
STTN
Learning Joint Spatial-Temporal Transformations for Video Inpainting:
GitHub - researchmm/STTN: [ECCV'2020] STTN: Learning Joint Spatial-Temporal Transformations for Video Inpainting
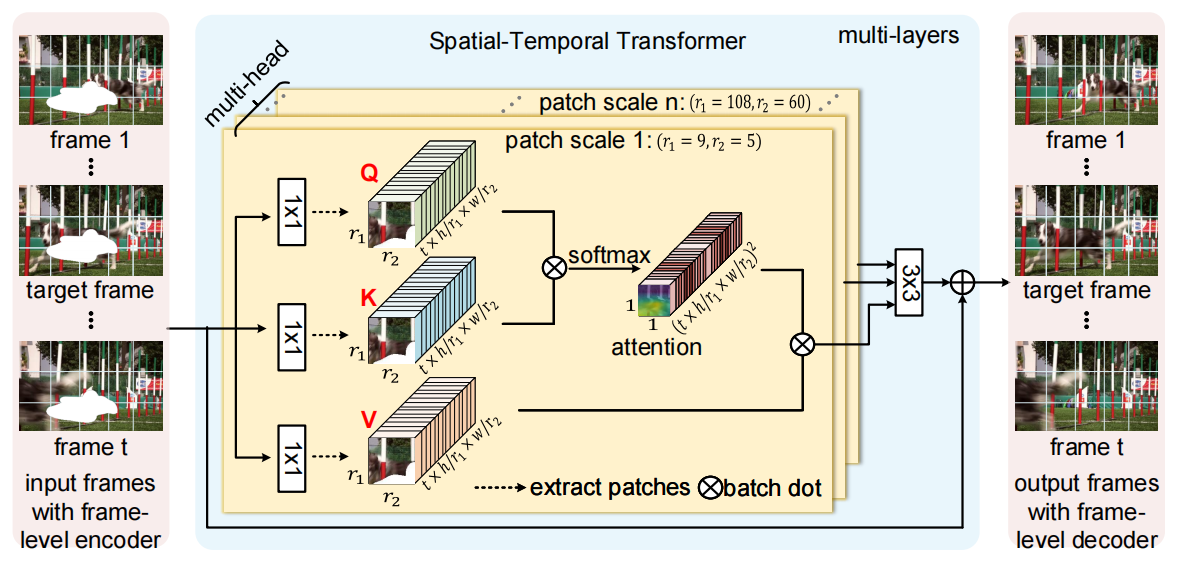
我认为STTN是属于使用transformer构建video inpainting的开山之作,只是使用transformer构建了时空transformer从而实现视频修复
DSTT
Decoupled Spatial-Temporal Transformer for Video Inpainting:GitHub - ruiliu-ai/DSTT
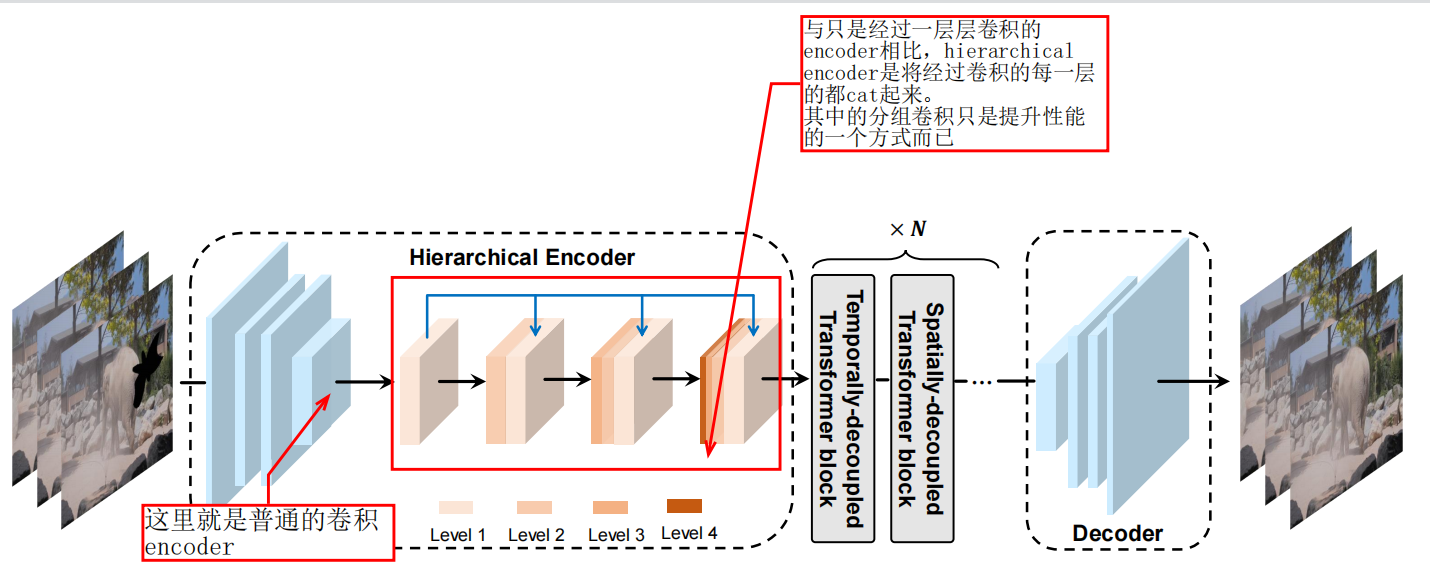
关于DSTT我认为总体的架构上并没有什么改变, 其中的改变或者叫做创新是将transformer encoder的部分做了一下变化,通过cat 不同的feature map替代单层的feature map,然后就是使用了分组卷积

FuseFormer
FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting:https://github.com/ruiliu-ai/FuseFormer
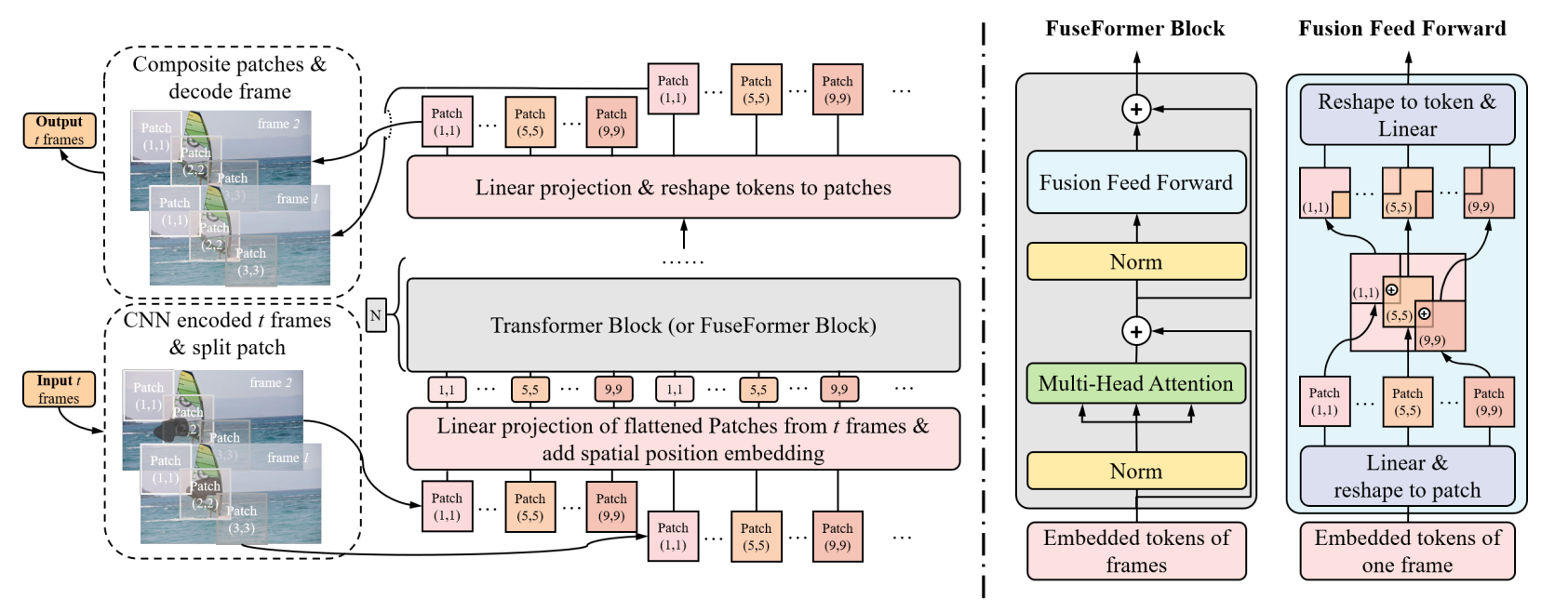
FuseFormer是在transformer block的前向传播过程中做了改进,原来我们将图像且分为patch的方式是将一个图像均匀的分为多少个patch,patch和patch之间并没有重叠,而FuseFormer将patch之间做到了融合,即patch之间有重叠的部分(通过fold和unfold方式实现),原文中说的是:overlapped区域聚合了很多tokens的信息,这对于平滑的边界以及增加感受野很有用
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/42935.html