
如果你现在就在问 OpenClaw 模型怎么选,最短答案是:先选最适合当前任务的模型,而不是先追“最强模型”。OpenClaw 模型选择真正影响结果的,不只是模型本身,还包括任务是否标准化、是否要接浏览器和文件、是否允许外部云模型、以及团队能不能稳定复核输出。
这篇文章不做空泛盘点,而是直接回答三件事。第一,Claude、GPT、Kimi、DeepSeek 和本地模型该怎么比。第二,OpenClaw 模型选择时,谁更适合内容、运营、自动化和内网流程。第三,第一轮试点怎么做,才不会因为选错模型把整条工作流带偏。
如果你已经在搭执行环境,可以把这篇文章和 OpenClaw 教程、AI Agent 工作流、OpenClaw 安装说明 一起看。这样做的好处是,OpenClaw 模型选择不会停留在讨论层,而是会直接回到你的真实任务、真实 SOP 和真实交接流程里。
关于搜索内容质量与代理式工作流的公开参考,你也可以顺手对照 Google Search Central 的 helpful content 指南、OpenAI Agents SDK 文档、Model Context Protocol 介绍 和 Anthropic Claude 开发文档。这些资料不会替你做 OpenClaw 模型选择,但能帮你把判断标准定得更稳。
很多团队一开始就把 OpenClaw 模型选择理解成“选冠军”。这通常会带来两个问题。第一,讨论会被品牌热度带偏,忽略任务差异。第二,试点会变成主观体验分享,最后没有办法回到同一张评分表里比较。
更稳的顺序是先分任务。你要先判断当前流程更偏中文写作、复杂推理、代码执行、工具协同、长流程稳定,还是偏内网敏感数据。OpenClaw 模型选择一旦先把任务拆开,后面的比较就会清楚很多,因为每类模型的强项和代价都不一样。
对大多数中文团队来说,第一轮最重要的不是“回答最聪明”,而是输出能不能稳定复核、能不能接住 SOP、能不能减少返工。OpenClaw 模型选择只要围绕这些现实问题来做,通常不会偏得太远。
OpenClaw 模型选择最怕维度不统一。A 同事盯中文自然度,B 同事盯代码能力,C 同事只看速度,最后得到三套彼此不能合并的结论。更有效的做法,是先写死同一套决策维度,再让不同模型跑同一批真实任务。
建议第一轮至少看五个核心维度:cost、setup、control、risk、performance。如果你的团队更重协作,还可以补两个辅助维度:support 和 management。这几项能直接覆盖大多数 OpenClaw 模型选择场景。
cost:看单次任务成本,也看返工成本和维护成本。setup:看浏览器、文件、账号体系和 SOP 接入难度。control:看格式稳定性、路由可控性和审计能力。risk:看数据边界、越权风险、漂移风险和供应商依赖。performance:看长流程成功率、复杂任务完成度和失败可定位性。
OpenClaw 模型选择一旦按照这五个维度去比,你就不会轻易被“这个模型大家都在用”之类的判断带偏。因为真正要比较的不是名气,而是它在你的流程里能不能稳、能不能控、能不能被接手。
如果只看定位,Claude 更偏长文本理解、复杂说明和结构化写作;GPT 更像综合能力均衡的通用执行层;Kimi 对中文内容、中文资料整理和中文运营协作更友好;DeepSeek 更常被拉进代码、推理和结构化判断对照;本地模型则主要解决 control 和 risk,不是天然追求“最强回答”。
Claude 常见优势是长上下文阅读、方案梳理和 SOP 解释。它在需要把复杂内容讲清楚、讲完整时,通常比较稳。GPT 的价值更像通用底盘,尤其适合要接浏览器、文件、代码辅助或多种工具链的团队。Kimi 在中文语境下的可读性和上手门槛通常更友好,适合非技术同事继续加工。DeepSeek 更适合进入代码、推理、规则判断占比更高的流程。本地模型的关键不在“输出最像人”,而在边界可控、部署可控、数据路径可控。
Claude 的坑通常不在“写不出来”,而在团队容易把它默认成所有任务都能吃下的长文本专家。GPT 的坑是太通用,导致很多团队懒得定义任务边界。Kimi 的坑是被当成“中文顺手就等于全能”。DeepSeek 的坑是只看某次推理表现,不看长流程稳定性。本地模型的坑则更现实,往往出在 setup 成本、维护能力和效果预期不一致。
- Claude:更强在长文理解、结构化表达和复杂说明。更适合方案初稿、SOP 解释和长文梳理。
- GPT:更像综合底盘。更适合通用 Agent、跨工具执行和多步骤自动化。
- Kimi:更偏中文友好。更适合中文运营、中文资料整理和内容草稿。
- DeepSeek:更常被拉进代码、推理和结构化判断。更适合复杂分析任务。
- 本地模型:更强调 control 和 risk。更适合内网任务、敏感数据流程和强边界环境。
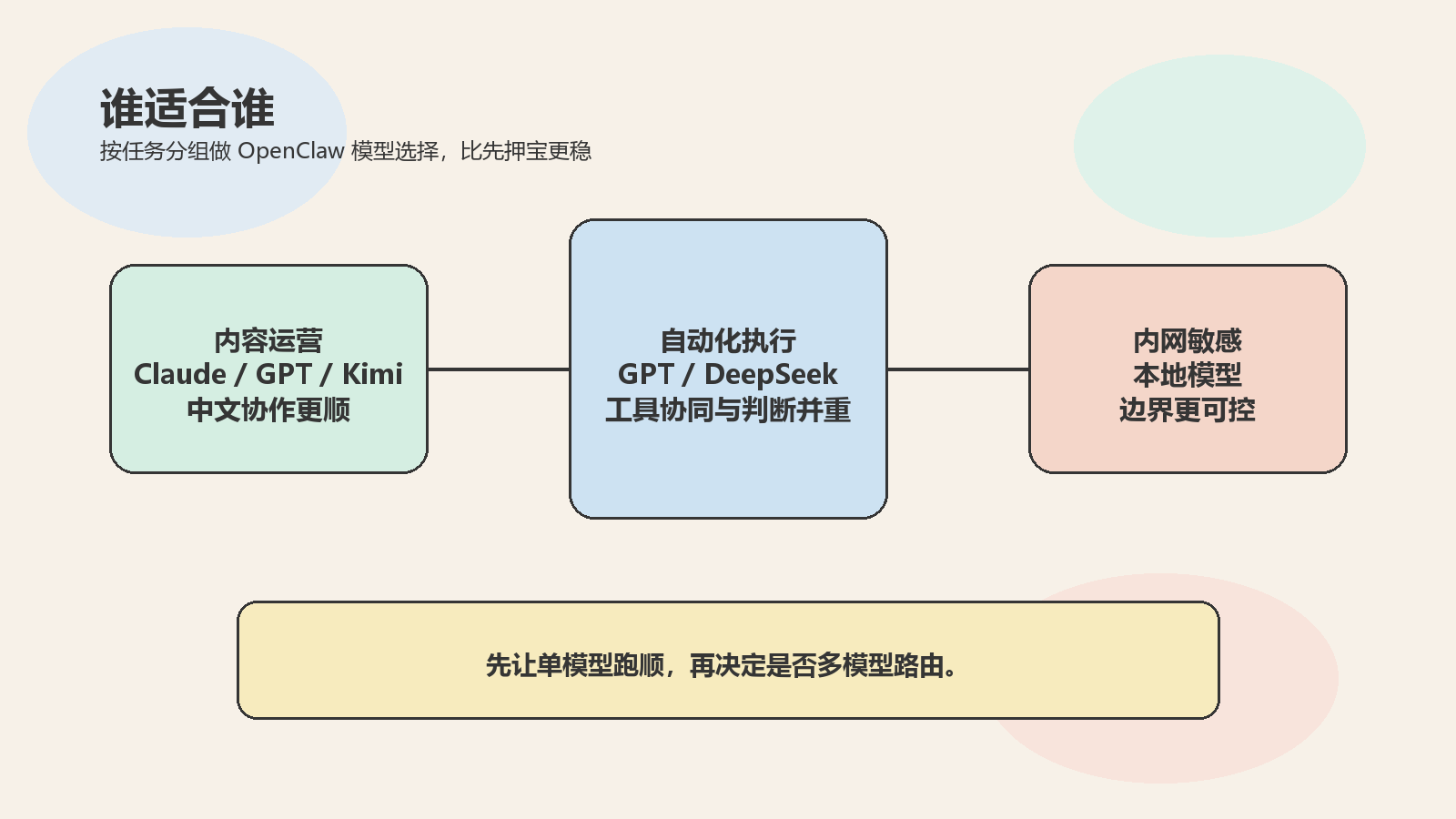
如果你的主要任务是中文内容、社媒运营、标题判断、资料压缩和 SOP 解释,OpenClaw 模型选择通常会优先在 Claude、GPT、Kimi 里做第一轮。理由很简单,这类任务最先要求的是中文可读、结构稳定、方便人工接手,而不是极限推理成绩。
做浏览器自动化、工具串联和多步骤执行时,GPT 往往更适合放进第一轮通用试点,因为它在多工具协同上的适配更均衡。Claude 更适合拿来处理复杂说明和高质量初稿。Kimi 更适合中文团队快速跑起来,尤其当执行人不是纯技术同事时,接手成本会更低。
如果你的任务已经明显带代码判断、规则拆解、异常定位,DeepSeek 就该进入同批对照,而不是等到后期再看。OpenClaw 模型选择最稳的做法,不是先押宝,而是先把不同任务放进不同测试组。
- 更适合先试 Claude / GPT / Kimi 的团队:中文内容多,运营协同多,希望快速试点,同时保留人工复核。
- 更适合把 DeepSeek 拉入对照的团队:代码、推理、结构化判断占比更高,愿意拿真实任务做多轮测试。
- 更适合单独评估本地模型的团队:数据边界敏感,需要私有化部署,也能承担运维和调优成本。
很多人把本地模型理解成“更安全,所以应该尽快上”。这个判断太粗。OpenClaw 模型选择里,本地模型真正值得上,通常出现在三个条件同时满足的时候:第一,你有明确的数据边界要求;第二,你有能力承担 setup、维护和调优;第三,你的流程已经稳定,不需要先靠云模型快速找打法。
如果这三个条件还不满足,本地模型更适合列入第二阶段,而不是第一阶段。因为第一阶段最需要的是快速看清任务边界、提示词规范和人工接手点。很多团队的问题根本不在模型,而在任务设计还没稳定。
所以 OpenClaw 模型选择不是“云模型还是本地模型”的道德题,而是时间顺序题。先把流程跑通,再决定哪些节点必须回到本地。这样的迁移路径通常比一开始全压本地更稳。
第一轮试点最稳的做法,不是把五类模型一次性全接进主流程,而是挑一条真实但低风险的任务做对照。例如,同一份标题规划、同一份资料包、同一份 SOP 检查清单,让两个到三个候选模型在同一套规则下输出结果。
优先选“真实但可回滚”的任务。比如文章结构整理、中文资料压缩、标准回复生成、浏览器步骤说明、异常记录总结。这些任务足够接近真实流程,但一旦失败,人工可以快速接手,不会把整条工作流带偏。
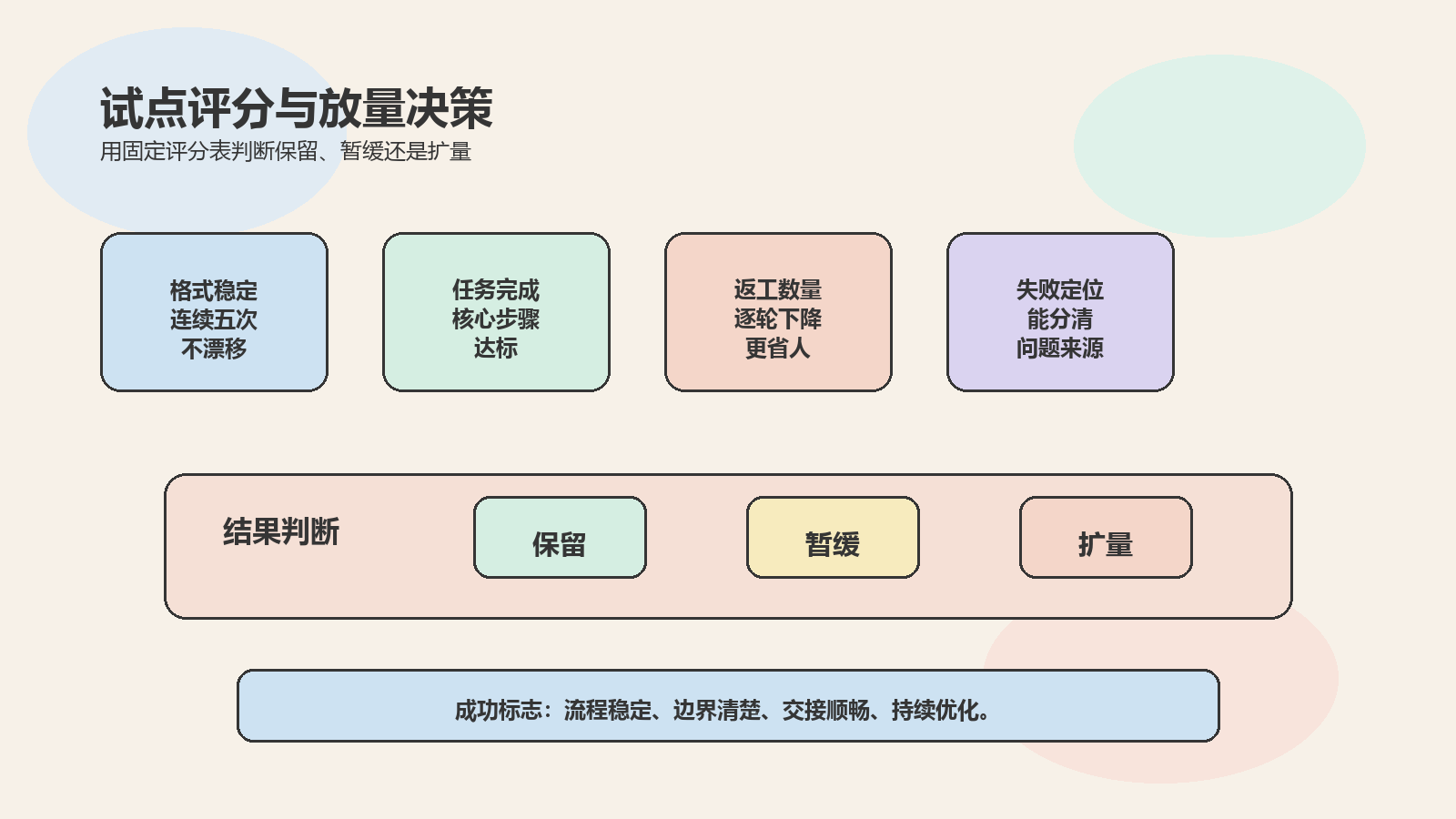
评分表至少保留五项:格式稳定度、任务完成度、中文可读性、人工返工点数量、失败原因清晰度。你也可以把 模型接入清单 和 多账号协作流程 里的检查点直接抄进试点表,让 OpenClaw 模型选择和你的执行规范共用一套语言。
建议把结果记录成表,而不是口头印象。下面这张表就能直接作为第一轮模板。
- 格式稳定度:看是否持续按指定结构输出。通过标准是连续 5 次任务不明显漂移。
- 任务完成度:看关键步骤是否都完成。通过标准是核心步骤完成率达到 80%。
- 中文可读性:看是否便于中文团队继续加工。通过标准是人工只需轻度润色。
- 返工点数量:看每次输出要修多少处。通过标准是返工点持续下降。
- 失败可定位性:看失败后能不能快速找原因。通过标准是能区分提示词、工具或模型问题。
试点阶段不要急着上多模型路由。先让单模型把流程跑顺,再决定是否要拆成“写作一个模型、代码一个模型、内网一个模型”。OpenClaw 模型选择越早上复杂路由,越容易把问题定位搞乱。
第一个误区,是把 OpenClaw 模型选择当成一次性决策。现实里它更像阶段性匹配。试点阶段、扩量阶段和私有化阶段,最合适的模型可能根本不是同一个。
第二个误区,是只看单次输出,不看连续任务稳定性。很多模型第一次表现都不差,但一旦进入真实流程,连续跑五次、十次,格式漂移、上下文丢失和风格波动才会暴露出来。Agent 场景最怕的不是偶尔写得一般,而是无法稳定复现。
第三个误区,是把“中文自然”当成唯一标准。中文自然当然重要,但如果经常偏离格式、漏掉步骤、难以复核,团队最后还是会被返工拖慢。第四个误区,是高估本地模型的即时收益。它的价值更多在 control 和 risk,不在于无门槛替代全部云模型。
更现实的做法是先定义任务,再定义评分表,最后定义切换条件。不要今天觉得 Claude 顺,明天觉得 GPT 全能,后天又因为价格去试 DeepSeek,结果工作流频繁切换却没有记录。OpenClaw 模型选择一旦没有记录,就很难复盘。
通常不是。更常见的正确做法,是选一个最适合当前任务和当前团队阶段的模型。试点阶段看稳定度,扩量阶段看成本和协作,私有化阶段看边界和维护。
可以,但更建议分阶段做。先用单模型把流程跑通,再根据任务类型拆分。如果一开始就多模型并行,问题定位通常会更难。
通常先从中文表达顺、综合能力稳、便于人工复核的模型开始更稳。对很多中文团队来说,Claude、GPT、Kimi 更适合作为第一轮对照对象。
更适合代码、推理、结构化判断占比更高的情况。它是否真的适合你的 OpenClaw 流程,仍然应该看同任务实测,而不是只看外部讨论。
更准确的说法是,它更可控。是否更适合,取决于你有没有部署能力、维护预算和明确的数据边界要求。如果这些条件都没有,本地模型未必更省事。
最该避免的是没有统一评分标准就频繁换模型。这样最后很难分辨,到底是模型不合适,还是任务规则本身没定义清楚。
至少要让候选模型跑过一批相似任务,并保留返工记录。只看一两次输出,通常不够判断它能不能进真实流程。
通常先优化任务设计更划算。很多“模型不行”的问题,最后发现其实是输入不清、输出标准不清、人工复核点缺失导致的。
OpenClaw 模型怎么选,关键不是追一张榜单,而是先把任务类型、决策维度和团队阶段讲清楚。Claude、GPT、Kimi、DeepSeek 和本地模型,各自都有更适合进入的流程位置。真正稳的 OpenClaw 模型选择,不是一次押中,而是让评分标准、试点记录和切换条件始终可复用。
如果你现在还在试点阶段,建议先用两到三个候选模型做同任务对照,保留通过率、返工点和失败原因。等你知道问题更多来自模型、提示词还是流程,再决定是否做多模型编排或私有化部署。这样的 OpenClaw 模型选择慢一点,但更不容易把整条工作流带偏。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/282012.html