
新闻聚合网站
本站使用了Vue3+NaiveUI作为前端框架与组件,使用了Nodejs+Express作为项目后端,阿里云MySQL数据库作为项目数据库。
项目展示
选取其中部分功能截图作为项目展示

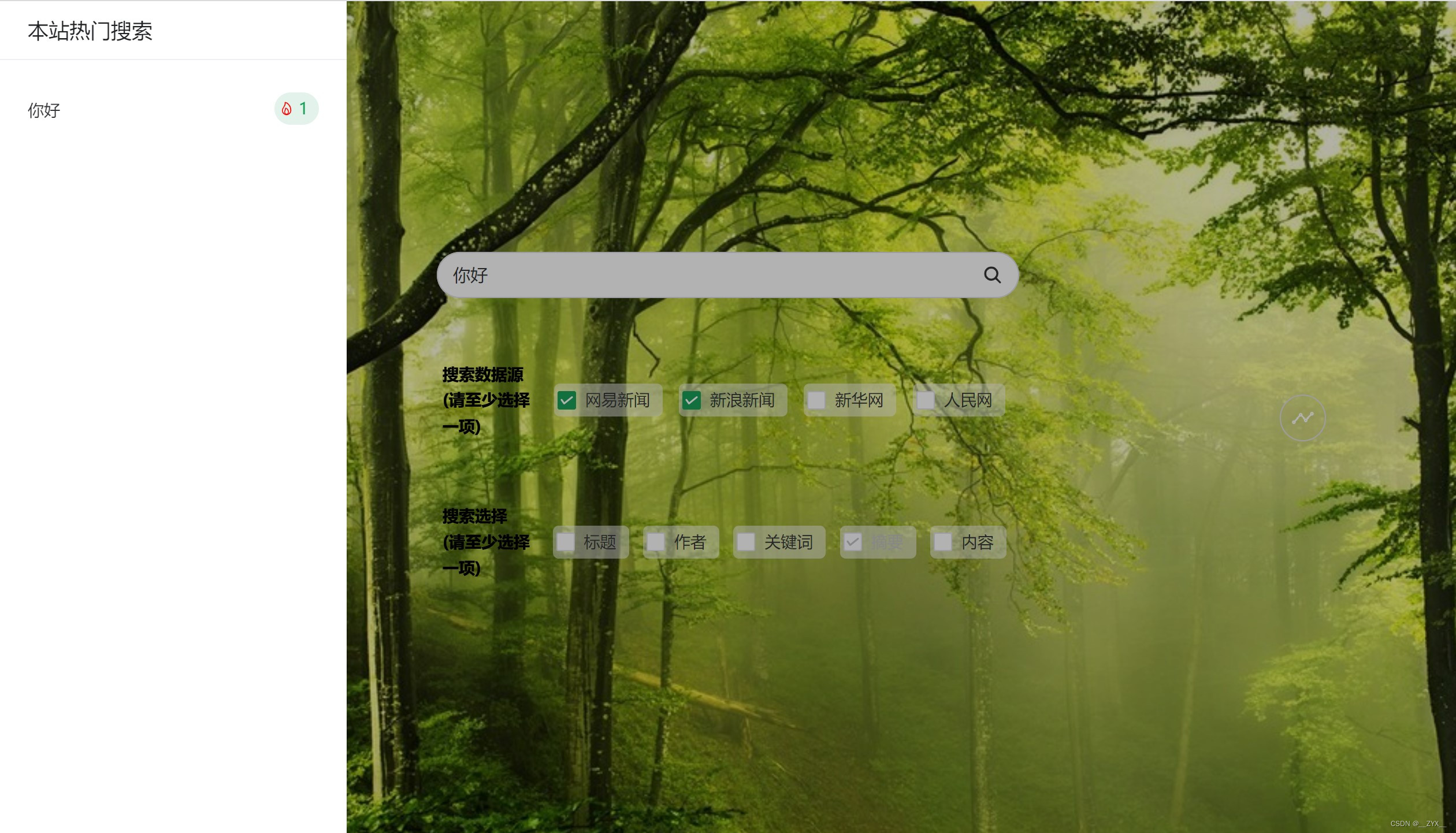


项目运行
本项目前后端分离,前端为front文件夹,后端为back文件夹,进入前后端文件夹后分别运行
npm install 讯享网
下载相应的module文件(如果没有的话)
由于本项目为demo项目,因此并没有做过深的负载等考虑,为开发模式,仅作为演示,因此Vue项目并未打包,均为源码开发模式呈现。
在front文件夹下运行
讯享网npm run serve
启动前端测试(默认运行在8080端口)
在back文件夹下运行
node main.js 启动服务器(默认运行在8000端口)
然后打开浏览器访问http://localhost:8080/即可测试项目
(tips:为保障隐私,阿里云部分用户密码已删除)
项目组成
前端
前端为单页面应用,所有交互均以模态框(或类模态框)进行,结构如下:
讯享网|-- front/src |-- main.js |-- App.vue |-- components | |-- Hot.vue | |-- Display.vue | |-- Result.vue |-- assets | ...
其中App.vue负责整体页面(主页),Hot.vue负责热搜模态框,Display.vue负责展示模态框,Result.vue负责搜索结果展示模态框(包含分页)。
后端
后端由于是第一次写nodejs后端,因此封装或者模块化都比较简陋,以后有兴趣的话可以将后端用Python或Java重写,结构如下:

|-- back |-- main.js |-- crawler | |-- common.js | |-- crawler.js | |-- websites | |-- wangyi.js | |-- xinlang.js | |-- xinhua.js | |-- renmin.js | ... 主体部分还是在爬虫上,由于针对不同网站的爬虫会有所不同,因此我将匹配的关键词放在了websites文件夹中的每个js文件中,种子页面处理放在crawler.js中,common.js用来放一些常用模块的二次封装(或者测试的时候可以拿来用,比如我的连接数据库操作是放在main中的,其他地方没有数据库,因此测试某个网站是否成功导入数据库中也可以在common中加入数据库连接操作并exports出来)。
其余定时器,search,热搜,展示的数据均在main.js中生成(这里是由于nodejs不太熟悉不会很好的封装,因此统一整合到了main中)
项目制作过程
前端
由于不是第一次写Vue前端,因此上手较为迅速,当然页面中也还有一部分小bug可能存在。在开发环境中需要解决跨域问题,我这里是将跨域在Vue中解决的,Vue提供了很好的devServer,只需修改proxy即可重定向所有请求url。
本次前端编写的难点在于Echarts和Vue的结合,因为本身Echarts是偏向于直接操作dom元素的,而Vue则是偏向于不直接操作dom,二者存在一定的分歧,这里的解决方案是将Echarts的元素挂在到一个虚拟dom上(也就是Vue3 ref定义出的变量),然后在template中定位到这个变量即可,但是这里有个点就是此时的Echarts是无法响应数据更改操作的,也就是说这是非响应式的(可能了解得不够深,这里可能用别的方法可以变成响应式),然而Echarts展示一般也只是生成出来就不变了得,因此我这边get到后端数据后直接在get的回调中对Echarts作挂载。
后端
数据库
由于本人的电脑曾经因为数据库无法卸载而苦恼过,因此并不是很想下载数据库到本地,而恰巧我申请的阿里云MySQL数据库还没有到期,因此本项目就将数据存入云数据库中,此时也需要修改部分数据库连接的代码,在示例代码中好像并没有指定某个数据库也没有host及port,这里对连接云数据库做一个扩展,同时也方便大家运行本项目:
讯享网const mysql = require('mysql') const db = mysql.createConnection({
host: "your.aliyuncs.com", database: "your database", port: 3306, user: "your username", password: "your password" }) db.connect((err) => {
if (err) {
console.log('fail to connect db', err.stack) throw err; } else {
console.log('connect to db successfully!') } })
这样就连接上了云数据库,db就可以用来做query。
爬虫
爬虫是本项目的一个重点,爬虫代码参考老师所给的示例代码,并进行了重构,稍微解耦了一点,方便重复使用,这里爬虫获得的title、keywords、description在大部分新闻网中都是通用的,因此这里基本不需要改,更多的是修改content、author、publishDate。这里有很多网站的作者(责任编辑)都是放在不同的位置,甚至同一个网站的不同页面位置也是不同的,因此我这里在找作者的时候做了一定的判断,如果实在找不到作者,则使用网站名称作为作者;出版时间也是如此。
在爬虫过程中也遇到了一些bug:
- 腾讯新闻用当前的爬虫代码无法爬取,甚至一个a标签都没有得到,这里查看源码后发现其每个a标签都有::before和::after等伪类或伪元素,可能是用了一些反爬技术。
- 在新浪新闻爬取过程中遇到了字符出现乱码的问题,查看网页源码后发现其网页格式并不是utf-8的而是GB2312的,修改encoding即可爬取。
- 使用示例代码爬虫时会出现有些网站是http://xxxxxhttps://xxxxxx,debug后发现是获取url的时候没有考虑前置是https的情况,将这一情况加入即可。
具体爬虫代码见back的crawler文件夹中(我稍微将var等语法改成了const和let,并使用了箭头函数)
热搜
我这里热搜的实现较为简单,是在服务器内部定义了一个变量,因此会随着服务器的开关导致搜索丢失,这里只是一个demo,如果真实场景下的话应当需要借助一些特殊工具来实现,这里是考虑到如果读写文件或者读写数据库的话IO过大可能网站比较慢,而且本站为demo流量比较少,所以直接放在服务器中了。
这里定义了全局的hotSearch对象初始为空,更新hotSearch函数为:
// 更新实时热搜 const updateHotSearch = (key) => {
if (key in hotSearch) {
hotSearch[key] += 1 } else {
hotSearch[key] = 1 } if (hotSearch.length > 75) {
let hotList = [] for (let k in hotSearch) {
hotList.push({
key: k, times: hotSearch[k] }) } hotList.sort((a, b) => -(a.times - b.times)) for (let i = 50; i < hotSearch.length; i++) {
delete hotSearch[hotList[i].key] } } } 这里需要注意的点是,js的sort函数比较的是字符串!,因此需要一个比较函数来对其进行校正。也就是
讯享网hotList.sort((a, b) => -(a.times - b.times))
这里就能将hotList中的元素按照其times属性从大到小排序(这里使用箭头函数较为方便)。
这里当热搜的长度大于75时候,就将热搜的后50名直接删除,这么做也是能减少一点点变化的次数。
热搜api获取数据的时候只需要差不多重做一遍长度大于75的情况就可以了:
// hot list api app.get('/api.hotList/', (req, res) => {
// 从hotSearch中获取热搜列表 let hotList = [] for (let k in hotSearch) {
hotList.push({
key: k, times: hotSearch[k] }) } hotList.sort((a, b) => -(a.times - b.times)) // 发送热搜列表 res.send({
hotList: hotList }) }) 展示数据
展示的数据如果也是实时获得就有点太慢了,因此我这里是将展示数据在服务器启动的时候就得到,然后在每次爬虫定时更新数据的时候重新获取一遍。这里主要是SQL语言的应用,我这里需要查询到所有keywords和每个source数据规模的大小,因此只需要分别各一句SQL查询即可。
针对keywords我们需要将其以分隔符分割,这里我爬取的数据一般是有两种分隔符:逗号和空格,因此我使用暴力两重循环直接对逗号和空格都进行分割,然后将分割好的数据push到一个数组中(其实可以直接在对象中进行操作,这里是为了测试),然后遍历数组,获得一个key为关键词value为出现次数的对象,接着按照同热搜中差不多的处理方法就可以获得热点词及其对应的次数了,将其打包成[{name: “name”, value: “value”}]的数组就可以直接发到前端去了。
讯享网const getKeywordsList = () => {
let keywords = [] let keywordsDic = {
} const keywordSQL = 'SELECT keywords FROM news' db.query(keywordSQL, (err, results) => {
for (let i = 0; i < results.length; i++) {
onekeys = results[i].keywords.trim() if (onekeys != '') {
if (onekeys.includes(',')) {
onekeysList = onekeys.split(',') for (let j = 0; j < onekeysList.length; j++) {
if (onekeysList[j].includes(' ')) {
temp = onekeysList[j].split(' ') for (let k = 0; k < temp.length; k++) {
keywords.push(temp[k]) } } else {
keywords.push(onekeysList[j]) } } } } } for (let i = 0; i < keywords.length; i++) {
if (keywords[i] in keywordsDic) {
keywordsDic[keywords[i]] += 1 } else {
keywordsDic[keywords[i]] = 1 } } for (key in keywordsDic) {
keywordsList.push({
name: key, value: keywordsDic[key] }) } keywordsList.sort((a, b) => -(a.value - b.value)) keywordsList = keywordsList.slice(0, 100) }) }
获取数据规模的方法比较简单,这里就不展示了。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/27041.html