
在搜索业务下有一个场景叫实时搜索(Instance Search),就是在用户不断输入过程中,实时返回查询结果。
此次赛题来自OPPO手机搜索排序优化的一个子场景,并做了相应的简化,意在解决query-title语义匹配的问题。简化后,本次题目内容主要为一个实时搜索场景下query-title的ctr预估问题。本次赛题为开放型算法挑战赛,优秀的解决方案会对我们解决这个场景以及其它场景下的问题带来极大的启发。我们期待优秀的你和你的团队能够投入进来!OPPO场景:
讯享网题目内容基于百万最新真实用户搜索数据的实时搜索场景下搜索结果ctr预估。给定用户输入prefix(用户输入,查询词前缀)以及文章标题、文章类型等数据,预测用户是否点击。文章资源类别非全网资源,属部分垂直领域内容。初赛后期开放B榜开放时间3小时,请在三小时内提交结果;初赛结束时需要提交完整代码,最终晋级复赛前100名;复赛全程采用线上赛形式。
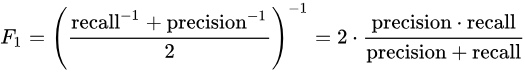 另外本赛题对模型数量进行了限制,至多只能使用一个模型,即单模。下面是官方给出的一些具体介绍和解释。 1.对于大家说的nn类模型数量限制问题,原则上认为训练出来的权重文件个数即为模型数量的参考值,允许自定义庞大的网络结构,但是需要注意在限定时间内完成训练和预测等 2.传统机器学习算法如xgb等树模型每训练出来一个权重文件则视为一个模型数量 3.可能大家争议的K折问题,大家正常理解的对一个模型进行K折交叉验证,训练出来一个权重文件的情况属于一个模型,多模型的K折做法是技术圈公开的这种(对xgb训练了5次,且分别预测五次结果,再取平均,这样的做法是明确的多模型融合,最多只能取两次):
另外本赛题对模型数量进行了限制,至多只能使用一个模型,即单模。下面是官方给出的一些具体介绍和解释。 1.对于大家说的nn类模型数量限制问题,原则上认为训练出来的权重文件个数即为模型数量的参考值,允许自定义庞大的网络结构,但是需要注意在限定时间内完成训练和预测等 2.传统机器学习算法如xgb等树模型每训练出来一个权重文件则视为一个模型数量 3.可能大家争议的K折问题,大家正常理解的对一个模型进行K折交叉验证,训练出来一个权重文件的情况属于一个模型,多模型的K折做法是技术圈公开的这种(对xgb训练了5次,且分别预测五次结果,再取平均,这样的做法是明确的多模型融合,最多只能取两次):
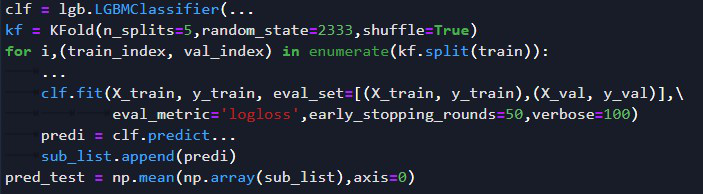
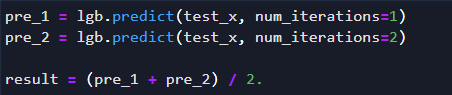
对于个别选手提出的树模型如(lgb)预测时每次取不同参数预测然后融合(如取平均)的做法属于“”同一网络结构但参数不同“”的范畴,举例如下:

2. 传统模型



3. NN模型
4. 模型融合

完整代码:https://github.com/bettenW/TIANCHI_OGeek_Rank2
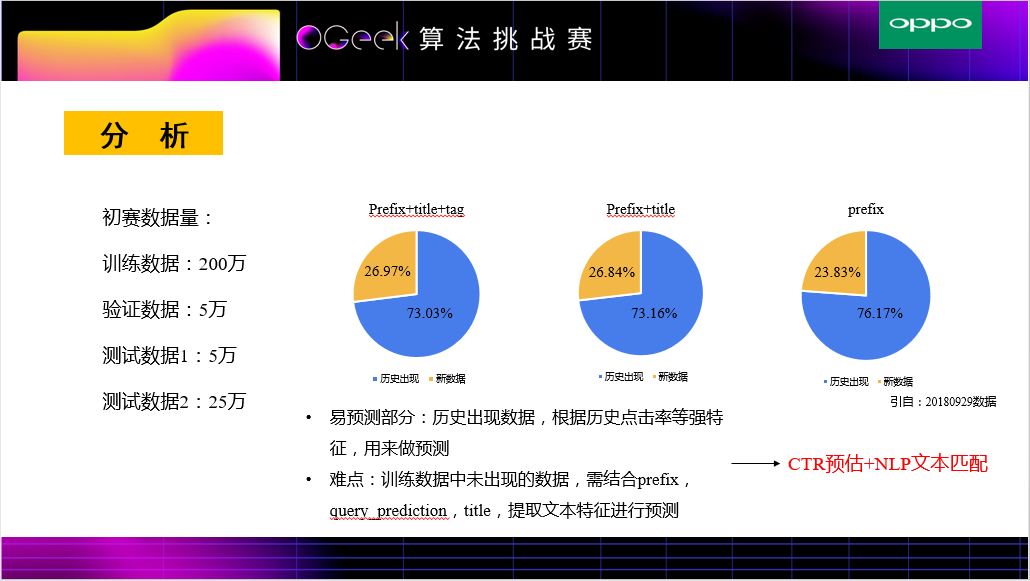
1. 数据分析
这一部分将会对部分数据进行分析,另外获取部分特征的点击率分布情况判断特征效果,看分布可以有一个很好的初步验证作用。
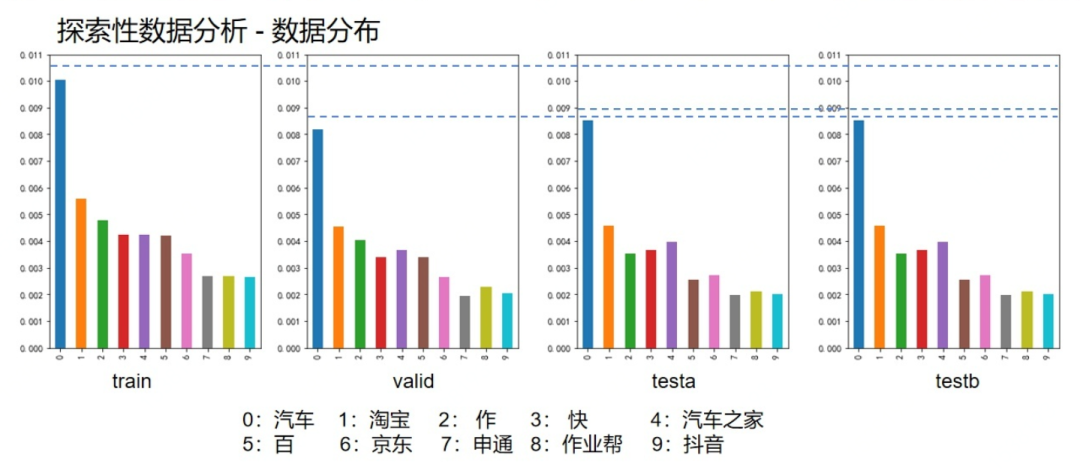
这四个图是prefix在各自数据集的百分比统计,并以训练集中出现频次top10的prefix画出了每个数据集的占比情况,可以发现valid与testa和testb的分布相似,说明valid与testa和testb的查询时间比较接近,作为验证集线下比较可信。
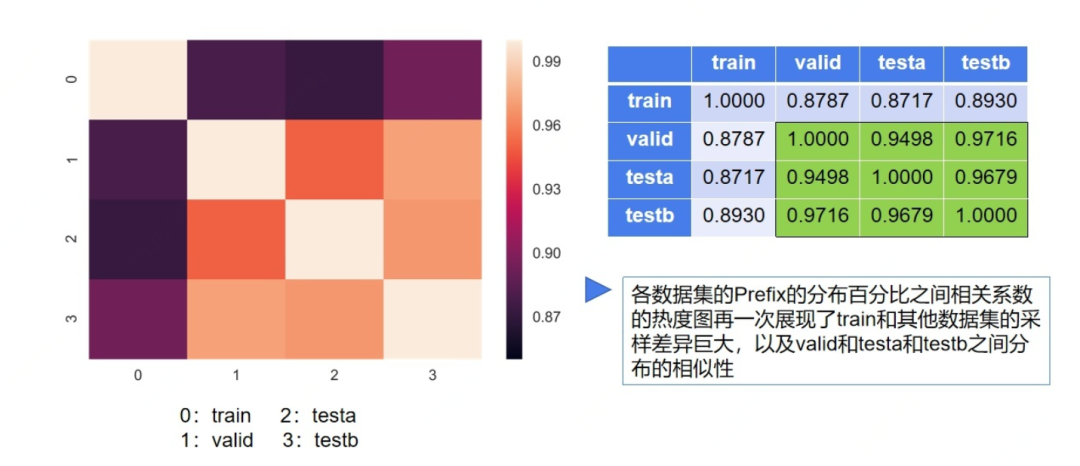
此处更近一步分析了train和testa、testb有较大的差异性。

我们对数据做了一些分析,发现:
(1)用户有可能会拼错prefix,如抖音 拼写成 枓音,分析发现,使用pinying会比中文大幅度减少不同值的出现次数,当然也有一部分不是拼写错误的,如痘印,所以最后我们中文和拼音的两部分特征都使用了。
(2)由于这是实时性比较强的搜索场景,分析发现,测试集中会有很大一部分prefix和title未在训练集中出现过。
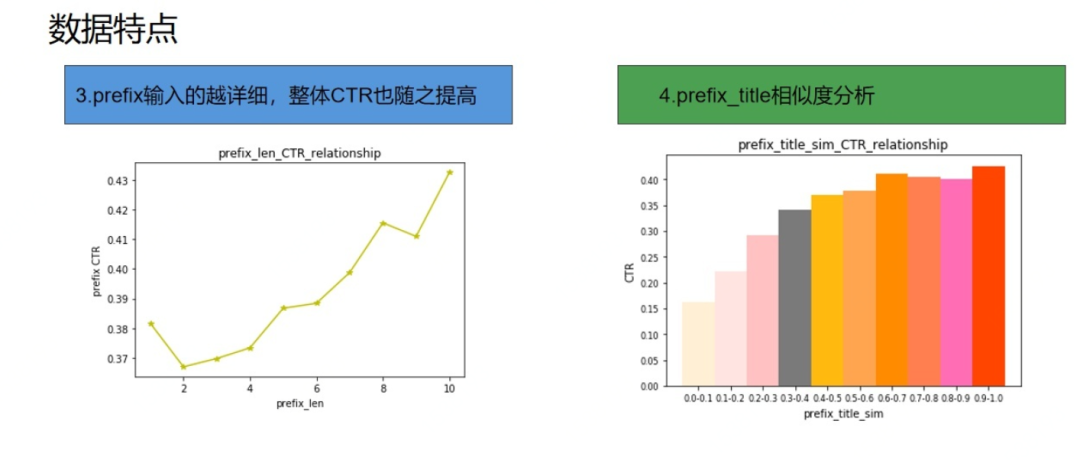
除基础数据分析外,我们还分析了部分特征,比如prefix的长度特征,其用户输入prefix越详细,整体CTR也随之提高,其他特征的长度也有类似的趋势。
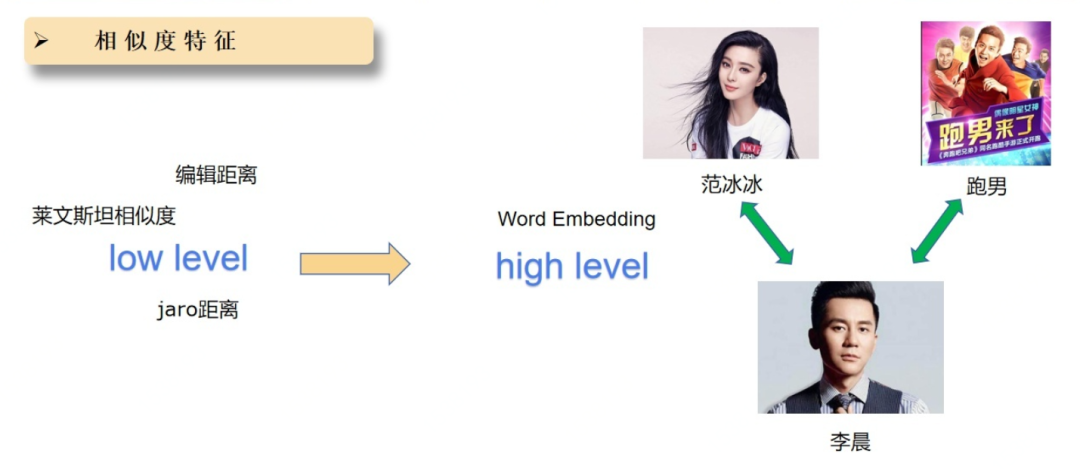
另外,相似度特征是非常重要的特征,prefix和title越相似度,点击的可能就越高。


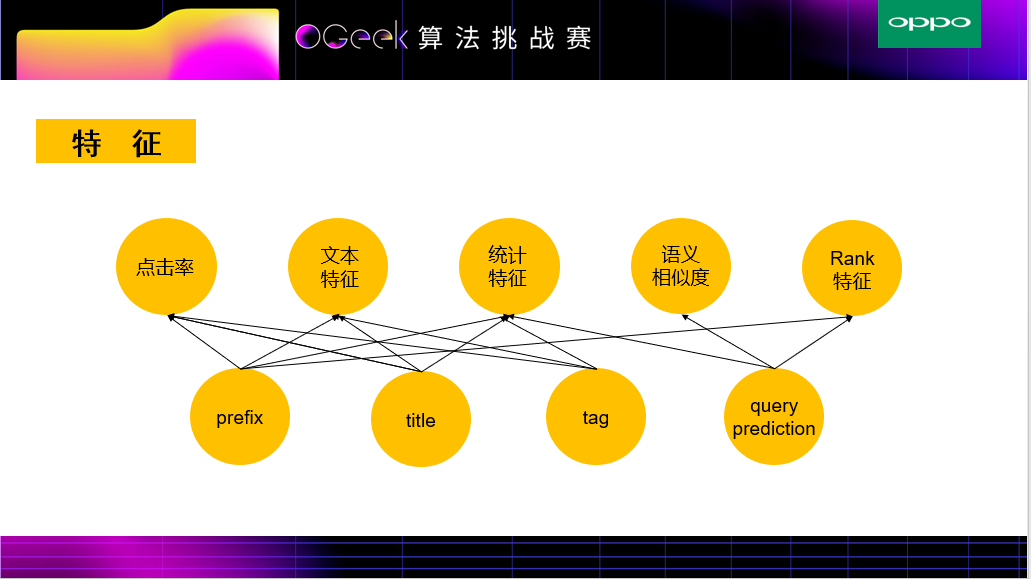
2. 特征工程(如何描述好两个实体?)

由于赛题的特殊性,给了我们验证集,通过观察训练集和验证集的数据,我们发现存在热点转移的情况,例如关于某个明星,title 1是高热点转换网页,可是到了验证集中,这位明星zhe'w的高热点title是另外的一些网页,说明实时热点性比较强

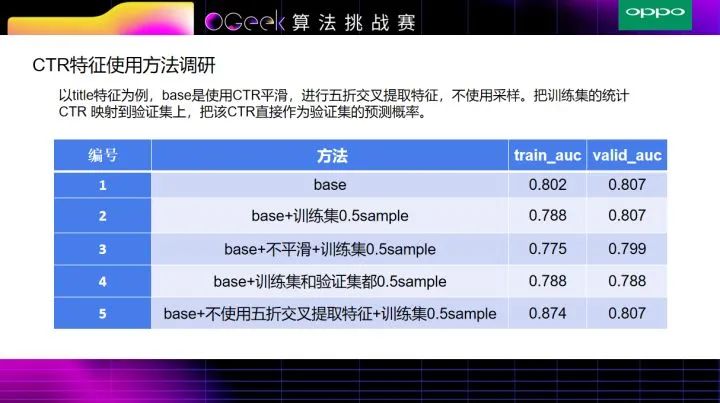
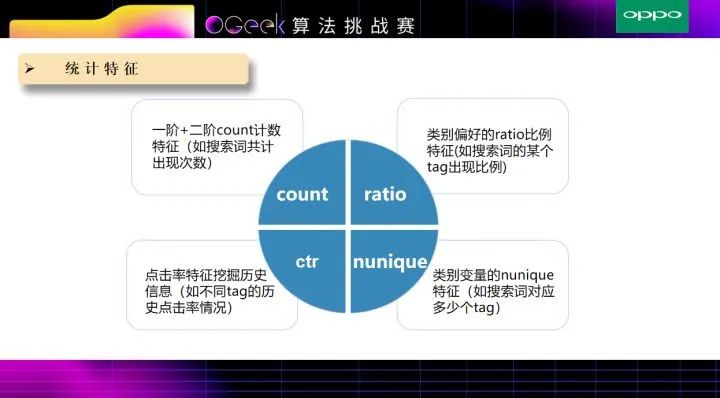
接下来是最关键的CTR特征。如果CTR特征做的不好,那就非常容易过拟合。我们这边采用了多种方式来防止过拟合,分别是多折交叉提取特征,平滑,以及采样。
从表格中(5)可以看出,不使用五折交叉提取特征,训练集的auc比验证集的auc高很多,这就非常容易过拟合,导致线上结果很差,(2)->(3)的过程就是相差了一个平滑,从而导致训练集和验证集上的auc都有所下降;此外,在我们的方法中加入了采样,是为了使得训练集和验证集结果都不会过拟合。
正如上表(4)所示,加入采样之后,训练集和验证集的auc都会有所降低,当然对非常近的数据可能不利,但是对训练集和测试集相隔比较远的数据,随热点的转移,CTR也会有所改善。

用了五折提取CTR,同时对于每一折,进行了0.5的sample
3. 算法模型
对于此次比赛我们对传统机器学习模型以及深度模型都进行了尝试。
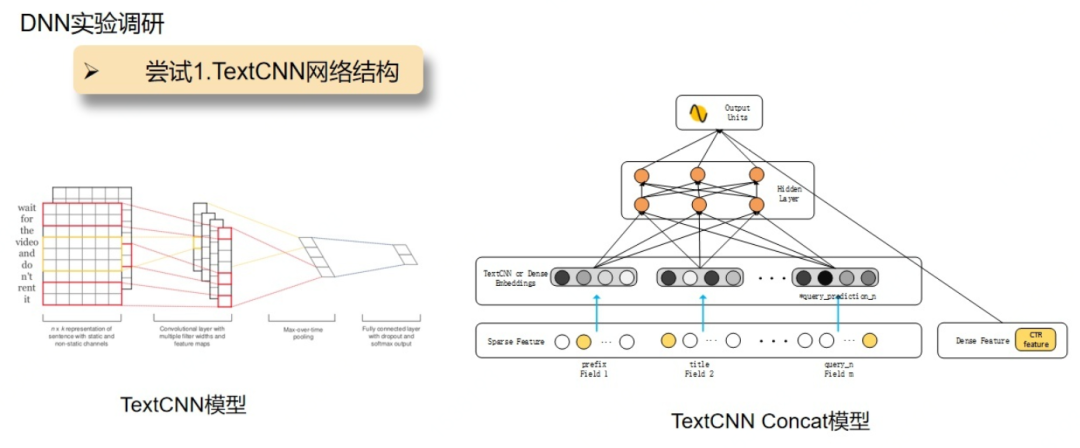
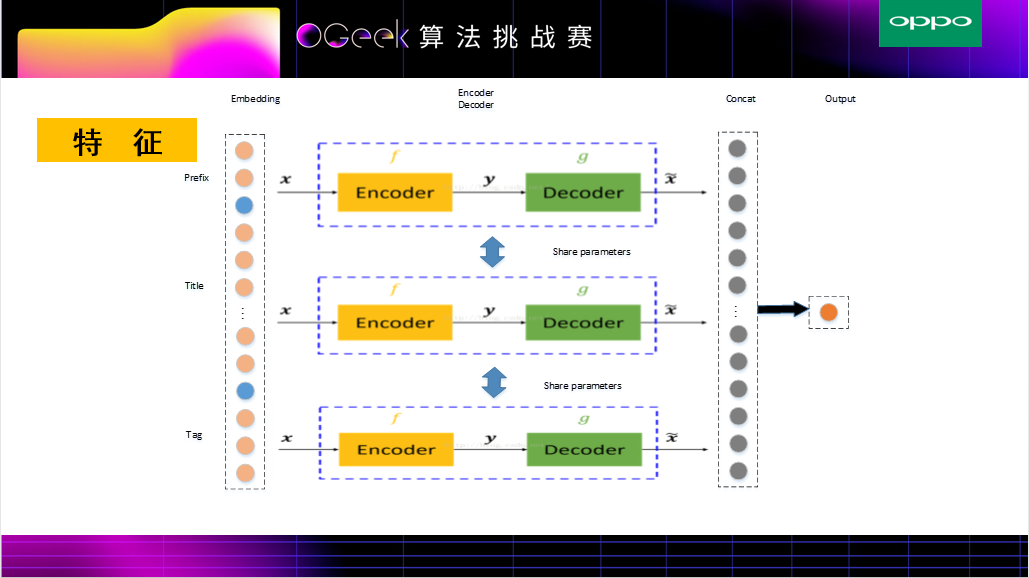
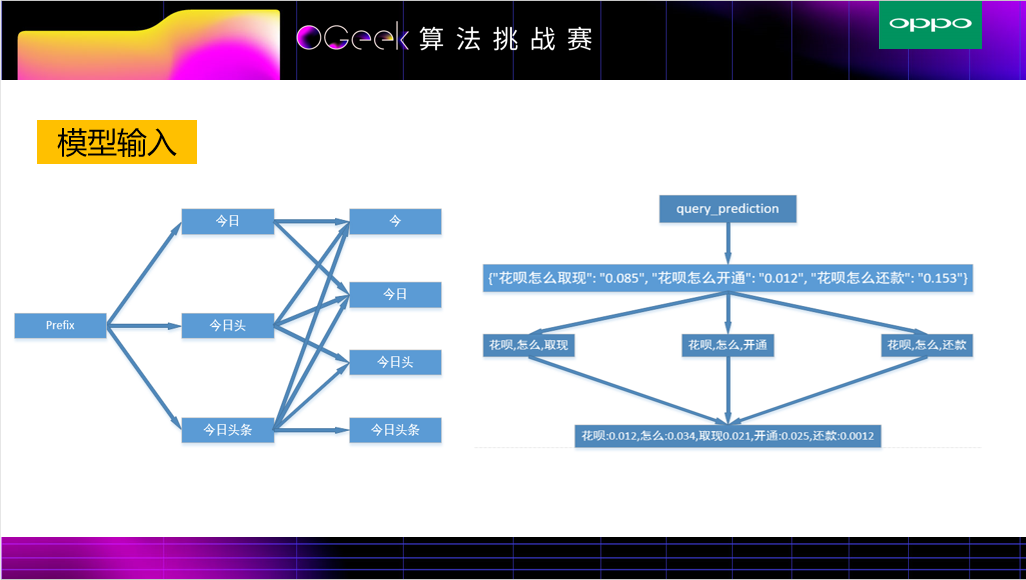
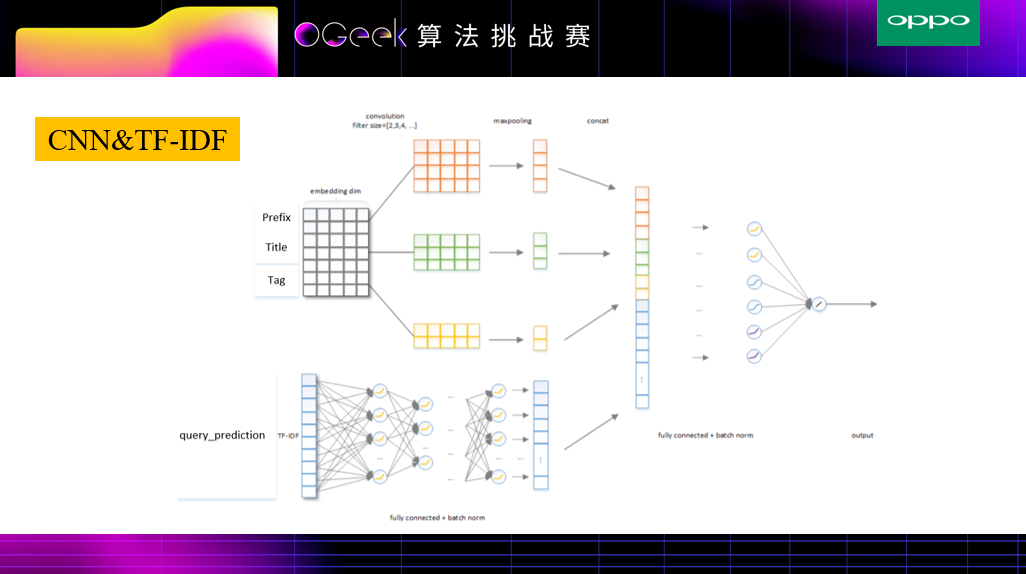
TextCNN是经典的文本特征提取网络,TextCNN Concat模型 输入是tag,prefix,title,query_prediction(query_prediction对其进行拆分成10条,查询词为文本,查询词概率为权重)+特征工程中的统计特征, 接着将所有基础的文本特征通过TextCNN来提取,非文本特征通过全连接层来提取,上述几部分结合作为最终的特征层。由于模型过于简单,并没有特征之间(title,prefix)的深层次关联,导致效果很一般。
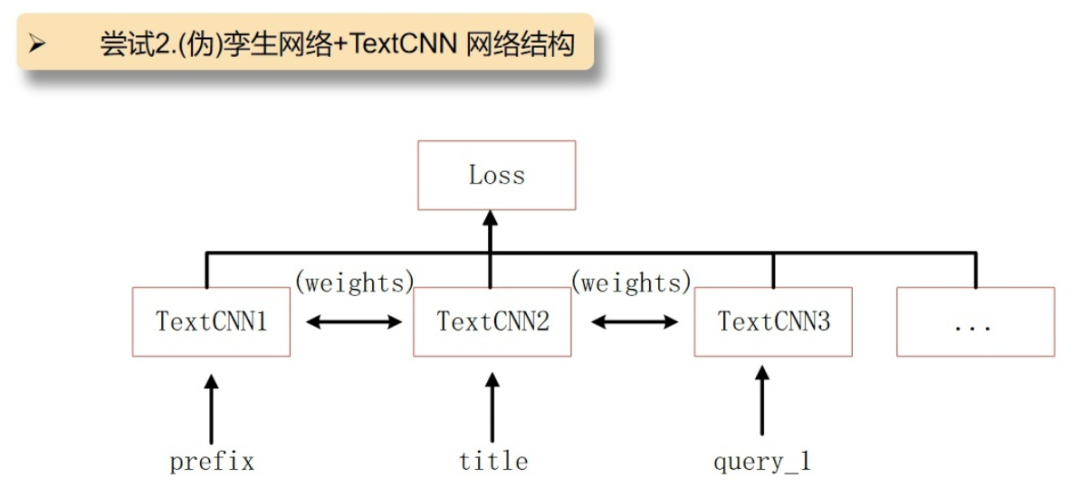
因为只用TextCNN结构的网络缺少prefix和title之间相似度的衡量,所以另外加了孪生网络或伪孪生网络来度量prefix和title之间相似度,以及prefix和query,title和query之间的相似度,并同样加入统计概率作为权重
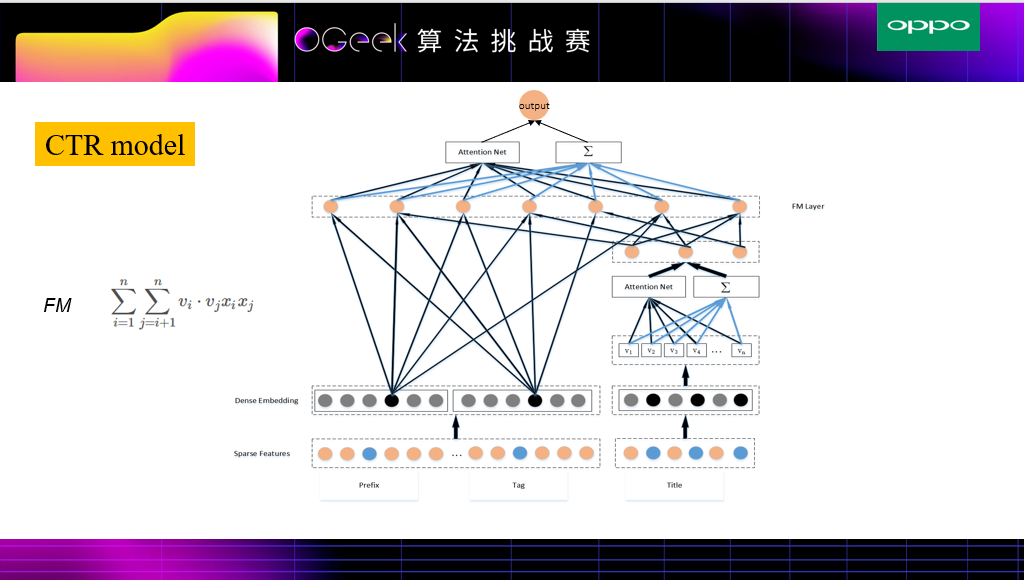
实验结果发现,由于prefix和title的长度有一些差别,反而用伪孪生网络比孪生网络取得了更好一些的效果,所以在上述模型中,prefix,title和query_prediction中并没有用共享权值(伪孪生网络)。该模型结合了TextCNN,DeepFM,AFM等相关操作。
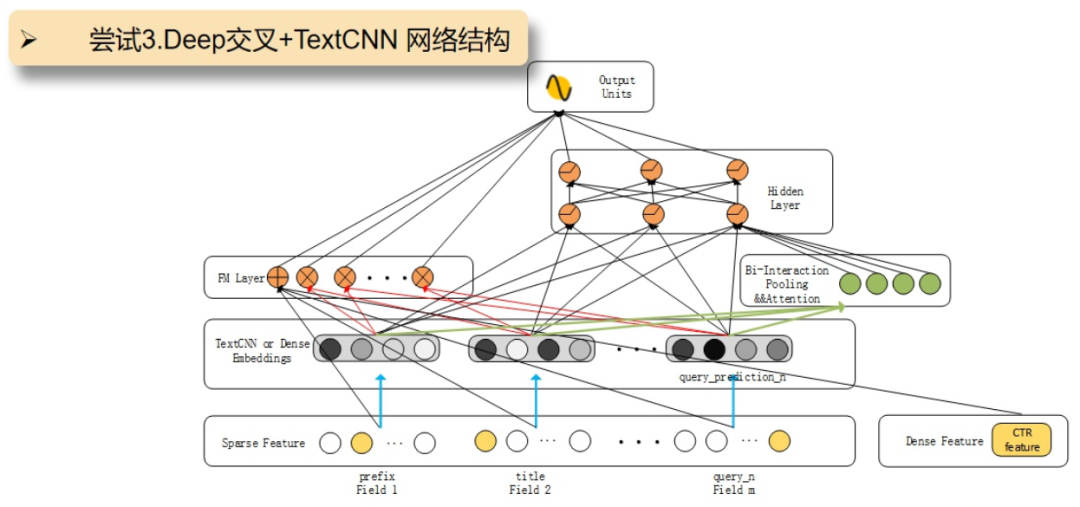
具体流程如下:输入分为两部分,对于prefix,title和query_prediction进行TextCNN操作提取文本特征,tag和统计特征通过全连接层获取对应的Embedding特征。
接着一部分是DeepFM模型,来获取浅层特征和交叉特征,其中query_prediction的统计概率作为query文本向量的权重。
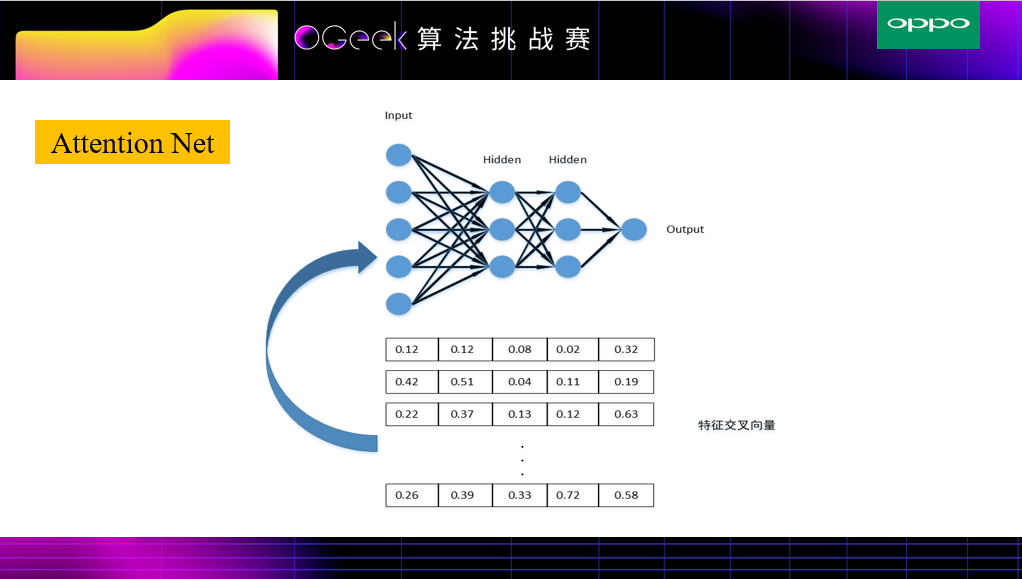
另外一部分是AFM相关操作,就是Bi-Interaction Pooling && Attention,对每两两Field的文本特征向量进行交叉,由于不同文本向量交叉的特征重要性不同,所以此处加入Attention,简单来说就是对不同文本向量交叉的特征加权平均得到向量再放入Deep层进行更深层次的训练。
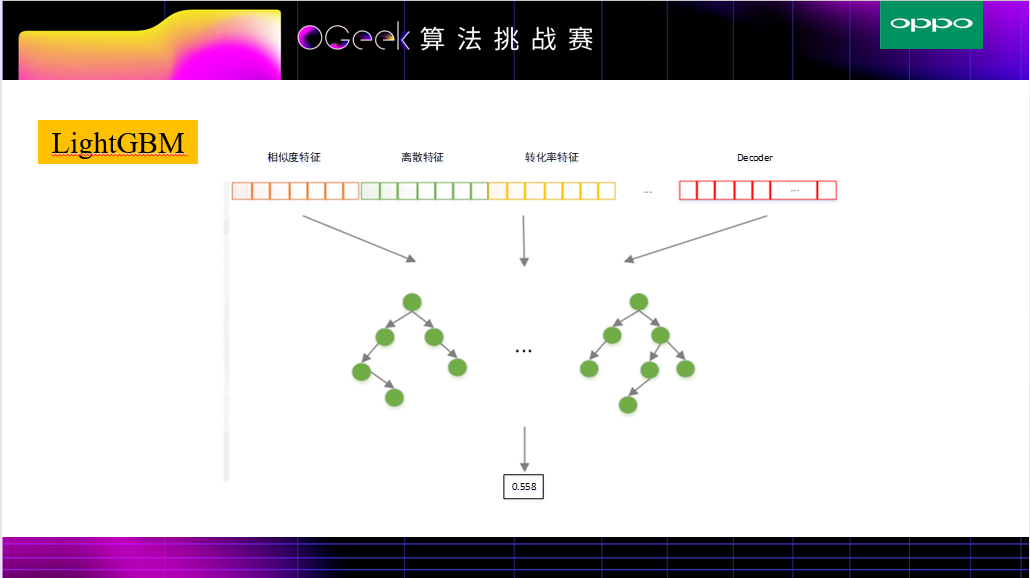
主要进行了以上几种深度学习模型,经过试验对比,尝试3能取得最好的效果,但由于数据量不是特别大,并没有取得比LightGBM模型更好的效果,虽然该模型与LightGBM模型融合有所提高,但是作为NN模型在200万规模的数据集上稳定性不够强,结果值会产生一定的波动,且模型受限于2个,所以最终提交的成绩并没有使用该模型。
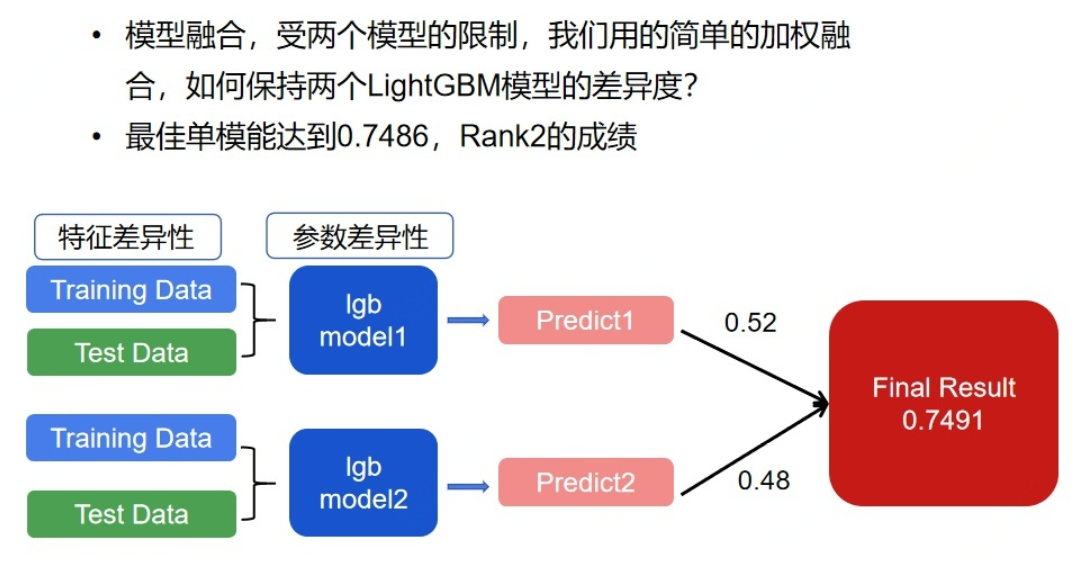
我们最终融合方案也比较简单,主要进行加权融合,权重的确定看的是线下分数。
第三名:seuzlg1. 赛题分析
本次比赛提供了用户输入前缀,文章标题等数据,预测用户是否点击。困难点在于预测准确度,训练集内存在矛盾,测试集有训练集中没有的搜索词。考虑到实际应用,模型预测速度应该较快。2. 特征工程
基础特征:
prefix与title的关系: prefix和title的长度、长度差,prefix在title中的位置等; query_prediction: query_prediction中查询词数量与预测概率均值、方差; 文本特征: 相似度特征:使用jieba默认词典对prefix、query0-10、title分词,计算title与其余12个字段的jaccard相似度、Levenshtein ratio相似度和cos相似度后加权求和,将最大值、最小值、均值和方差作为新的四个特征; 词袋特征:prefix、query、title中的词 预训练词向量:使用开源预训练词向量 统计特征: count特征:对prefix、title、tag统计单独count特征、两两交互count特征和三个交互count特征; nunique特征:统计prefix下title的种类数,prefix下tag的种类数和title下tag的种类数;ratio特征:tag、title、prefix两两之间的比率特征(共六个); 点击率特征:对prefix、title、tag统计单独ctr和sum特征、两两交互ctr和sum特征、三个交互ctr和sum特征;为了防止信息泄露,采取分块求点击率和点击数的策略。3. 模型
lightgbm(F1:0.750)
LGB是基于树的梯度 boosting 算法一个高效实现; 特征大多数为连续特征,LGB适合这种数据; LGB可以认为是一种特征交叉;DNN
统计,相似度等特征群对于不同而又相似的查询没有泛化性; “Iphone X”->“OPPO Find X”、“什么”->“啥” LGB无法良好使用向量来处理Prefix、Title这种文本信息; DNN可以通过引入预训练词向量来增强模型对测试集中未出现词的的样本鲁棒性。 特征:prefix、query0、query1、title,用词向量词典重新分词,后直接对多个词Embedding,Tag作为类别特征。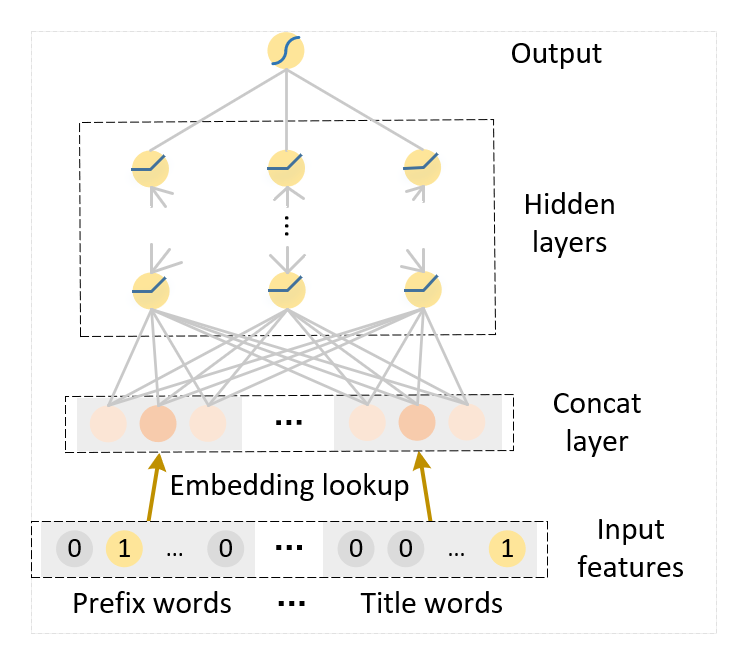 结构:Embedding层+4层全连接层(interaction based)。 技巧:Embedding使用预训练词向量初始化、所有的词Embedding层共享。 其他尝试:尝试过TextCNN和RNN效果不够好。 效果: 原始DNN:F1:0.700 DNN+词向量:F1 :0.719 DNN+词向量+Embedding层共享:F1:0.731
结构:Embedding层+4层全连接层(interaction based)。 技巧:Embedding使用预训练词向量初始化、所有的词Embedding层共享。 其他尝试:尝试过TextCNN和RNN效果不够好。 效果: 原始DNN:F1:0.700 DNN+词向量:F1 :0.719 DNN+词向量+Embedding层共享:F1:0.731
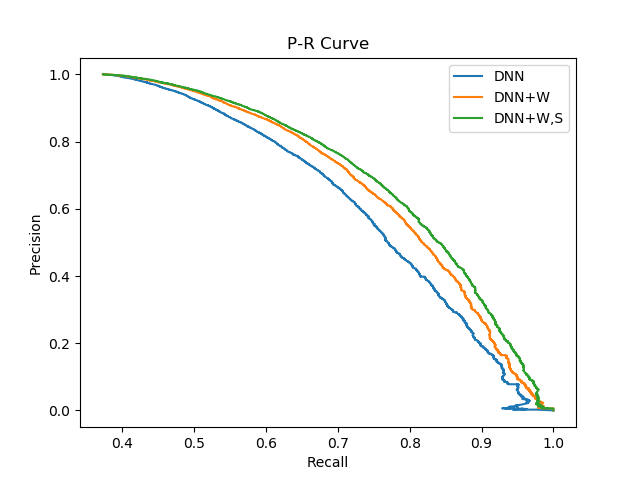
4. 模型融合
直接简单加权:LGB+DNN:0.750+0.719 -> 0.755 尝试离散化所有特征给DNN:LGB+DNN(F):0.750+0.745 -> 0.751 效果没有只使用词的好,融合时多样性比较重要!5. 未来探索
在更大的数据量下完全使用DNN,结合interaction based + representation based; 在更大的数据量下基于Word Embedding 转为基于 Character Embedding; 引入时序特征与用户画像。6. 相关文献
[1] Li S , Zhao Z , Hu R , et al. Analogical Reasoning on Chinese Morphological and Semantic Relations[J]. [2] Xu J, He X, Li H. Deep learning for matching in search and recommendation[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 2018: 1365-1368. [3] Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[C]//Advances in Neural Information Processing Systems. 2017: 3146-3154. Datawhale竞赛 群已成立可扫码加入Datawhale竞赛学习社群
在社群中,交流、讨论和组队算法赛事。
如果加入了之前的社群,请不需要重复添加!

▲长按加群
若进群失败,可加负责人微信后,再回复关键词 - 竞赛 即可进群。



版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/30298.html