
- 本文转自:安慰剂检验:最强攻略
- 复制这篇博文原因无他,只是害怕原文被删后无法找到这么简捷清晰的安慰剂检验文章!
一、 缘起
- 开学瞎折腾一段时候之后,终于有时间写自己一直念兹在兹的安慰剂检验了。po 主想写这个教程的初衷其实很简单,因为在目前流行的双重差分方法中,安慰剂检验已经成为和平行趋势一样必不可少的检验流程。
- 这本来是一种在思路上很直观,在具体操作上也并不复杂的方法。但是,目前网络上流行的教程,多数只讲怎么写代码。而且代码似乎也并不简洁,动辄十几行、乃至几十行代码。另外,作者也没有告诉我们其间的原理。这也是 po 主一直不赞成的,因为我们学的是计量经济学,不是 Stata 经济学。
- 因为,最终还是决定自己动手写一篇教程,记录一下自己的学习经历。
二、 理论逻辑
我们先引入一个经典的 DID 模型:

讯享网

三、 permute 命令
- 现存的教程,多使用 forvalue 循环,随机抽取样本进行一定次数的回归。这种方法在操作的过程中,至少会生成好几个文件。命令也少则几行,多则几十行。而现在我们引入 permute 命令,一行代码即可实现安慰剂检验。
- permute 的基本语法如下:
permute permvar exp_list [, options] : command 讯享网
permvar : 需要进行随机抽样的变量,即 DID 中的 ,或交互项
exp_list : 需要提取的统计量,一般是回归系数
options 有以下设定:
reps(#) : 抽样次数
enumerate : 计算所有可能的不同排列
rseed(#) : 设定抽样种子
strara(varlist) : 分层抽样
saving(file) : 保存抽样值
command : 回归命令
四、数据
我们先调入数据。这份数据来自普林斯顿大学的 DID 教学课件,可以通过网站:"http://dss.princeton.edu/training/Panel101.dta "下载。设定好处理组和处理时间之后,我们先进行简单的回归。

讯享网cd "~/Desktop" use "Panel101.dta", clear gen time = (year >= 1994) & !missing(year) gen treat = (country > 4) & !missing(country) replace y = y / 1e+09 gen did = time * treat reghdfe y did, absorb(country year) vce(robust)
- 回归结果如下。使用双固定效应之后,交互项 did 在 10% 的统计水平显著。
. reghdfe y did, absorb(country year) vce(robust) (MWFE estimator converged in 2 iterations) ------------------------------------------------------------------------------ | Robust y | Coefficient std. err. t P>|t| [95% conf. interval] -------------+---------------------------------------------------------------- did | -2.520 1.286 -1.960 0.055 -5.098 0.059 _cons | 2.493 0.406 6.147 0.000 1.679 3.306 ------------------------------------------------------------------------------ 五、安慰剂检验:方法 1
- 接下来,我们进行安慰剂检验。对交互项随机抽取 500 次,查看系数是否与基准估计结果存在显著差异。
- 下面汇报了抽样估计结果。我们只需要关注 beta 行即可。500 次抽样中,仅有一次结果在基准回归系数的右侧,占总抽样次数的 0.2%,所以我们可以看到它的 p value = 0.0020。这是单侧检验的结果。对于双侧检验而言,p value 则等于 0.0040。
- 可以看到,无论是单侧检验还是双侧检验,都表明在随机抽样的情况下,基准回归系数 -2.50 是一个小概率事件。这说明我们的安慰剂检验是成立的。
讯享网cap erase "simulations.dta" permute did beta = _b[did] se = _se[did] df = e(df_r), /// reps(500) rseed(123) saving("simulations.dta"): /// reghdfe y did, absorb(country year) vce(robust)
- 这是获取交互项系数以及标准误,以及残差项的自由度:详见https://bbs.pinggu.org/thread-1087267-1-1.html
Monte Carlo permutation results Number of observations = 70 Permutation variable: did Number of permutations = 500 Command: reghdfe y did, absorb(country year) vce(robust) beta: _b[did] se: _se[did] df: e(df_r) ------------------------------------------------------------------------------- | Monte Carlo error | ------------------- T | T(obs) Test c n p SE(p) [95% CI(p)] -------------+----------------------------------------------------------------- beta | -2. lower 1 500 .0020 .0020 .0001 .0111 | upper 499 500 .9980 .0020 .9889 .9999 | two-sided .0040 .0028 .0000 .0095 | se | 1. lower 499 500 .9980 .0020 .9889 .9999 | upper 1 500 .0020 .0020 .0001 .0111 | two-sided .0040 .0028 .0000 .0095 | df | 53 lower 500 500 1.0000 .0000 .9926 1.0000 | upper 500 500 1.0000 .0000 .9926 1.0000 | two-sided 1.0000 .0000 . . ------------------------------------------------------------------------------- Notes: For lower one-sided test, c = #{
T <= T(obs)} and p = p_lower = c/n. For upper one-sided test, c = #{
T >= T(obs)} and p = p_upper = c/n. For two-sided test, p = 2*min(p_lower, p_upper); SE and CI approximate. 5.1 回归系数图
- 接下来,我们按照固定范式,绘制回归系数的分布图。具体代码如下:
讯享网// 回归系数 use "simulations.dta", clear gen t_value = beta / se gen p_value = 2 * ttail(df, abs(beta/se)) #delimit ; dpplot beta, xline(-2.520, lc(black*0.5) lp(dash)) xline(0, lc(black*0.5) lp(solid)) xlabel(-3(1)3) xtitle("Estimator", size(*0.8)) xlabel(, format(%4.1f) labsize(small)) ytitle("Density", size(*0.8)) ylabel(, nogrid format(%4.1f) labsize(small)) note("") caption("") graphregion(fcolor(white)) ; #delimit cr
- 绘图结果如下。通过系数分布图,我们也可以清洗的观察到,随机抽样系数以零为均值,呈正态分布。仅有一次抽样系数位于 -2.520 的右侧。


5.2 t 值图
- 绘图结果如下。观察下图,我们可以得出相似的结论,大部分随机抽样结果的 t 值都位于零值附近,仅有少数估计结果的 t 值小于基准回归结果(-1.960)。
// t 值 #delimit ; dpplot t_value, xline(-1.960, lc(black*0.5) lp(dash)) xline(0, lc(black*0.5) lp(solid)) xtitle("T Value", size(*0.8)) xlabel(, format(%4.1f) labsize(small)) ytitle("Density", size(*0.8)) ylabel(, nogrid format(%4.1f) labsize(small)) note("") caption("") graphregion(fcolor(white)) ; #delimit cr 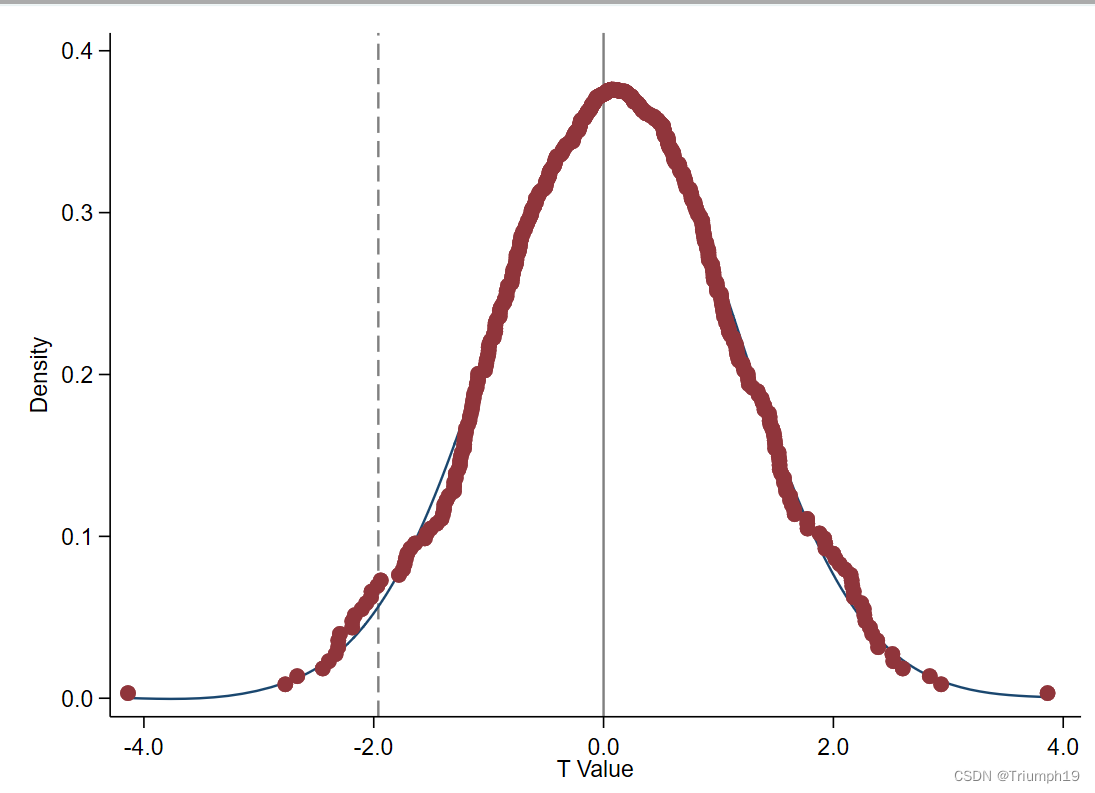
六、安慰剂检验:方法 2
- 与第一种方法直接抽取交互项不同的是,第二种方法是抽取处理组。只需要将permute 后面的 did 替换为 treat 即可:
讯享网*- 第二种抽样方法 use "Panel101.dta", clear gen time = (year >= 1994) & !missing(year) gen treat = (country > 4) & !missing(country) replace y = y / 1e+09 gen did = time * treat cap erase "simulations.dta" permute treat beta = _b[c.treat#c.time] se = _se[c.treat#c.time] df = e(df_r), /// reps(500) rseed(123) saving("simulations.dta"): /// reghdfe y c.treat#c.time, absorb(country year) vce(robust)
- 抽样结果如下。单侧检验 p 值为0.004,双侧检验结果为 0.008,都是小概率事件。安慰剂检验通过。
Monte Carlo permutation results Number of observations = 70 Permutation variable: treat Number of permutations = 500 Command: reghdfe y c.treat#c.time, absorb(country year) vce(robust) beta: _b[c.treat#c.time] se: _se[c.treat#c.time] df: e(df_r) ------------------------------------------------------------------------------- | Monte Carlo error | ------------------- T | T(obs) Test c n p SE(p) [95% CI(p)] -------------+----------------------------------------------------------------- beta | -2. lower 2 500 .0040 .0028 .0005 .0144 | upper 498 500 .9960 .0028 .9856 .9995 | two-sided .0080 .0040 .0002 .0158 | se | 1. lower 467 500 .9340 .0111 .9086 .9541 | upper 33 500 .0660 .0111 .0459 .0914 | two-sided .1320 .0151 .1023 .1617 | df | 53 lower 500 500 1.0000 .0000 .9926 1.0000 | upper 500 500 1.0000 .0000 .9926 1.0000 | two-sided 1.0000 .0000 . . ------------------------------------------------------------------------------- 6.1 回归系数图
- 我们同样可以绘制一个回归系数分布图:
- 所得结果与前面的基本一致:
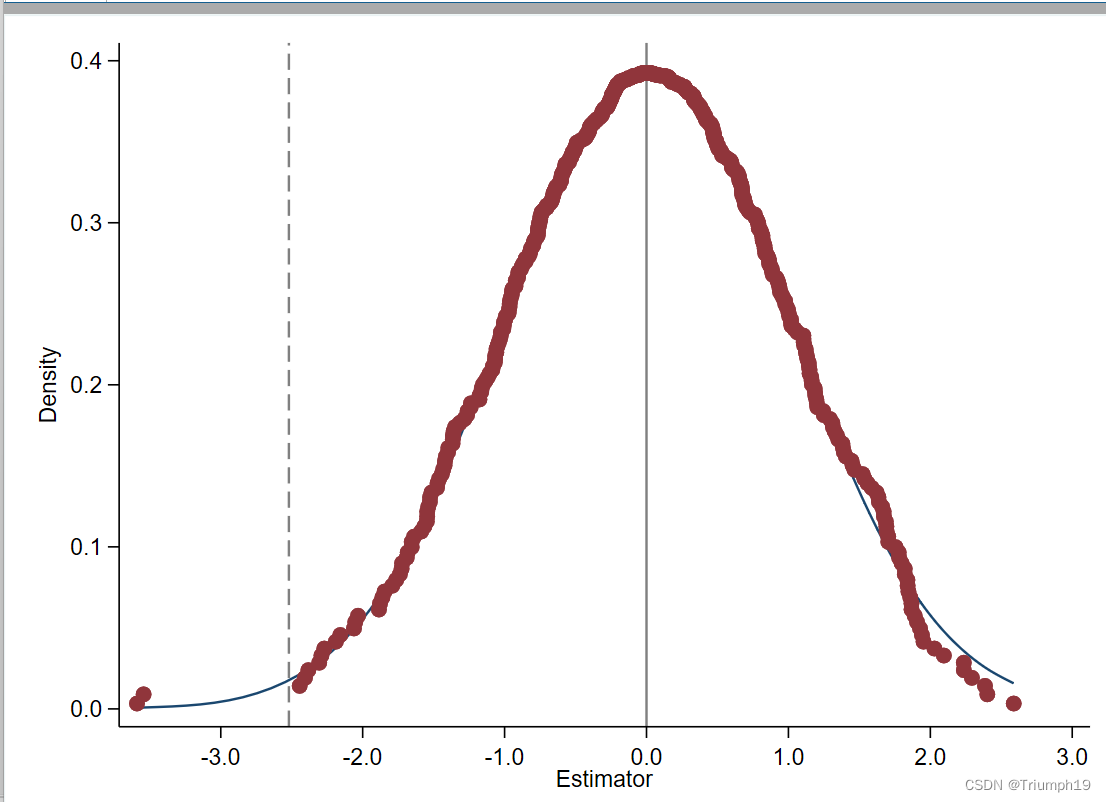
6.2 t 值图
-下面是 t 值分布图:
讯享网 // t 值 #delimit ; dpplot t_value, xline(-1.960, lc(black*0.5) lp(dash)) xline(0, lc(black*0.5) lp(solid)) xtitle("T Value", size(*0.8)) xlabel(, format(%4.1f) labsize(small)) ytitle("Density", size(*0.8)) ylabel(, nogrid format(%4.1f) labsize(small)) note("") caption("") graphregion(fcolor(white)) ; #delimit cr
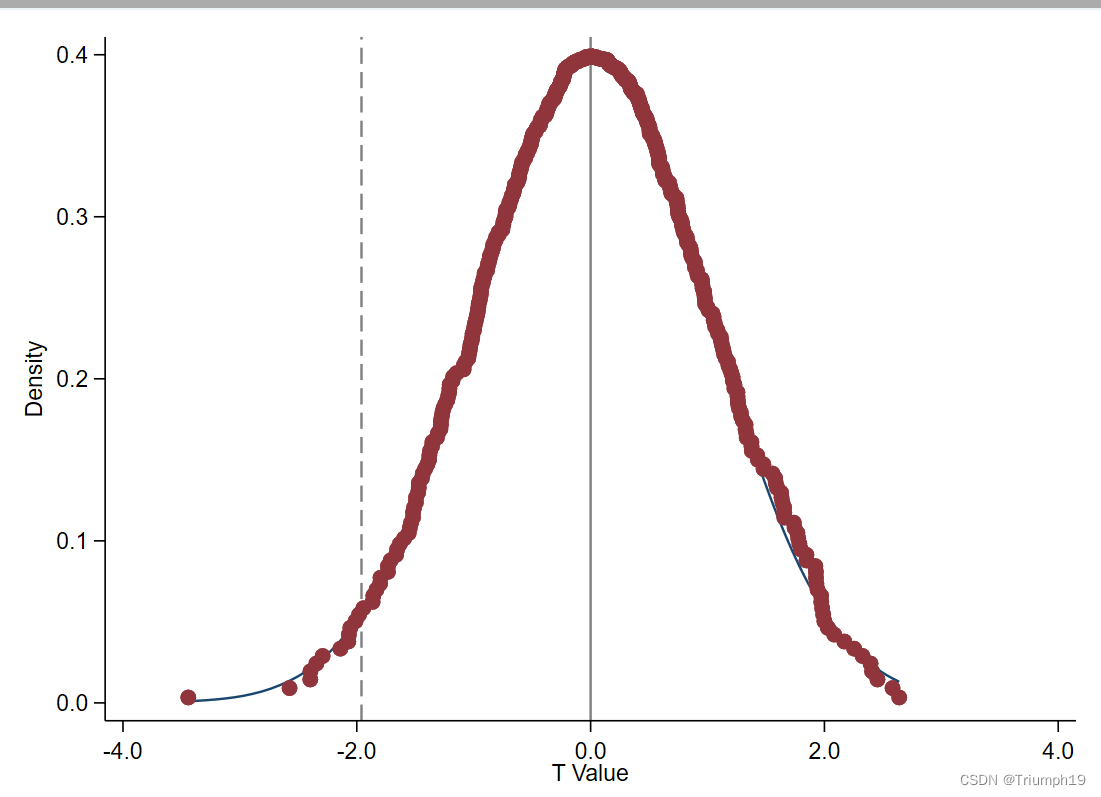
七、总结
- 使用 permute 命令,我们基本可以一行代码搞定安慰剂检验。这个命令有两个明显的优点。其一,我们可以实时观看抽样进度,不用在电脑面前瞎等。同时,该命令也会提供单侧检验与双侧检验的 p 值,帮助我们直接判断安慰剂检验是否通过,相比于肉眼的直观判断更为客观。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/53990.html