
摘要
网络剪枝被广泛应用于神经网络模型的轻量化和加速。结构化网络修剪会丢弃整个神经元或滤波器,导致精确度损失。在这项工作中,我们提出了一种新的神经元合并的概念,它既适用于完全连通层,也适用于卷积层,它补偿了由于修剪神经元/滤波器而造成的信息损失。神经元合并首先将初始权值分解成两个矩阵/张量。其中一个成为当前层的新权重,另一个是我们所称的缩放矩阵,指导神经元的组合。如果激活函数重新确定,则在一定条件下,尺度矩阵可以被吸收到下一层,补偿被移除的神经元。我们还提出了一种无数据、低成本的权值分解方法,利用神经元之间的余弦相似性进行权值分解。与相同拓扑结构的剪枝模型相比,我们的合并模型更好地保留了原始模型的输出特征映射;因此,它在没有微调的情况下保持了剪枝后的精度。我们展示了我们的方法在不同模型架构和数据集的网络剪枝上的有效性。例如,对于CIFAR-10上的VGG-16,我们在没有任何微调的情况下,在减少64%的总参数的同时,获得了93.16%的准确率。
1.介绍
现代卷积神经网络(CNN)模型在许多计算机视觉任务中表现出优异的性能。然而,由于其众多的参数和计算,将其部署到移动电话或边缘设备上仍然具有挑战性。一种广泛使用的减轻和加速网络的方法是修剪。网络修剪利用了网络高度过度参数化的发现。例如,Denil等人。[1]证明了仅用网络原始参数的一小部分就可以有效地重构网络。
一般来说,网络修剪有两个主要分支。其中之一是非结构化修剪,也称为权重修剪,它会移除单个网络连接。Han等人[2]通过对小分量权重进行修剪并对模型进行再训练,达到了90%的压缩率。然而,非结构化剪枝产生稀疏权矩阵,如果没有专门的硬件或[3]库,就不能导致实际的加速和压缩。另一方面,结构化剪枝方法消除了整个神经元甚至模型层,而不是单个连接。由于结构修剪保持了原有的权重结构,因此不需要专门的硬件或库来加速。CNN模型最普遍的结构化剪枝方法是对每个卷积层的滤波器和相应的输出特征映射通道进行剪枝。要移除的过滤器或通道是由不同的显著性标准决定的。
无论使用什么显著性标准,都会从下一层去除修剪神经元的相应通道。因此,下一层的输出将不会与剩余的神经元完全重组。特别地,当前层的神经元被移除时,重建误差继续累积,这导致性能下降[27]。
在本文中,我们提出了神经元合并,通过合并下一层神经元对应的维度来补偿被移除神经元的影响。神经元合并既适用于完全连通的层,也适用于卷积层,应用于卷积层的总体概念如图1所示。神经元合并首先将初始权值分解成两个矩阵/张量。其中一个成为当前层的新权重,另一个是我们所称的缩放矩阵,指导合并下一层的维度的过程。如果激活函数重新生成,且尺度矩阵满足一定条件,则可以将其吸收到下一层;因此,合并具有与剪枝相同的网络拓扑。
在这个公式中,我们还提出了一种简单且无数据的神经元合并方法。为了形成剩余的权重,我们利用众所周知的剪枝标准(例如,L1范数[15])。为了生成尺度矩阵,我们利用神经元之间的余弦相似度和L2范数比。即使只给出了预先训练的模型,没有任何训练数据,这种方法也是适用的。我们的大量实验证明了我们方法的有效性。对于CIFAR-10上的VGG-16[21]和WideResNet 404[28],我们在没有任何微调的情况下分别获得了93.16%和93.3%的准确率,同时分别减少了64%和40%的总参数。我们的贡献如下
- 我们提出并制定了一个神经元合并的概念,以补偿由于在完全连接层和卷积层中修剪的神经元/过滤器所造成的信息损失。
- 出了一种基于余弦相似度和神经元间比值的一次无数据神经元合并方法。
- 结果表明,与剪枝模型相比,我们的合并模型在剪枝后的即时精度、特征地图可视化和加权平均重建误差等方面都能更好地保留原始模型。
2 相关工作
人们提出了多种标准[5,6,15,18,26,27]来评估神经元的重要性,对于CNN,它是一个过滤器。然而,所有这些算法在剪枝后都出现了明显的准确率下降。因此,微调修剪后的模型通常需要与训练原始模型一样多的epoch,以恢复接近原始模型的精度。一些著作[16,25]将可训练参数添加到每个特征映射通道,以获得数据驱动的通道稀疏性,使模型能够自动识别冗余滤波器。在这种情况下,从零开始训练模型不可避免地会获得信道稀疏性,这是一个耗费时间和资源的过程。
在filter pruningworks中,Luo等人的[17]和He等人的[7]与我们的动机相似,目的是类似地重构下一层的输出特征图。Luo等人[17]搜索对下一层输出特征映射影响最小的滤波器子集。他等人提出了基于LASSO回归的通道选择和输出特征映射的最小二乘重构。在这两篇论文中,都需要数据样本来获得特征地图。然而,我们的方法是新颖的,因为它补偿了删除滤波器的损失,在一个一次性和无数据的方式。
Srinivas和Babu[22]通过迭代总结两个相似神经元的系数,为完全连通的层引入了无数据神经元修剪。与[22]不同的是,神经元合并引入了不同的公式,包括尺度矩阵,以系统地合并神经元的比例,并适用于各种模型结构,如具有批量归一化的卷积层。最近,穆赛等人。[19]通过找到神经元的核集并丢弃其余部分来近似下一层的输出。
Pruning-at-initialization方法[14,23]提前修剪单个连接,以节省训练时的资源。使用梯度来测量连接的重要性。相比之下,我们的方法适用于结构化剪枝,因此不需要专门的硬件或库来处理稀疏连接。同样,我们的方法也可以在不考虑修剪的情况下对模型进行训练。
正则多元(CP)分解[12]和Tucker分解[10]被广泛用于减轻卷积核张量。乍一看,我们的方法类似于行秩近似,因为它从把权矩阵/张量分解成两部分开始。与行秩近似不同,我们在推理时不保留所有分解的矩阵/张量。相反,我们将其中一个分解矩阵与下一层相结合,并实现与结构化网络剪枝相同的加速。

3 方法
首先,我们从数学上阐述了全连接层中神经元合并的新概念。然后,我们展示了如何将合并应用于卷积层。在第3.3节中,我们介绍了一种可能的无数据合并方法。
3.1 全连接层
为简单起见,我们从完全连接层开始,没有 b i a s bias bias,设 N i N_i Ni表示第 i i i个完全连接层的输入列向量的长度。第 i i i个全连接层将输入向量 x i ∈ R N i \mathbf{x}_{i} \in \mathbb{R}^{N_{i}} xi∈RNi变换为输出向量 x i + 1 ∈ R N i + 1 \mathbf{x}_{i+1} \in \mathbb{R}^{N_{i+1}} xi+1∈RNi+1。第i层的网络权值记为 W i ∈ R N i × N i + 1 \mathbf{W}_{i} \in \mathbb{R}^{N_{i} \times N_{i+1}} Wi∈RNi×Ni+1。
我们的目标是保持第 ( i + 1 ) (i+1) (i+1)层的激活向量,即 a i + 1 = W i + 1 ⊤ f ( W i ⊤ x i ) \mathbf{a}_{i+1}=\mathbf{W}_{i+1}^{\top} f\left(\mathbf{W}_{i}^{\top} \mathbf{x}_{i}\right) ai+1=Wi+1⊤f(Wi⊤xi)其中 f f f是激活函数

现在,我们将权重矩阵 W i W_i Wi分解成两个矩阵 Y i ∈ R N i × P i + 1 \mathbf{Y}_{i} \in \mathbb{R}^{N_{i} \times P_{i+1}} Yi∈RNi×Pi+1
和 Z i ∈ R P i + 1 × P i \mathbf{Z}_{i} \in \mathbb{R}^{P_{i+1} \times P_{i}} Zi∈RPi+1×Pi。其中 0 < P i + 1 ≤ N i + 1 0<P_{i+1} \leq N_{i+1} 0<Pi+1≤Ni+1,因而 W i ≈ Y i Z i \mathbf{W}_{i} \approx \mathbf{Y}_{i} \mathbf{Z}_{i} Wi≈YiZi。然后等式1可以近似为 a i + 1 ≈ W i + 1 ⊤ f ( Z i ⊤ Y i ⊤ x i ) \mathbf{a}_{i+1} \approx \mathbf{W}_{i+1}^{\top} f\left(\mathbf{Z}_{i}^{\top} \mathbf{Y}_{i}^{\top} \mathbf{x}_{i}\right) ai+1≈Wi+1⊤f(Zi⊤Yi⊤xi)
神经元合并的关键思想是将 Z i Z_i Zi和 W i + 1 W_{i+1} Wi+1结合起来,即下一层的权重。为了将 Z i Z_i Zi移出激活函数, f f f应该是 R e L U ReLU ReLU, Z i Z_i Zi需要有一定的约束条件。
定义1:

定理1的证明见附录。若 f f f为 R e L U ReLU ReLU且 z i z_i zi满足定理 1 1 1的条件,则公式2推导为: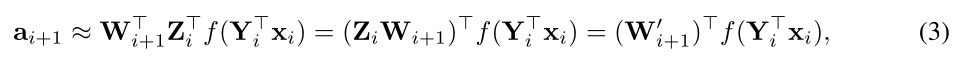
其中 W i + 1 ′ = Z i W i + 1 ∈ R P i + 1 × N i + 2 \mathbf{W}_{i+1}^{\prime}=\mathbf{Z}_{i} \mathbf{W}_{i+1} \in \mathbb{R}^{P_{i+1} \times N_{i+2}} Wi+1′=ZiWi+1∈RPi+1×Ni+2,如图2所示,合并后第 i + 1 i+1 i+1层的神经元数量由 N i + 1 N_{i+1} Ni+1减少到 P i + 1 P_{i+1} Pi+1。因此, y i y_i yi表示保留在第 i i i层的新的权值, z i z_i zi为缩放矩阵,表示如何补偿被移除的神经元。我们在附录中为带有偏置的全连接层提供了相同的推导。
3.2 卷积层
为了在卷积层中合并,我们首先定义两个n向张量的算子。
n-mode product:根据Kolda和Bader[11],张量 X ∈ R I 1 × I 2 × ⋯ × I N \mathcal{X} \in \mathbb{R}^{I_{1} \times I_{2} \times \cdots \times I_{N}} X∈RI1×I2×⋯×IN与矩阵 U ∈ R J × I n \mathbf{U} \in \mathbb{R}^{J \times I_{n}} U∈RJ×In的n模(矩阵)积由 X × n U \mathcal{X} \times_{n} \mathbf{U} X×nU表示,其大小为 I 1 + ⋯ + I n − 1 + I n − 1 × J × I n + 1 × ⋯ × I N I_{1}+ \cdots+I_{n-1}+I_{n-1} \times J \times I_{n+1} \times \cdots \times I_{N} I1+⋯+In−1+In−1×J×In+1×⋯×IN。
从本质上讲,我们有
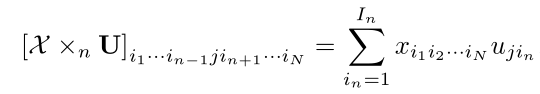
Tensor-wise convolution:定义了四向张量 W ∈ R N × C × K × K \mathcal{W} \in \mathbb{R}^{N \times C \times K \times K} W∈RN×C×K×K与三向张量 X ∈ R C × H × W \mathcal{X} \in \mathbb{R}^{C \times H \times W} X∈RC×H×W之间的张量卷积算子 ⊛ ⊛ ⊛。简单地说,我们假设卷积的步幅为1。然而,这种表示法可以推广到其他的卷积设置。
从本质上讲,我们有
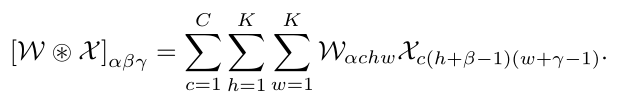
直观地, W ⊛ X \mathcal{W}⊛\mathcal{X} W⊛X表示由 X \mathcal{X} X和 W \mathcal{W} W的每个滤波器之间的3D卷积运算产生的输出特征映射矩阵的通道级联。
合并卷积图层:现在我们将神经元合并扩展到卷积层。与完全连接层类似设 N i N_i Ni和 N i + 1 N_{i+1} Ni+1表示第 i i i个卷积层的输入输出通道数。第 i i i个卷积层将输入特征映射 X i ∈ R N i × H i × W i \mathcal{X}_{i} \in \mathbb{R}^{N_{i} \times H_{i} \times W_{i}} Xi∈RNi×Hi×Wi转换成输出特征映射 X i + 1 ∈ R N i + 1 × H i + 1 × W i + 1 \mathcal{X}_{i+1} \in \mathbb{R}^{N_{i+1} \times H_{i+1} \times W_{i+1}} Xi+1∈RNi+1×Hi+1×Wi+1。第 i i i层的滤波器权值记为 W i ∈ R N i + 1 × N i × K × K \mathcal{W}_{i} \in \mathbb{R}^{N_{i+1} \times N_{i} \times K \times K} Wi∈RNi+1×Ni×K×K由 N i + 1 N_{i+1} Ni+1个滤波器组成。
我们的目标是保持第 i + 1 i + 1 i+1层的激活特征图,即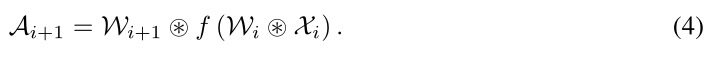
我们将4向张量 W i W_i Wi分解为矩阵 Z i ∈ R P i + 1 × N i + 1 \mathbf{Z}_{i} \in \mathbb{R}^{P_{i+1} \times N_{i+1}} Zi∈RPi+1×Ni+1和4向张量 Y i ∈ R P i + 1 × N i × K × K \mathcal{Y}_{i} \in \mathbb{R}^{P_{i+1} \times N_{i} \times K \times K} Yi∈RPi+1×Ni×K×K。

则Eq. 4近似为: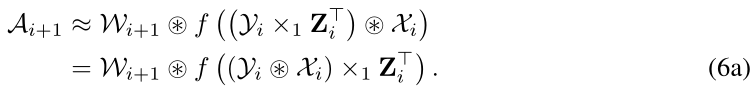
神经元合并的关键思想是将 Z i Z_i Zi和 W i + 1 W_{i+1} Wi+1相结合,即下一层的权重。如果 f f f是 R e l u Relu Relu,we can extend Theorem 1 to a 1-mode product of tensor。
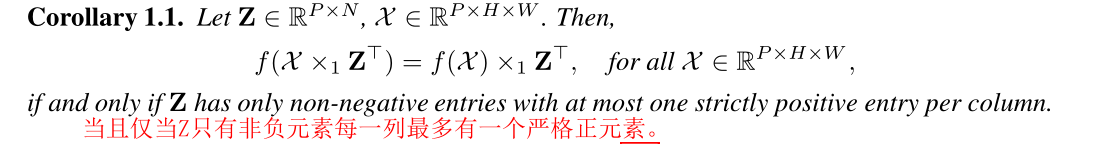
若 f f f是 R e L U ReLU ReLU且 Z i Z_i Zi满足推论1.1的条件
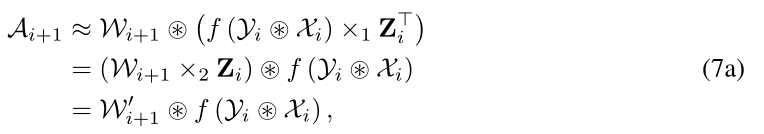
其中 W i + 1 ′ = ( W i + 1 × 2 Z i ) ∈ R N i + 2 × P i + 1 × K × K \mathcal{W}_{i+1}^{\prime}=\left(\mathcal{W}_{i+1} \times_{2} \mathbf{Z}_{i}\right) \in \mathbb{R}^{N_{i+2} \times P_{i+1} \times K \times K} Wi+1′=(Wi+1×2Zi)∈RNi+2×Pi+1×K×K。推论1.1(式6a, 7a)的证明见附录。式6a和7a。合并后,第 i i i个卷积层中的滤波器数量由 N i + 1 N_{i+1} Ni+1减少到 P i + 1 P_{i+1} Pi+1,因此网络拓扑结构与结构化剪枝相同。当 Z i Z_i Zi与第 i + 1 i+1 i+1层的权值合并时,修剪后的维度被吸收到剩余的维度中,如图1所示。
3.3 提出算法
神经元合并的整个过程如下。首先,我们将权重分解为两部分。 Y i / Y i \mathbf{Y}_{i} / \mathcal{Y}_{i} Yi/Yi表示保留在第 i i i层的新权值, Z i Z_i Zi为缩放矩阵。在分解之后, Z i Z_i Zi与下一层的权重结合,如3.1和3.2节所述。因此,实际的补偿是通过合并下一层的维度来实现的。修剪后的神经元对应的维数乘以一个正数,然后再与保留后的神经元的维数相加。
现在我们提出一种简单的一次性方法来分解权矩阵/张量为两部分。首先,我们选择最有用的神经元来形成 Y i / Y i \mathbf{Y}_{i} / \mathcal{Y}_{i} Yi/Yi。我们可以利用任何修剪标准。然后,我们通过为每个修剪后的神经元选择最相似的剩余神经元并测量它们之间的比率来生成 Z i Z_i Zi。算法1描述了全连通层一维神经元的整体分解过程。在将每个三维滤波张量重塑为一维向量之后,将相同的算法应用于卷积滤波器。
根据定理1,如果一个修剪后的神经元可以表示为剩余神经元的正倍数,我们可以在不造成输出向量损失的情况下对其进行去除和补偿。这让我们对确定相似神经元的标准有了一个重要的认识:方向,而不是绝对距离。因此,我们使用余弦相似度来选择相似的神经元。算法2演示了选择与给定神经元最相似的神经元并获得它们之间的比例。我们将量表值设为两个神经元的l2-norm比值。刻度值表示下一层移除的神经元的补偿量。
这里我们引入了超参数 t t t;只有当两个神经元之间的相似性达到以上时,我们才进行补偿。如果为1,则所有被修剪的神经元都被补偿,并且被补偿的神经元数目随着t接近1而减少。如果没有被移除的神经元被补偿,结果与香草修剪完全相同。换句话说,修剪可以被认为是神经元合并的特例。
Batch normalization layer:对于现代CNN体系结构,批处理规范化[9]被广泛用于防止内部协变量移位。如果在卷积层后进行批处理归一化,则两个相同滤波器的输出特征映射通道可能不同。因此,在选择最相似的滤波器时,我们引入一个额外的术语来考虑。
设 X ∈ R c × h × w \mathcal{X} \in \mathbb{R}^{c \times h \times w} X∈Rc×h×w表示卷积层的输出特征图,
X B N ∈ R c × h × w \mathcal{X}^{B N} \in \mathbb{R}^{c \times h \times w} XBN∈Rc×h×w表示批次归一化层之后的 X \mathcal{X} X。批处理归一化层包含四种类型的参数: γ , β , μ , σ ∈ R c \gamma, \boldsymbol{\beta}, \boldsymbol{\mu}, \boldsymbol{\sigma} \in \mathbb{R}^{c} γ,β,μ,σ∈Rc。

根据公式8,如果 B \mathcal{B} B为0, x 2 B N x_{2}^{B N} x2BN与 x 1 B N x_{1}^{B N} x1BN的比值就是 S \mathcal{S} S。我们选择同时使余弦距离 ( 1 − C o s i n e S i m ) (1 − CosineSim) (1−CosineSim)和偏置距离 ( ∣ B ∣ / S ) (|\mathcal{B}| / \mathcal{S}) (∣B∣/S)最小的滤波器,然后使用 S \mathcal{S} S作为尺度。我们将0到1之间的 b i a s bias bias距离归一化。算法3描述了具有批归一化的卷积层的总体选择过程。输入包括卷积层的第 n n n个滤波器,表示为 F n F_n Fn。采用超参数λ来控制余弦距离和偏置距离之间的比值。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/31083.html