
java基础教学:
注释:
注释的含义:
用来让自己看懂,对代码的一种解释说明
单行注释
//
多行注释
/* */
文档注释( )
/ */
注释的使用细节:
注释内容不会参与编译与运行,仅仅是对代码的解释说明
书写时不要嵌套
关键字:
1.什么是关键字:
被Java赋予了特殊含义的英文单词
2.关键字的特点:
关键字的字母全部小写
关键字有特殊的颜色标记
3.class关键字是什么意思
class表示定义一个类 后面跟随类名
有点像 void int之类的
字面量:
什么是字面量:
数据在程序中的书写格式
字面量的类型:
整数类型

![]()
小数类型
![]()
字符串类型
用双引号引起来的
![]()
字符类型
用单引号引起来的
![]()
布尔类型
![]()
空类型
![]()

制表符
在打印的时候,*把前面的字符串长度补齐到八,或者八的整数倍,最少补一个空格,最多补八个空格
`
讯享网
`
变量:
变量的使用方法:
1.输出打印
数据类型 变量名 =数据值;
`
`
2.参与计算
讯享网
3.修改变量记录的值
4.变量的注意事项
只能存一个值,刚才的**10已经被覆盖
变量名不允许重复定义
一条语句可以定义多个变量
变量在使用前一定要进行赋值
错误示范:
数据类型
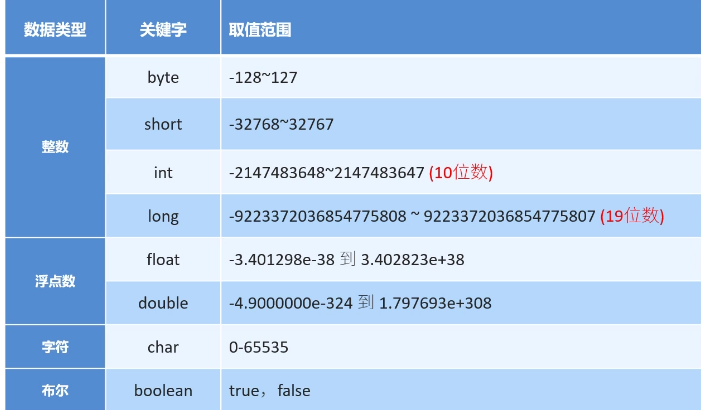
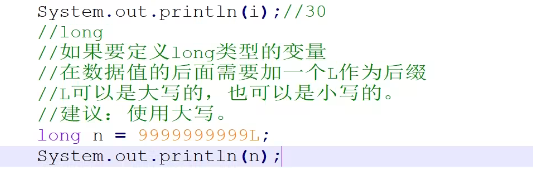
long 后面定义的时候在最后加一个大写的L;
float 后面加一个F做后缀
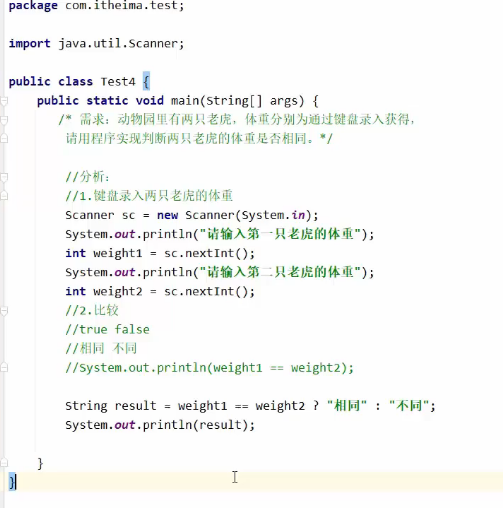
double 后面不用加
text2 输出老师信息 姓名:李宇航 年龄:19 身高:180.1 性别:男 是否单身:是
里面可以放多个
标识符
硬性要求
由数字,字母,下划线(—)和美元符($)组成
不能以数字开头
不能是关键字
区分大小写
软性建议


键盘录入

这个导包有点像C语言里面的题头
Scanner就是C语言里面的scanf
导包,找到Scanner这个类在哪,是固定的
运算符
1.算数运算符:
有小数参加不一定精确
test3位数分离
改动:

运算符
算数运算符:
1.数字相加
数字运算时,数据类型不一样时不能运算,需转换成一样的,才能运算
隐式转换(自动类型提升)
把一个取值范围小的数值,转换成取值范围大的数据


byte short char 三种类型的数据在运算的时候,都会直接提升为int ,然后再进行运算

2.强制转换

2.字符串的相加
当“+”操作中出现字符串时,这个“+”是字符串连接符,而不是算术运算符了,会将前后的数据进行拼接,产生一个新的字符串
“123” + 123
“”
连续+时,从左到右逐个执行
加不加引号是两个东西

![]()




最后一个相当于“3abc2”+1
3.字符相加
当字符加字符或者字符加数字时会先转换成ASCI表中数字进行计算

自增自减运算符

单独使用
++和 - - 不管是前面还是后面单独放在一行结果都是一样的
参与计算
赋值运算符
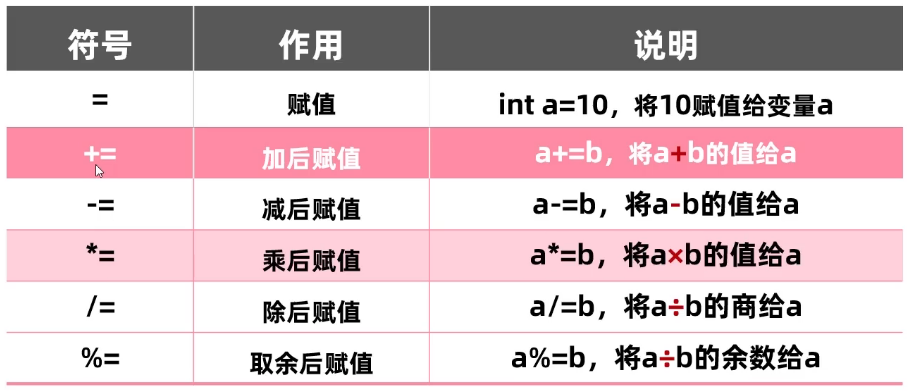
赋值运算符隐含了强制转换类型
关系运算符


逻辑运算符
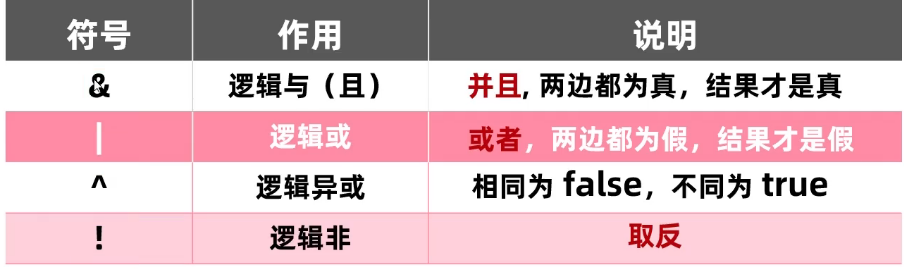
1.两边都是true才输出true
2.两边都是假结果才是假
3.相同为true,不同为false
4.取反
感叹号不要写多次要么写要么不写
短路运算符

短路运算符就有短路逻辑效果
当左边的表达式能确定最终的结果,那么右边就不会参与运算了

三元运算符

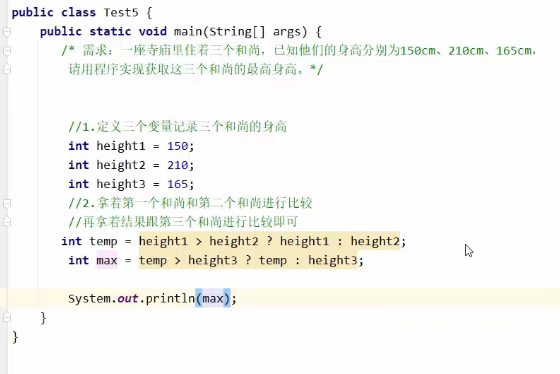
运算符的优先级

小括号优先于所有运算符
顺序结构
从上向下
分支结构
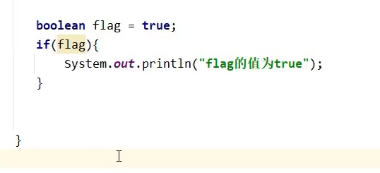
if语句
布尔类型直接把变量放在括号内,不要使用判断符号
switch case



无限循环

数组
1.数组静态初始化
手动指定数组元素,由系统给出元素个数,计算出数组的长度
类型 [] 命名=new 类型 内容
明确具体数值
2.数组动态初始化
手动指定元素长度,由系统给出默认初始化值
类型 [] 命名 = new 类型 [长度]
只明确元素个数,不明确具体数值
3.数组的内存图
4.数组的常见问题
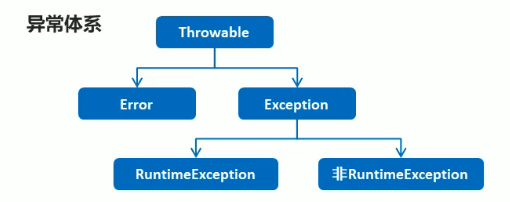
越界
索引最大长度是数组长度减一
5.数组的常见操作
<1>求最值
<2>.随机生成1到100以内的随机数十位,并存入到数组中去
5.random函数的用法
1.导包
2.创建对象
3.获取随机数
其中println变成print时不会换行但是+“ ”,会有一个空格
6.交换数据
数据倒叙:
7.数据打乱
8.数组内存图
1.只要是new出来的就在堆里开辟了一个小空间
2.如果new了多次,那么在堆里有很多小空间,每个小空间中都有各自的数据
3.两个数组指向同一个空间的内存图
4.第二个数组输入的数据会覆盖掉第一个数组中的数据
5.当两个数组指向同一个小空间时,其中一个数组对小空间中的值发生了改变,那么其他数组再次访问时就是修改后的结果了
方法(函数)
1.什么是方法?
程序中最小的执行单元
把重复的代码,具有独立功能的代码抽调到方法中
可以提高代码的复用性
提高代码的可维护性
2.方法的格式
方法的定义
- 最简单的方法定义
- 带参数的方法定义和调用
方法调用时,参数的数量与类型必须与方法定义中的小括号里面的变量一一对应,否则程序将报错,可以是具体的数值,也可以是一个变量
- 带返回值的方法的定义
.1.根据方法的结果,去编写另一段代码

比较长方形的面积
- 注意:
方法不调用就不执行
方法与方法之间是平级关系,补能把一个写到另一个里面
方法的编写程序与执行顺序无关
方法的返回值类型为void,表示没有返回值
没有返回值的方法可以省略return语句不写
如果要编写return,后面不能跟具体的数据
return语句下面,不能编写代码,永远不会执行
3.方法的重载
- 在同一个类中,定义了多个同名的方法,这些同名的方法具有同种功能
- 每个方法具有不同的参数类型或参数个数,这些同名的方法,就构成了重载关系
- 简单记:同一个类中,方法名相同,参数不同的方法,与返回值无关 没基础能参加java吗
- 参数不同:个数不同,类型不同,顺序不同
遍历数组
遍历数组求最大值
拷贝数组内容
4.方法的基本内存原理
在进栈时按照函数类型从上至下,进入栈中却是从下至上,输出时又是从下至上
5.基本数据类型和引用数据类型

- 引用数据类型:
变量中储存的是地址值
引用了其他空间中的数据
6.方法的值传递
基本数据类型存储的是真实的数据
引用数据类型存储的是地址值
引用数据类型可以改变内容
java快捷键:
1.for.i
2.sout
3.ctrl+p
显示方法中的形参
4.ctrl + alt+m
自动抽取方法
API:应用程序编程接口

常用API:
Math
Object
所以我们想要获得实际的内容就要对toString方法重写
equals
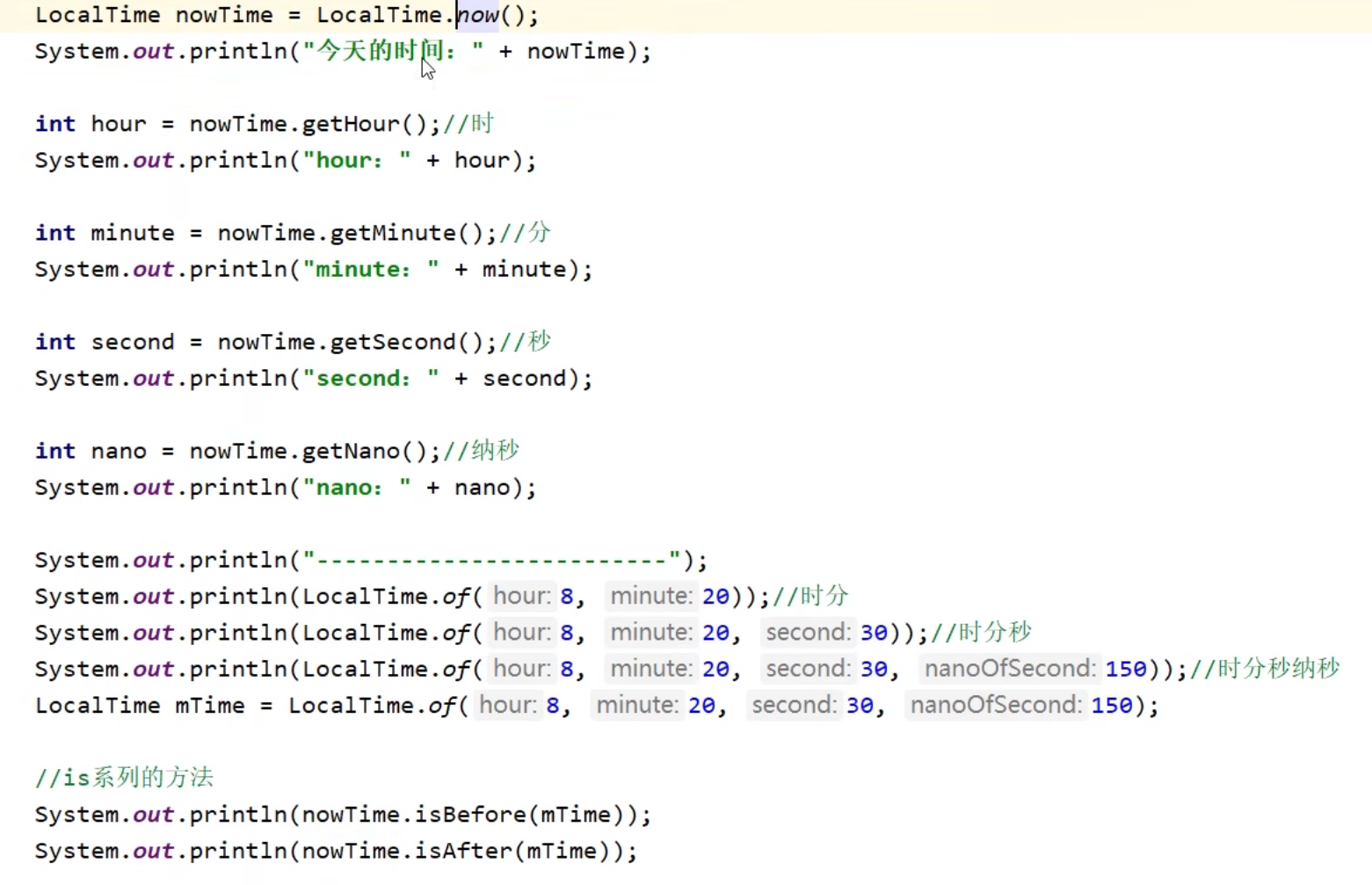
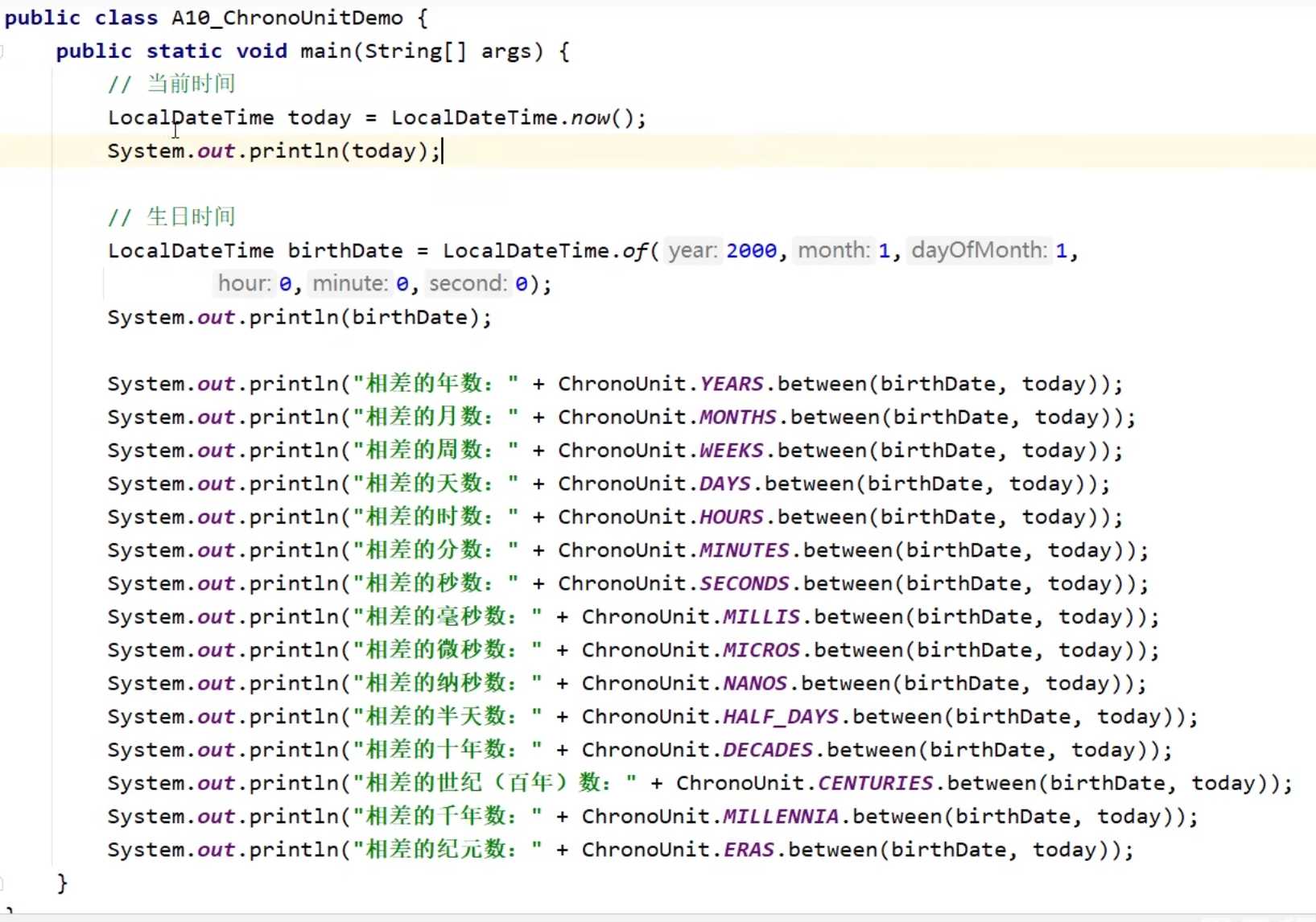
JDK7时间-Date
最开始以英国格林尼治时间为准,太阳直射时就是中午十二点
后来用原子钟计时:利用铯原子的振动频率计算出来的时间,作为世界标准时间(UTC)
震动9,192,631,770次等于一秒
中国时间是世界标准时间+8小时
一秒等于1000毫秒
一毫秒等于1000微秒
一微秒等于1000纳秒
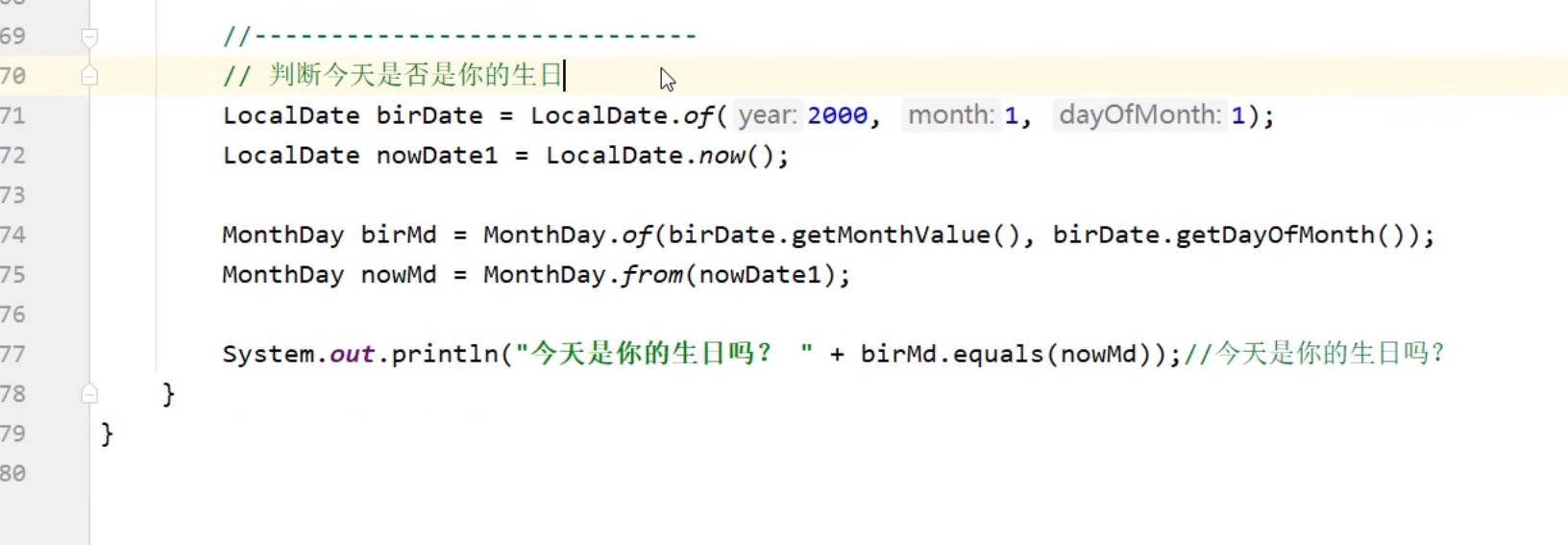
明年的时间:
随机创建两个时间对象,并比较他们的大小
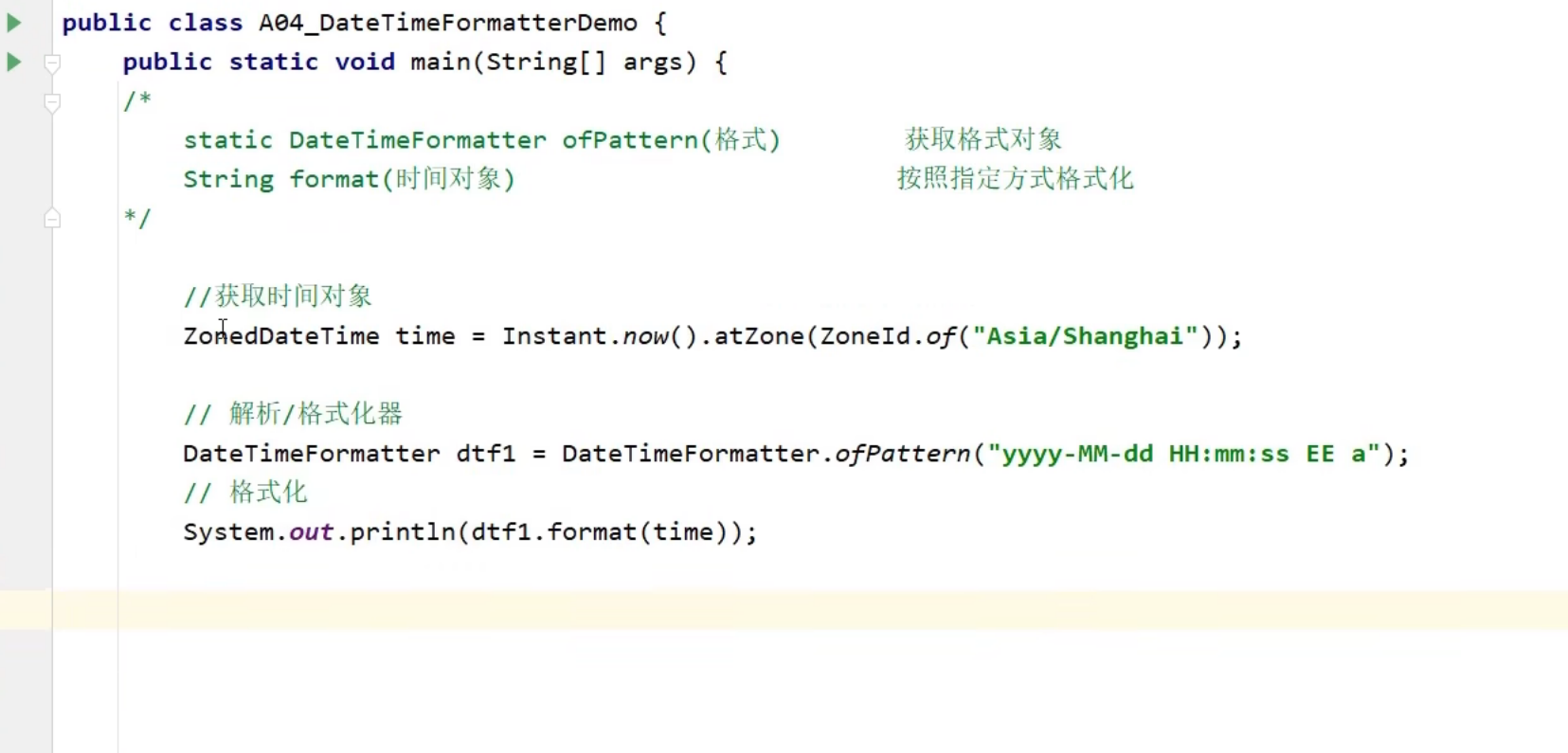
JDK7时间-SimpleDateFormat
作用:将时间格式化,更符合人们的阅读习惯
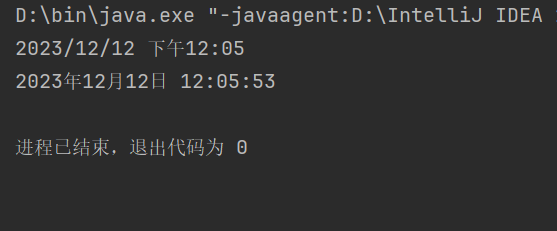
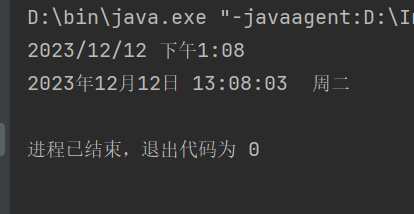
将字符串生日格式化
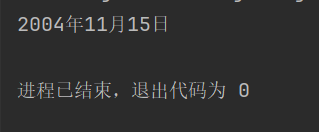
在转换时只能先将其转换为对应格式然后创建date对象之后再将该对象转换为字符串形式
一个简易的计票系统
JDK时间-Calender
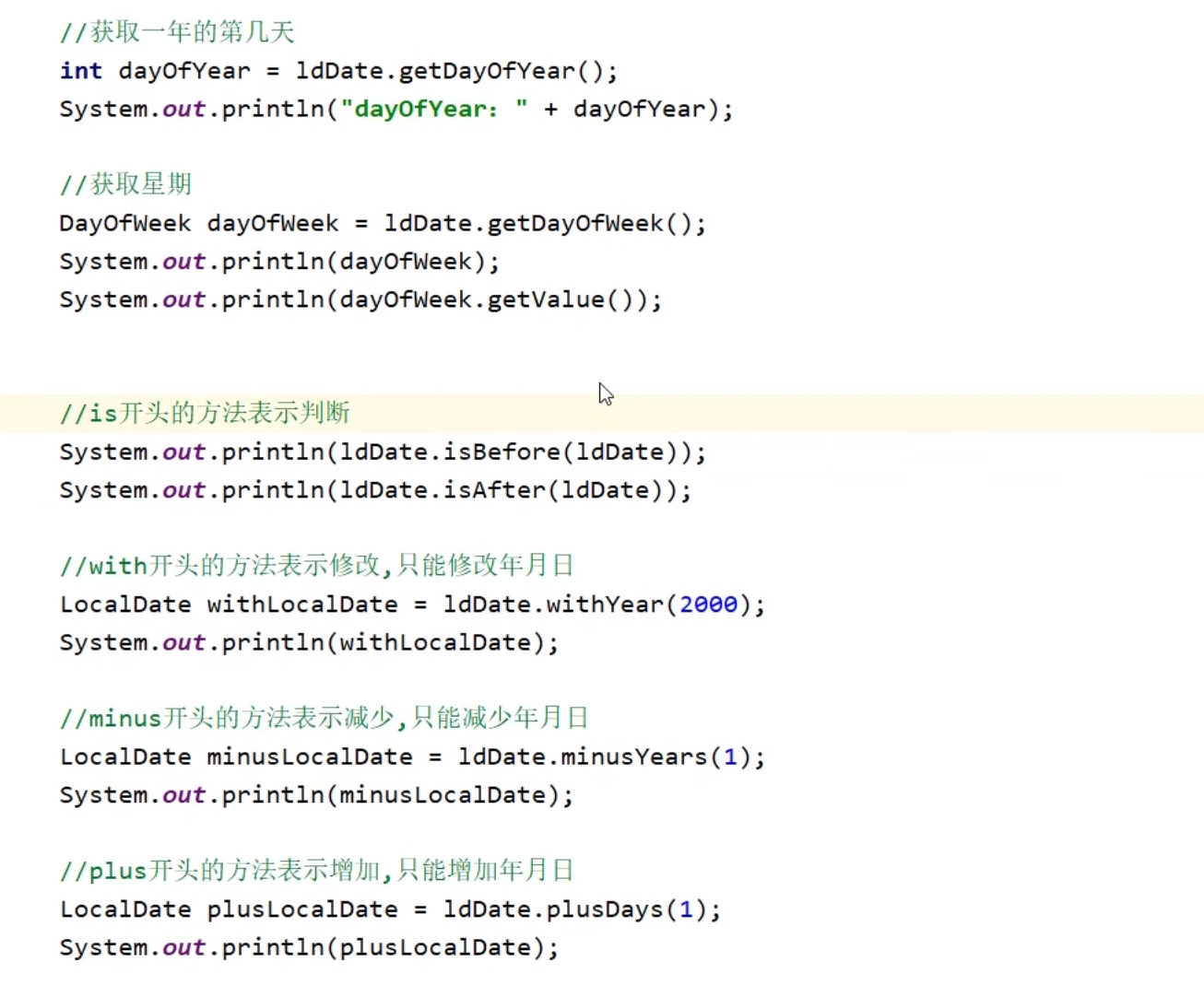
Calender 代表了系统当前时间的日历对象,可以单独修改,获取时间中的年月日
细节1:
Calender是一个抽象类,不能直接创建对象,而是通过一个静态方法获取到子类对象
底层原理:
会根据系统的不同时区来获取不同的日历对象,默认表示当前时间。
会把时间中的纪元,年,月,日,时,分,秒,星期,等等都放到一个数组当中,注意:
因为是数组所以索引从0开始
细节2:
月份:范围0~11,如果获取出来的是0,那么实际是一月
星期:在老外的眼里,星期日是一周中的第一天,以此类推
下面方法是创建一个对象把1970那个时间放入,如果想用现在时间则省去第2,3步,输出结果就是现在时间
get方法:
set方法:
获取时间里面想要的数据
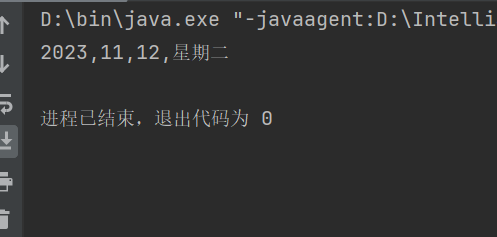
使用set对日历中的日期进行修改
add 格式与set相似在原来的日期上进行加减
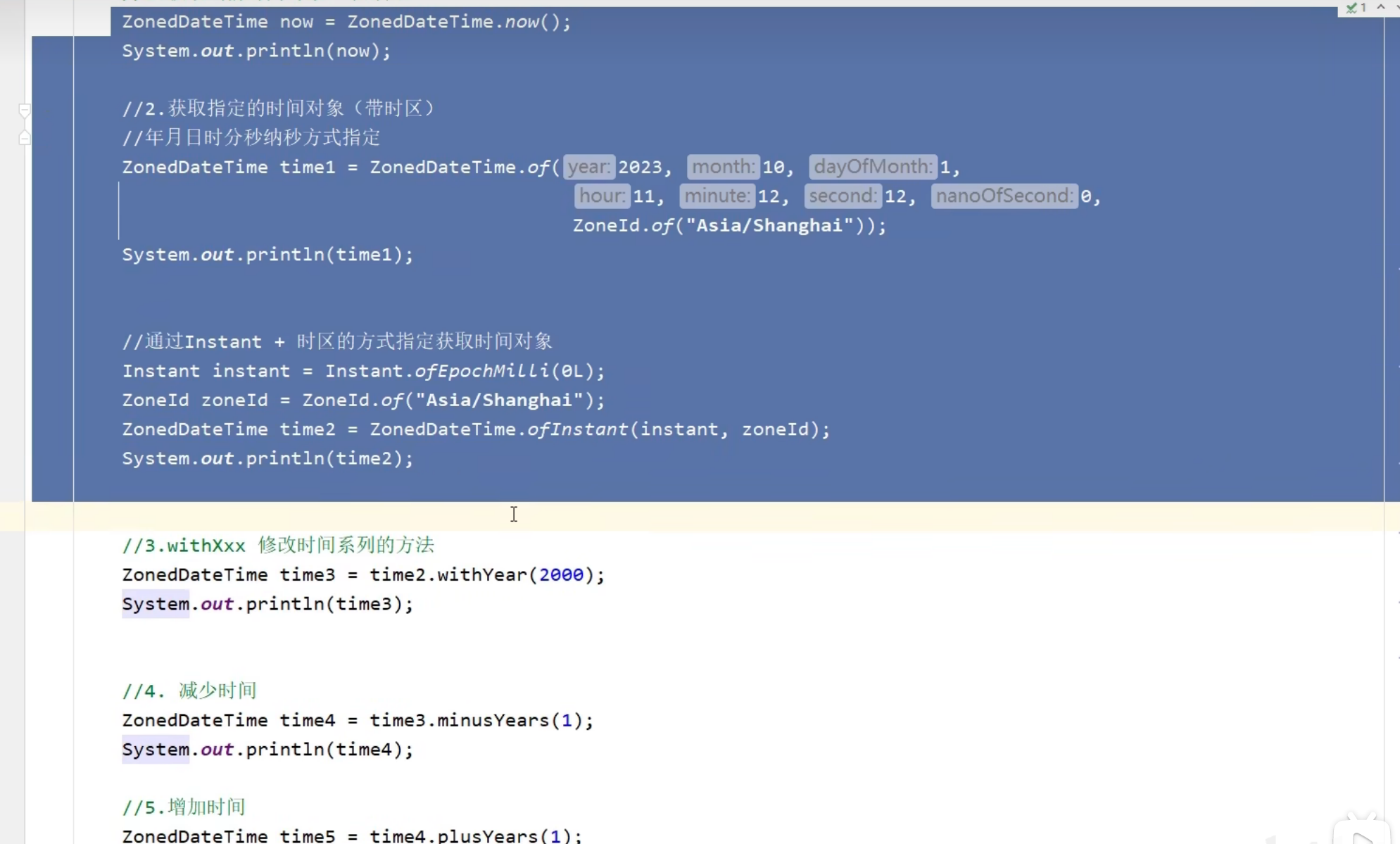
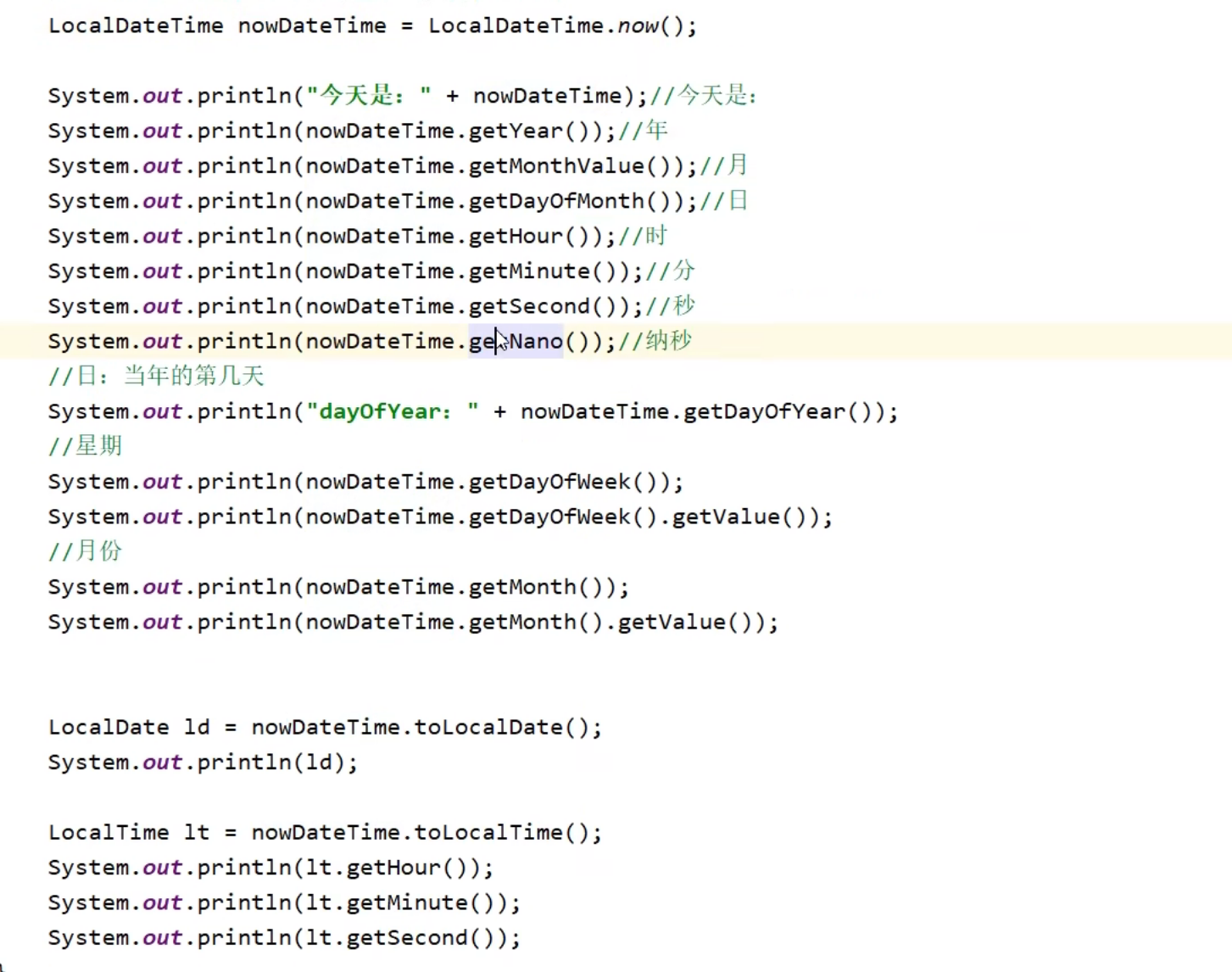
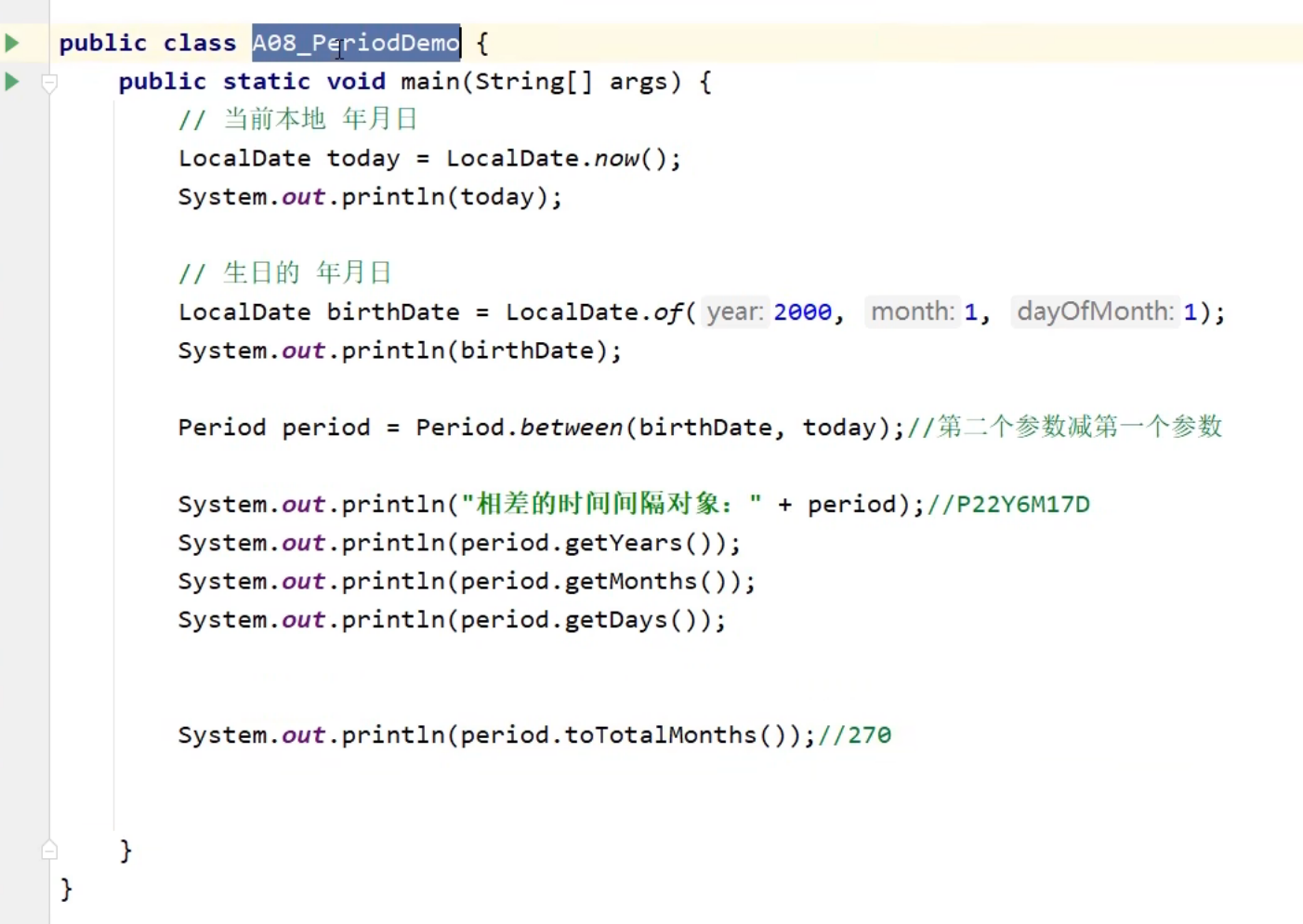
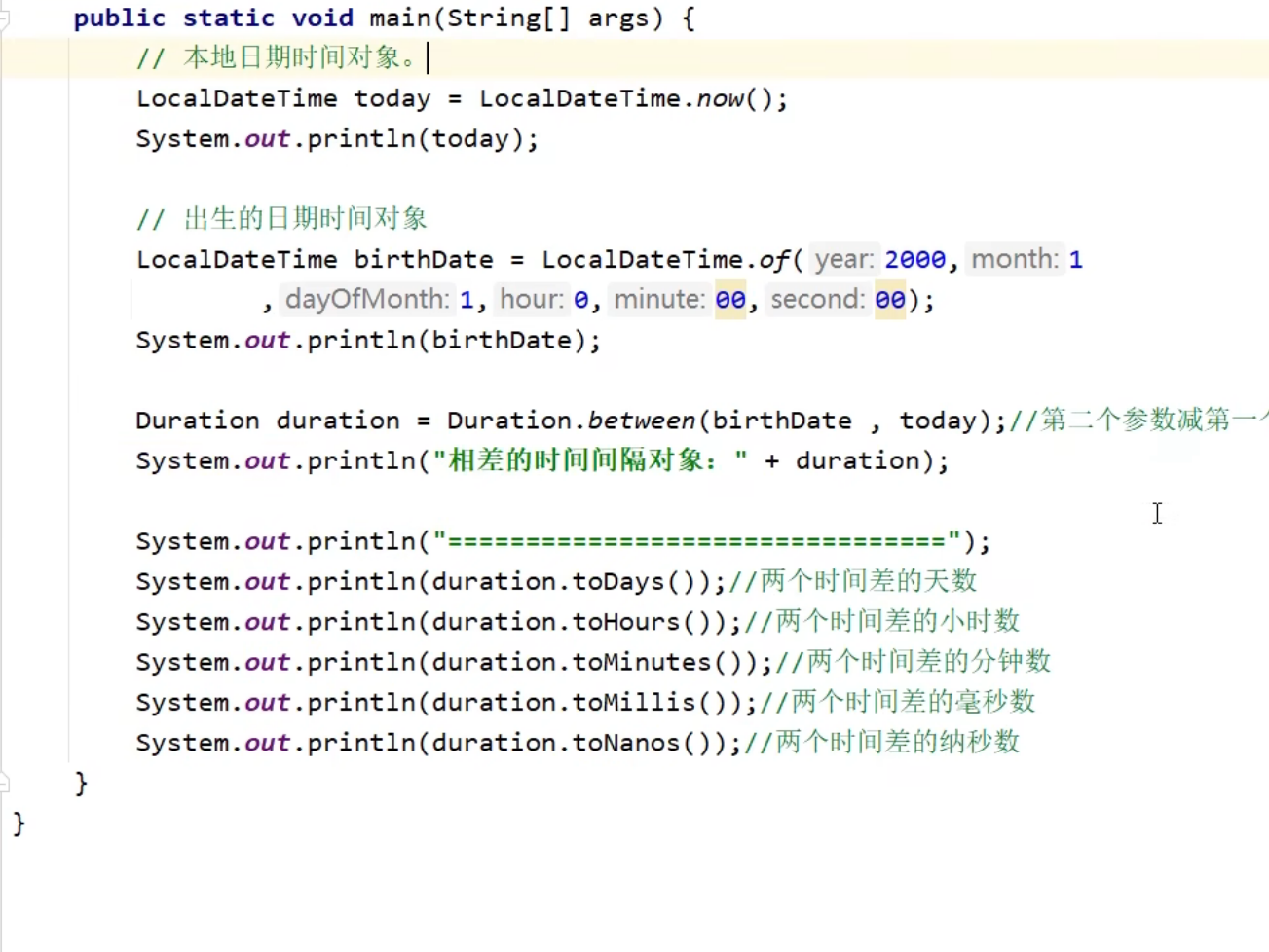
JDk8新加时间类
ZoneId类
Instant类



再转换基本数据时超出范围的数字才会被转换,否则将会被转换为一个数组内的值所以127,128的比较结果不一致

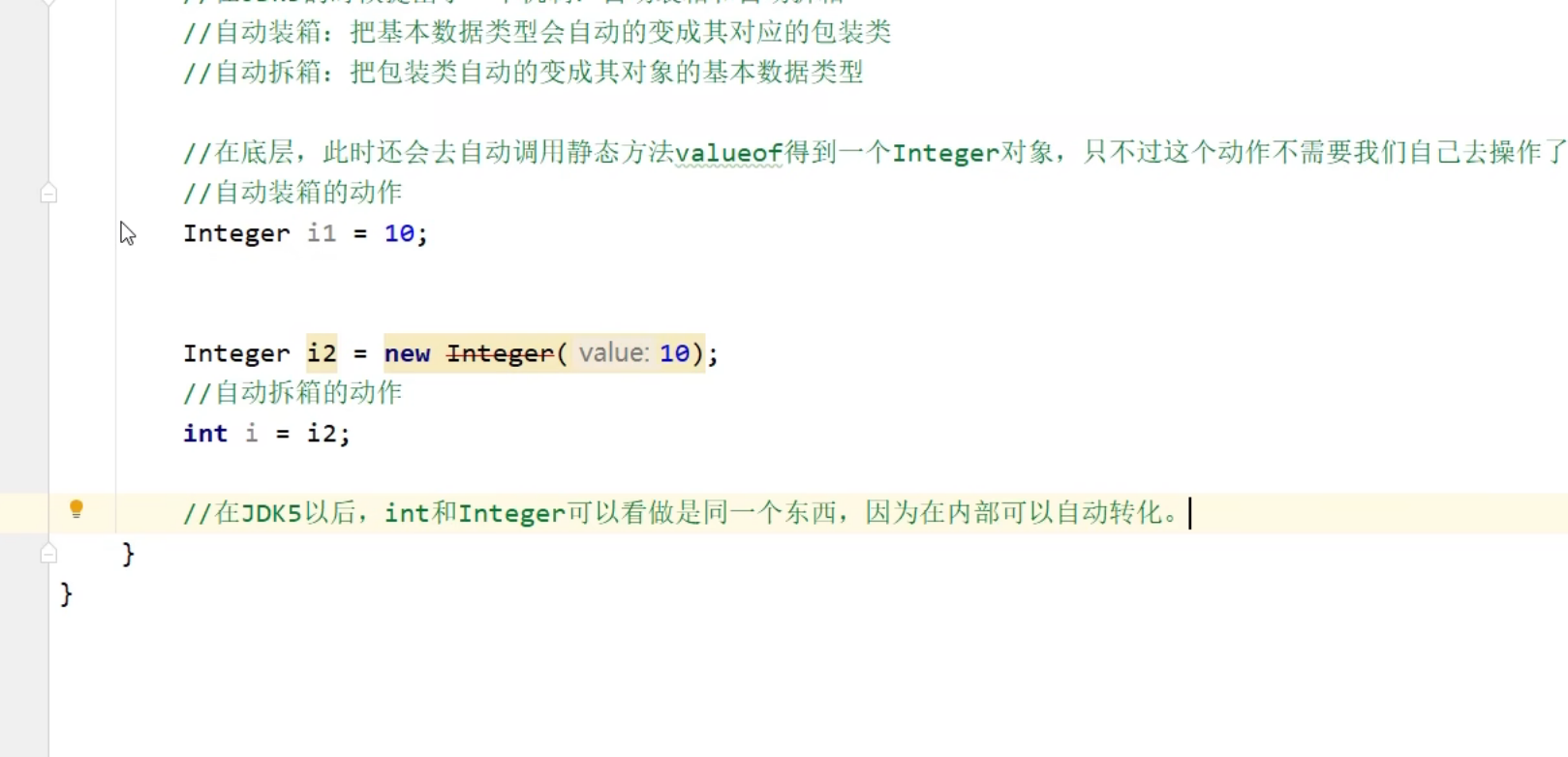
对象和对象之间不可以直接相加减,所以还要把对象换为基本数据类型
为了避免按麻烦出现了自动装箱,自动拆箱的方法,实际上可以把int和integer视为一个东西



字符串

equals方法的使用是要看前面的调用者是谁,前面是字符变量时,判断比较对象是否是字符串变量,若是再比较内部属性,若不是,则直接返回false,前面是对象时,若没有进行方法的重写则直接进行地址的比较,也是返回false,虽然返回的结果相同,但是有实质性差别
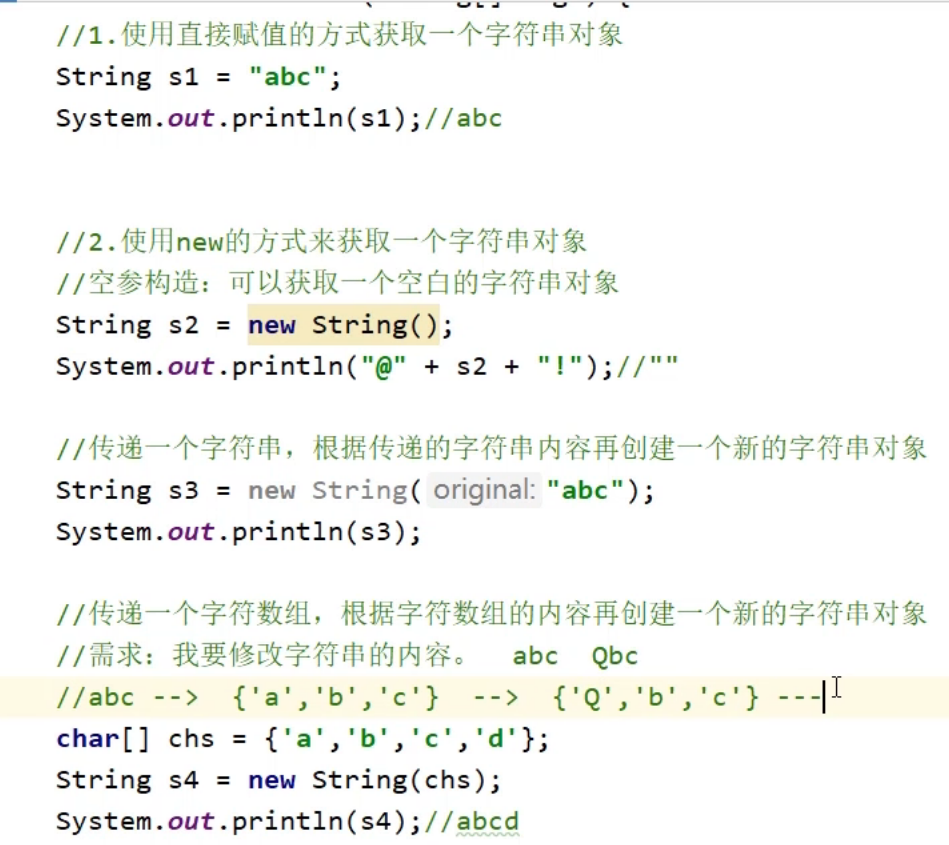
1.String 字符串

2.String 构造方法代码实现和内存分析
在网络当中传输的数据都是字节类型
我们一般要把字节信息进行转换,转换成字符串
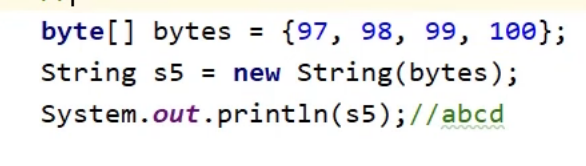

3.字符串的比较
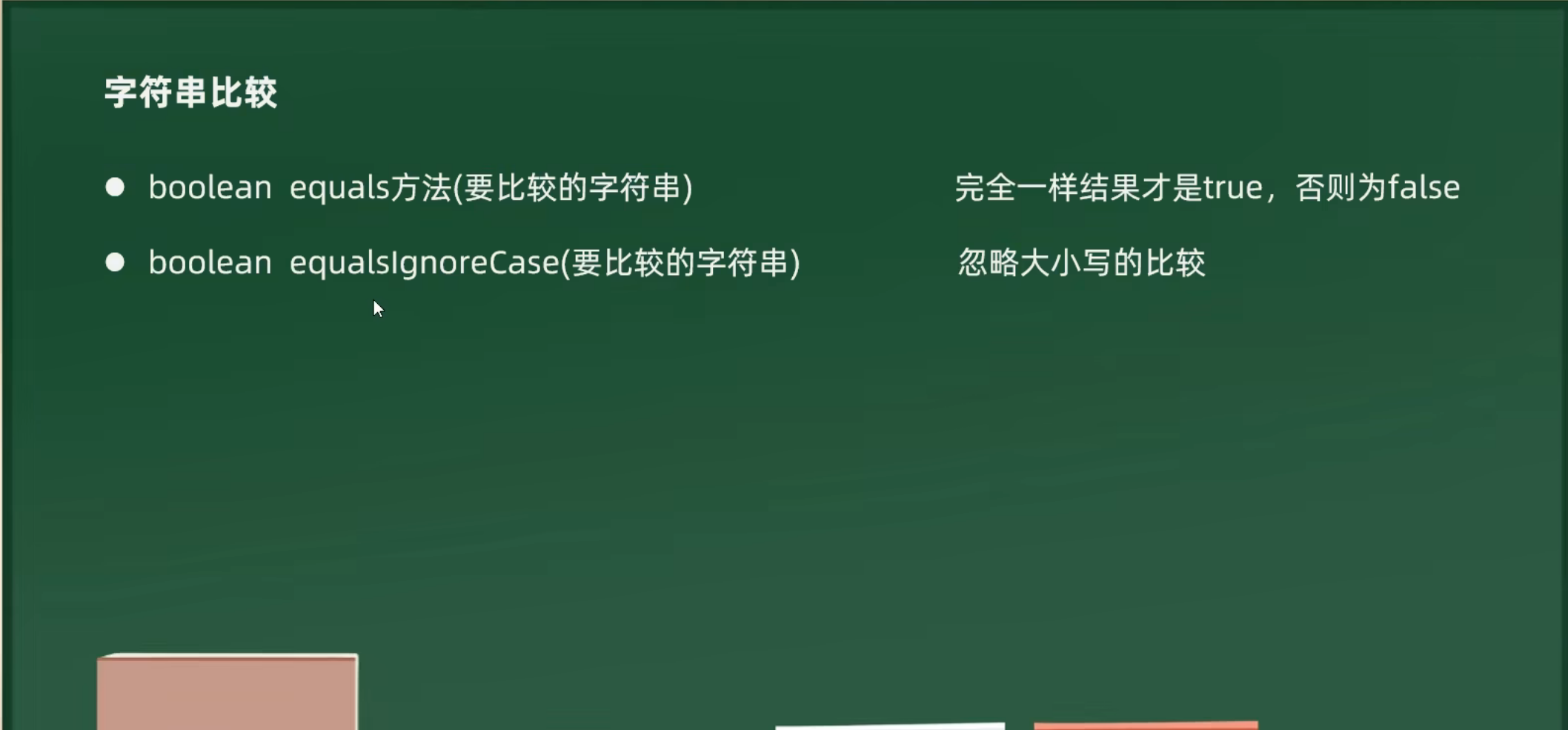
4.遍历字符串,并统计各类型数量
5.字符串拼接和反转
6.substring函数的使用



reverse 反转字符


ArrayList
集合的特点:
1.可以自动扩容没有固定长度
自动伸缩,可长可短
2.数组可以存储基本数据类型还有引用数据类型
集合可以存储引用数据类型,在存储基本数据类型时要将其变成对应的包装类
错误示范:
int 就是基本数据类型,所以不可以直接使用
String 是引用数据类型,可以直接使用
JDK 7之前的写法
现在改为:
ArrayList 是已经处理过的一个类,打印集合时不是集合的地址值而是集合里面的内容
集合的运用:
添加:
在以上添加任务中原来的字符是“456”,在添加之后不会把原来的覆盖而是加在原来内容之前,原来的数据会向后推移一个
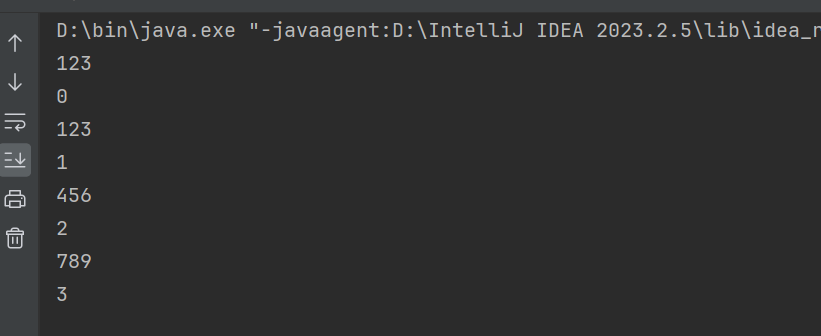
删除:
当要删除的元素不存在时,删除失败
删除时也可以根据索引来删除,索引的顺序就是添加元素时的顺序
修改:
将原来索引上的内容覆盖
查询:
遍历:
集合中基本数据类型的遍历:
在集合遍历时存放数据还是要new 一个变量来接收集合里面的值
上面是已经对对象进行了内容赋值的方法
下面是一种手动对对象进行赋值的一种方法
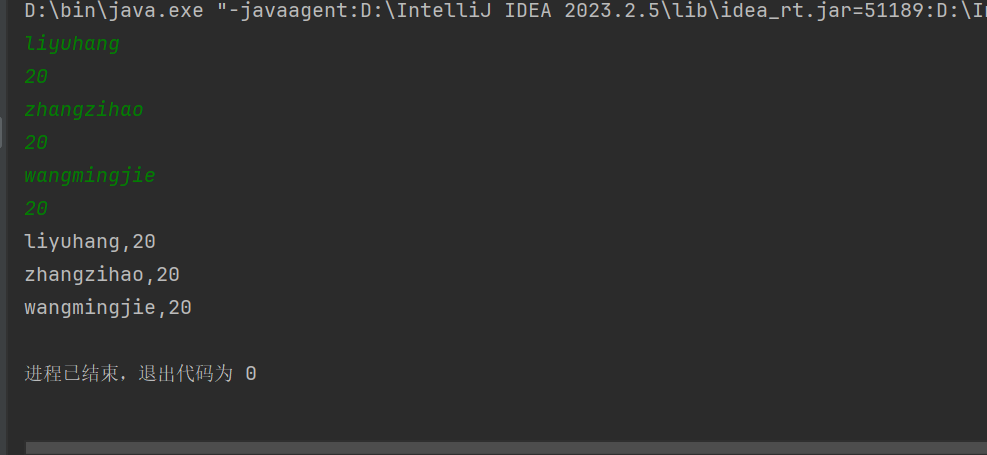
异常
概念:
异常就是程序出现了不正常的情况
异常及其子类是Throwable的形式,表示合理应用程序可能想要捕获的条件
异常类和不是RuntimeException的子类的任何子类都是检查异常
检查异常:
在编译期间必须要处理的,否则不能通过编译
RuntimeException类:
在编译期间不需要修改的,在报错之后才要回来修改的
比如说索引超出范围
Error:严重问题,不需要处理
Exception:称为异常类,他表示程序本身可以处理的异常
JVM的默认处理方案
- 把异常的名称,异常的原因及异常出现的位置等信息输出在了控制台
- 程序停止运行
异常的处理方法
try …catch …
格式:
执行流程:
程序从try里面的代码开始执行
出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统
当Java运行时系统接受到异常对象时,会到catch中去找匹配的异常类,找到后进行异常处理
执行完毕后,程序还可以继续往下执行
Throwable的成员方法:
getMessage:
返回此throwable的详细消息字符串
就是错误的原因
toString :
返回此可抛出的简短描述
异常的名称,还有原因
printStackTrace:
输出错误的类名,原因,位置
编译时异常还有运行时异常的区别:
编译时异常:必须显示处理,否则程序就会发生错误,无法通过编译
好像是什么编译时就会出来提示需要修改
运行时异常:无需显示处理,也可以和编译时异常一样处理
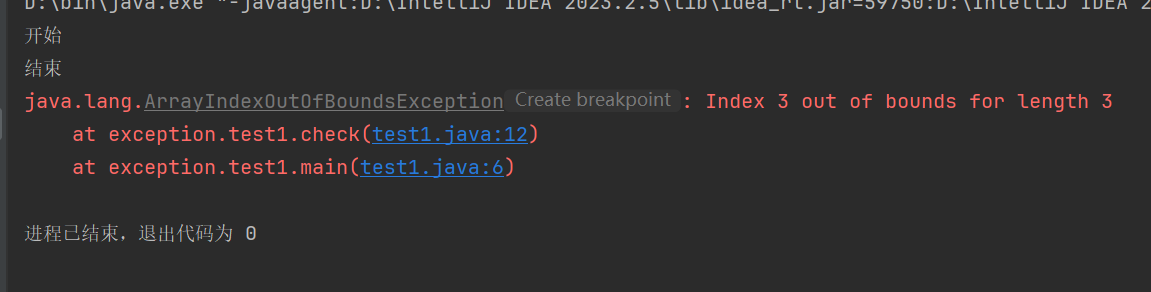
异常处理之throws
把异常抛出去,并不会解决问题运行到有问题的地方还是会停下来,还得用try…catch…来处理
- 就是个延后处理方式,将来谁调用谁处理
- 运行异常时可以不处理,出现问题后,需要我们回来改代码
自定义异常:

泛型:
1.什么是泛型
泛型出现的背景:
JAVA推出泛型之前,程序员可以构建一个元素类型为Obeject的集合,该集合能够储存任意的数据类型对象,而在使用该集合的过程中,需要程序员明确知道储存每个元素的数据类型,否则很容易引发ClassCastException异常
泛型是JDK5中引入的一个新特性,泛型提供了编译时类型安全检测机制,该机制允许我们在编译时检测到非法的类型数据结构
泛型的本质:
参数化类型,也就是所操作的数据类型被定为一个参数,算是把类型做一个指定
里面对存储元素的规定<String>就是泛型的一个指定
泛型的好处:
- 类型安全
- 消除了强制类型的转换
2.泛型类,接口

指定一个数据类型,却可以操作多个数据类型

泛型类,不支持基本数据类型,<int>等
同一泛型类根据不同数据类型创建的对象,本质上是同一类型
3.泛型类使用
4.泛型类派生子类
- 子类也是泛型类,子类要和父类的泛型类型要一致
- 子类不是泛型类,父类要明确泛型的数据类型
- 那么子类就是普通类,并且只可以使用父类已经指定的数据类型
5.泛型接口
泛型接口的使用
- 实现类不是泛型类,接口要明确数据类型
实现类是泛型类时,要和接口的泛型类保持一致
实现类泛型标识包括接口泛型表示即可,不用非得完全一致
6.泛型方法
泛型方法:是在调用方法的时候指明泛型的具体类型
public 与返回值中间<T> 非常重要,可以理解为声明此方法为泛型方法
只有声明了<T>的方法才是泛型方法,泛型类中使用了泛型的成员方法并不是泛型方法
<T> 表明该方法将使用泛型类型<T>,此时才可以在方法中使用泛型类型<T>
与泛型类的定义一样,此处T可以随便写成任意标识,常见的如:T,E , K , V 等形式

可变参数的泛型方法的调用:
泛型方法能使方法独立于类而产生变化
如果static方法要使用泛型能力,就必须使其成为泛型方法
7.类型通配符
类型通配符一般是使用“ ?”代替具体的类型实参
所以,类型通配符是类型实参,而不是类型形参
Integer 继承于 Nmuber,在主函数的使用中,如果定义方法想要向方法中传递其他类的类型时,若传递的数据类型不一样,那么就使用通配符来代替
8.类型通配符的上限
要求该泛型的类型,只能是实参类型,或实参类型的子类类型
如果在其中使用了集合等不可以向其中添加元素
9.类型通配符的下限
要求该泛型的类型,只能是实参类型,或实参类型的父类类型
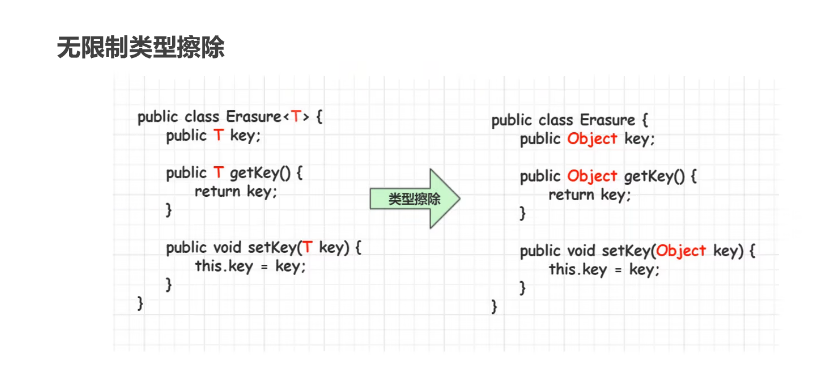
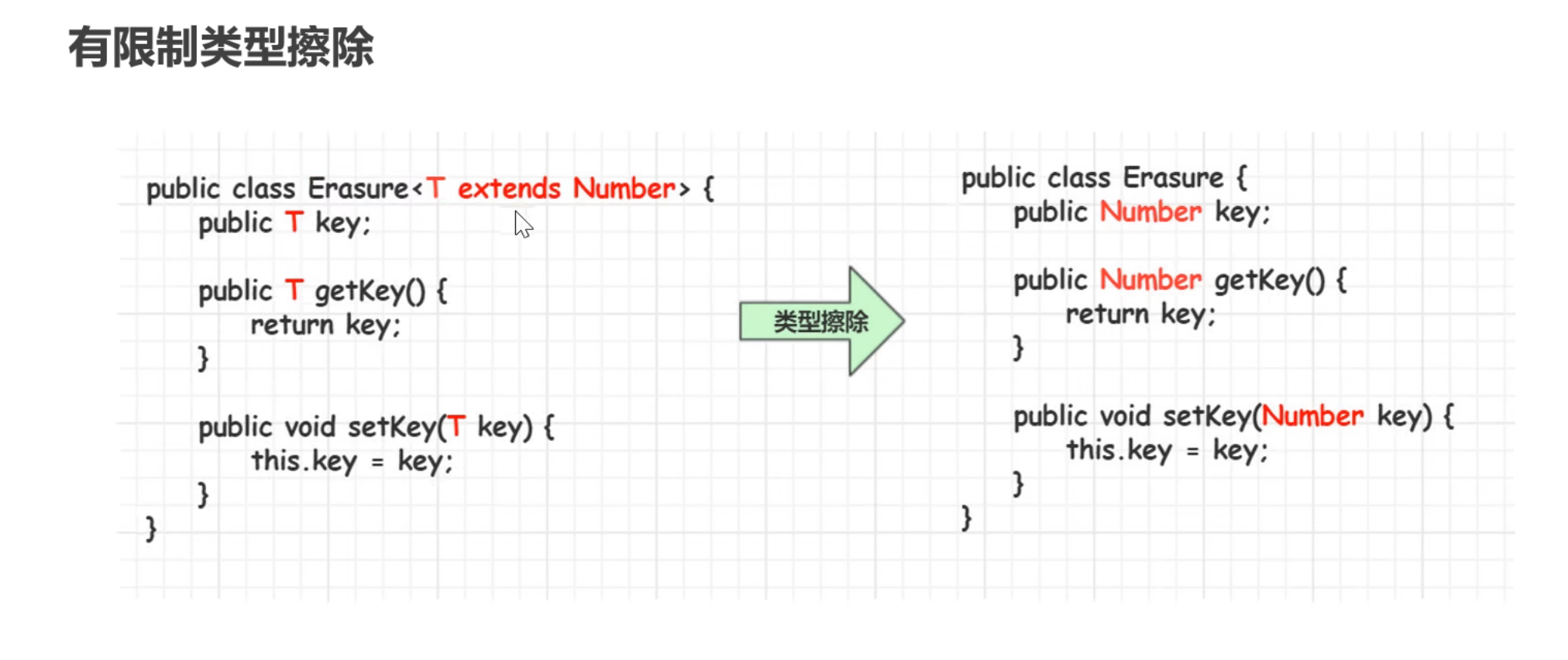
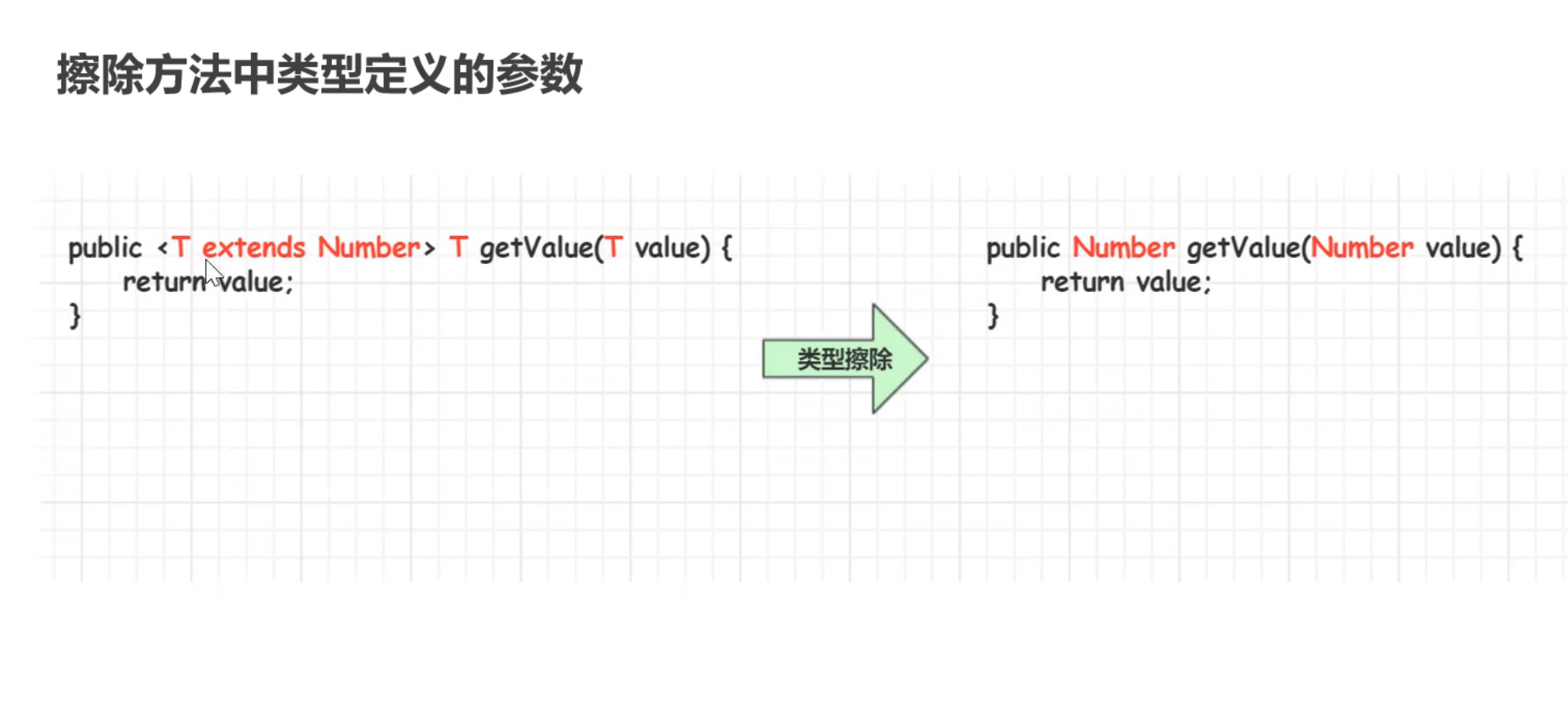
10.类型擦除
在进入JVM之前,与泛型相关的信息会被擦除掉,我们称之为– – 类型擦除
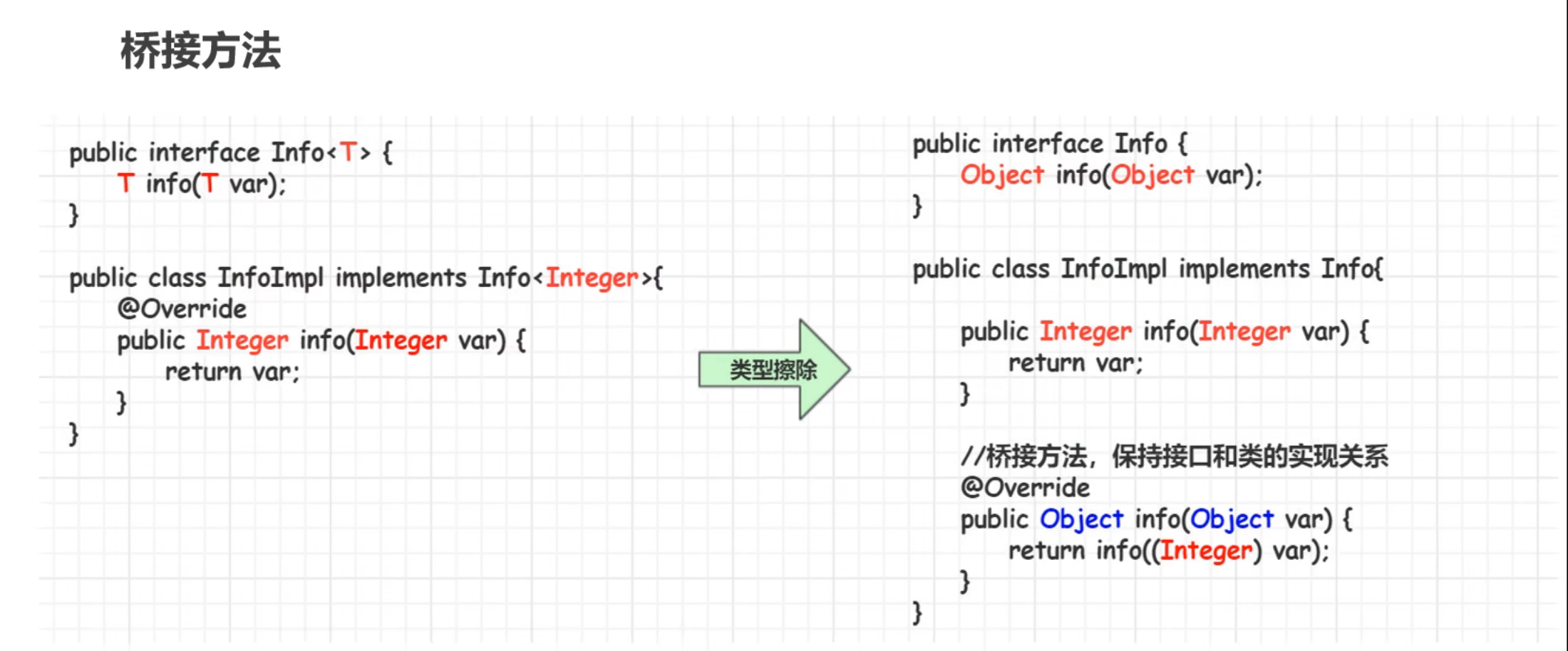
11.泛型和数组
泛型数组的创建
可以声明带泛型的数组引用,但是不能直接创建带泛型的数组对象
只有类型相同的数组还有集合才能赋值
可以通过java.lang.reflect.Array的newInstance(Class<T>,int)创建T[] 数组
12.泛型和反射
单列集合顶层接口Collection
集合体系结构
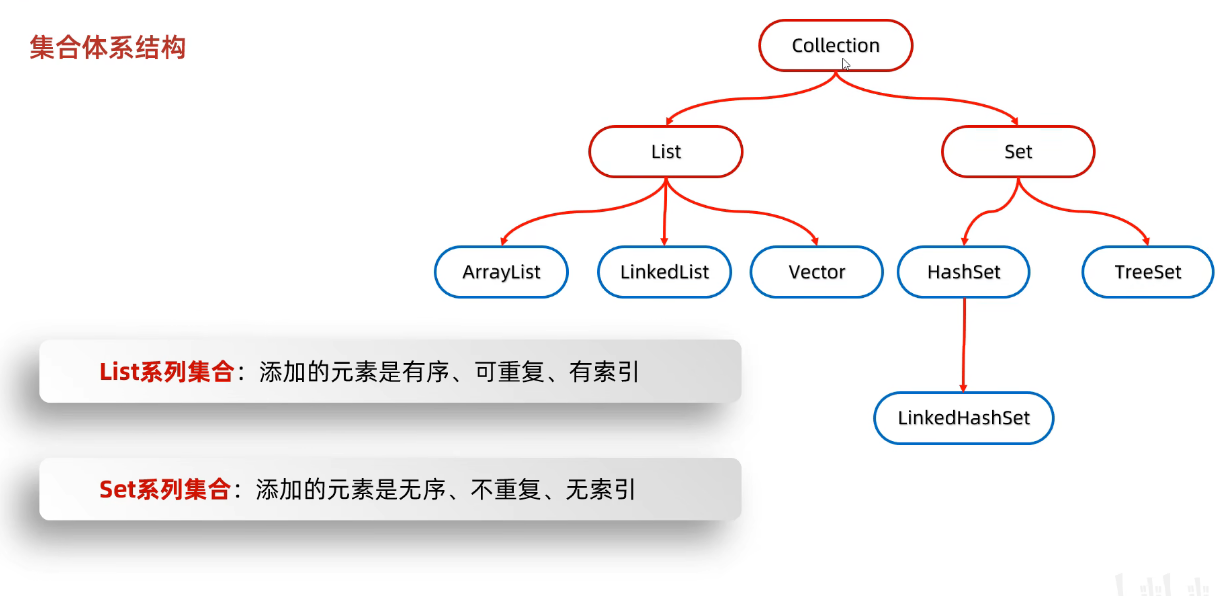
有序指的是:添加和取出的数据是有序的,一致的,而不是像数字排序一样,将内容排序
可重复指的就是:里面添加的元素是可重复的
有索引指的是,可以通过添加的顺序来进行查找,所以List集合有普通for循环查找
迭代器
- 注意细节:
- 当强行获取空指针的时候,就会传出报错NoSuchElementExecption
- 迭代器遍历完毕,指针不会复位,所以想要继续迭代的话,就要创建新的迭代器
- 循环中只能用一次next方法,不可以出现第二个next
- 迭代器遍历时,不能用集合的方法进行添加或者删除
增强for循环
Lambda表达式
List中常见的方法

数据结构
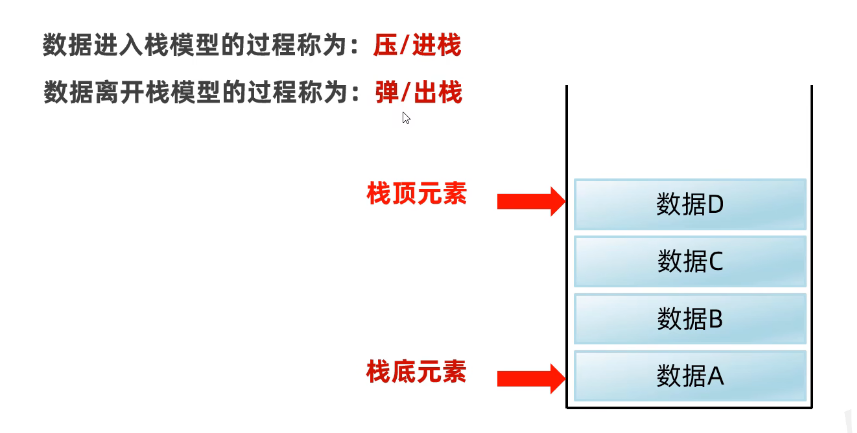
栈
特点:后进先出,先进后出
数据进入栈的过程称为:压/进栈
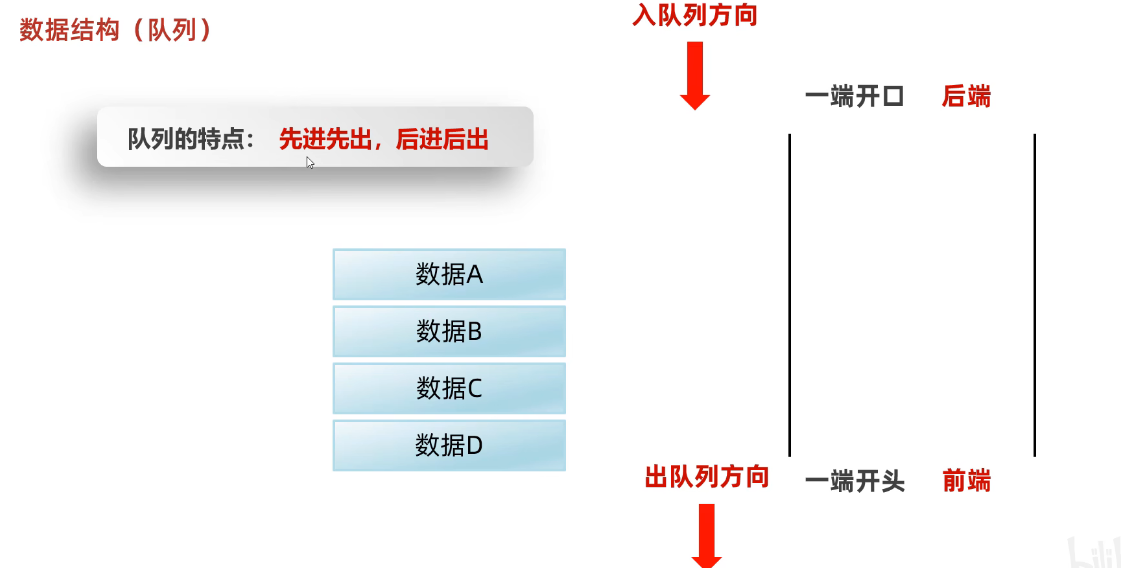
队列
特点:先进先出,后进后出,从后端进,从前端出
泛型进阶
泛型类
在没有泛型的时候,集合的数据类型可以随意添加,但是在遍历获取的时候,就会很麻烦,我们在获取数据时,无法用它的特有行为
当有泛型的时候,我们可以使用他特有的方法,并且可以轻易的对他的数据类型做一个强转
泛型的好处:
- 统一数据类型
- 把运行时期的问题,提前到了编译时期,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来
扩展知识点:
Java中的泛型是伪泛型,只是在添加的时候会做一个判断,看是不是限定类型数据,但是当添加进去后,就又转成Object类型了,当向外获取时,又会重新转换成特定类型
双列集合
特点:
- 双列集合一次需要一队数据,分别为键和值
- 键不能重复,值可以重复
- 键和值是一一对应的,每一个键只能找到自己对应的值
- 键和值这个整体我们称之为“键值对”或者“键值对对象”,在Java中叫做“Entry对象”
Map常见API
键取值遍历
键值对遍历
Lambda表达式
HashMap
- HashMap是Map里面的一个实现类
- 没有额外需要学习的特有方法,直接使用Map里面的方法就可以了
- 特点都是由键决定的:无序、不重复、无索引
- HsahMap跟HashSet底层原理是一模一样的,都是哈希表结构


版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/3763.html