
大模型(LLM)虽强大,但存在无记忆、无外部能力、易幻觉三大缺陷,无法直接落地企业级应用。LangChain 是大模型应用开发的标准框架,通过模块化设计补齐 LLM 短板,让开发者快速搭建聊天机器人、私有知识库、自主智能体等 AI 应用。
相比于LangChain的使用,我认为更重要的是理解Agent和RAG的工作机制,LangChain的各个模块间分别起到了什么作用。
LangChain 是基于大语言模型构建 AI 应用的开发框架,核心价值是模块化、流程化、标准化大模型应用开发,屏蔽底层差异,让开发者专注业务逻辑。
- 统一对接各类大模型(GPT、通义千问、文心一言等)
- 给 AI 添加上下文记忆,实现多轮对话
- 接入外部工具(搜索、计算、数据库)
- 搭建私有知识库,解决大模型幻觉
- 实现自主决策智能体,完成复杂任务
LangChain 采用模块化设计,6 大核心组件可自由组合,适配不同业务场景。
1.1 核心作用
LangChain 与大模型的交互入口,负责提示词管理、模型调用、输出解析,统一屏蔽不同 LLM 的 API 差异。
1.2 核心组件
PromptTemplate:提示词模板,动态传参,标准化指令ChatModels:对接各类对话大模型OutputParser:输出解析器,将自由文本转为 JSON / 列表等结构化数据
1.3 实战代码
from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.output_parsers import StrOutputParser import os # 配置大模型 os.environ["OPENAI_API_KEY"] = "你的API_KEY" llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) # 1. 定义提示词模板 prompt = ChatPromptTemplate.from_messages([ ("system", "你是专业的Java后端开发助手,回答简洁专业"), ("user", "{question}") ]) # 2. 定义输出解析器 parser = StrOutputParser() # 3. 组装链路:提示词 → 模型 → 解析器 chain = prompt | llm | parser # 调用 result = chain.invoke({"question": "Java后端有哪些常用锁?"}) print(result)
1.4 适用场景
所有 LangChain 应用的基础入口,所有模块都依赖 Model IO 对接大模型。
2.1 核心作用
将 Prompt + LLM + 组件 串成固定流程流水线,是 LangChain 最基础的执行单元,适合硬编码、固定顺序的任务。
2.2 核心特点
- 流程固定,执行稳定
- 开发简单,开箱即用
- 与 Agent 的区别:Chain 无自主决策,Agent 可动态规划
2.3 常用 Chain 类型
LLMChain:基础单步调用ConversationChain:带记忆的对话链SimpleSequentialChain:多步骤顺序执行
2.4 实战代码(顺序链)
from langchain.chains import LLMChain, SimpleSequentialChain # 步骤1:总结技术文章 prompt1 = ChatPromptTemplate.from_template("总结这段技术文章:{text}") chain1 = LLMChain(llm=llm, prompt=prompt1) # 步骤2:将总结转为面试题 prompt2 = ChatPromptTemplate.from_template("根据这段总结生成1道面试题:{summary}") chain2 = LLMChain(llm=llm, prompt=prompt2) # 组装顺序链(自动传递上一步结果) total_chain = SimpleSequentialChain( chains=[chain1, chain2], verbose=True # 打印执行流程 ) # 执行 total_chain.invoke("Redis分布式锁的实现原理是SETNX+过期时间,Redisson实现可重入和锁续约")
2.5 适用场景
固定步骤的简单任务:文本总结、翻译、格式转换、单轮问答。
3.1 核心作用
大模型本身无记忆,Memory 负责存储对话历史,将历史拼入 Prompt,实现多轮上下文对话。
3.2 核心工作流程
读历史 → 拼 Prompt → 写新历史
3.3 常用记忆类型(企业级选型)
表格
3.4 实战代码(生产级摘要记忆)
from langchain.memory import ConversationSummaryBufferMemory from langchain.chains import ConversationChain # 初始化摘要记忆(最大Token限制) memory = ConversationSummaryBufferMemory( llm=llm, max_token_limit=1000 # 超过则自动生成摘要 ) # 创建带记忆的对话链 conversation = ConversationChain( llm=llm, memory=memory, verbose=True ) # 多轮对话测试 conversation.invoke("我是Java后端开发,正在学LangChain") conversation.invoke("我适合做什么AI应用?") # 能记住上一轮信息
3.5 适用场景
所有多轮对话应用:智能客服、聊天助手、交互式 AI 工具。
4.1 核心作用
给大模型扩展外部能力,打破 LLM 知识边界,让 AI 能联网、计算、查数据库、调用业务接口。
4.2 核心分类
- 内置工具:搜索(Tavily)、计算器(PythonREPL)、代码执行
- 自定义工具:封装业务接口、数据库操作、内部系统
4.3 实战代码(自定义业务工具)
from langchain.tools import Tool # 自定义工具:Java后端技术推荐 def java_tech_recommend(level: str) -> str: """根据开发水平推荐Java后端技术栈""" if level == "初级": return "SpringBoot、MyBatis、MySQL、Redis基础" elif level == "中级": return "SpringCloud、Redis分布式、MQ、分库分表" elif level == "高级": return "微服务架构、ServiceMesh、云原生、可观测性" else: return "请输入正确的开发级别" # 创建工具对象 java_tool = Tool( name="JavaTechRecommend", func=java_tech_recommend, description="用于根据Java开发级别推荐技术栈,参数为初级/中级/高级" ) # 工具列表 tools = [java_tool]
4.4 适用场景
需要外部能力的 AI 应用:联网问答、数据计算、业务系统对接。
5.1 核心概念与定位
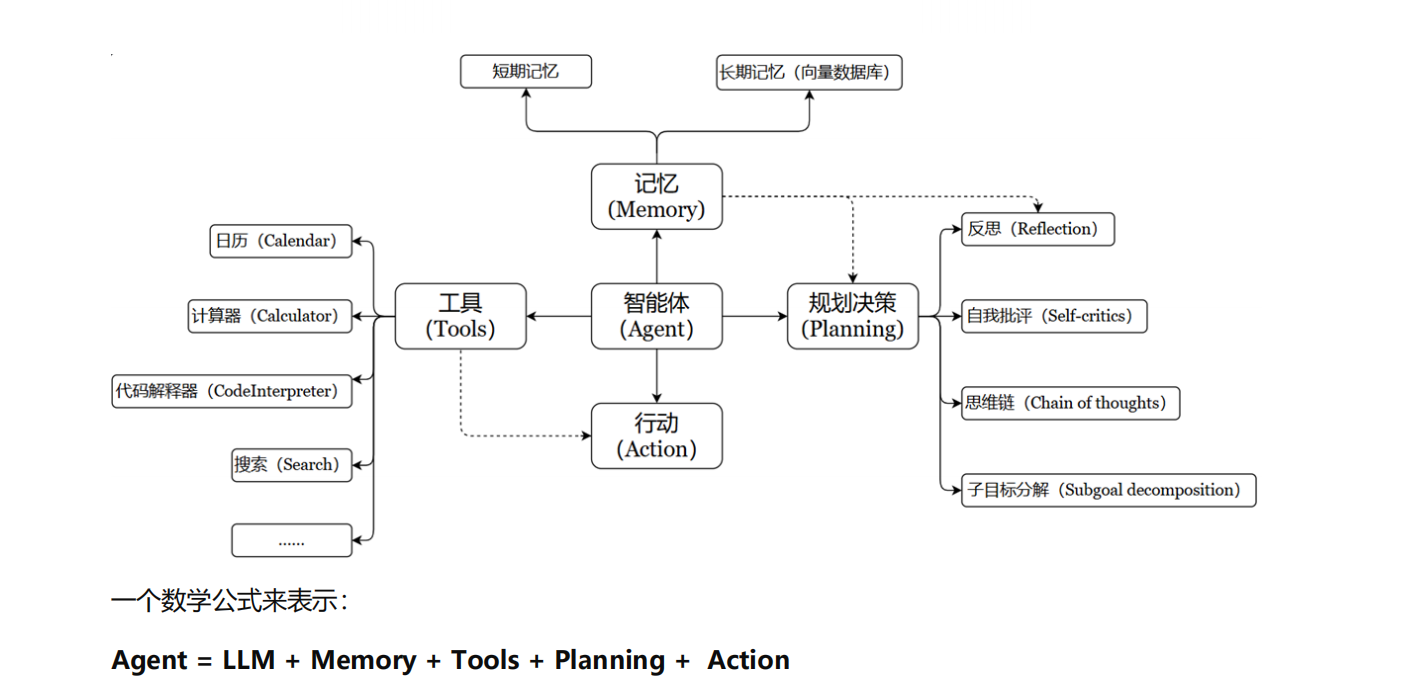
Agent(智能体)是 LangChain 的高阶核心模块,是以大语言模型 LLM 作为决策大脑,能够自主理解任务、拆解目标、选择工具、规划执行步骤、自主推进并完成复杂任务的系统。
与固定流程的 Chain 不同,Agent 没有写死的执行步骤,而是像人一样思考、决策、行动,处理开放、复杂、无固定规则的任务。
5.2 AI 能力等级类比(自动驾驶分级)
表格
5.3 Agent 与 Chain 核心区别
表格
5.4 Agent 核心组成(六要素)
- LLM 大脑:推理、决策、规划、判断
- Memory 记忆:短期上下文记忆 + 长期向量记忆
- Tools 工具:搜索、计算、代码、数据库、API
- Planning 规划:拆解任务、反思纠错、多步推进
- Action 执行:调用工具、获取结果、处理信息
- Collaboration 协作:多智能体协同完成复杂任务
5.5 Agent 两大核心工作模式
5.5.1 ReAct 模式(最通用)
全称:Reasoning + Acting原理:先思考推理,再行动调用工具,用自然语言描述思考过程。
- 优点:通用性强、所有模型都支持、可解释性好
- 缺点:速度稍慢、依赖格式解析
典型类型:
- ZERO_SHOT_REACT_DESCRIPTION(零样本推理)
- CONVERSATIONAL_REACT_DESCRIPTION(对话记忆版)
- STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION
5.5.2 Tool Calling 模式(高效)
原理:LLM 直接输出结构化 JSON,指定调用哪个工具、传什么参数。
- 优点:速度快、格式稳定、不易出错
- 缺点:需要模型原生支持工具调用能力
典型类型:
- OPENAI_TOOLS
- OPENAI_MULTI_TOOLS
表格
5.6 Agent 关键组件详解
5.6.1 Tool(工具)
工具是 Agent 与外部世界交互的接口:
- 联网搜索:TavilySearch、DuckDuckGo
- 数学计算:Calculator、PythonREPL
- 代码执行:Python、Shell
- 自定义能力:API、数据库、文件操作、企业内部系统接口
必备三要素:
name:工具名称func:具体执行函数description:功能描述(Agent 依靠描述自主选择工具)
5.6.2 Memory(记忆)
- ConversationBufferMemory(原始完整记忆)
- ConversationSummaryMemory(摘要压缩记忆)
- ConversationBufferWindowMemory(滑动窗口记忆)
- VectorStoreRetrieverMemory(长期向量持久记忆)
5.6.3 AgentExecutor(执行器)
- 运行 Agent 实例
- 调度工具流转
- 维护思考 - 行动 - 观察循环
- 错误捕获、格式容错
- 控制最大迭代次数,防止死循环
5.7 Agent 创建方式
5.7.1 传统快速方式(initialize_agent)
agent_executor = initialize_agent( tools=tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True, memory=memory, handle_parsing_errors=True )
5.7.2 通用灵活方式
prompt = hub.pull("hwchase17/react")//直接拉取提示词 agent = create_react_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
5.8 执行完整流程
- Thought:自主判断需要做什么、是否调用工具
- Action:选定工具并传入参数
- Observation:接收工具返回结果
- 循环多轮 → 信息足够
- Final Answer:输出最终答案
5.9 关键参数详解
verbose=True:打印完整思考链,调试必开handle_parsing_errors=True:解析失败自动修复,生产必备max_iterations=3:限制循环次数,避免死循环return_intermediate_steps=True:返回中间思考过程
5.10 带记忆的多轮对话 Agent(完整代码)
from langchain_openai import ChatOpenAI from langchain.agents import initialize_agent, AgentType from langchain_community.tools.tavily_search import TavilySearchResults from langchain.memory import ConversationBufferMemory import os # 配置密钥 os.environ["TAVILY_API_KEY"] = "你的密钥" os.environ["OPENAI_API_KEY"] = "你的密钥" # 1. 工具 search = TavilySearchResults(max_results=2) tools = [search] # 2. 记忆 memory = ConversationBufferMemory( memory_key="chat_history", return_messages=True ) # 3. 大模型 llm = ChatOpenAI(model="gpt-4o-mini", temperature=0) # 4. 创建Agent agent_executor = initialize_agent( tools=tools, llm=llm, agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, memory=memory, verbose=True, handle_parsing_errors=True ) # 5. 多轮对话 agent_executor.invoke("2026年人工智能发展趋势") agent_executor.invoke("有哪些对应的大模型") agent_executor.invoke("这些模型如何用于后端开发")
5.11 典型应用场景
- 智能问答(联网搜索 + 多步推理)
- 自动化信息收集、总结、分析
- 代码自动编写、调试、运行
- 股票 / 行业数据分析(搜索 + 计算)
- 智能客服、任务机器人、决策助手
- 复杂业务流程自动化
5.12 优势与价值
- 无需硬编码流程,自适应多变任务
- 可独立完成人类才能处理的复杂任务
- 降低开发成本,提升系统智能上限
- 可扩展、可记忆、可反思、可协作
6.1、RAG 到底是什么?
RAG = Retrieval-Augmented Generation检索增强生成。
大白话:先去私有知识库检索相关内容 → 把内容塞给大模型 → 让大模型只根据检索到的内容回答。
作用:
- 解决大模型幻觉(胡编乱造)
- 接入私有数据(PDF、Excel、Word、知识库)
- 保证答案真实、可追溯、可更新
6.2、RAG 标准六步流程(必背)
1. Source 数据源
支持:PDF、Word、CSV、JSON、TXT、HTML、Markdown、数据库、网页
2. Load 文档加载
用 DocumentLoader 把文件转成 LangChain 统一的 Document 对象。
常见加载器:
- TextLoader:txt
- PyPDFLoader:PDF
- CSVLoader:表格
- JSONLoader:JSON
- UnstructuredXXXLoader:Word/HTML/Markdown
3. Transform 文本切分(最关键)
长文本切成小块(chunk),才能向量化。
常用切分器:
- RecursiveCharacterTextSplitter(最常用、最通用)
- CharacterTextSplitter(按字符切)
- TokenTextSplitter(按 Token 切)
- MarkdownTextSplitter / HTMLHeaderTextSplitter(结构化文档)
- SemanticChunker(语义切分,效果最好)
4. Embed 文本转向量
把文本块变成 向量(embedding)。
常用嵌入模型:
- text-embedding-ada-002(OpenAI)
- text-embedding-3-large
- 开源:BGE、m3e、bge-m3
5. Store 向量存储
把向量存入 向量数据库。
常用向量库:
- FAISS(本地内存,简单)
- Chroma(轻量持久化)
- Milvus、Pinecone、Redis、ES
6. Retrieve 检索召回
用户提问 → 转向量 → 在向量库找最相似的文本块 → 塞给模型回答。
6.3、RAG 核心组件超详细讲解
1. DocumentLoader(文档加载器)
作用:把任何文件 → 统一的 Document 对象。
Document 只有两个东西:
- page_content:文本内容
- metadata:来源、页码、行数等
示例(加载 PDF):
loader = PyPDFLoader("xxx.pdf") documents = loader.load()
2. Text Splitter(文本切分器)
为什么要切分?
- 模型有 Token 限制
- 太长检索不精准
最常用:RecursiveCharacterTextSplitter
按 段落 → 换行 → 空格 → 字符 递归切分,尽可能保持语义完整。
text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, # 每块最大长度 chunk_overlap=50, # 重叠字符,避免切断语义 separators=[" ", " ", "。", "!", "?", ""] ) texts = text_splitter.split_documents(documents)
3. Embedding Model(向量模型)
把文本变成高维向量。
相似文本 → 向量距离近。
embedding = OpenAIEmbeddings(model="text-embedding-3-large")
4. Vector Store(向量数据库)
存储向量 + 快速相似度检索。
FAISS(最简单)
db = FAISS.from_documents(texts, embedding)
Chroma(持久化)
db = Chroma.from_documents( texts, embedding, persist_directory="./chroma_db" )
5. Retriever(检索器)
从向量库获取相关文本块。
retriever = db.as_retriever( search_kwargs={"k": 3} # 返回最相似3条 )
检索方式
- similarity_search:普通相似度
- similarity_score_threshold:分数阈值过滤
- max_marginal_relevance_search(MMR):平衡相似度 + 多样性
6.4、RAG 完整实战代码
# 1. 加载文档 loader = PyPDFLoader("mybook.pdf") documents = loader.load() # 2. 切分 splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=50 ) chunks = splitter.split_documents(documents) # 3. 向量模型 embedding = OpenAIEmbeddings() # 4. 存入向量库 db = FAISS.from_documents(chunks, embedding) # 5. 获取检索器 retriever = db.as_retriever(search_kwargs={"k=3"}) # 6. 构建RAG问答链 qa = RetrievalQA.from_chain_type( llm=ChatOpenAI(model="gpt-4o-mini"), chain_type="stuff", retriever=retriever, return_source_documents=True ) # 7. 提问 result = qa.invoke("分布式锁怎么实现?") print(result["result"])
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/280372.html