
OpenAI以惊人速度推出GPT-5.5,代号“土豆”,在多项基准测试中表现优异。此次更新并非微调,而是自GPT-4.5以来完整重训的底座模型,核心聚焦于“智能体化”,使模型能自主完成多步骤任务,如代码编写、在线研究、数据分析等。GPT-5.5在终端自主任务、跨职业知识工作和自主电脑操作等基准测试中领先对手,但在真实代码修复测试中与Claude存在争议。其最大的亮点在于智能体工作流表现,如在Web研究和金融分析Agent任务中表现突出。尽管价格翻倍,但OpenAI强调效率提升和Token消耗减少。GPT-5.5适合需要模型自主完成复杂任务的场景,如Agent应用、自动化研究工作流等。
2026年4月23日,就在昨天,OpenAI 推送了 GPT-5.5。距上一版 GPT-5.4 发布,仅过了六周。
这个迭代速度说明了一件事:顶尖 AI 实验室之间的竞争,已经到了按周计算的阶段。
GPT-5.5 内部代号叫“Spud”(土豆),OpenAI 的工程师喜欢给模型取接地气的食物名字。但这颗"土豆",发布当天就在多项关键基准测试上排到了全球第一。
本文基于 OpenAI 官方系统卡、MarkTechPost 技术解析、Artificial Analysis 独立评测数据,带你看清这次更新的真实价值。
很多人看到"5.5"的版本号会觉得:不就是微调?不是的。
OpenAI 官方说法是:“fully retrained base model since GPT-4.5”(自 GPT-4.5 以来完整重新训练的底座模型)。
这意味着 GPT-5.5 不是在 GPT-5.4 基础上微调出来的,而是从底层重新训练。训练目标非常明确——让模型更擅长在最少人工干预的情况下,独立完成多步骤计算机任务。
官方定义的五大核心能力:
- 代码编写与调试
(Writing and debugging code)
- 在线研究
(Researching online)
- 数据分析
(Analyzing data)
- 直接操作软件
(Operating software directly)
- 自主创建文档/表格
(Creating documents and spreadsheets autonomously)
这五项能力有一个共同特征:它们都是多步骤的,都需要模型主动规划、使用工具、检查结果,而不只是回答一个问题。
这就是为什么 OpenAI 把这次更新的重点标注为"Agentic(智能体化)"。
先看最直观的数据。
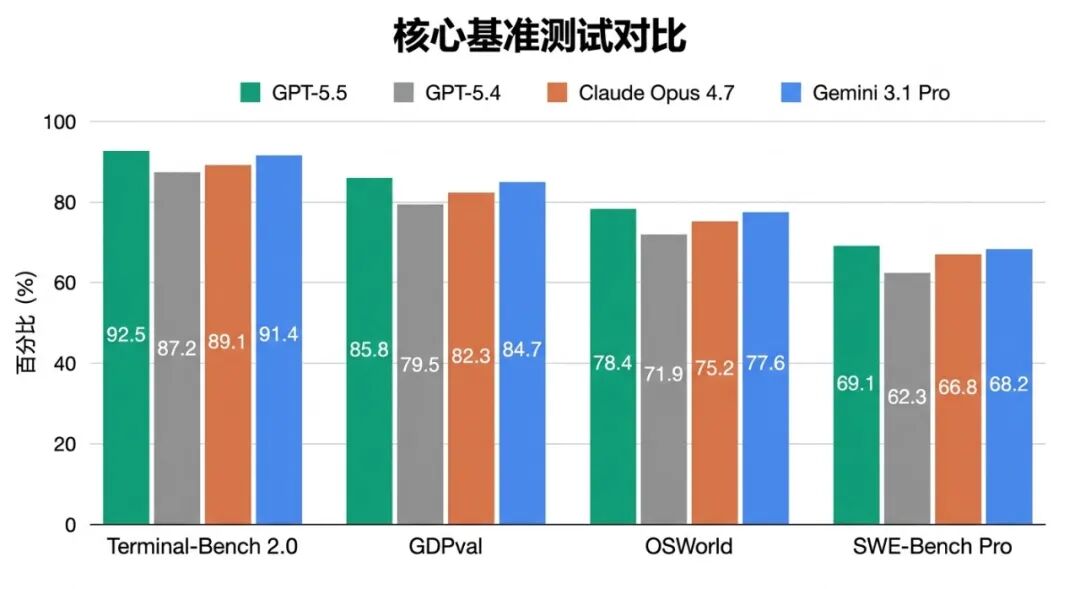 Terminal-Bench 2.0(终端自主任务)
Terminal-Bench 2.0(终端自主任务)
这是评估模型能否独立完成终端操作任务的基准,比如在服务器上自主执行一系列 shell 命令、管理文件、处理错误。
GPT-5.5 得分82.7%,对比:
- Claude Opus 4.7:69.4%(GPT-5.5 高出 13.3 个百分点)
- Gemini 3.1 Pro:68.5%
这是 GPT-5.5 优势最明显的单项测试。
GDPval(跨职业知识工作)
这个基准测试模型在 44 类职业场景中的实际工作表现,类似"让 AI 模拟一个财务分析师/法律顾问/数据科学家能完成多少任务"。
GPT-5.5 得分84.9%,对比:
- Claude Opus 4.7:80.0%
- GPT-5.4:83.0%
相比上一版,GPT-5.5 提升了约 2 个百分点。
OSWorld-Verified(自主电脑操作)
评估模型能否在真实的桌面操作系统环境中自主完成任务,比如打开浏览器、填写表单、操作 Excel。
GPT-5.5 得分78.7%,明显领先 Claude(62.1%)和 Gemini(59.3%)。
SWE-Bench Pro(真实代码修复)——有争议的数据点
这是最受开发者关注的基准之一,评估模型能否端到端修复真实 GitHub 仓库中的 Issue。
GPT-5.5 得分58.6%。Claude Opus 4.7 得分64.3%,看起来 Claude 更强。
但 OpenAI 在系统卡中明确指出:Anthropic 承认其 SWE-Bench 测试子集存在"记忆化(memorization)"迹象,即模型可能记住了测试数据中的部分答案,而不是真正解决问题。这使得 Claude 在这项测试的比较结果存疑。
两家公司各执一词,目前没有统一的独立裁判。建议开发者在自己的代码库上实测,而不是单看这个数字。
如果说基准测试数据还有争议,那么 GPT-5.5 在智能体(Agentic)场景的表现是公认的突破点。
BrowseComp(Web 研究):GPT-5.5 Pro 得分90.1%,Gemini 3.1 Pro 为 85.9%。
Tau2-bench Telecom(领域 Agent 任务):GPT-5.5 无需提示词优化,直接达到98.0%。
FinanceAgent(金融分析 Agent):60.0%,处于主流模型领先水平。
Internal Investment Banking Modeling(内部投行建模):88.5%。
更重要的是 Artificial Analysis 给出的综合智能指数:GPT-5.5(xhigh)在 207 个模型中排名第 1 位,智能指数得分60(中位数模型得分为 14)。

GPT-5.5 标准版价格是 GPT-5.4 的2 倍,但 OpenAI 给出了对应理由:
- Token 消耗更少
:完成同样的 Codex 任务,GPT-5.5 使用的 Token 数明显减少;
- 速度不降
:per-token 延迟与 GPT-5.4 持平;
- 错误更少
:减少中途出错需要重试的情况。
如果这三点确实成立,那么实际成本涨幅可能小于账面上的 2 倍。但这需要具体应用场景的实测来验证。
相比 Claude Opus 4.7(\(15/\)75),GPT-5.5 标准版在价格上仍有优势。
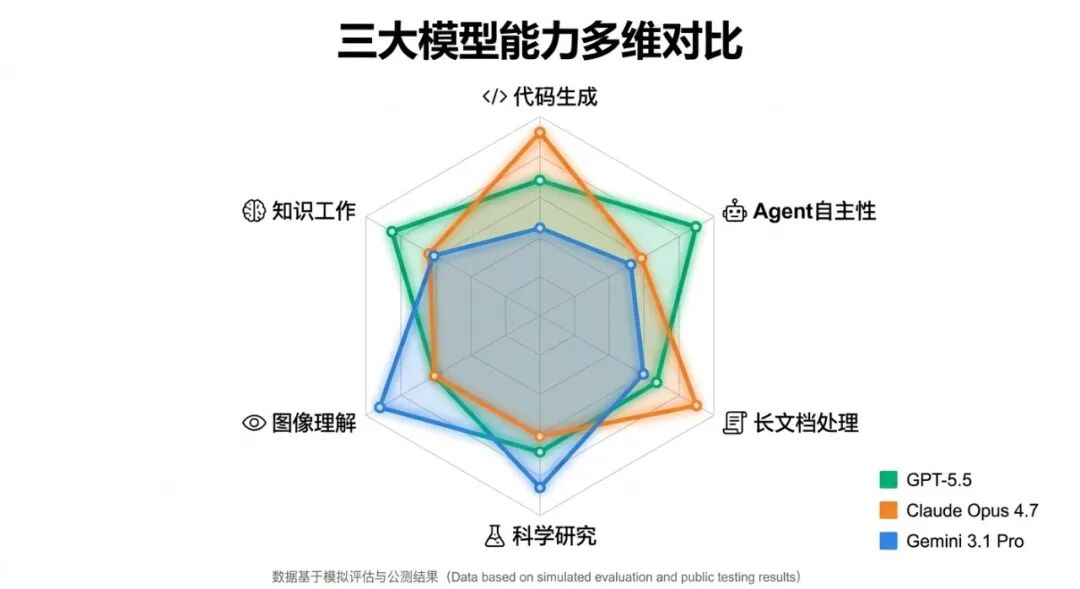 从多维度横向来看:
从多维度横向来看:
- 代码生成
:Claude Opus 4.7 仍是最强(尤其是 SWE-Bench 数据),GPT-5.5 次之
- Agent 自主性
:GPT-5.5 明显领先,这是本次更新的核心卖点
- 长文档处理
:Claude 的 200K 上下文在某些中等长度场景表现均衡
- 科学研究
:GPT-5.5 在 GeneBench(遗传学多阶段分析)和 BixBench(生物信息学)表现突出
- 图像理解
:Gemini 系列多模态能力传统较强,GPT-5.5 在多模态基准中排名第 64⁄112,相对弱项
- 知识工作
:GPT-5.5 在 GDPval 得分最高
没有一个模型全面碾压其他模型,选哪个取决于你的具体场景。
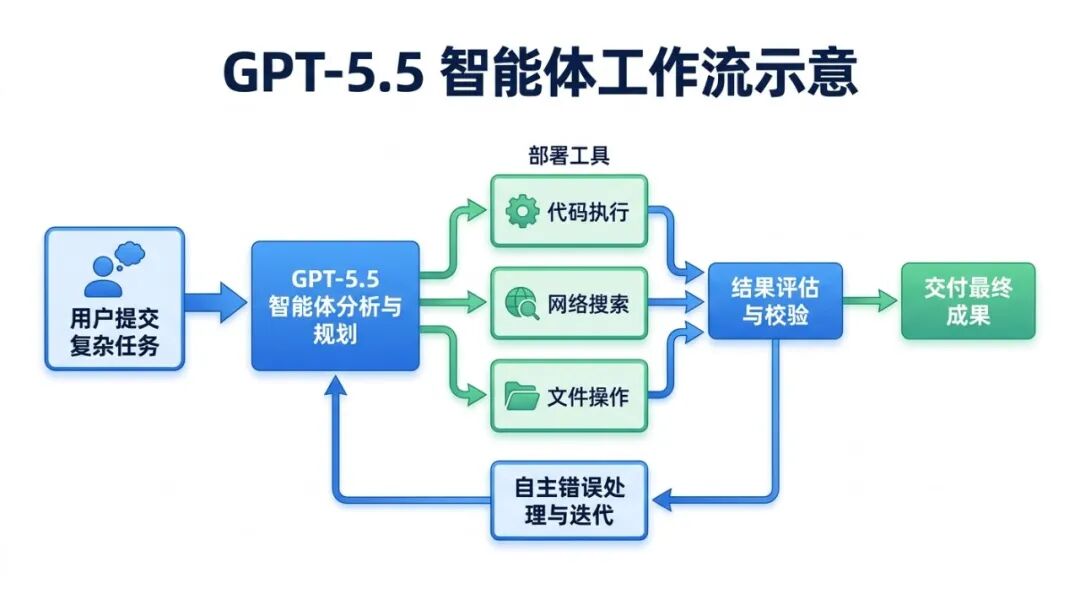 GPT-5.5 支持约1M Token(922K)上下文,与 GPT-5.4 和 Gemini 3.1 Pro 持平。
GPT-5.5 支持约1M Token(922K)上下文,与 GPT-5.4 和 Gemini 3.1 Pro 持平。
Claude Opus 4.7 的 200K 上下文在需要处理整本书或超长代码库时是瓶颈,但 Anthropic 在中等长度场景(16K–64K)的注意力机制更稳定。
值得注意的是:GPT-5.5 在 OpenAI-MRCR-v2 测试中,16K–64K 范围内的表现略低于 GPT-5.4,但在极长上下文(接近 1M)的情况下显著更好。如果你的任务主要是中等长度文档,这个细节值得留意。
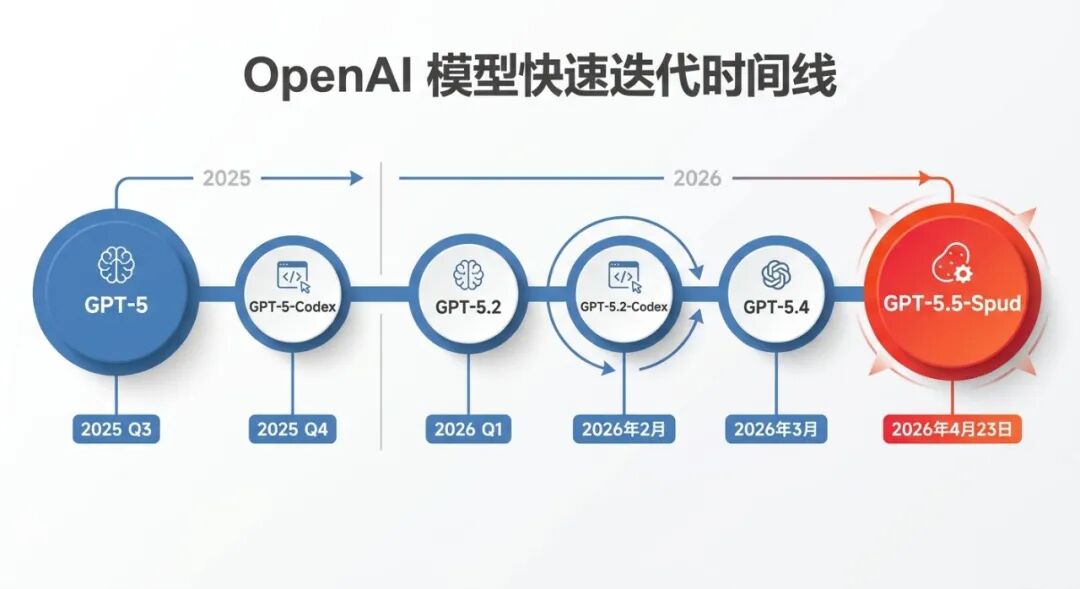 六周出一个大版本,这个速度在 AI 圈已经不稀奇,但放在大模型这个体量上仍然值得关注。
六周出一个大版本,这个速度在 AI 圈已经不稀奇,但放在大模型这个体量上仍然值得关注。
从 GPT-5 到 GPT-5.5,不到一年时间内 OpenAI 完成了 7 次主要版本迭代。其中 GPT-5.4 将独立的 Codex 编程线与通用推理线合并,GPT-5.5 则在此基础上做了完整底座重训。
这个节奏背后是规模空前的研发投入,也是与 Anthropic(Claude 4 系列)和 Google(Gemini 3 系列)正面交锋的必然结果。
 GPT-5.5 发布时,OpenAI 公布了一组数字:
GPT-5.5 发布时,OpenAI 公布了一组数字:
- 每周活跃用户
:9 亿+
- 付费订阅用户
:5000 万+
- B 端付费企业用户
:900 万
- Codex 活跃开发者
:400 万/周
这四个数字说明 OpenAI 的商业化已经远超纯粹的“技术研究”阶段。Codex 400 万活跃开发者周均使用量,意味着 GPT-5.5 在代码场景的改进能影响非常大规模的实际工程工作。
OpenAI 在发布前对 GPT-5.5 进行了内部安全分级,结果是“High”(高),而非最高级别的“Critical”(危急)。
“High”级别意味着:在网络安全场景中,该模型可能会放大现有的危害路径,但不会开创全新的攻击向量。为此,GPT-5.5 经过了专门针对网络安全和生物风险的第三方测试与红队演练。
简单来说:它比普通工具更危险,但还没到需要单独审批才能使用的程度。
根据现有数据,以下场景 GPT-5.5 有明显优势:
适合用 GPT-5.5 的场景:
- 需要模型自主完成多步骤任务(Agent 工作流)
-终端/命令行自动化(Terminal-Bench 第一)
-Web 研究自动化(BrowseComp Pro 90.1%)
-生物信息学/基因组学等科学研究辅助
-金融建模与分析
可能其他模型更合适的场景:
-纯代码生成/修复(Claude 在 SWE-Bench 数字更高,争议另当别论)
-图像分析与多模态任务(Gemini 系列传统优势)
-中等长度文档处理(16K–64K,GPT-5.5 有细微退步)
-预算受限的高频 API 调用(GPT-5.5 价格翻倍,Gemini 3.1 Pro 性价比更高)
GPT-5.5 是一次有实质意义的大版本更新,不是刷 PR 的小步迭代。
最核心的变化是:模型从“回答问题”更进一步向“主动完成工作”演进。Terminal-Bench 第一、GDPval 第一、AI Intelligence Index 第一,这些数据指向同一个方向——更强的自主规划与执行能力。
代价是 API 价格翻倍,以及在多模态和中等上下文场景存在弱点。
如果你在构建 Agent 应用、自动化研究工作流、或者需要模型独立操作电脑完成任务,GPT-5.5 目前是最值得优先评估的选项。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。

阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇






配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/281276.html