
文章首发于个人公众号:「阿拉平平」
在处理复杂工作时,将所有的逻辑都写到一个任务中是一种很糟糕的做法。将其拆解成多个子任务,重新编排并监控运行状况则要靠谱的多。也许你正在寻找一个好用的工作流引擎,那么这款基于 Python 的工作流工具:Prefect[1] 说不定可以帮助到你。
在这篇文章中,我将介绍并演示 Prefect 的用法,编写一个简单的工作流程序来说明 Prefect 是如何使用的。文中使用的 Python 版本为 3.6.5,Prefect 版本为 0.13.19。
快速开始
安装 Prefect 前请确保已安装 Python,且版本在 3.6 以上。
安装很简单,执行以下命令:
pip install prefect 讯享网
官方的示例代码如下:
讯享网from prefect import task, Flow, Parameter @task(log_stdout=True) def say_hello(name): print("Hello, {}!".format(name)) with Flow("My First Flow") as flow: name = Parameter('name') say_hello(name) flow.run(name='world') # "Hello, world!" flow.run(name='Marvin') # "Hello, Marvin!"
我们运行看下输出结果:
[2020-12-16 11:52:27+0800] INFO - prefect.FlowRunner | Beginning Flow run for 'My First Flow' [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'name': Starting task run... [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'name': Finished task run for task with final state: 'Success' [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'say_hello': Starting task run... [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Hello, world! [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'say_hello': Finished task run for task with final state: 'Success' [2020-12-16 11:52:27+0800] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded [2020-12-16 11:52:27+0800] INFO - prefect.FlowRunner | Beginning Flow run for 'My First Flow' [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'name': Starting task run... [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'name': Finished task run for task with final state: 'Success' [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'say_hello': Starting task run... [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Hello, Marvin! [2020-12-16 11:52:27+0800] INFO - prefect.TaskRunner | Task 'say_hello': Finished task run for task with final state: 'Success' [2020-12-16 11:52:27+0800] INFO - prefect.FlowRunner | Flow run SUCCESS: all reference tasks succeeded 可以看到,Prefect 很好地执行了任务,并输出了运行的日志。接下来,我们来尝试用 Prefect 编写一个简易的工作流程序。
项目实践
现在有这么个需求:获取 GitHub Trending 每日数据,并保存成 CSV 文件。这个要怎么实现呢?
我们先拆解下需求,大致可以分为以下步骤:
- download_data:调用接口,获取 GitHub Trending 每日数据。
- handle_data:对数据进行处理,选取需要的字段。
- save_data:将处理好的数据保存成 CSV 文件。
功能实现
以上的每个步骤分别对应一个子任务,我们来实现下。
首先是 download_data。通过 requests 库,这个不难实现,具体代码如下:
讯享网import requests GITHUB_TRENDING_URL = "https://trendings.herokuapp.com/repo" def download_data(): params = {
'since': 'today'} trending_data = requests.get(GITHUB_TRENDING_URL, params).json() return trending_data
我将接口返回的数据转成了 JSON 格式,数据如下:
{
"count": 24, "msg": "suc", "items": [ {
"repo": "getmeli/meli", "repo_link": "[https://github.com/getmeli/meli](https://github.com/getmeli/meli)", "desc": "", "lang": "TypeScript", "stars": "951", "forks": "18", "added_stars": "291 stars today", "avatars": [ "[https://avatars3.githubusercontent.com/u/?s=40&v=4](https://avatars3.githubusercontent.com/u/?s=40&v=4)", "[https://avatars3.githubusercontent.com/u/?s=40&v=4](https://avatars3.githubusercontent.com/u/?s=40&v=4)" ] }, ... many more records ] } 接下来是实现 handle_data。由于只需要 items 中的内容,所以对其进行处理,代码如下:
讯享网def handle_data(data): return [i for i in data["items"]]
最后是 save_data。选取 items 中的字段,保存到本地,代码如下:
import csv def save_data(rows): headers = ["repo", "repo_link", "stars", "forks", "added_stars"] with open("/tmp/trending.csv", "w", newline="") as f: f_csv = csv.DictWriter(f, headers, extrasaction='ignore') f_csv.writeheader() f_csv.writerows(rows) 工作流
子任务实现后,就可以用 Prefect 编写工作流了,代码片段如下:
讯享网from prefect import Flow with Flow("GitHub_Trending_Flow") as flow: data = download_data() rows = handle_data(data) save_data(rows) flow.run()
在 Prefect 中,Flow 用于描述任务之间的依赖关系,比如执行的先后顺序或是数据的传递。创建了 Flow 后,就可以通过调用 flow.run() 来执行。
任务
Prefect 将每个步骤当作一项任务,对应代码中的一个函数。但是,怎么将函数声明为 Prefect 的任务呢?

最简单的方法是使用装饰器 @task,比如将 download_data 声明为任务:
from prefect import task import requests GITHUB_TRENDING_URL = "https://trendings.herokuapp.com/repo" @task def download_data(): params = {
'since': 'daily'} trending_data = requests.get(GITHUB_TRENDING_URL, params).json() return trending_data 参数
现在需求有变:需要将获取的 GitHub Trending 数据从每日改成每周。考虑到之后时间还可能发生变化,所以我们将时间改为参数。
导入 Parameter,并将 since 作为参数传入,具体代码如下:
讯享网from prefect import task, Flow, Parameter import requests GITHUB_TRENDING_URL = "https://trendings.herokuapp.com/repo" @task def download_data(since): params = {
'since': since} trending_data = requests.get(GITHUB_TRENDING_URL, params).json() return trending_data with Flow("GitHub_Trending_Flow") as flow: since = Parameter("since") download_data(since) flow.run(since="weekly")
工作流编排
Prefect 提供了开源的 server 以及 UI 来编排工作流。但在使用前,请确保安装了 docker 和 docker-compose。
如果是第一次启动需要运行以下命令配置本地工作流:
prefect backend server 运行后会在 ~/.prefect 目录下生成配置文件,之后运行以下命令启动 server:
讯享网prefect server start
启动 server 后,访问 http://localhost:8080,如果 server 不安装在本机,则需要修改 ip 地址。同时也要注意修改主页 「PREFECT SERVER」中 GraphQL 的地址:
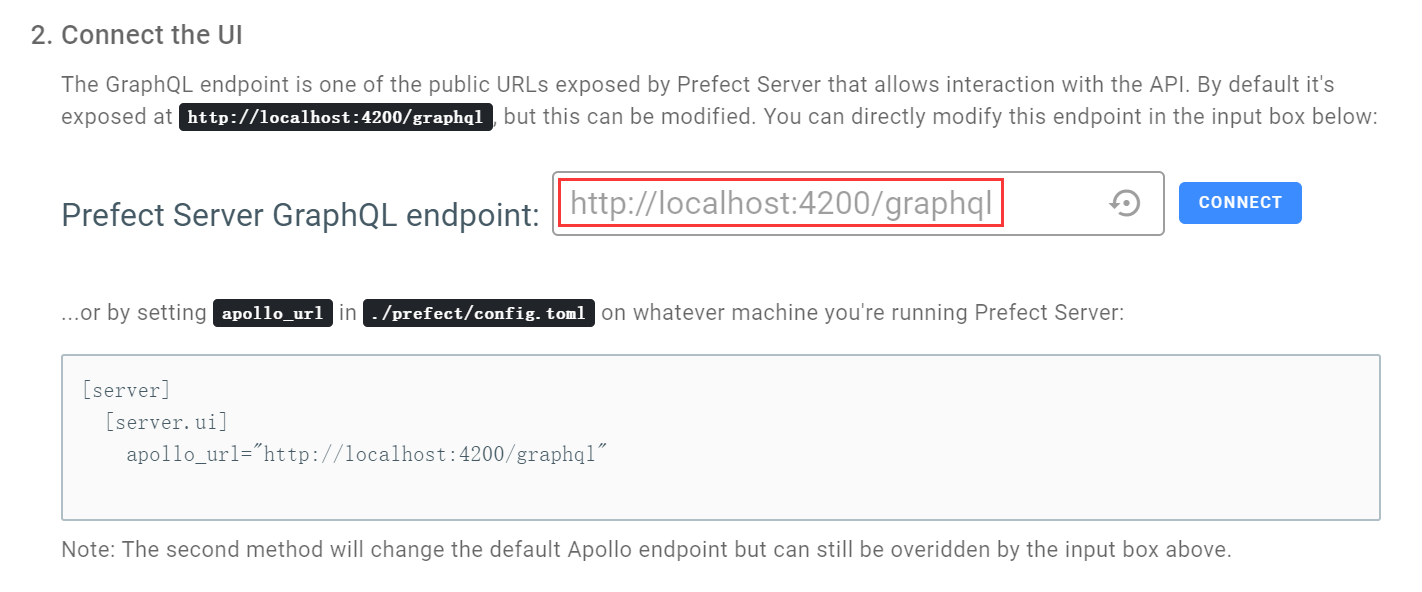
执行工作流任务至少需要运行一个 agent,可以在本机开启,命令如下:
prefect agent local start 接下来需要创建项目,可以通过命令行创建项目:
讯享网prefect create project "GitHub_Trending"
项目创建后,加入以下代码可以将工作流注册到 server 中,这里的 project_name 要和刚创建的项目名对应:
flow.register(project_name="GitHub_Trending") 运行代码进行注册,选好项目可以看到注册成功的工作流。
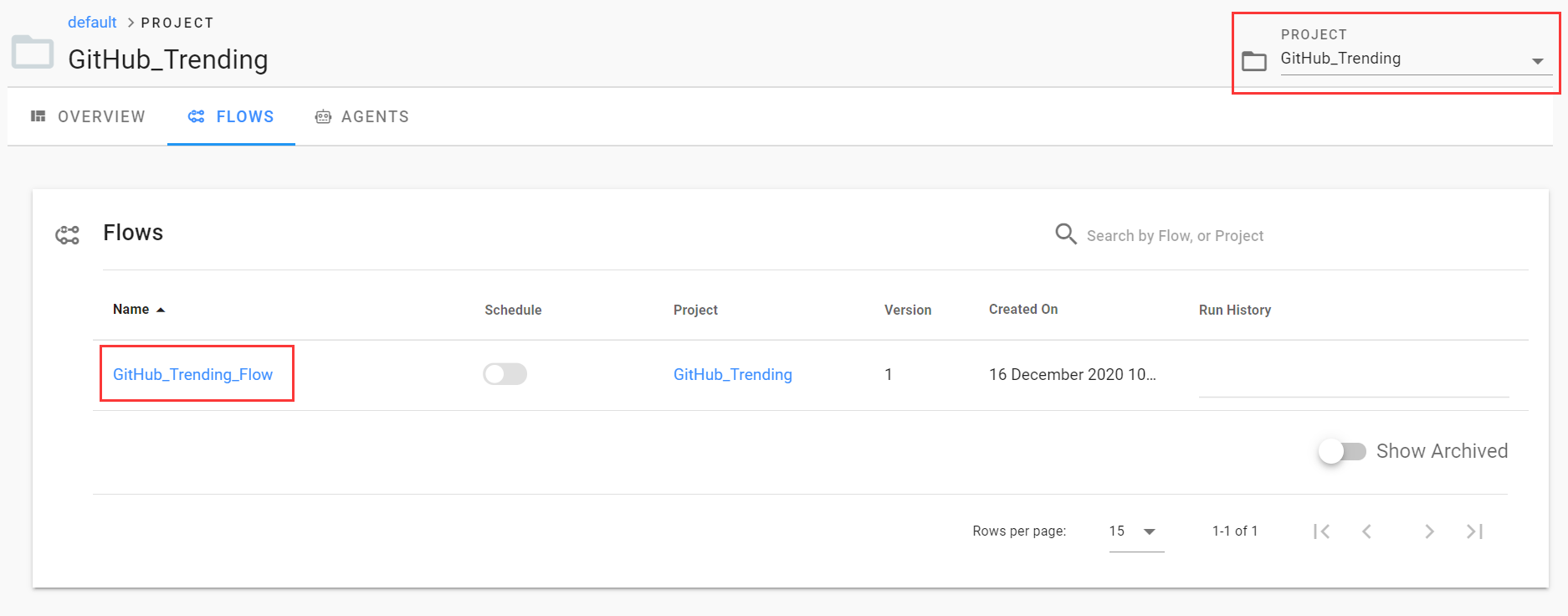
接着试下从页面运行工作流,不过别忘了指定参数的值:
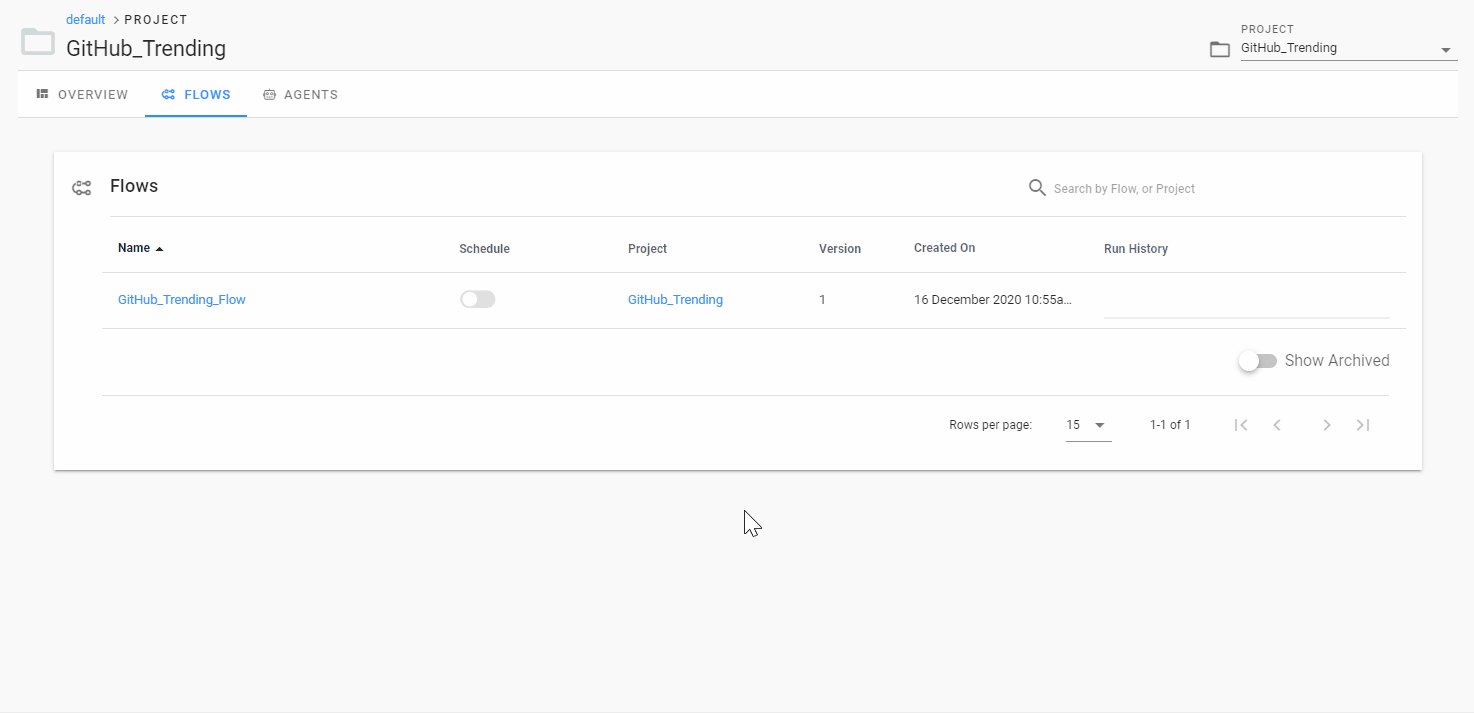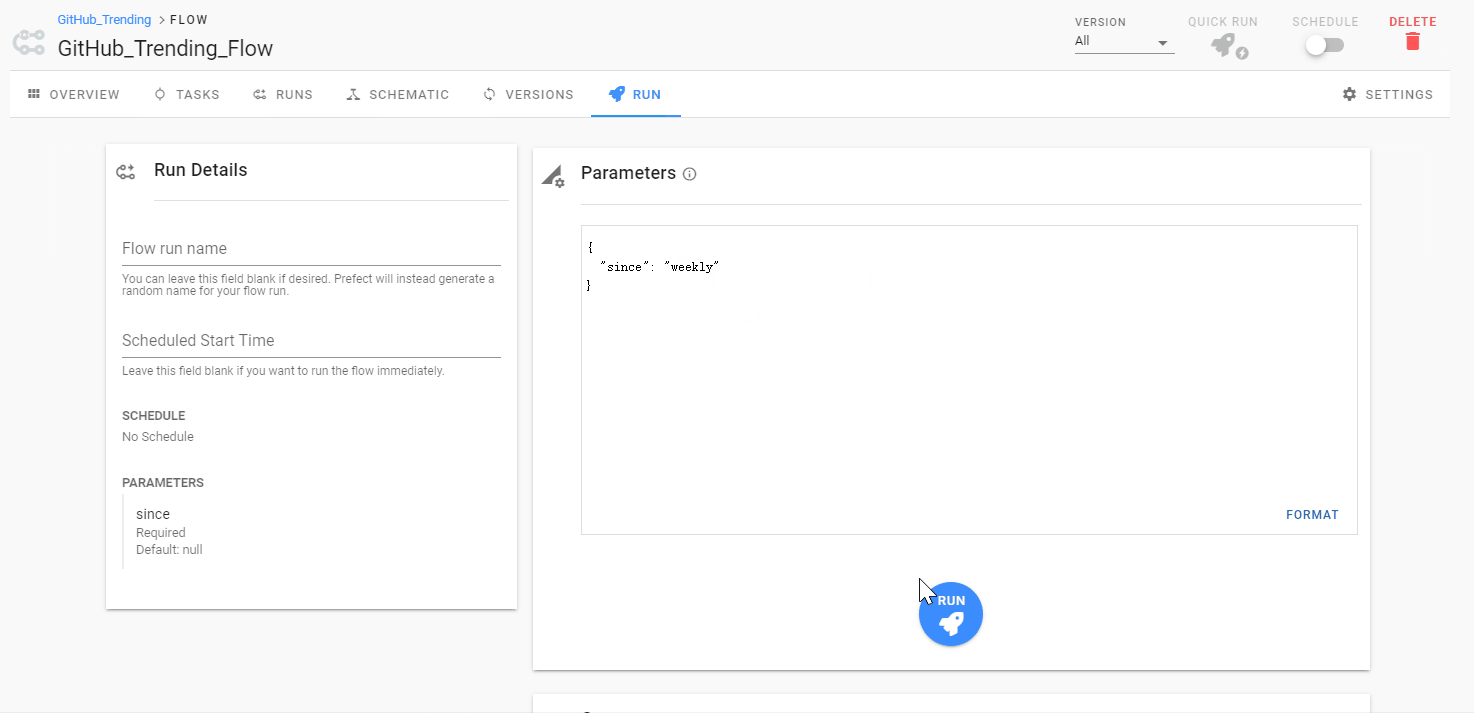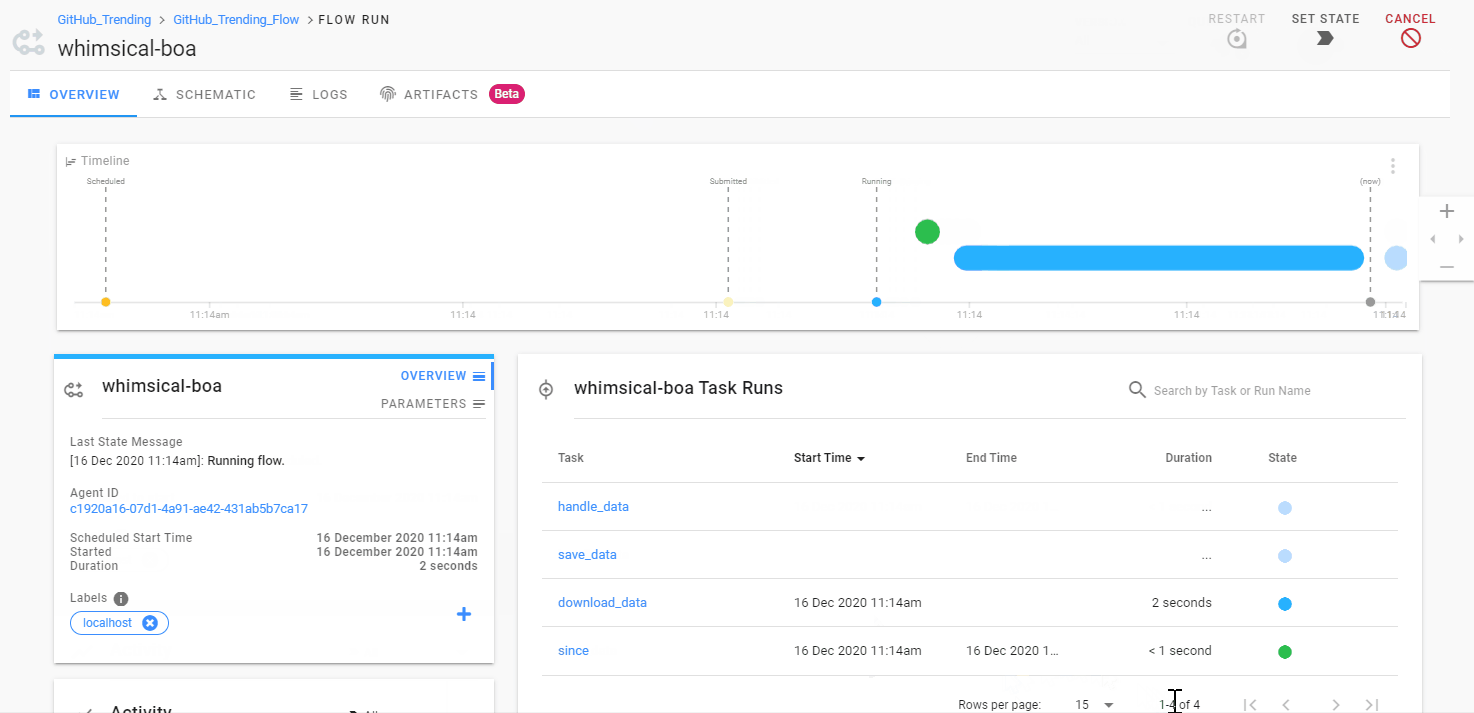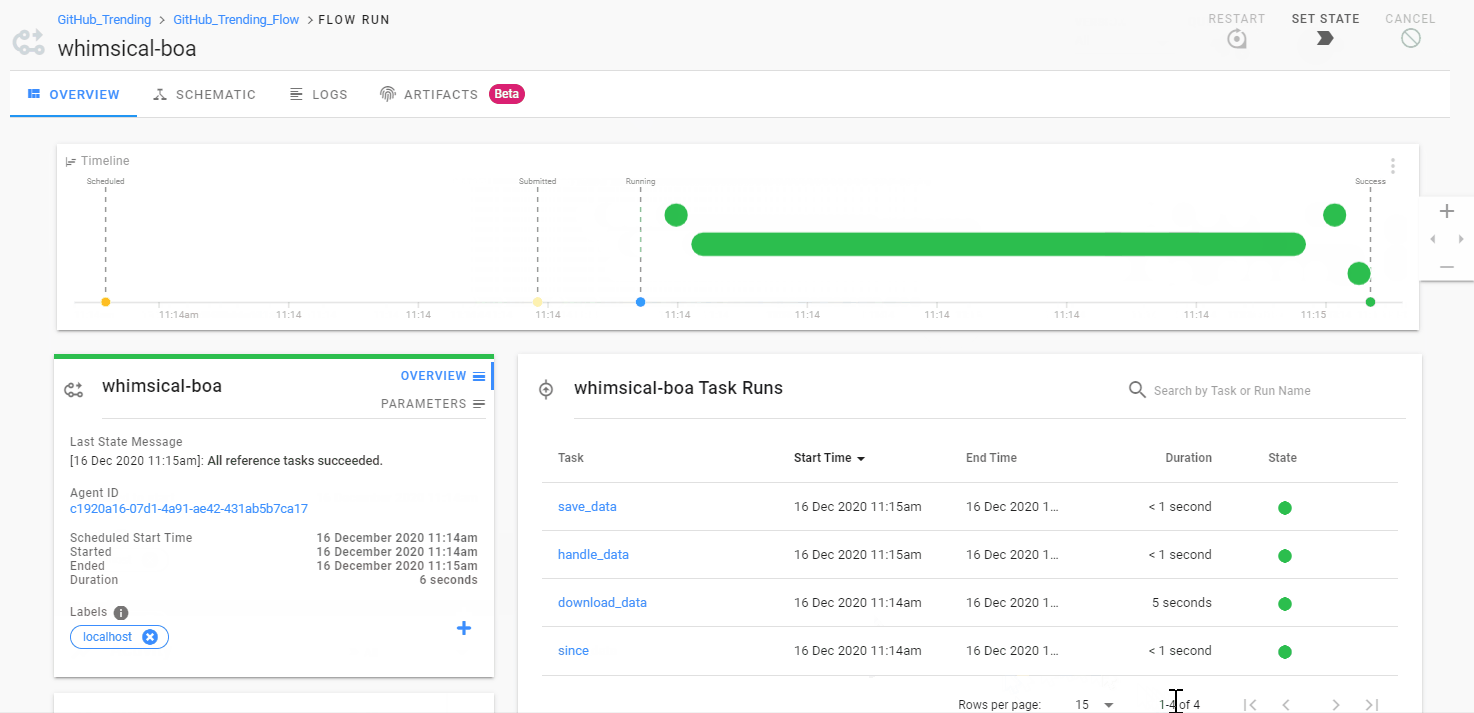
运行过程中,我们可以看到每个任务执行所消耗的时间。而在 「SCHEMATIC」中,我们也可以很清晰地了解整个工作流任务的依赖关系。
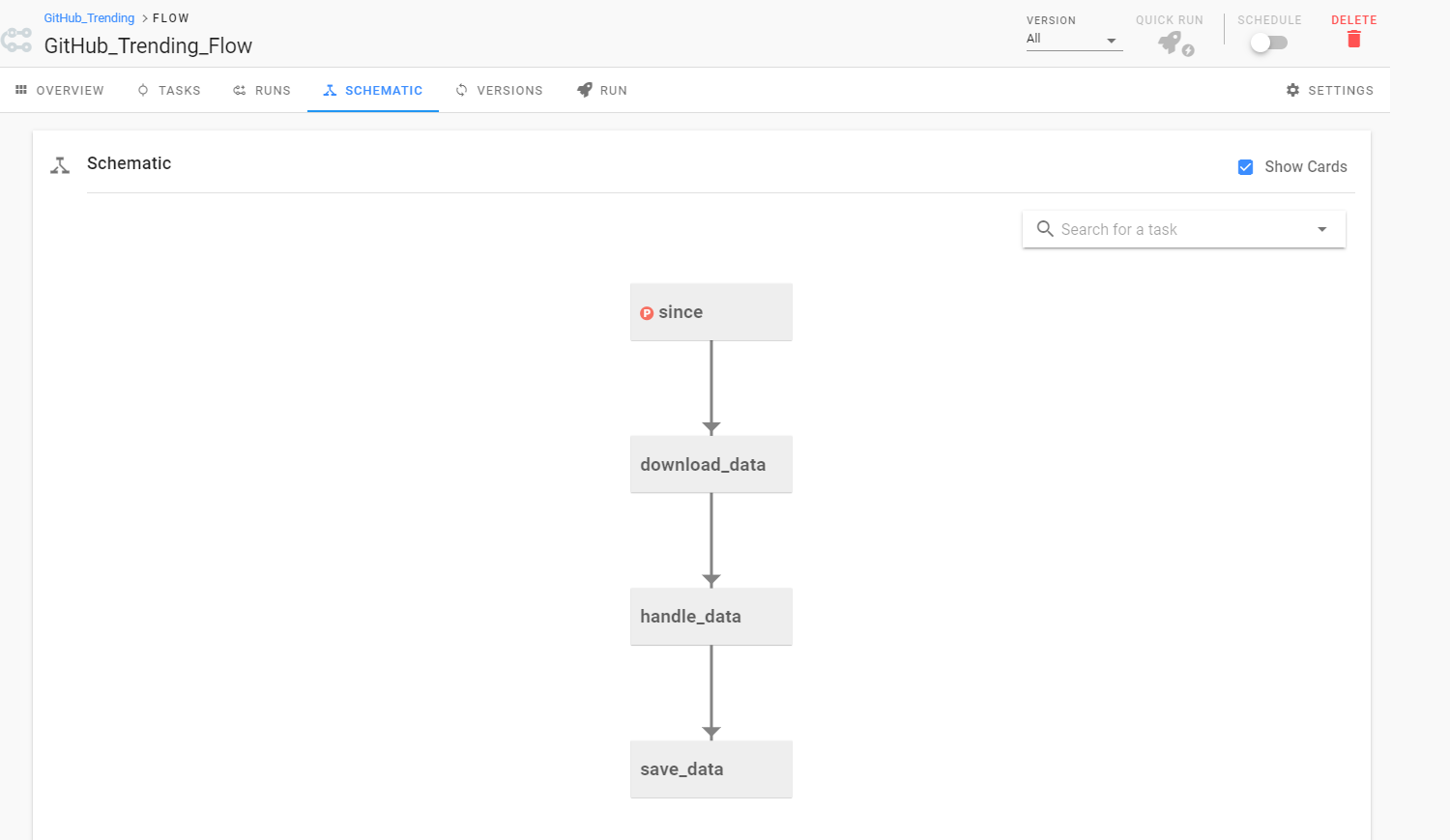
写在最后
文章中仅演示了 Prefect 的部分功能,事实上,Prefect 中还有许多高级的用法,大家有兴趣的话,可以参考官方文档[2],相信大家完全可以编写功能更复杂的工作流程序。
对这个项目有兴趣的小伙伴也可以读下这篇文章[3],作者编写了个统计疫情数据并上传至 S3 的工作流程序,并在 GitHub 上开源了,很不错的一篇文章。
最后附上示例的完整代码:
讯享网#!/usr/bin/env python3 from prefect import task, Flow, Parameter import requests import csv GITHUB_TRENDING_URL = "https://trendings.herokuapp.com/repo" @task def download_data(since): params = {'since': since} trending_data = requests.get(GITHUB_TRENDING_URL, params).json() return trending_data @task def handle_data(data): return [i for i in data["items"]] @task def save_data(rows): headers = ["repo", "repo_link", "stars", "forks", "added_stars"] with open("/tmp/trending.csv", "w", newline="") as f: f_csv = csv.DictWriter(f, headers, extrasaction='ignore') f_csv.writeheader() f_csv.writerows(rows) with Flow("GitHub_Trending_Flow") as flow: since = Parameter("since") data = download_data(since) rows = handle_data(data) save_data(rows) #flow.run(since="weekly") flow.register(project_name="GitHub_Trending")
References
[1] Prefect:https://github.com/PrefectHQ/prefect
[2] 文档:https://docs.prefect.io/core/
[3] 文章:https://makeitnew.io/prefect-a-modern-python-native-data-workflow-engine-7ece02ceb396
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/46806.html