
今天想学LSTM的情感分类,结果碰到了一系列问题,耽误了很多时间。特此记录!
一.项目来源
二.碰到的问题
1.报错AttributeError: module ‘torchtext.data‘ has no attribute ‘Field‘
解决方法1(在这个方法中没啥用,但是记录一下)
- 在2021年3月5日TorchText 0.9.0更新,一些API调用也发生变化
之前我们调用Field,TabularDataset,Iterator,BucketIterator是通过torchtext.data
import torch import torchtext from torchtext.data import Field,TabularDataset,Iterator,BucketIterator 讯享网
在torchtext0.9环境下,会报AttributeError: module ‘torchtext.data’ has no attribute ‘Field’
- 新的API调用代码如下(示例):
讯享网import torch import torchtext from torchtext.legacy.data import Field,TabularDataset,Iterator,BucketIterator
解决方法2(有用的)
因为这个项目是2020年,所以我把torchtext的版本往后退了。

- 先卸载原来的torchtext。
pip uninstall torchtext - 下载0.6.0版本的
讯享网pip install torchtext==0.6.0
2.Can’t find model ‘en’
pip install 存放位置/en_core_web_sm-3.0.0.tar.gz 同时需要下载spacy
讯享网pip install spacy==3.0.0
注意:spacy的版本要与en_core_web_sm版本要相同!!!spacy的版本要与en_core_web_sm版本要相同!!!spacy的版本要与en_core_web_sm版本要相同!!!重要的抒情说三遍!!!
3.torchtext 下载 IMDB 数据集时出现错误
import torch from torch import nn, optim from torchtext import data, datasets TEXT = data.Field(tokenize='spacy',tokenizer_language='en_core_web_sm') LABEL = data.LabelField(dtype=torch.float) train_data, test_data = datasets.IMDB.splits(TEXT, LABEL) print('Number of training examples:', len(train_data)) print('Number of testing examples:', len(test_data)) 虽然没报错了,但是数据集没下载下载,加载数据集为空,如下图:

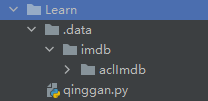
这里的最后一行代码一般会自动下载imdb数据集,但是常常速度很慢很慢,而且如果没下载完成就退出的话,再运行就不会自动下载了。这里我发现下载的数据集会在project里面的.data\imdb\文件夹下。
解决方法是去
aclImdb_v1.tar.gz下载包,用浏览器下会稍微快点,主要是不会丢失连接。下载完成以后,把压缩包放到.data\imdb\文件夹下并且解压。之后再运行以上代码就不会报错了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/41133.html