
「生成即理解」
目录
01 行业困境:生成与理解的长期割裂,专用模型的内卷困局
1. 任务与模型的强绑定,泛化性先天不足
2. 生成与理解的二元对立,资源重复浪费
3. 以往融合尝试的固有缺陷
02 核心创新:把所有视觉理解,重写成“生成可解码RGB图像”
1. 统一范式:感知即生成,输出即RGB
2. 训练方式:极轻量指令微调,不破坏基座能力
3. 关键技术:可解码可视化 schemes,让生成结果可量化
(1)度量深度的可逆映射
(2)分割与法向的自然映射
03 实验实证:统一模型碾压专项专家,生成理解双SOTA
1. 2D语义理解:全面超越SAM 3
2. 3D几何理解:超越Depth Anything 3与Lotus-2
3. 生成能力:与基座模型持平,实现“鱼与熊掌兼得”
04 范式重构:生成式预训练,将成为视觉基础模型的统一底座
1. 生成即理解:从“假说”到“实证”
2. 统一接口:图像生成 = 视觉任务的通用语言
3. 路线选择:视觉基础模型的未来,属于生成范式
05 客观局限:当前范式仍需解决的现实挑战
06 总结:视觉领域的GPT时刻,正在到来
过去五年,计算机视觉的发展路径始终围绕着一个核心分歧:表征学习该走判别式路线,还是生成式路线。
从监督分类、对比学习、掩码自编码,到各类自监督范式轮番登场,业界长期默认:生成模型只管画得像,理解与感知得靠判别模型。想要分割、深度估计、法向预测,就要为每个任务设计专属架构、损失函数与标注流程;想要兼顾图像生成与视觉理解,就得用多模型拼接,既冗余又难以协同。学界与工业界的主流实践,一直是“生成、理解二分”,用专用模型解决专用问题。
而在2026年4月,Google DeepMind发布的《Image Generators are Generalist Vision Learners》直接打破这一共识——图像生成模型,本身就是通用视觉学习器。
论文基于Nano Banana Pro图像生成模型,通过极轻量指令微调得到统一模型Vision Banana,在不牺牲生成能力的前提下,于2D分割、3D深度估计、法向估计等任务上超越SAM 3、Depth Anything 3等专项专家模型,证明生成式预训练可像LLM预训练一样,成为视觉基础模型的统一底座。
这不是一次简单的SOTA刷新,而是对视觉基础模型范式的重构:未来的视觉系统,或许不再需要割裂的“生成模型”与“感知模型”,只用一套生成预训练参数,就能以统一接口完成从画图到理解的全视觉任务。
在Vision Banana出现之前,视觉领域长期存在三层难以调和的矛盾。
传统视觉范式高度专业化:
- 语义/实例/指代表达分割,依赖SAM系列等专用架构与海量掩码标注;
- 单目深度估计,需要相机内参参与训练与推理,用专属回归损失优化;
- 表面法向估计,同样依赖专门设计的几何监督与网络结构。
这类模型任务内精度高,但跨任务迁移极差,换一个任务就要重新设计头结构、标注数据、训练流程,难以实现真正的通用视觉。
图像生成模型(如FLUX、Nano Banana Pro、GPT-Image)与视觉理解模型长期各自进化:
- 生成模型追求高保真、语义可控、细节丰富,预训练学习海量视觉分布;
- 理解模型追求分类、检测、分割、几何估计精度,用判别式目标优化。
两者共享同样的视觉世界,却用两套体系、两套参数、两套训练流程,大量冗余计算与标注成本被浪费。
此前也有研究试图用扩散模型做感知任务,但普遍存在两大硬伤:
- 输出格式不可解码,无法量化评估,只能看可视化效果;
- 全量微调+添加专用模块,彻底丢失原生成能力,通用性归零。
这些方案本质是“用生成架构做判别任务”,并未真正打通生成与理解的壁垒。
而Vision Banana的核心突破,正是不改变生成模型本质、不添加专用结构、不牺牲生成能力,只用轻量指令微调,把感知任务全部转化为图像生成问题。
Vision Banana的设计哲学极度简洁,完全对标LLM的“生成预训练+指令微调”范式:
图像生成 = 文本生成;视觉理解任务 = 指令;可解码RGB图 = 任务输出。
图| 通过指令微调揭示图像生成模型的隐藏视觉理解能力
论文提出一个颠覆性设定:所有视觉理解任务的输出,都参数化为可解码的RGB图像。
- 分割:按提示指定颜色生成掩码图,聚类像素即可还原掩码;
- 深度估计:生成深度伪彩色图,可严格逆变换回物理深度值;
- 表面法向:法向向量直接映射为RGB,天然对齐色彩空间。
这种设计带来三大优势:
1. 单一模型通吃多任务:权重完全共享,仅靠prompt切换任务;
2. 微调成本极低:只教模型按格式输出RGB,几乎不增加新数据;
3. 生成能力无损:输出仍是图像,基座生成先验不被破坏。
Vision Banana以Nano Banana Pro为基座,采用极低比例混合视觉任务数据做轻量指令微调,不进行全量微调、不添加任务分支、不修改主干架构。
论文用两组基准验证生成能力保留:
- 文生图(GenAI-Bench):Vision Banana胜率53.5%,略超基座Nano Banana Pro;
- 图像编辑(ImgEdit):胜率47.8%,与基座基本持平。
直白说:模型学会了理解,没忘记怎么生成,这是此前所有融合方案都未能实现的关键。
为了让生成的RGB能还原为感知标签,论文设计了严格可逆的映射规则:
图| 度量深度与 RGB 颜色值的双射映射可视化
(1)度量深度的可逆映射
深度值通过幂变换弯曲后,映射到RGB立方体边沿,形成一一对应双射,可精确解码回物理深度(单位:米)。
该设计全程不依赖相机内参,彻底摆脱传统深度模型的硬件约束。
(2)分割与法向的自然映射
- 分割:用prompt指定类别→颜色对应,聚类相近色值即可提取掩码;
- 表面法向:x/y/z三个分量直接对应RGB通道,无需复杂转换。
这些设计极简,却让生成模型的输出,直接接入传统感知benchmark的量化评估体系。
Vision Banana在不使用专项标注、不依赖相机参数、不添加专用结构的前提下,在2D理解、3D理解、图像生成三大维度全面领先或对齐SOTA。
图| 指令微调后的 Vision Banana 在生成与理解任务上超越 / 持平 SOTA 专用模型
作为视觉理解的核心任务,分割领域长期由SAM系列主导,而Vision Banana在零样本迁移设定下实现反超:
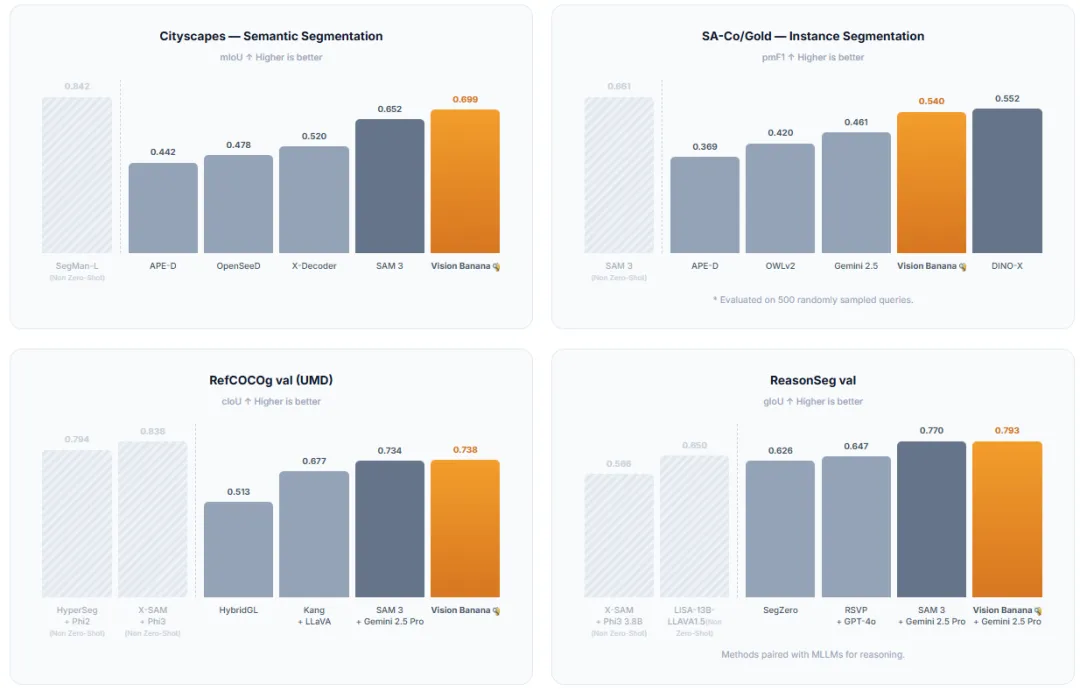
图| Vision Banana 在多个分割数据集上与 SOTA 方法对比
- Cityscapes语义分割mIoU:0.699 vs SAM3的0.652,领先4.7个点;
- RefCOCOg指代表达分割cIoU:0.738 vs SAM3 Agent的0.734;
- ReasonSeg推理分割gIoU:0.793 vs SAM3 Agent的0.770;
- SA-Co/Gold实例分割:与DINO-X持平(0.540 vs 0.552),且未使用该数据集训练。
图| Vision Banana 根据指令提示执行语义分割
这意味着:专门用来分割的模型,被一个顺便做分割的生成模型打败。
3D任务对几何先验要求极高,传统模型高度依赖相机参数与专门监督:
图| 零样本迁移设定下单目度量深度估计结果
- 度量深度估计(4数据集平均δ₁):0.929 vs Depth Anything 3的0.918;
- 表面法向估计(室内平均角度误差):15.549° vs Lotus-2的16.558°,误差最低。
更关键的是:训练全程零真实深度数据、零相机内参、零专项几何损失,完全靠生成预训练学到的几何常识完成预测。
图| Vision Banana 度量深度估计能力演示
在GenAI-Bench、ImgEdit等权威生成基准上,Vision Banana与Nano Banana Pro无显著差距,可视化对比也几乎无法区分。
这组结果给出铁证:
图| Vision Banana 与 Nano Banana Pro 文生图效果对比
Nano Banana Pro在预训练阶段就已具备完整的视觉理解表征,指令微调只是把这些能力“解锁”并“格式化输出”。
Vision Banana的真正价值,不在指标,而在重新定义视觉基础模型的技术路线。

学界一直有直觉:能生成高保真图像,必然理解语义、结构、几何、空间关系。
但此前始终缺乏严格量化证据。Vision Banana首次系统证明:
图像生成预训练 = 视觉领域的LLM预训练,生成过程自然习得通用视觉表征,可通过指令微调迁移到全品类感知任务。
正如文本生成统一NLP任务,RGB图像生成可以统一所有视觉任务:
- 输入:图像+自然语言指令;
- 输出:指定格式的RGB图;
- 解码:还原为分割掩码、深度值、法向向量等。
未来视觉系统可彻底告别任务专属头、专属损失、专属标注,一套模型、一套流程、一套接口搞定从创作到感知的全场景。
过去五年,视觉表征学习以判别式(对比学习、掩码重建)为主流;
未来,生成式预训练将成为构建通用视觉基础模型的主线。
原因很简单:
- 生成模型天然建模完整数据分布,泛化性远优于判别模型;
- 多任务统一,降低研发、部署、维护成本;
- 生成与理解一体化,更接近人类“先理解再创作、通过创作深化理解”的认知逻辑。
中立来看,Vision Banana打开了新范式,但仍存在明显短板:
1、计算成本高于专用模型
生成模型推理开销远大于轻量判别模型,落地端侧、高密度场景仍需优化加速。
2、部分细粒度任务仍有差距
实例分割在SA-Co/Gold上略低于DINO-X,对小物体、遮挡场景的精度仍有提升空间。
3、指令与解码规则需人工设计
目前任务prompt、颜色映射、逆变换规则需人工定义,尚未实现完全端到端自动化。
4、未扩展至视频与多视图
当前仅针对单目静态图像,视频时序理解、多视图3D重建仍待验证。这些局限不否定范式价值,反而指明了清晰的演进方向。
NLP领域的革命,始于“生成预训练+指令微调”统一所有语言任务;
计算机视觉的革命,正由“生成预训练+指令微调”统一所有视觉任务开启。Vision Banana的贡献可概括为三点:
1. 实证图像生成模型就是通用视觉学习器,生成预训练足以支撑全品类感知SOTA;
2. 建立感知即生成的统一范式,用RGB图像作为视觉任务通用接口;
3. 实现生成与理解不妥协,单一模型同时胜任创作与感知,颠覆传统专用模型路线。
长期来看,这篇工作很可能成为视觉基础模型的分水岭:
未来不再有孤立的文生图模型、分割模型、深度模型,取而代之的是以生成式预训练为底座、以指令为接口、兼顾创作与感知的全能视觉基础模型。
当生成与理解不再对立,计算机视觉才真正走向通用。
Ref
论文标题:Image Generators are Generalist Vision Learners
论文链接:https://arxiv.org/pdf/2604.20329
项目链接:https://vision-banana.github.io/
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/283379.html