。
![]()
6 二值化:
6.1 原理:
6.2 实战:
from sklearn.preprocessing import Binarizer import numpy as np x = np.array([[1, 2, 3, 4, 5]]) X = Binarizer(threshold=3).fit_transform(x) print(X)![]()
7 多项式特征:
7.1 原理:
多项式特征是指在机器学习中,通过对原始特征进行多项式转换,生成新的特征。这个转换过程是将原始特征的幂次方和交叉项组合起来,以构建更高阶的特征表示。
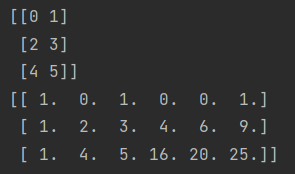
举个例子:[x1, x2],其对应的多项式特征为[1, x1, x2, x1^2, x1*x2, x2^2]
7.2 实战:
讯享网# 多项式特征(不同于对特征列进行操作,这个是对行进行操作的) from sklearn.preprocessing import PolynomialFeatures import numpy as np x = np.arange(6).reshape(3, 2) X = PolynomialFeatures(2).fit_transform(x) print(x) print(X)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/11653.html