
身为某世界一流退学的学生,大物实验自然是逃不过。本人有幸选择了大物实验最多的专业方向,从一级做到六级,直到上学期刚刚结束。大物实验里数据处理是占了很多时间的,那么怎么才能「优雅」地完成这一工作呢?
开始
大一的时候讲座推荐的软件是 Origin,画图、拟合等虽然方便,但完全鼠标操作,并且只有 Windows 上能运行,Wine 上有时会遇到个别功能不好用,很影响体验(当时我的电脑配置不好,玩不起虚拟机)。思来想去,还是觉得 Python 比较自然,于是故事就这样开始了。
在一级、二级大物中,需求基本是:散点画图(有时是对数)、线性拟合、组合的画图,以及不确定度计算和一般的数值计算。输入输出方面,要手工输入有时候多达几页的手写数据,画出来的图打印上交、计算出的结果手写进实验报告。
Python 做这些事情其实都不困难。画图用 Matplotlib 非常方便,也可以直接保存图片。数据计算自然是 NumPy。线性拟合的话,最初选择了 SciPy。输入输出还是比较基本,从文件读入。
于是,第一个实验「自由落体」的数据和处理就是这样:
讯享网
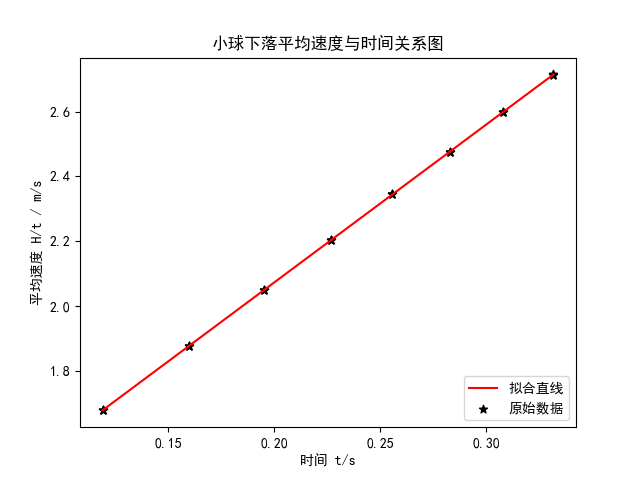
只是画了张图就这么麻烦,很明显,除了练习了 Python 之外,和 Origin 相比生产力负提升。
之后的问题就是简化这些过程了。
两年之后
经过一年多的开发,我将一些常用的画图和数据处理操作打包成库,并添加了方便的文件输入和自动生成 docx 文件的功能。同时将 Python 包 发布到了 PyPI(和 AUR 一样,在 PyPI 发布包的门槛几乎没有)。
这里以三级大物 β 射线吸收为例。现在,读入文件只需要这样:
数据做图也只要一行代码,一张图上多个曲线也只是一个参数的事,比如这是一张有三条线的图:
讯享网
画图并线性拟合也是非常常见的操作,于是也加入了库:

最后,一行代码将所有的数据和图片生成直接可以打印的 docx 文件,包含名字和日期:
文件如图所示,可以直接拿去打印了:
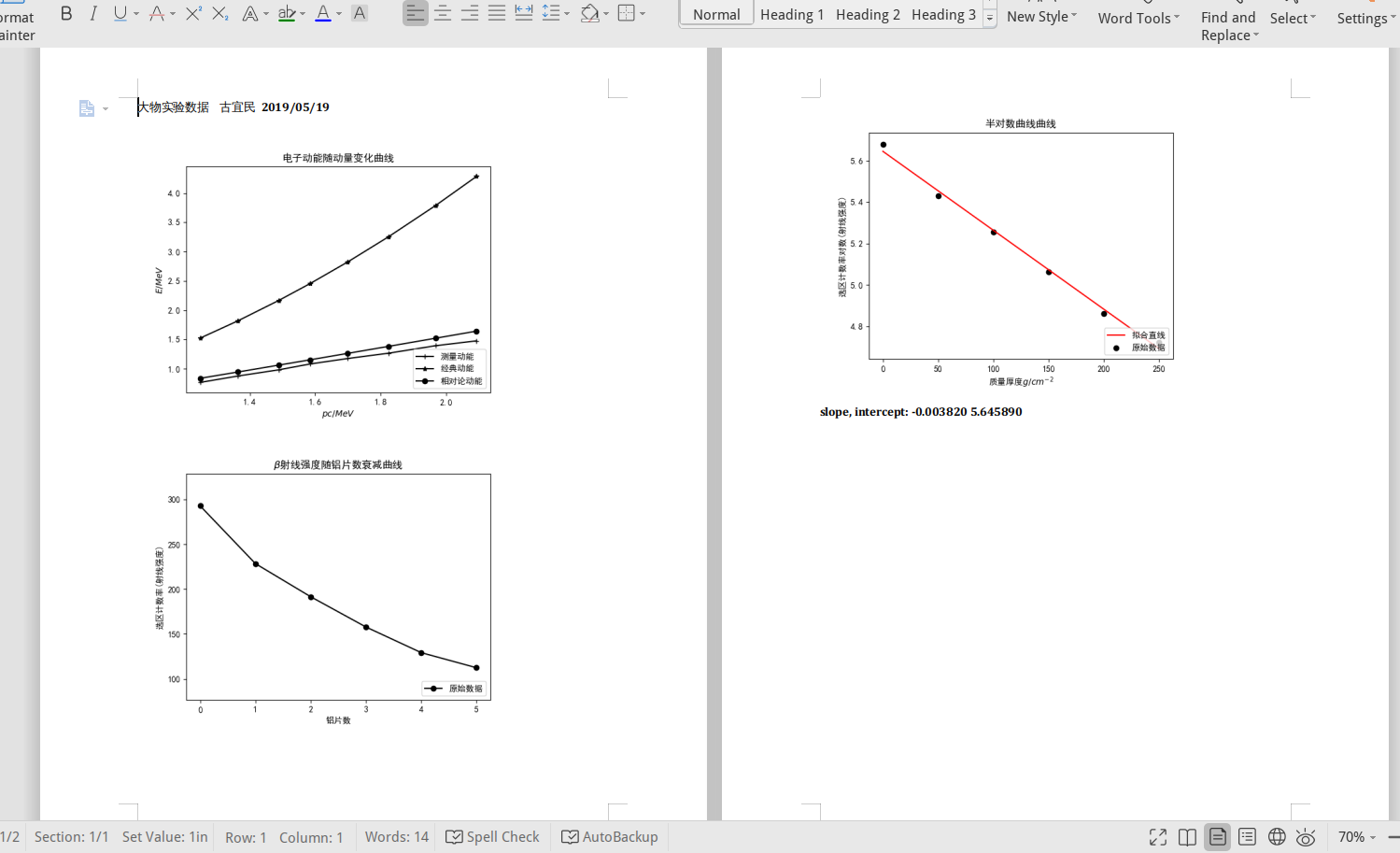
下面是整体代码:
整个代码不含空行和注释共 46 行,而上面的自由落体代码 45 行。可见包装程度还是不错的。先计算然后画这三张图,写上面的代码和 Origin 相比哪个更快呢?还是看个人习惯,反正我是比较习惯代码。至少,这说明了大物实验需要的数据处理还是有很多相似点的,以至于打包一些函数可以提高一些生产力。
用Java基础代码计算体脂率
当然,这只是一个例子,对于个别实验,不管怎么处理都是要多花写时间的(直流辉光等离子体,说的就是你)。
你可能会问,为什么没有误差分析的功能。这确实是一个问题:计算 A 类和 B 类不确定度等不同实验差别很大,水平有限,我能做的除了将常数打表提供最基础的功能外,好像就没什么了。并且,开发得差不多时已经到二级中期了,算不确定度也不常见了(所以,别被一级吓怕了),所以这部分也没怎么测试过,属于 TODO。
迟到的 Jupyter Notebook
以上还是标准的 Python,但五级大物时,我尝试了仅一次就发现明显 Jupyter Notebook 更适合做类似的工作——尽管它不能用 Vim 编辑代码!这下子,数据直接输入在 Notebook 里就好了,画图也是所见即所得,不用等一张一张弹出来了。而进行临时的运算也不必影响正常流程。如图:
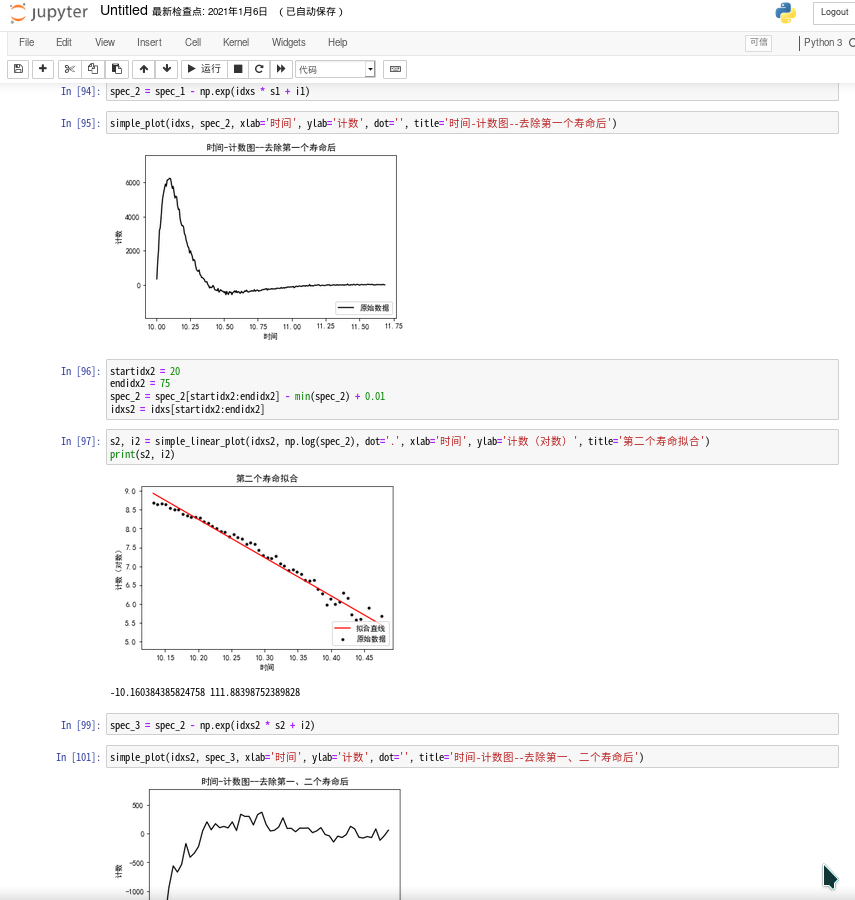
既然都到了 Jupyter,如果多人合作的话,JupyterHub 是非常不错的选择,可以多个人在一台服务器上使用 Jupyter Notebook。我之前配置的是每个用户一个隔离的 Docker 容器,里面的 Python 已经装好了包,可以直接使用,同时挂载了一个共享空间可以分享写好的 Notebook。其实 JupyterHub 有用 Github 帐号登录之类的权限管理功能,但当时我们是几个认识的人合作,就没有管这些。
具体的代码在我的 GitHub 上,如果有人在写大物实验报告的过程中无聊了想找个地方摸鱼浪费点时间,不妨来看看。
总结
如果您想尝试用 Python 处理大物实验数据,我可以比较负责地说对于 95% 以上的实验是完全没有问题的。使用 NumPy 和 SciPy 计算,Matplotlib 做图,配以 docx 生成、Jupyter Notebook 或 JupyterHub 团队合作,可以比较轻松(但不意味着节省时间)地完成所有需要的操作,并可以通过包装库提高效率。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/7648.html