
在第七代CPU之前,
赛扬和奔腾的区别在于频率和三缓。二者都是双核双线程。
赛扬2M三缓,频率一般在3.0以下,而奔腾频率大多超过3.0,配有3M的三缓。 当然,即使是同代的赛扬和奔腾也都有多个型号。
有一种说法是2M三缓和3M三缓在日常使用中区别巨大,而3M和6M的区别在日常使用中就很小了。
台式机里3.0以下算低频率了,这个时候频率每提高0.1G,带来的提升都是巨大的,至少有5%。
以四代赛扬为例,象棋跑分大概是4500,而奔腾大概是5000。虽然分数差不多,但是用起来是有区别的。
奔腾和I3的区别在于频率和超线程。I3是双核四线程。
I3比奔腾多两个线程,频率也进一步提高,一般都在3.5G以上。虽然三缓依然是3M,I3还多个AVX2指令集,具体作用可以百度。
多两个线程,可以理解为多两个虚拟的核心,这使得I3在多任务处理时明显优于奔腾,而高频率也使得I3的单核能力非常强大,I3 7100频率3.8G,论单核能力已经可以和I5叫板,甚至摸摸I7的屁股。
I3大约能跑7000多。
I3和I5的区别在于睿频,核心数,三缓。I5是四核四线程。
虽然I5 6M的三缓对于日常使用可能作用不大,但是核心数的提升确实质的变化,四核I5在多任务处理上显著优于双核四线程的I3。
睿频我不想多解释,同级别的I5睿频后频率才和I3一样,睿频并没有带给I5单核能力的优势。 I3 6100 频率3.7G,I5 6500频率3.2G,睿频后达到单核最高3.6G,还是不如I3 6100。关于睿频,请百度。
常见的I5 6500跑分大约10000。
I5和I7的区别在于超线程,三缓,频率。I7是四核八线程(暂且不谈I7至尊)。
I7有着8M的三缓,八个线程,I7比之于I5,相当于I3比之于奔腾。不必多言。
I7 6700K跑分16000。
至强又有E3 E5 E7
E3最常见,而E3中用的比较多的型号E3 1230V2,1231V3,1230V5,这些都是I7去掉核心显卡,略微降低频率的产物,
所以同代E3和I7的区别就是频率和核显,还有个没卵用的ECC内存支持,这里不谈。 基本上可以认为E3就是弱化版的I7,无论是E3还是I7,都没有任何神秘加成。
E3也有 四核四线程的版本,相当于I5的弱化版,也有带核显的版本,不过这些都是小众,不谈了。
E3-1230V5跑分14000。
E5和E3最大的区别是E5核心数非常多,频率非常低,使用专业工作,不适合玩游戏。
E3大多是四核八线程,E5甚至有十六核三十二线程的,虽然频率很低,但是上代的价格也不贵。
E7就不说了,反正大家都没有。
----
楼下匿名用户的答案真神了,这图太棒了。大家赶紧点赞!
谢不邀。圈内人士,朋友太多,匿了。
大一新生,有幸跟随导师到学校旁边的由Dalu Wang投资的Dangli Zhuanfan Technical Entertainment Inc.(以下简称ZTE)公司的工业园区参观。
我平时搞那个勤工俭学,没少给这个老师打下手,这次刚好有个人因为在加拿大买不上机票来不了了,顺理成章地就让我跟着去了。
进门倒是正常,没什么特别的,规模和隔壁的华为园区差不多,我一度以为就这样了,本来嘛,我能接触到的有什么厉害玩意儿?
参观车七拐八拐地把我们领到一个不起眼的24层小楼里,一进门就让我们签保密协议。
我之前是个小镇做题家,哪儿见过这阵仗,当时腿就有些软,详细看了看保密协议舒了一口气。
参观过程中,签了大概7、8个保密协议吧,具体多少我忘了,反正内容差不多:在Hedgehog Lab(以下简称HLAB)对外宣布之前连名字都不许提。
参观完之后只有一个心情:激动,或者说,沸腾。
以至于HLAB的信息一被公开,知乎上一出现这个问题,我就跑来回答(放心,回答已经给当时的导师提前看过了,他说这已经都是半公开的秘密了)。
先说来源:
HLAB是ZTE公司在冷战时期立项(此时美国已有颓势),并着手开发的,准备随时替代MATLAB的综合性、跨学科、强拓展、分布式的大数据分析与可视化软件。
我直接说结论吧:
HLAB,从发布到替代MATLAB,只需要一夜。
下面从问题来详细讲讲HLAB的情况,更多的我也没法透露,让子弹飞一会。
- HLAB是什么东西,采用了什么技术?
上面说了HLAB的定义,这里就不再赘述,HLAB现在只是用来替代MATLAB,是因为其它功能还不到时候,不必开放,我稍稍透露一点,HW的芯片部门由于FDA软件被禁,被迫求到ZTE公司申请使用这款软件度过难关,作为交换不再搬迁ZTE的现有在网设备。
采用的技术,我也不是特别懂,我就从我了解的角度来说吧,主要就是这么几个:
- 分布式
- 微内核
- 纯国产
- Serverless
- 已经适配包括鸿蒙在内的所有国产操作系统
- ...
其中分布式和微内核不必多讲,隔壁HW已经解释过了。适配系统也不必多说,是分内的事情。Serverless倒是该行业的创新,不过因为技术太普通就不必赘述了。
纯国产,这点大家可能不知道这个“纯”究竟有多纯。
现在因为还没有完全和美国闹僵,还是使用美国的编程语言进行编写,毕竟比较好用,但是也做好了随时更换到国产编程语言的准备。
“语言”纯:现在HLAB使用的语言,是Javascript(一种高性能、跨平台的编程语言)、CSS和HTML进行编写的,但是!但是!重要的话说三遍,HLAB所使用的编译器,是完全由ZTE公司亲自研发的、能使该语言运行的效率相比Chrome提升50%,并且由于初始的C编译器是ZTE公司自己研发的,不会存在任何后门,也不会受制于人。这是“语言”纯。
“血统”纯:HLAB,是由著名中国软件工程师Dr. DangLi进行设计并指导开发的,并且,开发人员,ZTE公司始终用的是35岁以下的中国年轻人(中老年人更容易受钱权蛊惑,年轻人不易泄密),没有任何一个政审不通过的人参与该项目。这是“血统”纯。
剩下的,不能多说了,还有很多意想不到的地方,也都是我们中国的工程师攻克的。
2. HLAB的性能怎么样?
在HLAB中,ZTE公司特意邀请了隔壁HW老总进行指导,毫不夸张地说,HLAB主要算法的时间复杂度已经达到了惊人的  ,什么概念,证明勾股定理只需要不到1秒。
,什么概念,证明勾股定理只需要不到1秒。
3. HLAB现在可以用到吗?
已经可以使用了,
Hedgehog Lab by Lidangzzz, the most powerful scientific computing environment in your browser with hardware acceleration
并且完全开源,根本不怕老外来抄。
那罗老师当年的操作就会成为现实。
骁龙865的性能如果提升十倍,CPU性能理论上可以吊打9900K,毕竟单核理论性能已经六倍于9900K了,多核性能也数倍于9900K,就算windows转ARM效率再低下,它的实际体验也远强于9900K。GPU性能提升十倍后大概能达到GTX1080的水平,这样的性能在台式机上都不多见。
一个显示器链接一台手机,那它们真的就是一个强劲的工作站。
性能提高10倍,在目前的散热和续航水平来说,没有几个厂商敢用。
如果性能提升10倍,同时,我说的是同时!同时电池技术突破,能量密度提升,在手机10倍性能的前提下依然保持现在的续航。
还有!散热技术也需要提升,在手机10倍性能的前提下依然保持现在的表现,那么这种提升,对于手机还是有一点的影响。
有没有革命性的影响不敢说,但是游戏画质提升、拍摄效果提升(算法和图片处理性能提升)、AR性能提升等等。反正就是硬件性能提升,软件可以尽情的塞东西进去,会带来一点点点点点点的体验提升。
但是,对于某些台式电脑或者轻薄本,容易威胁到它们的定位。有部分人(包括我爸妈),开个电脑就是码字、看视频,购物都不用。手机性能提升到这个地位,必然会有厂商推出一整套解决方案,回到家插上线,就能变成一套小主机了,能够驱动屏幕、鼠标和键盘,码个字、看个视频还是可以的。(笔记本:出去见客户的时候你带个屏幕or手机?咩咩咩?)。
办公室演示也有可能会采用这样的方案,毕竟性能跟得上。
再大胆一点,如果蓝牙采用全新的传输协议,性能提升10倍,回家甚至不用线,直接开个蓝牙就行。如果蓝牙性能提升10倍,第一个应用的可能不是手机,而是台式机和VR。这样的性能提升,对于VR来说,绝对是相当大的利好。台式机负责运算,通过比现在性能好10倍的蓝牙传输到VR眼镜,有条件让VR眼镜完全摆脱线的限制,能够在一个房间里自由活动,而且画质也能有一定的保证。做VR的直接就笑疯了~
那我们就用具体的UPR报告做一次初步解析吧。
因为我没有这个项目的源码,也没有看过这个项目运行的视频,也没有和官方聊过这个项目,只能从报告里的屏幕快照截图推断一下,所以有判断不准确的地方还请包涵。
官方的示例项目地址为:https://upr.unity.com/sample/projects/sample-project 。
项目信息如下:(文章是前段时间写的,现在示例项目已经重传了,猜测是因为报告特性升级了,要配合展示更多的报告内容)
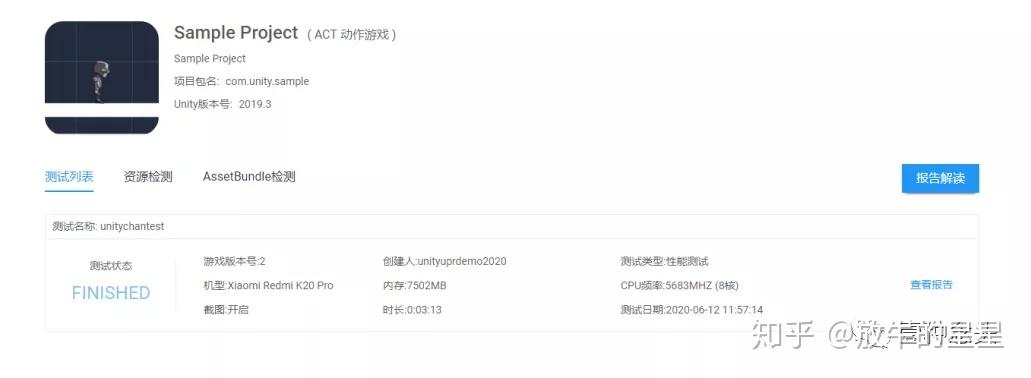
首先从基本信息可以看出来,测试的机器是相当"豪华"的,小米K20 Pro,8G内存 8核。这就意味着有些参数在这台机器上参考价值较小,比如FPS、CPU耗时这些。性能越高的机器,在一些性能指标上往往会表现更好,比如CPU、GPU的负载低那么发热和耗电量的问题就不会存在。但有一些指标的变化是不大的,比如纹理内存、Mono内存、DrawCall等,是基于项目逻辑的,只要跑的逻辑一致,区别不会很大。
1 初步推断
为了方便后面对问题的推测,我这里先大概推断一下Demo类型。根据快照可以看到,应该是一个类似于虚拟歌姬这种舞台+舞蹈的Demo。时长3分钟左右,大概就是一首歌的时间。有很多的舞台效果和漫天彩带的气氛效果,全程应该是没有切场景,没有其他多余操作,只是镜头在不停的变化角度和特写。
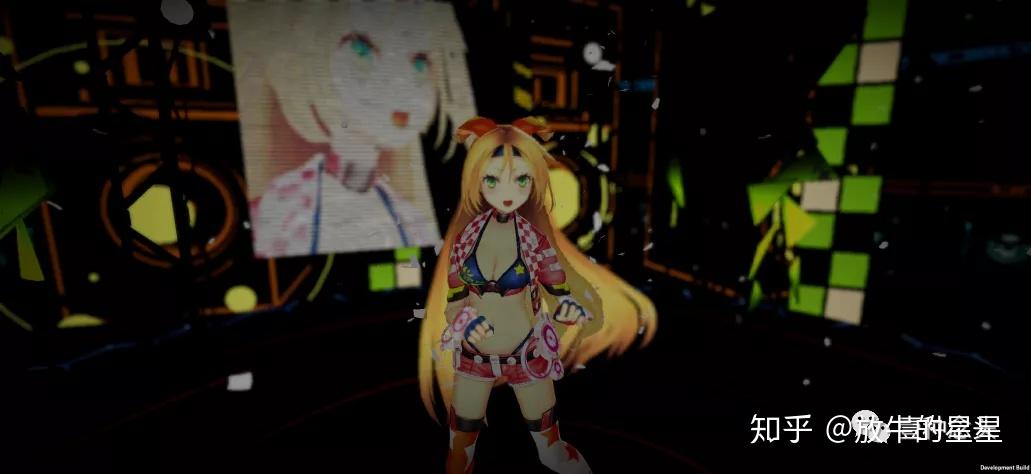
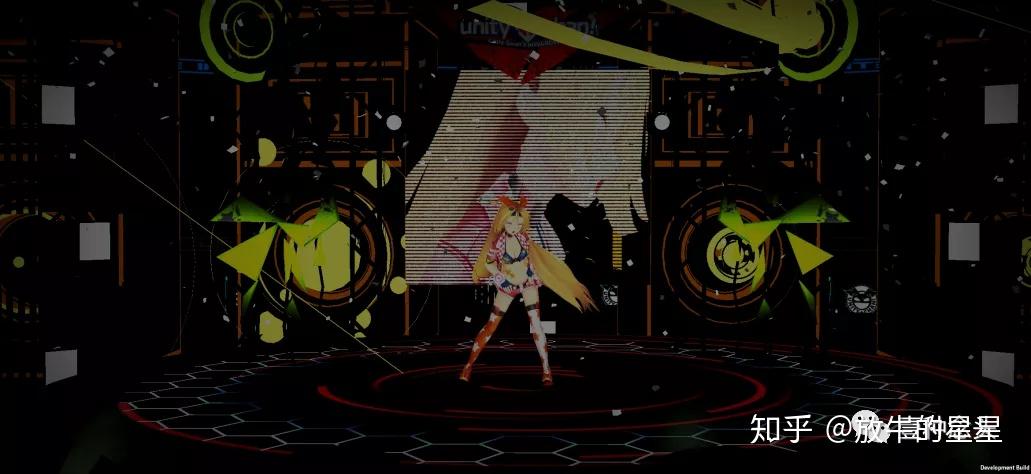
这样的项目理论上来说,资源不会有频繁的加载卸载情况,一般是进入场景,资源加载完成之后变化就不大了。
我们也按照UPR自己的页签做性能推测,页签如下:
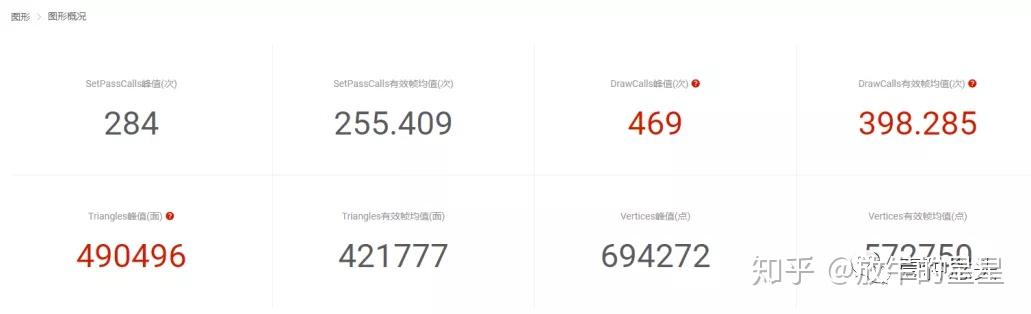
2 测试概况
进来之后,首先看到的是性能总览。
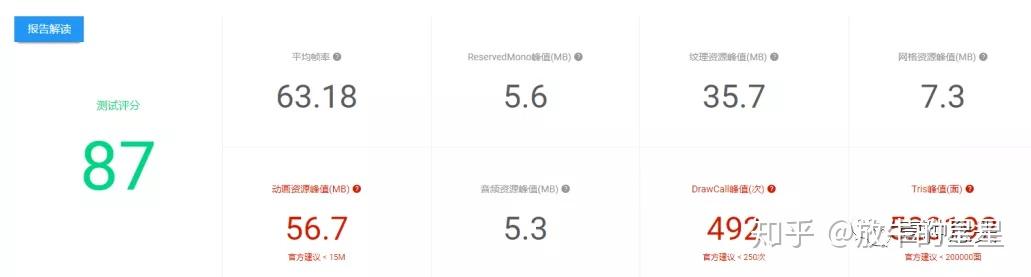
这里的评分我不知道计算公式是啥,但是我觉得没有什么参考价值。不同的游戏实现的方式不同,要达到的效果不同,所以这可以代表官方的评分,对于项目自身而言,你的评分应该基于自己项目实际情况去考量,不必每项都按照官方推荐去改。
第一眼看到的问题就是几个大红字,动画资源过大、DrawCall过多,三角面过多。其他几项从数值上看确实问题不大,但要记住这只是一个Demo,所以是不是有问题我们还要向下看。
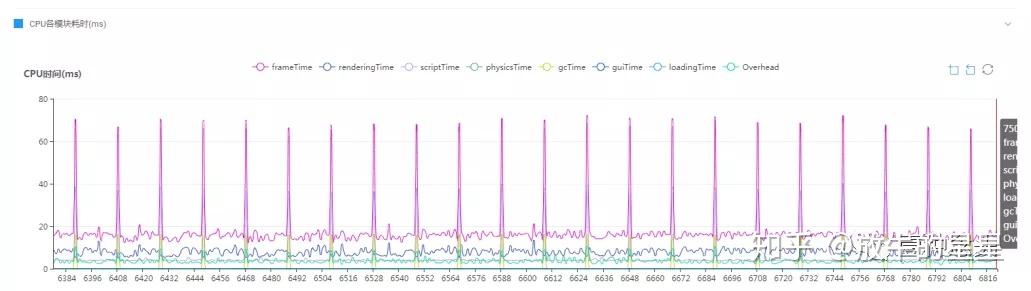
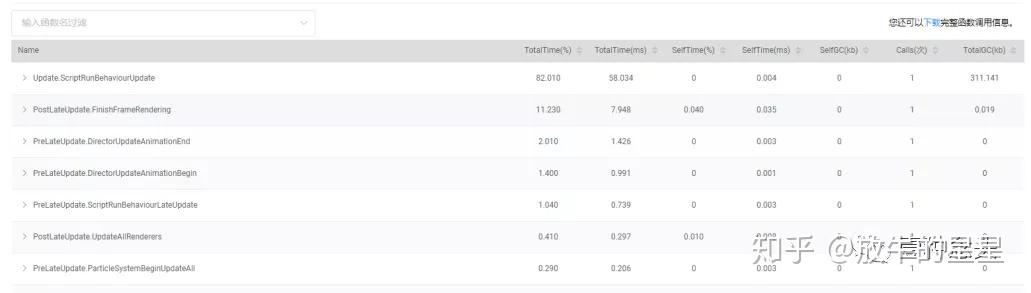
接下来是CPU各个模块耗时图。
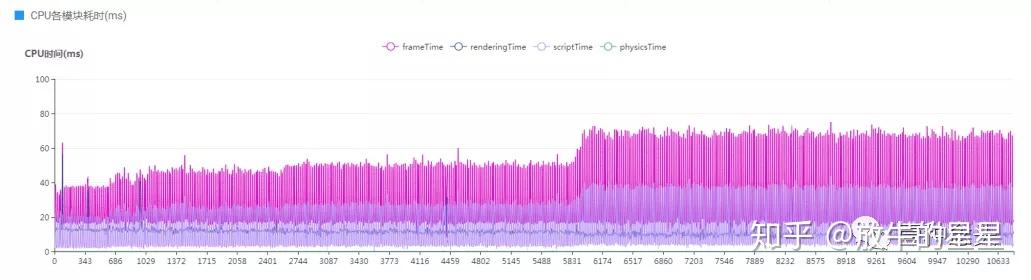
这张图就能看出一些问题了。首先前期段后期长,但相对来说比较平稳,但是这个CPU的执行时间和帧率会让我比较疑惑。按照这里的显示整体的平均帧耗时应该达到了60ms,为何平均帧率还有63呢?咨询了下负责人,概况这一栏的数据是只读的,并且是缩小的,需要在CPU栏放大之后有曲线波动,这个我们就留在CPU页签里说。目前来看帧率统计是没问题的。
再往下看:
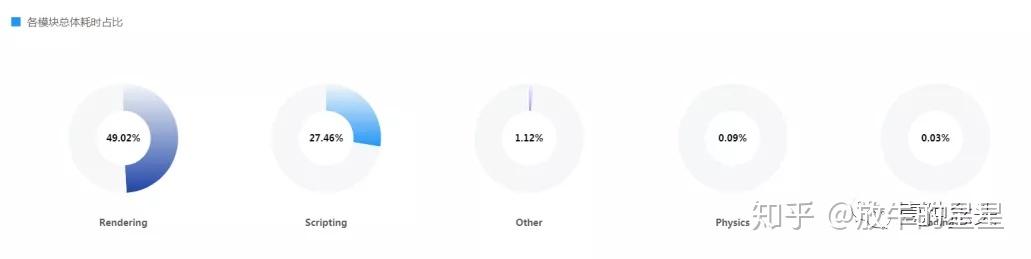
性能的问题大头在渲染层面,这也应和了前面DrawCall峰值接近500,三角面数达到52W。渲染有问题不代表逻辑层面没问题,但具体是不是真有问题还要留到后面汇总信息之后才能判定。
再往下就是本页签最后一个模块,函数帧耗时。这里有4个子页签,我们就选一下平均耗时和平均GC来看一下。
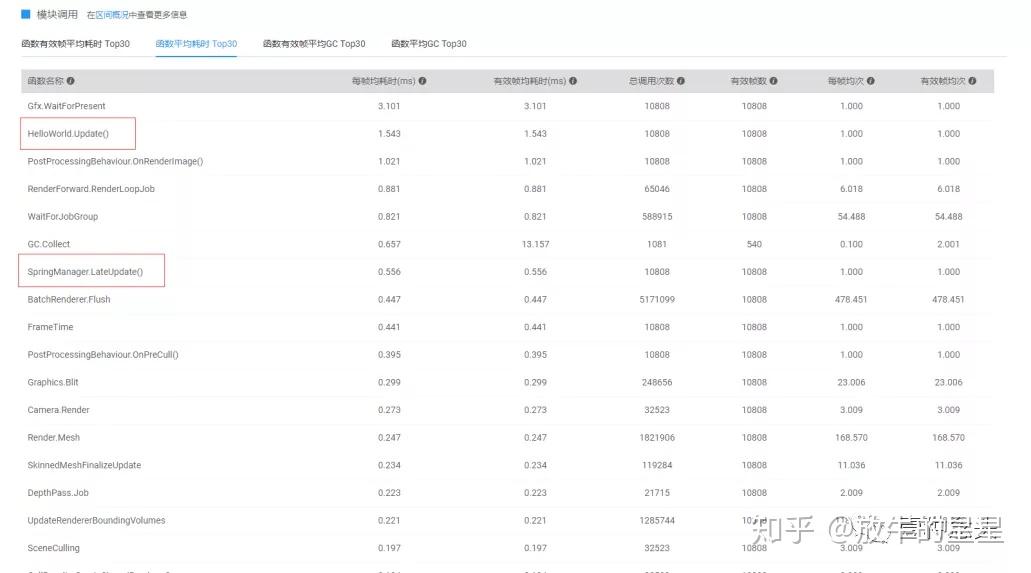
从函数平均耗时来看,top30里比较严重的还是跟渲染相关的部分。然后是逻辑计算和GC。因为我没有看到源码,所以具体逻辑问题不好分析。
而GC方面,逻辑和后处理部分比较严重,甚至说很严重。
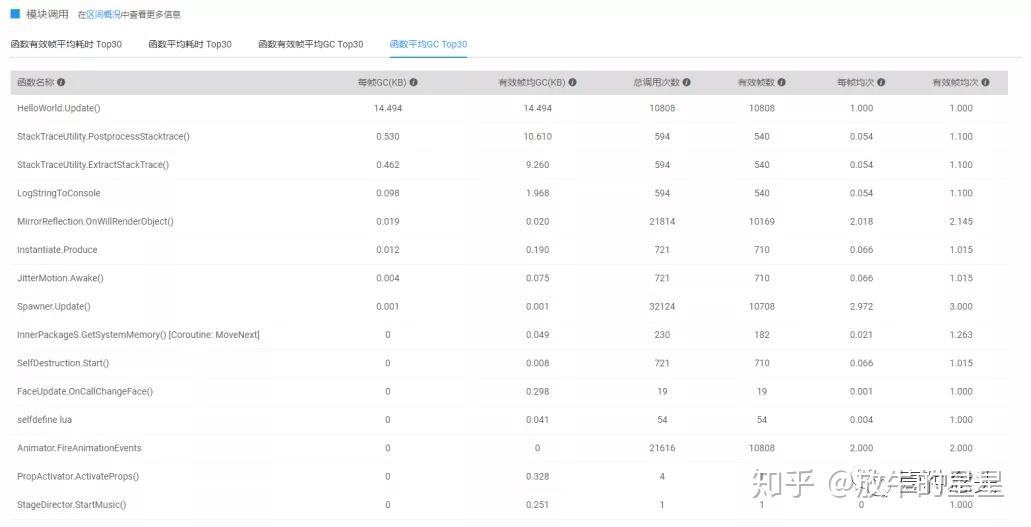
比如HelloWorld.Update帧均14K的GC值,如果累计起来会变的非常庞大。按照当前60帧算,1秒的的GC值快接近1M了。这还只是这一项。
那么总结一下,从概览这一栏,我们分析这个项目目前存在较大的渲染部分性能问题,GC部分性能。逻辑部分单从数据看,问题不大。但是结合项目来看还是有比较大的问题,毕竟这只是一个单独场景的Demo,完全不是真实的游戏项目,不应该有这么大的脚本消耗。
3 区间概况
这是UPR的一个特性,就是可以将整个性能报告的测试区间进行自定义。比如这个项目一共测试了10807帧,你可以选择任何一段连续的区间作为报告,分享给别人,并且所有的数据都会基于该区间重新计算。

默认只有一个区间,生成新区间可以参考手册:
https://upr.unity.com/instructions#intervalSummary
当生成了新区间之后,就可以基于该区间查看性能报告数据:
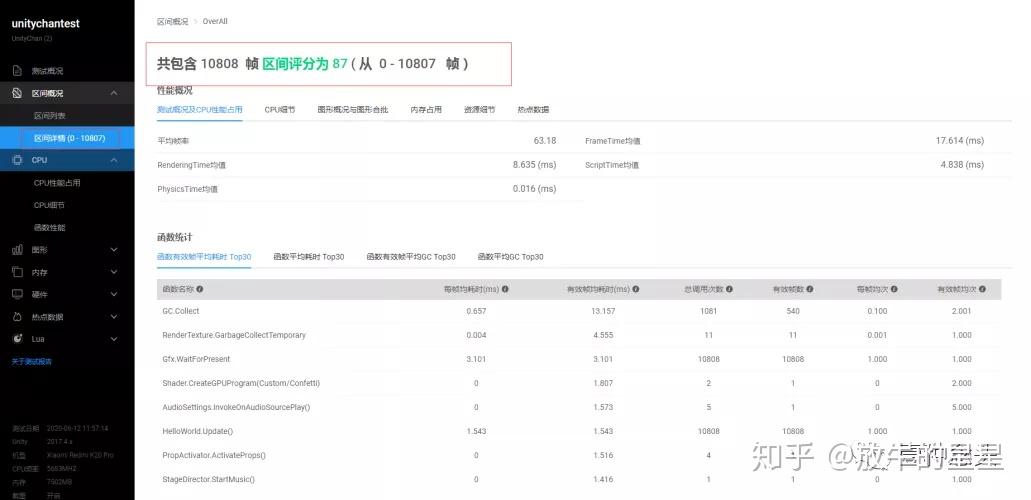
这里我们再看几个该页签下的独有统计。
整体概览看起来项目几乎没有问题。

CPU细节方面,个人觉得Destroy和Instantiate过多,没有必要。因为每个Instantiate的GameObject都要执行很多初始化操作,可以考虑缓存。

图形概况和图形合批上,问题较多,DrawCall、SetPassCall峰值和均值在手游中都无法接受。

内存方面,不太好评价,因为不知道模型和贴图精度,也不知道场景的资源数量,但从Demo的效果和经验来看偏大。

资源细节来看,纹理较大,一张2048*2048的纹理压缩格式下也就4-5M,这里可能是没有进行纹理压缩。AnimationClip资源大,毕竟是舞蹈类的游戏,动作资源量大是符合预期的,但是还是要排查动作资源是不是有做常规优化,或者去除一些不必要的动作参数,压缩一些精度等等。
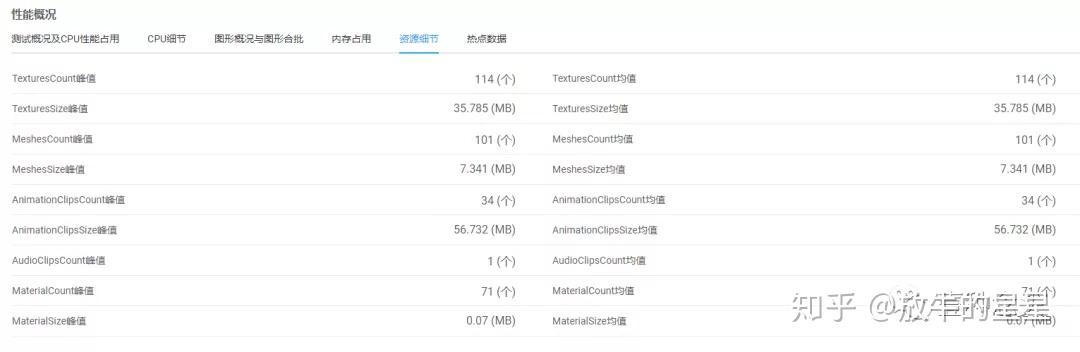
热点数据,问题不大。

4 CPU
这里分为三个模块,CPU性能占用、CPU细节、函数性能。内容比较多 一个一个看吧。
4.1 CPU性能占用
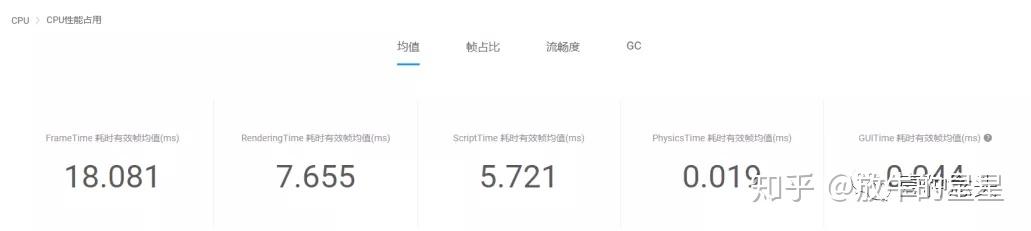
但看性能指标值,是没问题的。不过要记得我们之前说的,因为测试机器比较好,这里的值参考价值不是很大,实际的玩家手上不可能人人都是这么高配的机器,尤其是海外,机型大概就相当于国内15年,16年的平均水平。
上面有4个子页签,都比较好理解,刚才看的是均值,下面看下帧占比:

16ms意味着60帧以下的占比,>33ms意味着30帧以下的占比,>50ms意味着20帧一下的占比。这里的数据会
根据你选择的区间动态计算。区间选择在这里。

流畅度的jank统计,这个我有疑惑,问了负责人之后得到一下答案,供参考。

- CPU详情增加流畅度分析(Jank和BigJank),支持区间实时统计。
Jank: Frame time大于前三帧平均的2倍并且大约84ms
Big Jank: Frame time大于前三帧平均的2倍并且大约125ms
不过对于我个人做项目的经验,掉5帧以上玩家就会感受到比较明显的卡顿。所以理论上如果你的项目能达到60帧,但是偶尔会有几帧掉至55。那么它的流畅效果不如一直保持在50帧。
然后是GC,GC的问题比较严重,前面已经说过了。

OK再往下我们可以看下前面提到的CPU曲线了,激活成功教程前面帧率和CPU时间不对称现在就可以了。放大区间查看:
动力火车java基础怎么样
CPU非常有节奏的高时长(掉帧),这说明逻辑代码存在比较大的性能问题。
再从下面的GC曲线来看,就可以推测出问题来自于GC(并不是所有的CPU耗时问题都来自于GC,只是这个项目现在来看是GC问题,至于为什么会产生GC问题则要仔细分析源码)。
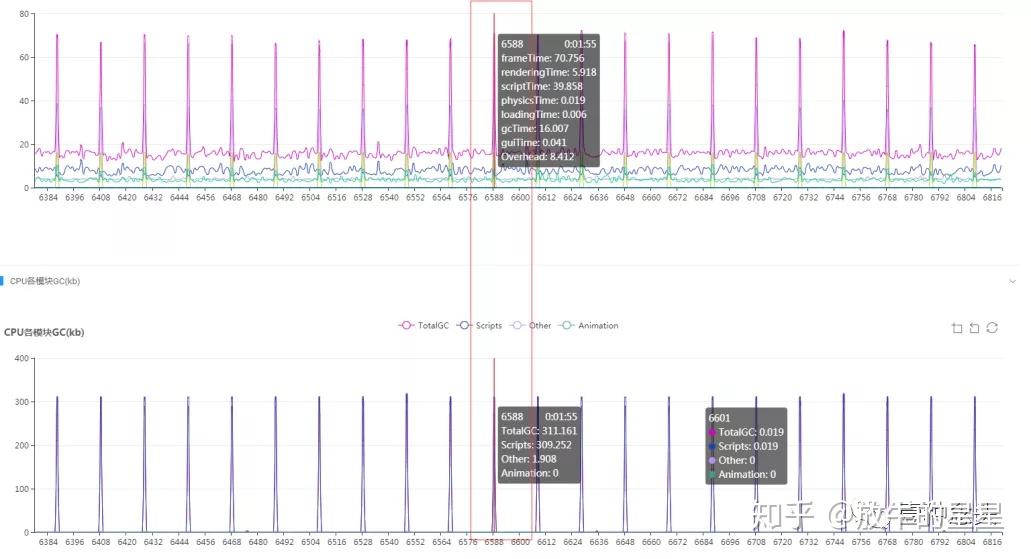
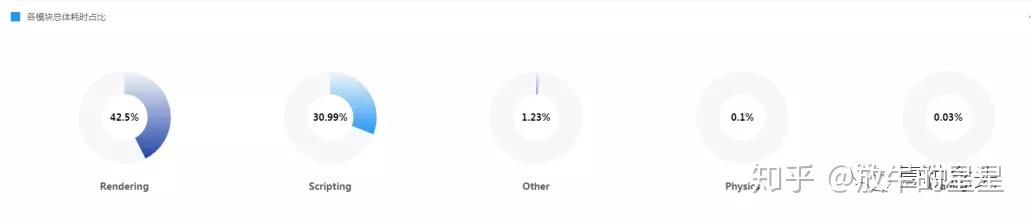
模块的总体耗时,符合前面预期,渲染问题较大,逻辑问题也不小。
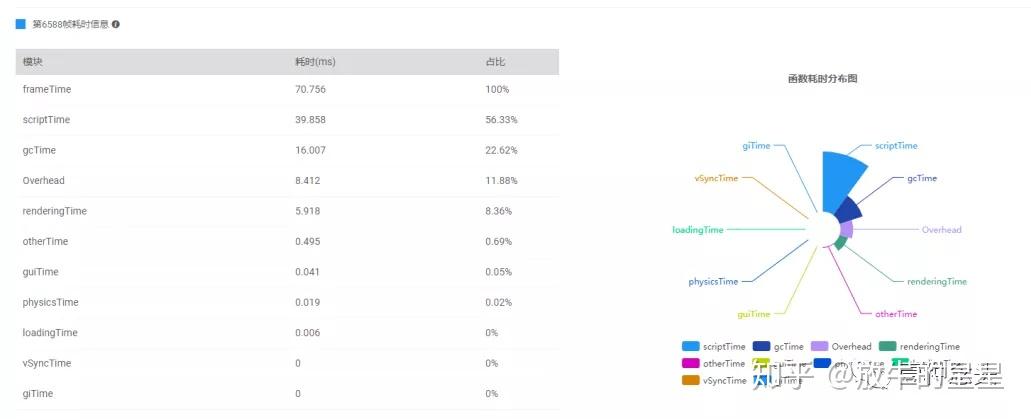
接下来是图形化的统计CPU在这一帧的耗时分布。
接下来是函数的层次结构模式,呃有点意思。和Memory Plus好像。

然后就是具体的函数了,可以搜索查询。
题外话,这里的问题显示来自于HelloWorld.Update。虽然没有看到源码,但基本也知道所有的Update都是在这里驱动的,所以这里不是第一现场。实际上要确定现场可以在代码里打Profiler.Sample的采样函数,这样要采样的函数就会出现在Profiler里了。
4.2 CPU细节
讲快一点吧,这里其实主要体现了三个方面,对象的激活,实例化和模块耗时。
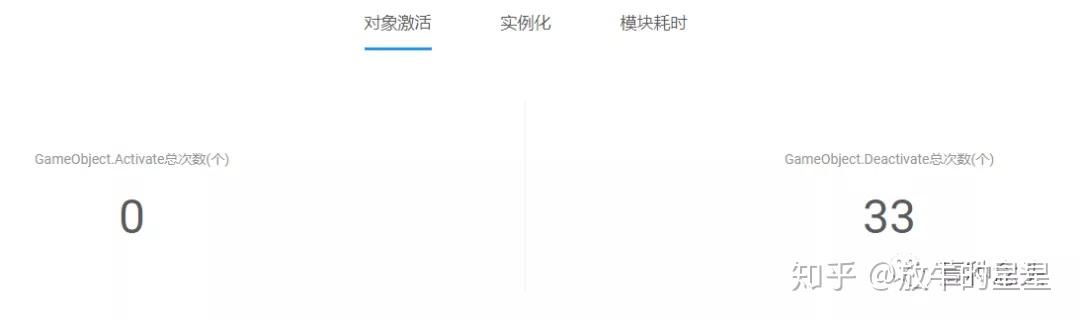

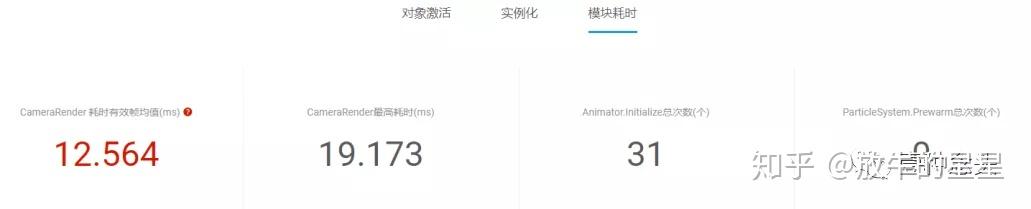
然后下面几条曲线都是针对单帧的统计。就不贴了。
这里主要的问题就是GameObject的初始化和销毁以及激活和隐藏都是有成本的,越多成本则越高。一方面来自于单个Gameobject的相关初始化和收尾工作,另外一方面则来自于后台GameObject和Asset的映射管理。只初始化10万个空的GameObject 什么都不干都能让你卡上一大会儿了。
4.3 函数性能
可以输入具体函数查看耗时。是函数分析的更具体化操作,不详细介绍了。
5 图形
图形分为2个页签,一个是概况一个是合批。其实前面我们已经看出图形这块问题比较大了,这里就可以详细展示一下每一帧对应的绘制情况。还是要再强调一下的是,无论是UWA还是UPR都是只是统计工具,定位问题和解决问题需要自己团队想办法的。
5.1 图形概况
前面已经提过了,这里就看下就好了。
然后我们可以挑选到某一个比较高的值,查看具体情况。
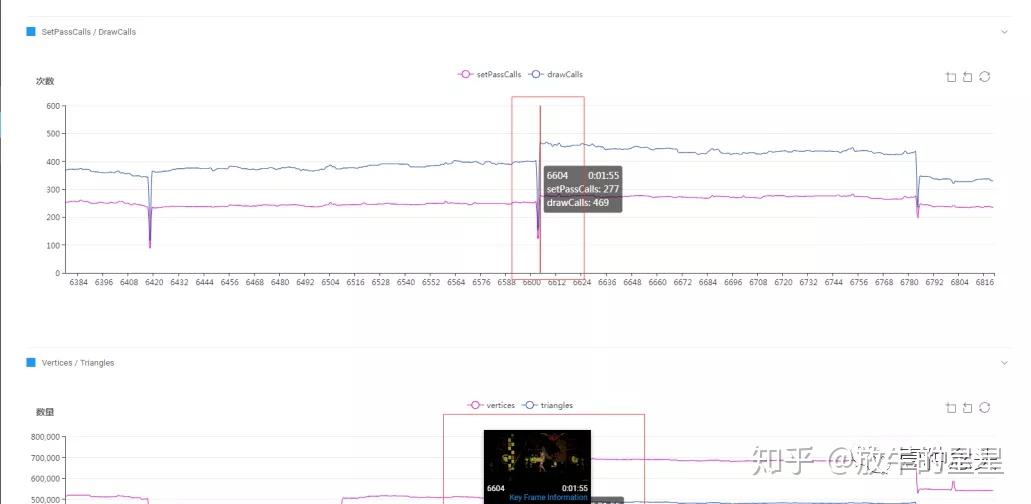
这一帧的截图长这样子:

因为没有实际用FrameDebug查看,不太清楚具体导致渲染的问题,初步判定可能跟模型的制作和场景灯光,包括后面的背景屏有关。背景屏不知道是不是第二套相机渲染,另外漫天的白色飞天推测是用粒子做的,也会影响到DrawCall。另外看不出来是否设置了阴影。
5.2 图形批次

这里可以看到有一些默认的动态合批,也可以看到动态批次曲线。但这只表明了有批次问题,还是不知道为什么会有问题以及如何解决。
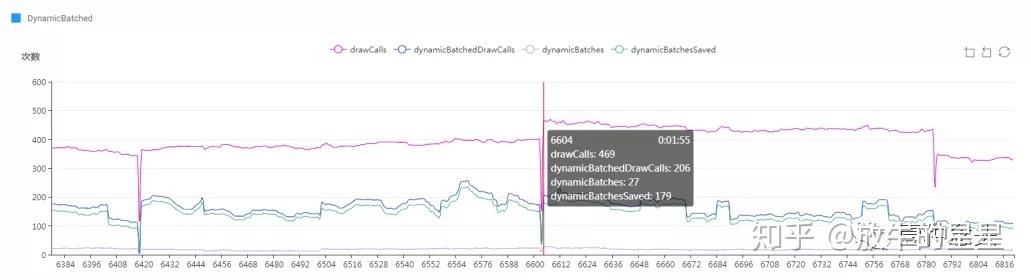
那解决方式只有自己的团队去查看场景和模型资源,找出没有合批批次的原因。
6 内存
内存分为3个部分,内存占用、资源细节、对象快照。
6.1 内存占用
总览,没什么特别之处。

这条曲线可以推测为,整个项目启动之后没有大的纹理、资源的处理,小范围的波动是因为频繁的GC。
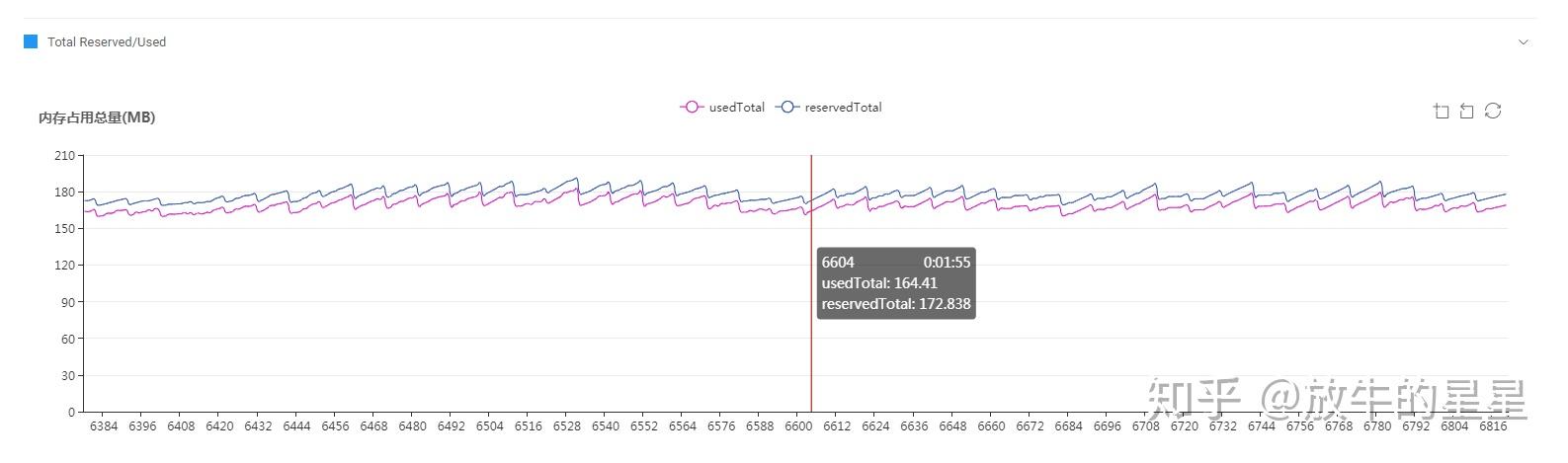
下面的Unity内存使用情况也可以印证这一点。
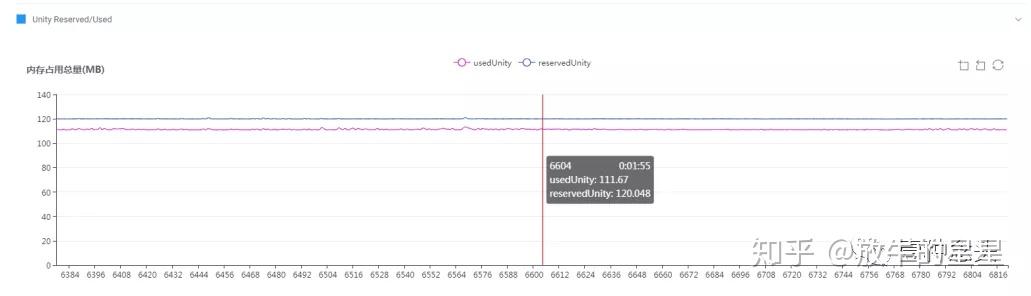
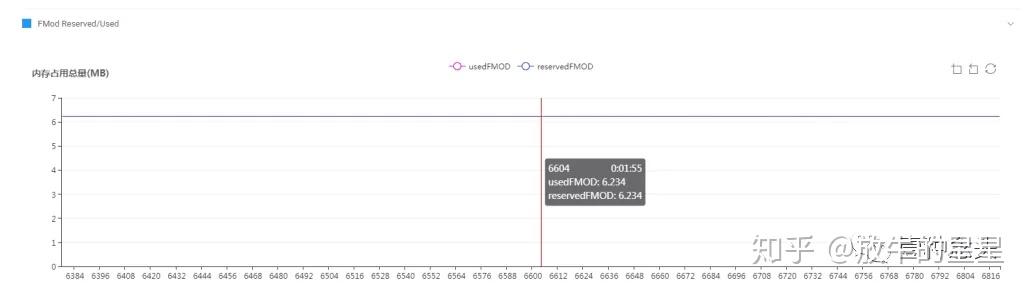
FMOD的内存是因为有歌曲,而Unity的内置音效模块是用的FMod
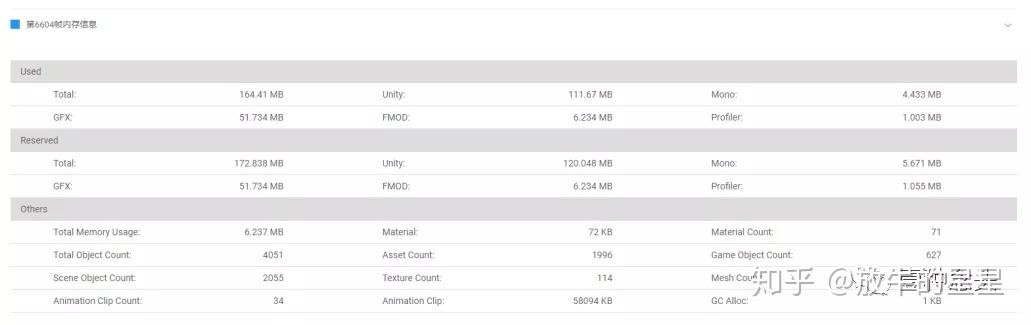
然后就是常规的帧内存信息
6.2 资源细节
这里分了很多子页签,不一一截图了。

这里的所有页签下的曲线都是水平的,也印证前面说的没有资源加载和销毁。都一次加载进内存了。
6.3 这个就是2次对象快照的一些基本信息比对。加入两个快照之后点比对。
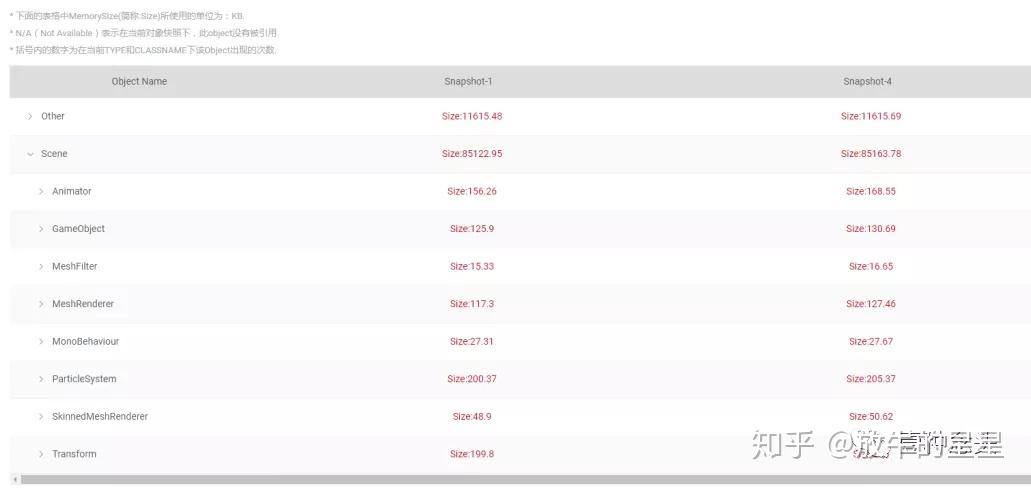
这里就可以看到很多不同的数据项了。
7 硬件
这里统计了电量和温度,一定程度可以体现发热量。另外设备内存这一项比较有用,可以看到总的程序内存占用。
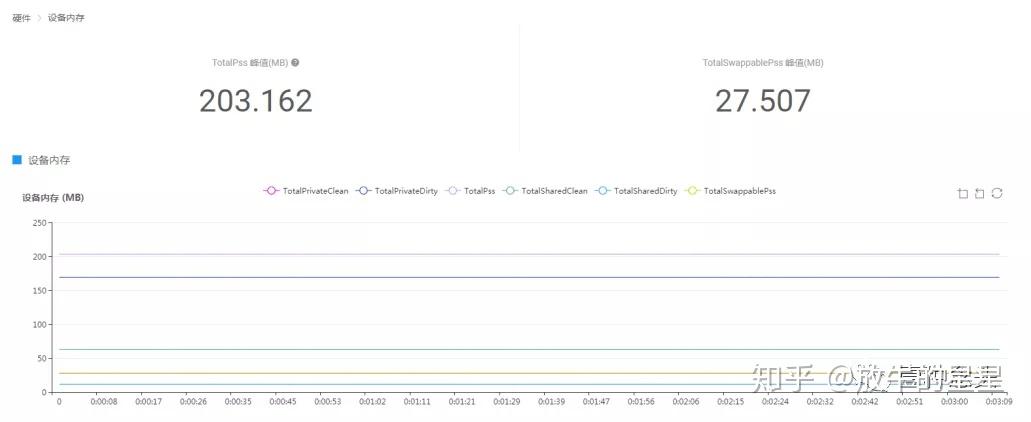
这和前面的内存不同的地方在于,前面的内存只统计了由Unity分配的内存情况,这里包含了很多第三方插件、SDK、Lua等代码分配的内存。TotalPass过高可能会导致闪退。

8 热点数据
热点数据是统计了之前几个页签下比较重要的数据值,前面都已经讲过了,不细说了。
9 Lua
统计Lua相关的内存数据。

可以看到总内存曲线
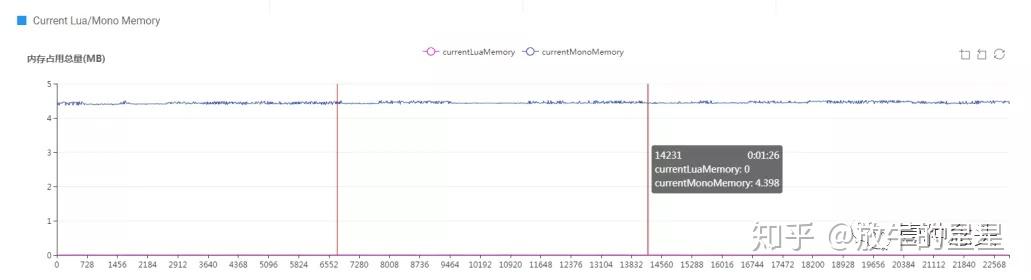
也可以查看区间的Lua情况。
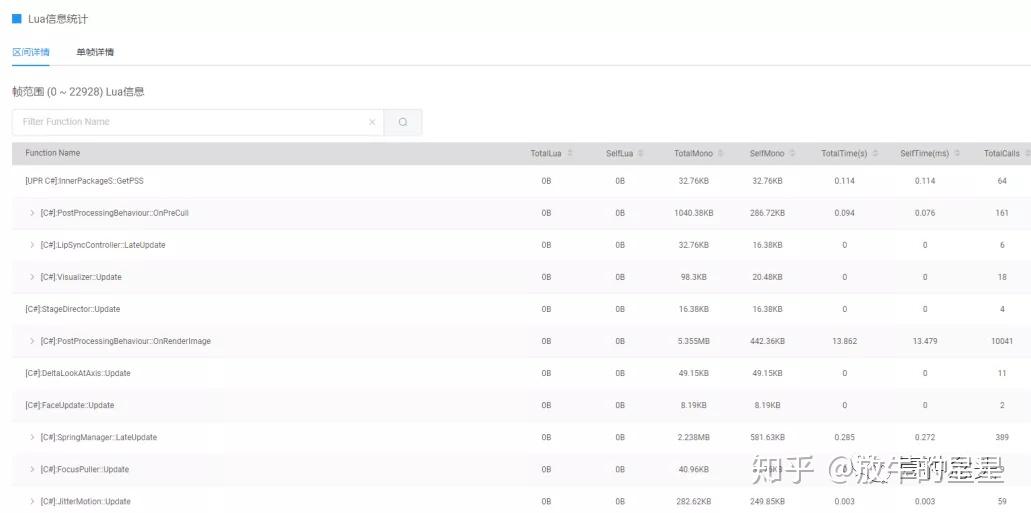
从该项目来看,没啥问题。
额本来只是想写一些性能问题的,但是在前面概况和CPU那边基本已经知道项目问题了,后面就变成了再介绍UPR的页签功能。不过后面稍微简化了一些,加快了文章结束。
其实我还是那句话,这些都只是工具,我们需要的是有人能懂怎么解决问题,然后再用工具找出问题,然后解决它们。不然这些眼花缭乱的数据只会让你不知所措。很多看似没有问题的地方其实潜在问题很多,而一些看似超标的值其实又不一定有问题。
另外一篇是分析如何用侑虎服务来分析性能问题的
如何根据侑虎(UWA)的性能报告,分析出性能问题?
题主并没有点明是台式机桌面版,还是笔记本移动版;
先说热门的笔记本方面;
RTX3050和RTX3060,一个是入门级,一个是主打走量级;
RTX3050基本上5K的游戏本就能入手了,80W版本(低的甚至轻薄本上用的35W也有),3Dmark跑分能上5000分上下了,这个级别,可以对付所有极高画质的网络游戏,包括吃鸡、Dota、原神,当然,对付一般3D建模、平面设计,也是够用的,这个性价比不算低;
这个比115W的2060虽然少了20%的样子,但无疑比1650入门级显卡,高了一个大大的档次;
RTX3060笔记本,这个功耗范围也同样,80W-115W都有;满血115W版本,3Dmark跑分,9000分上下,所有3A类游戏,极高画质下,都能流畅运行了,拔高了个较大档次;
但相对2060,4G显存,玩一些吃显存的游戏,例如Control这种,显存满了之后,掉帧还是很厉害的;


GTA5这种游戏,辆车差距,比control这里大作差距要小些;

大表哥2,帧数差距也在理论范围内;

赛博朋克也比较吃显存,帧数差距加大;
以上就是移动版的行情了;
预算紧自然3050,818活动中,有预算,G15也不差;
再说说桌面版
3060桌面版,今年最垃的桌面版显卡之一,空气就不说了,性能跟笔记本居然差不多,白白浪费了12G显存;
我这边搭载了个平台:
- R5 5600X +B450M重炮+8G*3200MHZ内存2根,玄冰400散热,显卡3060 LDR版本;
3dmark timespy跑了8800分;
现在散货有现货了,但价格依然不便宜...
这种品牌机,性能比我组装的还少5%左右(定制显卡);
至于3050,现在还是预期阶段,预计9月份可能会发行,但期待不高,毕竟3060摆在那里;
这种话题下几乎百分之百会吵起来,但从另一个角度想,品牌之间有竞争其实对我们消费者来说是好事。
如果有一个品牌或者系统占据了接近垄断的地位,所有人都一致认为它就是世界上最好的手机,那这个品牌很快就会进入「店大欺客」的状态,到时候消费者就没得选了。
没见过手机行业的垄断,但是手机里的某些APP,占据垄断地位之后是什么作风,大家应该有所体会吧。
所以现在这样有争论的状态,某种意义上是健康的。
只不过作为个人消费者,攻击其他手机的用户其实没多大意义,证明「我的选择比你的选择明智」或者「傻子才买XX牌手机」不会对厂商产生什么影响。
在「性价比」这个词里面,「价格」是线性的,但「性能」是多元的,影响购买决策的不只是传统意义上的运算性能。
在有的人眼里,「不用花时间研究买哪个」这件事很重重要,所以他们就闭着眼买。
在有的人眼里,「新鲜感」很重要,所以他们买跟上一部手机不一样的。
在有的人眼里,「我的手机跟我的闺蜜/朋友一样」很重要,所以周围人买什么他们就买什么。
在有的人眼里,「我的手机是最新款的」很重要,所以他们会买当下刚刚开过发布会的那个品牌。
在数码发烧友眼里,上面这些理由可能有点难以理解,但像这样买手机的人并不在少数,也并不都是不差钱的人,只不过他们对「性价比」里的那个「性能」的理解不同。
总之,不管是安卓用户还是苹果用户,理智的人都不会希望对方阵营垮掉,一家独大对消费者没什么好处,让厂商相互竞争、相互「卷」起来,消费者才能享受到物美价廉的商品。
钱是自己的,买什么根据自己的需要,买苹果的人很多,但是这集中在5000元以上价位,在刚过去的10月份5000元以上手机市场83.6%的人选iPhone。这是大家用自己的钱投票的结果,就按你说的2000——4000价位那么多高性能手机,那哪个性能强过A15了?真的看配置性价比,iPhone一点不差,因为性能太高了,iPhone是卖的贵不是性价比差。
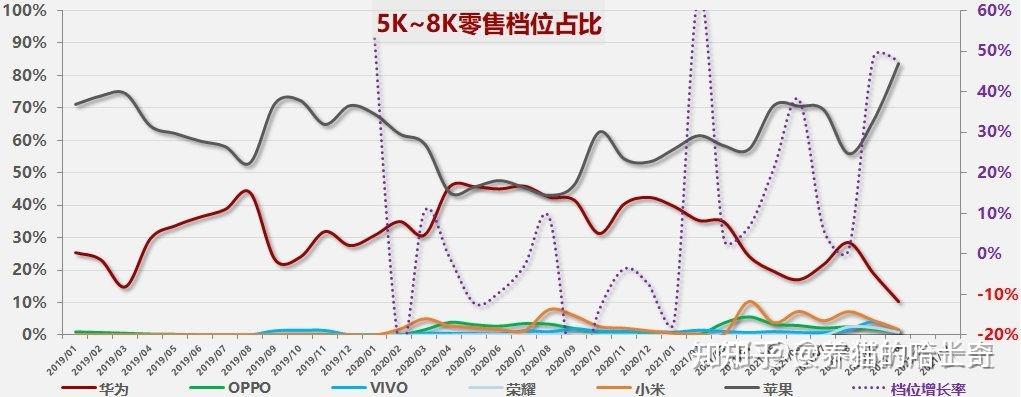
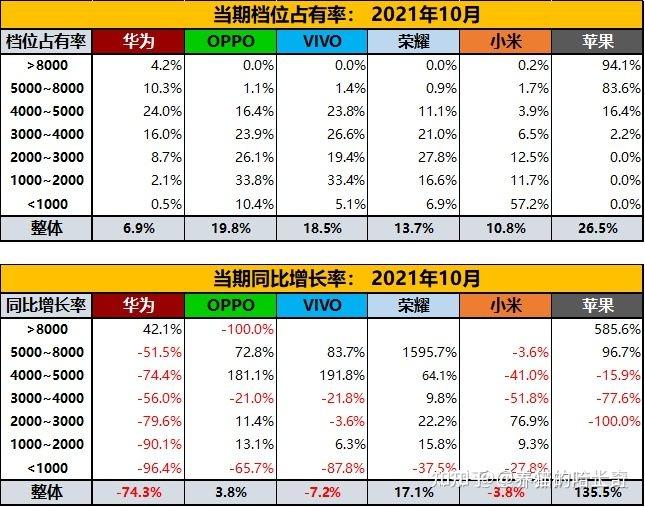
你看全球也是一样,不管什么时候最畅销的机型前几名都是iPhone。
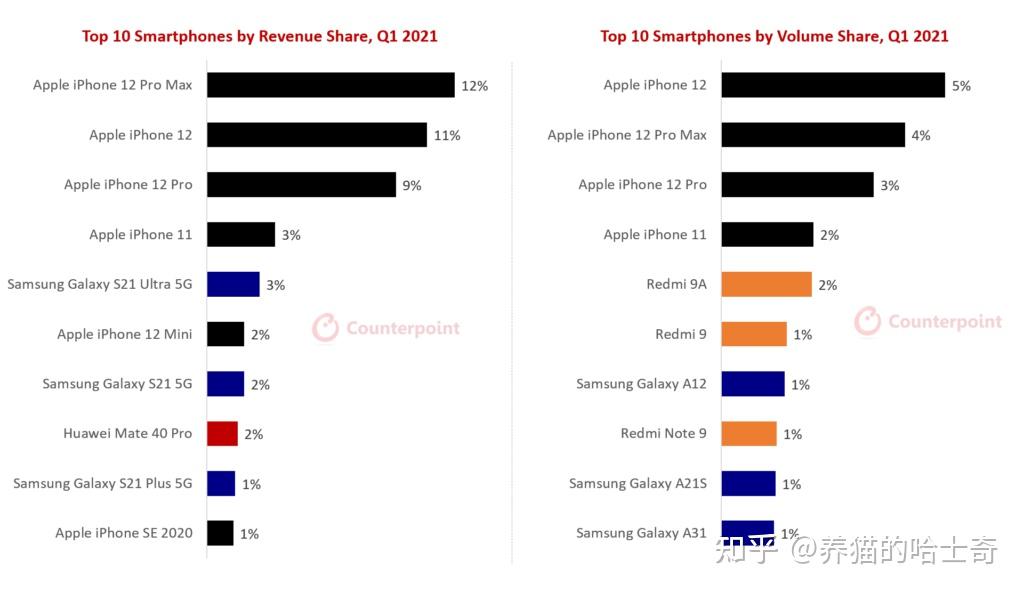
手机咱们大致分成硬件和软件两部分,再加上个品牌服务,这三项iPhone一直都是业界标杆,

硬件里面最重要的就是处理器,这个就不用说了,就安卓厂商这两年吹的线性马达,苹果也早就用了,体验也更好,屏幕也从来都是第一档次,现在连续航都改善了,真的不好挑毛病。
系统层面,我想用过IOS系统,独此一家,Android?选择众多,不是Android不好,是国内的Android缺乏有效管理是真的有点差。

品牌?
这个就不用说了吧。
如果哪个厂商在发布会上吊打一个友商,那说明这个友商的产品其实不错,被吊打最多的就是iPhone,他能不能真吊打那可不能只看他说。
苹果有啥缺点吗?当然,比如老生常谈的信号,是真的不行。
长久以来,我们对计算机资源的理解一直都停留在cpu,内存容量,IO这类的大粒度的划分之上。一个简单的top或者vmstat命令就很方便的帮助我们得到某某计算机需要升级CPU或者加内存这类的结论,经验告诉我们,这一切似乎没有什么错。
如果你是一个发烧级别的PC游戏爱好者,自己配过计算机,或者玩过几个当下“硬件杀手”级别的游戏,你也许会对资源亲和度有个比较粗暴的了解——xx游戏专门针对xx硬件进行了优化;花同样的钱,为了玩爽xx游戏,你应该买个支持xx的卡……这类的话题其实反应了一个问题:应用程序对硬件之间是存在亲和性的!而从这个角度出发,经验中那种盲目的增加硬件的方式并不是一个经济的做法。对于一个台式机来说由于其价格相对不高,且用途非常广泛,一个“亲和力”最多只能在买电脑的时候提供价格参考。而到了相对功能更为单一的服务器领域,“亲和力”就变得很重要。比如你的应用是redis,第一反应就是找台大内存,高频的双核CPU,这是很合理的;而搞一个几十核心,只有几个G内存的机器那就是浪费钱的举动。更何况严谨点的机房数据还有一个“性能功耗比/单位功耗性能”的指标。
毕竟前面提到的redis应用是一个简单到甚至不需要做实验的例子,对于不同的黑盒应用(这里指的是由各种原因无法大幅修改代码逻辑的应用)如何去找到对应亲和度更优的硬件,那就是另一命题了。
Topdown性能分析简介
首先,在系统级别上,我们可以直接通过iostat/vmstat/sar来判断IO或者network是否存在瓶颈,这也许就是传统的CPU/内存/IO三大块中比较容易辨别的IO瓶颈问题,遇上IO瓶颈大部分操作就是升级到更快的SSD硬盘或者更快的网卡。对于内存瓶颈来说,事实上的内存瓶颈有内存容量瓶颈和内存带宽瓶颈两大部分。而当下的x86架构通过多通道内存的方式将容量瓶颈和带宽瓶颈通过同一种简单粗暴加内存条的方式给统一到了一种处理方法上。唯独只有CPU瓶颈的表现成为了最为复杂的过程:轻指令还是重指令?换CPU还是升级版本以支持新功能?高频率还是多核心?大缓存还是大内存?……
前一段时间,读过一篇Ahmand Yasin的IEEE论文“A top-down method for performance analysis and counter architercture[1]”。这篇论文通过称为top-down模型的方法论(TMAM),将细粒度的CPU资源和指令操作联系到了一起,成为了一个兼具通用型和可操作型的应用程序评价系统。换而言之,每一个cpu的微指令都对应了不同的系统微资源的利用依赖度。最终,任何一个应用程序会有4种不同的倾向性。而通过不同倾向性以及子类的权重我们可以很直观的对目前系统特别是CPU的瓶颈作出客观的评价。
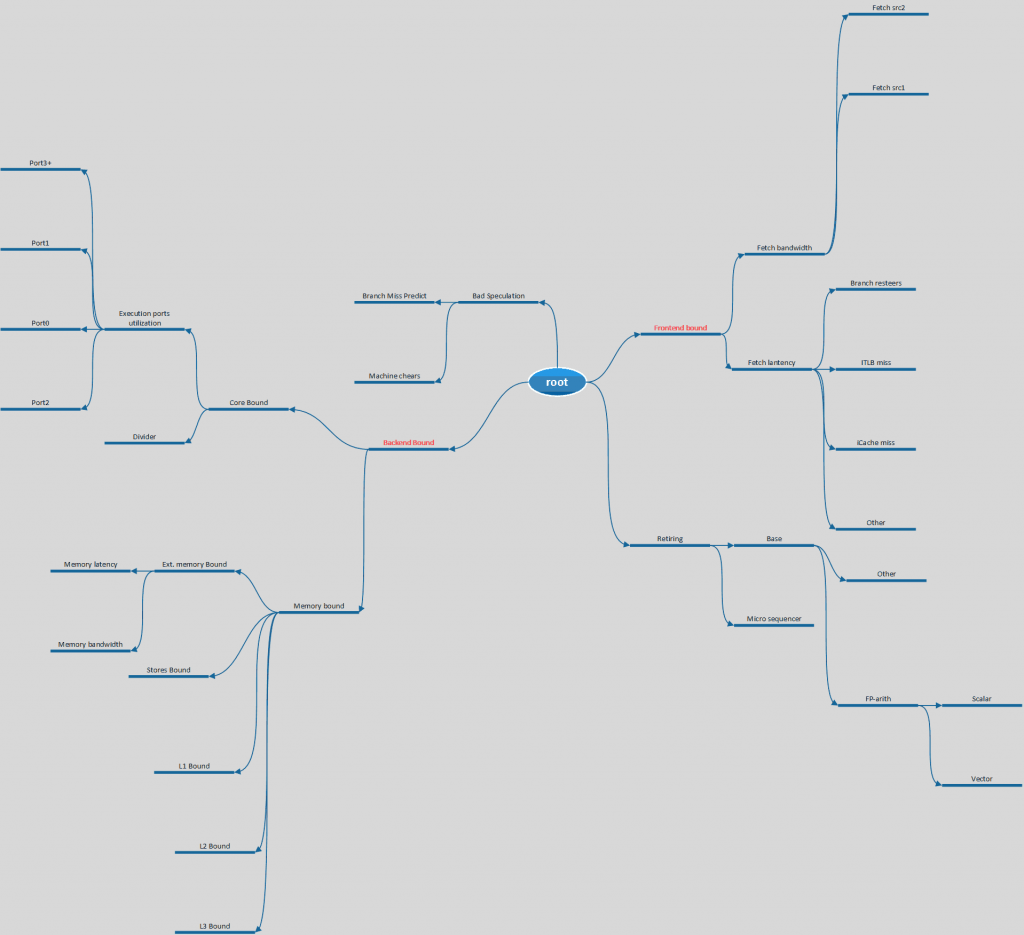
- Frontend bound(前端依赖)首先需要注意的是这里的前端并不是指UI的前端,这里的前端指的是x86指令解码阶段的耗时。
- Backend bound(后端依赖)同样不同于其他“后端”的定义,这里指的是传统的CPU负责处理实际事务的能力。由于这一个部分相对其他部分来说,受程序指令的影响更为突出,这一块又划分出了两个分类。core bound(核心依赖)意味着系统将会更多的依赖于微指令的处理能力。memory bound(存储依赖)我这里不把memory翻译成内存的原因在于这里的memory包含了CPU L1~L3缓存的能力和传统的内存性能。
- Bad speculation(错误的预测)这一部分指的是由于CPU乱序执行预测错误导致额外的系统开销。
- Retiring(拆卸)字面理解是退休的意思,事实上这里指的是指令完成、等待指令切换,模块重新初始化的开销。
由于以上所有的资源都是基于处理器微指令级别的,对于操作系统级别的CPU利用率之类的指标自然也就派不上用场。这里通常用CPI(Cycle Pre nstructuon平均每指令花费的时钟周期数)或者IPC(Instruction Pre Cycle平均每时钟周期完成的指令数)。从表达上看这就是互为倒数的同一个指标的描述,而这个数字是经过了CPU的时钟周期的校准,事实上是跟CPU频率脱了钩。个人习惯上会采用越小越好的CPI,因为系统中缩写为IPC的指标实在太容易混淆(*^_^*)。PS: 尽管当下的CPU理论CPI已经可以接近甚至突破0.3。但低于1.0已经很难说有什么经济性可言,而低于0.8的CPI事实上已无优化的必要。
在实际过程中,一旦系统能够通过应用程序级别的压力测试达到或者接近CPI的最低,我们可以认为系统由于某种原因出现了性能瓶颈。这时就可以通过性能调试工具很容易的获得一系列上面描述的4个指标的组成部分的百分比数(比如:vtune甚至支持直接导出TMAM树图),将各个指标不断的汇总为4个倾向性之后再对系统的性能瓶颈进行评估,这就是top-down的含义。除此以外的数据汇总过程相信根本上就是一个算数问题。
一旦我们得到了4个倾向性占比之后,在黑盒层面上我们已经可以知道该应用程序的亲和性了。剩下的几乎就是套路了。
- 前端依赖型:很少出现,这大多数都是由于CPU微指令无法及时的解析和加载造成的。但往往这意味着系统如果无法找出硬件或者微码级别的问题就无法简单的从代码出发优化程序了。
- 错误的预测型:多半是由于系统采用的编译器和编译配置不佳,尝试从编译器方向解决问题。“换版本”也是解决方法之一。当然,对于某些应用特别是严重绑定用户行为的应用在这一块耗时较长也是可以预期的。
- 拆卸:对不起,对于黑盒应用来说无解。这已经是系统最优结果了。
- 大部分情况下的(黑盒)性能提升都集中在后端依赖上,所以这一部分我们就直接进入下级细分。
- 后端核心依赖型:升级CPU频率,使用更多重指令优化,尽可能的提升子项中port的利用率。此外如果程序支持,只要过程中此项占比没有太大变化,采用更多的核心往往也会有非常线性的性能提升。
- 后端存储依赖型:根据子项中不同的cache level依赖度,找出该应用程序更多的倾向于哪个级别的cache,如果可能就找对应cache更大的产品。如果是内存的话就可以通过升级内存带宽或者更高频、更低潜伏期的内存来获得性能提升。
需要注意的是,以上的所谓套路都是在理论环境下基于一个均一化程度很高的应用程序得出的结论。在不同的硬件平台、不同的业务压力和业务状态下,倾向性也会有显著的差异。而top-down模型的重点在于它还可以通过一个在硬件或者软件配置的连续变化过程中倾向性占比的变化反应来预估应用程序的弹性、最大容量和最优容量。
总结下我自己对topdown分析方式的理解:topdown分析实质上是对应用程序占据的所有微指令CPU running time(CPU运行时间)的分类汇总,从这些数据进一步我们可以了解到每一个微指令基本的资源亲和力,进而为系统级别的的亲和力提供依据。
案例分析:
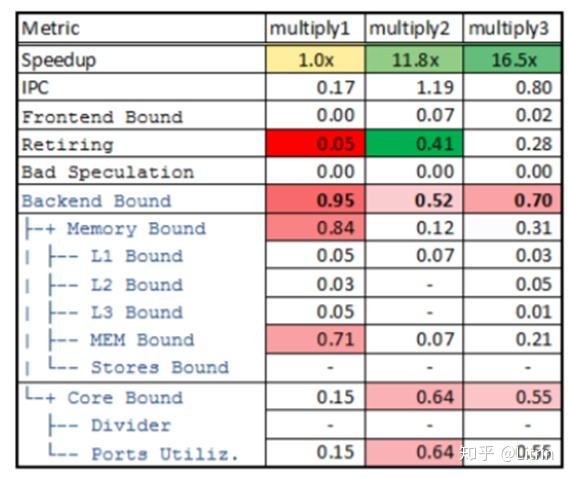
某应用的2步优化,性能提升了12倍和16.5倍,假定业务逻辑没有较大变化,推断优化方式。
1-2的优化分析:
- 首先是IPC和speedup部分接近等比例上升,说明算法部分的改变不大。同样,retiring的提升和IPC提升表明指令执行速度加快。这些是表象。
- memory bound占比减少,mem bound(dram)下降到1/10;core bound占比提升,且port的使用率提升4倍以上。说明应用在这个阶段主要通过优化memory cache,减少了内存的访问瓶颈,从L1的变化上看有极有可能是微调了数据结构,使得其大幅增加了L1的命中概率。
2-3的优化分析:
- IPC下降了50%,speedup上升了50%。看似有点不合理,好比搬砖速度下降了,但工作完成的时间减少了——要么是搬砖的人多了,要么是砖少了。说明算法上有了调整优化,指令数减少。
- memory bound提升不多,单mem bound 提升了3倍,说明读取的次数减少,但每次读取的数量增加,但这个信息结合speedup的提升反而变得没有参考性了。
- core bound/port utilization略降,但比例小于IPC下降的情况可以理解为平均每条指令的执行时间略有提升。指令更重,说明在这个阶段大概率使用了SIMD合并过指令。
--本文部分节选自开源小站2018/02/14发布的 Top-down性能分析模型 - 开源小站
你好,我是倪朋飞。
你是否也曾跟我一样,看了很多书、学了很多Linux性能工具,但在面对Linux性能问题时,还是束手无策?实际上,性能分析和优化始终是大多数软件工程师的一个痛点。但是,面对难题,我们真的就无解了吗?
固然,性能问题的复杂性增加了学习难度,但这并不能成为我们进阶路上的“拦路虎”。在我看来,大多数人对性能问题“投降”,原因可能只有两个。
一个是你没找到有效的方法学原理,一听到“系统”、“底层”这些词就发怵,觉得东西太难,自己一定学不会,自然也就无法深入学下去,从而不能建立起性能的全局观。
再一个就是,你看到性能问题的根源太复杂,既不懂怎么去分析,也不能抽丝剥茧找到瓶颈。
你可能会想,反正程序出了问题,上网查就是了,用别人的方法,囫囵吞枣地多试几次,有可能就解决了。于是,你懒得深究这些方法为啥有效,更不知道为什么,很多方法在别人的环境有效,到你这儿就不行了。
所以,相同的错误重复在犯,相同的状况也是重复出现。
其实,性能问题并没有你想像得那么难,只要你理解了应用程序和系统的少数几个基本原理,再进行大量的实战练习,建立起整体性能的全局观,大多数性能问题的优化就会水到渠成。
我见过很多工程师,在分析应用程序所使用的第三方组件的性能时,并不熟悉这些组件所用的编程语言,却依然可以分析出线上问题的根源,并能通过一些方法进行优化,比如修改应用程序对它们的调用逻辑,或者调整组件的配置选项等。
还是那句话,你不需要了解每个组件的所有实现细节,只要能理解它们最基本的工作原理和协作方式,你也可以做到。
性能指标是什么?
学习性能优化的第一步,一定是了解“性能指标”这个概念。
当看到性能指标时,你会首先想到什么呢?我相信“高并发”和“响应快”一定是最先出现在你脑海里的两个词,而它们也正对应着性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,直接影响了产品终端的用户体验。跟它们对应的,是从系统资源的视角出发的指标,比如资源使用率、饱和度等。

我们知道,随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求。这包含了一系列的步骤,比如下面这六个步骤。
- 选择指标评估应用程序和系统的性能;
- 为应用程序和系统设置性能目标;
- 进行性能基准测试;
- 性能分析定位瓶颈;
- 优化系统和应用程序;
- 性能监控和告警。
了解了这些性能相关的基本指标和核心步骤后,该怎么学呢?接下来,我来说说要学好Linux 性能优化的几个重要问题。
学这个专栏需要什么基础
首先你要明白,我们这个专栏的核心是性能的分析和优化,而不是最基本的Linux操作系统的使用方法。
因而,我希望你最好用过Ubuntu或其他Linux操作系统,然后要具备一些编程基础,比如:
- 了解Linux常用命令的使用方法;
- 知道怎么安装和管理软件包;
- 知道怎么通过编程语言开发应用程序等。
这样,在我讲性能时,你就更容易理解性能背后的原理,特别是在结合专栏里的案例实践后,对性能分析能有更直观的体会。
这个专栏不会像教科书那样,详细教你操作系统、算法原理、网络协议乃至各种编程语言的全部细节,但一些重要的系统原理还是必不可少的。我还会用实际案例一步步教你,贯穿从应用程序到操作系统的各个组件。
大家可以来试读部分专栏内容看看是否与自己的能力和实际情况匹配▽
ps:现在订阅还享首单特惠福利,是我争取到的最大福利了。
https:// xg.zhihu.com/plugin/084 cb97146bfb4b94919accd523e25a4?BIZ=ECOMMERCE学习的重点是什么?
想要学习好性能分析和优化,建立整体系统性能的全局观是最核心的话题。因而,
- 理解最基本的几个系统知识原理;
- 掌握必要的性能工具;
- 通过实际的场景演练,贯穿不同的组件。
这三点,就是我们学习的重中之重。我会在专栏的每篇文章中,针对不同场景,把这三个方面给你讲清楚,你也一定要花时间和心思来消化它们。
其实说到性能工具,就不得不提性能领域的大师布伦丹·格雷格(Brendan Gregg)。他不仅是动态追踪工具DTrace的作者,还开发了许许多多的性能工具。我相信你一定见过他所描绘的Linux性能工具图谱:
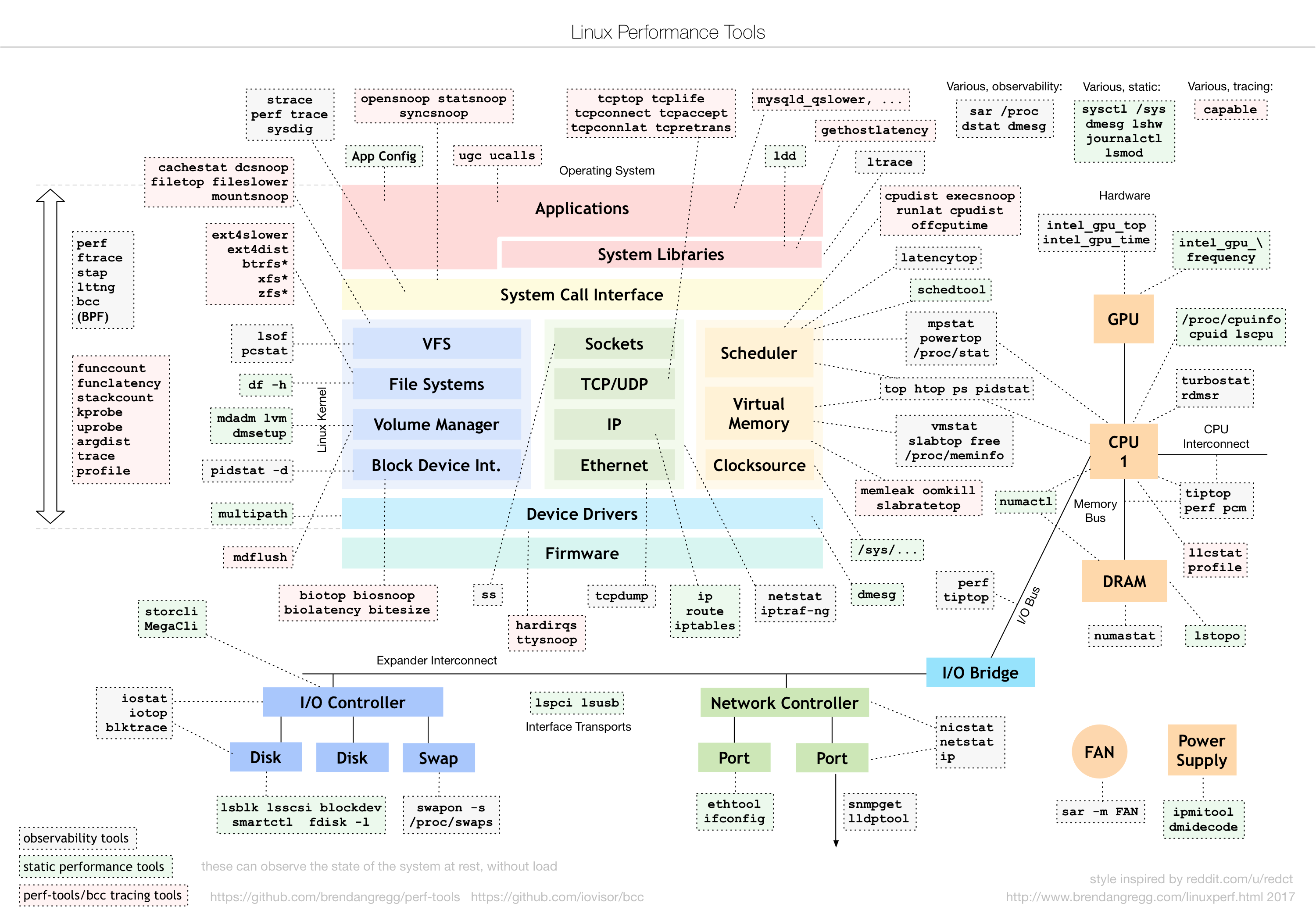
(图片来自[Brendan Gregg's Homepage])
这个图是Linux性能分析最重要的参考资料之一,它告诉你,在Linux不同子系统出现性能问题后,应该用什么样的工具来观测和分析。
比如,当遇到I/O性能问题时,可以参考图片最下方的I/O子系统,使用iostat、iotop、blktrace等工具分析磁盘I/O的瓶颈。你可以把这个图保存下来,在需要的时候参考查询。
另外,我还要特别强调一点,就是性能工具的选用。有句话是这么说的,一个正确的选择胜过千百次的努力。虽然夸张了些,但是选用合适的性能工具,确实可以大大简化整个性能优化过程。在什么场景选用什么样的工具、以及怎么学会选择合适工具,都是我想教给你的东西。
但是切记,千万不要把性能工具当成学习的全部。工具只是解决问题的手段,关键在于你的用法。只有真正理解了它们背后的原理,并且结合具体场景,融会贯通系统的不同组件,你才能真正掌握它们。
最后,为了让你对性能有个全面的认识,我画了一张思维导图,里面涵盖了大部分性能分析和优化都会包含的知识,专栏中也基本都会讲到。你可以保存或者打印下来,每学会一部分就标记出来,记录并把握自己的学习进度。
怎么学更高效?
前面我给你讲了Linux性能优化的学习重点,接下来我再跟你分享一下,我的几个学习技巧。掌握这些技巧,可以让你学得更轻松。
技巧一:虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节。
深陷到系统实现的内部,可能会让你丢掉学习的重点,而且繁杂的实现逻辑,很可能会打退你学习的积极性。所以,我个人观点是一定要适度。
你可以先学会我给你讲的这些系统工作原理,但不要去深究Linux内核是如何做到的,而是要把你的重点放到如何观察和运用这些原理上,比如:
- 有哪些指标可以衡量性能?
- 使用什么样的性能工具来观察指标?
- 导致这些指标变化的因素等。
技巧二:边学边实践,通过大量的案例演习掌握Linux性能的分析和优化。
只有通过在机器上练习,把我讲的知识和案例自己过一遍,这些东西才能转化成你的。我精心设计这些案例,正是为了让你有更好的学习理解和操作体验。
所以我强烈推荐你去实际运行、分析这些案例,或者用学到的知识去分析你自己的系统,这样你会有更直观的感受,获得更好的学习效果。
技巧三:勤思考,多反思,善总结,多问为什么。
想真正学懂一门知识,最好的方法就是问问题。当你能提出好的问题时,就说明你已经深入了解了它。
你可以随时在留言区给我留言,写下自己的疑问、思考和总结,和我还有其他的学习者一起讨论切磋。你也可以写下自己经历过的性能问题,记录你的分析步骤和优化思路,我们一起互动探讨。
学习之前,你的准备
作为一个包含大量案例实践的课程,我会在每篇文章中,使用一到两台Ubuntu 18.04虚拟机,作为案例运行和分析的环境。如果你只是单纯听音频的讲解,却从不动手实践,学习的效果一定会大打折扣。
所以,你是不是可以准备好一台Linux机器,用于课程案例的实践呢?任意的虚拟机或物理机都可以,并不局限于Ubuntu系统。
思考
今天的内容是我们后续学习的热身准备。从下篇文章开始,我们就要正式进入Linux性能分析和优化了。所以,我想请你来聊一聊,你之前在解决Linux性能问题时,有遇到过什么样的困难或者疑惑吗?或者是之前自己学习Linux性能优化时,有哪些问题吗?参考我今天所讲的内容,你又打算怎么来学这个专栏?
https:// xg.zhihu.com/plugin/084 cb97146bfb4b94919accd523e25a4?BIZ=ECOMMERCE△完整专栏点击即可订阅
△新用户享首单特惠,仅¥19.9
欢迎在留言区和我分享。

你好,我是倪朋飞。
你是否也曾跟我一样,看了很多书、学了很多Linux性能工具,但在面对Linux性能问题时,还是束手无策?实际上,性能分析和优化始终是大多数软件工程师的一个痛点。但是,面对难题,我们真的就无解了吗?
固然,性能问题的复杂性增加了学习难度,但这并不能成为我们进阶路上的“拦路虎”。在我看来,大多数人对性能问题“投降”,原因可能只有两个。
一个是你没找到有效的方法学原理,一听到“系统”、“底层”这些词就发怵,觉得东西太难,自己一定学不会,自然也就无法深入学下去,从而不能建立起性能的全局观。
再一个就是,你看到性能问题的根源太复杂,既不懂怎么去分析,也不能抽丝剥茧找到瓶颈。
你可能会想,反正程序出了问题,上网查就是了,用别人的方法,囫囵吞枣地多试几次,有可能就解决了。于是,你懒得深究这些方法为啥有效,更不知道为什么,很多方法在别人的环境有效,到你这儿就不行了。
所以,相同的错误重复在犯,相同的状况也是重复出现。
其实,性能问题并没有你想像得那么难,只要你理解了应用程序和系统的少数几个基本原理,再进行大量的实战练习,建立起整体性能的全局观,大多数性能问题的优化就会水到渠成。
我见过很多工程师,在分析应用程序所使用的第三方组件的性能时,并不熟悉这些组件所用的编程语言,却依然可以分析出线上问题的根源,并能通过一些方法进行优化,比如修改应用程序对它们的调用逻辑,或者调整组件的配置选项等。
还是那句话,你不需要了解每个组件的所有实现细节,只要能理解它们最基本的工作原理和协作方式,你也可以做到。
性能指标是什么?
学习性能优化的第一步,一定是了解“性能指标”这个概念。
当看到性能指标时,你会首先想到什么呢?我相信“高并发”和“响应快”一定是最先出现在你脑海里的两个词,而它们也正对应着性能优化的两个核心指标——“吞吐”和“延时”。这两个指标是从应用负载的视角来考察性能,直接影响了产品终端的用户体验。跟它们对应的,是从系统资源的视角出发的指标,比如资源使用率、饱和度等。

我们知道,随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解它们,从而更高效地利用系统资源处理更多的请求。这包含了一系列的步骤,比如下面这六个步骤。
- 选择指标评估应用程序和系统的性能;
- 为应用程序和系统设置性能目标;
- 进行性能基准测试;
- 性能分析定位瓶颈;
- 优化系统和应用程序;
- 性能监控和告警。
了解了这些性能相关的基本指标和核心步骤后,该怎么学呢?接下来,我来说说要学好Linux 性能优化的几个重要问题。
学这个专栏需要什么基础
首先你要明白,我们这个专栏的核心是性能的分析和优化,而不是最基本的Linux操作系统的使用方法。
因而,我希望你最好用过Ubuntu或其他Linux操作系统,然后要具备一些编程基础,比如:
- 了解Linux常用命令的使用方法;
- 知道怎么安装和管理软件包;
- 知道怎么通过编程语言开发应用程序等。
这样,在我讲性能时,你就更容易理解性能背后的原理,特别是在结合专栏里的案例实践后,对性能分析能有更直观的体会。
这个专栏不会像教科书那样,详细教你操作系统、算法原理、网络协议乃至各种编程语言的全部细节,但一些重要的系统原理还是必不可少的。我还会用实际案例一步步教你,贯穿从应用程序到操作系统的各个组件。
学习的重点是什么?
想要学习好性能分析和优化,建立整体系统性能的全局观是最核心的话题。因而,
- 理解最基本的几个系统知识原理;
- 掌握必要的性能工具;
- 通过实际的场景演练,贯穿不同的组件。
这三点,就是我们学习的重中之重。我会在专栏的每篇文章中,针对不同场景,把这三个方面给你讲清楚,你也一定要花时间和心思来消化它们。
其实说到性能工具,就不得不提性能领域的大师布伦丹·格雷格(Brendan Gregg)。他不仅是动态追踪工具DTrace的作者,还开发了许许多多的性能工具。我相信你一定见过他所描绘的Linux性能工具图谱:
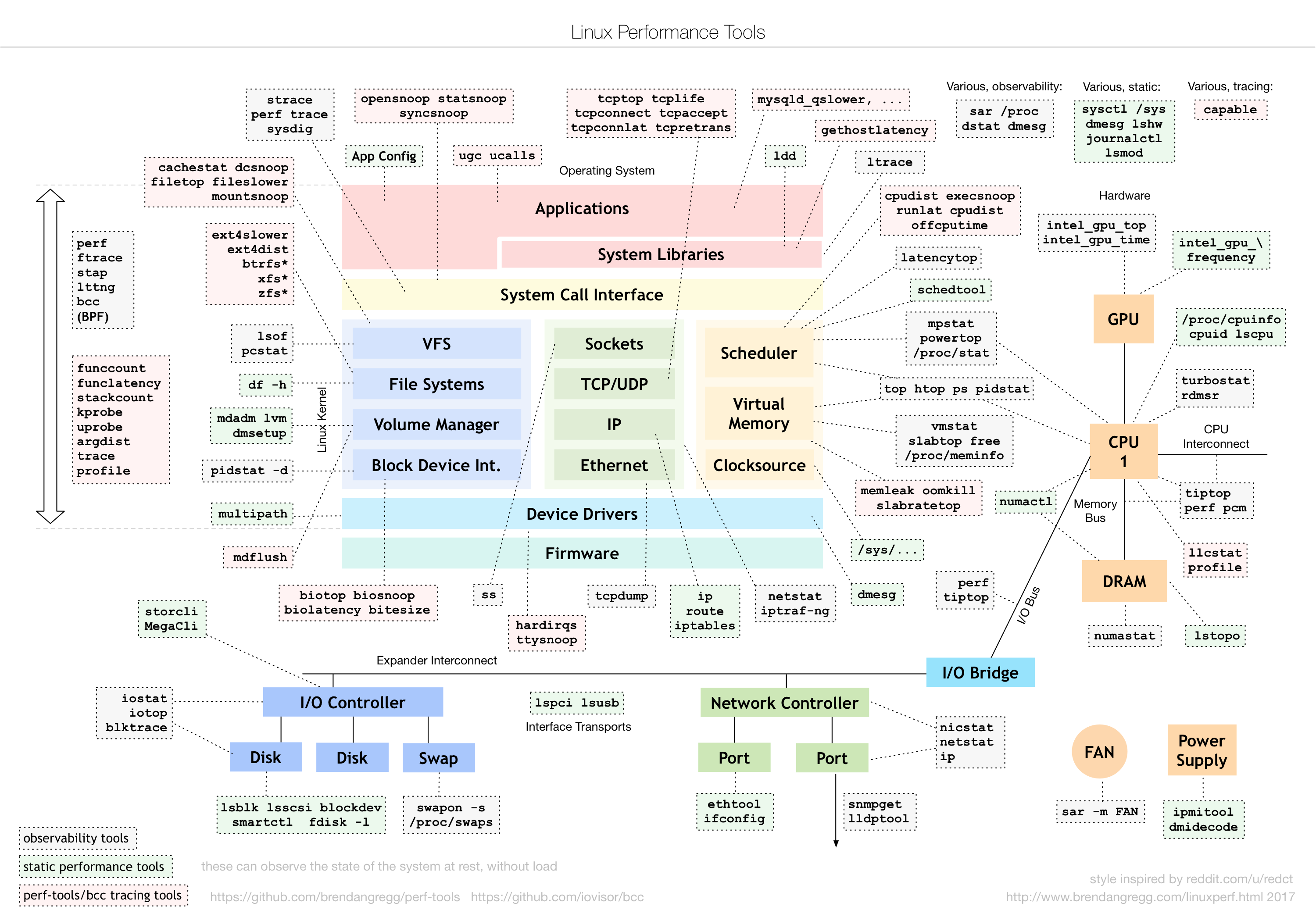
这个图是Linux性能分析最重要的参考资料之一,它告诉你,在Linux不同子系统出现性能问题后,应该用什么样的工具来观测和分析。
比如,当遇到I/O性能问题时,可以参考图片最下方的I/O子系统,使用iostat、iotop、blktrace等工具分析磁盘I/O的瓶颈。你可以把这个图保存下来,在需要的时候参考查询。
另外,我还要特别强调一点,就是性能工具的选用。有句话是这么说的,一个正确的选择胜过千百次的努力。虽然夸张了些,但是选用合适的性能工具,确实可以大大简化整个性能优化过程。在什么场景选用什么样的工具、以及怎么学会选择合适工具,都是我想教给你的东西。
但是切记,千万不要把性能工具当成学习的全部。工具只是解决问题的手段,关键在于你的用法。只有真正理解了它们背后的原理,并且结合具体场景,融会贯通系统的不同组件,你才能真正掌握它们。
最后,为了让你对性能有个全面的认识,我画了一张思维导图,里面涵盖了大部分性能分析和优化都会包含的知识,专栏中也基本都会讲到。你可以保存或者打印下来,每学会一部分就标记出来,记录并把握自己的学习进度。
怎么学更高效?
前面我给你讲了Linux性能优化的学习重点,接下来我再跟你分享一下,我的几个学习技巧。掌握这些技巧,可以让你学得更轻松。
技巧一:虽然系统的原理很重要,但在刚开始一定不要试图抓住所有的实现细节。
深陷到系统实现的内部,可能会让你丢掉学习的重点,而且繁杂的实现逻辑,很可能会打退你学习的积极性。所以,我个人观点是一定要适度。
你可以先学会我给你讲的这些系统工作原理,但不要去深究Linux内核是如何做到的,而是要把你的重点放到如何观察和运用这些原理上,比如:
- 有哪些指标可以衡量性能?
- 使用什么样的性能工具来观察指标?
- 导致这些指标变化的因素等。
技巧二:边学边实践,通过大量的案例演习掌握Linux性能的分析和优化。
只有通过在机器上练习,把我讲的知识和案例自己过一遍,这些东西才能转化成你的。我精心设计这些案例,正是为了让你有更好的学习理解和操作体验。
所以我强烈推荐你去实际运行、分析这些案例,或者用学到的知识去分析你自己的系统,这样你会有更直观的感受,获得更好的学习效果。
技巧三:勤思考,多反思,善总结,多问为什么。
想真正学懂一门知识,最好的方法就是问问题。当你能提出好的问题时,就说明你已经深入了解了它。
你可以随时在留言区给我留言,写下自己的疑问、思考和总结,和我还有其他的学习者一起讨论切磋。你也可以写下自己经历过的性能问题,记录你的分析步骤和优化思路,我们一起互动探讨。
学习之前,你的准备
作为一个包含大量案例实践的课程,我会在每篇文章中,使用一到两台Ubuntu 18.04虚拟机,作为案例运行和分析的环境。如果你只是单纯听音频的讲解,却从不动手实践,学习的效果一定会大打折扣。
所以,你是不是可以准备好一台Linux机器,用于课程案例的实践呢?任意的虚拟机或物理机都可以,并不局限于Ubuntu系统。
思考
今天的内容是我们后续学习的热身准备。从下篇文章开始,我们就要正式进入Linux性能分析和优化了。所以,我想请你来聊一聊,你之前在解决Linux性能问题时,有遇到过什么样的困难或者疑惑吗?或者是之前自己学习Linux性能优化时,有哪些问题吗?参考我今天所讲的内容,你又打算怎么来学这个专栏?
欢迎在留言区和我分享。
我们在上一篇文章中讲了性能测试的概念,肯定会有人觉得,那些概念很重要,怎么能轻易抹杀呢?那么,在今天的文章中,我们就来扒一扒性能场景,看看概念与实际之间的差别。
前面我们说了性能要有场景,也说了性能场景要有基准性能场景、容量性能场景、稳定性性能场景、异常性能场景。在我有限的十几年性能生涯中,从来没有见过有一个性能场景可以超出这几个分类。下面我将对前面说到的概念进行一一对应。
学习性能的人,一定看吐过一张图,现在让你再吐一次。如下:
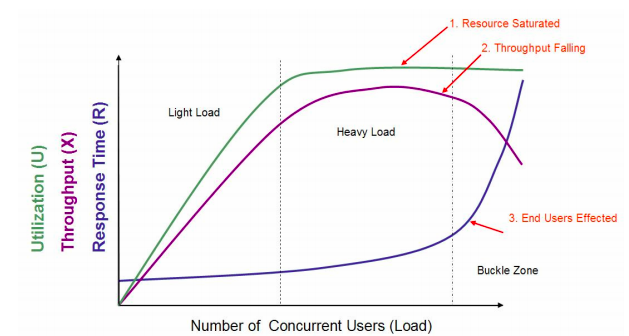
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述。
1. 三条曲线:吞吐量的曲线(紫色)、使用率/用户数曲线(绿色)、响应时间曲线(深蓝色)。
2. 三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)。
3. 两个点:最优并发用户数(The Optimum Number of Concurrent Users)、最大并发用户数(The Maximum Number of Concurrent Users)。
4. 三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)。
我在很多地方,都看到了对这张图的引用。应该说,做为一个示意图,它真的非常经典,的确描述出了一个基本的状态。但是,示意图也只能用来做示意图,在具体的项目中,我们仍然要有自己明确的判断。
我们要知道,这个图中有一些地方可能与实际存在误差。
首先,很多时候,重负载区的资源饱和,和TPS达到最大值之间都不是在同样的并发用户数之下的。比如说,当CPU资源使用率达到100%之后,随着压力的增加,队列慢慢变长,但是由于用户数增加的幅度会超过队列长度,所以TPS仍然会增加,也就是说资源使用率达到饱和之后还有一段时间TPS才会达到上限。
https:// xg.zhihu.com/plugin/45b 01d0d3c7437ea53999dbd1e541ddd?BIZ=ECOMMERCE大部分情况下,响应时间的曲线都不会像图中画得这样陡峭,并且也不一定是在塌陷区突然上升,更可能的是在重负载区突然上升。
另外,吞吐量曲线不一定会出现下降的情况,在有些控制较好的系统中会维持水平。曾经在一个项目中,因为TPS维持水平,并且用户数和响应时间一直都在增加,由于响应时间太快,一直没有超时。我跟我团队那个做压力的兄弟争论了三个小时,我告诉他接着压下去已经没有意义,就是在等超时而已。他倔强地说,由于没有报错,时间还在可控范围,所以要一直加下去。关于这一点争论,我在后续的文章中可能还会提及。
最优并发数这个点,通常只是一种感觉,并没有绝对的数据用来证明。在生产运维的过程中,其实我们大部分人都会更为谨慎,不会定这个点为最优并发,而是更靠前一些。
最大并发数这个点,就完全没有道理了,性能都已经衰减了,最大并发数肯定是在更前的位置呀。这里就涉及到了一个误区,压力工具中的最大用户数或线程数和TPS之间的关系。在具体的项目实施中,有经验的性能测试人员,都会更关心服务端能处理的请求数即TPS,而不是压力工具中的线程数。
这张图没有考虑到锁或线程等配置不合理的场景,而这类场景又比较常见。也就是我们说的,TPS上不去,资源用不上。所以这个图默认了一个前提,只要线程能用得上,资源就会蹭蹭往上涨。
这张图呢,本来只是一个示意,用以说明一些关系。但是后来在性能行业中,有很多没有完全理解此图的人将它做为很有道理的“典范”给一些人讲,从而引起了越来越多的误解。
此图最早的出处是2005年 Quest Software 的一个 PSO Consultant 写的一个白皮书[《Performance Testing Methodology》](http://hosteddocs.ittoolbox.com/questnolg22106java.pdf)。在18页论述了这张图,原文摘录一段如下:
> You can see that as user load increases, response time increases slowly and resource utilization increases almost linearly. This is because the more work you are asking your application to do, the more resources it needs. Once the resource utilization is close to 100 percent, however, an interesting thing happens – response degrades with an exponential curve. This point in the capacity assessment is referred to as the saturation point. The saturation point is the point where all performance criteria are abandoned and utter panic ensues. Your goal in performing a capacity assessment is to ensure that you know where this point is and that you will never reach it. You will tune the system or add additional hardware well before this load occurs.
按照这段描述,这个人只是随着感觉在描述一种现象,除此无它。比如说,The saturation point is the point where all performance criteria are abandoned and utter panic ensues.在我的工作经验中,其实在 saturation point 之前,性能指标就已经可以显示出问题了,并且已经非常 panic 了,而我们之所以接着再加压力是为了让指标显示得更为明显,以便做出正确的判断。而调优实际上是控制系统在饱和点之前,这里有一个水位的问题,控制容量到什么样的水位才是性能测试与分析的目标。
我们简化出另一个图形,以说明更直接一点的关系。如下所示:
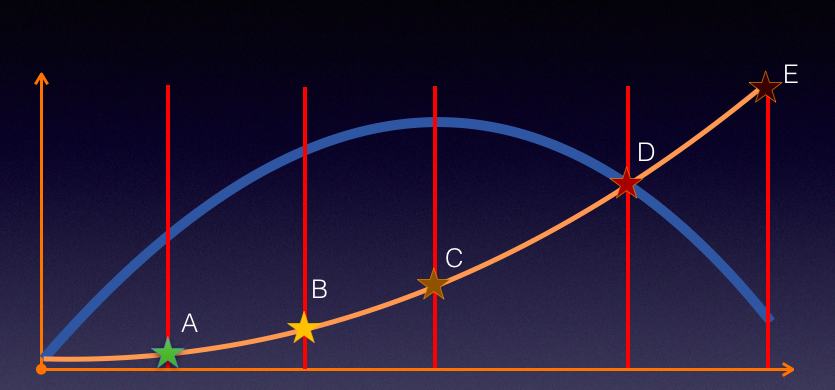
上图中蓝线表示TPS,黄色表示响应时间。
在TPS增加的过程中,响应时间一开始会处在较低的状态,也就是在A点之前。接着响应时间开始有些增加,直到业务可以承受的时间点B,这时 TPS 仍然有增长的空间。再接着增加压力,达到C点时,达到最大 TPS。我们再接着增加压力,响应时间接着增加,但 TPS 会有下降(请注意,这里并不是必然的,有些系统在队列上处理得很好,会保持稳定的 TPS ,然后多出来的请求都被友好拒绝)。
最后,响应时间过长,达到了超时的程度。
在我的工作中,这样的逻辑关系更符合真实的场景。我不希望在这个关系中描述资源的情况,因为会让人感觉太乱了。
为什么要把上面描述得如此精细?这是有些人将第一张图中的 Light load 对应为性能测试, Heavy Load 对应为负载测试,Buckle Zone 对应为压力测试……还有很多的对应关系。
事实上,这是不合理的。
下面我将用场景的定义来替换这些混乱的概念。

为什么我要如此划分?因为在具体场景的操作层面,只有场景中的配置才是具体可操作的。而通常大家认为的性能测试、负载测试、压力测试在操作的层面,只有压力工具中线程数的区别,其他的都在资源分析的层面,而分析在很多人的眼中,都不算测试。
拿配置测试和递增测试举例吧。
在性能中,我们有非常多的配置,像JVM参数、OS参数、DB参数、网络参数、容器参数等等。如果我们把测试这些配置参数,称为”配置测试“,我觉得未免过于狭隘了。因为对于配置参数来说,这只是做一个简单的变更,而性能场景其实没有任何变化呀。配置更改前后,会用同样的性能场景来判断效果,最多再增加一些前端的压力,实际的场景并没有任何变化,所以,我觉得它不配做为一个单独的分类。
再比如递增测试,在性能中,基准性能场景也好,容量性能场景也好,哪个是不需要递增的呢?我知道现在市场上经常有测试工程师,直接就上了几百几千线程做压力(请你不要告诉我这是个正常的场景,鉴于我的精神有限,承受不了这样的压力)。除了秒杀场景,同时上所有线程的场景,我还没有见到过。在一般的性能场景中,递增都是必不可少的过程。同时,递增的过程,也要是连续的,而不是100线程、200线程、300线程这样断开执行场景,这样是不合理的。关于这一点,我们将在很多地方着重强调。所以我觉得递增也不配做一个单独的分类。
其他的概念,就不一一批驳了。其实在性能测试中,在实际的项目实施中,我们并不需要这么多概念,这些杂七杂八的概念也并没有对性能测试领域的发展起到什么推进作用。要说云计算、AI、大数据这些概念,它们本身在引导着一个方向。
而性能测试中被定为“测试”,本身就处在软件生存周期的弱势环节,当前的市场发展也并不好。还被这些概念冲乱了本来应该有的逻辑的思路,实在是得不偿失。
总结
总之,在具体的性能项目中,性能场景是一个非常核心的概念。因为它会包括压力发起策略、业务模型、监控模型、性能数据(性能中的数据,我一直都不把它称之为模型,因为在数据层面,测试并没有做过什么抽象的动作,只是使用)、软硬件环境、分析模型等。
有了清晰的、有逻辑的场景概念之后,在后面的篇幅当中,我们将从场景的各个角度去拆解。在本专栏中,我们将保持理念的连贯性,以示我不变的职业初心。
思考题
如果你理解了今天的内容,不妨说说为什么说现在市场上的概念对性能项目的实施并没有太大的价值?其次,性能场景为什么要连续?而不是断开?
欢迎你在评论区写下你的思考,也欢迎把这篇文章分享给你的朋友或者同事,一起交流一下。
https:// xg.zhihu.com/plugin/45b 01d0d3c7437ea53999dbd1e541ddd?BIZ=ECOMMERCE大家好,日拱一卒,我是梁唐。
今天我们继续麻省理工missing smester,消失的学期的学习。这一次我们继续上一节课的内容,来看看性能分析的部分。
[MIT]计算机科学课堂中学不到的知识 The Missing Semester of Your CS Education(2020)_哔哩哔哩_bilibili
和之前一样,这节课的note质量同样非常高。
note笔记原文
这次的内容相对来说使用的频率会比debug稍微低一些,可能更多的是后端工程师应用得比较多。经常需要查看系统的性能,以及运行情况,方便做出分析以及优化。前端和算法/数据工程师相对来说用得很少。
日拱一卒,欢迎大家打卡一起学习。
性能分析(profiling)
Profile这个单词原本是画像、侧写的意思,这里指的是对计算机的运行情况做一个画像和侧写,用来了解当前系统的状态。
有的时候,可能我们的代码功能是正确的,但是性能上出了问题。比如说耗光了系统所有的CPU或者是内存。在算法课上,我们会学习使用O这个记号来代表程序复杂度的方法。仓促的开发,简陋的优化是万恶之源。你可以参考这篇文章关于仓促优化的说明:http://wiki.c2.com/?PrematureOptimization。
你需要学习一些profiler(侧写工具)以及监控工具。它们可以帮助你理解你程序的哪一个部分消耗了太多时间/资源,这样你就可以迅速锁定问题以及确定优化方案。
计时
和debug的案例一样,在许多场景当中,打印出程序当中两处位置的时间就足够发现问题。这里是Python当中使用time模块的一个例子:
import time, random n = random.randint(1, 10) * 100 # Get current time start = time.time() # Do some work print("Sleeping for {} ms".format(n)) time.sleep(n/1000) # Compute time between start and now print(time.time() - start) # Output # Sleeping for 500 ms # 0.04883 但是,这里有一个问题,执行时间(wall clock time)很容易误导人。因为你的计算机同时还在运行其他进程或者是在等待阻塞/事件。对于工具来说,它需要区分真实时间、用户时间以及系统时间。总体上来说用户时间和系统时间告诉你,你的进程实际占用了多少CPU时间,你可以参考这篇文章获得更多解释:https://stackoverflow.com/questions//what-do-real-user-and-sys-mean-in-the-output-of-time1
- 真实时间 - 从程序开始到结束流失掉的真实时间,包括其他进程的执行时间以及阻塞消耗的时间(例如等待 I/O或网络)
- User - CPU 执行用户代码所花费的时间
- Sys - CPU 执行系统内核代码所花费的时间
举个例子,试着在命令行运行一个获取HTTP请求的命令,并且在命令之前加上time关键字。在网络不好的时候,你可能会得到下面这样的结果。进程花费了2秒钟才运行结束,然而仅仅只有15毫秒的CPU用户时间,以及12毫秒的CPU内核时间,剩余的时间全部都在等待网络。

侧写工具(Profilers)
CPU
大多数时候,当人们提到侧写工具的时候,通常是在指CPU侧写工具。CPU侧写工具有两种:追踪侧写(tracing)和采样侧写(sampling)。
追踪侧写会记录你程序的每一个函数调用,而采样侧写只会周期性的检测你的程序栈(通常是毫秒级)。它们使用这些记录来进行聚合分析,找出程序在哪些事情上花费了时间。关于这个话题,可以参考这篇文章获取更多细节:
https://jvns.ca/blog/2017/12/17/how-do-ruby---python-profilers-work-
大多数编程语言拥有一些命令行侧写工具,可以用来进行代码分析。它们通常会被集成在IDE当中,但这节课上我们只会聚焦在命令行工具上。
在Python当中,我们可以使用cProfile模块来完成每个函数调用的耗时分析。这里有一个简单的例子,它实现了grep命令:
讯享网#!/usr/bin/env python import sys, re def grep(pattern, file): with open(file, 'r') as f: print(file) for i, line in enumerate(f.readlines()): pattern = re.compile(pattern) match = pattern.search(line) if match is not None: print("{}: {}".format(i, line), end="") if __name__ == '__main__': times = int(sys.argv[1]) pattern = sys.argv[2] for i in range(times): for file in sys.argv[3:]: grep(pattern, file)
我们可以使用如下的命令来进行代码分析。通过输出结果,我们可以看到IO消耗了最多的时间,但IO部分通常无法优化。另外我们可以发现,编译正则表达式也非常耗时。但正则表达式只需要编译一次,我们可以把它移动到for循环外来进行优化。
$ python -m cProfile -s tottime grep.py 1000 '^(import|\s*def)[^,]*$' *.py [omitted program output] ncalls tottime percall cumtime percall filename:lineno(function) 8000 0.266 0.000 0.292 0.000 {built-in method io.open} 8000 0.153 0.000 0.894 0.000 grep.py:5(grep) 17000 0.101 0.000 0.101 0.000 {built-in method builtins.print} 8000 0.100 0.000 0.129 0.000 {method 'readlines' of '_io._IOBase' objects} 93000 0.097 0.000 0.111 0.000 re.py:286(_compile) 93000 0.069 0.000 0.069 0.000 {method 'search' of '_sre.SRE_Pattern' objects} 93000 0.030 0.000 0.141 0.000 re.py:231(compile) 17000 0.019 0.000 0.029 0.000 codecs.py:318(decode) 1 0.017 0.017 0.911 0.911 grep.py:3(<module>) [omitted lines] python中的cProfile(以及其他的一些分析器)可以展示每一个函数调用的时间。这些工具运行的时候非常快,并且如果你在代码当中使用了一些第三方库,那么这些库中的内部函数的调用也会被统计进来。
侧写的时候对每行代码的运行时间进行计时会更加符合直觉,这就是line profiler的功能。
比如,接下来这段Python代码会向这门课的官网发起请求,并且解析返回结果,获取当中所有的URL:
讯享网#!/usr/bin/env python import requests from bs4 import BeautifulSoup # 这个装饰器会告诉行分析器 # 我们想要分析这个函数 @profile def get_urls(): response = requests.get('https://missing.csail.mit.edu') s = BeautifulSoup(response.content, 'lxml') urls = [] for url in s.find_all('a'): urls.append(url['href']) if __name__ == '__main__': get_urls()
如果我们使用Python的cProfile来进行侧写,我们会得到超过2500行的输出,即使我们进行排序也很难完全理解。使用line_profiler的话,我们会得到每一行代码运行的时间:
$ kernprof -l -v a.py Wrote profile results to urls.py.lprof Timer unit: 1e-06 s Total time: 0. s File: a.py Function: get_urls at line 5 Line # Hits Time Per Hit % Time Line Contents ============================================================== 5 @profile 6 def get_urls(): 7 1 .0 .0 96.5 response = requests.get('https://missing.csail.mit.edu') 8 1 21559.0 21559.0 3.4 s = BeautifulSoup(response.content, 'lxml') 9 1 2.0 2.0 0.0 urls = [] 10 25 685.0 27.4 0.1 for url in s.find_all('a'): 11 24 33.0 1.4 0.0 urls.append(url['href']) 内存
像是C和C++这样的语言,内存泄漏会导致你程序当中有一块内存始终无法释放。为了更好地解决我们debug内存问题,我们可以使用一些像是Valgrind这样的工具来定位内存泄漏问题。
对于一些垃圾回收语言,比如Python,使用内存侧写器同样非常有用。因为可以帮助我们定位一些一直没有被回收的对象。下面这个例子展示了memory-profiler是如何工作的(注意装饰器和line-profiler类似)
@profile def my_func(): a = [1] * (10 6) b = [2] * (2 * 10 7) del b return a if __name__ == '__main__': my_func() $ python -m memory_profiler example.py Line # Mem usage Increment Line Contents ============================================== 3 @profile 4 5.97 MB 0.00 MB def my_func(): 5 13.61 MB 7.64 MB a = [1] * (10 6) 6 166.20 MB 152.59 MB b = [2] * (2 * 10 7) 7 13.61 MB -152.59 MB del b 8 13.61 MB 0.00 MB return a 事件侧写
在你使用类似strace这样的工具进行debug的时候,你可能会想要忽视特定的一些代码,把它们当做是黑盒进行处理。perf命令通过各种方式对CPU进行抽象,它不会报告时间和内存的消耗,但是他会报告你程序当中的系统事件。比如说,perf会报告低缓存局部性(cache locality),大量的页面错误(page faults)或活锁(livelocks)。下面是关于它的一些简介:
- perf list - 列出可以被 pref 追踪的事件
- perf stat COMMAND ARG1 ARG2 - 收集与某个进程或指令相关的事件
- perf record COMMAND ARG1 ARG2 - 记录命令执行的采样信息并将统计数据储存在perf.data中
- perf report - 格式化并打印 perf.data 中的数据
可视化
对真实程序运行侧写器会得到大量的信息,因为软件当中对象继承关系导致的高度复杂度。人类是视觉动物,对于阅读大量的数字并不擅长,因此很多工具会将数据转化成更容易观察的方式展现。
对于采样侧写来说,常见的用来展示CPU分析数据的方式是火焰图:https://www.brendangregg.com/flamegraphs.html。它会在Y轴上展示函数调用的层次结构,在X轴上显示耗时的比例。火焰图同时还是可交互的,你可以放大特定的部分并查看堆栈信息。
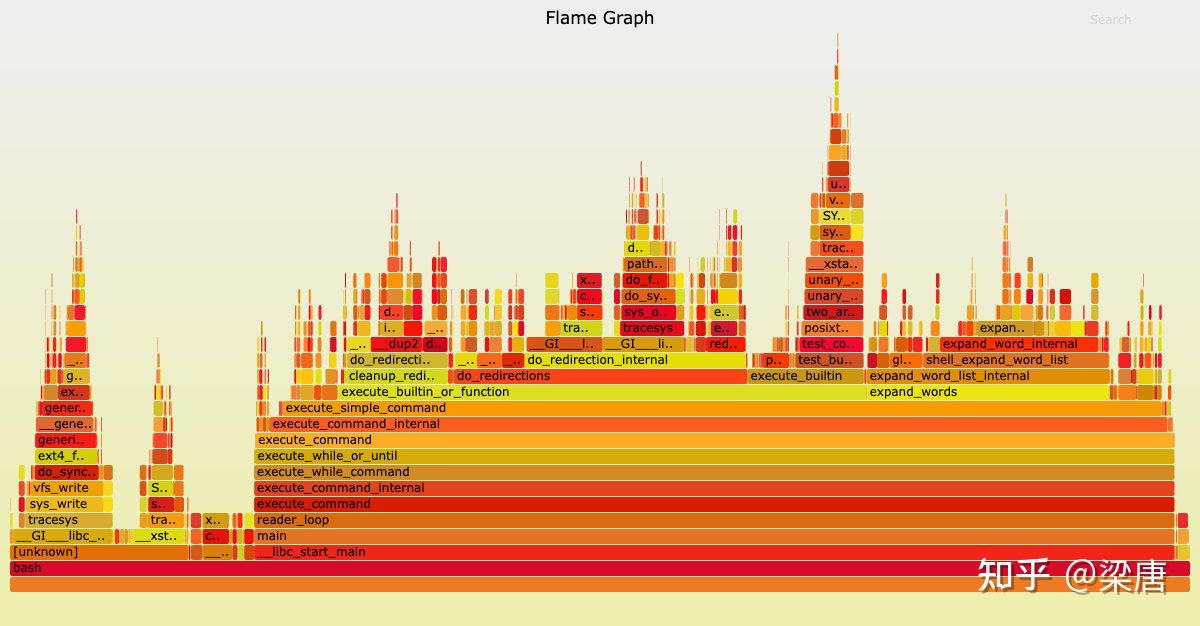
可以点击这个链接进行尝试:https://www.brendangregg.com/FlameGraphs/cpu-bash-flamegraph.svg
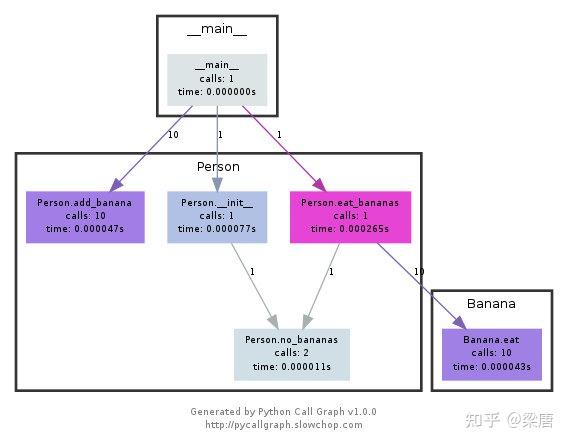
调用图或者是控制流图可以展示子程序之间的关系,它将函数当做是节点,函数之间的调用当做是有向边进行展示。结合侧写信息,比如调用次数、耗时等信息,调用关系图对于阐释程序的流程非常有用。在python当中,你可以使用pycallgraph库来生成它。
资源监控
很多时候,分析程序性能的第一步就是理解它到底消耗了多少资源。程序跑得慢通常是因为资源限制,比如没有足够的内存了,或者是网络连接很慢。
有很多命令行工具可以来展示不同的系统资源,比如CPU使用率、内存使用率、网络、磁盘使用率等等。
- 通用监控 - 最流行的工具要数 htop,了,它是 top的改进版。htop 可以显示当前运行进程的多种统计信息。htop 有很多选项和快捷键,常见的有: 进程排序、 t 显示树状结构和 h 打开或折叠线程。 还可以留意一下 glances ,它的实现类似但是用户界面更好。如果需要合并测量全部的进程, dstat 是也是一个非常好用的工具,它可以实时地计算不同子系统资源的度量数据,例如 I/O、网络、 CPU 利用率、上下文切换等等
- I/O 操作 - iotop 可以显示实时 I/O 占用信息而且可以非常方便地检查某个进程是否正在执行大量的磁盘读写操作
- 磁盘使用 - df 可以显示每个分区的信息,而 du 则可以显示当前目录下每个文件的磁盘使用情况( disk usage)。-h 选项可以使命令以对人类(human)更加友好的格式显示数据;ncdu是一个交互性更好的 du ,它可以让您在不同目录下导航、删除文件和文件夹
- 内存使用 - free 可以显示系统当前空闲的内存。内存也可以使用 htop 这样的工具来显示
- 打开文件 - lsof 可以列出被进程打开的文件信息。 当我们需要查看某个文件是被哪个进程打开的时候,这个命令非常有用
- 网络连接和配置 - ss 能帮助我们监控网络包的收发情况以及网络接口的显示信息。ss 常见的一个使用场景是找到端口被进程占用的信息。如果要显示路由、网络设备和接口信息,您可以使用 ip 命令。注意,netstat 和 ifconfig 这两个命令已经被前面那些工具所代替了
- 网络使用 - nethogs 和 iftop 是非常好的用于对网络占用进行监控的交互式命令行工具
如果你想要测试这些工具,你可以手动使用stress命令来为机器增加负载。
专用工具
有时候,你会想要对黑盒进行性能测试,从而决定应该使用什么工具。像是hypterfine这样的工具可以帮你进行快速测试。比如,我们在shell工具那一课当中推荐使用fd而不是find。我们可以使用hyperfine来对比一下它们。
比如在下面的例子当中,fd运行速度是find的20倍以上。
$ hyperfine --warmup 3 'fd -e jpg' 'find . -iname "*.jpg"' Benchmark #1: fd -e jpg Time (mean ± σ): 51.4 ms ± 2.9 ms [User: 121.0 ms, System: 160.5 ms] Range (min … max): 44.2 ms … 60.1 ms 56 runs Benchmark #2: find . -iname "*.jpg" Time (mean ± σ): 1.126 s ± 0.101 s [User: 141.1 ms, System: 956.1 ms] Range (min … max): 0.975 s … 1.287 s 10 runs Summary 'fd -e jpg' ran 21.89 ± 2.33 times faster than 'find . -iname "*.jpg"' 和debug一样,浏览器也提供了非常好的页面分析工具。让你能够发现时间都消耗在了什么地方(加载、渲染、脚本等等)。可以在使用的浏览器帮助当中查找这部分信息。
练习
- 这里有很多已经实现好的排序算法:https://missing.csail.mit.edu/static/files/sorts.py。使用
cProfile和line_profiler来对比插入排序和快速排序的耗时。每一个算法的瓶颈是多少?使用memory_profiler来检查内存使用,为什么插入排序更优?然后再查看快排的inplace版本。挑战:使用perf来查看每个算法循环次数以及缓存命中和和没命中的情况 - 这里有一些计算斐波那契数列的Python代码,对计算每个数字定义了一个函数:
#!/usr/bin/env python def fib0(): return 0 def fib1(): return 1 s = """def fib{}(): return fib{}() + fib{}()""" if __name__ == '__main__': for n in range(2, 10): exec(s.format(n, n-1, n-2)) # from functools import lru_cache # for n in range(10): # exec("fib{} = lru_cache(1)(fib{})".format(n, n)) print(eval("fib9()")) 把代码拷贝进入文件,然后执行它。首先安装依赖pycallgraph和graphviz(如果你能运行dot,说明你已经有了GraphViz)。使用pycallgraph graphviz -- https://www.zhihu.com/topic//fib.py命令运行代码,查看pycallgraph.png文件。fib0被调用了多少次?我们可以通过记忆化对算法进行优化。放开注释的代码,重新生成图片,现在,对于每个fibN函数,分别调用了多少次?
- 想要使用的端口被占用是一个非常常见的问题。现在让我们看看怎么样发现是被什么程序占用了。首先,运行
python -m http.server 4444来启动一个mini web服务器监听端口4444。在另外一个终端当中运行lsof | grep LISTEN打印出所有正在监听的进程以及端口。找到监听4444的进程id,并使用kill干掉 - 限制进程能够使用的资源也是一个很好的办法。试着使用
stree -c 3并使用htop对CPU消耗进行可视化。执行taskset --cpu-list 0,2 stress -c 3来进行可视化。stress占用了3个CPU吗?为什么没有?阅读一下man taskset来找答案。挑战:使用cgroups命令来实现同样的效果,试着使用stress -m来限制内存消耗 - (进阶)
curl ipinfo.io命令发起一个HTTP请求并获取你的公共IP。打开Wireshark:https://www.wireshark.org/尝试抓取curl发起的请求和受到的结果。(提示:可以使用http进行过滤只显示HTTP包)
robot:软件工具专栏概述及目录
获取性能数据
在chrome上运行程序,右键-检查,在Console一栏找到Performance,运行程序,执行操作,点击record,结束的时候再点击record,获得阶段性的性能数据。
性能分析
Task
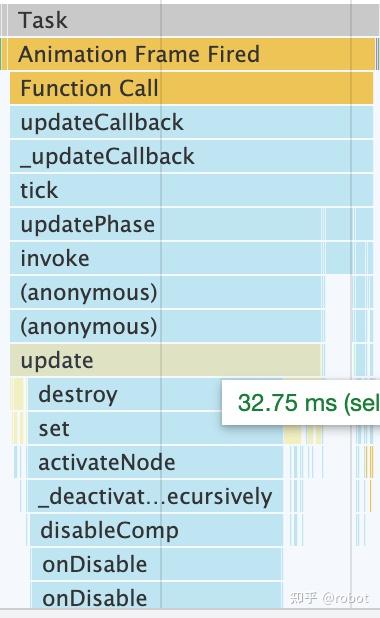
- Animation Frame Fired
- Function Call
- updateCallback
- _updateCallback
- tick
- updatePhase
- invoke
- (anonymous)
- update
- destroy
- set
- activateNode
- _deactivat...ecursively
- disableComp
- onDisable
- OnDisable
Summary-点击Task下的一栏
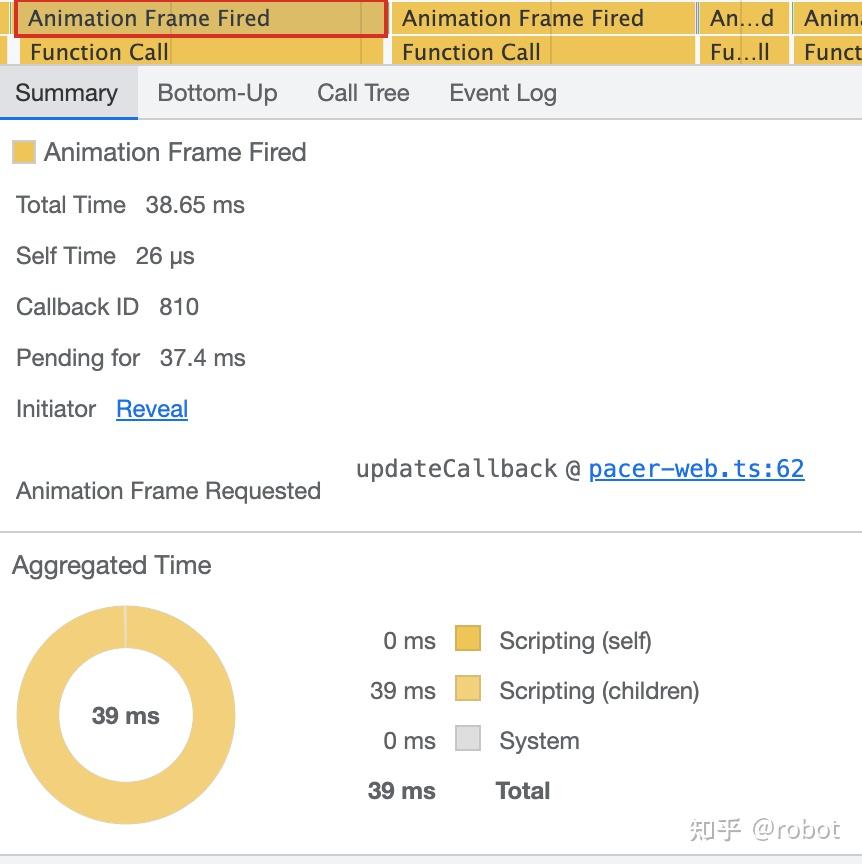
- Total Time 38.65ms
- Self Time 26us
- Callback ID 810
- Pending for 37.4ms
- Initiator Reveal
- Animation Frame Requested --updateCallback @pacer-web.ts:62
- Aggregated Time 39ms
- Scripting(self) 0ms
- Scripting(children) 39ms
- System 0ms
- Total 39ms
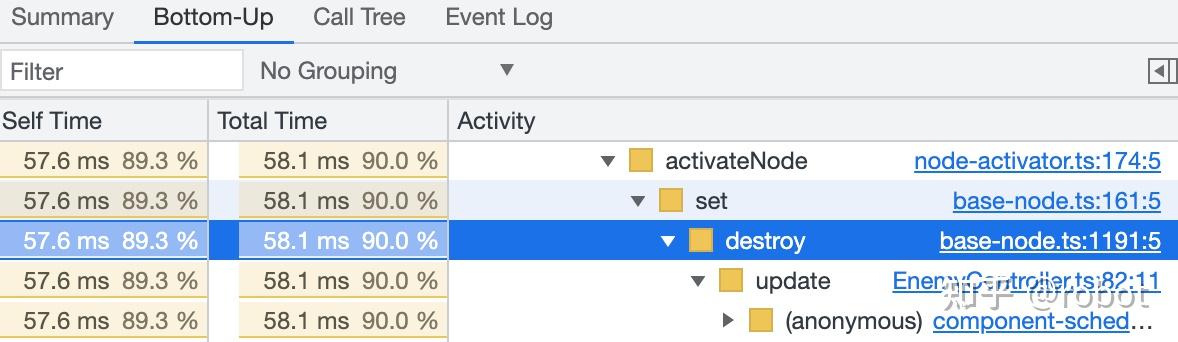
Bottom-Up能看到具体某个函数的执行时间
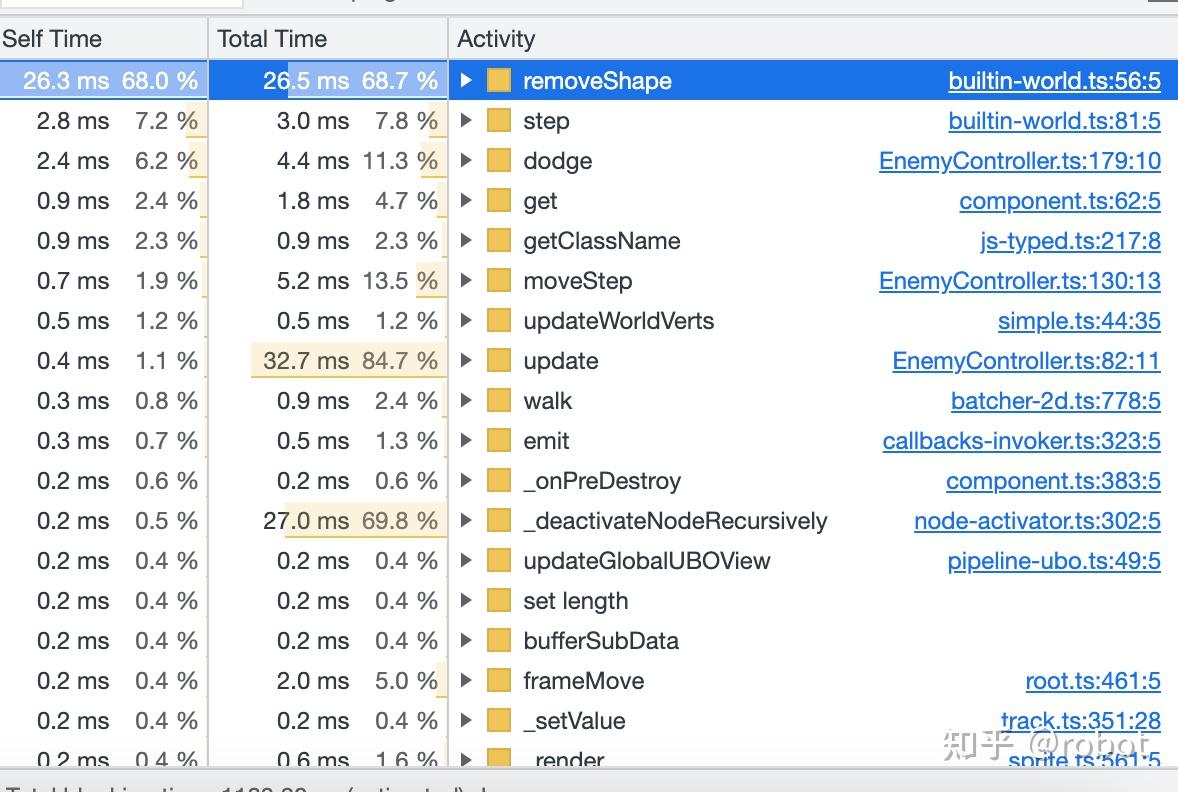
- Self Time 26.3ms 68.0%
- Total Time 26.5ms 68.7%
- Activity-removeShape builtin-world.ts:56:5
Call Free-Task里面选取的任务函数的堆栈数据

EventLog-没看到和上面的区别
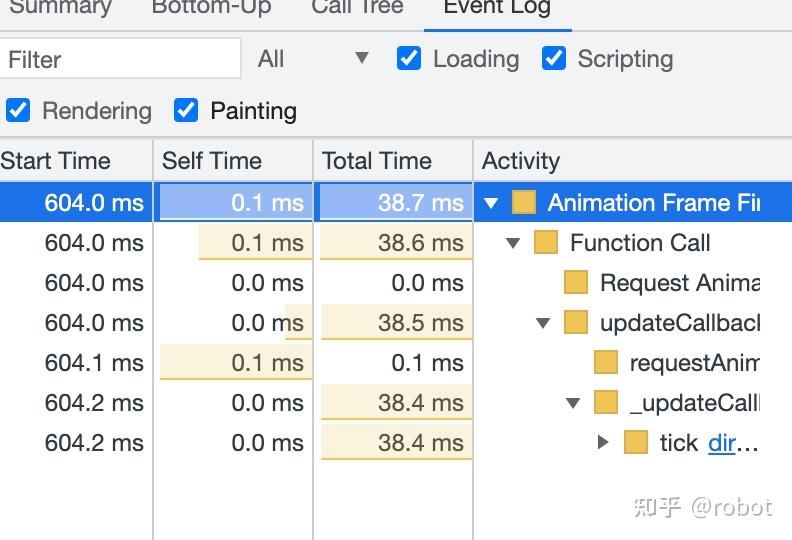
选取异常帧-在时间序列里可以看到所有帧的游戏截图,找到fps异常的帧进行分析。

异常帧选取Task提示Warning Long task took 68.34ms.
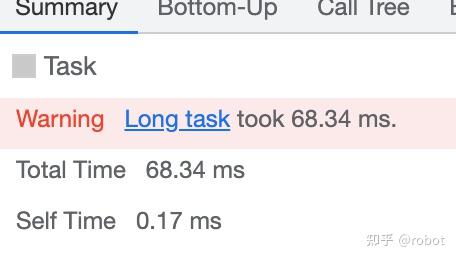
定位到具体某个函数destroy耗时58.1ms
"Animation Frame Fired" 是一个通常出现在 Web 开发中的信息,表示浏览器已经执行了一个动画帧(animation frame)。
在 Web 开发中,动画通常是通过使用 JavaScript 和 CSS 来实现的。浏览器使用 requestAnimationFrame API 来调度和执行这些动画,requestAnimationFrame API 可以让浏览器根据屏幕的刷新频率来优化动画的性能,以确保它们能够平滑地运行。
当一个动画帧被执行时,浏览器会触发 "Animation Frame Fired" 这个信息,通常是作为调试和性能分析的一部分。如果动画帧的执行时间过长,就可能会导致动画的卡顿或者影响其他代码的执行。因此,通过监视 "Animation Frame Fired" 这个信息,可以更好地优化和调整动画的性能。
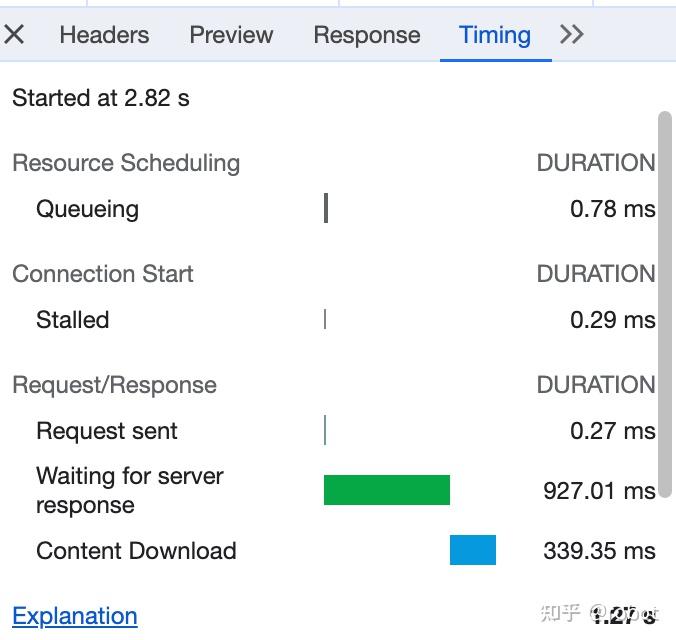
Timing有细分的服务器请求返回时间以及数据下载时间

网页卡顿
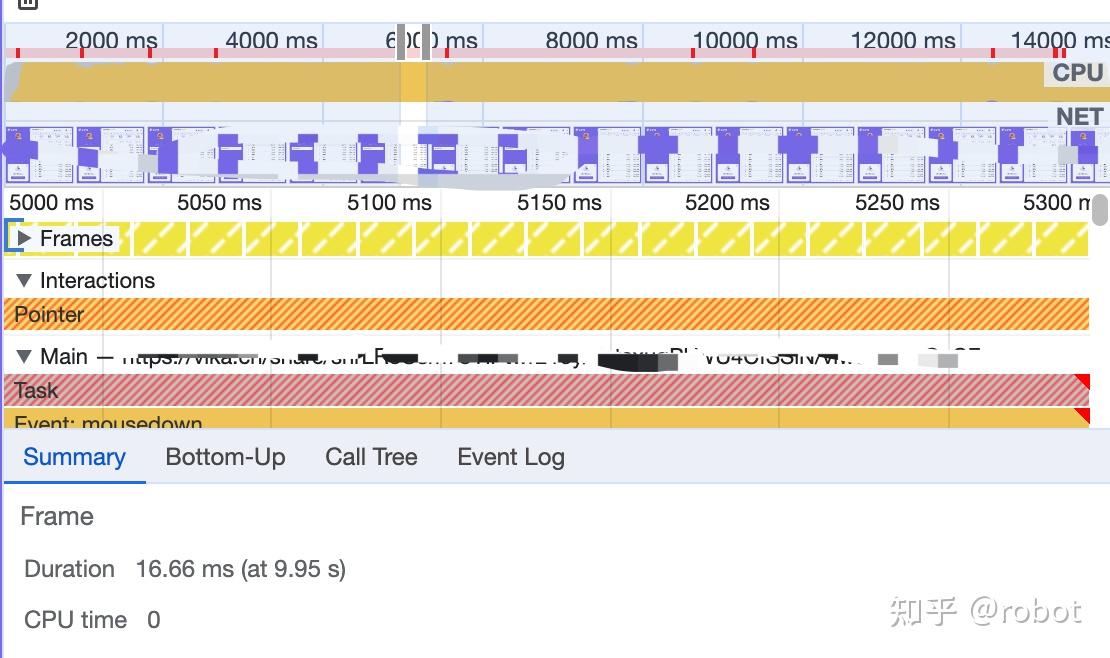
现象:鼠标无法拖动,Bottom-Up为空,对比没明显区别,点开Frame后Bottom-Up不为空,定位到具体的函数以及堆栈。
异常:9.95s
正常:2.88s
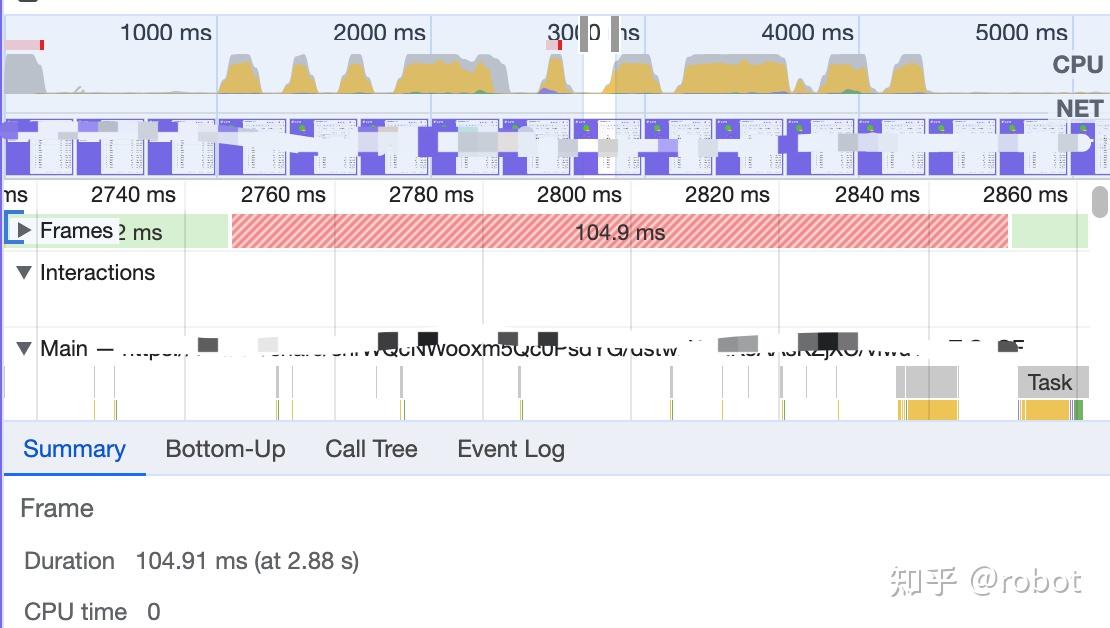
卡顿原因是是每帧某个函数x调用耗时太长,调用频率越多,耗时越长,用缓存的方式可以优化性能。
在调用前获取缓存,没有的话,调用函数获取数据,判断是否需要存缓存,需要的话存缓存。 缓存何时更新?不更新。。常用操作
- 网页断开链接:network-offline
- 网页打开所有请求先后顺序:network-waterfall-鼠标悬停会有queued at(请求开始时间)
调试
禁用所有调试

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/4271.html