

此文的目标,是用一个非常系统化、通俗但尽量准确的框架,尝试去讲清楚 AI 相关知识,建立一个理解 AI 产业与技术栈的核心框架。
本文档不是只讲“怎么用 ChatGPT”,也不是只讲“模型参数有多大”,而是从 AI 产业和技术栈的底层往上看:
- 能源层:AI 为什么需要大量电力?
- 芯片层:AI 为什么需要 GPU / NPU / TPU?算力到底是什么?
- 基建层:为什么一堆芯片不能简单堆在一起,而要变成数据中心和 AI Factory?
- 模型层:LLM、多模态、模型训练/蒸馏、MoE、Transformer/RWKV、世界模型、训练范式到底是什么?
- 应用层:Agent、小龙虾/Hermes、Skill、MCP、Harness、Vibe Coding等又是些什么?
AI 不是单独一个模型,而是一条从电力、芯片、数据中心、模型算法,到 Agent 应用和业务场景的完整技术与产业链。
很多人理解 AI,会直接想到:ChatGPT、DeepSeek、Claude、Gemini、Midjourney、Cursor、Codex、AI Agent、豆包等。
这些当然都是 AI,但它们只是 AI 体系最上层的产品形态。
真正的 AI 系统,背后至少有五层:
如果只看模型,很容易产生误判,也有很多问题没法解释,例如
- 为什么 AI 公司疯狂建数据中心?
- 为什么 英伟达NVIDIA 市值这么高?
- 为什么大模型训练要几千万甚至上亿美元?
- 为什么 DeepSeek 的效率优化会引起全球关注?
- 为什么同一个模型,在不同 Agent 工具里体验差别很大?
- 为什么Benchmark高,不代表产品一定好用?
这些问题无法只靠“模型层”解释,必须把五层连起来看。
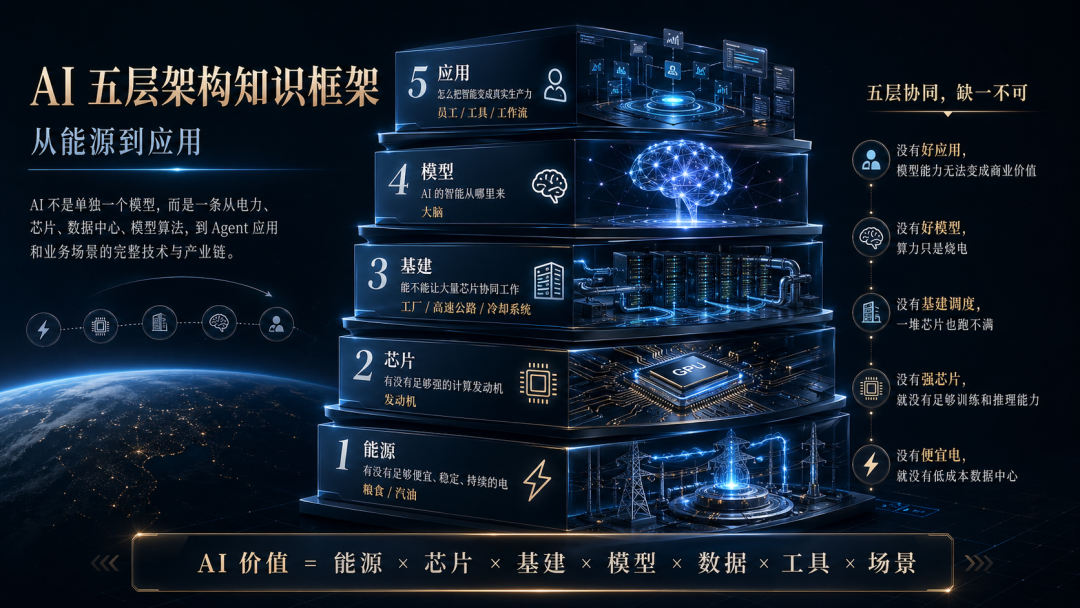
这五层不是彼此独立的,而是互相制约:
- 没有便宜电,就没有低成本数据中心。
- 没有强芯片,就没有足够训练和推理能力。
- 没有基建调度,一堆芯片也跑不满。
- 没有好模型,算力只是烧电。
- 没有好应用,模型能力无法变成商业价值。
- 这五层,越底层的变化发生得越慢,但带来的影响会更大;越上层的变化发生得越快,很可能很快就被替代,例如模型层,现在SOTA模型的领先周期越来越短了,但对于底层的能源层,各国的能源格局没那么容易被改变。
可以用一个公式理解:
AI 价值 = 能源 × 芯片 × 基建 × 模型 × 数据 × 工具 × 场景
这里每个乘数都很重要。
如果其中任何一项接近 0,最终价值都会被拉低。
- 只有模型,没有业务场景:很难商业化。
- 只有芯片,没有软件生态:开发者不好用。
- 只有数据中心,没有调度能力:GPU 利用率低。
- 只有 Agent 概念,没有工具权限和执行环境:只能聊天,不能干活。
能源层回答的是:
AI 为什么越来越像能源密集型产业?为什么大模型公司、云厂商、芯片公司都开始关心电力、数据中心、核电和储能?
以前互联网主要关心服务器、带宽和软件。AI 时代,服务器变成了高功率 GPU 集群,电力和散热成为核心瓶颈。
AI 的耗电主要来自两件事:
第一是训练耗电
训练大模型,就是让模型在海量数据上反复学习。比如:
- 读大量网页、论文、书籍、代码、对话数据。
- 通过预测下一个 token 学语言规律。
- 用大量 GPU 同时进行矩阵计算。
- 持续训练数周甚至数月。
训练越大,通常需要更多芯片、更长时间、更多数据、更复杂的网络通信、更强冷却、更高电力稳定性。
第二是推理耗电
推理就是模型被用户调用时的计算。例如:
- 用户问 ChatGPT 一个问题。
- AI 生成一张图片。
- Agent 读代码、改文件、运行测试。
- 电商 AI 自动分析 10 万个 SKU。
- 客服机器人一天回答几百万次咨询。
训练偏向一次性大投入,而推理是长期持续消耗。
未来 AI 普及后,推理耗电可能比训练更重要,因为训练是少数大公司做,但推理可能每天发生数十亿次。
能源层有几个常见单位:
如果一个 AI 数据中心持续使用 1GW 功率:
1GW = 1,000,000 kW 一年小时数 = 24 × 365 = 8760 小时 年耗电量 = 1,000,000 × 8760 = 8,760,000,000 kWh 也就是 87.6 亿度电 = 8.76 TWh 1.3.1粗略电费测算
按照深圳市2025年全社会总用电约 1272.1 亿度来预估,1GW的数据中心跑一年,就要消耗掉深圳市25天的全社会用电量。
所以,一个 1GW 级 AI 数据中心,如果全年满负荷运行,耗电量已经相当于中国一线城市数周级别的全社会用电量。
这只是电费,还没算:土地、机房建设、芯片采购、网络设备、存储系统、冷却系统、运维人员、备用电源、折旧等费用。(单从模型训练和研发成本看,顶级的模型例如之前的GPT-4,就已经是上亿美金的系统工程了,再加上这些费用,就能理解为啥模型不是普通公司能研发的了)
未来 AI 公司之间的竞争,不只是模型能力竞争,也会变成能源资源竞争。
关键问题包括:
- 是否能拿到长期稳定的低价电?
- 是否能在电网允许的地区建设数据中心?
- 是否需要自建能源?
- 是否需要储能平滑电力波动?
- 是否能用核电、天然气、风电、太阳能等组合供电?
- 是否能降低单位 token 的能耗?
这也是为什么越来越多 AI 公司、云厂商和能源公司开始合作。
芯片层回答的是:
AI 为什么需要专门的芯片?GPU、TPU、NPU、ASIC 有什么区别?英伟达NVIDIA 为什么强?国产芯片替代到底难在哪里?
算力,本质上是机器做数学运算的能力。
大模型处理文本、图像、声音时,都会先把它们变成数字向量,然后进行大量矩阵计算。
例如一句话:
今天深圳天气很好。
模型不会直接理解汉字,也不会像人一样先“懂中文意思”再思考。它会先把文字切成 token,再把 token 映射成向量,然后通过模型参数做一层又一层的数学运算。
这也是理解大模型的一个关键:
模型本质上不是一个内置规则库,也不是一个天然会精确计算的计算器,而是一个通过大量数据训练出来的概率预测系统(但现代 reasoning model、tool use、verifier、test-time compute 会让行为不只是简单补全)。
它看到一个问题后,会根据上下文和参数,生成最可能的下一个 token,再继续生成下一个 token。它可以表现得像在理解、推理、计算,但底层仍然是在高维向量空间里做概率生成。
插个题外话,这也解释了为什么有些简单算术题,模型有时会算错。
普通的算数对计算器来说,这是一个精确符号运算问题。
但对语言模型来说,它看到的是一串 token,并根据训练中学到的模式生成答案。如果它没有调用计算器、代码执行器,或者没有经过足够可靠的推理过程,就可能把数字当成语言模式来“猜”,于是出现看起来很低级的算术错误。
AI 算力常见指标:
AI 特别适合 GPU,是因为大模型里有大量相似的矩阵计算,可以并行执行。
CPU 像一个聪明经理,能处理复杂事情,但一次管不了几万个重复计算任务。
GPU 像成千上万个工人,可以同时做类似的计算。
TPU、部分 NPU 本身也可以被视为 ASIC 的一种实现,表格是按产业语境拆开讲。
英伟达NVIDIA的 H100 / H200 / B200 / GB200
这是目前全球 AI 训练和推理最重要的芯片和系统路线之一。
- H100:
过去一轮大模型训练核心芯片。
- H200:
提升显存容量和带宽,更适合大模型推理。
- B200:
Blackwell 架构,面向更高性能训练和推理。
- GB200NVL72:
机架级系统,把 72 块 Blackwell GPU 通过 NVLink 连接成一个大型计算域。
GB200 NVL72 不是单块芯片,而是一套机架级 AI 系统。
它的重要意义是:
AI 正在从“单服务器 GPU”走向“机架级超级计算节点”。
AMD MI300X
AMD MI300X 是 NVIDIA 之外的重要竞争产品,由超威半导体公司 (AMD, Advanced Micro Devices) 生产。
它的特点是大显存、高带宽,适合大模型推理和部分训练场景。
AMD 的挑战主要不在单点硬件,而在软件生态和开发者迁移成本。
Google TPU
TPU 是 Google 自研的 AI 加速器。
它主要服务于 Google 自己和 Google Cloud 生态。
TPU 的特点是软硬件一体设计,适合 Google 内部大规模训练和推理。
华为 Ascend(昇腾)
华为 Ascend,中文称为昇腾,是中国国产 AI 算力路线的核心之一。
它的重要性不仅是性能本身,更在于:
- 供应链自主
- 国产 AI 训练和推理平台
- 与 CANN 软件栈配套
- 支撑中国大模型企业在受限环境下继续发展
2026年4月DeepSeek V4 已针对华为 Ascend AI 芯片和 Ascend 超节点做了适配,可在华为昇腾算力集群上运行/推理;其中 V4-Flash 还被报道有 Ascend 集群参与训练。但这代表的是国产算力适配和生态替代能力增强,不等于 NVIDIA 生态依赖已经被完全消除。
基建层回答的是:
为什么买了很多 GPU,不代表就拥有强 AI 能力?为什么芯片之间怎么连接、怎么调度、怎么冷却、怎么供电,会决定模型训练和推理效率?
单块芯片是发动机。但 AI 需要的是成千上万台发动机协同工作。
基建层的核心就是:把大量芯片、电力、网络、存储、冷却和调度系统组织成稳定高效的 AI 工厂。
AI 基建可以分层理解:
AI Factory 这个说法很形象。传统工厂生产汽车、手机、衣服,而AI Factory 生产:token、embeddings(向量表示:把文本、图片、商品、用户行为等转成一串数字向量,用于检索、聚类、推荐和相似度计算)、图像、视频、代码、决策建议、Agent 执行动作等等。
数据中心不是简单的“放很多服务器的房间”。
AI 数据中心通常包括:
AI 数据中心和传统互联网数据中心最大的区别是:
AI 数据中心的功率密度更高,网络通信更密集,冷却压力更大,任务中断成本更高。
数据中心有一个效率指标PUE,全称是Power Usage Effectiveness。
公式是:PUE = 数据中心总耗电 / IT 设备耗电
假设 GPU 服务器本身耗电 100MW:
- 如果 PUE = 1.1,总耗电约 110MW。
- 如果 PUE = 1.3,总耗电约 130MW。
- 如果 PUE = 1.5,总耗电约 150MW。
PUE 越接近 1,说明非计算耗电越少。
但注意:
PUE 不是唯一指标。一个数据中心 PUE 很低,不代表它整体成本一定最低,因为还要看电价、土地、冷却水、芯片利用率、网络效率、运维稳定性等。
大模型训练和推理通常要用并行计算。
常见并行方式包括:
并行的目标是:
- 让模型装得下。
- 让数据吞吐上去。
- 让 GPU 不闲着。
- 让训练和推理成本下降。
很多人以为 AI 训练就是 GPU 在算。
但实际大模型训练中,很大一部分挑战来自通信。
GPU 之间要传:
- 参数:模型内部的权重,也就是模型学到的“经验刻度”。
- 梯度:训练时用来告诉参数应该往哪个方向调整的信号。
- 激活值:模型每一层处理输入后产生的中间结果,后续层还要继续使用。
- KVcache:推理时缓存的 attention Key / Value,用来避免每生成一个 token 都重新计算前文。
- 路由信息:MoE 模型中,路由器决定某个 token 应该交给哪些专家处理的选择结果。
- 专家输出:MoE 中被选中的专家网络处理后的结果。
- 中间状态:训练或推理过程中需要跨芯片同步的临时计算结果、状态信息和控制信息。
如果通信慢,就会出现一个问题:
GPU 明明很贵,却在等数据。
这会直接降低芯片利用率。
芯片利用率可以理解为:
你花钱买的 GPU,到底有多少时间真的在做有效计算?
影响利用率的因素包括:
就像是你请了 100 个工人,不代表 100 个人都在干活。
有的人在等材料,有的人在等上一道工序,有的人太热休息,有的人工具坏了。
AI 基建就是尽量让这些昂贵工人少等待、多干活。
AI 集群非常怕电力不稳定。原因是:
- 训练任务可能持续几周。
- 集群规模很大,任何单点故障都可能影响任务。
- GPU 功耗高,瞬时负载变化大。
- 断电或波动可能导致 checkpoint 损坏、任务重启、数据丢失。
所以数据中心需要:
- UPS(Uninterruptible Power Supply,不间断电源:主电源异常时,短时间继续供电,给系统争取切换或安全停机时间)
- 备用发电机
- 储能系统
- 冗余供电
- 电力监控
- 负载调度
GPU 高负载运行会产生大量热。如果散热不好:
- 芯片降频
- 性能下降
- 故障率上升
- 服务器寿命缩短
- 训练任务中断
传统数据中心很多用风冷。高密度 AI 数据中心越来越多使用液冷。
通俗点理解,AI 芯片像很多大火炉。火炉越多,屋子越热。因此不但要有电,还要有水管、风扇、空调和消防,不然火炉再贵也不能一直烧。
AI 基建的目标不是“堆更多 GPU”,而是:
用更低成本、更高稳定性、更高利用率,持续生产更多高质量 token 和智能服务。
衡量指标包括:单位 token 成本、GPU 利用率、集群故障率、训练吞吐、推理延迟、每瓦性能、每美元性能、部署效率、容灾能力。
模型层回答的是:
AI 的智能是怎么来的?LLM、Transformer架构、MoE、多模态、RAG、Memory、SFT、RLHF、DPO/GRPO、世界模型到底都是些什么?
这是整个文档最重要的一章,也是陌生名词层出不穷的一章。
模型层可以分成几大部分:
- 基础概念
- LLM 演变
- Transformer 架构
- MoE、多模态与长上下文
- 非 Transformer 路线
- 训练与后训练
- 推理与 reasoning
- Benchmark 与评测
LLM 全称 Large Language Model,大语言模型。
最基础的定义是:
LLM 是一个通过海量文本和代码训练出来的模型,它学会了根据上下文预测下一个 token。
例如输入:
今天天气很好,我们去…… 模型可能预测:
公园 / 散步 / 海边 / 打球 等等 表面上,LLM 只是在预测下一个 token。
但当模型足够大、数据足够多、训练足够充分时,它会涌现出很多能力(涌现了智能),LLM会写作、翻译、总结、问答、推理、编程、规划、角色扮演、多轮对话、工具调用等等。
4.2.1 公司、产品、模型:先分清楚这些名词的对应关系
很多人容易把“公司名、产品名、模型名、工具名”混在一起。例如:
- Anthropic是公司。
- Claude是产品家族/ AI助手品牌。
- Claude Code是编码Agent产品。
- Claude Opus 4.7才是模型名。
再比如:
- OpenAI是公司。
- ChatGPT是用户使用的聊天产品。
- Codex是OpenAI的编程Agent产品。
- GPT-5.5是模型。
四类名词的区别
4.2.1.1常见公司—产品—模型对应表
下面表格用于帮助建立概念,不是完整排名,也不是永远不变的清单。模型和产品名称更新很快,正式引用时应以官网和 API 文档为准。按“公司”聚合来看(国内的大家比较熟悉,举一些国外例子):
4.2.1.2为什么一定要区分这几类?
因为很多讨论会混淆层级,导致判断错误。
例如:
- “Claude Code 变差了”不一定等于“Claude Opus 模型变差了”。也可能是产品 prompt、默认 reasoning 配置、缓存、工具调用或 Harness 改了,就像前段时间大家都在讨论的Opus4.7降智,本质上是因为Harness的问题而非模型的问题。
- “ChatGPT 很好用”不等于某个 GPT 模型裸能力一定最好,因为 ChatGPT 还包含系统提示词、工具、记忆、文件处理、UI 和产品策略。
- “Cursor 写代码强”不等于 Cursor 自己训练了最强模型,它可能是 IDE 上下文、索引、编辑体验、模型选择和 workflow 做得好。
- “Llama 很强”不等于 Meta AI 产品一定最好,因为开放权重模型被不同团队部署和调优后,体验会不同。
- “某个 API 模型 benchmark 高”不代表某个应用产品一定好用,因为产品层还有 Harness、工具、记忆、权限、延迟和成本。
4.2.2 Token 是什么?
Token 是模型处理文本的基本单位,2026年3月24日中文官方翻译为“词元”。
它不完全等于一个字,也不完全等于一个词。例如:
“ChatGPT 很强” 可能会被切成:
Chat / GPT / 很 / 强 中文、英文、代码、标点都会被 tokenizer 切成模型可处理的小片段。
一个 token 大致有多长?
可参考OpenAI的tokenizer:
https://platform.openai.com/tokenizer?utm_source=chatgpt.com
所以,不能简单说“1 个 token = 1 个字”或“1 个 token = 1 个词”。更准确的说法是:
token 是模型自己的文本切片单位,不同模型、不同语言、不同 tokenizer 会有差异。
Token 重要,是因为:
- 计费通常按 token。
- 上下文窗口按 token 计算。
- 推理速度按 token/s 衡量。
- 模型训练数据量也按 token 衡量。
4.2.3 参数 B 是什么?
模型参数是模型内部可学习的权重。
B 是 Billion的缩写,十亿。
所以,像qwen/qwen3.5-9b这个模型,9b意味着这个模型的参数量级是90亿。例如:
参数不是知识本身,而是模型从数据中学到的统计规律。
可以把参数理解成模型脑子里的大量“小旋钮”。训练就是不断调整这些旋钮,让模型更会预测、更会回答。
4.3.1 Prompt
Prompt 是用户给模型的输入指令。例如:
帮我写一封英文离职邮件,语气真诚、低调、有感谢。 Prompt 决定了模型当前任务。
4.3.2 Context
Context 是模型当前能看到的上下文,包括:用户当前问题、前面的对话、上传文件内容、系统指令、工具返回结果、RAG 检索结果等等。
4.3.3 Context Window
Context Window 是模型一次能处理的最大上下文长度。
可以理解为 AI 桌子的大小。桌子越大,能摊开的资料越多。
4.3.4 Memory
Memory 是跨会话保存的信息。
它不是模型参数本身,而是外部记忆机制。例如:
- 用户偏好
- 项目信息
- 公司名称
- 常用写作风格
- 长期任务背景
总的来说,一开始LLM通过chatbot的方式,只能进行简单的单次对话,例如你发prompt问它:1+1等于多少?它回答是2之后,你再问“再加1呢?”,它可能就回答不了了,因为没有上下文信息。
接着有了context/memory之后,有了上下文和记忆,AI就能回答需要历史背景信息的对话问题了。
但是只有Context/Memory还不够,因为有很多信息是模型之外的,需要读取本地文件或者联网搜索的(这就是接下来章节要讲到的RAG等内容),甚至要调用外部工具,这些在后续章节都会介绍。
非常通俗地解释:Prompt 是你现在跟 AI 说的话,Context 是 AI 眼前桌子上摆着的资料,Memory 是 AI 另一本小笔记本,下次还能记得你的一些偏好。
RAG 全称 Retrieval-Augmented Generation,检索增强生成。
它的基本逻辑是:
先从外部知识库检索相关资料,再把资料交给模型回答(基于资料来生成答案)。
4.4.1为什么要RAG?
因为普通 LLM 只靠模型内部参数回答,无法访问很多私有数据,且很容易出现知识过期或幻觉。带着这种特性,所以RAG有很强的应用场景。
RAG 可以让模型回答基于公司文档、产品手册、法律条款、论文资料、数据库记录、客服知识库等。
看到这你可能会问,那我不能把所有文档先都丢给AI吗?
目前还真不行,核心原因有几个,一是当前LLM有上面提到的上下文窗口的数据限制,二是如果都把全部相关文档输入进去,不仅成本很大,且每次回答都得调用全部数据,响应效率也非常低。
所以解决思路是,当问题来了,用一个办法先找到文档中最相关的部分,再交给LLM去回答。
4.4.2 RAG 流程
用户问题 → 向量检索 / 关键词检索 → 找到相关资料 → 拼进上下文 → 模型生成答案 这里核心流程可以拆分成两个阶段。一个是前期的数据准备,一个是回答用户问题过程。
4.4.2.1数据准备
如果要基于文档资料来生成答案,那第一步就需要先处理原始文档。
- 第一步是文档切分:文档非常长,首先要做的是文档切分(Chunking),就是可以按照不同章节、段落、字数长度等各种维度去把文档切分成不同的块(Chunk),保证每块的语义相对完整。
- 第二步是Embedding向量化:这个词很高级,别慌,其实非常容易理解。因为计算机是不理解文字的,所以要把这些文字转成数字,向量化的本质是把每一段文字,映射到一个语义空间的坐标。
举个简化的例子,坐标轴大家都熟悉,有x轴y轴,坐标轴上可以有很多坐标(2,1)、(2,4)等,前面切分好的语义完整的块的内容。假设:
块Chunk A内容是“退换货的流程要先确认收货”,对应坐标a(2,1);
块Chunk B内容是“退换货平均成本是2块钱”,对应坐标就会跟坐标a很近,因为内容都是“退换货”相关,假设是坐标b(2,2);
块Chunk C的内容是“不正当竞争罚款”,因为跟块Chunk A和B都不太相关,块Chunk C的坐标就会相对远离,对应坐标c(-10,-21)。
所以,在语义坐标空间里,意思相近的内容,距离会更近,不相关的内容距离就会更远。实际embedding不是简单的二维xy轴坐标系,会更复杂很多,但做的事情是一样的。
- 第三步是向量数据库存储:前面两步把文档切好了不同的块,每一块都对应了一个向量坐标,接下来就是把这些内容存入向量数据库,有一个基本的对应关系:
4.4.2.2用户提问
假设此时用户问了一个问题“我要怎么申请退换货?”
- 对于具体的问题,文本也是要转化成向量的,假设这个问题转换成的向量坐标是(2.5,3.5)。如果遇到问题不清晰或者比较口语化,LLM在这一层中还要重写问题(Rewrite)。
- 接着计算相似度:接下来这个向量坐标(2.5,3.5)要跟向量数据库中的向量计算相似度,具体方法有余弦相似度、欧式距离等,衡量该向量坐标与向量数据中的向量的距离。实际应用场景中是通过混合检索(关键词检索和向量相似度检索)。
- 然后返回Top-k个Chunk块:例如计算完之后数据召回了5个块,完成初筛。但此时,这5个块并不能保证可以回答用户的问题。
- 接着做重排Rerank:这5个块的内容重新跟用户问题做匹配,找出最能回答用户问题的内容,例如精选了其中3个作为最终使用的Chunk。
- 然后整合:最后把用户的问题+最终检索到的资料(3个chunk)+程序Prompt(程序额外定义的,eg“要严格基于资料内容回答,不能胡乱编造”之类的)整合起来,变成一个新的Prompt喂给LLM。
- 最后大模型生成答案返回给用户。
讲到这里,你终于理解了RAG不属于LLM的一部分,(那可能会问,为什么放到LLM这一层?因为跟LLM紧密配合啊),RAG只是帮助LLM去高效查询资料,并基于资料的内容让LLM生成答案,但过程中也存在很多的挑战:
- 公司文档格式多种多样,解析难度不一样,数据清洗很难。
- Chunk切块的颗粒度准确性,切块太大不精准,切块太小语义就容易断裂。因此要保证每一个块的语义都是完整的。例如上述的块ChunkB(退换货平均成本是2块钱),如果切成了两块“退换货”和“平均成本是2块钱”,那就不知道什么东西的“平均成本是2块钱”了。
幻觉是指模型输出看起来很自信,但实际上不准确或不存在的信息。原因包括:
- 模型本质是生成概率最高的回答,不是真正查证事实。
- 训练数据可能有错误。
- 问题超出模型知识范围。
- 上下文不足。
- 模型为了流畅性补全细节。
- 用户要求过于模糊。
降低幻觉的方法:
- RAG:让模型先检索外部资料,再基于资料回答。
- 工具调用:让模型调用计算器、代码、搜索、数据库,而不是凭空生成。
- 引用来源:要求模型说明依据来自哪里。
- 让模型承认不确定:允许模型说“不知道”或“需要更多信息”。
- 结构化输出:用固定字段、JSON、表格等减少自由发挥空间。
- 人工审核:关键场景由人类复核。
- 用Eval做质量评估:Evaluation 是指建立一套测试题、真实业务样本和评分规则,持续评估模型的准确率、幻觉率、格式稳定性、工具调用成功率等。例如做电商选品 Agent,就可以准备 100 个历史商品案例,看模型是否能正确判断趋势、利润、风险和推荐理由。
- 语言建模方法的演变:模型如何学习语言。
- 模型架构的演变:模型内部结构如何变化。
- 训练范式的演变:模型怎么被训练和对齐。
- 能力边界的演变:模型从文本扩展到代码、多模态、长上下文、推理。
Agent 不属于 LLM 本身的演变阶段,而属于应用层。只是因为 LLM 具备了更强的工具调用、长上下文和推理能力,才让 Agent 应用成为可能。
4.6.1 按语言建模方法看
*BERT:Bidirectional Encoder Representations from Transformers(来自Transformer的双向编码器表示),在2018年由Google AI团队推出,其核心思想深刻影响了后续几乎所有的大型语言模型。
4.6.2 按模型架构看
4.6.3 按训练范式看
4.6.4 按能力边界看
注意:
工具调用能力是模型能力的一部分,但 Agent 是应用系统。更统一的表达是:Agent = Model + Harness,其中 Harness 内部包含 Tools、Memory、Execution Environment、Policy / Permissions、Observability 等运行时能力。具体Harness内容会放到应用层再讲。
Transformer 是现代 LLM 的核心架构。
它来自 2017 年论文《Attention Is All You Need》。
Transformer 的核心机制是 Attention。
4.7.1 Attention 是什么?
人读一句话时,不会平均关注每个字。例如:
苹果今天发布了新手机。 这里的“苹果”不是水果,而是 Apple 公司。
模型要理解这一点,就要关注“发布”“新手机”等上下文。
Attention 的作用就是:
让模型在处理每个 token 时,动态判断上下文中哪些 token 更重要。
4.7.2 Transformer 的主要模块
你读文章时,会抓关键词,看前后文。
Attention 就是让 AI 学会:这句话里哪些词更重要,哪些词要连起来理解。
4.7.3 Transformer 的三种主流形态
当前主流聊天大模型,多数是 Decoder-only 架构。
原因是它非常适合自回归生成:
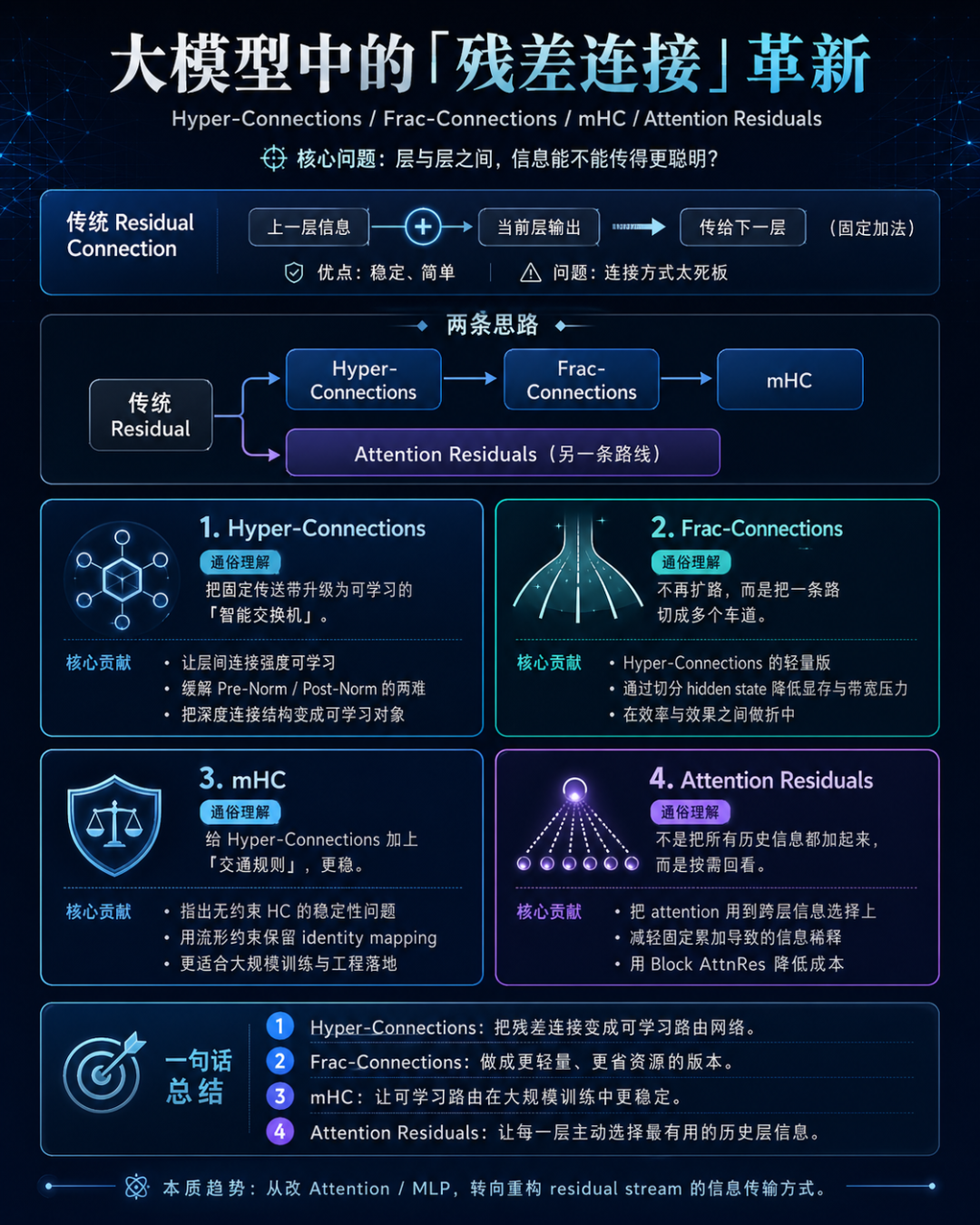
根据前面的 token,一个一个生成后面的 token。 4.7.4 HC / FC / mHC / Attention Res 怎么理解(非技术人员可skip)?
这四个东西分别对应四篇论文,可以总结为“Residual Stream Architecture:大模型深度方向的信息路由革命”。
这四篇论文都在重新设计 Transformer/LLM 里非常基础的残差连接 Residual Connection:
Hyper-Connections提出“残差连接不该是固定加法,而应该是可学习的跨层连接矩阵”;Frac-Connections是它的轻量化版本;mHC是它的大规模稳定化版本;Attention Residuals则走另一条路线,把残差累加改成“对历史层输出做 attention 选择”。整体趋势是:模型结构创新开始从 Attention/MLP 内部,转向 residual stream / depth-wise topology 这种更底层的架构设计。
- Hyper-Connections(2024年字节团队提出):提出新范式,残差连接从“固定加法”变成“可学习连接矩阵”。
- Frac-Connections:Fractional Extension of Hyper-Connections(2025年字节团队提出):HC 的省内存版本,用 hidden state 分块/分数化替代复制扩宽。
- mHC(Manifold-Constrained Hyper-Connections,带流形约束的超连接设计,2025.12.31 DeepSeek团队提出):HC 的大规模稳定版本,用流形约束恢复 identity mapping 和传播稳定性。
- Attention Residuals(2026.03 Kimi团队提出):不走 HC 多流路线,而是让每层用 attention 选择历史层输出,解决残差累加导致的信息稀释。
好吧,别说你们了,我也看不懂。再来通俗易懂解释下:
4.7.4.1 通俗理解
一个关键点可以先抓住:
这些论文不是在改“注意力公式本身”,而是在改模型层与层之间“信息怎么传”。这相当于从改发动机,转向改整辆车的传动系统。
可以把大模型想象成一个有很多层的“加工流水线”。
每一层都会对信息加工一次,比如第 1 层理解词,第 10 层理解句子结构,第 30 层理解推理关系。
传统 Residual Connection 残差连接 就像一条主干传送带:
上一层的信息 + 当前层加工出来的新信息 = 传给下一层
它的好处是:信息不容易丢,梯度也更容易传回去。
但问题是:它太“死板”了。每一层的信息都用差不多固定的方式往后加,模型不能很好地判断:哪一层的信息更重要?哪些层之间应该强连接?哪些层其实可以少传一点?
这四篇论文,本质上都在回答同一个问题:
大模型层与层之间的信息,能不能传得更聪明?
好了,小白们到这里就可以了。如果还想继续那就看完整版PDF吧。
此处省略4.7.4.2-4.7.4.5
4.7.4.6小结:四篇论文的关系,用一句话串起来
- 传统 Residual Connection:信息固定往后加。
- Hyper-Connections:让层与层之间的连接强度可以学习。
- Frac-Connections:把 Hyper-Connections 做得更省显存。
- mHC:给 Hyper-Connections 加稳定约束,让它更适合大规模训练。
- Attention Residuals:不用 HC 的多流连接方式,而是让每一层用 attention 主动选择历史层信息。
4.8.1 模型训练回答什么问题
模型训练回答的是:
模型为什么会变聪明?预训练、微调、对齐、强化学习、蒸馏、推理时扩展分别在做什么?
可以把模型训练分成:
- 预训练
- 后训练
- 对齐
- 强化学习
- 蒸馏
- 量化与部署优化
- 推理时计算扩展
4.8.2 预训练 Pre-training
预训练是大模型能力的基础。
模型在海量数据上学习通用规律。
常见训练目标:
预训练学到的是基础能力:
- 语言规律
- 世界知识
- 代码结构
- 常识关系
- 概念关联
- 一定程度的推理模式
通俗理解,预训练像孩子先读很多书、看很多题、见很多例子。
他还没学会怎么当客服、程序员或运营,但已经有了基础知识。
4.8.3 Scaling Law
Scaling Law (规模定律)研究的是:
模型参数、训练数据、算力之间如何配比,才能更有效提升模型能力。
过去几年大模型能力提升,很大程度来自 scale:
- 更大模型
- 更多数据
- 更多算力
- 更长训练
但 scale 不是盲目做大。如果参数很大但数据不足,会训练不充分。如果数据很多但模型太小,吸收能力有限。如果算力不足,训练无法充分收敛。
4.8.3.1 Scaling Law 是什么?
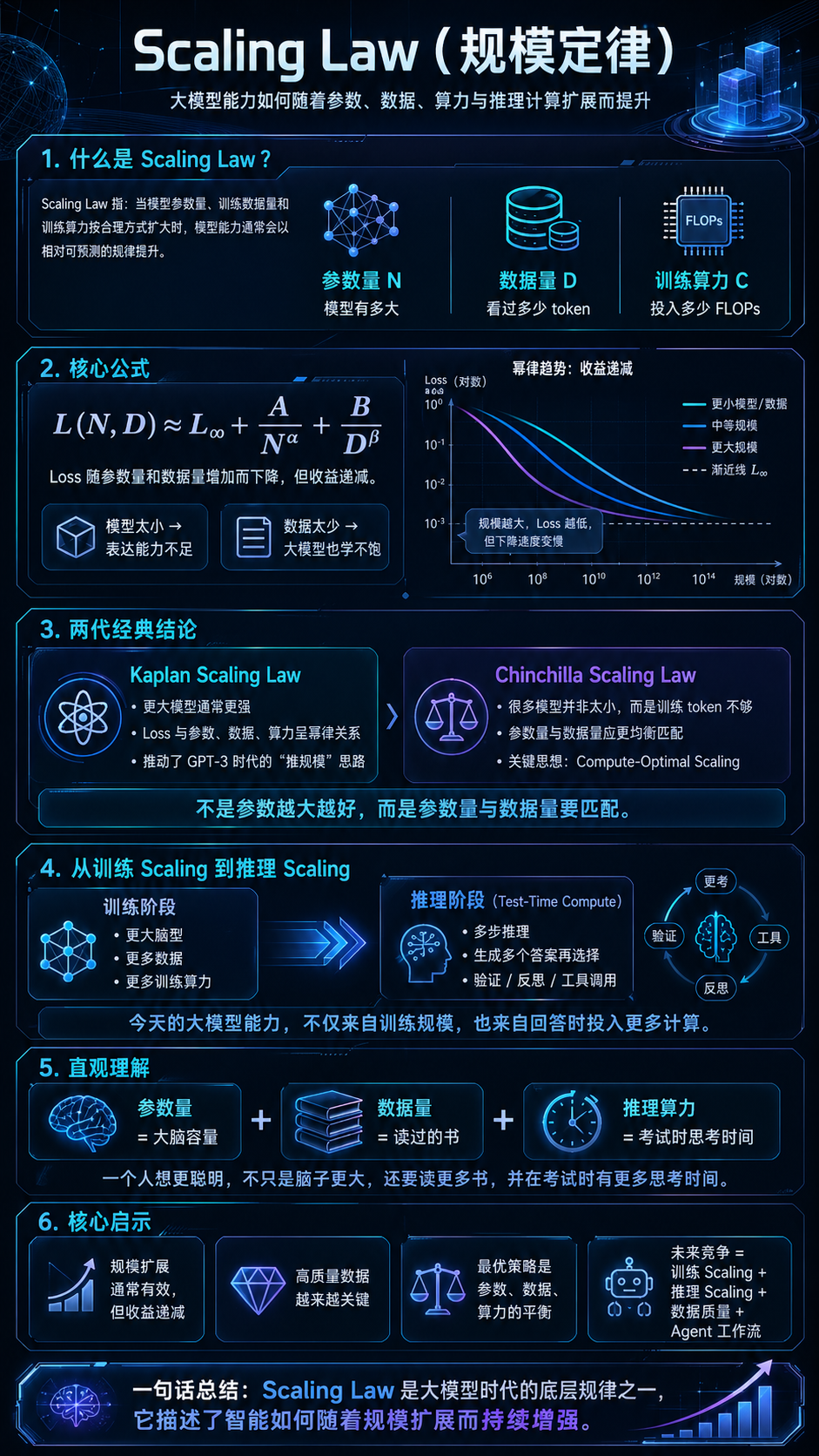
在 AI 里,Scaling Law 指的是:模型能力会随着某些关键资源的扩大而呈现相对可预测的提升规律。
对大模型来说,最核心的三个变量是:
- 模型参数量 N:模型有多大。
- 训练数据量 D:模型看过多少 token / 样本。
- 训练算力 C:训练时投入了多少计算资源,通常用 FLOPs 衡量(每秒浮点运算次数,这个概念在芯片层有提到)。
早期2001年 OpenAI 的《Scaling Laws for Neural Language Models》发现,语言模型的交叉熵损失会随着模型大小、数据量和训练算力增加,呈现近似 power-law 幂律下降;也就是说,规模越大,loss 越低,但收益会逐渐递减。论文还指出,在一定范围内,宽度、深度等架构细节的影响,反而不如整体规模变量明显。
也就是说:只要数据、参数、算力按合理比例扩大,模型能力通常会变强,而且这种变强在训练 loss 上可以被****。
4.8.3.2 最核心的公式直觉
一个常见的简化表达是:
L(N,D) ≈ L∞+A / N^α+B / D^β
各个参数代表的意思是:
- L:模型损失,越低通常代表模型预测下一个 token 的能力越强。
- N:参数量。
- D:训练 token 数。
- L∞:理论上接近但难以突破的最低损失。
- A / N^α:模型太小带来的误差。
- B / D^β:数据太少带来的误差。
这说明两个关键点:
第一,模型太小不行。参数不够,表达能力不足。
第二,数据太少也不行。模型再大,如果训练 token 不够,就会“没吃饱”,也就是 undertrained。
4.8.3.3 为什么 Scaling Law 重要?
Scaling Law 的战略意义非常大,因为它让 AI 公司可以在真正花几十亿训练大模型之前,先用小模型实验来预测大模型表现。
它解决的是一个核心问题:
我到底应该把钱花在更大的模型、更大的数据,还是更多训练算力上?
如果没有 Scaling Law,训练大模型就像赌博。
有了 Scaling Law,训练大模型更像工程投资:先做小规模实验,拟合曲线,再推算大规模训练的预期收益。
这也是为什么过去几年大模型公司会疯狂投入 GPU、数据中心和训练数据,因为 Scaling Law 给了他们一个信念:继续扩大规模,大概率还能带来能力提升。
4.8.3.4 早期结论-Kaplan Scaling Law
2020 年 OpenAI 相关研究提出的 Scaling Law 可以理解为第一代经典版本。
它的核心观点是:
模型性能主要由参数量、数据量和训练算力决定。
论文发现,loss 和模型规模、数据规模、计算规模之间呈现幂律关系,而且这种趋势跨越了超过 7 个数量级。论文还提出,大模型通常更具样本效率,因此在固定算力下,训练一个更大的模型,并在还没完全收敛时停止,有时是更高效的选择。
这套结论推动了 GPT-3 时代的思路:更大模型 = 更强能力。
所以当时很多公司倾向于堆参数量,比如 100B、500B、1T 参数。
4.8.3.5 第二次重要修正-Chinchilla Scaling Law
后来 DeepMind 在 2022 年提出了著名的 Chinchilla Scaling Law,这篇论文对行业影响很大。
它指出,很多大模型其实不是“太小”,而是 训练数据太少,也就是 undertrained。
DeepMind 训练了 400 多个不同规模的模型后发现,在固定训练算力下,模型参数量和训练 token 数应该大致同步增长:模型参数翻倍,训练 token 也应该翻倍。
这带来了一个非常重要的转变:
不是参数越大越好,而是参数量和数据量要匹配。
Chinchilla 本身只有 70B 参数,但用了比 Gopher 多 4 倍的数据,在相同计算预算下,表现超过了 Gopher 280B、GPT-3 175B、Jurassic-1 178B 和 Megatron-Turing NLG 530B 等更大的模型。
所以 Chinchilla 之后,行业共识变成:大模型不是单纯堆参数,而是要追求 compute-optimal:在给定算力下,参数量和数据量最优分配。
4.8.3.6 训练 Scaling Law vs 推理 Scaling Law
过去讲 Scaling Law,主要讲的是 训练阶段:
更大模型 + 更多数据 + 更多训练算力。
但从 2024 到 2025 年以后,一个新的方向变得非常重要:test-time compute scaling,也就是推理阶段的 scaling。
意思是,模型训练完之后,在回答某个问题时,也可以投入更多计算:
- 多生成几个答案再选择;
- 多步推理;
- self-consistency;
- verifier / reward model 评分;
- search;
- tree-of-thought;
- agent 多轮调用工具。
ICLR 2025 的一篇研究指出,在数学推理任务中,合理分配测试时计算资源,可以比简单 best-of-N 更高效;在 FLOPs 匹配的评估下,较小模型通过更多 test-time compute,有时可以超过 14 倍参数量的更大模型。
这意味着行业逻辑正在从:
训练一个巨大模型,一次回答。
变成:
训练一个足够强的模型,再让它在复杂问题上多思考、多搜索、多验证。
这也是 reasoning model、agent、deep research 类产品背后的重要逻辑。
4.8.3.7 Scaling Law 的6种类型
1)参数 Scaling
增加模型参数量,让模型表达能力更强。典型路径是从 1B、7B、13B、70B、175B、500B 甚至更大。
但问题是:参数越大,训练和推理成本越高;如果数据不够,模型会 undertrained。
2)数据 Scaling
增加训练 token 数。Chinchilla 之后,数据量的重要性大幅提升。
但今天的问题是:高质量互联网文本正在变得稀缺。所以后续的竞争不只是“更多数据”,而是:
- 更高质量数据;
- 专业领域数据;
- 合成数据;
- 多模态数据;
- 用户交互数据;
- agent 执行轨迹数据。
3)算力 Scaling
增加训练 FLOPs。这对应 GPU 集群、数据中心、能源、网络互联、训练稳定性。
但算力不是无脑堆,核心是:同样的算力,应该分配给更大模型,还是更多数据,还是更长训练?
这就是 compute-optimal scaling 要解决的问题。
4)架构 Scaling
虽然早期 Scaling Law 认为架构细节在一定范围内不如规模重要,但架构创新仍然非常关键。比如:
- Transformer;
- MoE;
- Mamba / State Space Model;
- Hybrid architecture;
- 更高效 attention;
- 更好的 normalization;
- 更好的 residual / connection 设计。
这些技术的作用是:让同样的算力产生更好的性能。
5)后训练 Scaling
现在大模型不只是预训练,还需要:
- SFT;
- RLHF;
- RLAIF;
- DPO;
- GRPO;
- rejection sampling;
- reward model;
- process reward model。
这部分也有自己的 scaling 逻辑:更多高质量偏好数据、更强 reward model、更长 RL 训练,可能带来更好的对齐和推理能力。
但相比预训练,RL / post-training 的 scaling law 还没有像 Kaplan / Chinchilla 那样完全成熟。
6)推理 Scaling
这是近几年最重要的新方向之一。核心不是让模型本身更大,而是让模型在回答时投入更多计算。比如:
普通回答:直接输出答案。
推理扩展:生成多个思路 → 验证 → 反思 → 工具调用 → 搜索 → 再综合答案。
这对复杂任务特别重要,比如数学、代码、科研、策略分析、商业推演。
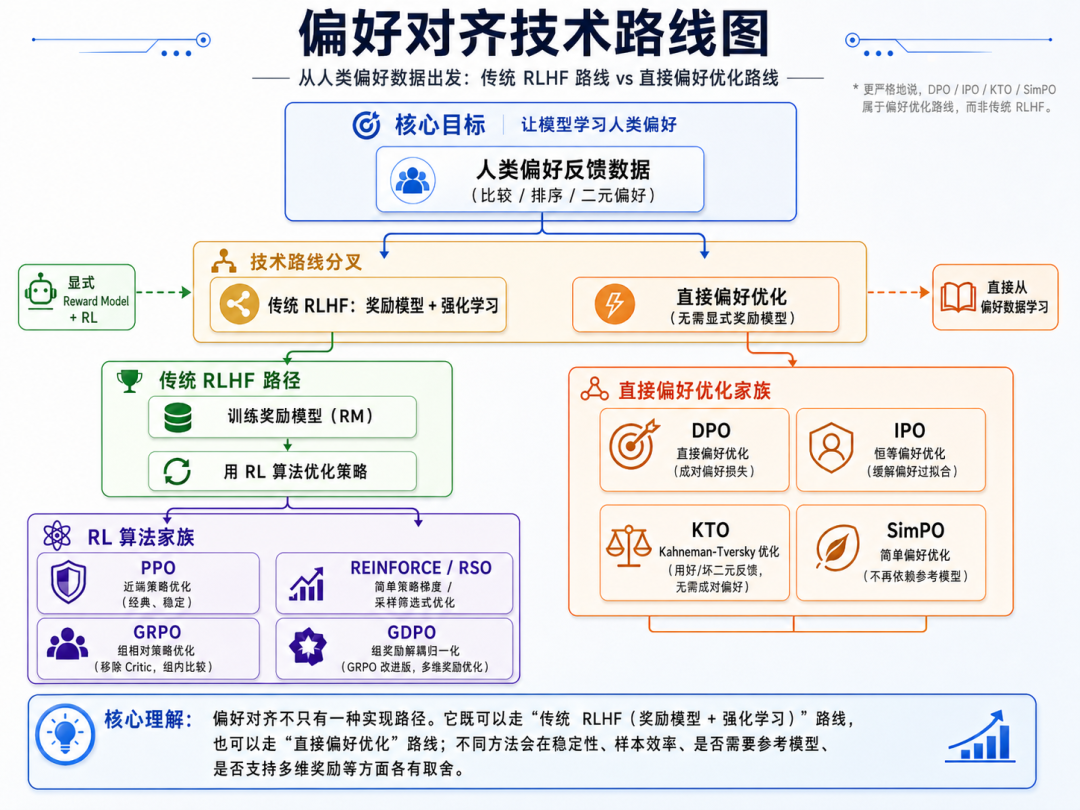
4.8.4 RLHF、SFT、DPO、PPO、GRPO、GDPO是什么?
先整体解释下这几个概念和之间的关系(都属于模型对齐/后训练语境)。
- RLHF是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback),是一套完整的训练流程,目的是让模型学会“偏好”人类喜欢的回答,而不仅仅是模仿。
- SFT是监督微调(Supervised Fine-Tuning),是RLHF 的前置步骤,用人工标注的“输入-期望输出”数据对模型进行监督微调,得到一个基础对话模型。SFT让模型学会“模仿”人类提供的标准答案,是训练的第一步。
- DPO、PPO、GRPO、GDPO是RLHF 流程中用来更新模型的具体优化算法,也可以作为独立的偏好对齐方法使用。
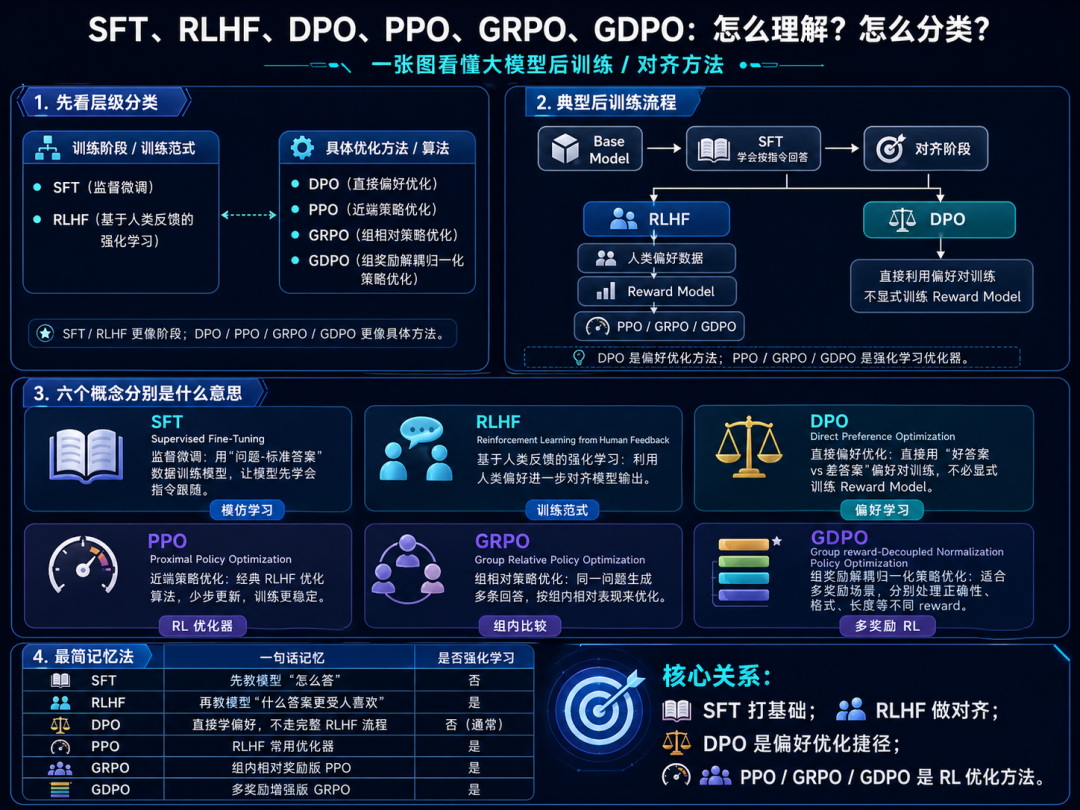
4.8.4.1 RLHF:基于人类反馈的强化学习
RLHF 全称 Reinforcement Learning from Human Feedback。基本流程:
- 模型对同一个问题生成多个答案。
- 人类标注哪个答案更好。
- 用偏好数据训练 Reward Model。
- 用强化学习让模型更倾向于输出高分答案。
RLHF 解决的是:
- 更符合人类偏好
- 更安全
- 更有帮助
- 更少冒犯
- 更会遵循指令
但 RLHF 也复杂:
- 需要训练奖励模型。
- 强化学习不稳定。
- 成本高。
- 可能 reward hacking。
标准 RLHF 通常分三步:
1)SFT:用人工标注的“输入-期望输出”数据对模型进行监督微调,得到一个基础对话模型。
2)训练奖励模型(Reward Model):让人类对多个模型输出进行排序,训练一个打分模型。
3)用强化学习算法优化大模型:以奖励模型的分数作为信号,更新模型参数。
其中第三步的“强化学习算法”就可以是 PPO、DPO、GRPO、GDPO 等。
4.8.4.2 SFT:监督微调
SFT 全称 Supervised Fine-Tuning。
它是在预训练模型基础上,用高质量问答样本继续训练。例如:
SFT 的作用是让模型从“会续写”变成“会按指令回答”。
预训练是读书,而SFT 是老师拿标准答案教你:这个题应该这样答。
4.8.4.3 DPO:直接偏好优化
DPO 全称 Direct Preference Optimization。
它也使用偏好数据,但不显式训练奖励模型。
它直接告诉模型:
在同一个问题下,A 答案比 B 答案更好。
DPO 的优点:
- 比 RLHF 简化。
- 训练更稳定。
- 不需要单独 reward model。
- 工程实现相对容易。
RLHF 是先训练一个“评分老师”,再让学生按老师分数改。DPO 是直接告诉学生:这篇比那篇好,以后多学这篇。
4.8.4.4 PPO、GRPO、GDPO
PPO 是强化学习里的经典算法,全称 Proximal Policy Optimization。RLHF 中经常使用 PPO 来优化模型策略。
GRPO 全称 Group Relative Policy Optimization。它被 DeepSeekMath、DeepSeek-R1 等路线广泛讨论。
核心思想可以粗略理解为:
对一组生成结果进行相对比较,让模型学习这一组里哪些答案更好。
GRPO 的意义在于:
- 降低传统 PPO 中 reward model / value model 的部分复杂度。
- 适合数学、代码、推理这类可以比较答案质量的任务。
- 对 reasoning model 训练很重要。
其中,在这里也对比下DPO和GRPO,DPO是没有reward 模型,直接两个答案,A比B好;但GRPO引入群体标注,不是比较两个的好与坏,而是会给一个相对排名,A>B>C>D>E.
GDPO 全称 Group reward-Decoupled Normalization Policy Optimization,是面向多奖励场景改进 GRPO。
它解决的是 GRPO 在 多奖励场景 下的问题。比如训练一个模型时,不只看“答案对不对”,还同时看数学正确性、格式是否符合要求、长度是否合适、是否会调用工具、代码是否通过测试、是否安全等。
NVIDIA 的 GDPO 论文指出,直接把 GRPO 用到多奖励场景时,如果把不同 reward 混在一起做归一化,可能导致训练信号分辨率下降,甚至训练不稳定;GDPO 的方法是对不同 reward 维度做解耦归一化,以更好保留各个奖励之间的相对差异。
通俗理解:GRPO 像是只看总分;GDPO 像是把“正确性、格式、长度、工具调用”等科目分别看清楚,不让某一个维度把其他维度淹没。
4.8.5 模型蒸馏 Distillation
蒸馏是指:
用大模型的输出、推理过程或偏好,训练一个更小、更便宜的模型。
用途包括:
例如一个 100B 大模型可以生成大量高质量电商选品分析样本,再训练一个 7B 小模型专门做选品。
但不像网上各种自媒体说的,只要用模型A的输出作为模型B的输入,都叫蒸馏,这种说法太宽泛了。
“蒸馏”(Knowledge Distillation)是有明确的定义和特定条件的,不仅仅是“一个模型的输出作为另一个模型的输入”。
具体来说,需要同时满足以下几点才算蒸馏:
- 目的:
让学生模型(模型B)模仿教师模型(模型A)的行为或输出分布,从而获得比直接训练更好的泛化能力。
- 阶段:
发生在训练阶段,而不只是推理阶段。
- 迁移内容:
通常使用教师模型的软输出(如概率分布、logits、中间层特征),而不仅仅是硬标签(最终类别或生成文本)。
4.8.6 量化 Quantization
量化是大模型部署中非常重要、但也很容易被误解的概念。
最简单的定义是:
量化就是把模型里原本很精细的数字,用更粗略、更省空间的数字来表示,从而减少显存占用、降低推理成本、提升运行速度。
先理解一个背景:
大模型本质上是一堆参数。参数就是很多很多数字。
例如一个 70B 模型,大约有 700 亿个参数。每个参数都要存在显存或内存里。参数越多,模型越大,占用显存越多。
4.8.6.1 模型为什么会占很多显存?
假设一个模型有 70B 参数。
如果每个参数用 FP16 存储,也就是 16 bit = 2 byte。
那么仅参数本身大小大约是:
70B × 2 byte = 140GB 也就是说,一个 70B 模型如果用 FP16 权重,仅模型参数就大约需要 140GB 显存,还没有算 KV cache、运行时缓存、框架开销等。
这就是为什么大模型经常需要多张 GPU 才能跑起来。
4.8.6.2 FP32、FP16、INT8、INT4 是什么意思?
这些词表示数字的存储精度。
量化就是把原来 FP16 / FP32 这种“更精细的小数”,转换成 INT8 / INT4 这种“更粗略的数字”。
4.8.6.3 一个直观例子
假设模型中有一个参数:
0. 高精度保存时,它会尽量保留很多小数位。
量化后,可能变成类似:
0.73 或者进一步变成某个整数编号:
127 然后系统再通过比例系数把它映射回近似值。
所以量化不是随便砍掉数字,而是用一套映射规则,把大量连续小数压缩成有限个离散值。
4.8.6.4 为什么量化能省显存?
以 70B 模型为例:
这就是为什么量化很重要。
一个原本需要多张高端 GPU 才能跑的模型,量化后可能可以:
- 用更少 GPU 跑。
- 在消费级显卡上跑。
- 在本地电脑上跑。
- 在手机、边缘设备上跑小模型。
- 降低云端推理成本。
4.8.6.5 量化为什么可能影响效果?
因为量化本质上是一种近似。
原本模型参数很精细,现在变粗了。
大多数情况下,适度量化影响不大;但在一些复杂推理、长上下文、多轮Agent任务场景里,损失会明显,特别是需要高精度判断的专业任务。
一个模型原来区分两个候选答案的差异很细微,量化后数字变粗,可能判断就不稳定了。
4.8.6.6 量化分几类?
常见分法:
4.8.6.7 量化和压缩图片类比
原图可能是 20MB,很清晰。
压缩后变成 2MB,大多数时候看起来差不多。
但如果你放大看细节,可能会发现边缘模糊、颜色断层。
模型量化也是类似:
- 压缩轻一点:基本看不出损失。
- 压缩太狠:回答质量、推理能力、代码能力可能下降。
4.8.6.8 企业应该怎么看量化?
量化不是越低越好,而是要在三者之间平衡:
成本 ↓ 速度 ↑ 质量 ↓或稳定性风险 ↑ 不同场景选择不同策略:
4.8.7 Thinking Time Scaling / Test-Time Compute
传统模型主要靠训练阶段变强。
推理模型开始强调:
回答问题时,多花一些计算,多想一会儿,再给最终答案。
这叫 test-time compute scaling,也可以理解为 thinking time scaling。常见方式:
它的特点是:
- 难题效果提升。
- 推理成本增加。
- 延迟变高。
- 更适合数学、代码、复杂规划。
Thinking time scaling跟预训练pre-training scaling不一样。
假设有两个学生参加同一场考试。
Pre-training scaling的预训练同学在备考阶段投入巨资,请最好的老师,上最长的课程,刷最多的题,在上考场前就变得渊博,对应到AI就是增加训练时的投入,例如砸更多的钱、用更多的数据和算力,训练一个更大的模型,eg 从GPT3到GPT4,模型一旦训练完成,能力就固定了回答问题速度很快。
而Thinking time scaling的思维同学在上述考试类比中,则是在考试本身投入时间,例如允许在考场花更多时间审题、打草稿、反复推演,用更深的思考弥补知识储备的不足,对应到AI就是增加推理时的投入,不改变模型本身,但在让它处理每个问题时,允许它多想一会,比如让它分步骤推理(思维链CoT,Chain of Thought)、自我辩论、生成多个答案选最好的,这会显著增加每个回答的成本和时间。但最终得分差不多。
MoE 全称 Mixture of Experts,专家混合模型。
普通模型是所有参数都参与计算。但前面我们有聊到很多模型参数,都是按照多少B(十亿)量级来衡量,每个问题都调用所有参数来计算,过于庞大。
MoE 模型有很多专家,但每个 token 只激活其中一部分专家。例如:
- 数学问题,激活数学专家
- 代码问题,激活代码专家
- 翻译问题,激活语言专家
- 电商问题,激活商业/商品专家
MoE 的好处:
- 总参数可以很大。
- 每次计算只用一部分参数。
- 训练和推理成本相对可控。
- 有利于扩展模型能力。
MoE 的难点:
- 路由器怎么判断该找哪个专家。
- 专家负载是否均衡。
- 通信开销是否过大。
- 训练是否稳定。
- 推理部署是否复杂。
MoE 模型参数量级大,但激活很少,这样计算成本少,效率高,而且被验证真的有效。
如果要讲到技术一些,那就是Attention层不变,但全链接层会拆分多个专家,且会有路由层自动负责去找哪些专家。
通俗来讲,普通模型像一个全科医生。MoE 像一家大医院。问题来了,不是所有医生一起看,而是分诊台把病人送到相关科室。
多模态是指模型不只处理文本,还能处理图片、音频、视频、传感器数据、3D / 空间数据等。
多模态模型的关键难点是“对齐”。
一张猫的图片、一句“这是一只猫”、猫叫的声音,在人类看来是同一个对象的不同表达。模型要学会把不同模态放到同一个语义空间里。
4.10.1 多模态也是 LLM 吗?
严格来说,LLM 指 Large Language Model,也就是以语言为核心的大模型。
多模态模型不一定都叫 LLM,更准确的说法包括:
如果一个模型以 LLM 作为核心,再接入视觉编码器、音频编码器、视频理解模块,并且仍然通过语言进行理解和生成,我们通常可以称它为 多模态大语言模型MLLM。
但如果一个模型主要用于图像生成、语音识别、视频生成,它未必适合直接叫 LLM。
所以更准确的表达是:
多模态不是 LLM 的同义词,而是大模型能力从语言扩展到图像、音频、视频等模态后的更大范畴。很多现代多模态模型是以 LLM 为核心扩展出来的。
长上下文指模型一次能处理更多 token,如8K token、32K token、128K token、1M token。
长上下文的价值很多,读长文档、分析代码仓库、处理合同、多轮对话不丢信息、Agent 长任务执行、企业知识库问答等。
但长上下文也带来成本,显存占用增加、注意力计算复杂、推理变慢、需要更好的位置编码和记忆机制。
KV Cache 是推理时缓存过去 token 的 Key 和 Value。它的作用是:
不用每生成一个 token 都重新计算前面所有内容。
RWKV 是一种尝试结合 RNN 和 Transformer 优点的架构,层级上跟前面讨论的Transformer架构平级,是两种不同的架构。
它的全称是 Receptance Weighted Key Value,名字来源于其模型架构中的四个核心元素。
它的目标是:
- 像 Transformer 一样并行训练。
- 像 RNN 一样高效推理。
- 减少 attention 在长序列上的成本。
Transformer 的问题是长上下文成本高。
RWKV 试图通过 RNN 式状态传递,让推理时不需要每次都看完整上下文。
SSM 是 State Space Model,状态空间模型。
Mamba 是其中代表路线之一。
它试图解决 Transformer 在长序列上的成本问题。
Transformer 的 attention 在长文本上成本较高,而 Mamba 这类模型追求更接近线性复杂度的序列建模。适合关注长文本、音频、基因序列、时间序列、长视频、低延迟推理。
LLM 主要从语言中学习世界。
但人类智能不只是语言。
人还知道杯子推到桌边会掉下去,也知道球往上抛会落下来,车太快转弯会失控,人走路要避开障碍物。
世界模型试图让 AI 学会:
真实世界如何变化,以及自己的动作会造成什么后果。
世界模型特别重要的场景,如机器人、自动驾驶、工业控制、游戏智能体、物理仿真等。
4.14.1世界模型和 LLM 的区别
当然,未来 LLM 和世界模型可能会融合。
因为一个更强的通用智能系统,可能既需要语言能力,也需要对物理世界和行动后果的理解。
4.14.2 JEPA 是什么?
JEPA 全称 Joint Embedding Predictive Architecture,联合嵌入预测架构。
它是 Yann LeCun(杨立昆)长期倡导的一类路线。
需要注意的是,“世界模型”本身是一个开放且正在发展的研究领域,存在多种不同的技术路线。JEPA路线(专注于抽象表征预测)只是其中之一。其他主流路线还包括:
- 生成式世界模型:以视频或多模态生成的方式模拟世界,常用于生成合成数据和策略训练。
- 空间世界模型:强调对三维空间的几何结构和持久场景进行显式建模和交互,以李飞飞创办的World Labs为代表。
4.15.1 模型评测回答什么问题
模型评测回答的是:
怎么判断一个模型强不强?Benchmark 分数意味着什么?为什么不能迷信排行榜?
Benchmark 就是模型考试。
但考试分数不能完全代表真实工作能力。
4.15.2 常见 Benchmark
Benchmark 可以按能力类型拆分,而不是混在一起看。不同 benchmark 的来源、题型和适用场景不同,不能简单把所有分数横向比较。这类Benchmark非常多,各个不同组织和机构推出的标准也不一样,跟手机跑分类似,知道是用来评估模型能力的就行。
4.15.3 怎么读这些 Benchmark?
可以按用途分:
不要用一个 benchmark 判断模型强弱。
例如:
- 一个模型 HumanEval 高,不代表能修真实项目 bug。
- 一个模型 MMLU 高,不代表 Agent 任务稳定。
- 一个模型 Arena 排名高,不代表你的企业场景最好用。
- 一个模型 MMMU 高,不代表能稳定做电商商品图分析。
企业真正要做的是:
通用 benchmark 只做初筛,最终必须建立自己的业务 eval。
4.15.4 Benchmark 的问题
Benchmark 有价值,但有几个常见问题:
第一,数据污染
模型训练数据里可能包含测试题。这就像学生提前见过考卷。
第二,刷榜
模型可能被专门优化某个榜单。榜单高,不代表真实业务好用。
第三,任务失真
真实工作往往不是单轮选择题,而是多轮沟通、读文件、调工具、做取舍、处理异常、接受反馈、长期执行等,很多 benchmark 测不到这些。
第四,产品体验不等于模型裸分
一个 AI 产品好不好用,还取决于:prompt 设计、RAG、工具调用、UI、延迟成本、稳定性、权限设计、安全策略、工作流集成等等。
可以把 AI 模型的开源/闭源 理解成一句话:
开源不是“能不能免费用”,而是“你能不能拿到模型的关键资产,并且被法律允许使用、研究、修改、再发布”。
更准确地说,AI 模型不是像传统软件那样只有“源代码”。它至少有 代码、结构、权重、数据、训练流程、许可证 这几层,所以 AI 的“开源”其实是一个光谱。
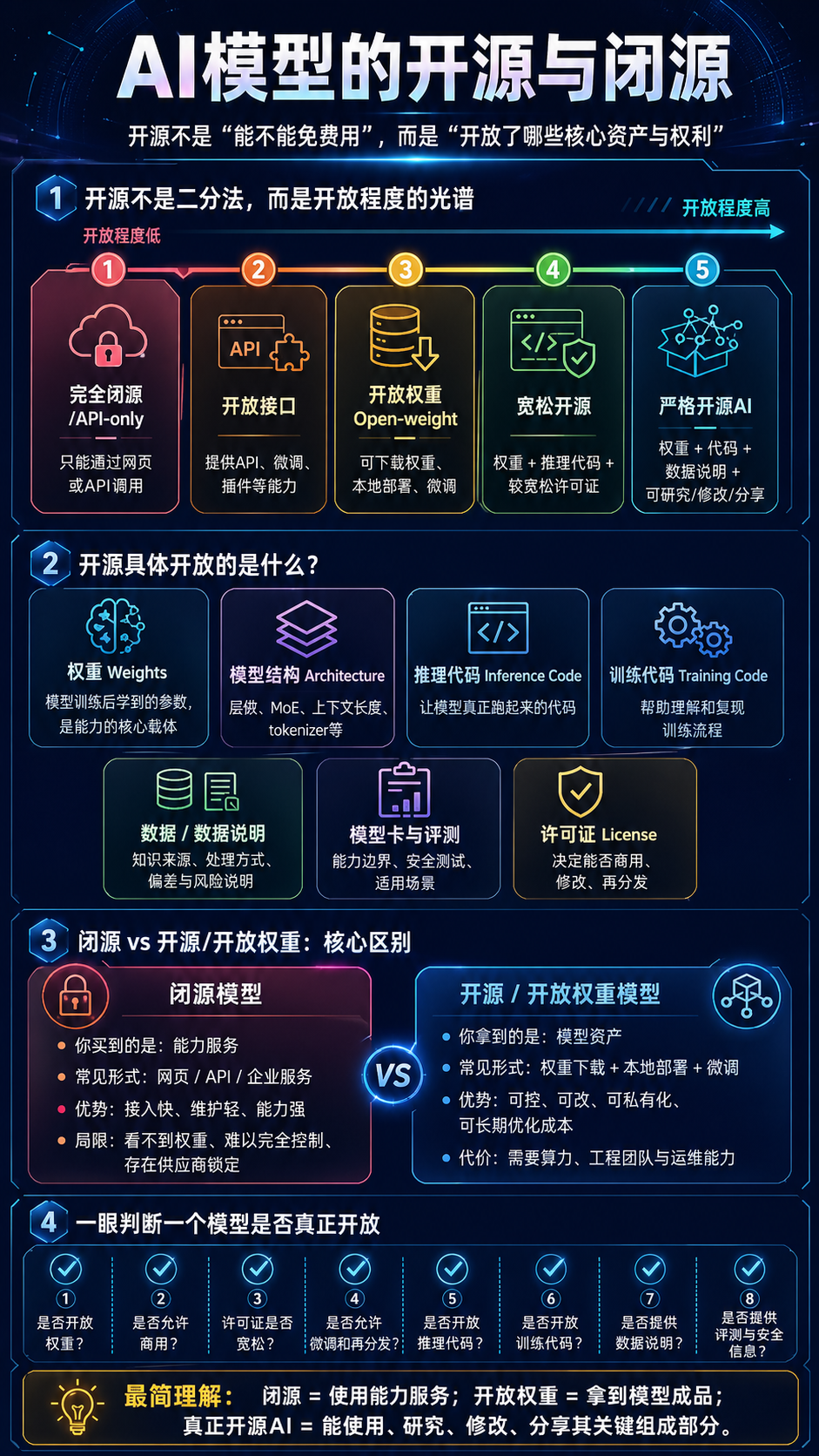
4.16.1. 先建立一个核心判断:开源不是二分法,而是开放程度
可以分成 5 档:
Open Source Initiative 在 Open Source AI Definition 1.0 里把 AI 系统的开放重点放在:能够 使用、研究、修改、分享,并且 AI 模型由 架构、参数/权重、推理代码 等部分组成。它还特别区分了 “Open Source models” 和 “Open Source weights”,因为只开放权重并不等于完整开源。
4.16.2. AI 模型“开源”具体开放的是什么?
最核心不是“开放模型名字”,而是开放下面这些东西。
4.16.2.1第一层:模型权重,也就是 weights
这是大家最常说的“开源模型”里的关键资产。
权重是什么?
可以理解为模型训练后学到的一大堆数字参数。模型会不会写代码、懂不懂中文、推理强不强,很大程度上都凝结在这些权重里。
如果开放权重,你通常可以:运行模型、本地部署模型、做微调、量化压缩、蒸馏、改成企业内部版本。
但注意:开放权重 ≠ 完全开源。因为你虽然拿到了“训练后的成品”,但不一定知道它是怎么训练出来的、用了什么数据、能不能自由商用。
4.16.2.2第二层:模型结构,也就是 architecture
比如:Transformer 结构、层数、hidden size、attention 形式、MoE 专家数量、上下文长度、tokenizer 设计等。
4.16.2.3第三层:推理代码,也就是 inference code
这是让模型真正跑起来的代码。比如:
如何加载权重、如何分词、如何生成 token、如何做 KV Cache、如何支持 batch inference、如何支持 GPU 推理。
很多所谓“开源模型”至少会开放这一层,因为否则开发者很难使用。
4.16.2.4第四层:训练代码,也就是 training code
这一层更关键,但很多模型不会开放。它包括:
预训练代码、SFT 代码、RLHF/DPO 代码、优化器设置、学习率策略、数据混合比例、训练超参数、checkpoint 处理方式等。
如果没有训练代码,开发者可以使用模型,但很难复现模型。所以从研究角度看:
4.16.2.5第五层:训练数据或数据说明
这是 AI 开源里争议最大的部分。
所以训练数据非常关键。
但现实中,很多公司不会开放完整训练数据,原因包括版权、安全、隐私、商业竞争。OSI 的定义更强调需要提供足够的数据相关信息,使别人能够理解训练数据如何构成、如何处理,而不是只给一个模糊说法。
4.16.2.6第六层:评测、安全与对齐资料
比如:模型卡、训练报告、benchmark、红队测试、安全策略、已知限制、适用场景、不适用场景。
这一层不一定决定“是否开源”,但决定你能不能负责任地使用模型。
尤其企业部署时,这些信息非常重要。
4.16.2.7第七层:许可证,也就是 license
这是最容易被忽略、但商业上最关键的一层。
你要看许可证允许什么:
- 是否允许商用?
- 是否允许微调?
- 是否允许再分发?
- 是否允许把它做成 SaaS?
- 是否有用户规模限制?
- 是否要求署名?
- 是否有特定行业限制?
- 是否要求衍生模型也开放?
4.16.3. 最重要的区分:Open-source vs Open-weight
这两个词一定要分清。
4.16.3.1 Open-weight:开放权重
意思是模型参数可以下载,你可以本地运行,通常也可以微调。
但它可能没有开放:完整训练数据、完整训练代码、完整数据处理流程、无条件商用权利。
所以很多行业里说的“开源大模型”,严格说其实是开放权重大模型。
4.16.3.2 Open-source AI:严格意义的开源 AI
更高标准是:不仅能拿到权重,还要有足够的信息和权限,让你能够使用、研究、修改、分享,最好还包括训练和运行系统所需的完整代码、数据说明、参数等。OSI 的定义正是在尝试给“AI 开源”建立更严格的边界,避免把只是开放权重的模型都包装成“开源”。
4.16.4. 闭源模型到底闭的是什么?
闭源模型通常关闭这些东西:
- 模型权重不开放。
- 训练数据不开放。
- 训练代码不开放。
- 模型结构细节不完整公开。
- 对齐方法不完整公开。
- 推理系统不开放。
- 只能通过 API、网页或企业服务访问。
例如你使用一个闭源模型时,本质上是在调用一个云端能力:
所以闭源模型开放的通常是:API、上下文窗口、函数调用能力、微调接口、RAG 接口、控制台、企业权限、日志管理、计费系统、SLA。
它开放的是产品能力,不是模型资产。
4.16.5. 可以用一个“模型开放度金字塔”来理解
从浅到深:
第 1 层:开放使用,你可以在网页或 API 上用。
第 2 层:开放接口,你可以把它接进自己的产品。
第 3 层:开放权重,你可以下载、部署、微调。
第 4 层:开放代码,你能理解它如何训练、如何推理。
第 5 层:开放数据信息,你能理解模型知识来源、偏差来源、风险来源。
第 6 层:开放许可证权利,你被法律允许自由使用、修改、商用、再分发。
真正判断一个模型开放不开放,要看它到了第几层。
应用层回答的是:
怎么把模型能力变成真实产品、真实工作流和真实商业价值?
模型只是大脑。
应用层要给大脑配上了工具、数据、权限、记忆、工作流、UI、执行环境、反馈机制。
Chatbot 是“会说”,Copilot 是“帮你做”,Agent 是“能自己推进任务”。
Agent 可以简单定义为:
Agent = Model + Harness
但这里的 Harness 不是一个狭义外壳,而是包含工具、记忆、执行环境、任务循环、权限控制、日志审计等能力的 Agent 运行时框架。
更完整地展开是:
Agent = Model + Harness Harness = Agent Loop + Tools + Memory + Execution Environment + Policy / Permissions + Observability 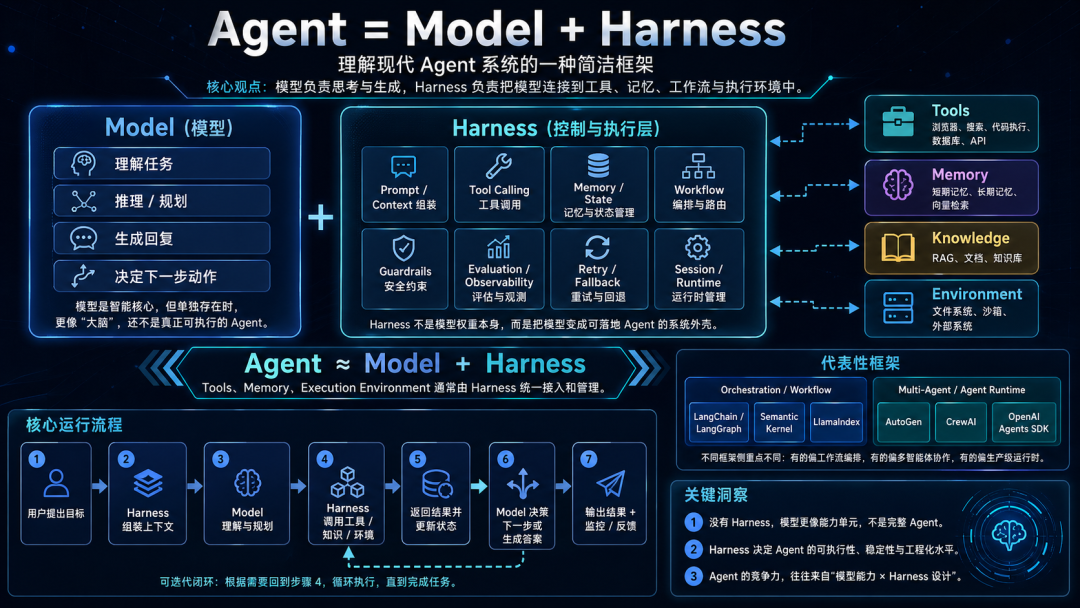
一个典型 Agent loop:
理解目标 → 制定计划 → 选择工具 → 执行动作 → 观察结果 → 反思修正 → 继续执行 → 输出结果 Agent 不只是生成文字。
它可以:搜索网页、读取文件、写代码、修改表格、调用 API、运行命令、创建日程、发邮件草稿、分析数据库、自动执行测试。Agent就像是给模型大脑赋予了手,能帮我们做很多事情。
这些概念很容易混。
LLM 本身只是“会推理和生成”的大脑;Tool / Function Calling / MCP / Plugin / Skill / Harness,都是为了让这个大脑能接入外部知识、外部系统和可执行流程。
但它们不在同一层级。
Tool 是能力;Function Calling 是调用动作;MCP 是连接协议;Plugin / Action 是产品化集成形态;Skill 是任务方法包;Harness 是运行时外壳;Agent 是最终应用。
随着AI Agent(智能体)技术的发展,不同公司和框架(OpenAI、Anthropic、LangChain、AutoGPT等)对类似功能起了不同的名字,造成了概念的交叉。
要理解它们,关键在于区分能力类型、调用方式、协议标准和执行环境。可以按照如下四层框架去理解:
可以把AI Agent调用外部世界的能力想象成“厨师做菜”:
- 能力层(有什么原料?):具备某种功能的单元 → Tool(工具)
- 调用层(怎么按菜单点菜?):让模型声明需要哪个功能 → Function Calling(函数调用)
- 集成层(厨房怎么连接不同供应商?):标准化工具与客户端的连接协议 → Plugin(插件)、MCP(模型上下文协议)
- 编排层(整个烹饪流程如何管理?):封装好的任务流程或执行环境 → Skill(技能)、Harness(框架/ harness)
1)能力层:最原子的单元-Tool(工具)
- 本质是一个可以被调用的函数、API或脚本。它有明确的输入、输出和功能边界。
- 例子:get_weather(城市)、search_web(关键词)、send_email(收件人, 内容)。
- 属于基础能力单元,是所有上层概念最终都要封装和执行的东西。
2)调用层:模型如何请求使用工具-Function Calling(函数调用)
- 本质是一种技术机制。大语言模型在生成回复时,不是直接输出文本,而是输出一个结构化的JSON,声明“我需要调用某个函数,参数是什么”。
- 关键:模型本身不执行函数,只是输出调用请求。由外部系统(你的代码)去执行。
- 属于模型与外部世界的交互协议。它是让Tool能够被LLM“理解”和“请求”的接口标准。OpenAI、Anthropic、Google都有各自实现的类似功能,常统称为Function Calling或Tool Use。
3)集成层:如何标准化连接和管理工具-Plugin(插件)
- 本质是一种集成方式。通常指将第三方服务(Tool)打包成符合特定平台(如ChatGPT)规则的一个安装包。用户安装后,模型就能自动调用。
- 与Tool的关系:Plugin是Tool的包装和分发形式。一个Plugin内部可以包含一个或多个Tool。
- 特点是由平台主导(ChatGPT Plugin生态),侧重于方便用户安装和使用。
- 属于平台特定的集成分发单元。
4)集成层:如何标准化连接和管理工具-MCP (Model Context Protocol,模型上下文协议)
- 本质是一个开放标准协议。由Anthropic提出,旨在解决“多个LLM客户端如何统一连接多个工具/数据源服务器”的问题。
- 关键:它定义了MCP Client(如Claude Desktop、IDE插件)和MCP Server(提供Tool或数据的独立进程)之间的通信规范。有点像USB-C接口,任何电脑(客户端)都能插任何U盘(服务器)。
- 与Plugin的区别:Plugin是中心化、平台绑定的(每个平台一套规则)。MCP是去中心化、标准通用的(一个服务器可服务任何MCP客户端)。
- 属于工具/数据源的通用连接协议,属于集成层的底层标准。
5)编排层:如何组合与管理执行-Skill(技能)
- 本质是一个高级封装。它通常不是单一函数调用,而是针对特定任务(如“写一篇博客”、“分析财报”)的多步工作流,可能包含多个Tool的调用顺序、特定的Prompt(提示词)模板、甚至代码逻辑。
- 与Tool的关系:Tool是原子操作,Skill是微操作或宏。一个Skill可以调用多个Tool。
- 属于任务导向的自动化单元,在编排层,面向最终用户任务。
6)编排层:如何组合与管理执行-Harness
- 这个词不太统一,但在AI Agent工程中,常指执行环境、测试框架或编排内核。
- 分类归属:运行与管理的底层框架/沙盒。它不像Tool或Skill那样直接面向功能,而是提供运行这些功能的骨架、安全约束和生命周期管理。
放到整体流程中:

举个例子,你问AI:“帮我查一下明天北京天气,如果下雨就发邮件提醒我。”
- Harness (比如LangChain的AgentExecutor) 开始运行,管理整个循环。
- LLM 通过 Function Calling 输出: }
- Harness 接收这个调用请求,去执行对应的 Tool (get_weather 函数)。
- get_weather 返回“明天北京有雨”。
- LLM 再次输出调用:{ “tool”: “send_email”, “params”: {“to”: “”, “body”: “明天下雨,记得带伞”}}
- Harness 执行 send_email Tool。
- 如果“发送邮件”这个动作不是单个Tool,而是一个包含了“生成标题、选择收件人、调用邮件API”的标准化流程,那它可能被打包成一个 Skill。
- 如果 get_weather 和 send_email 是通过 MCP 协议连接的通用服务器,或者是以 Plugin 形式安装在ChatGPT里的,那只是接入方式不同,不影响上述逻辑。
5.4.1 Function Calling / Tool Calling 是什么?
Function Calling,也常被称为 Tool Calling。
它的核心作用是:
让模型不要只用自然语言回答,而是能用结构化格式告诉系统:我想调用哪个函数、需要传什么参数。
它是从“模型会说话”走向“模型会做事”的关键机制之一。
5.4.1.1为什么需要 Function Calling?
普通 LLM 直接回答问题时,容易遇到几个问题:
Function Calling 的思路是:
模型负责判断“该调用什么工具”;程序负责真正执行工具;工具执行完以后,再把结果交回模型组织成答案。
5.4.1.2 Function Calling 的基本流程
用户提出问题,然后模型判断是否需要工具,接着模型生成结构化工具调用请求,由应用程序执行对应函数 / API,之后函数返回结果,模型再基于结果生成最终回答。
例如用户问:
帮我查一下今天深圳天气,然后判断适不适合户外拍摄。
模型不应该凭空编天气,而应该生成类似这样的工具调用请求:
}
应用程序接收到这个请求后,真正去调用天气 API。拿到结果后,再交给模型总结。
5.4.1.3关键点:模型通常不是自己执行函数
很多初学者会误以为:模型真的在自己执行代码。
更准确地说:
模型通常只是生成“调用意图”和“参数”;真正执行函数的是外部应用程序、服务器、沙盒环境或工具运行时。
- 模型说:我要调用 get_weather(city=“深圳”)。
- 应用程序看到这个请求。
- 应用程序调用真实天气 API。
- 天气 API 返回数据。
- 应用程序把数据交回模型。
- 模型再生成自然语言答案。
5.4.2 Skill 是什么?“式神”怎么理解?
Skill 可以理解为一个可复用的专项能力包,本质上我觉得是升级的结构化的带有行为指引和部分Asset的prompt。
它通常包括:操作说明+流程步骤+示例+脚本+模板+参考文件+输出格式要求。
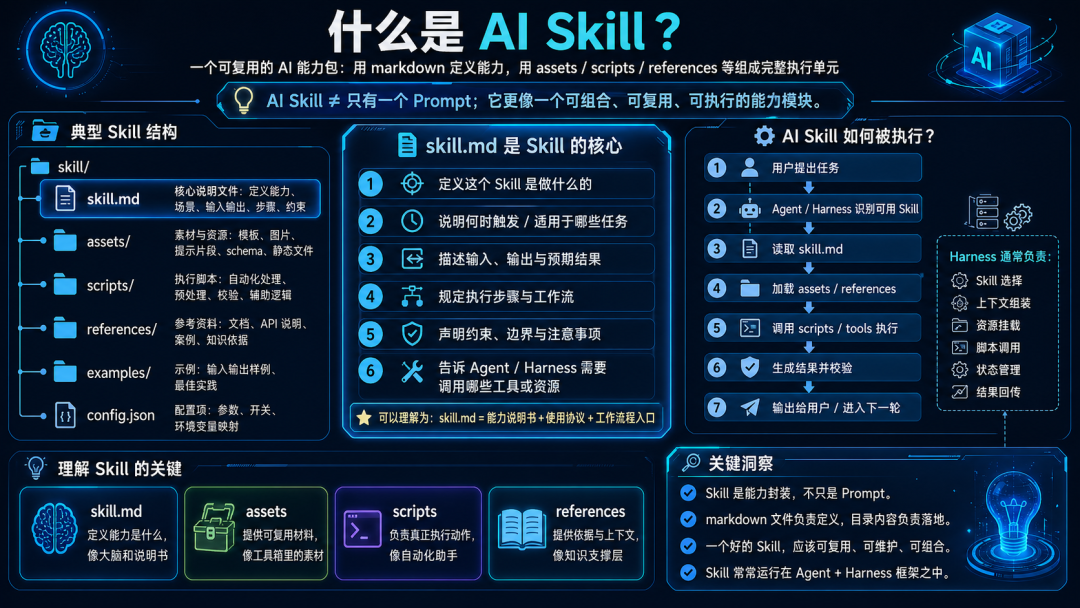
你可以把 Skill 比喻为“式神”或“技能卡”。
主 Agent 遇到特定任务时,调用对应 Skill。
但要注意:
Skill 本身通常不是完整独立智能体,而是一组可加载的操作能力和知识。
而且个人觉得,skill很强大的两点特征是:
- 大语言模型LLM本身是非常发散的,当有一些任务是需要follow某些既定成熟流程或者SOP,用Skill来约束LLM的行为就非常重要。
- Token很贵,skill的特性是渐进式披露,按需加载,能在一定程度上节省很多token。
-Level1元数据-: SKILL.md 文件开头的 name 和 description,消耗token是极小的(~100 tokens),启动时,对所有可用 Skill 加载。
-Level2核心指令-:SKILL.md 文件的正文(Markdown 部分),消耗token是中等的(~几百到几千 tokens),但只有当 LLM 根据元数据判断“这个 Skill 可能有用”时才加载。
-Level3详细资源-:scripts/, references/, assets/ 等目录中的文件,消耗token是很大的(可达几十万 tokens)。这部分内容不会主动加载,仅在 LLM 执行 Level 2 指令时,根据具体需求按需调用。
5.4.3 Harness 是什么?
Harness 属于应用层下面的 Agent 工程层 / 运行时层。它不是模型层,也不是底层数据中心基建层,而是把模型组织成可执行 Agent 的工程框架。
也就是说,应用层可以再拆成三层:
用户应用层:ChatGPT、Cursor、Claude Code、Codex、企业客服 Agent Agent 工程层:Harness、Tool Router、Memory、Skill、MCP、权限、安全、日志 基础服务层:模型 API、向量数据库、搜索、文件系统、浏览器、代码沙箱 Harness 位于中间的 Agent工程层。
它不是用户直接感知的产品界面,但决定了 Agent 能不能稳定工作。
5.4.3.1 Harness 的定义
Harness 可以理解为:
包住模型的执行框架,负责让模型安全、稳定、可控地使用工具、读写上下文、执行动作、记录过程并处理异常。
它负责管理上下文、工具、权限、记忆、文件系统、沙盒环境、多轮任务、错误重试、日志和审计、成本和限流、人类确认节点等。可以用公式理解:
Agent = Model + Harness Harness = Agent Loop + Tools + Memory + Execution Environment + Policy / Permissions + Observability 模型负责思考和生成。Harness 负责把工具、记忆、执行环境、权限、安全、日志、错误重试等能力组织起来,让模型安全、稳定、可控地执行任务。
5.4.4 MCP 是什么?
MCP 全称 Model Context Protocol。
它的目标是让 AI 应用更标准地连接外部工具和数据源。
传统方式下:
- 每个模型要单独接每个工具。
- 每个工具要单独适配每个模型。
- 集成成本很高。
MCP 希望变成统一标准。常见对象包括:
为了更好理解这三者是啥意思,可以打开Codex的官网,能看到非常形象的理解。
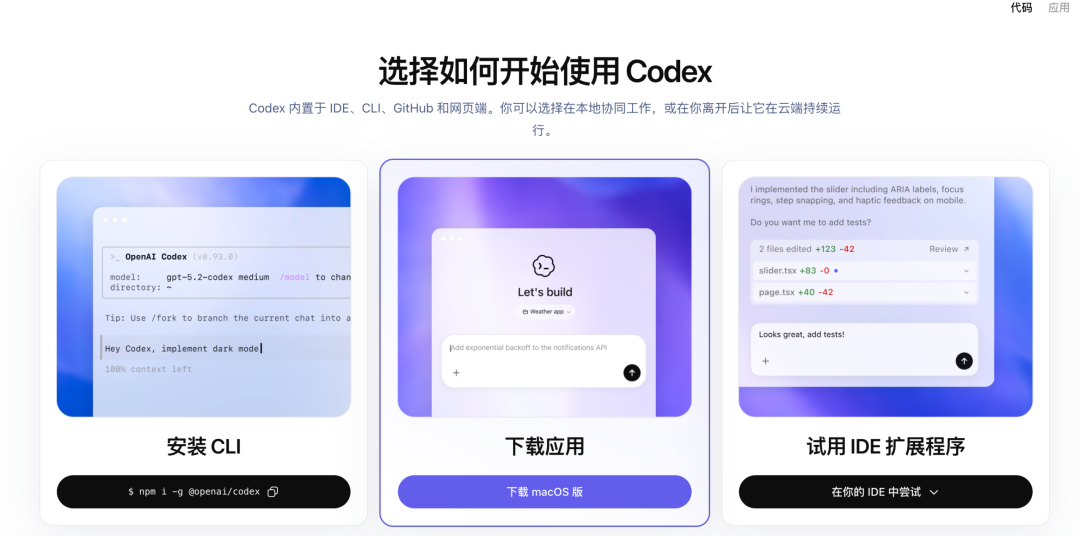
- 用户可以选择安装CLI,是指在命令行界面中安装codex,后续的应用也是在命令行界面中进行,例如mac的terminal 命令行终端。
- 也可以选择安装codex的桌面版官方应用。
- 还可以用IDE扩展程序来配置和使用Codex(如Visual Studio Code、Cursor、Xcode等)。
所以AI Agent 工具常见三种使用形态:
5.5.1 CLI(Command-Line Interface,命令行界面)
例如:
- Codex CLI
- Claude Code CLI
- Gemini CLI
特点是在终端运行,适合工程师。
5.5.2 客户端
例如:
- ChatGPT 桌面端 / Web
- Claude Desktop
- Codex App
特点是更适合普通用户,UI 页更加友好。
5.5.3 IDE 插件(Integrated Development Environment,集成开发环境)
例如:
- Cursor
- VS Code 插件
- JetBrains 插件
- Xcode 集成
特点是直接嵌入开发环境,适合代码补全、重构、调试、文件修改,对人类开发者来说也更容易审查 diff。
不要简单问“谁更强”。
更应该看:
- 你是在终端工作还是 IDE 工作?
- 任务是补全代码,还是跨文件改造?
- 是否需要运行测试?
- 是否需要连接 GitHub?
- 是否需要团队协作?
- 是否需要权限控制?
- 是否需要长任务执行?
Vibe Coding 氛围编程,是一种新的开发方式。它的核心是:
人用自然语言描述目标,AI 负责生成、修改、运行、调试代码,人负责方向、判断和验收。
传统开发:人写每一行代码,而Vibe Coding:人描述目标 → AI 生成方案 → AI 写代码 → AI 跑测试 → 人审查和调整方向。
5.7.1 Vibe Coding 的风险
- 架构可能变乱。
- 代码质量不稳定。
- 安全漏洞难发现。
- 依赖版本可能错误。
- AI 可能误删文件。
- 需求不清会导致反复返工。
Vibe Coding是Karpathy在2025年2月提出,在2026年2月Karpathy又提出了升级版的概念Agentic Engineering。
Agentic Engineering 并非简单地改名,它在核心理念上几乎是 Vibe Coding 的颠覆:
- 核心模式:Vibe Coding 侧重于通过自然语言提示引导 AI 编写代码;Agentic Engineering 则是由人类定义目标和把关,AI Agent 主导规划、执行与测试。
- AI使用方式:Vibe Coding 通常使用单个 AI 模型,依赖单次交互;Agentic Engineering 则是人类编排、协调多个 AI Agent 分工协作。
- 人类角色:Vibe Coding 中人类是直接编写提示词的“提问者”;Agentic Engineering 中人类是定义目标和约束的 “架构师”和监督者,大部分时间不直接写代码。
- 项目类型:Vibe Coding 更适合实验性、一次性或原型项目;Agentic Engineering 适用于需要长期维护与迭代的专业、企业级项目。
这两个是 2026 年 Agent 圈里非常火的社区称呼。
注意:
这两个都不是单纯的 LLM 模型,而是 Agent 应用 / Agent 工程框架。
它们通常会调用外部 LLM 作为大脑,再通过工具、记忆、技能和运行时环境完成任务。
5.8.1 小龙虾 Agent:OpenClaw
OpenClaw 被社区称为“小龙虾”,主要来自 Claw 这个词带来的龙虾/钳子意象。
OpenClaw 的定位是:
一个你可以运行在自己设备上的开源个人 AI 助理。
它的关键特征包括:
- 可以作为个人 AI assistant 使用。
- 支持不同操作系统和平台。
- 可以接入你常用的聊天渠道或设备。
- 通过 Gateway / 控制平面连接模型、工具和交互入口。
- 强调“assistant”而不是单纯“chatbot”。
- 社区里衍生出很多教程、模板、SOUL.md、人设和技能玩法。
它和普通聊天机器人的区别是:普通 Chatbot 主要回答问题。
OpenClaw 这类 Agent 更强调:
- 能接管一些工具。
- 能执行动作。
- 能跨应用工作。
- 能长期在线。
- 能形成个人助理式体验。
5.8.2 SOUL.md 是什么?
在 OpenClaw 相关社区中,常见一个说法叫 SOUL.md。
可以把它理解为:
Agent 的人格、行为风格、身份设定和长期原则文件。
它类似于一个固定加载的系统提示词。
例如 SOUL.md 可能定义:
- 你是谁。
- 你如何称呼用户。
- 你说话风格如何。
- 你做事原则是什么。
- 你在不确定时怎么处理。
- 你如何记住和协助用户。
这也是为什么社区会说某些小龙虾“有灵魂”。
5.8.3 爱马仕 Hermes Agent
Hermes Agent 是 Nous Research 推出的开源 Agent 项目。
它的 slogan 是类似:
The agent that grows with you. 也就是“与你一起成长的 Agent”。
Hermes Agent 的核心特点不是单纯会调用工具,而是强调:
- 持久记忆
- 自我学习
- 自动生成 Skill
- 从过往任务中沉淀经验
- 能跨会话检索过去对话
- 可以长期运行在服务器上
- 不一定绑定某个 IDE 或本地电脑
5.8.3.1 Hermes Agent 的关键机制
Hermes Agent 的重要点在于:
它把 Agent 从“每次重新开始的工具调用器”,推进到“会积累经验的长期个人系统”。
5.8.4 Hermes Agent 和 OpenClaw 的区别
5.8.5 它们和 Claude Code / Codex / Cursor 有什么关系?
它们都属于 Agent 生态,但侧重点不同。
5.8.6 它们为什么突然火?
原因有几个:
- LLM 工具调用能力增强。
- 长上下文和记忆机制进步。
- Claude Code、Codex、Cursor 等让用户看到 Agent 能真的干活。
- 开源社区开始把 Agent 做成可部署、可改造、可分享的系统。
- 个人用户希望拥有“自己的 AI 助理”,而不是每次打开一个空白聊天框。
5.8.7 也要看到风险
这类 Agent 越强,风险越明显:
- 误删文件。
- 误发信息。
- 误操作账户。
- 泄露 API key。
- 长期记忆记录敏感信息。
- 工具权限过大。
- 被 prompt injection 攻击。
- 自生成 Skill 质量不可控。
所以,真正可用的 Agent 必须有:
- 权限分级
- 沙盒隔离
- 人类确认节点
- 日志审计
- 敏感信息保护
- 可撤销操作
- 失败回滚
- Skill 审核机制
Markdown 是一种轻量级标记语言*,是一种文件格式,后缀名是.md。*
它的核心价值是:
用普通文本里的简单符号,表达标题、列表、表格、引用、代码块等结构。
Markdown 不像 Word 那样依赖复杂排版按钮,也不像 HTML 那样需要写很多标签。它既适合人阅读,也适合机器解析。
5.9.1 为什么 AI 经常用 Markdown?
因为 AI 输出通常需要同时满足两件事:
*1)*人类要读得舒服。
*2)*内容要有结构,方便复制、编辑、转文档、转网页、转 PPT。
Markdown 很适合这种场景,固定的格式渲染后就会变成有层级、有列表、有表格的内容。
5.9.2Markdown 常用语法
token 代码样式 代码块 三个反引号包裹 多行代码 链接 文字 可点击链接 表格 用 和 —
5.9.3Markdown 在 AI 场景里的作用
5.9.4在 Prompt 里怎么用 Markdown?
好的 prompt 也可以用 Markdown 组织。例如:
# 任务
帮我分析一个跨境电商选品机会。
# 背景
目标市场:东南亚
平台:Shopee
品类:家居用品
# 输出要求
请按以下结构输出:
1. 市场趋势
2. 目标用户
3. 竞争分析
4. 利润测算
5. 风险点
6. 结论建议
# 格式要求
用表格总结关键指标。
这样的 prompt 比一整段话更清楚,模型也更容易按结构回答。
5.9.5Markdown 的注意事项
不同平台对 Markdown 支持不完全一样。表格、脚注、任务列表属于扩展语法,不是所有环境都支持。Markdown 也不适合复杂排版,例如多栏、精细字体、复杂图文混排。
写给 AI 的 Markdown 要结构清晰,不要过度嵌套。
如果要程序稳定解析,不要只依赖 Markdown,最好用 JSON schema。
5.10.1 企业应用落地要回答什么问题
企业真正落地 AI,不能只买一个模型 API。要回答:
AI 怎么进入业务流程?怎么接数据?怎么控制成本?怎么评估效果?怎么保证安全?
省略5.10.2-5.10.4,细节请参考完整版PDF。
6.1.1能源影响芯片
电力越便宜,芯片运行成本越低。电力越稳定,训练越不容易中断。
6.1.2芯片影响基建
芯片功耗、显存、互联方式,会决定数据中心设计,例如高功率 GPU 会推动液冷普及。
6.1.3基建影响模型
基建越强,模型能训练得越大、越快、越稳定。高效基建还能降低推理成本,让更多复杂模型商业化。
6.1.4模型影响应用
模型能力决定应用上限,例如:
- 长上下文让 AI 能读完整合同。
- 多模态让 AI 能看商品图。
- reasoning model 让 AI 能做复杂规划。
- tool use 让 AI 能真正执行任务。
6.1.5应用反过来影响模型和基建
应用需求会反推模型优化,例如:
- 代码 Agent 需要更强工具调用和长上下文。
- 电商选品需要结构化数据理解和多模态商品理解。
- 客服需要低成本低延迟。
- 金融/医疗需要高准确性和可审计。
坚持看到此,以下问题应该很容易就有答案了。遇到网上的咨询和自媒体文章/视频,应该也很好判断具体的讨论落在哪一层了。
第一,AI的竞争表面是模型,底层是能源、芯片和基建。
大模型不是凭空运行的。它背后是海量电力、高端芯片、高速网络和复杂数据中心。
第二,NVIDIA 的强,不只是芯片强,而是生态强。
CUDA、NVLink、软件库、服务器系统、开发者生态共同构成壁垒。
第三,国产 AI 算力替代是系统工程。
不是换一块芯片就结束。
它需要硬件、编译器、算子库、框架、通信、调度、开发者生态一起成熟。
第四,LLM的本质是预测token,但能力已经从续写演变到推理、工具调用和Agent。
它从语言模型发展为通用任务接口。
第五,Transformer仍是主流,但RWKV、Mamba、JEPA、世界模型等方向都在探索新的效率和智能边界。
未来不是单一路线,而是多种架构并存。
第六,训练范式正在从单纯预训练扩展到后训练、偏好对齐、强化学习、蒸馏和test-time compute。
模型变强不只是“参数更大”,也包括“训练更聪明”和“推理时更会思考”。
第七,应用层的未来是Agent化、工具化、工作流化。
AI 不再只是聊天工具,而会成为能使用工具、读写文件、调用系统、推进任务的数字员工。
第八,企业真正的AI护城河,是数据、场景、流程、评测、成本和组织能力。
模型越来越容易获得,但把模型变成稳定生产力仍然很难。
这是我一直在用的AI理解框架,基本能辅助你理解网上大部份关于AI的讨论。
里面的内容有借助AI生成,特别是技术的部分,也有加入部分个人不成熟的理解。
因此一定会有纰漏。
所以该文档我会持续更新(会发表在公众号“GenFanTech”),毕竟AI每天发展都很快,SOTA模型也领先不了多长周期,说不定短时间又会有新的AI scaling 范式,应用层面就不用说了,每天都铺天盖地更新。
在AI浪潮,学习好AI我理解就两个重点就够了:
掌握学习框架,然后碎片化学习(AI发展太快也只能如此);
实际动手,多用,多体验AI产品(条件允许,就付费用好的)。
聊到英伟达,那就不能只讲芯片层的事情了。因为NVIDIA 的优势不只是 GPU 性能。
真正强的是完整生态:
这意味着 NVIDIA 卖的不是一块芯片,而是一个完整 AI 工厂方案。

8.1.1整体结构:NVIDIA 不是只卖 GPU
NVIDIA 的 AI 生态可以分成 8 层。
这就是为什么 NVIDIA 不是单纯硬件公司,而是 AI 基础设施平台公司。
8.1.2 GPU 硬件:H100、H200、B200、GB200
8.1.2.1. GPU 硬件解决什么问题?
GPU 是 AI 计算的核心发动机。
大模型训练和推理本质上是大量矩阵运算。GPU 擅长并行计算,所以比 CPU 更适合训练和运行大模型。可以理解为CPU 像一个很聪明的经理,适合处理复杂逻辑;GPU 像成千上万个熟练工,适合同时做大量相似计算。
8.1.3、CUDA:开发者调用 GPU 的软件平台
8.1.3.1. CUDA 是什么?
CUDA ,Compute Unified Device Architecture(统一计算设备架构),是 NVIDIA 的并行计算平台和编程模型。
简单说:CUDA 让开发者可以写程序,把原本跑在 CPU 上的计算任务,交给 NVIDIA GPU 并行执行。
NVIDIA 官方 CUDA Programming Guide 把 CUDA 定义为一种由 NVIDIA 开发的并行计算平台和编程模型,可以通过利用 GPU 显著提升计算性能。
CUDA Toolkit 还包括:
- 编译器
- GPU 加速库
- 调试工具
- 性能分析工具
- runtime library
- 头文件和开发资源
NVIDIA 官方 CUDA Toolkit 页面也说明,它提供用于创建高性能 GPU 加速应用的开发环境,包括库、调试和优化工具、C/C++ 编译器和运行时库。
8.1.3.2. CUDA 为什么重要?
CUDA 是 NVIDIA 生态最核心的护城河之一。
因为很多 AI 框架、算子库、训练系统、推理引擎都围绕 CUDA 优化。例如:
- PyTorch 支持 CUDA。
- TensorFlow 支持 CUDA。
- JAX 可以在 NVIDIA GPU 上加速。
- 大量开源项目默认优先适配 CUDA。
- 很多工程师已经熟悉 CUDA 生态。
这导致一个现象:
不是只要有一块性能接近 NVIDIA 的芯片就够了,还要有和 CUDA 类似成熟的软件生态。
8.1.3.3. CUDA 和 GPU 的关系
8.1.4、cuDNN / TensorRT:深度学习和推理优化库
8.1.4.1. cuDNN 是什么?
cuDNN 全称 CUDA Deep Neural Network library。
它是 NVIDIA 为深度学习准备的底层加速库。
cuDNN 的作用是把深度学习常见计算模式做成高度优化的底层库,让框架不用从零实现 GPU 加速。
NVIDIA cuDNN 文档介绍 cuDNN Graph API 可以表达深度学习中的常见计算模式,并把操作表示为节点、张量表示为边,类似深度学习框架中的数据流图。
8.1.4.2. TensorRT 是什么?
TensorRT 是 NVIDIA 的高性能深度学习推理 SDK。
注意:cuDNN 更偏训练和深度学习通用算子加速;TensorRT 更偏 模型部署和推理优化。
NVIDIA 官方介绍 TensorRT 基于 CUDA,并能优化主流框架训练出来的神经网络模型,通过量化、层融合、张量融合、kernel tuning 等技术优化推理。
8.1.4.3. cuDNN 和 TensorRT 的区别
8.1.5、NVLink:GPU 之间高速互联
8.1.5.1. 为什么需要 NVLink?
单个 GPU 再强,也很难独立完成大模型训练和推理。原因包括:
- 模型太大,单卡放不下。
- batch 太大,需要多卡并行。
- 长上下文 KV cache 占显存。
- MoE 模型需要跨专家通信。
- 多机训练需要频繁同步梯度和参数。
所以 GPU 之间必须高速通信。
如果通信慢,就会出现:GPU 在等数据,而不是在算。
这会直接降低 GPU 利用率。
8.1.5.2. NVLink 是什么?
NVLink 是 NVIDIA 的高速 GPU 互联技术。
它的作用是是让 GPU 与 GPU、GPU 与 CPU 之间以更高带宽、更低延迟交换数据。
在 GB200 NVL72 中,NVIDIA 称第五代 NVLink 提供 1.8TB/s GPU-to-GPU interconnect,并和 InfiniBand、Magnum IO 等一起支撑大规模训练。
2.5.5.3. NVLink 解决什么问题?
8.1.6、NVSwitch:让更多 GPU 高速互联
8.1.6.1. NVLink 和 NVSwitch 的区别
这两个概念很容易混。
如果只有 NVLink,你可以让几张 GPU 快速互联。
但当 GPU 数量变多时,就需要一个“交换中心”,让更多 GPU 之间形成高效通信网络,这就是 NVSwitch。
8.1.6.2. NVSwitch 解决什么问题?
大模型训练需要很多 GPU 之间做 all-to-all 或 all-reduce 通信。
如果 GPU 数量从 8 张扩展到 72 张、几百张、几千张,通信拓扑就变得非常复杂。
NVSwitch 的意义是:把很多 GPU 组织成更大的高速互联域,让它们更像一个统一的大计算资源。
NVIDIA 官方介绍,NVLink Switch 可以把 NVLink 连接扩展到节点之间,形成无缝、高带宽、多节点 GPU 集群,效果上接近“数据中心级 GPU”。
8.1.6.3. 为什么它对大模型关键?
大模型训练和推理越来越依赖:
- Tensor Parallel
- Expert Parallel
- Pipeline Parallel
- MoE all-to-all
- 长上下文 KV cache 通信
- 多机多卡梯度同步
这些都高度依赖 GPU 之间通信。
因此,在大模型时代:通信能力本身就是算力的一部分。
8.1.7、DGX / HGX / NVL 系统:服务器和机架级方案
8.1.7.1. 为什么要有系统方案?
很多人以为买 GPU 就行。
但 AI 数据中心真正需要的是完整系统:GPU、CPU、内存、高速互联、网络、存储、电源、散热、机箱、管理软件、驱动和工具链。
所以 NVIDIA 不只是卖芯片,还卖系统方案。
如果用“房子”来理解这三者的区别:
DGX 就像精装交付的整体房产。你买到的是一套可以直接拎包入住的完整住宅,包含了所有基础设施和内部装修。
HGX 就像是高品质的标准化建材和户型图。它本身不直接出售给最终用户,而是提供给Dell、HPE等服务器厂商,让他们能快速搭建自己品牌的AI住宅。
NVL 可以看作是由多个房产连接在一起的超大型社区。例如 GB200 NVL72,就是用高速光纤(NVLink)将多个算力单元(GB200 Superchip)连成一个庞大的系统。
8.1.8、开发者生态:PyTorch、TensorFlow、JAX 等深度适配
8.1.8.1. 开发者生态为什么是护城河?
AI 生态里最重要的不只是芯片性能,还有:开发者愿不愿意用,框架支不支持,代码能不能稳定跑,调试和部署是否方便。
NVIDIA 的开发者生态强在:
- CUDA 历史久。
- AI 框架默认优先支持 CUDA。
- 大量开源项目先适配 NVIDIA。
- 工程师熟悉 CUDA 调试和优化。
- 云厂商和服务器厂商普遍支持 NVIDIA。
- 各种工具链、教程、社区经验非常丰富。
8.1.8.2. PyTorch、TensorFlow、JAX 和 NVIDIA 的关系
开发者生态的结果是:当研究员、工程师、开源社区、云厂商都优先围绕 NVIDIA 优化时,NVIDIA 的优势会被不断放大。
8.1.8.3. 为什么其他芯片追赶难?
不是只要硬件性能接近就够了,还要解决:
- PyTorch 是否完整支持?
- 算子库是否够全?
- 编译器是否稳定?
- 模型迁移是否容易?
- 调试工具是否成熟?
- 多卡训练是否稳定?
- 社区有没有足够教程?
- 出问题时有没有足够工程经验?
8.1.9、运维生态:集群管理、监控、调优、合作伙伴体系
8.1.9.1. 为什么运维生态重要?
当你只有 8 张 GPU 时,问题还比较简单。但当你有:
- 1000 张 GPU
- 10000 张 GPU
- 多个数据中心
- 多个训练任务
- 多个团队共用资源
- 复杂权限和成本分摊
你真正需要的不只是 GPU,而是如何把 GPU 集群长期稳定、高利用率、低故障地运行起来。
8.1.11、为什么这构成护城河?
NVIDIA 的护城河可以拆成 5 个层次:
1)硬件护城河:GPU 性能强,迭代快,HBM、Tensor Core、Transformer Engine、低精度计算能力强。
2)软件护城河:CUDA、cuDNN、TensorRT、NCCL、Triton、profiling 工具等生态成熟。
3)互联护城河:NVLink / NVSwitch 让多 GPU 协作更高效,这对大模型训练和推理极其关键。
4)系统护城河:DGX、HGX、NVL、SuperPOD 等让客户不只是买芯片,而是买经过验证的系统。
5)生态护城河:开发者、云厂商、服务器厂商、框架、科研社区、企业客户都围绕 NVIDIA 优化,形成正反馈。
最终结果是:
NVIDIA 的优势不是“我有一块快芯片”,而是“从单卡到机架,从训练到推理,从软件到运维,从开发者到数据中心建设,我都有成熟方案”。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/283558.html