
从PDF文档中提取信息,是很多类似RAG这样的应用第一步要处理的事情,这里需要做好三件事:
- 提取出来的文本要保持信息完整性,也就是准确性
- 提出的结果需要有附加信息,也就是要保存元数据
- 提取过程要完成自动化,也就是流程化
然而,在我们开始之前,我们需要指定目前不同类型的pdf,更具体地说,是出现最频繁的三种:
- 机器生成的pdf文件:这些pdf文件是在计算机上使用W3C技术(如HTML、CSS和Javascript)或其他软件(如Adobe Acrobat、Word或Typora等MarkDown工具)创建的。这种类型的文件可以包含各种组件,例如图像、文本和链接,这些组件都是可以被选中、搜索和易于编辑的。
- 传统扫描文档:这些PDF文件是通过扫描仪、手机是通过扫描王这样的APP从实物上扫描创建的。这些文件只不过是存储在PDF文件中的图像集合。也就是说,出现在这些图像中的元素,如文本或链接是不能被选择或搜索的。本质上,PDF只是这些图像的容器而已。
- 带OCR的扫描文档:这种类似有点特殊,在扫描文档后,使用光学字符识别(OCR)软件识别文件中每个图像中的文本,将其转换为可搜索和可编辑的文本。然后软件会在图像上添加一个带有实际文本的图层,这样你就可以在浏览文件时选择它作为一个单独的组件。但是有时候我们不能完全信任OCR,因为它还是存在一定几率的识别错误的。
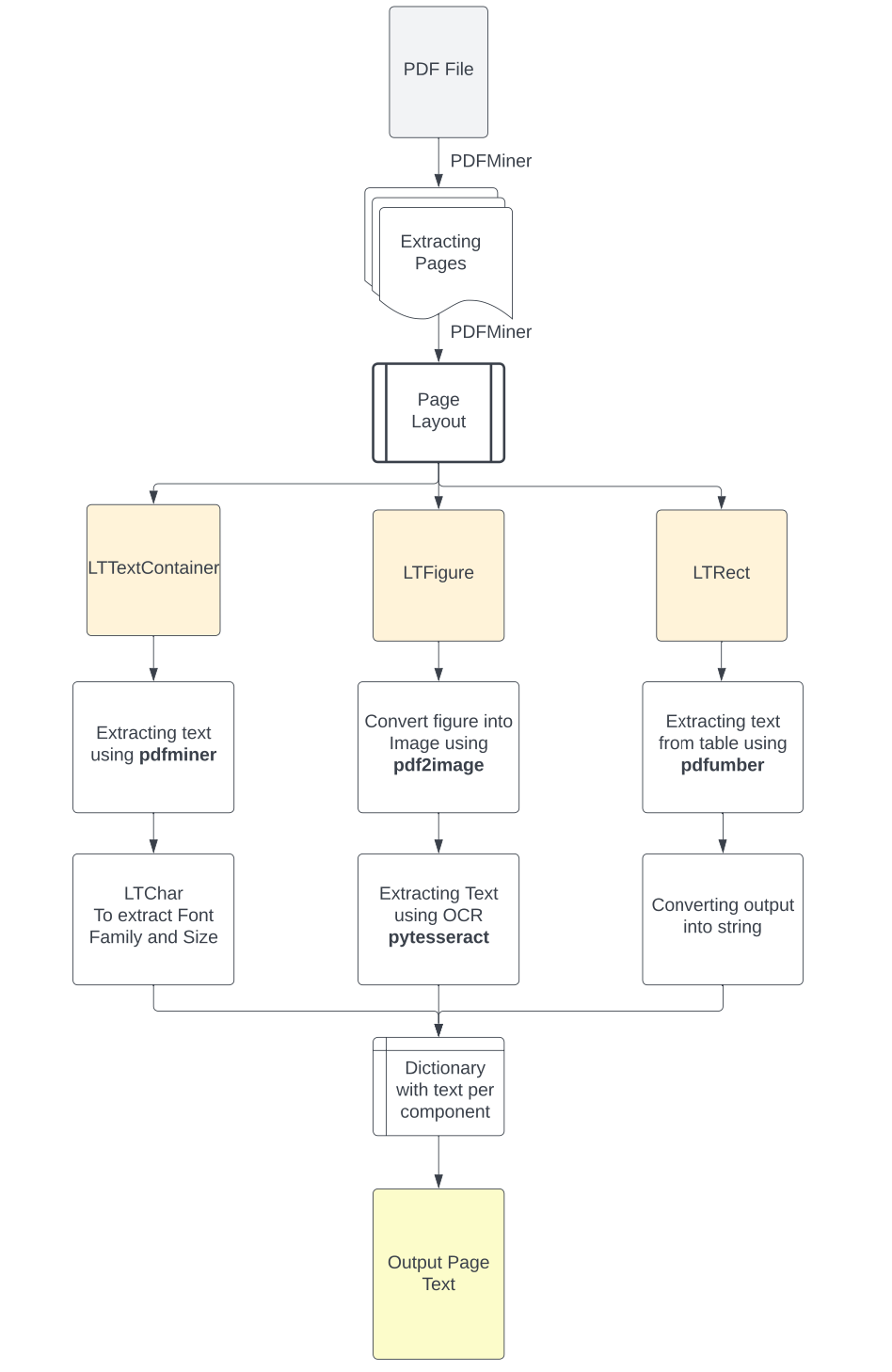
考虑到所有上面说的几种不同类型的PDF文件格式,对PDF的布局进行初步分析以确定每个组件所需的适当工具就很重要了。更具体地说,根据此分析的结果,我们将应用适当的方法从PDF中提取文本,无论是在具有元数据的语料库块中呈现的文本、图像中的文本还是表格中的结构化文本。在没有OCR的扫描文档中,从图像中识别和提取文本将非常繁重。此过程的输出将是一个Python字典(dictionary),其中包含为PDF文件的每个页面提取的信息。该字典(dictionary)中的每个键将表示文档的页码,其对应的值将是一个列表,其中包含以下5个嵌套列表:

- 从语料库中每个文本块提取的文本
- 每个文本块中文本的格式,包括font-family和font-size
- 从页面中的图像上提取的文本
- 以结构化格式从表格中提取的文本
- 页面的完整文本内容

文本提取示意
这样,我们可以实现对每个PDF组件提取的文本的更合乎逻辑的分离,并且有时可以帮助我们更容易地检索通常出现在特定组件中的信息(例如,LOGO中的公司名称、表格中各数据的对应关系)。此外,从文本中提取的元数据,如font-family和font-size,可以用来轻松地识别文本标题或高亮的重要文本,这将帮助我们进一步分离,或者在多个不同的块中对文本进行合并、排序等后续处理。最后,以LLM能够理解的方式保留结构化表信息将显著提高对提取数据中关系的推理质量。然后,这些信息可以在最终输出的时候保留它原本的格式。您可以在下面的图片中看到这种方法的流程图。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/39002.html