
函数
讯享网
CANet由三部分组成,encoder,co-attention fusion module,decoder。首先看最重要的部分co-attention fusion module代码,该module由PCAM和CCAM模块组成:

class PCAM_Module(Module): """ Position attention module""" #Ref from SAGAN def __init__(self, in_dim): super(PCAM_Module, self).__init__() self.chanel_in = in_dim self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1) self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1) self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1) self.gamma = Parameter(torch.zeros(1)) self.softmax = Softmax(dim=-1) def forward(self, x, y): """ inputs : x : input feature maps( B X C X H X W) returns : out : attention value + input feature attention: B X (HxW) X (HxW) """ m_batchsize, C, height, width = x.size() # # 生成Q,尺寸变换为(b,c,h,w)->(b,c,w*h)->(b,w*h,c/8) proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1) # 生成K,尺寸变换为(b,c,h,w)->(b,c/8,w*h) proj_key = self.key_conv(y).view(m_batchsize, -1, width*height) # q*k,维度变换为(b,w*h,c/8) * (b,c/8,w*h) = (b,w*h,w*h) energy = torch.bmm(proj_query, proj_key) # 经过softmax生成注意力图,(b,w*h,w*h) attention = self.softmax(energy) # 生成V,维度变换为(b,c,h,w)->(b,c,h*w) proj_value = self.value_conv(y).view(m_batchsize, -1, width*height) # attention * V = (b,c,h*w) * (b,w*h,w*h) = (b,c,w*h) out = torch.bmm(proj_value, attention.permute(0, 2, 1)) # (b,c,w*h)->(b,c,h,w) out = out.view(m_batchsize, C, height, width) out = self.gamma*out + x return out class CCAM_Module(Module): """ Channel attention module""" def __init__(self, in_dim): super(CCAM_Module, self).__init__() self.chanel_in = in_dim self.gamma = Parameter(torch.zeros(1)) self.softmax = Softmax(dim=-1) def forward(self, x, y): """ inputs : x : input feature maps( B X C X H X W) returns : out : attention value + input feature attention: B X C X C """ m_batchsize, C, height, width = x.size() # 生成q,(b,c,h,w)->(b,c,n) proj_query = x.view(m_batchsize, C, -1) # 生成k,(b,c,h,w)->(b,c,n)->(b,n,c) proj_key = y.view(m_batchsize, C, -1).permute(0, 2, 1) # 矩阵相乘,(b,c,n) * (b,n,c) = (b,c,c) energy = torch.bmm(proj_query, proj_key) # 生成energy每一行最大的值,以及对应的索引。这里只取值,将其扩充到energy维度减去energy energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy # 输出注意力map,(b,c,c) attention = self.softmax(energy_new) # 生成V,维度为(b,c,h*w) proj_value = y.view(m_batchsize, C, -1) # (b,c,c)*(b,c,h*w) = (b,c,h*w) out = torch.bmm(attention, proj_value) # (b,c,h*w)->(b,c,h,w) out = out.view(m_batchsize, C, height, width) out = self.gamma*out + x return out 讯享网
最后输出的两个特征图和卷积输出的特征图共同输入到fusion layer:
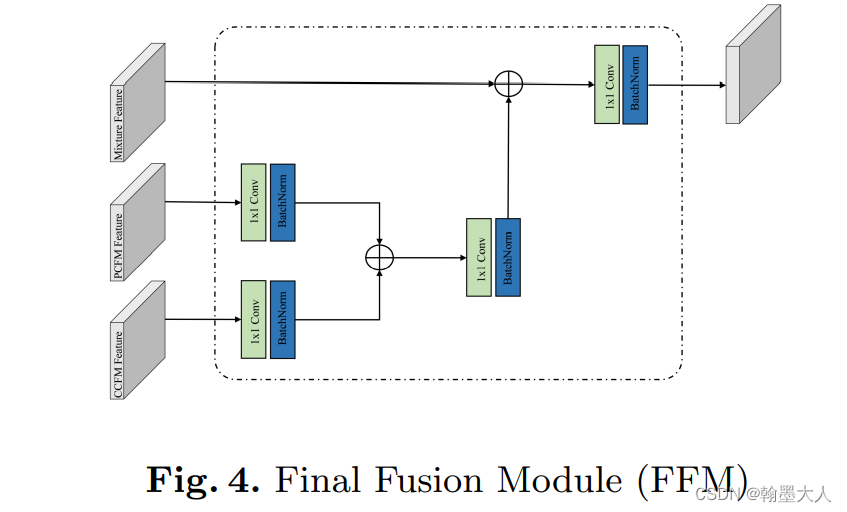
讯享网class FusionLayer(Module): def __init__(self, in_channels, groups=1, radix=2, reduction_factor=4, norm_layer=None): super(FusionLayer, self).__init__() inter_channels = max(in_channels//reduction_factor, 32) # (256或者32) self.radix = radix # 2 self.cardinality = groups self.use_bn = norm_layer is not None self.relu = ReLU(inplace=True) self.fc1_p = Conv2d(in_channels, inter_channels, 1, groups=self.cardinality) # 1024 -> 256 self.fc1_c = Conv2d(in_channels, inter_channels, 1, groups=self.cardinality) # 1024 -> 256 if self.use_bn: self.bn1_p = norm_layer(inter_channels) self.bn1_c = norm_layer(inter_channels) self.fc2_p = Conv2d(inter_channels, in_channels*radix, 1, groups=self.cardinality) # 256 -> 1024 self.fc2_c = Conv2d(inter_channels, in_channels*radix, 1, groups=self.cardinality) # 256 -> 1024 self.rsoftmax = rSoftMax(radix, groups) def forward(self, x, y, z): """ :param x: convolution fusion features,(b,2048,h,w) :param y: position attention features,(b,1024,h,w) :param z: channel attention features,(b,1024,h,w) :return: """ assert self.radix == 2, "Error radix size!" # (b,2048,h,w) batch, rchannel = x.shape[:2] # n, 2048 if self.radix > 1: splited = torch.split(x, rchannel//self.radix, dim=1) # 两个,维度分别为(b,1024,h,w) gap_1 = splited[0] # (b,1024,h,w) gap_2 = splited[1] # (b,1024,h,w) else: gap_1 = x gap_2 = x assert gap_1.shape[1] == y.shape[1], "Error!" assert gap_2.shape[1] == z.shape[1], "Error!" gap_p = sum([gap_1, y]) gap_c = sum([gap_2, z]) gap_p = F.adaptive_avg_pool2d(gap_p, 1) # n, 1024, h, w -> n, 1024, 1, 1 gap_c = F.adaptive_avg_pool2d(gap_c, 1) # n, 1024, h, w -> n, 1024, 1, 1 gap_p = self.fc1_p(gap_p) # n,256,1,1 gap_c = self.fc1_c(gap_c) # n,256,1,1 if self.use_bn: gap_p = self.bn1_p(gap_p) gap_c = self.bn1_c(gap_c) gap_p = self.relu(gap_p) gap_c = self.relu(gap_c) atten_p = self.fc2_p(gap_p) # n, 256, 1, 1 -> n, 2048, 1, 1 atten_c = self.fc2_c(gap_c) # n, 256, 1, 1 -> n, 2048, 1, 1 atten_p = self.rsoftmax(atten_p).view(batch, -1, 1, 1) # (n, 2048) -> (n, 2048, 1, 1) atten_c = self.rsoftmax(atten_c).view(batch, -1, 1, 1) # (n, 2048) -> (n, 2048, 1, 1) if self.radix > 1: attens_p = torch.split(atten_p, rchannel//self.radix, dim=1) # 2(n, 1024, 1, 1) tuple attens_c = torch.split(atten_c, rchannel//self.radix, dim=1) # 2(n, 1024, 1, 1) tuple splited_p = (gap_1, y) # ((n, 1024, h, w),(n, 1024, h, w)) splited_c = (gap_1, y) # ((n, 1024, h, w),(n, 1024, h, w)) out_p = sum([att * split for (att, split) in zip(attens_p, splited_p)]) # (n, 1024, h, w) out_c = sum([att * split for (att, split) in zip(attens_c, splited_c)]) # (n, 1024, h, w) else: out_p = atten_p * y out_c = atten_c * z if self.radix > 1: out = torch.cat([out_p, out_c], 1) # (n, 2048, h, w) else: out = sum([out_p, out_c]) return out.contiguous()
CANet整体模块,首先需要明确的几点:
1:backbone采用resnet50
2:在decoder采用的TransBasicBlock进行上采样

首先定义一些基本函数,然后对RGB和depth分别进行特征提取:
class ACNet(nn.Module): def __init__(self, num_class=37, backbone='ResNet-101', pretrained=False, pcca5=False): super(ACNet, self).__init__() self.pcca5 = pcca5 self.backbone = backbone if self.backbone == 'ResNet-50': layers = [3, 4, 6, 3] else: layers = [3, 4, 23, 3] block = Bottleneck transblock = TransBasicBlock # RGB image branch self.inplanes = 64 self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(64) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2) self.layer3 = self._make_layer(block, 256, layers[2], stride=2) # use PSPNet extractors self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # depth image branch self.inplanes = 64 self.conv1_d = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) self.bn1_d = nn.BatchNorm2d(64) self.relu_d = nn.ReLU(inplace=True) self.maxpool_d = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1_d = self._make_layer(block, 64, layers[0]) self.layer2_d = self._make_layer(block, 128, layers[1], stride=2) self.layer3_d = self._make_layer(block, 256, layers[2], stride=2) self.layer4_d = self._make_layer(block, 512, layers[3], stride=2) """ # merge branch self.atten_rgb_0 = self.channel_attention(64) self.atten_depth_0 = self.channel_attention(64) self.maxpool_m = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.atten_rgb_1 = self.channel_attention(64*4) self.atten_depth_1 = self.channel_attention(64*4) # self.conv_2 = nn.Conv2d(64*4, 64*4, kernel_size=1) #todo 用cat和conv降回通道数 self.atten_rgb_2 = self.channel_attention(128*4) self.atten_depth_2 = self.channel_attention(128*4) self.atten_rgb_3 = self.channel_attention(256*4) self.atten_depth_3 = self.channel_attention(256*4) self.atten_rgb_4 = self.channel_attention(512*4) self.atten_depth_4 = self.channel_attention(512*4) """ self.inplanes = 64 self.layer1_m = self._make_layer(block, 64, layers[0]) self.layer2_m = self._make_layer(block, 128, layers[1], stride=2) self.layer3_m = self._make_layer(block, 256, layers[2], stride=2) self.layer4_m = self._make_layer(block, 512, layers[3], stride=2) # agant module self.agant0 = self._make_agant_layer(64, 64) self.agant1 = self._make_agant_layer(64*4, 64) self.agant2 = self._make_agant_layer(128*4, 128) self.agant3 = self._make_agant_layer(256*4, 256) self.agant4 = self._make_agant_layer(512*4, 512) #transpose layer self.inplanes = 512 self.deconv1 = self._make_transpose(transblock, 256, 6, stride=2) self.deconv2 = self._make_transpose(transblock, 128, 4, stride=2) self.deconv3 = self._make_transpose(transblock, 64, 3, stride=2) self.deconv4 = self._make_transpose(transblock, 64, 3, stride=2) # final blcok self.inplanes = 64 self.final_conv = self._make_transpose(transblock, 64, 3) self.final_deconv = nn.ConvTranspose2d(self.inplanes, num_class, kernel_size=2, stride=2, padding=0, bias=True) self.out5_conv = nn.Conv2d(256, num_class, kernel_size=1, stride=1, bias=True) self.out4_conv = nn.Conv2d(128, num_class, kernel_size=1, stride=1, bias=True) self.out3_conv = nn.Conv2d(64, num_class, kernel_size=1, stride=1, bias=True) self.out2_conv = nn.Conv2d(64, num_class, kernel_size=1, stride=1, bias=True) if self.pcca5: self.conv_5a = nn.Sequential(nn.Conv2d(2048, 512, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(512), nn.ReLU()) self.conv_5c = nn.Sequential(nn.Conv2d(2048, 512, kernel_size=3, stride=1, padding=1, bias=False), nn.BatchNorm2d(512), nn.ReLU()) self.pca_5 = PCAM_Module(512) self.cca_5 = CCAM_Module(512) """ self.pconv_5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False), BatchNorm2d(512), nn.ReLU()) self.cconv_5 = nn.Sequential(nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False), BatchNorm2d(512), nn.ReLU()) self.pconv_out = nn.Sequential(nn.Conv2d(512, 2048, kernel_size=3, stride=1, padding=1, bias=False), BatchNorm2d(2048), nn.ReLU(), nn.Dropout2d(0.1, False)) self.cconv_out = nn.Sequential(nn.Conv2d(512, 2048, kernel_size=3, stride=1, padding=1, bias=False), BatchNorm2d(2048), nn.ReLU(), nn.Dropout2d(0.1, False)) self.alpha = Parameter(torch.ones(1)) self.beta = Parameter(torch.ones(1)) """ self.pconv_5 = nn.Sequential(nn.Conv2d(512, 1024, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(1024), nn.ReLU()) self.cconv_5 = nn.Sequential(nn.Conv2d(512, 1024, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(1024), nn.ReLU()) self.split_conv = FusionLayer(in_channels=1024, groups=1,radix=2, reduction_factor=4, norm_layer=nn.BatchNorm2d) # weight initial for m in self.modules(): if isinstance(m, nn.Conv2d): n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels m.weight.data.normal_(0, math.sqrt(2. / n)) elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() if pretrained: self._load_resnet_pretrained()其中分别调用了_make_layer函数,block函数,_make_agant_layer函数,_make_transpose函数。
1:_make_layer函数,将输入维度,输出维度,步长,上采样输入到block函数,返回的是一个列表,里面是block个layer。
讯享网 def _make_layer(self, block, planes, blocks, stride=1, dilation=1): downsample = None if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample)) self.inplanes = planes * block.expansion for i in range(1, blocks): layers.append(block(self.inplanes, planes, dilation=dilation)) return nn.Sequential(*layers)
2:block函数,就是一个普通的残差网络,维度由输入的inplane,到输出的inplane*4。
class Bottleneck(nn.Module): expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, dilation=1): super(Bottleneck, self).__init__() self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False) self.bn1 = nn.BatchNorm2d(planes) self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, dilation=dilation, padding=dilation, bias=False) self.bn2 = nn.BatchNorm2d(planes) self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) self.bn3 = nn.BatchNorm2d(planes * 4) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out 3:_make_agant_layer函数,将刚才四倍输出变为原来的维度。
讯享网 def _make_agant_layer(self, inplanes, planes): layers = nn.Sequential( nn.Conv2d(inplanes, planes, kernel_size=1, stride=1, padding=0, bias=False), nn.BatchNorm2d(planes), nn.ReLU(inplace=True) ) return layers
4:_make_transpose函数。使用nn.ConvTranspose2d进行上采样,将layer放在一起,生成序列。这里的block是TransBasicBlock。
def _make_transpose(self, block, planes, blocks, stride=1): upsample = None if stride != 1: upsample = nn.Sequential( nn.ConvTranspose2d(self.inplanes, planes, kernel_size=2, stride=stride, padding=0, bias=False), nn.BatchNorm2d(planes), ) elif self.inplanes != planes: upsample = nn.Sequential( nn.Conv2d(self.inplanes, planes, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(planes), ) layers = [] for i in range(1, blocks): layers.append(block(self.inplanes, self.inplanes)) layers.append(block(self.inplanes, planes, stride, upsample)) self.inplanes = planes return nn.Sequential(*layers) 接着对rgb和depth进行提取:
讯享网 def encoder(self, rgb, depth): rgb = self.conv1(rgb) rgb = self.bn1(rgb) rgb = self.relu(rgb) depth = self.conv1_d(depth) depth = self.bn1_d(depth) depth = self.relu_d(depth) m0 = rgb + depth rgb = self.maxpool(rgb) depth = self.maxpool_d(depth) m = self.maxpool(m0) # block 1 rgb = self.layer1(rgb) depth = self.layer1_d(depth) m = self.layer1_m(m) m1 = m + rgb + depth # block 2 rgb = self.layer2(rgb) depth = self.layer2_d(depth) m = self.layer2_m(m1) m2 = m + rgb + depth # block 3 rgb = self.layer3(rgb) depth = self.layer3_d(depth) m = self.layer3_m(m2) m3 = m + rgb + depth # block 4 rgb = self.layer4(rgb) depth = self.layer4_d(depth) m = self.layer4_m(m3) if self.pcca5: rgb_down = self.conv_5a(rgb) depth_down = self.conv_5c(depth) attention_position = self.pca_5(rgb_down, depth_down) attention_channel = self.cca_5(rgb_down, depth_down) p_out = self.pconv_5(attention_position) c_out = self.cconv_5(attention_channel) m4 = self.split_conv(m, p_out, c_out) """ smooth_p = self.pconv_5(attention_position) smooth_c = self.cconv_5(attention_channel) p_out = self.pconv_out(smooth_p) c_out = self.cconv_out(smooth_c) m4 = m + self.alpha * p_out + self.beta * c_out """ else: m4 = m + rgb + depth return m0, m1, m2, m3, m4 # channel of m is 2048
最后输入进decoder:
def decoder(self, fuse0, fuse1, fuse2, fuse3, fuse4): agant4 = self.agant4(fuse4) # upsample 1 x = self.deconv1(agant4) if self.training: out5 = self.out5_conv(x) x = x + self.agant3(fuse3) # upsample 2 x = self.deconv2(x) if self.training: out4 = self.out4_conv(x) x = x + self.agant2(fuse2) # upsample 3 x = self.deconv3(x) if self.training: out3 = self.out3_conv(x) x = x + self.agant1(fuse1) # upsample 4 x = self.deconv4(x) if self.training: out2 = self.out2_conv(x) x = x + self.agant0(fuse0) # final x = self.final_conv(x) out = self.final_deconv(x) if self.training: return out, out2, out3, out4, out5 return out 将encoder输出作为decoder输入,整个模型就搭建完毕了。
讯享网 def forward(self, rgb, depth, phase_checkpoint=False): fuses = self.encoder(rgb, depth) m = self.decoder(*fuses) return m
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/34243.html