
数据关系型图表
沈益
7/29/2019
4.1 带趋势线的散点图
mydata<-read.csv("配套资源/第4章 数据关系型图表/Scatter_Data.csv",stringsAsFactors=FALSE) ggplot(data = mydata, aes(x,y)) + geom_point(fill="black",colour="black",size=3,shape=21) + #geom_smooth(method="lm",se=TRUE,formula=y ~ splines::bs(x, 5),colour="red")+ #(h) geom_smooth(method = 'gam',formula=y ~s(x))+ #(g) #geom_smooth(method = 'loess',span=0.4,se=TRUE,colour="#00A5FF",fill="#00A5FF",alpha=0.2)+ #(f) scale_y_continuous(breaks = seq(0, 125, 25))+ theme( text=element_text(size=15,color="black"), plot.title=element_text(size=15,family="myfont",hjust=.5,color="black"), legend.position="none" )讯享网

4.2 残差分析图
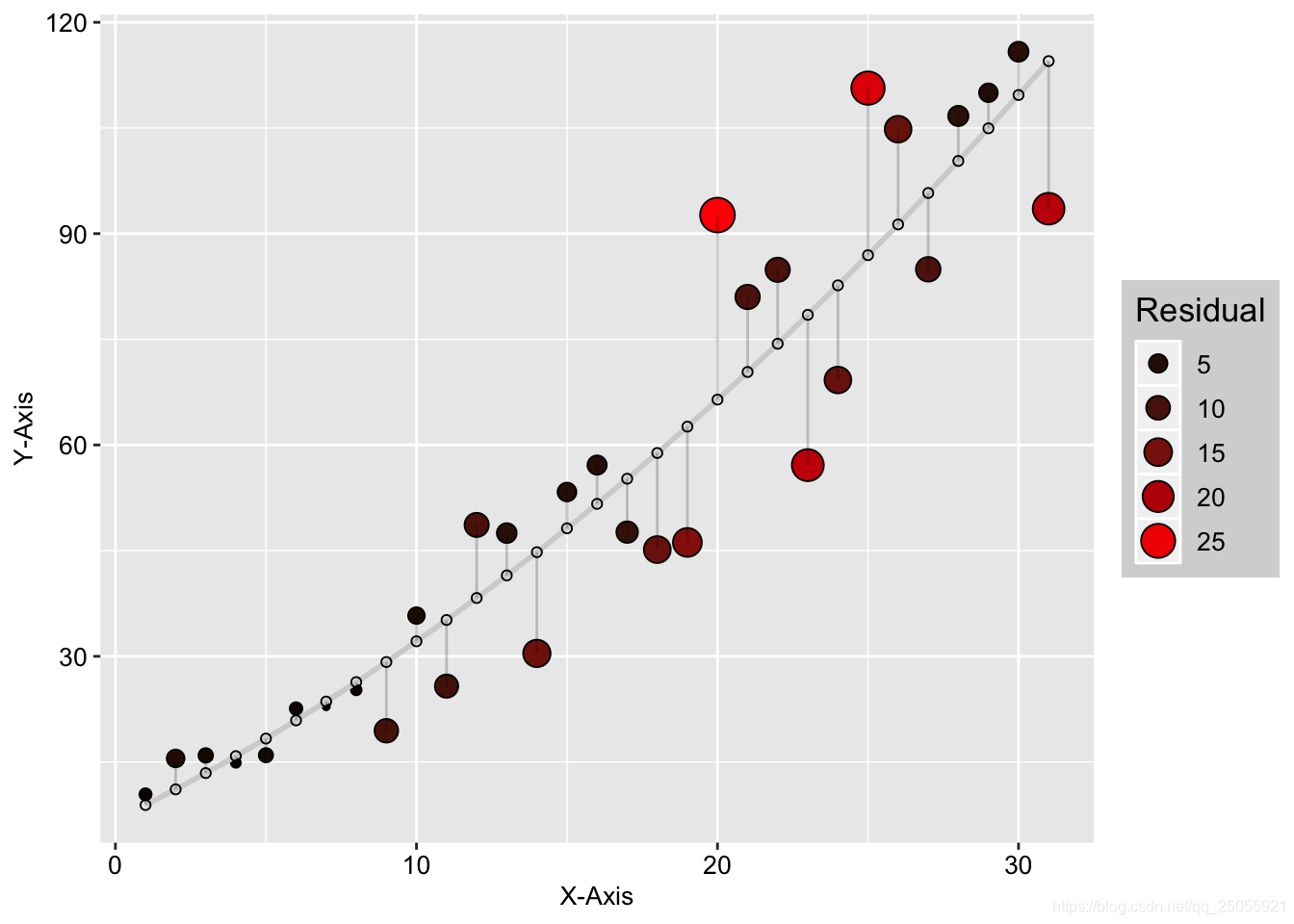
采用黑色到红色渐变颜色和气泡面积大小两个视觉暗示对应残差的绝对值大小,用于实际数据点的表示;而拟合数据点则用小空心圆圈表示,并放置在灰色的拟合曲线上。用直线连接实际数据点和拟合数据点。残差的绝对值越大,颜色越红、气泡也越大,连接直线越长,这样可以很清晰地观察数据的拟合效果 线性回归
讯享网 mydata <- read.csv("配套资源/第4章 数据关系型图表/Residual_Analysis_Data.csv", stringsAsFactors = FALSE) fit <- lm(y2 ~ x, data = mydata) # 对数据进行线性拟合 mydata$predicted <- predict(fit) # 拟合曲线的预测值 mydata$residuals <- residuals(fit) # 拟合曲线的残差值 mydata$Abs_Residuals <- abs(mydata$residuals) # 拟合曲线的残差值的绝对值 ggplot(mydata, aes(x, y2)) + geom_point(aes(fill = Abs_Residuals, size = Abs_Residuals), shape = 21, color = "black") + scale_fill_continuous(low = "black", high = "red") + # 修改填充颜色 geom_smooth(method = "lm", se = FALSE, color = "lightgrey") + geom_point(aes(y = predicted), shape = 1) + # 绘制预测拟合点 geom_segment(aes(xend = x, yend = predicted), alpha = .2) + # 绘制线段 guides(fill = guide_legend((title = "Residual")), size = guide_legend(title = "Residual")) + ylim(c(0, 150)) + xlab("X-Axis") + ylab("Y-Axis") + theme(text = element_text(size = 15, face = "plain", color = "black"), axis.title = element_text(size = 10, face = "plain", color = "black"), legend.position = "right", legend.title = element_text(size = 13, face = "plain", color = "black"), legend.background = element_rect(fill = alpha("black", 0.2)))
二次回归
mydata <- read.csv("配套资源/第4章 数据关系型图表/Residual_Analysis_Data.csv", stringsAsFactors = FALSE) fit <- lm(y5 ~ x+I(x^2), data = mydata) mydata$predicted <- predict(fit) mydata$residuals0 <- residuals(fit) mydata$Residuals <- abs(mydata$residuals0) ggplot(mydata, aes(x, y5)) + geom_point(aes(fill=Residuals, size = Residuals), shape = 21, color = "black") + geom_smooth(method = "lm", formula = y ~ x+I(x^2), se = FALSE, color = "lightgrey") + geom_segment(aes(xend = x, yend = predicted), alpha=0.2) + geom_point(aes(y = predicted), shape = 1) + scale_fill_continuous(low = "black", high = "red") + xlab("X-Axis") + ylab("Y-Axis") + guides(fill = guide_legend(title = "Residual"), size = guide_legend(title = "Residual")) + theme(text = element_text(size = 15, face = "plain", color = "black"), axis.title = element_text(size = 10, face = "plain", color = "black"), axis.text = element_text(size = 10, face = "plain", color = "black"), legend.position = "right", legend.title = element_text(size = 13, face = "plain", color = "black"), legend.text = element_text(size = 10, face = "plain", color = "black"), legend.background = element_rect(fill = alpha("black", 0.2)))
4.3 直方图
块状直方图
讯享网x <- rnorm(250, mean = 10, sd=1) # 随机生成250个,平均值是10,标准差为1的服从正态分布的数 step <- 0.2 breaks <- seq(min(x) - step, max(x) + step, step) # 指定分隔好的区间个数 hg <- hist(x, breaks = breaks, plot = FALSE) # 统计数据频数 bins <- length(hg$counts) yvals <- numeric(0) xvals <- numeric(0) for(i in 1:bins){ yvals <- c(yvals, hg$counts[i]:0) # 每一列有几个数就显示几个方块 xvals <- c(xvals, rep(hg$mids[i], hg$counts[i] + 1)) } dat <- data.frame(xvals, yvals) dat <- dat[yvals > 0,] # colormap <- colorRampPalette(rev(brewer.pal(11, "Spectral")))(32) # 创建梯度颜色 ggplot(dat, aes(x=xvals, y=yvals, fill=yvals)) + geom_tile(colour="black") + #scale_fill_gradientn(colours = colormap) scale_fill_distiller(palette = "Spectral") + ylim(0, max(yvals) * 1.3) + theme( text = element_text(size = 15, color = "black"), plot.title = element_text(size = 15, family = "myfont", face = "bold.italic", hjust = .5, colour = "black"), legend.background = element_rect(alpha("black", 0.1)), legend.position = c(0.9, 0.75) )

圆圈状点图
x <- rnorm(250, mean = 10, sd=1) # 随机生成250个,平均值是10,标准差为1的服从正态分布的数 step <- 0.2 breaks <- seq(min(x) - step, max(x) + step, step) # 指定分隔好的区间个数 hg <- hist(x, breaks = breaks, plot = FALSE) # 统计数据频数 bins <- length(hg$counts) yvals <- numeric(0) xvals <- numeric(0) for(i in 1:bins){ yvals <- c(yvals, hg$counts[i]:0) # 每一列有几个数就显示几个方块 xvals <- c(xvals, rep(hg$mids[i], hg$counts[i] + 1)) } dat <- data.frame(xvals, yvals) dat <- dat[yvals > 0,] colormap <- colorRampPalette(rev(brewer.pal(11, "Spectral")))(32) # 创建梯度颜色 ggplot(dat, aes(x=xvals, y=yvals, fill=yvals)) + geom_point(color = "black", shape=21, size = 4) + scale_fill_gradientn(colours = colormap) + ylim(0, max(yvals)*1.3) + theme( text = element_text(size = 15, color = "black"), plot.title = element_text(size = 15, family = "myfont", face = "bold.italic", hjust = .5, color = "black"), legend.background = element_blank(), legend.position = c(0.9, 0.75) )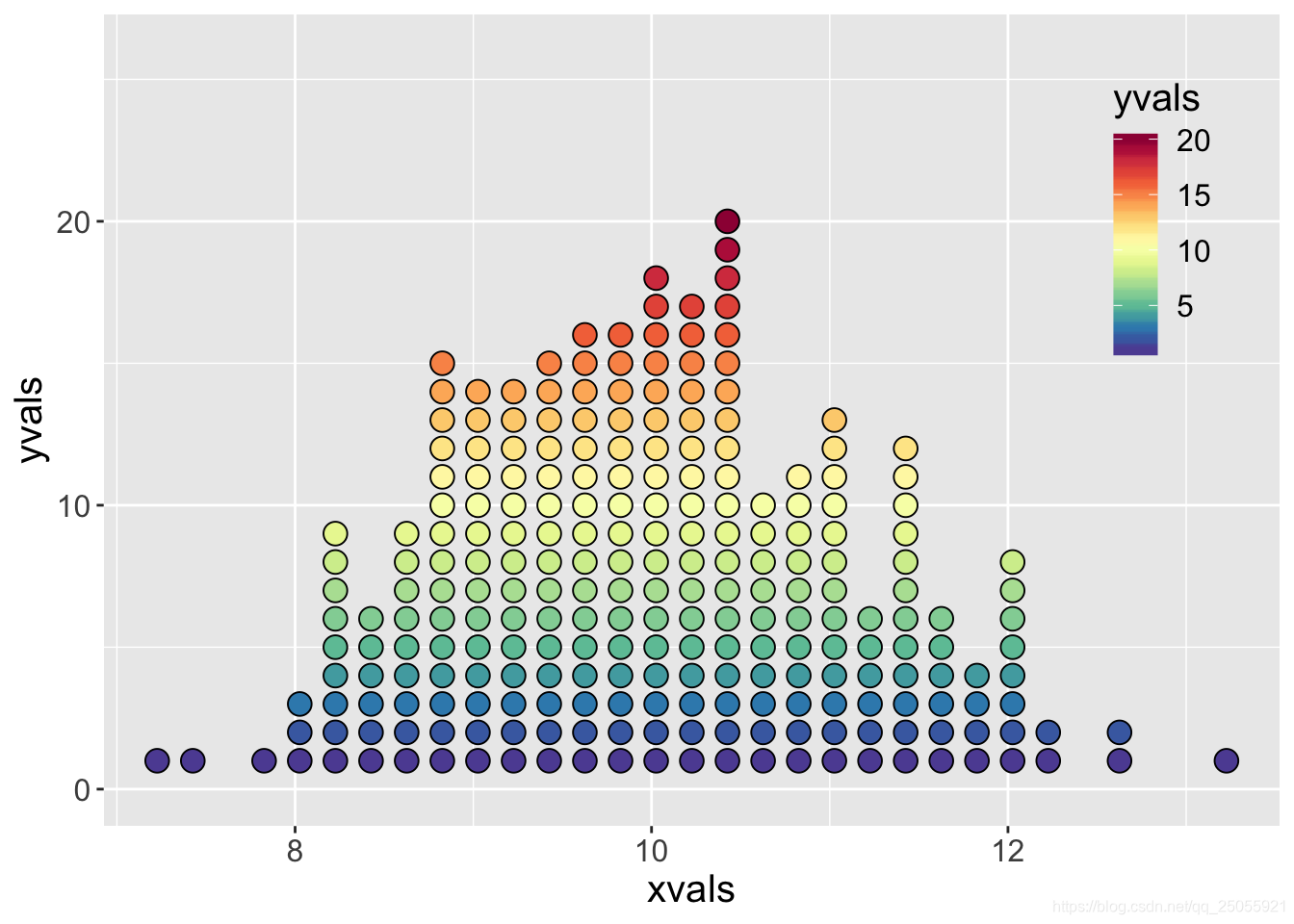
4.4 Q-Q图
P-P图(或 Q-Q 图)可检验的分布包括:beta distribution;t-distribution;chi-squrae;gamma distribution;normal distibution; uniform distribution; Pareto distribution; logistic distributon 一般来说,当比较两组样本时,Q-Q图是一种比直方图更加有效的方法。

讯享网df <-data.frame(x=rnorm(250 , mean=10 , sd=1)) ggplot(df, aes(sample = x))+ # 图需要制定 sample geom_(shape =1) + geom__line(fill = "#00AFBB",size=1)

P-P图
library(CircStats)讯享网pp.plot(x)

4.5 散点图
散点图通常用于显示和比较数值,不仅可以显示趋势,还能显示数据集群的形状,以及在数据云团中各个点的关系。这类散点图非常适合聚类分析。常用的聚类方法包括 K-means, FCM, KFCM, DBSCAN, MeanShift 等。
带透明度设置的散点图
mydata<-read.csv("配套资源/第4章 数据关系型图表/HighDensity_Scatter_Data.csv",stringsAsFactors=FALSE) ggplot(data = mydata, aes(x,y)) + geom_point(colour="blue",alpha=0.2)+ # 设置透明度 labs(x = "Axis X",y="Axis Y")+ theme( text=element_text(size=15,color="black"), plot.title=element_text(size=15,family="myfont",face="bold.italic",hjust=.5,color="black"), legend.position="none" )
k-means 聚类的散点图
讯享网mydata <- read.csv("配套资源/第4章 数据关系型图表/HighDensity_Scatter_Data.csv") kmeansResult <- kmeans(mydata, 2, nstart = 20) # 聚类的数量为 2,随机数据集选择次数为 200 mydata$cluster <- as.factor(kmeansResult$cluster) ggplot(mydata, aes(x, y, color=cluster)) + geom_point(alpha=0.2) + scale_color_manual(values = c("#00AFBB", "#FC4E07")) + labs(x = "Axis X", y = "Axis Y") + theme( text = element_text(size = 15, face = "bold.italic", color = "black"), plot.title = element_text(size = 15, face = "bold.italic", color = "black"), legend.background = element_blank(), legend.position = c(0.85, 0.15) )

带椭圆标定的聚类散点
mydata <- read.csv("配套资源/第4章 数据关系型图表/HighDensity_Scatter_Data.csv") mydata$cluster <- as.factor(kmeansResult$cluster) ggplot(data = mydata, aes(x,y,color=cluster)) + geom_point (alpha=0.2)+ # 绘制透明度为0.2 的散点图 stat_ellipse(aes(x=x,y=y,fill= cluster), geom="polygon", level=0.95, alpha=0.2) + #绘制椭圆标定不同类别,如果省略该语句,则绘制图3-1-7(c) scale_color_manual(values=c("#00AFBB","#FC4E07")) +#使用不同颜色标定不同数据类别 scale_fill_manual(values=c("#00AFBB","#FC4E07"))+ #使用不同颜色标定不同椭类别 labs(x = "Axis X",y="Axis Y")+ theme( text=element_text(size=15,color="black"), plot.title=element_text(size=15,family="myfont",face="bold.italic",color="black"), legend.background=element_blank(), legend.position=c(0.85,0.15) )
4.6 多数据系列散点图
多数据系列散点图只是在单数据系列上添加新的数据系列,使用不同的填充颜色或者形状区分数据系列,R 中 ggplot2 包中的 geom_point()函数可以根据数据类别映射到不同的填充颜色与形状,以及边框颜色。
讯享网mydata <- read.csv("配套资源/第4章 数据关系型图表/HighDensity_Scatter_Data.csv", stringsAsFactors = FALSE) mydata <- mydata[round(runif(300, 0, 10000)), ] kmeanResult <- kmeans(mydata, 2, nstart = 20) mydata$cluster <- as.factor(kmeanResult$cluster) ggplot(mydata, aes(x, y, fill
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/62196.html