
比赛背景
本次比赛的目标是:评估8至12年级英语学习者(ELL)的语言水平。利用ELL撰写的论文数据集将有助于开发更好地支持所有学生的熟练程度模型。这项工作将帮助ELL获得有关其语言发展的更准确的反馈,并加快教师的分级周期。这些结果可以使ELL获得更合适的学习任务,以帮助他们提高英语能力。
竞赛主持人范德比尔特(Vanderbilt)和学习机构实验室(Learning Agency Lab)共同合作,为数据科学家提供了使用机器学习,自然语言处理和教育数据分析的数据科学技能来支持ELL的机会。您可以通过使其对语言熟练程度敏感来改善ELL的自动反馈工具。最终的工具可以通过确保在当前语言水平的背景下评估其工作来减轻分级负担和支持ELL来为教师提供服务。
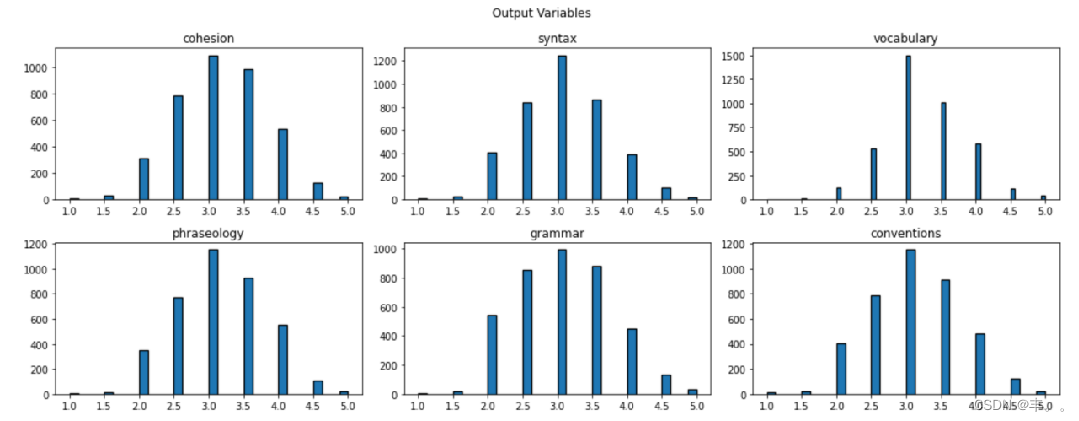
此次比赛的数据集包括由8至12年级英语学习者(ELL)撰写的议论文。这些论文已根据六项评分标准进行评分:连贯程度,语句结构,词汇,词组,语法和规则。每个评分标准都代表论文写作熟练程度的组成部分,某一项得分越高代表该方面越熟练。评分为1.0至5.0,增量为0.5。 此次的任务是预测测试集中给出的论文的六项评分标准。
提供的数据集包含:
train.csv - 训练集,包含每篇文章的全文,由唯一的 text_id 标识。
test.csv - 对于测试数据,我们只给出一篇文章的全文及其 text_id。
我们的方案
数据解读
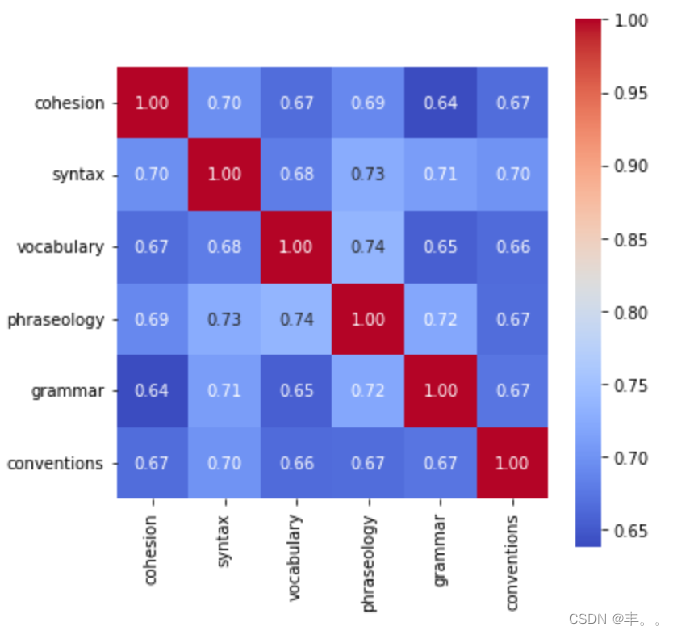
解读数据的相关性
讯享网
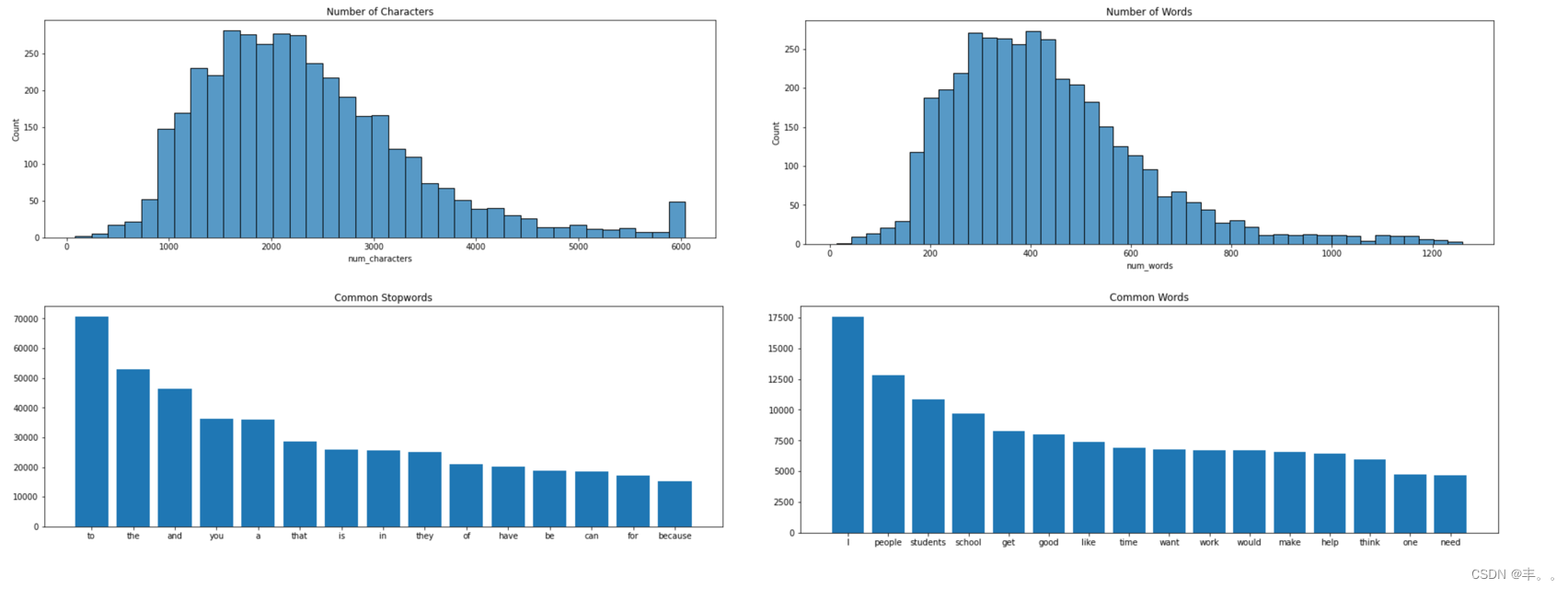
通过对文章内容进行分析,可以获得以下结果:
字母数量大多分布在1000-3000之间,词汇数量大多分布在200-500之间。
使用最频繁的停用词为to、the、and等,使用最频繁的词汇为I、people、students等。
使用Rapids SVR进行训练和预测。由于Rapids cuML’s SVR使用GPU,因此速度非常快。这让我们可以快速训练更多提取出来的EMBEDDING特征和FOLD。此方案中使用了25折交叉验证,从5个NLP-transformers中提取,并将它们串联使其具有6000列的特征。
这个方案参考了 Giba 在 Kaggle 宠物比赛中的第一名解决方案。那场竞争就是计算机视觉回归。Giba从数十个图像CNN和图像转换器中提取嵌入。这些模型是预先训练的(最有可能在ImageNet数据上),但没有经过微调(在Kaggle竞争数据上)。他连接了嵌入并在数以万计的特征列上训练了 RAPIDS SVR。
先将训练数据划分成25折,用DeBERTa模型下的Base、Large、Large V3、Large MNLI以及Xlarge进行词嵌入,将不同方法得到的结果进行组合,接下来对处理过的训练集和测试集利用Rapids cuML’s SVR方法获得每一折上的均方根误差,并得到总体均方根误差。
下一步,做数据增强
基于已有的训练样本数据来生成更多的训练数据,目的就是为了使扩增的训练数据尽可能接近真实分布的数据,从而提高检测精度。此外,数据增强能够迫使模型学习到更多鲁棒性的特征,从而有效提高模型的泛化能力。
具体方案是
用SynonymAug(同义词替换),word2evc(相近embedding词替换)和回译, 预先对全部数据增强后存在本地,然后把每一折里的训练数据和全部增强数据匹配,保证每一折里只有训练数据被增强,验证集不会被增强。
在对DeBERTa模型的优化中,添加了deberta-v3-base,deberta-v3-small,deberta-v2-xlarge, deberta-v2-xxlarge等模型。
在进行过优化之后,得到的RSME = 0.26096,lb=0.44,lb排名高于该方案最初参考的baseline。
优化方案在结果上有一定的提升,提升幅度较小的原因是同义词替换等操作后,理论上这个场景下标签应该是变化的,但目前没有办法判断变化后的标签是多少。
在之前的优化方案中,因为效果不佳、推理速度缓慢,因此舍弃了embedding+svr的方法。
此次深度优化方案中,在开源的MeanPooling + Layer-wise learning rate decay + DeBERTaV3 base pre-trained model finetuning with Tensorflow基础上重新训练了10折。
按照Deberta模型所需的方式将输入的文本进行tokensize。

在神经网络中,我们经常会看到池化层。池化层有一个很明显的作用:减少特征图大小,也就是可以减少计算量和所需显存。max-pooling和min-pooling在lb上的效果都略差于mean-pooling,所以此处选择mean-pooling。
mean-pooling(平均池化):即对邻域内特征点只求平均,其优缺点为:能很好的保留背景,但容易使得图片变模糊。
WeightedLayerPooling的权重总和需要为1。
Layer-wise Learning Rate Decay(不同层渐变学习率)是一种对顶层应用较高学习率而对底层应用较低学习率的方法。这是通过设置顶层的学习率并使用乘法衰减率从上到下逐层降低学习率来实现的。
结合本地cv、lb值筛选训练的模型、折数,采用加权平均or手动设置权重的方式融合筛选后的模型结果

请注意,我们不会微调 NLP 转换器。本笔记本中的Deberta变压器与我们从Hugging Face下载的预训练变压器相同。他们没有对Kaggle的竞争数据进行微调。这表明预训练模型已经具有智能。
这类似于 Giba 在 Kaggle 宠物比赛中的第一名解决方案。那场竞争就是计算机视觉回归。Giba从数十个图像CNN和图像转换器中提取嵌入。这些模型是预先训练的(最有可能在ImageNet数据上),但没有经过微调(在Kaggle竞争数据上)。他连接了嵌入并在数以万计的特征列上训练了 RAPIDS SVR!
Load Libraries and Data加载库和数据
import numpy as np import pandas as pd import os, gc, re, warnings warnings.filterwarnings("ignore") 讯享网
讯享网dftr = pd.read_csv("/kaggle/input/feedback-prize-english-language-learning/train.csv") dftr["src"]="train" dfte = pd.read_csv("/kaggle/input/feedback-prize-english-language-learning/test.csv") dfte["src"]="test" print('Train shape:',dftr.shape,'Test shape:',dfte.shape,'Test columns:',dfte.columns) df = pd.concat([dftr,dfte],ignore_index=True) dftr.head()
target_cols = ['cohesion', 'syntax', 'vocabulary', 'phraseology', 'grammar', 'conventions',] Make 25 Stratified Folds!分成25折
讯享网import sys sys.path.append('../input/iterativestratification') from iterstrat.ml_stratifiers import MultilabelStratifiedKFold FOLDS = 25 skf = MultilabelStratifiedKFold(n_splits=FOLDS, shuffle=True, random_state=42) for i,(train_index, val_index) in enumerate(skf.split(dftr,dftr[target_cols])): dftr.loc[val_index,'FOLD'] = i print('Train samples per fold:') dftr.FOLD.value_counts()
Generate Embeddings生成嵌入
from transformers import AutoModel,AutoTokenizer import torch import torch.nn.functional as F from tqdm import tqdm 讯享网def mean_pooling(model_output, attention_mask): token_embeddings = model_output.last_hidden_state.detach().cpu() input_mask_expanded = ( attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() ) return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp( input_mask_expanded.sum(1), min=1e-9 )
BATCH_SIZE = 4 class EmbedDataset(torch.utils.data.Dataset): def __init__(self,df): self.df = df.reset_index(drop=True) def __len__(self): return len(self.df) def __getitem__(self,idx): text = self.df.loc[idx,"full_text"] tokens = tokenizer( text, None, add_special_tokens=True, padding='max_length', truncation=True, max_length=MAX_LEN,return_tensors="pt") tokens = {
k:v.squeeze(0) for k,v in tokens.items()} return tokens ds_tr = EmbedDataset(dftr) embed_dataloader_tr = torch.utils.data.DataLoader(ds_tr,\ batch_size=BATCH_SIZE,\ shuffle=False) ds_te = EmbedDataset(dfte) embed_dataloader_te = torch.utils.data.DataLoader(ds_te,\ batch_size=BATCH_SIZE,\ shuffle=False) 讯享网tokenizer = None MAX_LEN = 640 def get_embeddings(MODEL_NM='', MAX=640, BATCH_SIZE=4, verbose=True): global tokenizer, MAX_LEN DEVICE="cuda" model = AutoModel.from_pretrained( MODEL_NM ) tokenizer = AutoTokenizer.from_pretrained( MODEL_NM ) MAX_LEN = MAX model = model.to(DEVICE) model.eval() all_train_text_feats = [] for batch in tqdm(embed_dataloader_tr,total=len(embed_dataloader_tr)): input_ids = batch["input_ids"].to(DEVICE) attention_mask = batch["attention_mask"].to(DEVICE) with torch.no_grad(): model_output = model(input_ids=input_ids,attention_mask=attention_mask) sentence_embeddings = mean_pooling(model_output, attention_mask.detach().cpu()) # Normalize the embeddings sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1) sentence_embeddings = sentence_embeddings.squeeze(0).detach().cpu().numpy() all_train_text_feats.extend(sentence_embeddings) all_train_text_feats = np.array(all_train_text_feats) if verbose: print('Train embeddings shape',all_train_text_feats.shape) te_text_feats = [] for batch in tqdm(embed_dataloader_te,total=len(embed_dataloader_te)): input_ids = batch["input_ids"].to(DEVICE) attention_mask = batch["attention_mask"].to(DEVICE) with torch.no_grad(): model_output = model(input_ids=input_ids,attention_mask=attention_mask) sentence_embeddings = mean_pooling(model_output, attention_mask.detach().cpu()) # Normalize the embeddings sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1) sentence_embeddings = sentence_embeddings.squeeze(0).detach().cpu().numpy() te_text_feats.extend(sentence_embeddings) te_text_feats = np.array(te_text_feats) if verbose: print('Test embeddings shape',te_text_feats.shape) return all_train_text_feats, te_text_feats
Get Base Embeddings获取基本嵌入
MODEL_NM = '../input/huggingface-deberta-variants/deberta-base/deberta-base' all_train_text_feats, te_text_feats = get_embeddings(MODEL_NM) Get Large V3 Embeddings获取大型 V3 嵌入
讯享网MODEL_NM = '../input/deberta-v3-large/deberta-v3-large' all_train_text_feats2, te_text_feats2 = get_embeddings(MODEL_NM)
Get Large Embeddings获取大型嵌入
MODEL_NM = '../input/huggingface-deberta-variants/deberta-large/deberta-large' all_train_text_feats3, te_text_feats3 = get_embeddings(MODEL_NM) Get Large MNLI Embeddings获取大型 MNLI 嵌入
讯享网MODEL_NM = '../input/huggingface-deberta-variants/deberta-large-mnli/deberta-large-mnli' all_train_text_feats4, te_text_feats4 = get_embeddings(MODEL_NM, MAX=512)
Get XLarge Embeddings获取 XLarge 嵌入
MODEL_NM = '../input/huggingface-deberta-variants/deberta-xlarge/deberta-xlarge' all_train_text_feats5, te_text_feats5 = get_embeddings(MODEL_NM, MAX=512) Combine Feature Embeddings合并特征嵌入
讯享网all_train_text_feats = np.concatenate([all_train_text_feats,all_train_text_feats2, all_train_text_feats3,all_train_text_feats4, all_train_text_feats5],axis=1) te_text_feats = np.concatenate([te_text_feats,te_text_feats2, te_text_feats3,te_text_feats4, te_text_feats5],axis=1) del all_train_text_feats2, te_text_feats2 del all_train_text_feats3, te_text_feats3 del all_train_text_feats4, te_text_feats4 del all_train_text_feats5, te_text_feats5 gc.collect() print('Our concatenated embeddings have shape', all_train_text_feats.shape )
Train RAPIDS cuML SVR
from cuml.svm import SVR import cuml print('RAPIDS version',cuml.__version__) 讯享网from sklearn.metrics import mean_squared_error preds = [] scores = [] def comp_score(y_true,y_pred): rmse_scores = [] for i in range(len(target_cols)): rmse_scores.append(np.sqrt(mean_squared_error(y_true[:,i],y_pred[:,i]))) return np.mean(rmse_scores) #for fold in tqdm(range(FOLDS),total=FOLDS): for fold in range(FOLDS): print('#'*25) print(' Fold',fold+1) print('#'*25) dftr_ = dftr[dftr["FOLD"]!=fold] dfev_ = dftr[dftr["FOLD"]==fold] tr_text_feats = all_train_text_feats[list(dftr_.index),:] ev_text_feats = all_train_text_feats[list(dfev_.index),:] ev_preds = np.zeros((len(ev_text_feats),6)) test_preds = np.zeros((len(te_text_feats),6)) for i,t in enumerate(target_cols): print(t,', ',end='') clf = SVR(C=1) clf.fit(tr_text_feats, dftr_[t].values) ev_preds[:,i] = clf.predict(ev_text_feats) test_preds[:,i] = clf.predict(te_text_feats) print() score = comp_score(dfev_[target_cols].values,ev_preds) scores.append(score) print("Fold : {} RSME score: {}".format(fold,score)) preds.append(test_preds) print('#'*25) print('Overall CV RSME =',np.mean(scores))
Create Submission CSV
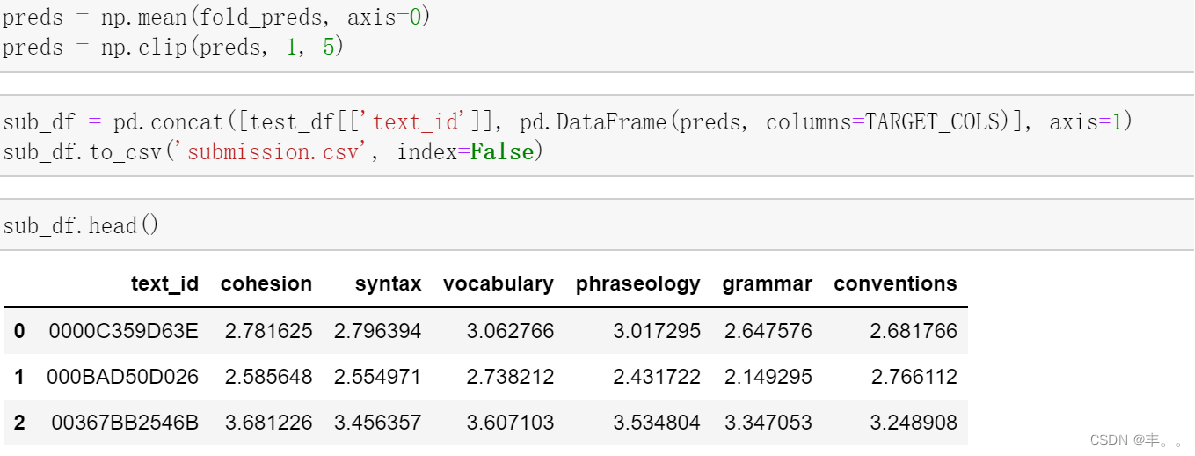
sub = dfte.copy() sub.loc[:,target_cols] = np.average(np.array(preds),axis=0) #,weights=[1/s for s in scores] sub_columns = pd.read_csv("../input/feedback-prize-english-language-learning/sample_submission.csv").columns sub = sub[sub_columns] sub.to_csv("submission.csv",index=None) sub.head()
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/46984.html