
本文深入探讨了单智能体和多智能体架构的优劣,指出正确的架构选择应基于任务结构而非技术野心。单智能体适合紧密耦合工作,而多智能体在可并行化任务中效率高,但错误放大风险大。行业领导者 Anthropic、OpenAI 等建议从单智能体开始,仅在特定瓶颈时引入多智能体。文章详细分析了多智能体的三个适用场景:上下文污染、并行化和专业化,并提供了实用的决策框架和成本优化策略。最终强调,架构质量比模型智能更重要,应在特定接缝处谨慎引入多智能体编排。
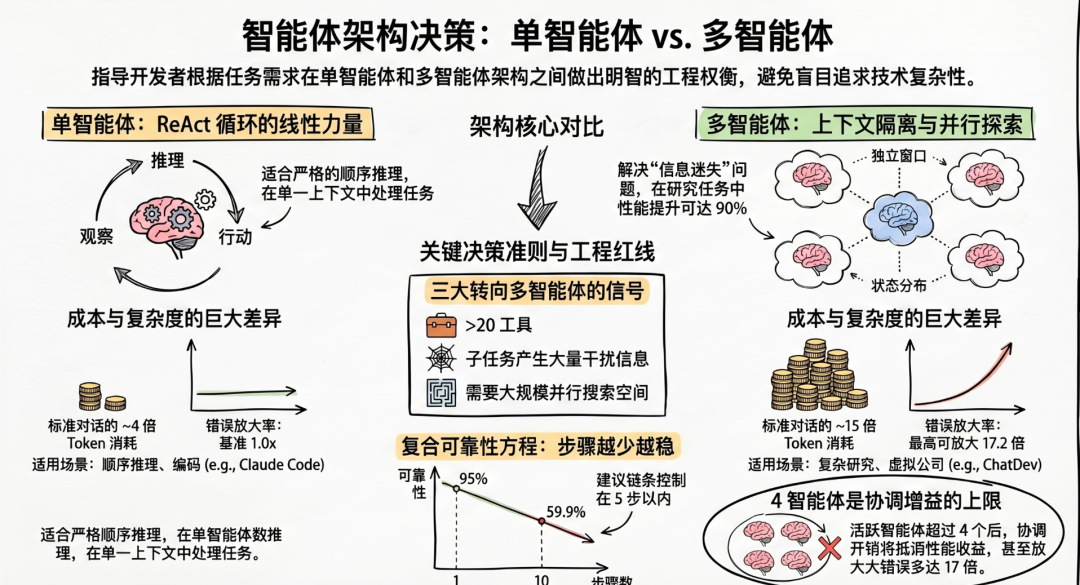
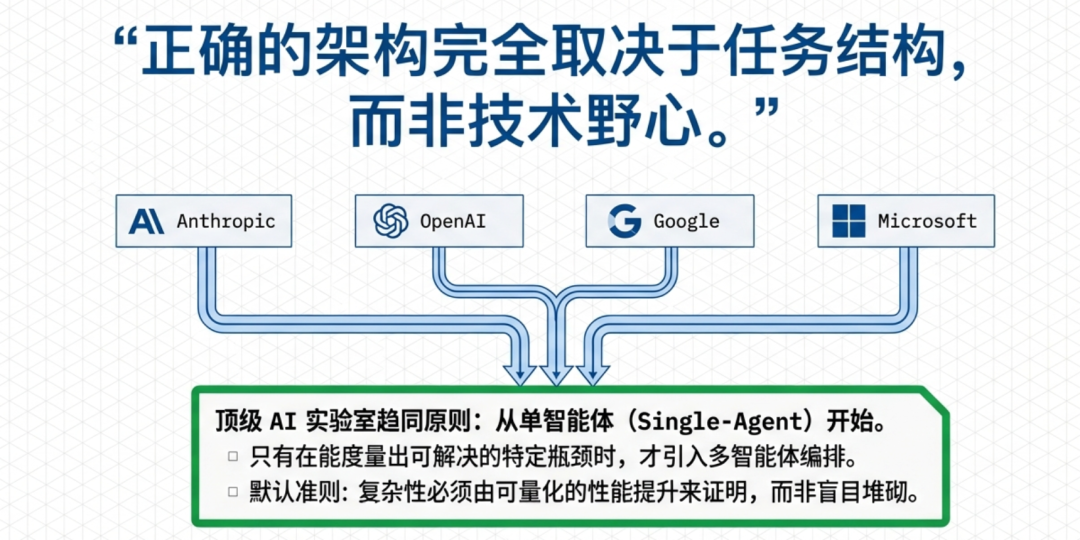
正确的架构完全取决于任务结构,而非技术野心。 多智能体系统在可并行化的研究任务上能比单智能体高出 90%,但在紧密耦合的工作中会将错误放大多达 17 倍。每个主要 AI 实验室——Anthropic、OpenAI、Google、微软——现在都趋向同一原则:从单智能体开始,仅在能度量出多智能体可解决的特定瓶颈时才引入多智能体。本报告综合了 2024–2025 年来自行业领导者的指南、覆盖 180+ 种智能体配置的学术研究、生产案例研究以及中文技术社区的实践洞察,提供了一个可直接用于决策的架构选型框架。
单智能体系统运行一个 LLM 的 ReAct 循环(推理 → 行动 → 观察 → 重复)。模型接收输入,决定调用哪个工具,观察结果,然后迭代直到任务完成。所有状态都存在于一个上下文窗口中——对话历史、工具输出和中间推理累积在一个不断增长的 prompt 中。Claude Code 就是这种模式的典范:一个主 while(tool_use) 循环,配合 14 个专注的工具和一个扁平的消息历史。没有竞争的智能体角色,没有协调开销。当模型输出文本而非工具调用时,循环终止。
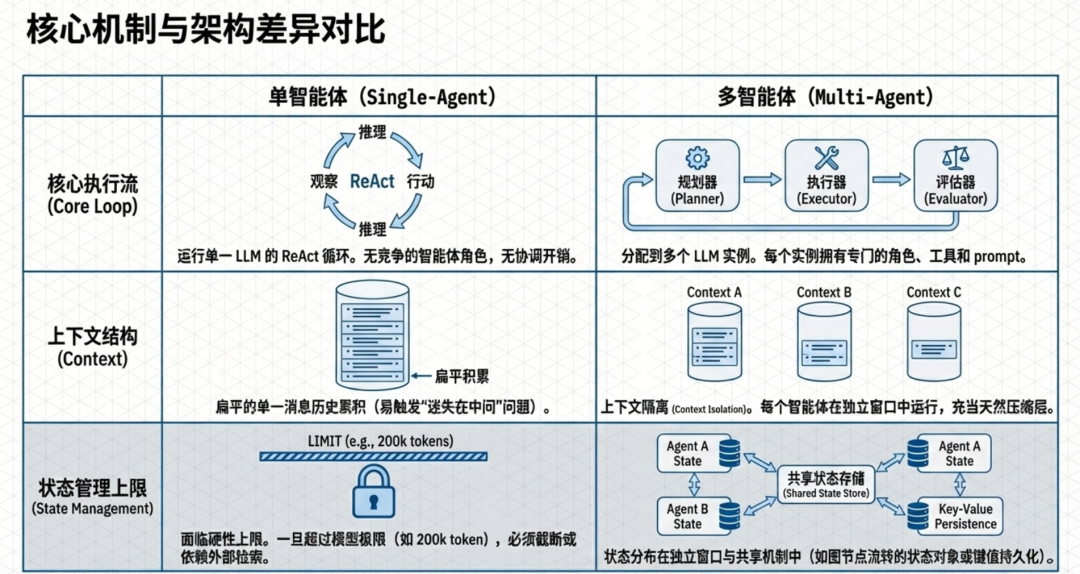
多智能体系统将工作分配到多个 LLM 实例上,每个实例拥有专门的角色、工具和 prompt。架构上的关键差异不仅是并行性——而是上下文隔离。每个智能体在自己的上下文窗口中运行,防止了长上下文中被埋没的信息被忽略的“迷失在中间”(lost in the middle)问题。例如,Anthropic 的多智能体研究系统使用一个主导智能体(Claude Opus 4)生成并行子智能体(Claude Sonnet 4),每个子智能体独立探索,然后返回压缩后的发现。
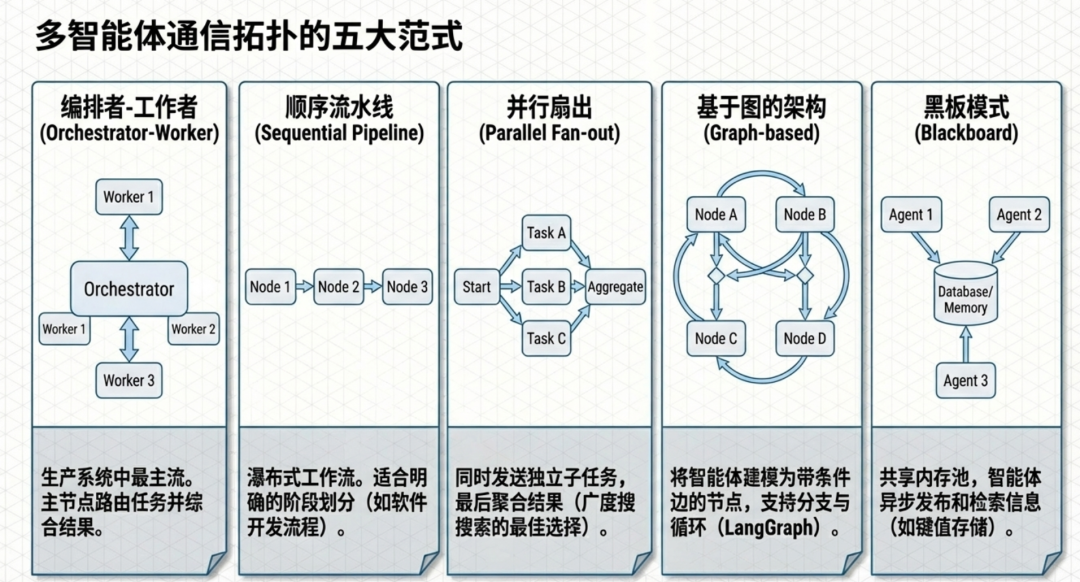
通信拓扑定义了这些智能体如何交互。编排者-工作者模式(中心辐射型)在生产系统中占主导地位:一个中心智能体路由任务并综合结果。顺序流水线将一个智能体的输出传递给下一个,适合瀑布式工作流(如 ChatDev 的软件开发流程)。并行扇出将独立子任务同时发送给多个工作者,然后聚合结果。基于图的架构(LangGraph 的核心范式)将智能体建模为带条件边的节点,支持分支、循环和动态路由。黑板模式可追溯到 1980 年代的 AI 研究,使用共享内存让智能体异步发布和检索信息——现代实现包括 LangGraph 的 TypedDict 状态对象和 Google ADK 的会话级键值存储。
状态管理揭示了最尖锐的对比。单智能体系统面临硬性上限:一旦上下文窗口填满,信息必须被截断、摘要化或从外部存储中检索。多智能体系统将状态分布在各智能体的独立窗口加上共享机制中。当上下文超过 200,000 token 时,Anthropic 的主导智能体会将其研究计划保存到内存中。LangGraph 通过图节点流转共享状态对象,并用归约器(reducer)定义并发更新的合并方式。Google ADK 提供会话级状态,跨智能体交互持久化,并通过 Vertex AI 上的托管云会话进行生产部署。
Anthropic 2026 年 1 月的指南明确了多智能体持续优于单智能体的恰好三种场景,并已通过其生产研究系统验证:

上下文污染发生在子任务生成大量信息(超过 1,000 token)且大部分与主任务无关时。子智能体提供上下文隔离——每个在自己的窗口中探索,仅返回核心发现,充当天然的压缩层。LangChain 的 token 分析证实:子智能体模式对多领域查询消耗约 9,000 token,而移交模式携带增长的对话历史累积至 14,000+ token。
并行化在探索具有独立子任务的大搜索空间时带来增益。Anthropic 的多智能体研究系统(Claude Opus 4 主导、Claude Sonnet 4 工作者)在广度优先研究任务上比单智能体 Claude Opus 4 高出 90.2%,复杂查询的研究时间缩短多达 90%。Google DeepMind 对 180 种智能体配置的研究发现,在可并行化的金融推理任务上——智能体同时分析收入趋势、成本结构和市场对比——集中式多智能体协调比单智能体基准提高了 80.9%。
专业化在单个智能体累积了过多工具时变得重要。三个信号表明了这个问题:工具数量超过约 20 个、不相关工具集之间的领域混淆、以及添加新工具时性能下降。OpenAI 的实践指南指出,某些智能体可以成功使用 15+ 个不同工具,而另一些在不到 10 个重叠工具时就失败——通常是重叠而非数量导致失败。
反之,多智能体在需要严格顺序推理的任务上性能下降 39–70%。Google DeepMind 在 PlanCraft 任务上对测试的每种多智能体变体都证明了这一点。中文从业者将此总结为“默认单 Agent,除非有明确理由”。
多智能体设计中最重要的数字是复合可靠性方程。如果每个智能体步骤达到 95% 的可靠性,在 10 个顺序步骤后,整体可靠性下降到 59.9%。经过 20 个步骤,崩溃到 35.8%。MAST 研究(UC Berkeley/Stanford/MIT,2025 年 3 月)分析了七个多智能体框架的 1,642 个执行轨迹,发现失败率在 41% 到 86.7% 之间,其中协调故障占所有失败的 36.9%。
成本急剧增长。Anthropic 报告智能体使用的 token 是聊天交互的 4 倍,而多智能体系统使用的 token 约为标准聊天的 15 倍。一个具体示例:客户支持工作流在单智能体上花费 \(0.05,但在五智能体系统上花费 \)0.40——8 倍的差额。不受约束的软件工程智能体每个任务可能花费 $5–8。然而,成本优化策略可以弥补大部分差距:prompt 缓存将输入成本降低约 90%,延迟降低 75%;计划-执行模式(前沿模型规划,便宜模型执行)与全程使用前沿模型相比可节省高达 90% 的成本。
延迟通过智能体移交复合累积。单次 LLM 调用约 800ms。每次智能体移交增加 100–500ms 的开销;链接五个智能体在任何处理开始前就增加了超过两秒。带有反思循环的编排者-工作者设置可能需要 10–30 秒。但多智能体并行化的主要优势是完整性而非速度——这些系统通常由于总计算量增加而花费更长时间,但覆盖的范围显著更广。
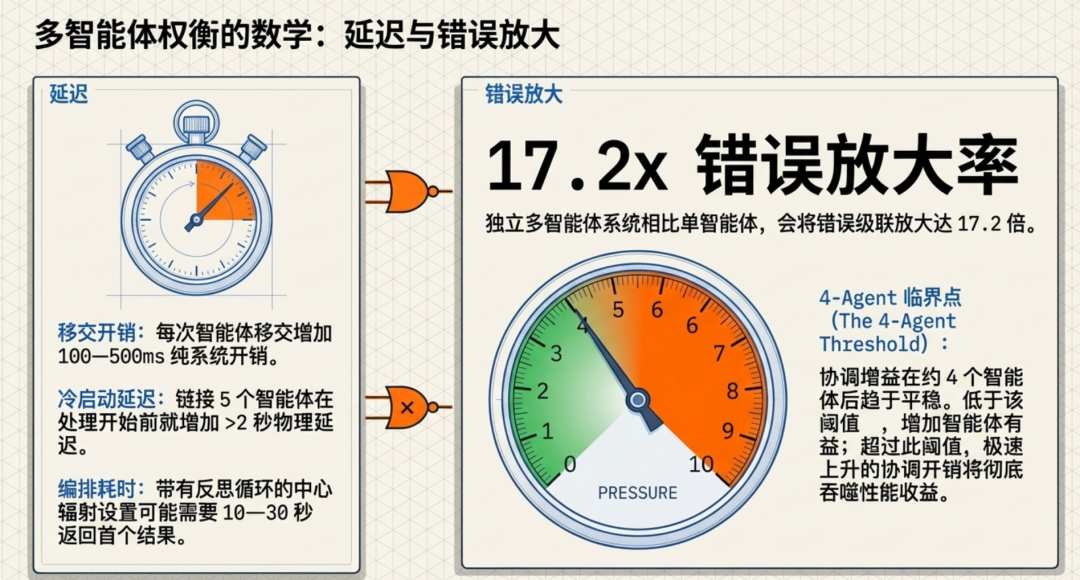
错误放大遵循可预测的模式。Google DeepMind 发现,独立多智能体系统相比单智能体基准将错误放大多达 17.2 倍。带有协调者的集中式架构将放大限制在 4.4 倍。协调增益在约 4 个智能体后趋于平稳——低于该阈值,添加智能体有帮助;超过该阈值,协调开销消耗掉收益。一位中国开发者的轶事说明了风险:一个三智能体文档分析流水线(提取 → 分析 → 摘要)产出了“看起来很专业但完全错误”的结果,原因是静默的错误级联。
Claude Code 代表了单智能体架构的最先进水平。其设计理念——“简单的单线程主循环结合严格的工具和规划,即可实现可控的自主性”——有意拒绝多智能体的复杂性,以换取可调试性。
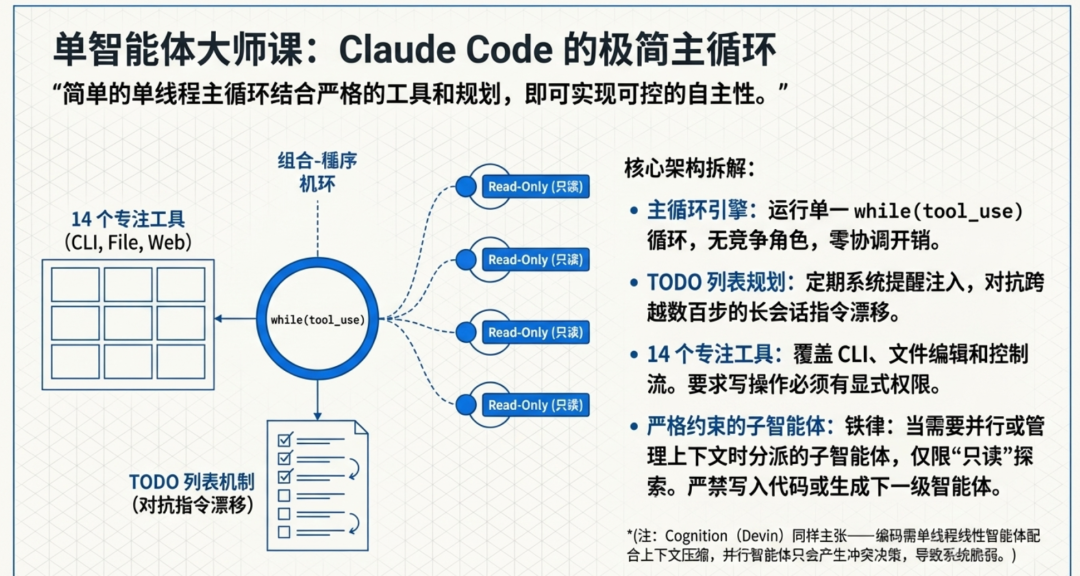
架构分为四层:用户交互层(CLI、VS Code、Web)、带有主循环引擎的智能体核心、拥有 14 个专注工具的工具执行层、以及要求写操作显式允许/拒绝的安全/权限层。14 个工具覆盖命令行操作(Bash、Glob、Grep、LS)、文件交互(Read、Write、Edit、MultiEdit、NotebookRead、NotebookEdit)、Web 访问(WebSearch、WebFetch)和控制流(TodoWrite、Task)。
Claude Code 使用 TODO 列表进行规划,通过定期系统提醒注入来跟踪进度,以对抗跨越数百步的会话中的指令漂移。当需要上下文管理或并行化时,它通过 Task 工具分派子智能体——但在严格约束下。子智能体不能生成进一步的子智能体,不能写入代码,也不能对写操作并行运行。它们仅服务于两个目的:管理上下文窗口大小和加速只读探索。异步双缓冲队列允许用户在任务进行中注入新指令,而无需重启。
这种架构证明了一个精心设计的单智能体配合细致的上下文管理可以比多智能体替代方案更可靠地处理大多数编码任务。Cognition(Devin 的开发者)强化了这一点:他们倡导单线程线性智能体配合通过微调摘要模型的上下文压缩,认为对于编码——共享代码库的并行智能体会产生冲突决策——多智能体协作“只会导致脆弱的系统”。
ChatDev 通过模拟虚拟软件公司来体现良好实现的多智能体架构。专门化的智能体——CEO、CTO、程序员、设计师、测试员——通过结构化的多轮对话协作,自主地进行设计、编码、测试和文档编写。
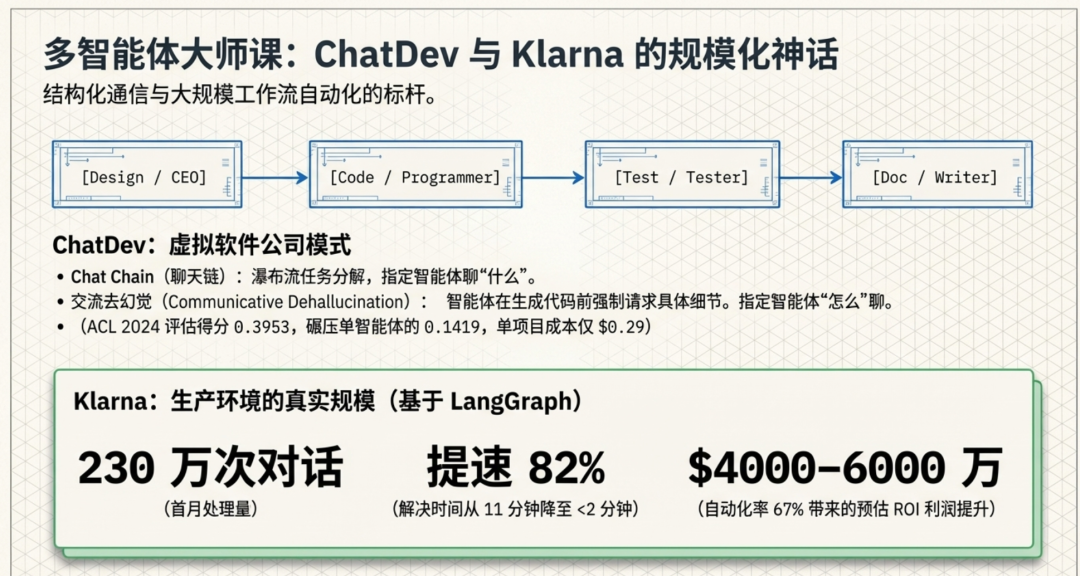
核心机制是 Chat Chain,它将瀑布式开发流程分解为阶段(设计 → 编码 → 测试 → 文档)。每个阶段涉及角色扮演智能体之间的结构化对话,受两个原则指导:Chat Chain 指定智能体通信的内容(任务分解),而交流去幻觉(Communicative Dehallucination)指定它们通信的方式(智能体在生成响应前请求具体细节,最大限度减少编码幻觉)。智能体使用自然语言进行系统设计,使用编程语言进行调试。
在 ACL 2024 评估中,ChatDev 在所有指标上均优于单智能体 GPT-Engineer 和多智能体 MetaGPT,质量得分达到 0.3953,对比 MetaGPT 的 0.1523 和 GPT-Engineer 的 0.1419。每个项目的平均开发成本为 $0.2967,开发时间为 409 秒。MetaGPT 采用互补方法,使用带有 SOP 的结构化通信——智能体生成 PRD、架构图和接口规范,而非无约束的自然语言,通过结构化输出格式和迭代的代码-测试循环实现 100% 的任务完成率。
Klarna 的生产部署展示了多智能体在大规模场景下的价值:基于 LangGraph 的架构在第一个月处理了 230 万次对话,将解决时间从 11 分钟降至不到 2 分钟(快 82%),实现了 67% 的自动化率,预估带来了 4000–6000 万美元的利润提升。
六大主要框架定义了当前生态系统,各自具有独特的设计理念:

LangGraph 将智能体工作流建模为有状态有向图。节点是智能体函数,边是转换(包括条件路由),共享状态对象在图中流转。它提供持久执行(自动检查点)、人机协作检查,以及全面的内存管理。生产用户包括 Klarna、Uber 和 J.P. Morgan。LangGraph 于 2025 年末达到 v1.0,成为所有 LangChain 智能体的默认运行时,月下载量 3450 万次。
CrewAI 使用基于角色的团队隐喻,包含两层:Crews(动态的、基于角色的智能体协作)和 Flows(确定性的、事件驱动的任务编排)。智能体具有定义的角色、背景故事和目标——使其对业务工作流自动化非常直观。它在框架中提供最快的搭建速度,但在快速变化的环境中可能面临适应性挑战。
AutoGen(微软)将工作流视为智能体之间的对话。其 v0.4 重新设计引入了异步事件驱动架构并支持 .NET——这在框架中独一无二。微软在 2025 年 10 月宣布将 AutoGen 和 Semantic Kernel 合并为统一的微软 Agent Framework,具备 SOC 2 和 HIPAA 合规性,目标 2026 年 Q1 正式发布。已有超过 10,000 个组织使用 Azure AI Foundry Agent Service。
OpenAI 的 Agents SDK(2025 年 3 月发布,是实验性 Swarm 的继任者)提供四个原语:Agents、Handoffs、Guardrails 和 Tracing。其极简设计避免了图或状态机抽象——控制通过显式的移交函数在智能体之间转移。AgentKit(2025 年 10 月)增加了可视化构建器、连接器注册表和评估功能。
Google ADK(2025 年 4 月)让“智能体开发感觉更像软件开发”,具备层级化智能体组合。三种智能体类型——LLM Agent(用于推理)、Workflow Agent(Sequential、Parallel、Loop,用于确定性控制)和 Custom Agent——可以嵌套。A2A(Agent-to-Agent)协议实现跨框架互操作性。部署目标从本地 Docker 到托管的 Vertex AI Agent Engine。
AWS Strands Agents(2025 年 5 月)采用模型驱动的方法:定义 prompt 和工具,让 LLM 自行处理编排。它内部驱动 Amazon Q Developer,累计 1400 万+ 下载量。部署覆盖 Lambda、Fargate 和托管的 Bedrock AgentCore。
生态系统正在围绕几个标准收敛:MCP(Model Context Protocol)用于工具集成,A2A 用于跨框架智能体通信,OpenTelemetry 用于可观测性。中国生态系统贡献了 Spring AI Alibaba 等框架,提供面向企业 Java 部署的 Supervisor 和路由智能体模式。
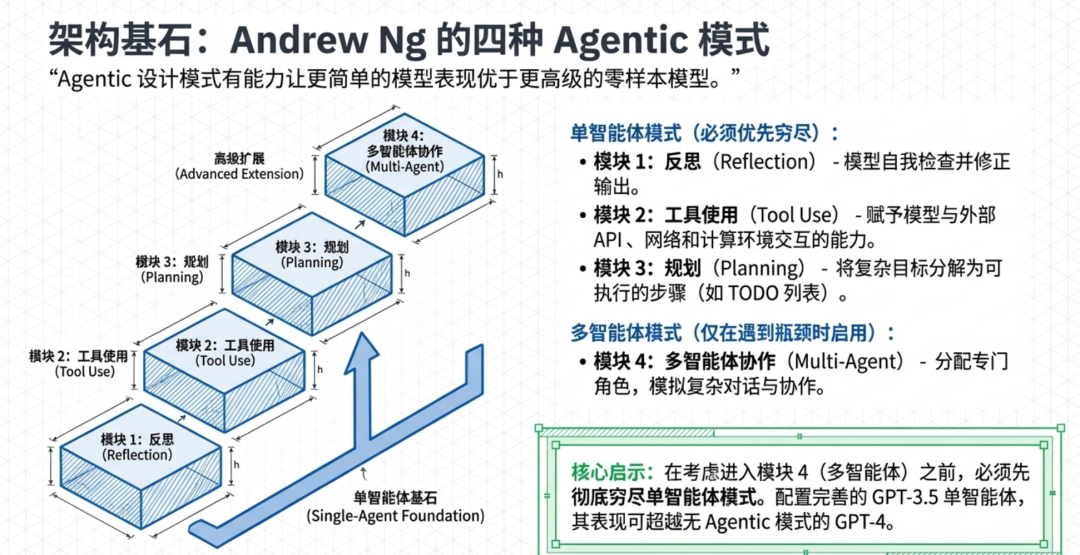
Andrew Ng 的四种 agentic 设计模式——反思(Reflection)、工具使用(Tool Use)、规划(Planning)和多智能体协作(Multi-Agent Collaboration)——提供了基础分类法。他的关键洞察是:“Agentic 设计模式有能力让更简单的模型表现优于更高级的模型。”采用 agentic 模式的 GPT-3.5 可以优于零样本的 GPT-4。启示是:在考虑多智能体之前,先穷尽单智能体模式。
综合 Anthropic、Google、微软和中文从业者指南得出的实用决策树遵循清晰的层级。始终从单智能体开始。用类生产负载测试其极限。仅在测试发现以下四种特定限制之一时才转向多智能体:子任务噪声导致的上下文退化、工具集过载导致的工具选择失败、独立搜索空间的并行探索需求、或法规要求处理步骤之间的数据隔离。
构建多智能体时,遵循以下经生产验证的约束:将智能体链控制在 5 个顺序步骤以内以保持 80% 以上的可靠性。将活跃智能体上限控制在约 4 个,超过此阈值协调开销将超过收益。从第一天起就实施可观测性——分布式追踪、每智能体成本归因、以及作为独立指标的工具延迟。使用路由模式对查询复杂度分类,将简单查询导向单智能体,复杂查询导向多智能体流水线。采用彩虹部署(逐步流量迁移,同时维护新旧版本),因为智能体在更新期间可能正处于任务中间。
中文从业者在知乎上补充了有价值的生产洞察:“在生产级 Agent 系统中,AI 仅完成 30% 的工作;剩余 70% 是工具工程”——设计反馈接口、高效管理上下文、处理部分失败、构建 AI 适配的错误恢复机制。demo 和生产之间的差距不在模型——而在围绕模型的工程。
单智能体与多智能体的决策不是一个先进程度的光谱——它是一个具有可量化参数的工程权衡。多智能体架构在可并行化、松耦合的任务上带来变革性的增益:Anthropic 在研究查询上 90.2% 的提升和 Klarna 节省的 4000–6000 万美元证明了其潜力。但复合可靠性方程、独立系统中 17 倍的错误放大、以及 15 倍的 token 成本倍增意味着多智能体是精密工具,而非默认选择。Google DeepMind 的预测模型仅基于任务属性——而非模型能力——就能对 87% 的未知任务正确识别最优架构。该领域正在形成的共识——在英文和中文技术社区中完全一致——是架构质量比模型智能更重要。2025 年最可靠的生产系统以具有严格工具设计的单智能体为基础,仅在上下文隔离、并行化或专业化能带来可量化改进的特定接缝处才引入多智能体编排。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 ,却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是**时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
- 掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
- 学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/275139.html