
phoenix表操作
官网 :https://phoenix.apache.org/language/index.html#upsert_select
进入命令行,这是sqlline.py 配置到path环境变量的情况下
sqlline.py localhost 例如:phoenix-sqlline.py xxxxxxxxxx:2181 如果要退出命令行:!q 或者 !quit 讯享网
创建表
讯享网CREATE TABLE IF NOT EXISTS us_population ( state CHAR(2) NOT NULL, city VARCHAR NOT NULL, population BIGINT CONSTRAINT my_pk PRIMARY KEY (state, city));
插入数据
UPSERT INTO us_population (state, city, population) values ('NY','New York',); UPSERT INTO us_population (state, city, population) values ('CA','Los Angeles',); 在phoenix中,默认情况下,表名等会自动转换为大写,若要小写,使用双引号,如"us_population"。
显示所有表
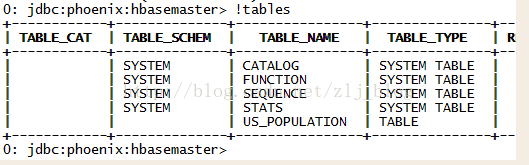
讯享网!tables
phoenix表映射
默认情况下,直接在hbase中创建的表,通过phoenix是查看不到的, US_POPULATION是在phoenix中直接创建的,而test是在hbase中直接创建的,默认情况下,在phoenix中是查看不到test的。
如果需要在phoenix中操作直接在hbase中创建的表,则需要在phoenix中进行表的映射。映射方式有两种:视图映射和表映射。
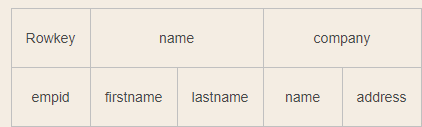
hbase 中test的表结构如下,两个列簇name、company.
hbase命令行中创建表
$ cd /home/hadoop/hbase/bin

$ ./hbase shell 进入hbase命令行
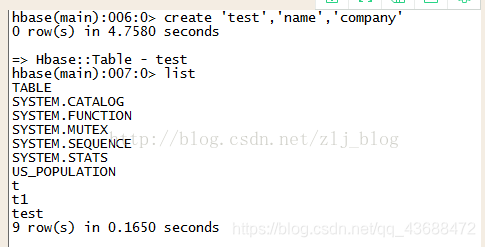
讯享网 create 'test','name','company' 创建表,如下图
视图映射(不推荐)
Phoenix创建的视图是只读的,所以只能用来做查询,无法通过视图对源数据进行修改等操作。而且相比于直接创建映射表,视图的查询效率会低,原因是:创建映射表的时候,Phoenix会在表中创建一些空的键值对,这些空键值对的存在可以用来提高查询效率。
1)创建视图 讯享网create view"test"(empid varchar primarykey,"name"."firstname" varchar,"name"."lastname"varchar,"company"."name" varchar,"company"."address"varchar);
2)删除视图 讯享网 drop view "test";
表映射
使用Apache Phoenix创建对HBase的表映射,有两种方法:
1) 当HBase中表已存在,创建同名表和结构即可 2)当HBase中不存在,可以直接使用create table指令创建需要的表,并且在创建指令中可以根据需要对HBase表结构进行显示的说明。 第1)种情况下,如在之前的基础上已经存在了表,则表映射的语句如下: 讯享网create table "HBASE_BMDA5"("SS5" varchar primary key , "info"."NodeType" INTEGER , "info"."NodeName" varchar, "info"."IsWarehouse" INTEGER, "info"."IsAssetUser" INTEGER);
View Code 然后数据就直接有了.
讯享网使用create table创建的关联表,如果对表进行了修改,源数据也会改变,同时如果关联表被删除,源表也会被删除。但是视图就不会,如果删除视图,源数据不会发生改变。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/36126.html