
前言:2007年,编写Pig虽然比MapReduce编程简单,但是还是要学习。于是Facebook发布了Hive,支持使用SQL语法进行大数据计算,写个Select语句进行数据查询,Hive会将SQL语句转化成MapReduce计算程序。这样,熟悉数据库的数据分析师和工程师便可以无门槛地使用大数据进行数据分析和处理了,Hive出现后大大降低了Hadoop的使用难度,迅速得到开发者和企业的追捧。
一、Hive简介
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查 询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
Hive特点:
- 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
二、Hive的体系架构
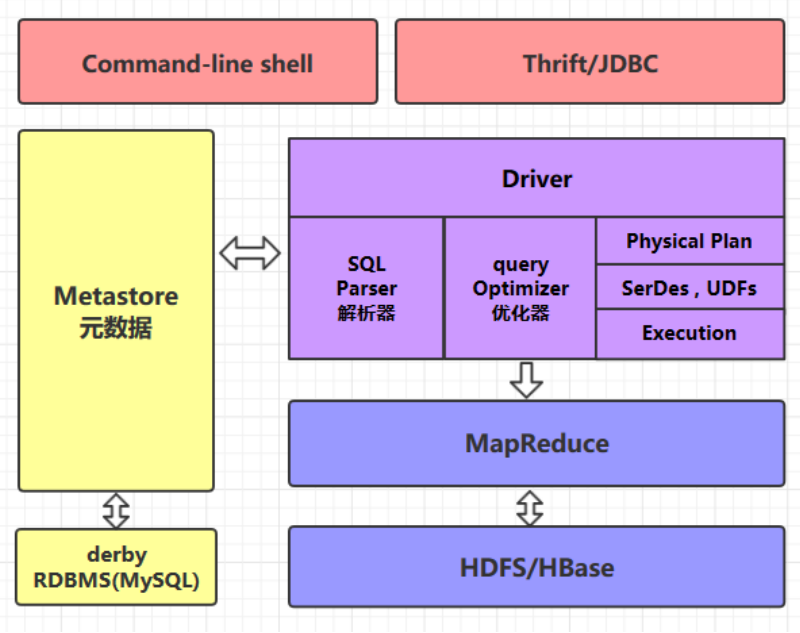
2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
command-line shell:通过 hive 命令行的的方式来操作数据;
thrift/jdbc:通过 thrift 协议按照标准的 JDBC 的方式操作数据。
2.2 Metastore
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认 存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户 端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/
sparksql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto /impala/sparksql 中创建一张表,在 Hive 中也可以直接使用。
2.3 HQL的执行流程
Hive 在执行一条 HQL 的时候,会经过以下步骤:
1. 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树
AST Tree;
2. 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;

3. 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
4. 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的
ReduceSinkOperator,减少 shuffle 数据量;
5. 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
6. 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
三、Hive数据类型
3.1 基本数据类型
Hive 表中的列支持以下基本数据类型:
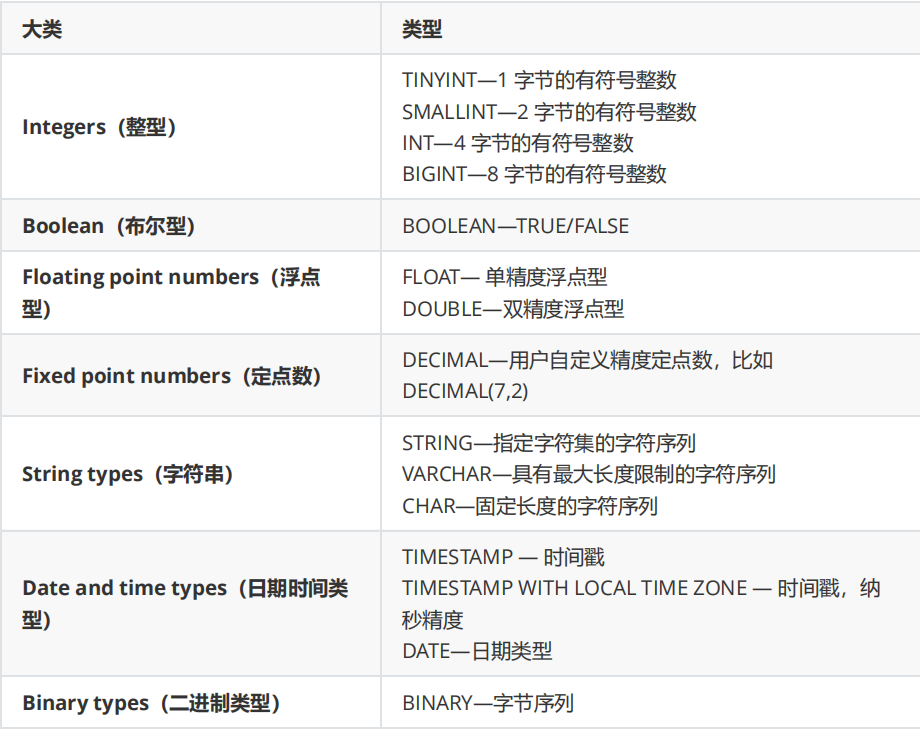
TIMESTAMP 和 TIMESTAMP WITH LOCAL TIME ZONE 的区别如下:
- TIMESTAMP WITH LOCAL TIME ZONE:用户提交时间给数据库时,会被转换成数据库所
- 在的时区来保存。查询时则按照查询客户端的不同,转换为查询客户端所在时区的时间。
- TIMESTAMP :提交什么时间就保存什么时间,查询时也不做任何转换。
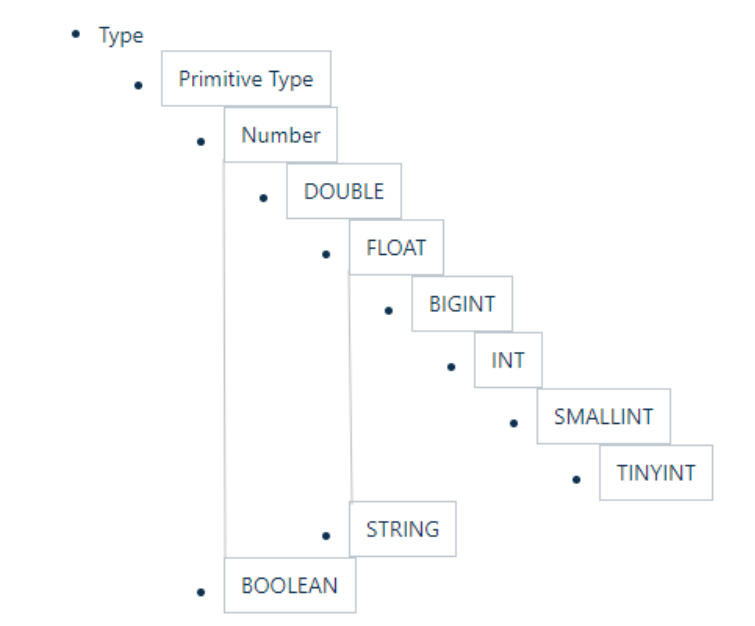
3.2 隐式转换
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例 如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类 型隐式转换为 DOUBLE 类型。
3.3 复杂类型

3.4 示例
如下给出一个基本数据类型和复杂数据类型的使用示例:
CREATE TABLE students( name STRING, -- 姓名 age INT, -- 年龄 subject ARRAY<STRING>, --学科 score MAP<STRING,FLOAT>, --各个学科考试成绩 address STRUCT<houseNumber:int, street:STRING, city:STRING, province: STRING> --家庭居住地址 ) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";讯享网
四、Hive内容格式
当数据存储在文本文件中,必须按照一定格式区别行和列,如使用逗号作为分隔符的 CSV 文件
(Comma-Separated Values) 或者使用制表符作为分隔值的 TSV 文件 (Tab-Separated Values)。但此时 也存在一个缺点,就是正常的文件内容中也可能出现逗号或者制表符。
所以 Hive 默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在文件中。Hive默认 的行和列分隔符如下表所示。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/57085.html