
Pandas字符串处理
1.使用方法:先获取Series的str属性,然后在属性上调用函数;
2.只能在字符串列上使用,不能数字列上使用;
3. Dataframe上没有str属性和处理方法
4.Series.str并不是Python原生字符串,而是自己的一套方法,不过大部分和原生str很相似;
内容如下:
1.获取Series的str属性,然后使用各种字符串处理函数
2.使用str的startswith、contains等bool类Series可以做条件查询
3.需要多次str处理的链式操作
4.使用正则表达式的处理
1、分步骤读取数据
import pandas as pd fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv' df=pd.read_csv(fpath) df.head()讯享网
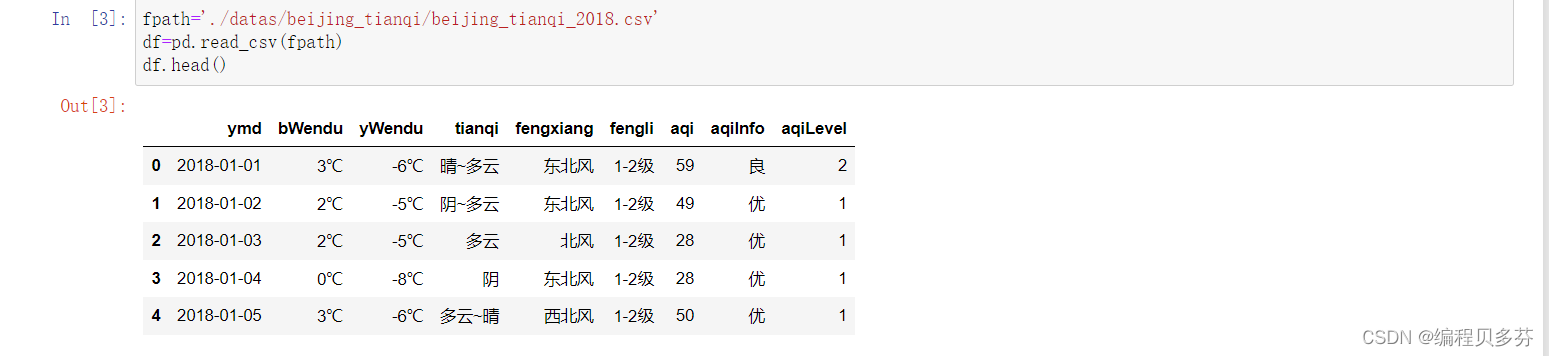
讯享网df.dtypes
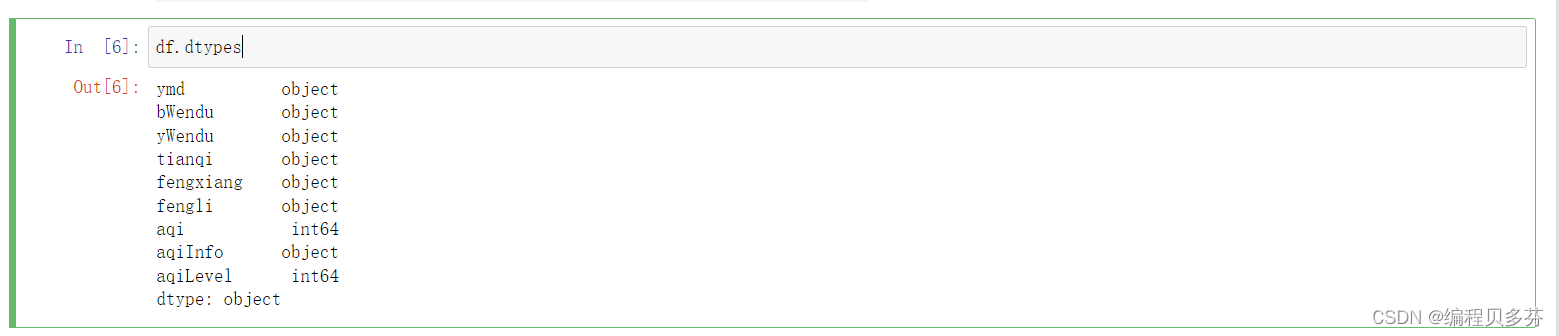
2、获取Series的str属性,使用各种字符串处理函数
获取最高温度的Series的温度列
#获取最高温度的Series的温度列 df['bWendu'].str
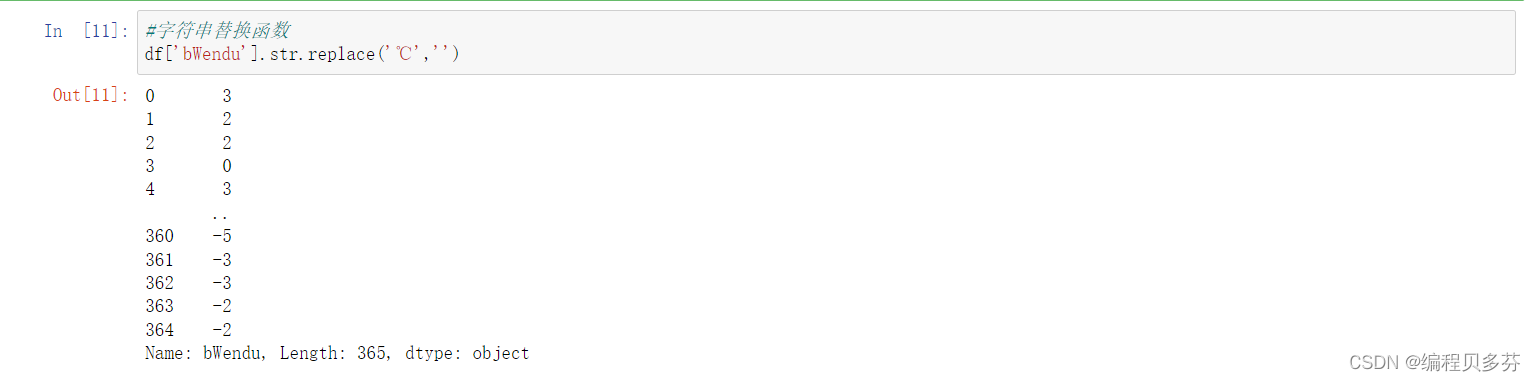
字符串替换函数
讯享网#字符串替换函数 df['bWendu'].str.replace('℃','')
判断是不是数字
#判断是不是数字 df['bWendu'].str.isnumeric()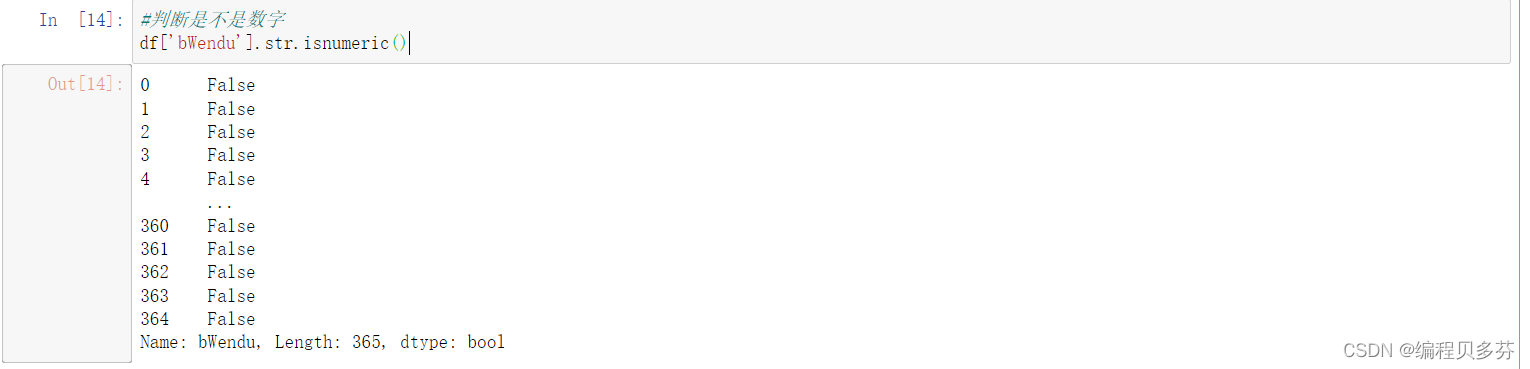
讯享网df['aqi'].str.len() #AttributeError: Can only use .str accessor with string values! len()方法只能用于字符串类型的数据
AttributeError: Can only use .str accessor with string values! len()方法只能用于字符串类型的数据
3、使用str 的startwith、contains等得到bool的Series可以做条件查询
Pandas startswith()是另一种在系列或 DataFrame 中搜索和过滤文本数据的方法。此方法类似于Python的startswith()方法,但参数不同,并且仅适用于Pandas对象。因此,.str必须在每次调用此方法之前加上前缀,以便编译器知道它与默认函数不同。
用法:Series.str.startswith(pat, na=nan)
参数:
pat:要搜索的字符串。 (不接受正则表达式)
na:用于设置序列中的值为NULL时应显示的内容。
返回类型:布尔序列,为True,其中值的开头是传递的字符串。

从ymd这一列挑选出2018-03这类型的数据,返回的是一个Boolean类型
#从ymd这一列挑选出2018-03这类型的数据,返回的是一个Boolean类型 condition=df['ymd'].str.startswith('2018-03') condition
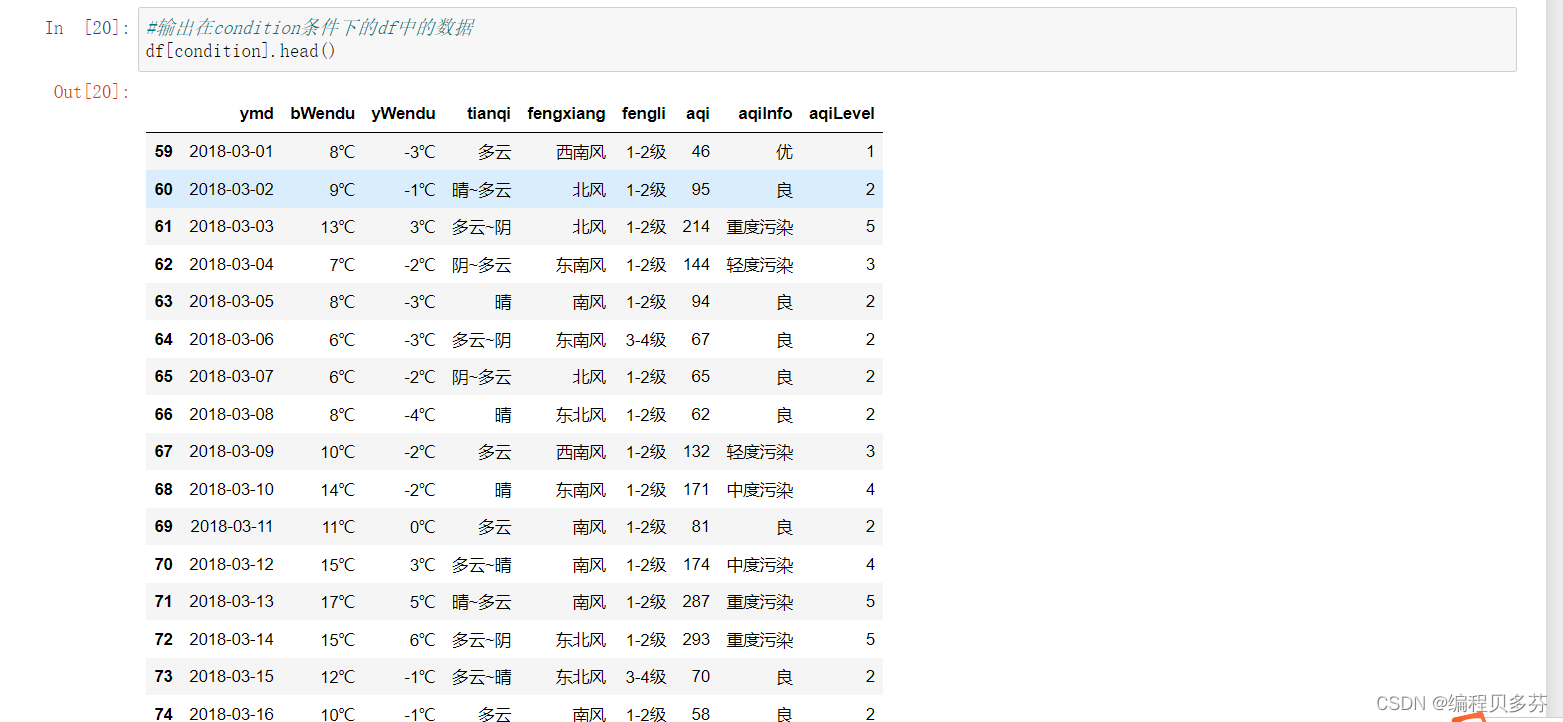
输出在condition条件下的df中的数据
讯享网#输出在condition条件下的df中的数据 df[condition].head()
4、需要多次str处理的链式操作
df['ymd'].str.replace('-','')
问题:直接在Series上面调用方法的话,是否可行?
答:不可行
原因:每次调用函数,都会返回一个新的series
df['ymd'].str.replace('-','').slice(0,6)
'Series' object has no attribute 'slice'---意思就是series不能够直接去调用slice函数,必须经过str调用后才可以使用
讯享网#原因:每次调用函数,都会返回一个新的series df['ymd'].str.replace('-','').slice(0,6) #'Series' object has no attribute 'slice'---意思就是series不能够直接去调用slice函数,必须经过str调用后才可以使用
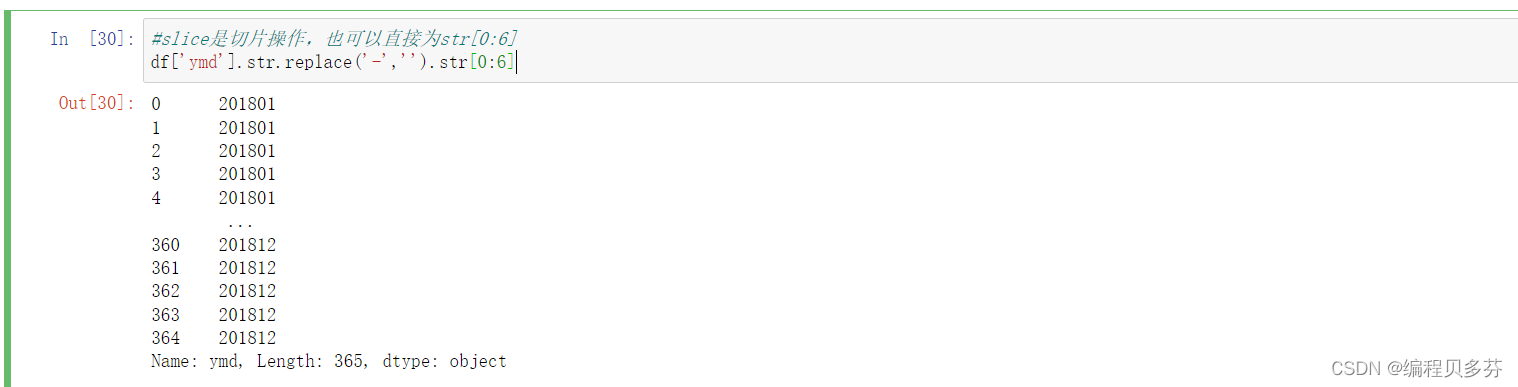
df['ymd'].str.replace('-','').str.slice(0,6)
slice是切片操作,也可以直接为str[0:6]
讯享网#slice是切片操作,也可以直接为str[0:6] df['ymd'].str.replace('-','').str[0:6]
5、使用正则表达式的处理
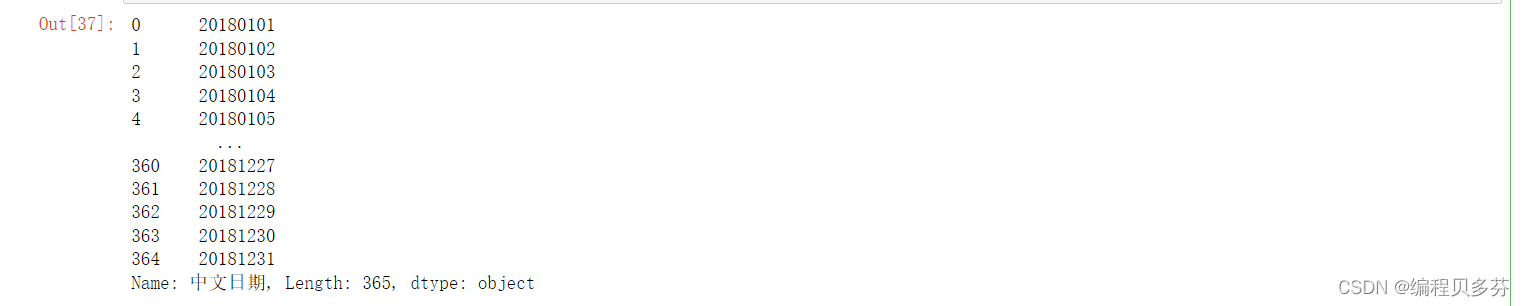
#添加新列 def get_riqi(x): year,month,day=x['ymd'].split('-') return f'{year}年{month}月{day}日' df['中文日期']=df.apply(get_riqi,axis=1) df['中文日期']
new question? -----如何将日期中,年月日三个字去除
方法1:链式replace
讯享网#方法1:链式replace df['中文日期'].str.replace('年','').str.replace('月','').str.replace('日','')
Series.str默认开启了正则表达式模式
方法2:正则表达式替换
#方法2:正则表达式替换 df['中文日期'].str.replace('[年月日]','',regex=True)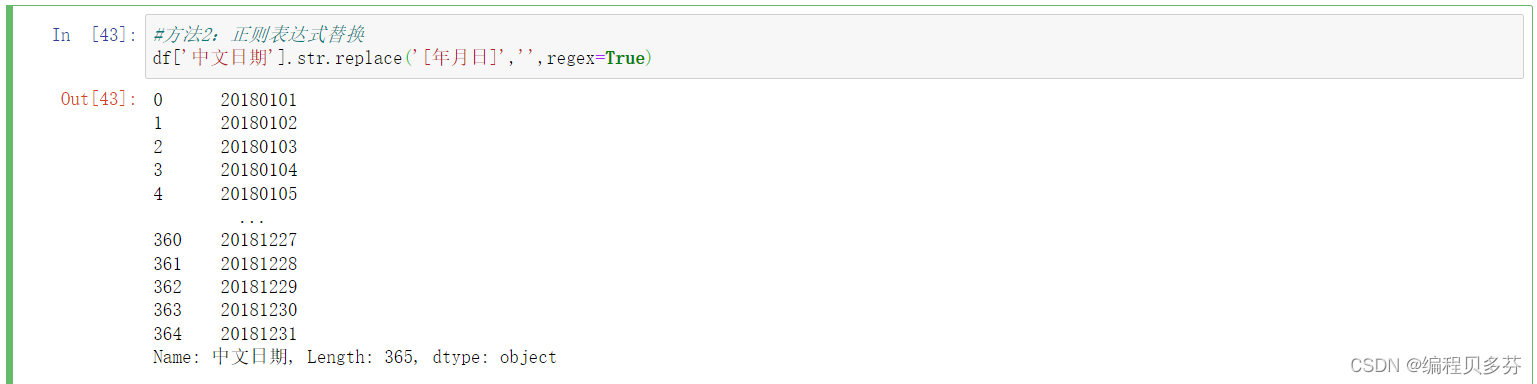
注:
The default value of regex will change from True to False in a future version.
在Pandas未来的版本中,.str.replace() 的regex的默认值将从True变为False
而当regex=True时,单字符正则表达式不会被视为文本字符串
因为我们是针对price中两个单个字符进行操作,因此设置regex=True

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/37785.html