
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
Speaker Recognition
背景简介
什么是声纹
声音纹理(Voiceprint)是一种带有言语信息的声波频谱,它是一种生物特征,它由一百多个维度组成,包括波长、频率和强度,它具有稳定性、可测量性和唯一性。
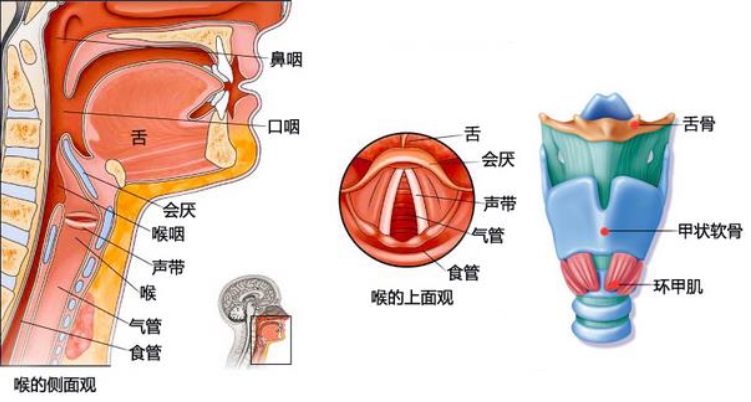
人的语言生成是人类语言中心和发音器官之间一个复杂的生理物理过程,舌、牙、喉、肺、鼻等发声器官在大小和形状上各不相同,因此对任何两个人来说,声纹图谱都是不同的。
个体的语音声学特征具有相对的稳定性和可变性,且并非一成不变。这些变化可能来自生理、病理、心理、模拟、伪装等,也可能与环境干扰有关。
然而,由于每个人的发音器官都不一样,所以在一般情况下,人们仍然可以区分不同的人的声音,或者判断是否是同一个人发出的声音。
讯享网
识别的原理
每个人说话时所用的发声器官在大小和形状上都有很大的不同,因此任何两个人发音的声纹图都有不同,主要体现在以下几个方面:
共振模式特点:咽腔共振,鼻腔共振,口腔共振。
声音纯度特征:不同人的声音,纯度一般都不相同,大致可以分为高纯度(明亮)、低纯度(沙哑)和中纯度三个等级。
均音高特点:均音高的高低即一般所说的嗓音是高还是低。
音高的高低是指人们通常所说的音色是否饱满或干瘪。
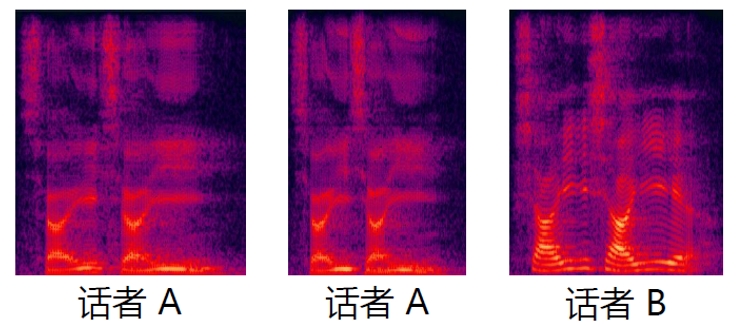
语谱图中不同人声的谐振峰分布情况不同,而声纹识别则是通过比较两段语音说话人的发音,判断其是否属于同一人声,实现“闻声识人”的功能。
评价的指标
在算法层面上,声纹识别可以通过以下基本技术指标来判断其性能,除此之外,还有其他一些指标,如:信道的鲁棒性、时变的鲁棒性、假冒攻击的鲁棒性、群体的普适性等,这部分后面将详细展开。
误拒绝率(FalseRejectionRate,FRR):在分类问题中,如果两个样本是相同的(相同的人),但被系统误认为是不同的(不同的人),那么就是错误的拒绝案例。误报率是指所有同类匹配案例中误报率的百分比。
误报率(FAR):在分类问题中,如果两个样本是异类(非同一人),但被系统误认为是同类(同一人),那么就是错误接受情况。误报率是指所有异类匹配病例中错误接受病例的比例。
等错率:调整阈值,使误拒绝率(FalseRejectionRate,FRR)等于误接受率(FalseAcceptanceRate,FAR),此时FAR和FRR的值称为等错率。
速率:(提取速度:提取声纹速度与音频时长相关,验证比对速度):实时RealTimeFactor比(衡量提取时间与音频时长的关系,例如:1秒可以处理80s的音频,然后实时比是1:80)。校验比值对速度是指平均每秒可以进行的声纹比对次数。
门限:在接受/拒绝二元分类系统中,通常设置一个门限,当分数超过这个值时,才会作出接受的决定。根据业务需求调整阈值可以平衡FAR和FRR。在设置高阈值时,系统对接受决策的评分要求更严格,FAR降低,FRR提高;在设置低阈值时,系统对接受决策的评分要求更宽松,FAR提高,FRR降低。对于不同应用场景,调节不同阈值,则可在安全性和便利性之间实现均衡。

影响识别的一些因素
声源采样率
- 人类语音的频段集中于50Hz ~ 8KHz之间,尤其在4KHz以下频段
- 离散信号覆盖频段为信号采样率的一半(奈奎斯特采样定理)
- 采样率越高,信息量越大
- 常用采样率:8KHz (即0 ~ 4KHz频段),16KHz(即0 ~ 8KHz频段)
信噪比(SNR)
- 信噪比衡量一段音频中语音信号与噪声的能量比,即语音的干净程度
- 15dB以上(基本干净),6dB(嘈杂),0dB(非常吵)
信道
- 不同的采集设备,以及通信过程会引入不同的失真
- 声纹识别算法与模型需要覆盖尽可能多的信道
- 手机麦克风、桌面麦克风、固话、移动通信(CDMA, TD-LTE等)、微信……
语音时长
- 语音时长(包括注册语音条数)会影响声纹识别的精度
- 有效语音时长越长,算法得到的数据越多,精度也会越高
- 短语音(1~3s)
- 长语音(20s+)
文本内容
- 通俗地说,声纹识别系统通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人
- 固定文本:注册与验证内容相同
- 半固定文本:内容一样但顺序不同;文本属于固定集合
- 自由文本
识别方案实践
一般说话人识别整体的方案流程如下:
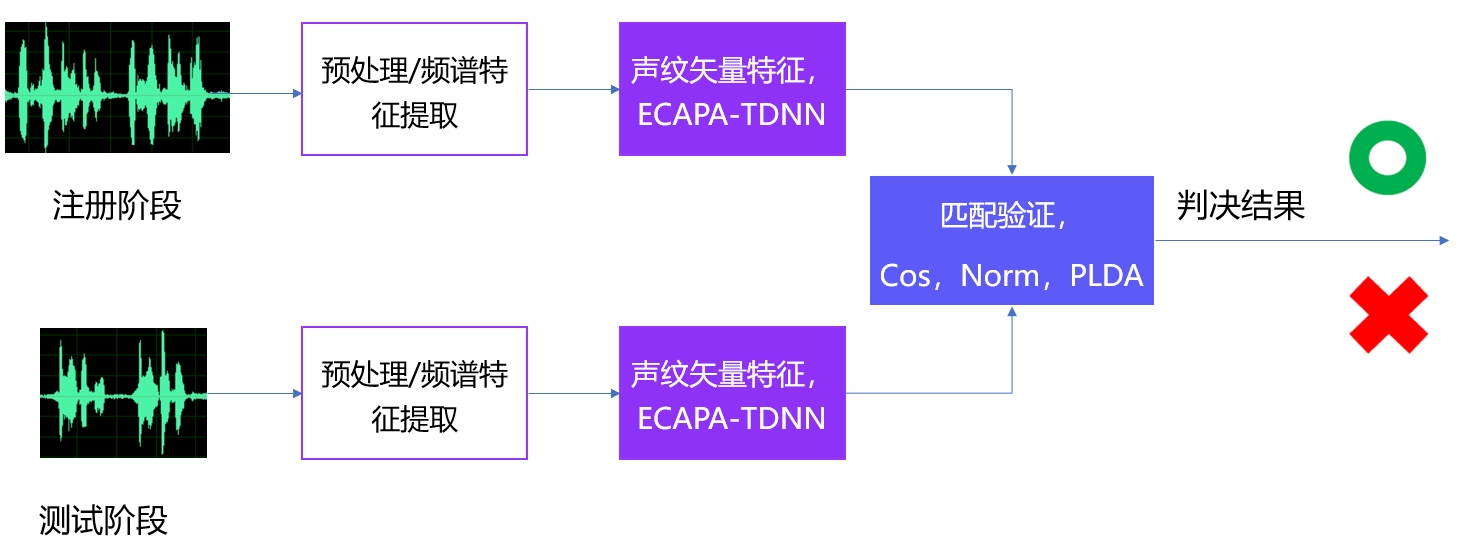
包括预处理,语音活动检测,提取声纹矢量特征,匹配验证,获得判决结果

预处理
频谱特征
对音频进行分帧,预加重,加窗等操作,如下图所示:
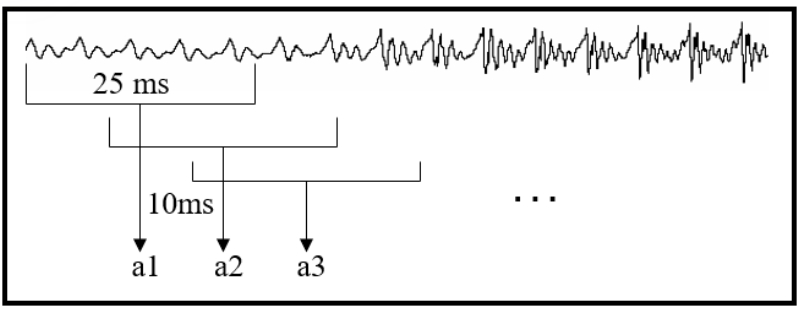

上述过程相当于将原始非常密集型的音频信号,转化为稀疏型一组组特征向量,然后在该基础上,进行进一步处理
# 环境准备:安装paddlespeech和paddleaudio !pip install --upgrade pip && pip install paddlespeech==1.2.0 paddleaudio==1.0.1 -U 讯享网
讯享网import warnings warnings.filterwarnings("ignore") import IPython import numpy as np import matplotlib.pyplot as plt %matplotlib inline
获取音频并提取音频特征
# 获取示例音频 !test -f ./.wav || wget https://paddlespeech.bj.bcebos.com/vector/audio/.wav IPython.display.Audio('./.wav') 讯享网from paddleaudio import load data, sr = load(file='./.wav', mono=True, dtype='float32') # 单通道,float32音频样本点 print('wav shape: {}'.format(data.shape)) print('sample rate: {}'.format(sr)) # 展示音频波形 plt.figure() plt.plot(data) plt.show()
import paddle import numpy as np data, sr = load(file='./.wav', sr=16000, mono=True, dtype='float32') x = paddle.to_tensor(data) n_fft = 512 win_length = 512 hop_length = 160 # [D, T] spectrogram = paddle.signal.stft(x, n_fft=n_fft, win_length=win_length, hop_length=160, onesided=True) print('spectrogram.shape: {}'.format(spectrogram.shape)) print('spectrogram.dtype: {}'.format(spectrogram.dtype)) spec = np.log(np.abs(spectrogram.numpy())2) plt.figure() plt.title("Log Power Spectrogram") plt.imshow(spec[:100, :], origin='lower') plt.show() 语音活动检测

模型构建
ECAPA-TDNN 是发表于2020年五月的文章,在Voxceleb上取得了当时最优的效果,它在传统 TDNN 模型进行了改进,主要有三个方面的优化,分别是:
- 增加了一维SE残差模块(1-Dimensional Squeeze-Excitation Res2Block)
- 多层特征融合(Multi-layer feature aggregation and summation)
- 通道和上下文相关的统计池化(Channel- and context-dependent statistics pooling)
所以在本方案中,我们也采用了该网络结构,如下图所示:

- 模型输入80维的Fbank特征,长度为T,实际对音频进行分片处理,每个片段3s
- 第一层是经过一层Conv1D+ReLU+BN模块处理,因为是一维卷积,所以等同于一个TDNN模块,实现代码是右边第一块TDNNBlock
- 第二部分会有N层的SE-Res2Net模块,层数是channels的个数减二(代码中是从1开始计数,到len(channels) -1,),具体实现中有五层,分别是: [1024, 1024, 1024, 1024, 3072],所以这里有三层SE-Res2Net模块,同时要注意的是它还是一个空洞卷积,空洞率分别是dilations=[1, 2, 3, 4, 1],所以对前面[2,3,4]层都有一定的前后context
- 第三部分继续接了一层TDNN模块,作用是多层特征融合,所以这里的输入是前面每层SE-Res2Net模块输出所拼接的,也就是channels最后一维的3072,来源是1024*3=3072
- 第四部分是一个Attentive Statistical Pooling层,用来对输出进行概率池化
- 第五部分是一个全连接加上一个BatchNorm1d层,用来对最后的特征进行linear transformation,输出维度是预设的lin_neurons值,这里取的是192(这个特征向量就是我们需要的 Embedding)
- 最后是AAM(Additive Angular Margin)-Softmax层,用来对输出进行分类,分类的个数是说话人的数量
模型训练
数据准备
| 数据集 | vox1-dev | vox1-test | vox2-dev | vox2-test |
|---|---|---|---|---|
| 说话人个数 | 1211 | 40 | 5994 | 118 |
| 音频条数 | 4874 | 36273 | ||
| 总时长(h) | 340.4 | 11.2 | 2360.2 | 79.9 |
调用以下示例代码读取数据集音频文件,创建训练集和验证集。详细代码请参考仓库中example/voxceleb/sv0/run.sh
讯享网 from paddlespeech.vector.io.dataset import CSVDataset train_dataset = CSVDataset( csv_path=os.path.join(args.data_dir, "vox/csv/train.csv"), label2id_path=os.path.join(args.data_dir, "vox/meta/label2id.txt")) dev_dataset = CSVDataset( csv_path=os.path.join(args.data_dir, "vox/csv/dev.csv"), label2id_path=os.path.join(args.data_dir, "vox/meta/label2id.txt"))
定义优化器 Loss
lr_schedule = CyclicLRScheduler( base_lr=config.learning_rate, max_lr=config.max_lr, step_size=config.step_size // nranks) optimizer = paddle.optimizer.AdamW( learning_rate=lr_schedule, parameters=model.parameters()) criterion = LogSoftmaxWrapper( loss_fn=AdditiveAngularMargin(margin=config.margin, scale=config.scale)) 启动训练
讯享网 epochs = 20 log_interval = 5 save_interval = 10 batch_size = 32 for epoch in range(1, epochs + 1): model.train() avg_loss = 0 num_corrects = 0 num_samples = 0 for batch_idx, batch in enumerate(train_loader): waveforms, labels = batch['waveforms'], batch['labels'] waveforms, lengths = batch_pad_right(waveforms.numpy()) waveforms = paddle.to_tensor(waveforms) if len(augment_pipeline) != 0: waveforms = waveform_augment(waveforms, augment_pipeline) labels = paddle.concat( [labels for i in range(len(augment_pipeline) + 1)]) feats = [] for waveform in waveforms.numpy(): feat = melspectrogram( x=waveform, sr=config.sr, n_mels=config.n_mels, window_size=config.window_size, hop_length=config.hop_size) feats.append(feat) feats = paddle.to_tensor(np.asarray(feats)) feats = feature_normalize( feats, mean_norm=True, std_norm=False) # Features normalization logits = model(feats) loss = criterion(logits, labels) loss.backward() optimizer.step() if isinstance(optimizer._learning_rate, paddle.optimizer.lr.LRScheduler): optimizer._learning_rate.step() optimizer.clear_grad() avg_loss = loss.item() preds = paddle.argmax(logits, axis=1) num_corrects += (preds == labels).numpy().sum() num_samples += feats.shape[0] if (batch_idx + 1) % log_interval == 0 and local_rank == 0: lr = optimizer.get_lr() avg_loss /= log_interval avg_acc = num_corrects / num_samples print_msg = 'Train Epoch={}/{}, Step={}/{}'.format( epoch, epochs, batch_idx + 1, steps_per_epoch) print_msg += ' loss={:.4f}'.format(avg_loss) print_msg += ' acc={:.4f}'.format(avg_acc) print_msg += ' lr={:.4E} step/sec={:.2f} ips={:.5f}| ETA {}'.format( lr, timer.timing, timer.ips, timer.eta) logger.info(print_msg) if epoch % save_interval == 0 and batch_idx + 1 == steps_per_epoch: if local_rank != 0: paddle.distributed.barrier() continue dev_sampler = BatchSampler( dev_dataset, batch_size=batch_size, shuffle=False, drop_last=False) dev_loader = DataLoader( dev_dataset, batch_sampler=dev_sampler, collate_fn=waveform_collate_fn, num_workers=0, return_list=True, ) model.eval() num_corrects = 0 num_samples = 0 logger.info('Evaluate on validation dataset') with paddle.no_grad(): for batch_idx, batch in enumerate(dev_loader): waveforms, labels = batch['waveforms'], batch['labels'] feats = [] for waveform in waveforms.numpy(): feat = melspectrogram( x=waveform, sr=config.sr, n_mels=config.n_mels, window_size=config.window_size, hop_length=config.hop_size) feats.append(feat) feats = paddle.to_tensor(np.asarray(feats)) feats = feature_normalize( feats, mean_norm=True, std_norm=False) logits = model(feats) preds = paddle.argmax(logits, axis=1) num_corrects += (preds == labels).numpy().sum() num_samples += feats.shape[0] print_msg = '[Evaluation result]' print_msg += ' dev_acc={:.4f}'.format(num_corrects / num_samples) logger.info(print_msg)
执行预测
waveform, sr = load_audio("./.wav") feat = melspectrogram( x=waveform, sr=sr, n_mels=n_mels, window_size=window_size, hop_length=hop_size) feat = paddle.to_tensor(feat).unsqueeze(0) lengths = paddle.ones([1]) feat = feature_normalize(feat, mean_norm=True, std_norm=False) embedding = model.backbone( feat, lengths).squeeze().numpy() 命令行示例:
- 提取声纹矢量特征
paddlespeech vector --task spk --input “./.wav” - 比较声纹矢量特征
paddlespeech vector --task score --input “./.wav ./.wav”
建库检索方案实践
方案简介
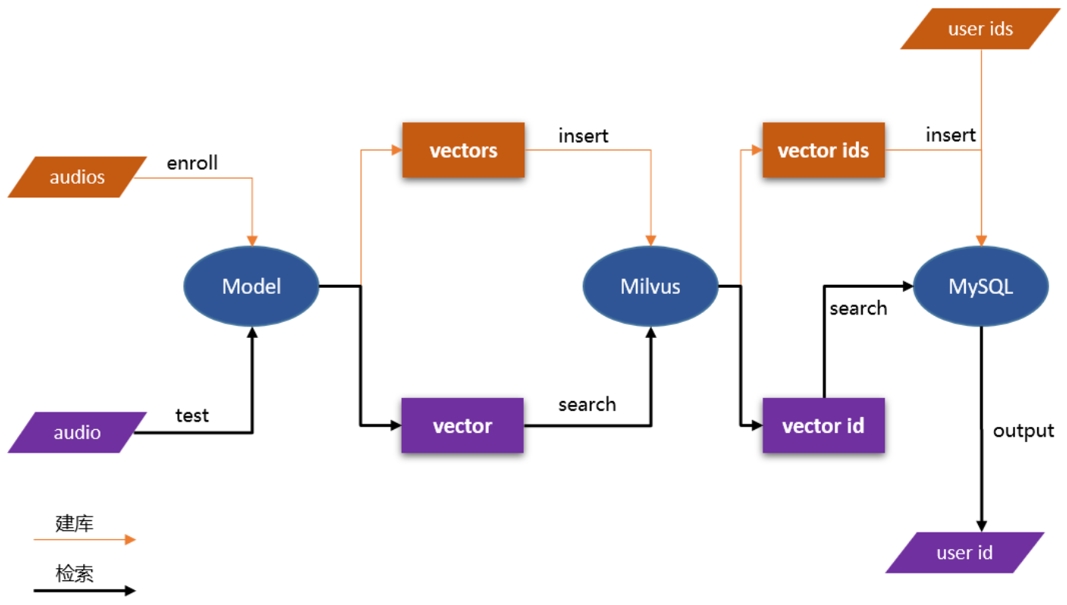
使用基于 PaddleSpeech 预训练模型(音频分类模型,说话人识别模型等)将上传的音频片段转换为向量数据,并存储在 Milvus 中。Milvus 自动为每个向量生成唯一的 ID,然后将 ID 和 相应的音频信息(音频id,音频的说话人id等等)存储在 MySQL,这样就完成建库的工作。用户在检索时,上传测试音频,得到向量,然后在 Milvus 中进行向量相似度搜索,Milvus 返回的检索结果为向量 ID,通过 ID 在 MySQL 内部查询相应的音频信息即可。
数据准备
为了便于演示流程,本范例采用了较小的数据集
讯享网!wget -N "https://paddlespeech.bj.bcebos.com/vector/audio/example_audio.tar.gz"
!tar -xvf ./example_audio.tar.gz 环境准备
检索需要用到 Milvus, MySQL 服务。 我们可以通过 docker-compose.yaml 一键启动这些容器,所以请确保在运行之前已经安装了 Docker Engine 和 Docker Compose。
由于aistudio不支持搭建Milvus,有条件的同学可以本地搭建一个,使用Docker安装。具体可以参考paddlespeech 里面 audio searching demo 的 readme,如下:
讯享网 先进入到 audio_searching 目录,如下示例 cd ~/PaddleSpeech/demos/audio_searching/ 然后启动容器内的相关服务 docker-compose -f docker-compose.yaml up -d
建库索引
对下载的音频数据集,进行声纹矢量特征的抽取,然后存入到Milvus并建立索引,同时将一些信息存入到MySQL
def get_audio_embedding(path): """ Use vpr_inference to generate embedding of audio """ try: embedding = vector_executor( audio_file=path, model='ecapatdnn_voxceleb12') embedding = embedding / np.linalg.norm(embedding) embedding = embedding.tolist() return embedding except Exception as e: LOGGER.error(f"Error with embedding:{
e}") return None def extract_features(audio_dir): """ Get the vector of audio """ try: cache = Cache('./tmp') feats = [] names = [] audio_list = get_audios(audio_dir) total = len(audio_list) cache['total'] = total for i, audio_path in enumerate(audio_list): norm_feat = get_audio_embedding(audio_path) if norm_feat is None: continue feats.append(norm_feat) names.append(audio_path.encode()) cache['current'] = i + 1 print( f"Extracting feature from audio No. {
i + 1} , {
total} audios in total" ) return feats, names except Exception as e: LOGGER.error(f"Error with extracting feature from audio {
e}") sys.exit(1) def do_load(table_name, audio_dir, milvus_cli, mysql_cli): """ Import vectors to Milvus and data to Mysql respectively """ if not table_name: table_name = DEFAULT_TABLE vectors, names = extract_features(audio_dir) ids = milvus_cli.insert(table_name, vectors) milvus_cli.create_index(table_name) mysql_cli.create_mysql_table(table_name) mysql_cli.load_data_to_mysql(table_name, format_data(ids, names)) return len(ids) 匹配查找
对于测试音频,我们先提取声纹矢量特征,然后到库里面进行相似性打分,最后得到排序结果
讯享网def do_search(host, table_name, audio_path, milvus_cli, mysql_cli): """ Search the uploaded audio in Milvus/MySQL """ try: if not table_name: table_name = DEFAULT_TABLE feat = get_audio_embedding(audio_path) vectors = milvus_cli.search_vectors(table_name, [feat], TOP_K) vids = [str(x.id) for x in vectors[0]] paths = mysql_cli.search_by_milvus_ids(vids, table_name) distances = [x.distance for x in vectors[0]] for i in range(len(paths)): tmp = "http://" + str(host) + "/data?audio_path=" + str(paths[i]) paths[i] = tmp distances[i] = (1 - distances[i]) * 100 return vids, paths, distances except Exception as e: LOGGER.error(f"Error with search: {
e}") sys.exit(1)
本地程序运行的部分结果展示:
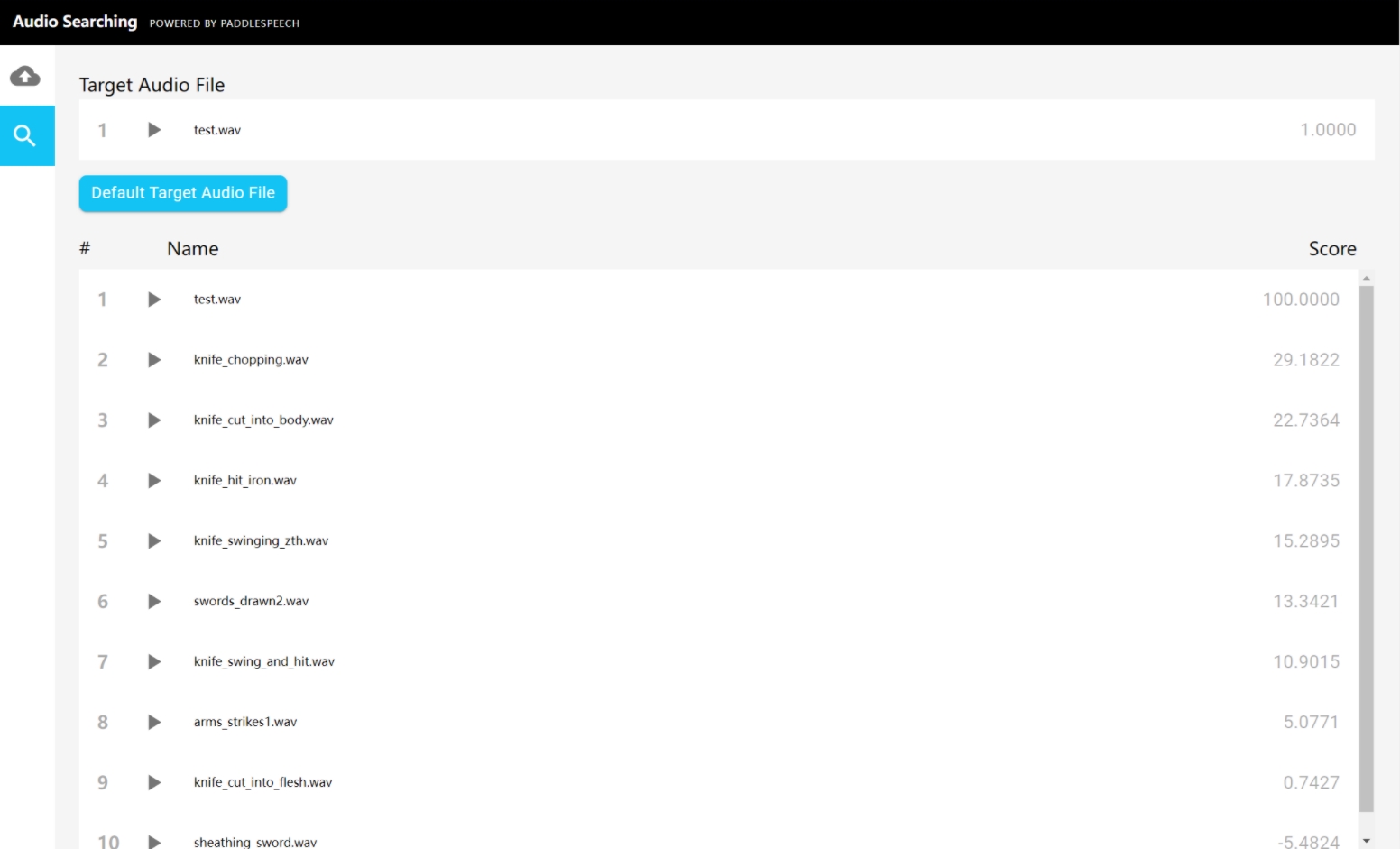
2022-04-27 22:54:16,086 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/test.wav, score 100.0 2022-04-27 22:54:16,087 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/knife_chopping.wav, score 29.8716 2022-04-27 22:54:16,087 | INFO | audio_search.py | search_local_audio | 132 | search result http://testserver/data?audio_path=./example_audio/knife_cut_into_body.wav, score 22.708 界面展示
在浏览器中输入 127.0.0.1:8068 访问前端页面
上传音频
在服务端下载数据并解压到一文件夹,假设为 /home/speech/data/,那么在上传页面地址栏输入 /home/speech/data/ 进行数据上传
检索相似音频
选择左上角放大镜,点击 “Default Target Audio File” 按钮,从客户端上传测试音频,接着你将看到检索结果
PaddleSpeech
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:
- 扫描二维码
- 添加运营小姐姐微信
- 通过后回复【语音】
- 系统自动邀请加入技术群

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36932.html