
OMC - 01 用 19 个 Agent 打造你的 Claude Code“工程团队”:oh-my-claudecode 深度解析与实战指南
OMC - 02 五分钟起步,走向多智能体协作:深入解析 oh-my-claudecode 快速开始与架构设计
OMC - 03 从 0 到高效:Oh My ClaudeCode 安装与实践全指南
大模型写代码这件事,从一开始的“帮我补全一段函数”,已经演变成“帮我从 0 到 1 做一个完整的小系统”。但只靠一次次自然语言对话,很快会遇到几个现实问题:
- 想法不清晰,模型和人互相误解;
- 任务拆分随意,做着做着就迷路;
- 多轮修改之后没人知道“到底算不算完成”;
- 项目一换,上下文、约定、经验全部丢失。
Oh-My-ClaudeCode(下文简称 OMC)试图用一套“会话内技能系统”解决这些问题:把常见工作流抽象成 30 个可复用技能,在对话中随时调用,让 AI 不再只是“一次性回答器”,而是可以被编排、被约束、可验证的长期协作伙伴。
这篇文章面向日常在终端、IDE、中重度使用 AI 编程助手的开发者和技术爱好者,系统梳理 OMC 的会话技能体系:它解决什么问题,30 个技能如何分层协作,典型工作流怎么落地,以及如何在自己团队中长期用好这套体系。
在 OMC 里,“技能”(Skill)是对某类复杂工作流的统一封装:每个技能对应一个独立目录,里面有一份带 YAML frontmatter 的 SKILL.md 描述该技能的元数据、触发方式和执行步骤。
/oh-my-claudecode:<skill-name> [arguments] OMC 会通过“技能桥接脚本”自动扫描 skills/ 目录,无需额外注册即可加载新技能;调用时 Claude 会进入对应工作流,按定义的步骤迭代执行,直至完成或被取消。
技能有三种常见触发方式:
- 显式斜杠命令,例如:
/oh-my-claudecode:ralph fix the null check in auth.ts - 自然语言触发词,例如对话里说:
autopilot build me a REST API
效果等价于显式调用 autopilot 技能。
- 自动关键词检测:在对话中输入特定短语,会触发对应技能(下文会列出关键词表)。
这种设计有几个直接好处:
- 行为可预期:每个技能的输入、阶段、成功标准清晰,避免“随机发挥”;
- 可组合:技能之间可以通过
pipeline或next-skill形成流水线; - 可扩展:你可以把自己摸索出的好用工作流,沉淀成新技能,在团队内共享。
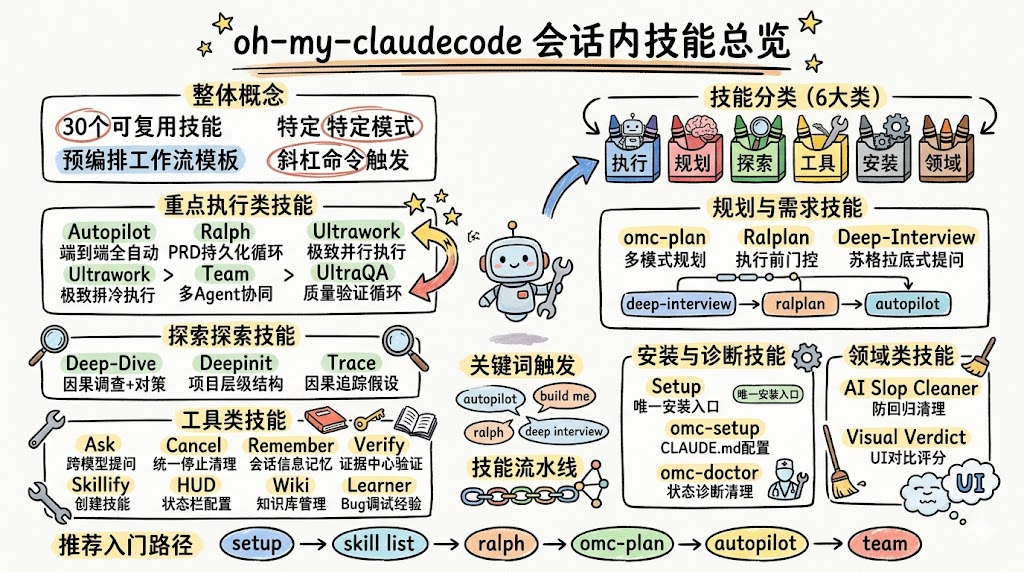
OMC 把 30 个技能划分成六大类,每一类对应开发生命周期中的不同环节:
autopilot,
ultrawork,
ralph,
team,
ultraqa 多 Agent 编排、并行执行、持久化循环与质量闭环 规划(Planning)
omc-plan,
ralplan,
deep-interview 需求澄清、共识规划、规格说明 探索(Exploration)
deep-dive,
deepinit,
trace,
external-context 根因分析、代码库熟悉、上下文探索 工具(Utilities)
ask,
cancel,
learner,
remember,
skill,
skillify,
verify,
hud,
wiki 会话管理、跨模型查询、记忆与知识库、技能管理 安装与诊断
setup,
omc-setup,
omc-doctor,
mcp-setup 安装配置、环境诊断、MCP 集成 领域(Domain)
ai-slop-cleaner,
ccg,
visual-verdict,
project-session-manager,
writer-memory,
self-improve,
sciomc,
configure-notifications 针对特定场景的专用流水线,如防回归、UI 对比等
理解这张“地图”,是用好 OMC 的前提。
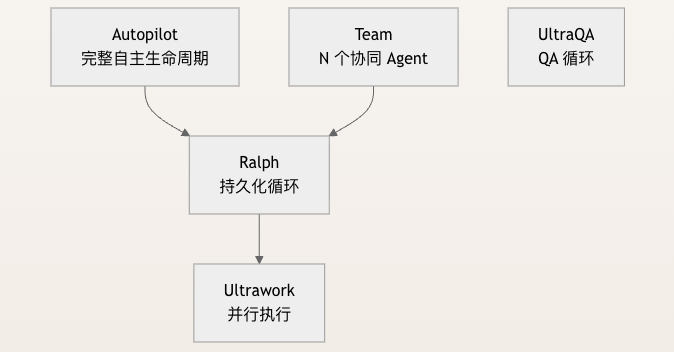
执行类技能是 OMC 的核心战力,负责真正“干活”:编码、重构、修复、测试,以及整条链路的质量闭环。 它们之间是分层关系:
调用方式:
/oh-my-claudecode:autopilot <产品想法> 典型触发词:"autopilot", "build me", "create me", "I want a..."。
Autopilot 面向的是“给你一个想法,你帮我跑完整个软件生命周期”的场景:从需求分析、技术设计,到任务规划、并行编码、QA 循环及最终多方验证。
其内部通常会经历 5 个阶段:
- 阶段 0 – 扩展:把简短想法扩展为详细规格说明(若已有 Deep Interview 或 Ralplan 输出可直接复用);
- 阶段 1 – 规划:产出可执行的技术方案与任务分解;
- 阶段 2 – 实现:并行执行编码任务,底层由 Ultrawork 提供并行能力;
- 阶段 3 – QA 循环:最多 5 轮“测试 → 修复 → 再测”,直到满足目标;
- 阶段 4 – 多视角验证:由代码审查员、安全审查员、架构师等不同角色给出签字结论。
适合用 Autopilot 的场景:
- 新建一个 Demo 服务或内部工具;
- 为已有系统增加一个中等规模的模块;
- 希望尽量少打断 AI,自主跑完一条链路。
不适合的场景:
- 只是想比较几种技术方案或权衡取舍(先用规划类技能,如
omc-plan); - 只需要小改动或一次性修复(用
ralph或直接点对点委派)。
一个典型例子是:
“帮我做一个支持用户注册、登录和JWT鉴权的 REST API,技术栈用 Node.js + PostgreSQL。”
此时直接丢给 Autopilot,会自动拉起完整链路:从 schema 设计到路由、控制器、中间件再到测试和验证。
调用方式:
/oh-my-claudecode:ralph [--no-deslop] [--critic=architect|critic|codex] <任务> 典型触发词:"ralph", "don't stop until", "must complete"。
Ralph 的核心目标是:确保任务真正完成并通过验证,而不是“差不多就行”。
工作方式上,它会:
- 从你的任务描述生成
prd.json,将需求拆成一条条具有可测试验收标准的用户故事; - 按故事逐个迭代,每个故事执行 → 测试 → 审查 → 必要时重试;
- 强制引入审查 Agent(默认为架构师,可通过
--critic切换),从结构、质量和一致性层面把关; - 可选地在审查通过后执行“slop 清理”(反 AI 冗余清理),通过
--no-deslop可以关闭。
适合用 Ralph 的场景:
- 你有一组清晰的变更需求,必须逐条兑现;
- 需要长期跟踪进度,例如把一个迭代拆成多个故事,一次次落地;
- 希望结果在结构上“像是人写的”,而不是大量重复和过度抽象。
比如:
“把我们旧版认证模块整体升级到支持 OAuth2 + 内部单点登录,确保所有原有用例都不回归。”
此时通过 Ralph 建立 PRD 并持久化推进,比简单地让 AI“帮我改一下”更可靠。
调用方式:
/oh-my-claudecode:ultrawork <包含并行项的任务> 典型触发词:"ulw", "ultrawork"。
Ultrawork 是一个偏底层的可组合组件:负责并行执行和模型智能路由,但不管状态持久化,也不做闭环验证。
它会根据任务类型把子任务路由到不同模型层级,例如:Haiku 处理简单查询,Sonnet 负责常规开发任务,Opus 处理复杂分析。
适用的典型场景是:
- 有一堆彼此独立的小任务,例如同时写多个工具函数、生成多份配置;
- 你会自己检查结果,不要求系统帮你“记住今天做了什么”。
如果希望在并行基础上增加持久化和验收,就可以让 Ralph 来封装 Ultrawork;再往上则由 Autopilot 封装 Ralph。
调用方式:
/oh-my-claudecode:team [N:agent-type] [ralph] <任务> 典型触发词:"team"。
Team 把“多 Agent 协作”作为一等公民:创建 N 个协作 Agent,在共享任务列表上分工合作,由主 Agent 负责拆解、分配和调度。
具备几项关键能力:
- 支持多种 Worker:Claude Worker、Codex CLI Worker、Gemini CLI Worker;
- 内置阶段化流水线:探索 → 调研 → 设计 → 规划 → 编码 → 测试 → 验证;
- 任务依赖与重分配机制,以及看门狗策略防止任务卡死;
- 可以通过
ralph修饰符和 Ralph 组合,实现“多 Agent + 持久化”的混合模式; - 集成 Git worktree,在代码层面实现隔离的并行开发分支。
适合团队中这样的一类任务:
“给我们的微服务架构做一次全面诊断:找出风险点,给出改进设计,并分模块实现关键改动。”
在这种场景下,单 Agent 很容易“脑丢失”;Team 模式则可以分角色深入不同子系统,再通过共享待办汇总。
调用方式:
/oh-my-claudecode:ultraqa [--tests|--build|--lint|--typecheck|--custom] [--interactive] UltraQA 关注的是质量闭环:它会启动一个 QA 循环,引入 QA tester 与架构师两个角色,让他们在“检测 → 分析 → 修复 → 复测”的回路中最多执行 5 轮,直至达到预设的质量目标。
支持多种目标类型:--tests、--build、--lint、--typecheck、--custom 以及交互式测试模式。
典型用法是接在 Ralph 或 Autopilot 之后,对某个模块做一次心理上更“安心”的质量收尾。
规划技能解决的是“需求搞不清楚,写代码只会重复返工”的老问题。 OMC 提供了从轻量到重量的多个层级。
调用方式:
/oh-my-claudecode:omc-plan [--direct|--consensus|--review] [--interactive] [--deliberate] <任务> 根据你的输入情况,Plan 会选择不同模式:
--direct 或输入已非常详细 跳过访谈直接生成计划 共识
--consensus 或使用 “ralplan” 语义 规划师 ↔ 架构师 ↔ 评论员 多轮往复 审查
--review 对现有计划做评审和改进
共识模式下,Plan 会持续迭代生成一份 RALPLAN-DR 摘要,包括决策原则、关键驱动因素、可选方案和风险预估,甚至支持事前验尸(pre-mortem)。 通过审批后,这份计划可以直接交给 Autopilot 或 Ralph 执行。
调用方式:
/oh-my-claudecode:ralplan [--interactive] [--deliberate] <任务> Ralplan 本质上是 omc-plan --consensus 的简写,但它还有一个更关键的角色:执行前门控。
当你以模糊指令调用执行类技能(比如“ralph fix this”)时,Ralplan 会拦截这类请求,让系统先进入共识规划流程,避免盲目执行。
只有在检测到足够“具体信号”时,它才会放行,例如:明确的文件路径、Issue 编号、函数名、编号步骤或具体代码块。 若你非常确定自己要干什么,也可以用 force: 或 ! 前缀绕过门控。
这种设计,实际上是用“规划”去保护“执行”,帮助你避免把大量算力浪费在错误方向。
调用方式:
/oh-my-claudecode:deep-interview [--quick|--standard|--deep] [--autoresearch] <想法> 典型触发词包括 "deep interview", "interview me", "ouroboros", "don't assume"。
Deep Interview 把“需求明确化”当成一个可以度量的过程:引入数学上的“模糊度评分”,每轮只就清晰度最差的维度提一个问题,并拒绝在模糊度降到 20% 以下前进入后续执行阶段。
更有意思的是,它在不同轮次会引入角色切换,例如:第 4 轮引入反对者,第 6 轮引入简化者,第 8 轮引入本体论者,以不同视角挑战原有假设。
它最适合这样一种状态:
“我有个模糊的产品想法,连自己都说不清楚,更别说直接上来写代码。”
在 OMC 推荐的三阶段流水线中,通常是:
deep-interview→ralplan→autopilot。
先把需求清晰到“模糊度 ≤ 0.2”,再通过 Ralplan 达成团队级共识,最终由 Autopilot 全流程执行。
探索技能服务于“搞清楚发生了什么”和“熟悉环境”两类需求。
调用方式:
/oh-my-claudecode:deep-dive <问题> Deep Dive 将 trace 和 deep-interview 编排成一个两阶段流水线:先在多条并行通路上做因果调查(Trace),再把得到的发现注入到 Deep Interview 中,形成针对性的对策设计。
这样可以避免单独跑 Trace 或单独跑访谈时的上下文割裂问题。
调用方式:
/oh-my-claudecode:deepinit Deepinit 的目标很简单:扫描项目,为 AI Agent 生成一个层级化的 AGENTS.md,帮助后续各种技能更好理解代码库结构。 在把 OMC 接入老项目时,优先跑一遍 Deepinit 会非常有价值。
调用方式:
/oh-my-claudecode:trace <观察现象> Trace 面向的是那种“靠猜很容易错”的问题:表现为一组观察现象,却隐藏复杂因果链。
它会系统地完成几件事:
- 重述观察现象,确保大家谈的是同一件事;
- 生成多条竞争性假设;
- 为每条假设并行收集证据;
- 对不同解释进行排序;
- 提出后续可操作的鉴别性探测。
整个过程严格区分“观察”“假设”“证据”和“当前**解释”,刻意避免退化成“试试改这里”“再试试改那里”的修 bug 循环。
这类技能不直接写代码,却决定了 OMC 在一个项目中能否长期高效运作。
调用方式:
/oh-my-claudecode:ask <问题> ask 通过 omc ask 封装器,把请求路由到本地的 Claude、Codex 或 Gemini CLI,并把结果持久化到 .omc/artifacts/ask/ 目录。
建议始终用 omc ask 而不是手写底层 CLI 命令,既方便日志留存,也减轻心智负担。
调用方式:
/oh-my-claudecode:cancel [--force|--all] 当 Autopilot、Ralph、Ultrawork、UltraQA、Team 等模式正在运行时,cancel 是统一的退出方式:自动检测当前模式并做相应的清理,避免残留状态在后续会话中造成干扰。
调用方式:
/oh-my-claudecode:ccg <问题> CCG 通过 ask 同时向 Codex(偏架构/后端)和 Gemini(偏 UX/设计)发起查询,再由 Claude 综合三方视角给出答案。 适合需要多维度权衡的问题,例如架构选型或 API 设计。
- Remember:把当前会话中有价值的信息分类存入项目记忆、记事本或
docs/AGENTS等持久层,而不是简单堆在某个“黑洞”里。 - Wiki:受 Karpathy 启发的 Markdown 知识库,支持导入、查询、Lint、快速添加和列表,存储在
.omc/wiki/。 - Learner:在解决某个“独特且难以搜索”的棘手 Bug 后,从调试过程抽取可复用的原则和启发式,形成 Level 7 自我改进技能。
三者组合起来,可以让“这次踩坑学到的东西”真正积累起来,成为下次的先验知识,而不是每次从零开始。
- Skill:管理内置技能、用户级技能和项目级技能(分别对应 OMC 内置、
~/.claude/skills/omc-learned/和.omc/skills/)。例如/skill list查看所有技能,/skill add新建技能。 - Skillify:把当前会话中成功的多步工作流自动提取为一份技能草案,包含 YAML frontmatter、触发词、步骤和成功标准,写入用户或项目级目录。
- HUD:配置状态栏显示模式,例如
minimal、focused(默认)和full,以及安装/修复 HUD 封装脚本。
这三个技能,让你可以从“使用技能”上升到“设计技能、管理技能”,逐步搭出一套符合自己团队习惯的 AI 协作操作系统。
调用方式:
/oh-my-claudecode:setup [doctor|mcp|wizard] 不带参数时进入完整安装向导,doctor 进入诊断流程,mcp 进入 MCP 服务器配置。
omc-setup:配置本地或全局 CLAUDE.md、设置 HUD、配置通知并执行健康检查,支持–local、–global、–force。omc-doctor:检查插件版本、旧版钩子、CLAUDE.md 配置等,以 CRITICAL/WARN/OK 级别给出可操作建议。
安装技能把“环境搭建”和“问题排查”本身做成了可复用工作流,避免每次换机或换项目都手忙脚乱。
领域技能更多是针对特定场景的深度优化。
调用方式:
/oh-my-claudecode:ai-slop-cleaner [--review] 这个技能专注于清理 AI 生成的“slop”代码:冗余、重复、过度抽象等。 工作准则是:
- 在改动前先通过测试锁定行为;
- 优先删除多余代码,而不是再加新东西;
- 保持差异小且可逆,降低回滚成本。
配合 Ralph 或 Autopilot 使用,可以大幅降低“代码看上去是 AI 写的”的违和感。
调用方式:
/oh-my-claudecode:visual-verdict Visual Verdict 会把当前 UI 截图与参考图进行对比,给出 0–100 分的 JSON 评分,并驱动反复编辑,直到评分达到 90 分以上。
对于追求像素级还原设计稿的前端或客户端团队,这个技能能显著降低肉眼对比的体力劳动。
此外,还有项目会话管理、写作记忆、自我改进、通知配置等领域技能,可以根据自己的技术栈和团队习惯按需引入。
在日常对话里,你不必每次都输入完整命令,一些常见短语会自动激活技能:
"autopilot",
"build me",
"I want a"
autopilot
"ulw",
"ultrawork"
ultrawork
"ralph",
"don't stop until"
ralph
"deep interview",
"interview me",
"ouroboros"
deep-interview
"stop",
"cancel",
"abort"
cancel
"deslop",
"anti-slop"
ai-slop-cleaner
"wiki",
"wiki this"
wiki
这有点像给会话加上“热词插件”:当你自然说出这些短语时,系统自动切换到更适合的模式,而不是停留在普通问答。
技能定义中可以通过 pipeline 或 next-skill 把多个技能串成标准流水线,OMC 会自动插入统一的交接块,让下游技能能正确消费上游输出。
典型例子是 Plan 技能内置的三阶段流水线:
pipeline: [deep-interview, omc-plan, autopilot] 这条链路的效果是:
- 先用 Deep Interview 把想法澄清成低模糊度规格;
- 再用 omc-plan 做共识规划;
- 最后交给 Autopilot 按方案执行。
你也可以在自定义技能里显式调用其他技能,比如:
- 先用某个 explore 技能获取上下文;
- 再用 architect 技能做架构分析;
- 最后用 executor 技能完成编码实现。
如果你刚接触 OMC 的技能系统,可以按下面的路线逐步升级自己的使用方式:
- 从
/oh-my-claudecode:setup开始
完成基本安装与配置,并通过omc-doctor确认环境健康。
- 用
/oh-my-claudecode:skill list熟悉技能全貌
了解有哪些“模式”可用,脑子里有张技能地图。
- 用
/oh-my-claudecode:ralph处理第一个真实任务
选择一个不算太大的需求,让 Ralph 驱动完整 PRD 和执行循环,体验“绝不漏项”的工作流。
- 探索
/oh-my-claudecode:omc-plan做规划
在动手改代码之前,借助 Plan 做方案对齐,尤其是多人协作场景。
- 升级到
/oh-my-claudecode:autopilot
把一个端到端的功能点全权交给 Autopilot 执行,形成对“自动驾驶开发”的直观感受。
- 掌握
/oh-my-claudecode:team的多 Agent 协作
在较大任务中试试 Team 模式,逐步培养“给 AI 分工”的习惯,而不是只和单个助手对话。
- 把自己的成功套路 Skillify 掉
当某条工作流多次实践效果不错,用skillify把它沉淀成项目级技能,让团队成员可以一键复用。
OMC 的会话技能系统,真正有价值的地方在于三个层面:
- 结构化:把“写需求 → 做设计 → 划分任务 → 并行执行 → QA → 验证”的过程实体化为技能,减少临场发挥带来的随机性;
- 可组合:技能之间可以形成流水线,再配合记忆与知识库,使 AI 在同一项目内持续变“熟练”;
- 可沉淀:不仅你可以用内置技能,还可以通过 Skillify 把自己的**实践固化下来,变成个人或团队的专用助手模式。
如果你已经习惯了在编辑器里敲下 “// TODO: ask AI”,不妨进一步想一想:这是不是某个可以固化下来的工作流?它是不是应该变成一个可复用的技能?当这件事发生时,你使用的就不再只是一个“智能补全工具”,而是一套真正可编程的 AI 协作系统。
建议的实践起点:
- 先用
deep-interview → ralplan → autopilot这条流水线做一次端到端实验;- 然后挑一条你常做的重复性工作,尝试用
skillify把它变成你的第一个自定义技能。

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/277894.html