
Linux常用命令总结(test develop engineer):
文件
cd
- cd .:切换到当前目录
- cd ..:切换到上一层目录
- cd -:切换到之前的工作目录,相当于撤销操作
- cd ~:切换到家目录
cp 复制
- cp anaconda-ks.cfg anaconda-ks-temp.cfg
- 拷贝文件夹 cp -r a a-temp
mv 移动和剪切命令
- 文件重命名: mv 123 123.bak
- mv 123 a 将123文件移动到a文件夹
mkdir
- -p, --parents 可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录;
- -v, --verbose 每次创建新目录都显示信息
touch
rm
- -i:防止不小心删除有用的文件,在删除之前给出提示。
- -r:递归的删除目录。
- -f:强制删除。
注意:rmdir命令只能删除空目录,rm –r命令可以删除目录及子目录。
head
- –n:使用-n可以指定显示的行数,–n5 = –n 5
tail
- -f或者—follow可以当正文信息发生变化时将变化的信息展示出来。
- –n:同上(head)
wc:命令显示文件行、单词和字符数
- -l:仅显示行数 line
- -w:仅显示单词数 word
- -c:仅显示字符数 chars
history
- !1050:执行第1050行
echo
将一个命令的输出作为另一个命令的参数
- echo “\$hostname” # 打印结果:$hostname
- num1=1;num2=2 echo $[$num1 + $num2] # 数学运算
- echo “$hostname” # zcc
- \也可以用作换行
-
zcc@DESKTOP-C33QO0S MINGW64 ~/Desktop $ echo a \ > d \ > c a d c zcc@DESKTOP-C33QO0S MINGW64 ~/Desktop
讯享网 - 单引号:禁止所有的命令行扩展功能
- 双引号:禁止所有的命令行扩展功能,但以下特殊符号除外:$,`,\,!
常用的快捷键
- Ctrl + A:光标移动到命令行开始处 after
- Ctrl + E:光标移动到命令行结尾处 end
- Ctrl + U:删除到命令行所有内容;
- Ctrl + 箭头:向左向右移动一个字。
find
- -name:查找与指定文件名相匹配的文件 find /etc/ -name "*init???"
- -size :+n:查找大于n、-n:小于等于n的文件。find /etc/ -size +2M、find . -size +12k
- -atime:查找访问时间超过/低于/等于n天的文件。
- -mtime[+/-]n:查找更改时间超过n天不到n天或正好等于n天的文件。
- -user loginID:查找属于loginID名(用户)的所有文件。find /root –user root、find /root –group root
- -type:查找某一类型的文件,如f(文件)或d(目录)。find /etc/ -name init* -type f。
重定向到文件中
- >:覆盖原文件内容
- >>:在原文件之后追加内容
sort
- -r:进行反向排序(降序),r是reverse的第一个字母。
- -f:忽略字符的大小写,f是folds的第一个字母。
- -n:以数字的顺序进行排序,n是numeric的第一个字母。
- -u:去掉输出中的重复行,u是unique的第一个字母。
- -t:-t c表示以c作为分隔符。
- -k:-k n表示按照第n个字段进行排序。
- -k n1,n2:表示先按第n1个字段进行排序,当第一个字段重复时再按照第二个字段排序。
uniq:去掉文件中相邻的重复行
- -c:在显示的行前冠以该行出现的次数
- -d:只显示重复行
- -i:忽略字符的大小写
- -u:只显示唯一的行,即只出现一次的行
chmod
- r:4 chmod 755 file
- w:2 chmod g+w file
- x:1
- -:0
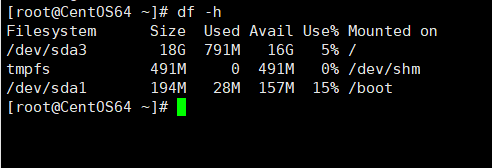
df:检查磁盘空间
- df:显示文件系统中磁盘使用和空闲区的数量
- df –h:列出每个系统(磁盘)的使用情况

讯享网- df –i:列出每一个文件系统的i节点的使用情况
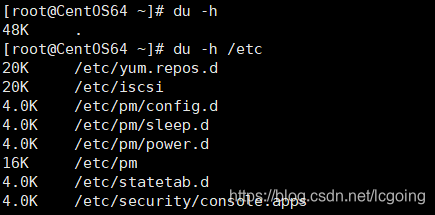
du:显示磁盘使用的总量
- du –sh:某用户Home目录下所使用的全部磁盘空间信息。
diff:比较两个文件的差别
- diff a.txt b.txt
grep
- .:匹配除换行符之外的任意字符
- [xyz]:匹配包含方括号中的任意一个字符;
- [^xyz]:匹配包括方括号字符以外的字符;[^xyz] 会匹配 xa、ys
- ^:grep ^s a.txt 匹配s开头的行
- $:grep s$ a.txt 匹配s结尾的行
- \w:字母或数字或文字或下划线
- \d:匹配数字
- \s:任意空白符
- \bhello\b:匹配单词hello \ba\w*\b # 匹配a开头的单词
- c*:将匹配0个(即空白)或多个字符c;
扩展正则
- +:重复一次或大于一次
- ?:重复零次或一次
- {n,m}:重复n到m次
- |:或
注意:在基本正则表达式中,元字符等已经失去了它们原来的意义,可以使用转义字符(\)。
工具:https://tool.oschina.net/regex
egrep = grep -E = 扩展正则
- -c:仅列出包含模式的行数;
- -i:忽略模式中字母的大小写;
- -n:在每行的最前面列出行号;
- -v:列出没有匹配模式的行;
- -o:只输出符合的字符串
awk
原理: 将文件逐行读入,默认以空格为分隔符切片,然后进行处理。
- BEGIN 处理文本之前要执行的操作 awk 'BEGIN {print "BEGIN", "BEGIN"}{print $1}' /at.xt
- END处理文本之后要执行的操作
- FS = -F 设置切片分隔符,默认是空格 awk -F : # 以冒号为分隔符
- RS 设置行读入的分隔符,默认是回车 awk 'BEGIN {RS="|"}{print $0}' #以|为分割逐行读入
- NR 已读的记录行数 awk 'NR==2{print $0}' /a.txt # 打印第二行
- awk '$9~/404|500/' nginx.log # 取出第9列的内容进行正则匹配
- awk '/hello/{print $0}' a.txt # 打印出现hello 的行,双斜杠包起来为正则

- awk 'NR==5' 、awk 'NR==5{print$0}' 、sed -n 5p # 打印第5行
- awk '{if($0==""){print NR}}' 、awk '/^$/ {print NR}' # 输出空行的行号
- grep -vE '^$'、sed '/^$/d'、awk '!/^$/ {print $0}' # 不输出空行
- awk '{(sum=sum+$6)}END{print sum}' # 统计第6列和
sed
流程:先行存储在模式空间,sed命令处理,送入屏幕,清空模式空间,再下一行。
双斜杠可以改为#等也是可以的,双斜杠之间是正则
- sed -e '4 a hello' a.txt # 第四行后面增加一行hello, -e是可省参数
- sed -e '4 i hello' a.txt # 第四行前面插入一行hello, -e可省
- sed -e '2,4 c hello' a.txt # 第2到4行被hello取代 -e可省
- sed -e '2,4 d hello' a.txt # 第2到4行被删除 -e可省
- sed -e '/hello/p' a.txt # 打印匹配到hello的行 -e可省
- sed -e 's/hello/hi/g' a.txt # 把全部hello用hi替换 -e可省
- sed -i 's/hello/hi/g' a.txt # 把全部hello用hi替换,并修改原文件
vi
- -R:以只读方式打开一个文件。
- 2、插入模式:
- (1)a:进入插入模式并在光标之后进行添加;
- (2)i:进入插入模式并在光标之前进行添加;
- 3、命令行下修改、删除与复制的操作:
- (2)dd:删除光标所在行;
- (3)yy:复制光标所在行;
- (10)p:将数据放置在当前行之下;(如果之前操作的数据是字符,意思为:将数据放置在光标之后)
- (11)P:将数据放置在当前行之上。(如果之前操作的数据是字符,意思为:将数据放置在光标之前)
- 4、存储和退出
- (1):w:将文件存入/写入磁盘;
- (2):q:退出vi 编辑器;
- (3):wq:将文件存入磁盘并退出vi 编辑器。
- 注意:可以在以上命令之后加上!,!是强制执行的意思。
tar
- -c :新建打包文件
- -t :查看打包文件的内容含有哪些文件名
- -x :解打包或解压缩的功能
- -C(大写)指定解压的目录,注意-c,-t,-x不能同时出现在同一条命令
- -j :通过bzip2的支持进行压缩/解压缩
- -z :通过gzip的支持进行压缩/解压缩
- -v :在压缩/解压缩过程中,将正在处理的文件名显示出来
- -f filename :filename为要处理的文件
- -C dir :指定压缩/解压缩的目录dir
压缩:tar -jcv -f filename.tar.bz2 要被处理的文件或目录名称
查询:tar -jtv -f filename.tar.bz2
解压:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
less
- -i 忽略搜索时的大小写
- /字符串:向下搜索“字符串”的功能 再按n跳转下一个,按N跳转上一个
- ?字符串:向上搜索“字符串”的功能
- 回车下滚动一行
- 空格滚动一页
- u 向前滚动半页
- Q 退出less 命令
xargs:把步骤1的内容作为步骤2的命令的选项参数拼接起来
- echo "/" | xargs ls -l = ls -l /
网络
netstat:查看网络端口
- -t:监控tcp协议的进程
- -l:listening
- -n:显示端口号信息
- -p:显示进程的PID
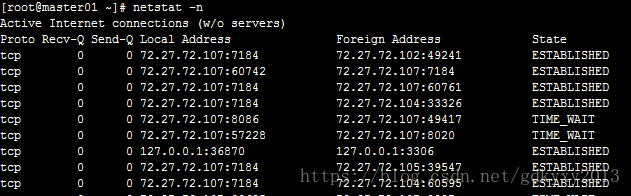
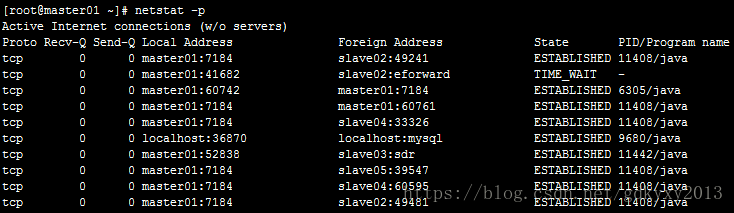
ifconfig:查看系统中所有网卡的IP、MAC信息
- up 启动指定网络设备/网卡。
- down 关闭指定网络设备/网卡。
ping
- -c:次数
curl
- -G = -X GET 发送get请求
- -d 指定请求数据 有-d指定为post请求
- -X POST 发送post请求
- -o 文件名 保存响应内容到文件
- -v 显示整个过程
- -s 不输出错误和进度信息
- -x 设置代理
性能
top
查看系统资源,相当于任务管理器,没隔三秒更新一次,q键退出
free:查看内存信息。
- -m:指的是以MB的格式显示。
ps
- –ef:查看系统进程;
- -a :不与terminal有关的所有进程
- -u :有效用户的相关进程
- -x :一般与a参数一起使用,可列出较完整的信息
kill:杀死正在运行的进程
- kill -9
no hub: 不挂起
yum -y
uname -r
Linux执行返回码:https://www.cnblogs.com/apple2016/p/6139106.html
bash
练习网址:https://www.nowcoder.com/activity/oj
变量
- hostname="zcc" # 创建变量
- echo “$hostname” # 打印变量
- unset hostname # 删除变量
- greeting = "hi, ""$hostname"! 字符串拼接
组数
- 定义:arry_name=(1,2,3)
- 取值:value = ${arry_name[2]} ${arry_name[*]}、${arry_name[@]} # 取所有值
- 赋值:arry_name[2] = 4
控制语句
- if
-
讯享网
a = 3, b = 2 $ if [ $a -eq $b ]; then echo "equal"; elif [ $a -lt $b ]; then ehco "small"; elif [ $a -gt $b ]; then echo "big"; fi - for
-
# 文件格式 for loop in 1 2 3 4 5 do echo "hello" done # 命令行格式 for i in $(cat a.txt); do echo "$i"; done # 空白行不输出, 空格后面的会输出到下一行 while while (( $int <= 5 )) do echo $int let "int++" done while read line; do echo $line; done<aa.txt # 输出与原文本一致
read 从文本或终端读取整行输入,每行末尾的换行不读入
- read a # 输入变量a的值
-
讯享网
read a b c 1 2 3 # a=1 b=2 c=3
参数
- $1 $2 # 第一个参数 第二个参数
- $0 # 文件名
- $# # 参数数量
- $* # 所有参数
- $? # 返回值
运算符
- 加法:`expr $a + $b`
- 减法:`expr $a - $b`
- 乘法:`expr $a \* $b`
- 除法:`expr $a / $b`
- 取余:`expr $a % $b`
- -eq ==
- -ne !=
- -gt >
- -lt <
- -ge >=
- -le <=
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/63659.html