
windows下安装pyltp:
1、下载python对应版本的pyltp wheel文件(以python3.6为例)
2、在wheel文件所在的目录打开cmd,输入命令 pip install pyltp-0.2.1-cp36-cp36m-win_amd64.whl
下载开源的ltp_data文件(包括ltp训练好的模型):
1、下载地址https://pan.baidu.com/share/link?shareid=1988562907&uk=2738088569#list/path=%2F(有多个版本,以3.4.0为例)
2、cws.model 分词模型
ner.model 实体识别模型
parser.model 句法分析模型
pisrl_win.model 语义角色标注模型
pos.model 词性标注模型
version 3.4.0
句法分析需要调用的模型(依次调用):
1、cws.model
2、pos.model
3、parser.model
注:各模型具体调用方法参见https://pyltp.readthedocs.io/zh_CN/latest/api.html
句法分析图:
1、安装nltk pip install nltk
2、from nltk import DependencyGraph
3、conlltree = DependencyGraph(par_result) # 转换为依存句法图
tree = conlltree.tree() # 构建树结构
tree.draw() # 显示输出的树
注:par_result为调用ltp模型生成的结果
讯享网
程序如下:
讯享网import sys, os from pyltp import * from nltk import DependencyGraph class LtpParsing(object): def __init__(self, model_dir='ltp_data'): self.segmentor = Segmentor() self.segmentor.load(os.path.join(model_dir, "cws.model")) self.postagger = Postagger() self.postagger.load(os.path.join(model_dir, "pos.model")) self.parser = Parser() self.parser.load(os.path.join(model_dir, "parser.model")) def par(self, infilm, outfilm): input_data = open(infilm, 'r', encoding='utf-8') output_data = open(outfilm, 'w+', encoding='utf=8') for line in input_data.readlines(): line = line.strip() # 分词 words = self.segmentor.segment(line) # self.segmentor.load_with_lexicon('lexicon') # 使用自定义词典,lexicon外部词典文件路径 # print('分词:' + '\t'.join(words)) # 词性标注 postags = self.postagger.postag(words) # print('词性标注:' + '\t'.join(postags)) # 句法分析 arcs = self.parser.parse(words, postags) rely_id = [arc.head for arc in arcs] # 提取依存父节点id relation = [arc.relation for arc in arcs] # 提取依存关系 heads = ['Root' if id == 0 else words[id - 1] for id in rely_id] # 匹配依存父节点词语 output_data.write(line) output_data.write('\n') output_data.write('句法分析:') par_result = '' for i in range(len(words)): if arcs[i].head == 0: arcs[i].relation = "ROOT" par_result += "\t" + words[i] + "(" + arcs[i].relation + ")" + "\t" + postags[i] + "\t" + str(arcs[i].head) + "\t" + arcs[i].relation + "\n" output_data.write(relation[i] + '(' + words[i] + ', ' + heads[i] + ')' + '\n') # print(par_result) conlltree = DependencyGraph(par_result) # 转换为依存句法图 tree = conlltree.tree() # 构建树结构 tree.draw() # 显示输出的树 output_data.write('\n') input_data.close() output_data.close() def release_model(self): # 释放模型 self.segmentor.release() self.postagger.release() self.parser.release() if __name__ == '__main__': infilm = 'infilm.txt' outfilm = 'outfilm.txt' ltp = LtpParsing() ltp.par(infilm, outfilm) ltp.release_model()
输入文件为:
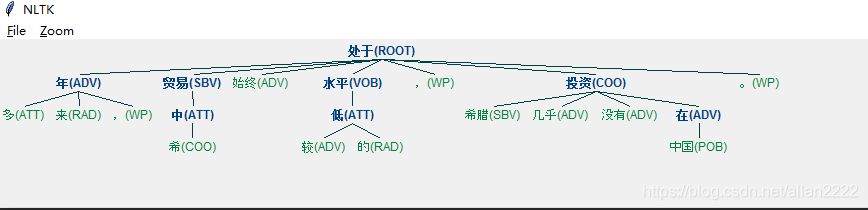
我叫李明,在清华读书。 多年来,中希贸易始终处于较低的水平,希腊几乎没有在中国投资。
输出文件:

讯享网我叫李明,在清华读书。 句法分析:SBV(我, 叫) HED(叫, Root) VOB(李明, 叫) WP(,, 叫) ADV(在, 读书) POB(清华, 在) COO(读书, 叫) WP(。, 叫) 多年来,中希贸易始终处于较低的水平,希腊几乎没有在中国投资。 句法分析:ATT(多, 年) ADV(年, 处于) RAD(来, 年) WP(,, 年) ATT(中, 贸易) COO(希, 中) SBV(贸易, 处于) ADV(始终, 处于) HED(处于, Root) ADV(较, 低) ATT(低, 水平) RAD(的, 低) VOB(水平, 处于) WP(,, 处于) SBV(希腊, 投资) ADV(几乎, 投资) ADV(没有, 投资) ADV(在, 投资) POB(中国, 在) COO(投资, 处于) WP(。, 处于)
句法图:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/48426.html