

聚类和分类
聚类
聚类算法是将一系列文档聚团成多个子集或簇,聚类的结果是要求簇内的文档之间要尽可能相似,而簇间的文档要尽可能不相似。
聚类是无监督学习的一种最普遍的形式,无监督意味着不存在对文档进行类别标注。
分类
分类是监督学习的一种形式,其目标是对人类赋予数据的类别差异进行学习或复制。
而在以聚类为代表的无监督学习中,并没有这样的人来对类别的差异进行引导。
K-means算法
K-均值算法是最重要的扁平聚类算法,它的目标是最小化文档到其簇中心的欧氏距离平方的平均值。
步骤
1、随机选取k个初始质心
2、计算所有点离质心的距离,将每个点划分到最近的质心中成为聚类
3、计算每个聚类的平均值,并作为新的质心
4、重复2-3,直到这k个质心不再变化(收敛了),或执行了足够多的迭代
示例
声明:以下标号并不是顺序标号,而是对应上文的步骤标号,这样方理解。
首先我选定了这6个点作为示范

他们在坐标上的分布如下图

1、选取P1、P2作为初始质心(当然其他的也可以)


2、算出每个点距离初始质心的距离,选择离他最近的初始质心成为一个类


一类:P1
二类:P2、P3、P4、P5、P6
3、重新计算新的质心(这个质心可以是虚拟的,意思就是不是之前存在的点)
红色标记为新的质心


我们可以看到新的质心中P1还是之前存在的点,而点A是新生成的质心,并不是之前存在的点!!
一类:P1
二类:P2、P3、P4、P5、P6
质心还在变化,所以要继续进行2、3步骤
2、算出每个点距离质心距离,选择距离比较近的质心组成一个类


一类:P1、P2、P3
二类:P3、P4、P5
3、重新计算簇中的质心


质心还在变化,所以要继续进行2、3步骤
2、算出每个点距离质心距离,选择距离比较近的质心组成一个类


3、重新计算簇中的质心


4、这K个质心不再变化,聚类结束
问题
1、K如何制定?
手肘法、Canopy算法、与层次聚类结合、稳定性方法、系统演化方法...
2、初始质心如何选择?
随机的选取初始中心、使用层次聚类技术、Canopy算法
以下具体讲解Canopy算法,其他方法请参考参考文献[1]
Canopy算法
什么是Canopy算法?
与传统的聚类算法(比如K-means)不同,Canopy聚类最大的特点是不需要事先指定k值(即clustering的个数),因此具有很大的实际应用价值。与其他聚类算法相比,Canopy聚类虽然精度较低,但其在速度上有很大优势,因此可以使用Canopy聚类先对数据进行“粗”聚类,得到k值,以及大致的K个初始质心,再使用K-means进行进一步“细”聚类。所以Canopy+K-means这种形式聚类算法聚类效果良好。
步骤
我们假设每个数据用小圆点来表示。在计算机中用 List 集合存储。 Canopy 算法首先选择两个距离阈值:T1 和 T2,其中 T1 > T2
(1)原始状态下的数据还没有分类,所以从集合中取出一点 P,将 P 作为第一个类, 我们也将这个类称为 Canopy。

(2)继续从集合中取点,比如R,计算R到已经产生的所有Canopy的距离,如果到某个Canopy的距离小于T1,则将R加入到该Canopy;如果R到所有Canopy中心的距离都大于T1,则将R作为一个新Canopy,如下图中的Q就是一个新的Canopy。


(3)如果P到该Canopy距离小于T2,则表示P和该Canopy已经足够近,此时将P从从集合中删除,避免重复加入到其他Canopy。
(4)对集合中的点继续执行上述操作直到集合为空,算法结束,聚类完成。
以上内容搬运来源水印(参考文献[2])
以下为我个人对此算法的看法:
个人拙见,如有错误还请不吝赐教。
在我对这个算法进行学习的过程时,通过查阅资料我没有找到关于T1、T2的确定方法,所以在这方面我个人存有疑问,所以我个人采用的是如下方法:
(1)首先我们确定一个T(取值方法下面会给出)。
(2)原始状态下的数据还没有分类,所以从集合中取出一点P,将P作为第一个类,我们也将类称为Canopy。
(3)继续从集合中取点,比如R,计算R到已经产生的所有Canopy的距离,如果到某个Canopy的距离小于T,则把该点从列表中删除;如果R到所有Canopy中心的距离都大于T,则将R从列表中取出作为一个新Canopy。
(4)对集合中的点继续执行上述操作直到集合为空,算法结束,聚类完成。
在我的方法中我仅仅使用了一个T,这个T的作用相当于上文方法中的T2,因为上文所说的方法中T1并没有起到什么作用。尽管如果有的点到质心的距离小于T1,那这个点不会从列表中删除。而循环终止的条件为列表中元素为空,所以我只用了一个T,如果距离小于T则直接把这个点划分为这个类中,把这个点从列表中删除。如果这个点大于T,则直接把这个点从列表中取出来当做质心创建一个新的类。
T的取值
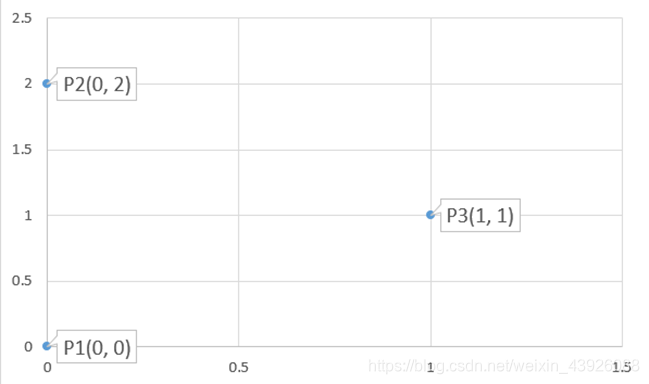
以这三个点为例:
对点P1
d(P1-P2)=2 d(P1-P3)=1. 平均值(ave1)= 1. 讯享网
对点P2
讯享网d(P2-P1)=2 d(P2-P3)=1. 平均值(ave2)= 1.
对点P3
d(P3-P1)= 1. d(P3-P2)= 1. 平均值(ave3)= 1. 所以T=(ave1+ave2+ave3)/3 = 1.
思路小结

参考文献
[1]从零开始实现Kmeans聚类算法:https://blog.csdn.net/u0/article/details/
[2]Canopy聚类算法过程:https://blog.csdn.net/u0/article/details/
[3]划分方法聚类(三) Canopy+K-MEANS 算法解析:https://blog.csdn.net/wojiaosusu/article/details/
[4]Mahout之聚类Canopy分析:https://blog.csdn.net/yclzh0522/article/details/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/58526.html