
在机器学习的大多数漂亮的结果背后,是一个研究生(我)或工程师花费数小时训练模型和调整算法参数。正是这种乏味无聊的工作使得自动化调参成为可能。
在 RISELab 中,我们发现越来越有必要利用尖端的超参数调整工具来跟上最先进的水平。深度学习性能的提高越来越依赖于新的和更好的超参数调整算法,如基于分布的训练(PBT) ,HyperBand,和 ASHA。
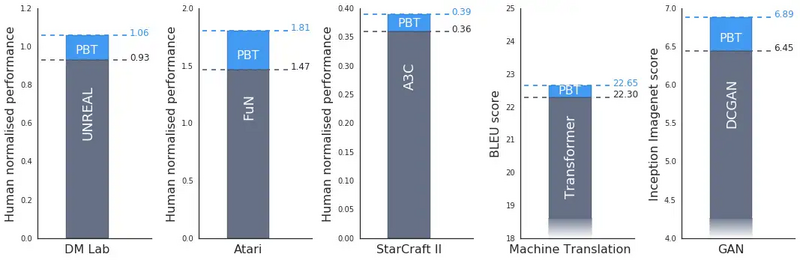
Source: 基于分布的训练大大提高了 DeepMind 在许多领域的算法。来源:https://deepmind.com/blog/population-based-training-neural-networks/
这些算法提供了两个关键的好处:他们最大化模型的性能: 例如,DeepMind 使用 PBT在星际争霸中获得超人般的表现; Waymo 使用实现无人驾驶汽车的 PBT.
他们将训练成本降到最低: HyperBand 和 ASHA 覆盖到高质量的配置 以前的方法所需时间的一半; 基于总体的数据增强算法 实现指数级削减成本

然而,我们看到,绝大多数研究人员和团队没有利用这种算法。
为什么?大多数现有的超参数搜索框架没有这些新的优化算法。一旦达到一定的规模,大多数现有的并行超参数搜索解决方案可能会很难使用ーー您需要为每次运行配置每台机器,并经常管理一个单独的数据库。
实际上,实现和维护这些算法需要大量的时间和工程。
但事实并非如此。我们相信,没有理由说超参数调优需要如此困难。所有的人工智能研究人员和工程师都应该能够在8个 gpu 上无缝运行并行异步网格搜索,甚至可以扩展到利用基于分布的训练或者云上的任何贝叶斯优化算法。
在这篇博客文章中,我们将介绍 Tune, 一个基于 Ray 的强大的超参数调整库,旨在消除艰辛、设置实验执行和超参数调整过程中的难度。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/47913.html