
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
一种利用langchain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。

受GanymedeNil的项目document.ai和AlexZhangji创建的ChatGLM-6B Pull Request启发,建立了全流程可使用开源模型实现的本地知识库问答应用。现已支持使用ChatGLM-6B等大语言模型直接接入,或通过fastchat api形式接入Vicuna, Alpaca, LLaMA, Koala, RWKV等模型。
今天分享中Embedding默认选用的是GanymedeNil/text2vec-large-chinese,LLM默认选用的是ChatGLM-6B。依托上述模型,本项目可实现全部使用开源模型离线私有部署。
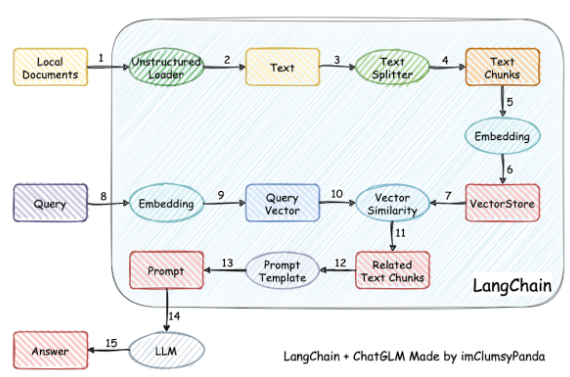
实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
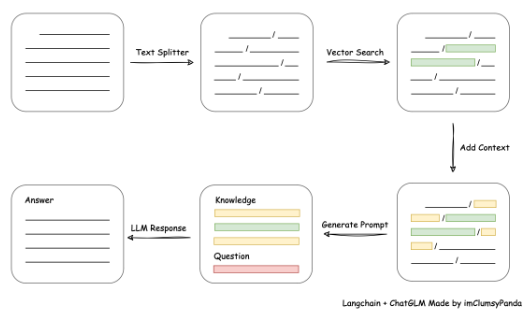
从文档处理角度来看,实现流程如下:
本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。核心部分代码为:
执行初始化 init_cfg(LLM_MODEL, EMBEDDING_MODEL, LLM_HISTORY_LEN) # 使用 ChatGLM 的 readme 进行测试 vector_store = init_knowledge_vector_store("/home/mw/project/test_chatglm_readme.md")讯享网
中vector_store的初始化可以传递 txt、docx、md 格式文件,或者包含md文件的目录。更多知识库加载方式可以参考langchain文档,通过修改 init_knowledge_vector_store 方法进行兼容。
官方注:ModelWhale GPU机型需要从云厂商拉取算力资源,耗时5~10min,且会预扣半小时资源价格的鲸币。如果资源未启动成功,预扣费用会在关闭编程页面后五分钟内退回,无需紧张,如遇问题欢迎提报工单,客服会及时处理。
硬件需求
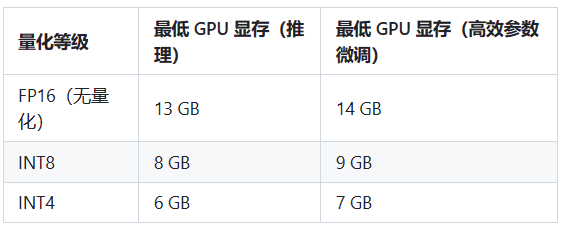
- ChatGLM-6B 模型硬件需求
注:如未将模型下载至本地,请执行前检查$HOME/.cache/huggingface/文件夹剩余空间,模型文件下载至本地需要15GB存储空间。
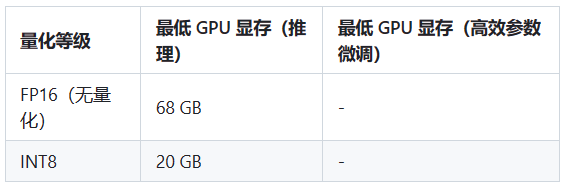
- MOSS 模型硬件需求
注:如未将模型下载至本地,请执行前检查$HOME/.cache/huggingface/文件夹剩余空间,模型文件下载至本地需要70GB存储空间
- Embedding 模型硬件需求
本项目中默认选用的Embedding 模型GanymedeNil/text2vec-large-chinese约占用显存3GB,也可修改为在CPU中运行。
Docker 部署
为了能让容器使用主机GPU资源,需要在主机上安装 NVIDIA Container Toolkit。具体安装步骤如下:
讯享网sudo apt-get update sudo apt-get install -y nvidia-container-toolkit-base sudo systemctl daemon-reload sudo systemctl restart docker
安装完成后,可以使用以下命令编译镜像和启动容器:
docker build -f Dockerfile-cuda -t chatglm-cuda:latest . docker run --gpus all -d --name chatglm -p 7860:7860 chatglm-cuda:latest #若要使用离线模型,请配置好模型路径,然后此repo挂载到Container docker run --gpus all -d --name chatglm -p 7860:7860 -v ~/github/langchain-ChatGLM:/chatGLM chatglm-cuda:latest开发部署
软件需求
本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
vue前端需要node18环境
从本地加载模型
请参考 THUDM/ChatGLM-6B#从本地加载模型
1. 安装环境
环境检查
讯享网# 首先,确信你的机器安装了 Python 3.8 及以上版本 $ python --version Python 3.8.13 # 如果低于这个版本,可使用conda安装环境 $ conda create -p /your_path/env_name python=3.8 # 激活环境 $ source activate /your_path/env_name $ pip3 install --upgrade pip # 关闭环境 $ source deactivate /your_path/env_name # 删除环境 $ conda env remove -p /your_path/env_name
项目依赖
# 拉取仓库 $ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git # 进入目录 $ cd langchain-ChatGLM # 项目中 pdf 加载由先前的 detectron2 替换为使用 paddleocr,如果之前有安装过 detectron2 需要先完成卸载避免引发 tools 冲突 $ pip uninstall detectron2 # 检查paddleocr依赖,linux环境下paddleocr依赖libX11,libXext $ yum install libX11 $ yum install libXext # 安装依赖 $ pip install -r requirements.txt # 验证paddleocr是否成功,首次运行会下载约18M模型到~/.paddleocr $ python loader/image_loader.py2. 设置模型默认参数
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 中的各项模型参数设计是否符合需求。
如需通过 fastchat 以 api 形式调用 llm,请参考 fastchat 调用实现
3. 执行脚本体验 Web UI 或命令行交互
注:鉴于环境部署过程中可能遇到问题,建议首先测试命令行脚本。建议命令行脚本测试可正常运行后再运行 Web UI。
执行 cli_demo.py 脚本体验命令行交互:
讯享网$ python cli_demo.py
或执行 webui.py 脚本体验 Web 交互
$ python webui.py或执行 api.py 利用 fastapi 部署 API
讯享网$ python api.py
或成功部署 API 后,执行以下脚本体验基于 VUE 的前端页面
$ cd views $ pnpm i $ npm run dev讯享网VUE 前端界面如下图所示:
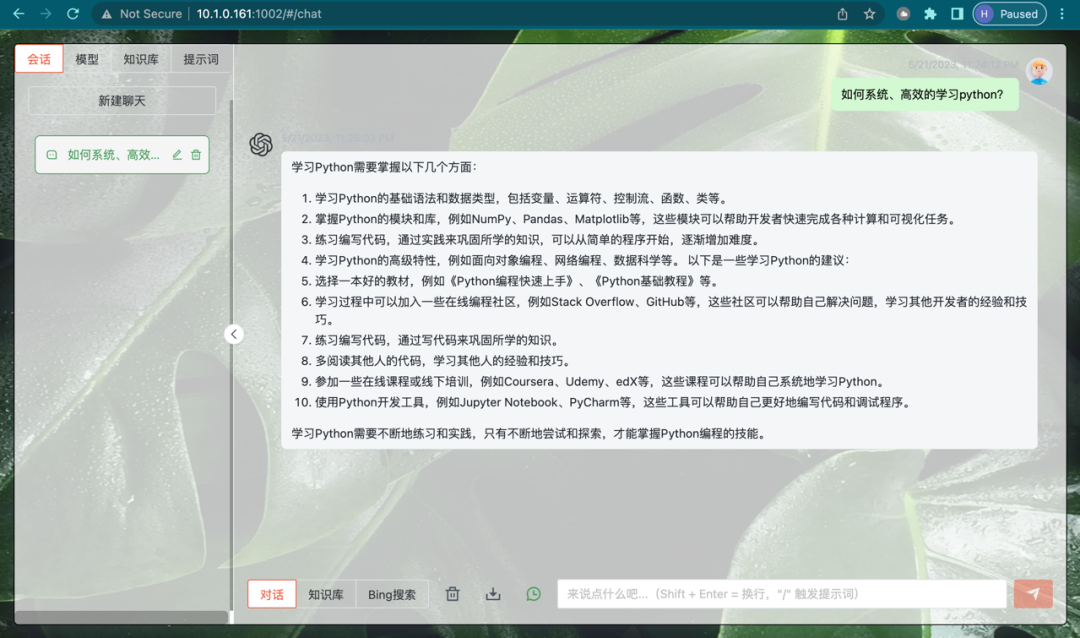
- 对话界面

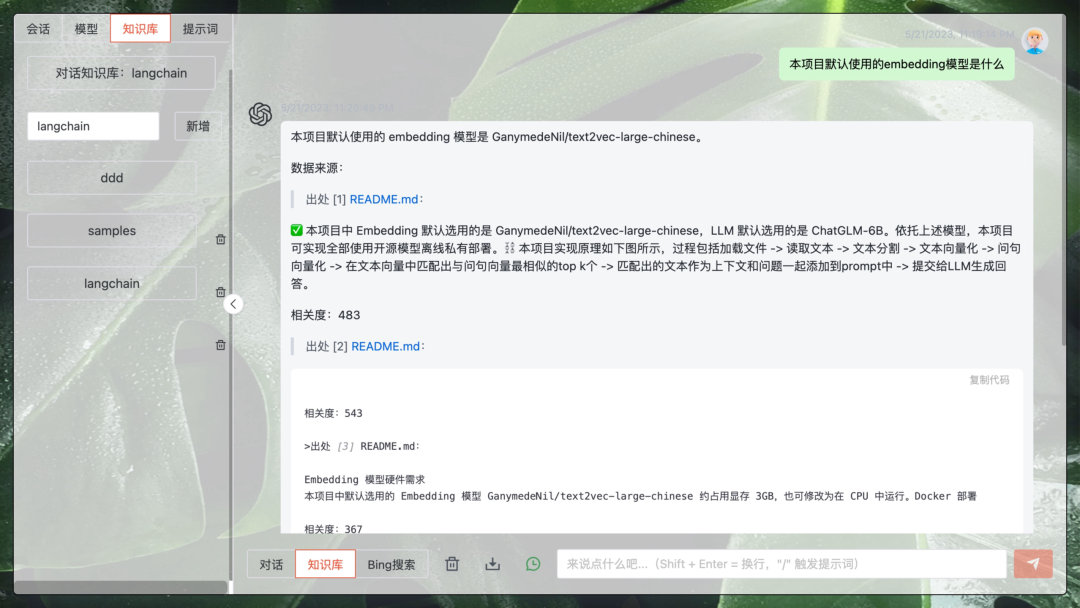
- 知识问答界面
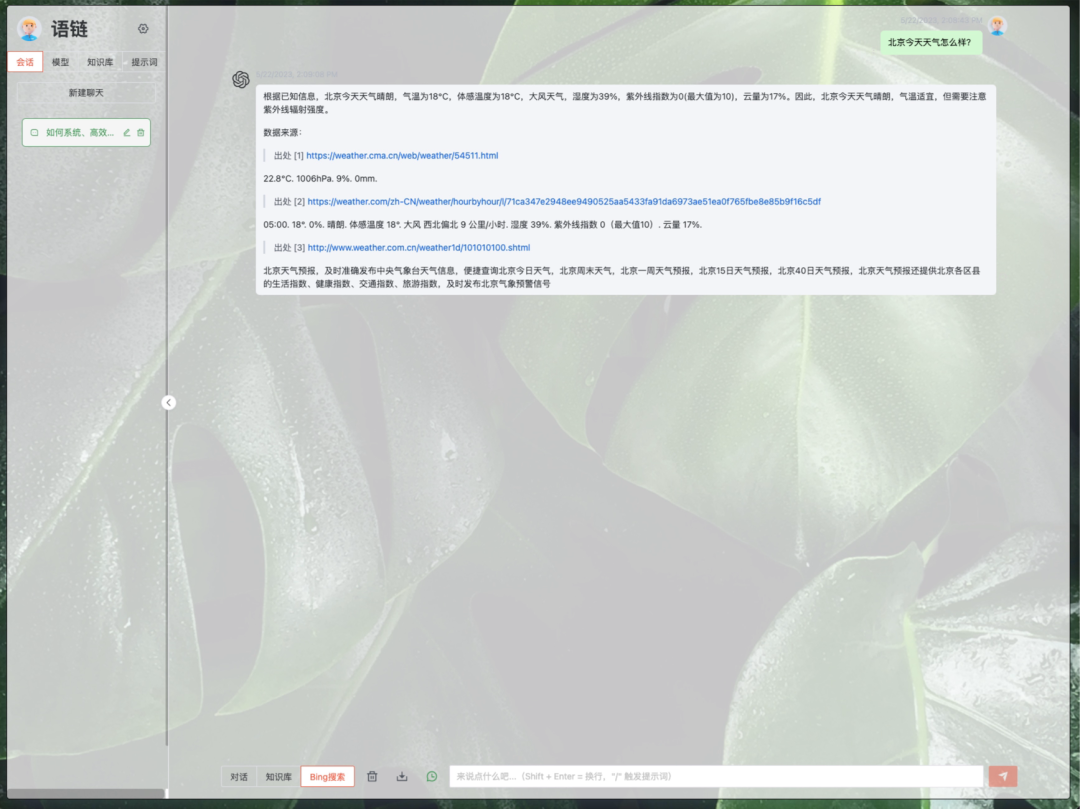
- bing搜索界面
WebUI 界面如下图所示:
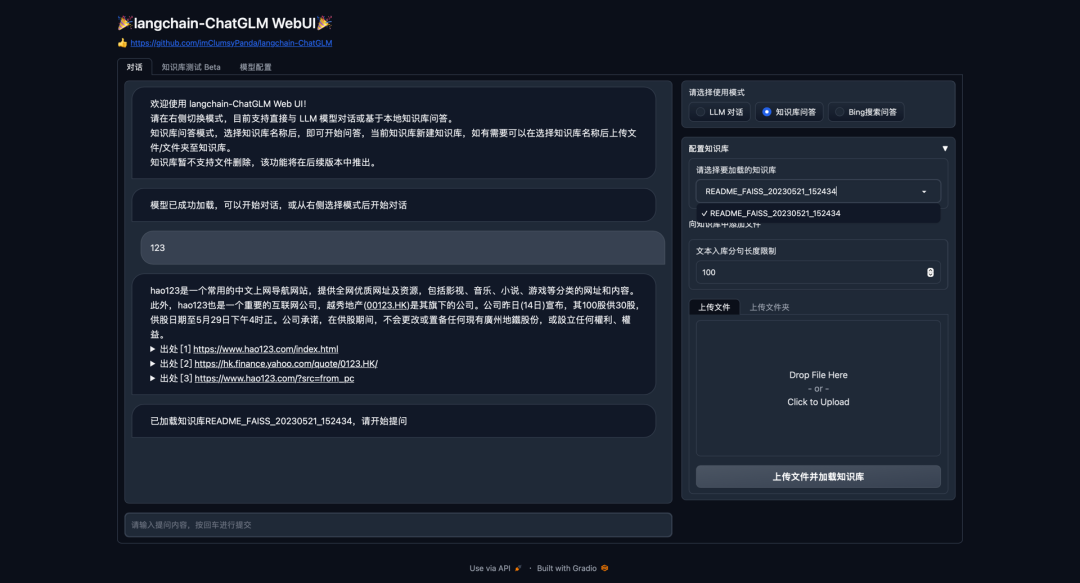
- 对话Tab界面
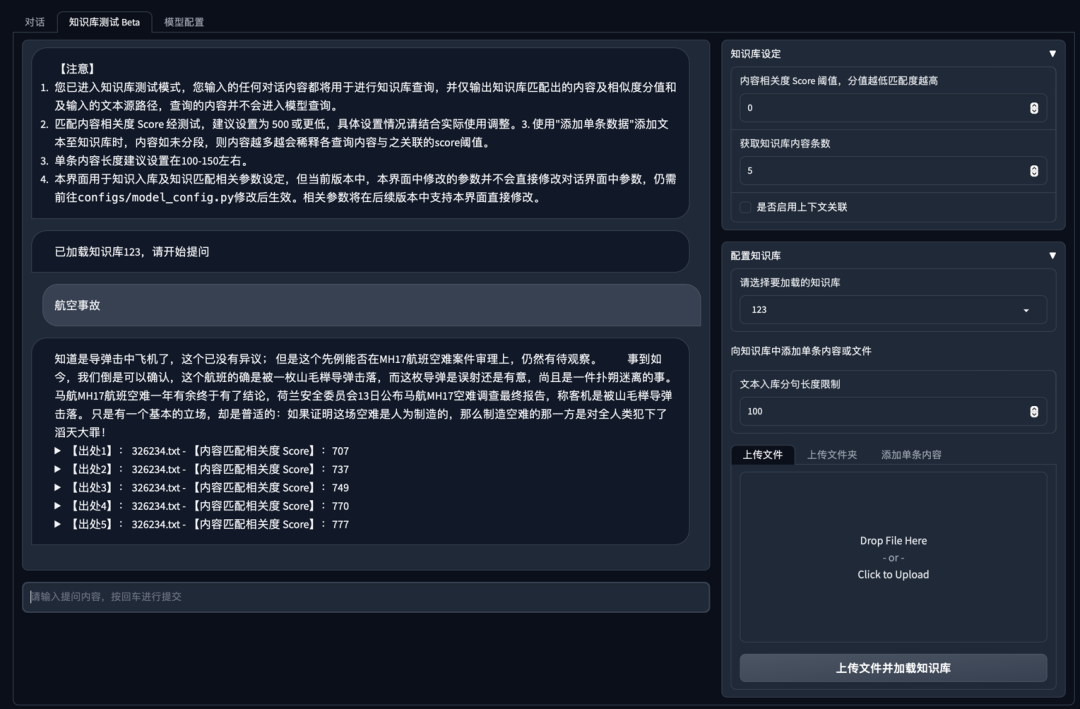
- 知识库测试Beta Tab界面
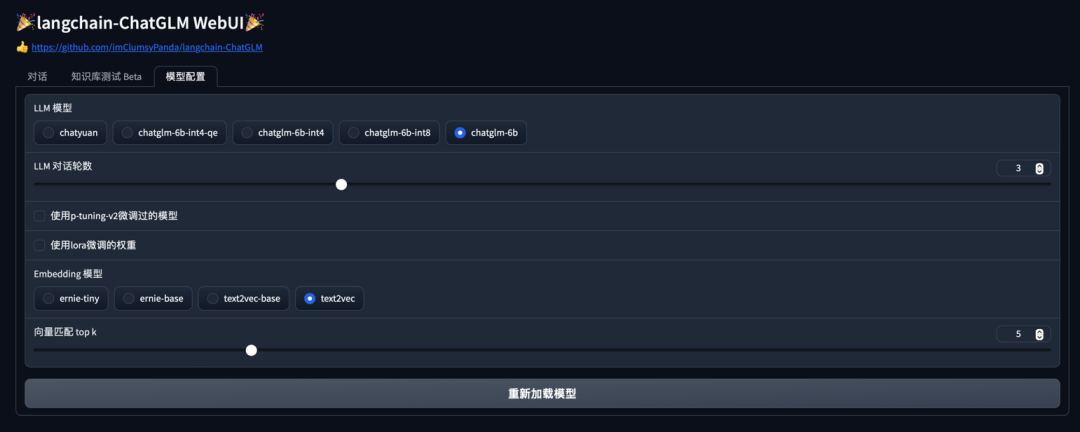
- 模型配置Tab界面
Web UI 可以实现如下功能:
- 运行前自动读取configs/model_config.py中LLM及Embedding模型枚举及默认模型设置运行模型,如需重新加载模型,可在 模型配置 Tab 重新选择后点击 重新加载模型 进行模型加载;
- 可手动调节保留对话历史长度、匹配知识库文段数量,可根据显存大小自行调节;
- 对话 Tab 具备模式选择功能,可选择 LLM对话 与 知识库问答 模式进行对话,支持流式对话;
- 添加 配置知识库 功能,支持选择已有知识库或新建知识库,并可向知识库中新增上传文件/文件夹,使用文件上传组件选择好文件后点击 上传文件并加载知识库,会将所选上传文档数据加载至知识库中,并基于更新后知识库进行问答;
- 新增 知识库测试 Beta Tab,可用于测试不同文本切分方法与检索相关度阈值设置,暂不支持将测试参数作为 对话 Tab 设置参数。
- 后续版本中将会增加对知识库的修改或删除,及知识库中已导入文件的查看。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:

往期推荐
🔗
- All Things ViTs:在视觉中理解和解释注意力
- OVO:在线蒸馏一次视觉Transformer搜索
- 最近几篇较好论文实现代码(附源代码下载)
- AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
- CVPR 2023|EfficientViT:让ViT更高效部署实现实时推理(附源码)
- VS Code支持配置远程同步了
- 基于文本驱动用于创建和编辑图像(附源代码)
- 基于分层自监督学习将视觉Transformer扩展到千兆像素图像
- 霸榜第一框架:工业检测,基于差异和共性的半监督方法用于图像表面缺陷检测
- CLCNet:用分类置信网络重新思考集成建模(附源代码下载)
- YOLOS:通过目标检测重新思考Transformer(附源代码)
- 工业检测:基于密集尺度特征融合&像素级不平衡学习框架(论文下载)
- Fast YOLO:用于实时嵌入式目标检测(附论文下载)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/47942.html