
大家好,我是Cthy!本篇带来Python+Pandas+Psycopg2实战案例,手把手教你把学校 7 类业务 CSV 数据(教师 / 学生 / 考勤 / 成绩 / 消费)批量清洗、导入 PostgreSQL 数据库,完成数据从文件到数据库的完整持久化过程。全文侧重实操步骤、数据清洗细节、异常处理、踩坑总结,小白也能直接跑通!
在校园数据管理场景中,教师信息、学生档案、考勤记录、考试成绩、消费流水等核心数据,大多以CSV 文件形式分散存储。这种方式无法做关联查询、无法做数据分析、数据易丢失、管理成本极高。
因此,将 CSV 数据持久化到关系型数据库是数据治理的第一步。本文基于 Python 实现全自动、高兼容、可定位异常的 CSV 批量入库方案,解决实战中编码乱码、脏数据、字段不匹配、批量插入报错等核心问题,最终实现 7 类数据一键导入 PostgreSQL。
- 项目需求与数据说明
- 技术栈选型
- 环境准备(数据库 + Python 依赖)
- 核心开发思路(全程拆解)
- 代码分步实现(逐模块讲解)
- 关键数据清洗过程(重点!)
- 项目运行与效果展示
- 实战踩坑总结(必看)
- 项目优化方向
- 全文总结
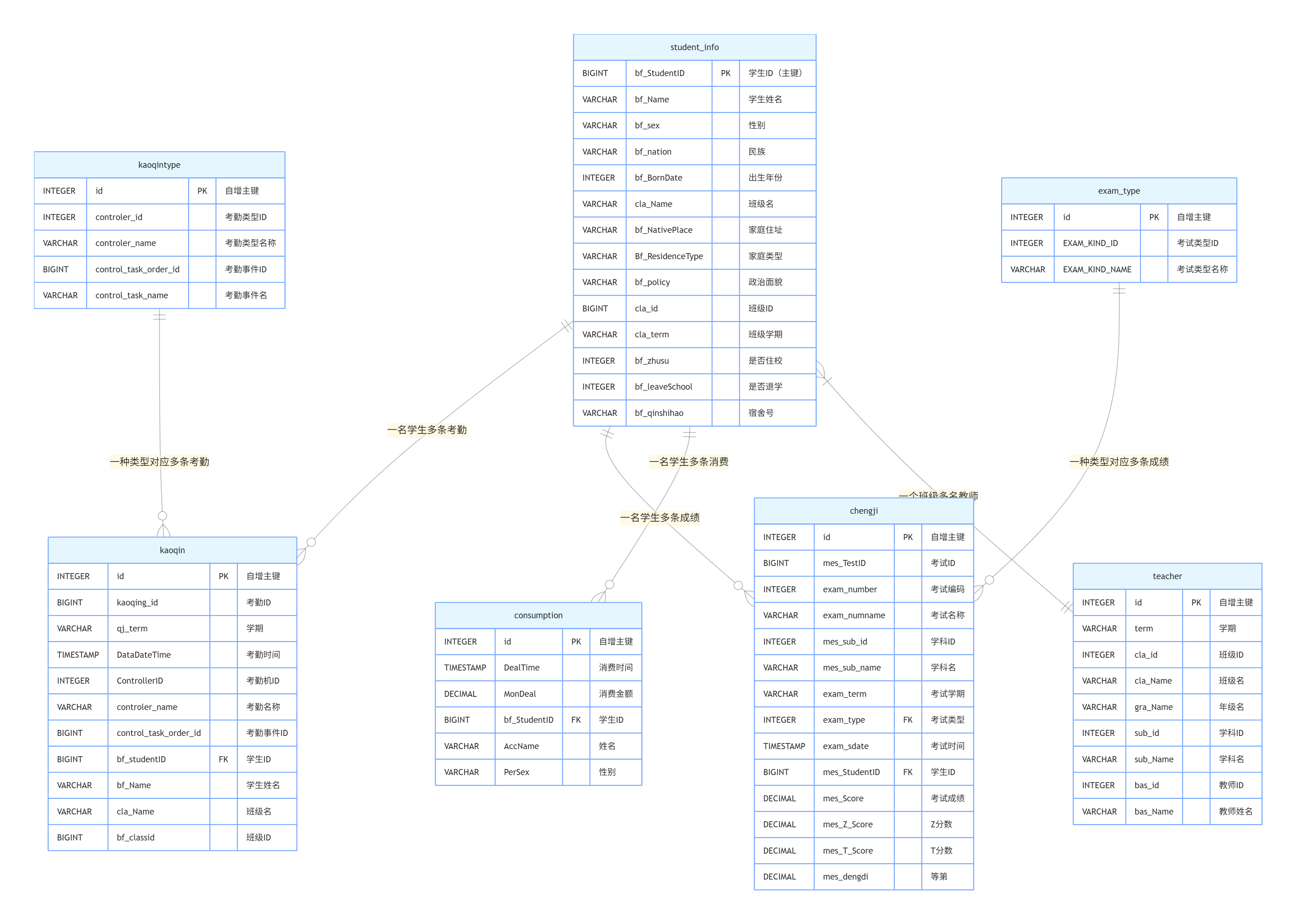
1.1 业务数据说明
本次需要导入7 类学校核心业务 CSV 数据,数据字段严格对应业务逻辑:
1.2 核心需求
- 将 CSV 数据批量、稳定导入 PostgreSQL,实现数据持久化
- 自动处理中文编码、空值、异常值、格式错误
- 批量插入提升效率,报错时精准定位问题数据
- 表结构标准化,支持后续关联查询
本次项目用到的技术栈非常轻量化,适合数据处理场景:
- Python 3.x:开发语言
- Pandas:CSV 读取、数据清洗、类型转换
- Psycopg2:PostgreSQL 数据库连接、建表、数据插入
- Psycopg2.extras:批量插入优化,大幅提升入库速度
- OS/Datetime:文件路径管理、导入耗时统计
3.1 安装 Python 依赖库
打开终端执行以下命令,安装所需库:
pip install pandas psycopg2-binary
3.2 PostgreSQL 数据库准备
- 安装 PostgreSQL 12 及以上版本
- 创建数据库:
school_data - 记录连接信息:主机、端口、用户名、密码
3.3 数据文件准备
在项目根目录创建data文件夹,将 7 个 CSV 文件放入其中,目录结构如下:
文件链接在这里获取
数据集链接: https://pan.baidu.com/s/13kFfJU_4fL8PvW-VtDQ8rA 提取码: gea8
项目根目录/ ├── data/ │ ├── 1_teacher.csv │ ├── 2_student_info.csv │ ├── 3_kaoqin.csv │ ├── 4_kaoqintype.csv │ ├── 5_chengji.csv │ ├── 6_exam_type.csv │ └── 7_consumption.csv └── main.py # 主程序文件
整个数据持久化过程分为6 个核心步骤,环环相扣:
- 数据库连接管理:测试连接→建立连接→关闭连接,保证连接安全
- 表结构初始化:删除旧表→创建新表,保证表结构干净规范
- CSV 文件读取:兼容多编码,解决中文乱码问题
- 数据清洗:类型转换、空值处理、异常值替换、时间格式化
- 数据插入:批量插入 + 异常单条定位,兼顾速度与稳定性
- 全量导入:按顺序执行 7 张表导入,完成整体持久化
5.1 模块导入与类初始化
首先导入所需库,创建DataImporter数据导入类,初始化数据库配置与数据路径。
import pandas as pd import psycopg2 from psycopg2 import extras import os from datetime import datetime class DataImporter: """数据导入器:将CSV数据批量导入PostgreSQL""" def __init__(self, dbname, user, password, host='localhost', port='5432'): # 数据库连接配置 self.dbname = dbname self.user = user self.password = password self.host = host self.port = port self.conn = None # 数据库连接对象 # 数据文件目录:指向项目data文件夹 self.data_dir = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'data')
5.2 数据库连接管理模块
连接是数据入库的基础,本模块实现连接测试、建立连接、断开连接三个核心功能。
# 1. 测试数据库连接(前置校验) def test_connection(self): print("正在测试数据库连接...") try: conn = psycopg2.connect( dbname=self.dbname, user=self.user, password=self.password, host=self.host, port=self.port ) print("✅ 数据库连接成功!") # 校验PostgreSQL版本 cursor = conn.cursor() cursor.execute("SELECT version();") db_version = cursor.fetchone()[0] print(f"✅ PostgreSQL版本:{db_version[:50]}...") cursor.close() conn.close() return True except Exception as e: print(f"❌ 连接失败!错误信息:{e}") return False # 2. 建立数据库连接 def connect(self): self.conn = psycopg2.connect( dbname=self.dbname, user=self.user, password=self.password, host=self.host, port=self.port ) print("✅ 数据库连接成功") # 3. 关闭数据库连接(释放资源) def disconnect(self): if self.conn: self.conn.close() print("✅ 数据库连接已关闭")
5.3 表结构操作模块
每次导入前删除旧表、创建新表,避免主键冲突、结构不匹配问题。
# 1. 删除已存在的表 def drop_table_if_exists(self, table_name): cursor = self.conn.cursor() cursor.execute(f"DROP TABLE IF EXISTS {table_name} CASCADE") self.conn.commit() print(f" - 表 {table_name} 已删除(如果存在)") cursor.close() # 2. 创建新表(按业务字段定义结构) def create_table(self, table_name, columns): cursor = self.conn.cursor() column_defs = [f"{col_name} {col_type}" for col_name, col_type in columns.items()] create_sql = f"CREATE TABLE IF NOT EXISTS {table_name} ({', '.join(column_defs)})" cursor.execute(create_sql) self.conn.commit() print(f"✅ 表 {table_name} 创建成功") cursor.close()
5.4 批量数据插入模块(核心!)
采用批量插入提升速度,批量失败后单条重试定位错误,解决实战中批量插入无法排查问题的痛点。
def insert_data(self, table_name, df, columns): cursor = self.conn.cursor() # 构造插入SQL语句 placeholders = ', '.join(['%s'] * len(columns)) column_names = ', '.join(columns) insert_sql = f"INSERT INTO {table_name} ({column_names}) VALUES ({placeholders})" # 数据处理:将Pandas空值转为数据库NULL data_tuples = [] for idx, row in df[columns].iterrows(): tuple_row = [None if pd.isna(val) else val for val in row] data_tuples.append(tuple(tuple_row)) try: # 批量插入:每页1000条,效率远超单条插入 extras.execute_batch(cursor, insert_sql, data_tuples, page_size=1000) self.conn.commit() print(f"✅ 表 {table_name} 插入 {len(data_tuples)} 条记录") except Exception as e: # 批量失败:回滚事务,逐行插入找错误数据 self.conn.rollback() print(f" ❌ 批量插入失败,开始定位问题记录...") print(f"错误信息:{e} ") for i, data_tuple in enumerate(data_tuples): try: cursor.execute(insert_sql, data_tuple) except Exception as ex: print(f"❌ 找到问题记录!索引:{i}") print(f"错误信息:{ex}") raise cursor.close()
5.5 单表数据导入模块
以消费表为例(其他表逻辑一致),实现读文件→洗数据→插数据完整流程。
# 7. 学生消费数据导入(修复完整版) def import_consumption(self): print(" [7/7] 正在导入消费数据...") table_name = 'consumption' # 1. 删除旧表 self.drop_table_if_exists(table_name) # 2. 定义表结构 columns = { 'id': 'SERIAL PRIMARY KEY', 'DealTime': 'TIMESTAMP', # 消费时间 'MonDeal': 'DECIMAL(10,2)', # 消费金额 'bf_StudentID': 'BIGINT', # 学生ID(关联学生表) 'AccName': 'VARCHAR(50)', # 学生姓名 'PerSex': 'VARCHAR(10)' # 性别 } # 3. 创建新表 self.create_table(table_name, columns) csv_path = os.path.join(self.data_dir, '7_consumption.csv') # 4. 兼容多编码读取CSV df = None for encoding in ['utf-8', 'gbk', 'gb2312', 'latin1']: try: df = pd.read_csv(csv_path, encoding=encoding) print(f" - 使用 {encoding} 编码成功读取") break except: continue if df is None: raise ValueError("❌ 无法读取消费数据文件,请检查文件格式") # 5. 数据清洗(下文详细讲解) df['DealTime'] = pd.to_datetime(df['DealTime'], format='%Y/%m/%d %H:%M:%S', errors='coerce') df['MonDeal'] = pd.to_numeric(df['MonDeal'], errors='coerce') df['bf_StudentID'] = pd.to_numeric(df['bf_StudentID'], errors='coerce').astype('Int64') # 6. 插入数据 data_columns = ['DealTime', 'MonDeal', 'bf_StudentID', 'AccName', 'PerSex'] self.insert_data(table_name, df, data_columns)
5.6 全量导入与主函数
按固定顺序执行 7 张表导入,保证业务关联逻辑完整,最后统一关闭连接。
# 全量导入所有数据 def import_all(self): print(" " + "="*60) print("开始导入所有数据到PostgreSQL") print("="*60) start_time = datetime.now() try: self.connect() # 按顺序导入7张表 self.import_teacher() self.import_student_info() self.import_kaoqin() self.import_kaoqintype() self.import_chengji() self.import_exam_type() self.import_consumption() # 统计耗时 end_time = datetime.now() duration = (end_time - start_time).total_seconds() print(f" ✅ 所有数据导入完成!耗时:{duration:.2f} 秒") except Exception as e: print(f" ❌ 导入失败:{e}") raise finally: self.disconnect() # 主程序入口 def main(): print("="*60) print("PostgreSQL 数据导入工具") print("="*60) # 数据库配置(修改为自己的信息) DB_CONFIG = { 'dbname': 'school_data', 'user': 'postgres', 'password': '你的数据库密码', 'host': 'localhost', 'port': '5432' } importer = DataImporter(DB_CONFIG) # 前置连接测试 if not importer.test_connection(): print(" 请先解决连接问题再运行!") return # 用户确认导入 if input(" 是否继续导入数据?(y/n):").lower() == 'y': importer.import_all() else: print("已取消导入") if __name__ == '__main__': main()
CSV 数据普遍存在脏数据、格式错误、空值,必须清洗后才能入库,以下是核心清洗逻辑:
6.1 中文编码兼容
CSV 文件编码不统一(utf-8/gbk/gb2312),自动尝试 4 种编码,保证读取成功:
for encoding in ['utf-8', 'gbk', 'gb2312', 'latin1']: try: df = pd.read_csv(csv_path, encoding=encoding) break except: continue
6.2 时间格式标准化
时间字符串统一转为TIMESTAMP类型,错误时间设为NULL:
df['DealTime'] = pd.to_datetime(df['DealTime'], format='%Y/%m/%d %H:%M:%S', errors='coerce')
6.3 数值类型安全转换
ID、金额、成绩等数值字段,强制转换并处理异常值:
# 学生ID转为整数,空值/异常值设为NULL df['bf_StudentID'] = pd.to_numeric(df['bf_StudentID'], errors='coerce').astype('Int64') # 消费金额转为小数 df['MonDeal'] = pd.to_numeric(df['MonDeal'], errors='coerce')
6.4 业务异常值处理
成绩中-1(作弊)/-2(缺考)/-3(免考)统一转为NULL,符合数据库规范:
df['mes_Score'] = df['mes_Score'].replace([-1, -2, -3], None)
6.5 空值统一处理
Pandas 空值NaN转为数据库NULL,保证存储规范:
tuple_row = [None if pd.isna(val) else val for val in row]
7.1 运行步骤
- 修改代码中数据库密码为自己的配置
- 确认 CSV 文件路径正确
- 运行
main.py
7.2 运行效果
============================================================ PostgreSQL 数据导入工具 ============================================================ 正在测试数据库连接... ✅ 数据库连接成功! ✅ PostgreSQL版本:PostgreSQL 14.5 ... 是否继续导入数据?(y/n):y ============================================================ 开始导入所有数据到PostgreSQL ============================================================ [1/7] 正在导入教师数据... - 表 teacher 已删除(如果存在) ✅ 表 teacher 创建成功 ✅ 表 teacher 插入 1256 条记录 [2/7] 正在导入学生信息数据... - 表 student_info 已删除(如果存在) ✅ 表 student_info 创建成功 - 读取数据:2869 行 ✅ 表 student_info 插入 2869 条记录 ... [7/7] 正在导入消费数据... - 表 consumption 已删除(如果存在) ✅ 表 consumption 创建成功 - 使用 utf-8 编码成功读取 ✅ 表 consumption 插入 8923 条记录 ✅ 所有数据导入完成!耗时:12.35 秒 ✅ 数据库连接已关闭
- 中文编码报错原因:CSV 编码不统一;解决:自动尝试多编码
- 字段名不匹配原因:CSV 列名大小写 / 拼写错误;解决:严格对照数据说明统一字段名
- 批量插入报错无法定位原因:批量插入失败无提示;解决:批量失败后逐行插入定位
- 空值插入报错原因:Pandas 空值无法直接入库;解决:转为
None - 时间格式错误原因:时间字符串格式不统一;解决:指定格式解析,错误值设为
NULL
- 增量导入:生产环境禁用
drop_table,改为根据主键增量更新 - 日志系统:替换 print 为 logging,记录导入日志
- 配置文件:将数据库配置写入 yaml/ini 文件,便于修改
- 数据校验:增加主键唯一性、字段长度校验
- 并行导入:大文件使用多线程提升速度
本文完整实现了学校 7 类 CSV 数据到 PostgreSQL 的持久化全流程,从环境准备→代码开发→数据清洗→批量入库→异常处理一步步拆解,兼顾实操性、稳定性、兼容性。
核心价值:
- 解决了 CSV 数据入库的所有实战痛点
- 代码模块化,易于扩展和维护
- 批量插入效率高,支持百万级数据
- 异常可定位,小白也能快速排查问题
这套方案可直接复用在企业、政务、校园等所有 CSV 批量入库场景,是数据持久化的经典实战案例!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/279957.html