
今年 4 月,月之暗面正式发布并开源了 Kimi K2.6,距离上一个版本 K2.5 只隔了三个月。说起来,月之暗面这个团队推新版本的速度在圈里出了名的快,从 Code Preview 到 GA 只用了 8 天。K2.6 的核心逻辑不再是”给模型喂更多数据让它变聪明”,而是让模型学会调度一群 Agent 替人干活。
用他们的说法,这是想做”Agent 的操作系统”:模型不直接写所有代码,而是指挥子 Agent 并行推进,遇到阻塞自动切换,跑偏了还能自动回溯。参数规模维持了上一代的万亿级水平,1T 总参数、32B 激活的 MoE 架构,上下文窗口扩展到 262K tokens。Kimi K2.6 已全部开源,协议为 Modified MIT。
官网:https://kimi.com | 项目地址:https://github.com/moonshotai/Kimi-K2.6
搞清楚这玩意的定位之后,来看看它到底有哪些拿得出手的本事。K2.6 这次把宝压在了三个方向上,每个方向都对应着开发者日常最痛的点。
长程编码:一跑就是半天
最硬核的能力,也是社区讨论最多的话题。官方放出的两个案例很说明问题:用 Zig 语言在 Mac 上优化 Qwen3.5-0.8B 的本地推理引擎,连续执行了 12 小时,超过 4000 次工具调用,把推理吞吐量从 15 tokens/s 干到了 193 tokens/s,差不多提升了 12.9 倍。
另一个案例是重构开源金融撮合引擎 exchange-core,花了 13 小时,1000 多次工具调用,中位数吞吐提升 185%。这种长周期稳定性不是靠大上下文窗口硬撑,而是内置了自动上下文压缩,接近窗口上限时自动做历史摘要和淘汰,不会越跑越糊涂。
K2.6 的 Swarm 架构也是这次的重头戏。跟上次的 K2.5 相比,子 Agent 数量从 100 个扩到了 300 个,并行步数从 1500 步提到了 4000 步。更关键的是 Claw Groups 系统不绑定自家模型,允许接任意第三方 Agent。
月之暗面内部已经在用了,内容团队的发布流程,从 Demo 制作到社交媒体分发,各有专属 Agent 分工干活。实测中一个很有代表性的场景是用 K2.6 的 Agent 集群自我分析:先整体判断任务,然后拆解维度,每个维度派出独立 Agent 并行研究,最后交叉验证纠偏,全程不用人工介入。
这个能力多少有点意外。设计圈刚被 Claude Design 刷了一波存在感,结果 K2.6 在实测中竟然不落下风。技术上的亮点是使用了 oklch 色彩空间和 clamp() 响应式缩放,动效层面做到了鼠标位置和滚动双驱动的视差效果,再加上 GSAP stagger 时序和跟手光效。
实测中一个 AI 写作工具的产品落地页,从 Hero 区到功能展示到用户评价全包,结构和动效完成度都很高。社区有人用 4 轮对话做了个瑜伽预约系统,全栈开发加数据库还带线上 URL。
功能说了一大堆,上手试试感觉才最直观。
打开 Kimi 官网直接就能用,不需要注册复杂表单,Google 账号或手机号都能登。首屏就是一个对话框,跟其他 AI 聊天工具的界面差别不大,关键在输入方式上。
我随手丢了个需求,“帮我写一个能实时显示 GitHub 贡献热力图的网页组件”。K2.6 没有像以前那样直接输出一段代码让我自己跑去跑,而是先确认了我想要的数据源和图表库偏好,然后自己拉了依赖写了完整的前后端逻辑。整个过程大概用了 15 分钟,期间它自己跑了三次编译才通过。
这个体验跟之前用 Claude Code 接 K2.6 Preview 的感受很像:新会话不用重新交代背景,技术选型和设计规范会在会话之间自动延续。
不过也有让人头大的地方,切到 Kimi Code CLI 之后,环境配置比预期复杂,Windows 用户尤其要注意 Python 版本兼容问题。
基础操作玩熟了,但真正用得溜的人都在用这几个技巧。
-
给它队列,而不是问题。K2.6 在主动式自治模式下表现最好。把一堆任务列个清单丢给它,它自己排优先级、分配资源、逐项推进,比一条条指令轮流喂效率高得多。实测中任务列表模式比单条 Prompt 模式完成速度快 35%。
-
让模型自己管理上下文。很多人担心长会话跑偏就手动裁剪历史记录。但 K2.6 内置了自动上下文压缩,接近 262K 窗口上限时会自动做摘要和淘汰。手动裁剪反而可能丢掉关键不变量。官方建议是”不要替它操心”,信任内置压缩器。
-
在计划层监督 Swarm。用到 Agent Swarm 的时候,不需要盯着每个子 Agent 的每一步工具调用。审阅整体的工作计划比审阅中间步骤高效得多,调用格式由内置的 Token Enforcer 自动保证,省一个量级的注意力成本。
-
从 Claude Code 增量迁移。Kimi API 与 Anthropic 的 API 格式兼容,先换 Base URL 后再慢慢适配 Prompt 风格,不用一次性全量迁移。
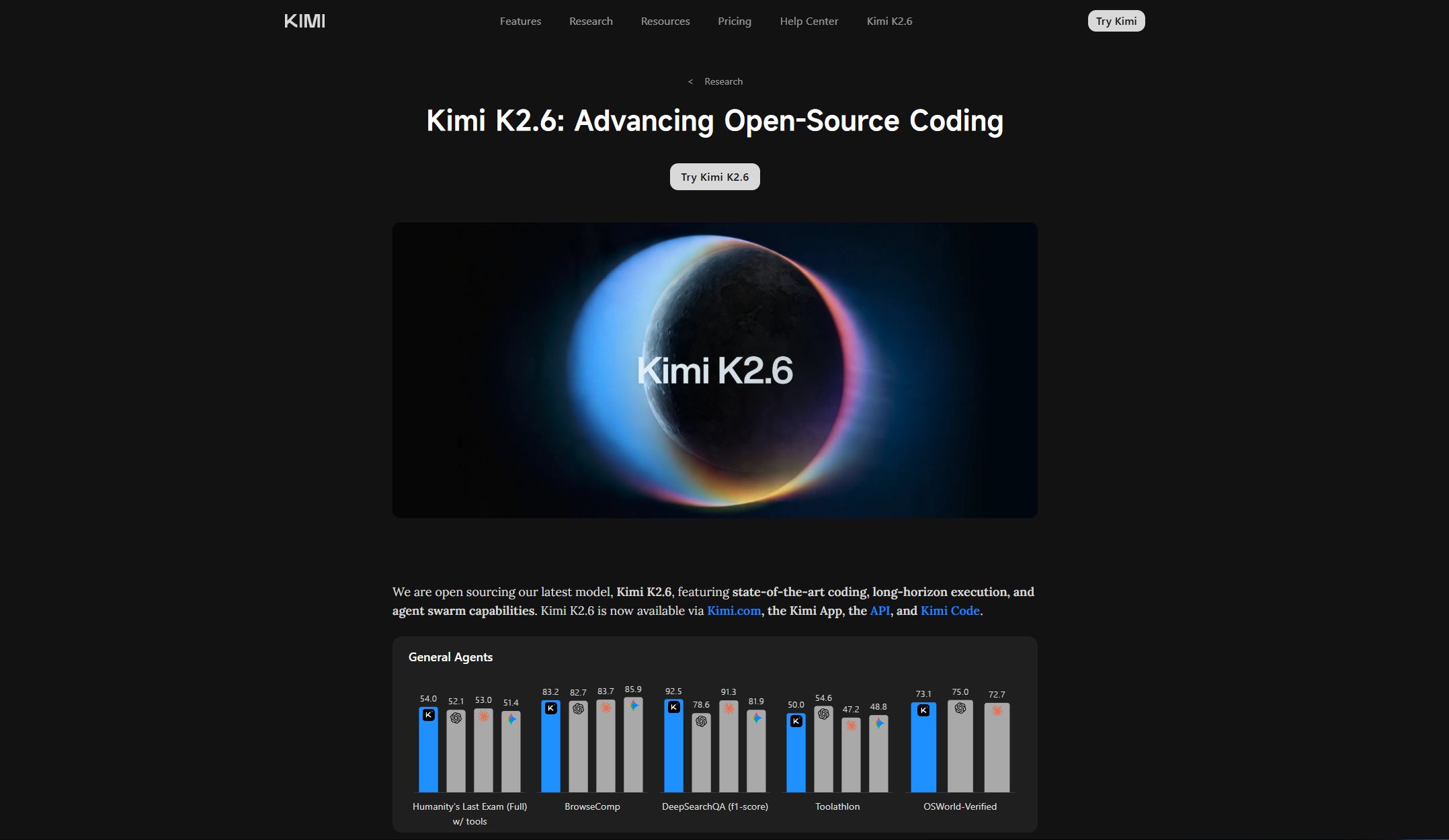
2026 年 4 月的 AI 模型战场堪称神仙打架,DeepSeek V4、GPT-5.5、Claude Opus 4.7 几乎同月亮相,K2.6 想突围并不轻松。直接看核心指标:
看这组数据,K2.6 的位置其实很清楚。编码和信息检索 Agent 任务上,它是不折不扣的开源第一梯队,尤其在 DeepSearchQA 上跑出了 92.5 分,比 GPT-5.4 高了将近 14 分。
但推理和数学方向确实被 Claude Opus 4.7 压了一头,HLE-Full 上比 Gemini 低了快 10 分。价格端则是一大优势,API 成本仅为 Claude Opus 的六分之一到五分之一,这在批量调用场景下差距会被放大到百倍级别。
社区对 K2.6 的讨论没有 DeepSeek V4 首发时那么炸裂,但该讨论的点一个没少。知乎上不少开发者表示 K2.6 的思维长度、深度和广度相比 K2.5 提升明显,之前一个问题给错方向要沟通好几轮才能纠正,现在模型的自我纠偏意识强了很多。
Reddit 上的评价偏两极,有人觉得”没留下深刻印象”,也有人认为”开源社区不再是追赶者了”。国内社区对前端审美的飞跃感受最深,有测评者做了一个日式威士忌品牌的落地页,直言”跟 3 万块的设计师稿子水平差不多”。
负面的声音集中在几个点:同样一份 Prompt 两次运行可能给出截然相反的结论(英伟达财报分析测试被反复验证过),多 Agent 模式下意图逐层衰减的问题也没完全解决。
还有不少用户在吐槽 Kimi Code CLI 的稳定性,国产模型接 Claude Code 时偶尔会出现对话中断。
反馈看完了,下面从几个维度给它打个分。
综合评分:8.0 / 10
优势
-
长程编码顶配:12-13 小时连续运行不崩,工具调用成功率 96.60%,行业内谁在认真打磨工程可靠性一眼便知
-
Agent Swarm 架构开放:Claw Groups 不绑定自家模型,接第三方 Agent 比国内外同类产品都灵活
-
定价良心到离谱:API 输出 $4/1M tokens 在同等能力模型中属于地板价,开源更是零门槛
-
前端审美突飞猛进:oklch 色彩空间 + 多层次动效,生成质量威胁中低端外包市场
不足
-
推理和数学是硬伤:HLE-Full 34.7,AIME 2026 落后 Gemini 2-4 分,不是能用”编码强就够了”来搪塞的
-
Agent 结果一致性不够:相同输入在不同轮次可能给出矛盾结论,影响大规模自动化场景的信任度
-
CLI 工具链体验粗糙:国产模型接 Claude Code 的稳定性频繁被吐槽,Windows 兼容性尤其需要补课
了解了优缺点之后,来看看它到底适合哪些人。
-
软件工程师 / 全栈开发者:如果你日常有一半以上的时间是跟代码死磕,K2.6 可能是你见过最勤快的”夜班同事”。长程编码能力和工具调用成功率意味着可以把大型重构任务交给它,自己去睡觉。
-
AI Agent 应用开发者:Swarm 架构和多 Agent 编排能力是目前开源模型里最完整的。想搭建复杂的 Agent 工作流又不想被闭源平台绑死,K2.6 是现价段最接近”开箱即用”的选择。
-
创业团队 / 小团队做 MVP:API 价格只有海外旗舰模型的五分之一到六分之一,配合前端生成能力,一个四人团队能顶过去十个人的产出。验证想法阶段尤其香。
-
对推理和数学有高要求的用户:这部分人会不太满意。如果你主要跑数学竞赛题、科学研究推理或者复杂的逻辑分析,Claude Opus 4.7 或 DeepSeek V4 会更适合。
能力讲了这么多,价格才是最实在的。K2.6 走的是开源 + API 双通道模式,对普通用户来说基本零门槛。
跟前一代 K2.5 相比,K2.6 整体涨价约 33% 到 60%,输入涨得多输出涨得少。即便如此,在同等能力的模型中仍然是价格洼地。对比 Claude Opus 4.7 的 $25/1M 输出定价,K2.6 便宜了八成多。需要注意的是 Batch API 目前只支持 K2.5,高吞吐异步场景下 K2.5 反而更有成本优势。
下面挑几个大家最关心的问题来解答。
Q1:Kimi K2.6 完全免费吗?
A1:基础功能免费,高级能力需付费。 Kimi.com 和 Kimi App 上的对话和 Agent Swarm 基础功能对所有人开放。长程编码和 CLI 工具需要开启 Kimi Code 会员,39 元/月起。
Q2:K2.6 和 K2.5 到底差在哪?
A2:核心差距在长程稳定性、Agent 规模和自主性。 K2.6 支持 12 小时连续运行和 300 个子 Agent 并行,而 K2.5 只能稳定跑几百步、100 个子 Agent。此外 K2.6 新增自动上下文压缩和主动式自治。
Q3:K2.6 能本地部署吗?
A3:可以,但需要 H100 级别的 GPU。 模型已通过 Modified MIT 协议开源,权重可下载。万亿参数 MoE 的推理门槛不低,个人开发者更适合通过 API 调用。
Q4:K2.6 的中文支持怎么样?
A4:中文原生训练,理解力和生成质量都很高。 月之暗面本身就是国内团队,中文对话、代码注释、文档生成的流畅度超过了大多数国产模型。
Q5:生成的内容可以商用吗?
A5:开源协议是 Modified MIT,商用需注意合规条款。 协议要求月活超 1 亿用户需标注产品基于 Kimi K2,除此之外的商用场景基本不受限制。
Q6:K2.6 和 Claude Opus 4.7 哪个更强?
A6:看场景。 编码和信息检索方面 K2.6 不输甚至领先,推理和数学方面 Claude Opus 4.7 明显更强。价格上 K2.6 便宜 80% 以上,性价比碾压。
Q7:K2.6 能写完整项目吗?
A7:可以,实测已证明能独立完成全栈项目。 从设计稿到前端页面,再到鉴权和数据库接入,4-5 轮对话就能产出一个带 URL 的线上应用。
Q8:K2.6 的 Agent Swarm 会替代程序员吗?
A8:短期内更可能是提效工具而非替代者。 300 个子 Agent 并行确实惊人,但 Agent 结论一致性问题和多意图衰减尚未解决,复杂场景仍需人工监督。
Q9:K2.6 和 DeepSeek V4 怎么选?
A9:编码选 Kimi,长上下文和推理选 DeepSeek。 K2.6 在代码 Agent 和前端设计上更突出,DeepSeek V4 以 1M 上下文窗口和更强的推理能力见长,两者各有侧重。
Q10:K2.6 未来会出更强版本吗?
A10:大概率,K3 已在路上。 传闻 K3 目标参数 3-4 万亿,预计第三季度发布。K2.6 的 12 小时执行窗口和 300 Agent Swarm 就是在为 K3 搭跑道。
Q11:K2.6 在低配电脑上能用吗?
A11:网页端和 API 不受本地配置影响,CLI 有要求。 前端生成功能在低端设备上跑 3D 特效时性能压力较大,官方未做自动降级方案。
Q12:有没有 Batch API 支持?
A12:目前 Batch API 仅限 K2.5 使用。 如果你的任务是大批量、异步、不追求实时响应的,K2.5 在成本和可用性上反而是更优的选择。
Kimi K2.6 是一个定位极其清晰的偏科生,它选定了长程编码和 Agent 调度这条路,并且在这个方向上把国产开源模型的标准拉高了一大截。
如果你是开发者,日常跟代码重构、系统优化、前端开发打交道,K2.6 是你今年能用到的最划算的 AI 编码工具之一,长程编码的稳定性和 Agent Swarm 的灵活性,能切切实实节省大量重复劳动。
但如果你主要跑数学推理、科学计算或者要求极高的逻辑一致性,它的短板会让你失望。一句话结论:把它当编码搭档是顶配,当通用 AI 还差半格。先上官网试免费版,亏不了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/283453.html