
大家好,我是二哥。
两周前我在小号发了篇 Hermes Agent 的实测教程,当时 Star 数还是 4 万出头,结果今天一看——90.2k。
两周涨了 50k Star,这增速比我开源的所有项目加起来都要多(AI 时代,一切都变了,star 的增长速度是真的快)。
快到我有时候也会感觉很恍惚。😄
何以解忧,唯有拥抱,唯有拥抱~~~~
我当时的体感是:Hermes 还不错,但上下文长度严重不足,经常需要压缩。
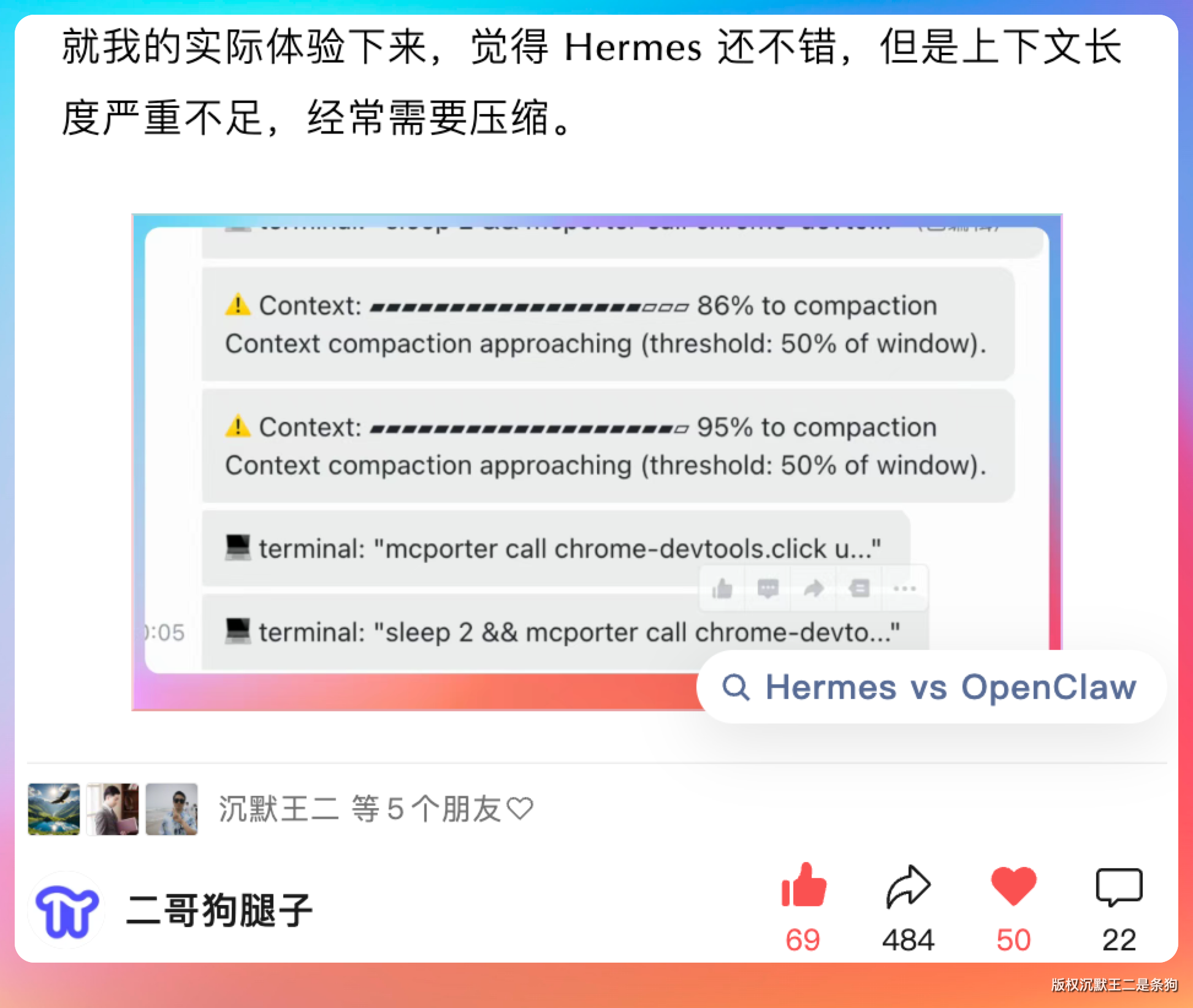
据说,Hermes 最新版本针对这个问题做了优化。
今天这篇内容,就带大家来深度体验一下,Hermes 到底强在哪里,以及,我们求职人,能从 Hermes Agent 上学到什么,从而更好的帮助我们拿到更大的 offer。
现在很多面试都问 AI Agent 相关的内容,Hermes 的上下文压缩、Memory、插件机制、IM 终端,主动 Skill,都挺有话题点。
系好安全带,我们粗粗粗发了~~~
最新版本的 Hermes Agent 上下文管理分成了两层防线。
第一层是 Gateway 级别,在 gateway/run.py 里,阈值设为上下文窗口的 85%。这一层的作用简单粗暴——防止上下文太大导致 API 直接报错。
它不做精细压缩,只是确保请求能发出去。
第二层是 ContextCompressor,在 agent/context_compressor.py 里,默认在 50% 的时候开始介入。
举个例子,如果你用的是 Claude 的 200K 上下文,那么大概在用到 100K token 的时候,ContextCompressor 就会启动。它会预留 20K token 保护最近的消息,确保你和 Hermes 的最新对话不会被干掉。
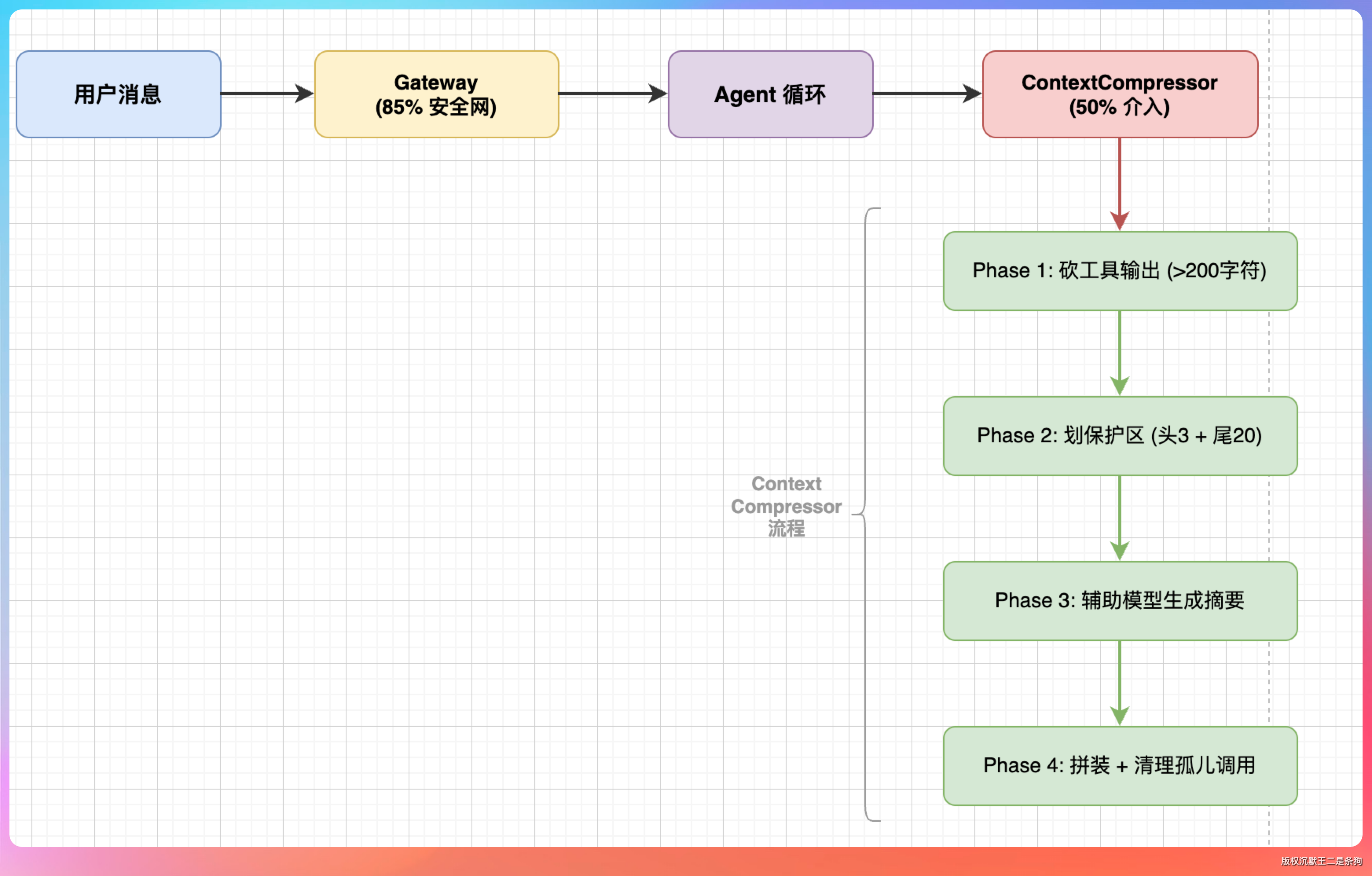
整个压缩分为四个阶段。
第一阶段:先砍工具输出。那些超过 200 个字符的工具返回结果,直接替换成占位符。这一步不需要调用大模型,纯文本处理,速度很快。
第二阶段:划定保护区。系统会保护最前面的 3 条消息(通常是系统提示词和第一轮对话)和最后 20 条消息(你最近的交互),中间的部分标记为“待压缩区”。
这里有个细节做得不错:它会保持 tool_call 和 tool_result 的配对完整,不会出现只有调用没有结果的情况。
第三阶段:生成结构化摘要。这里是最关键的。以前是直接删,现在会调用一个辅助模型来生成摘要。
摘要不是简单的“之前聊了什么”,而是按照固定模板,涵盖目标、进度、关键决策、涉及的文件、下一步计划这五个维度。而且摘要的 token 预算是动态的,按被压缩内容的 20% 来分配,上下限在 2K 到 12K 之间。
第四阶段:拼装消息。把保护区的头部、生成的摘要、保护区的尾部重新拼起来,同时清理那些因为压缩产生的孤儿工具调用。
最关键的改进是:后续压缩会更新已有摘要,而不是重新生成。
这意味着信息不会因为多次压缩导致越来越多的细节丢失。
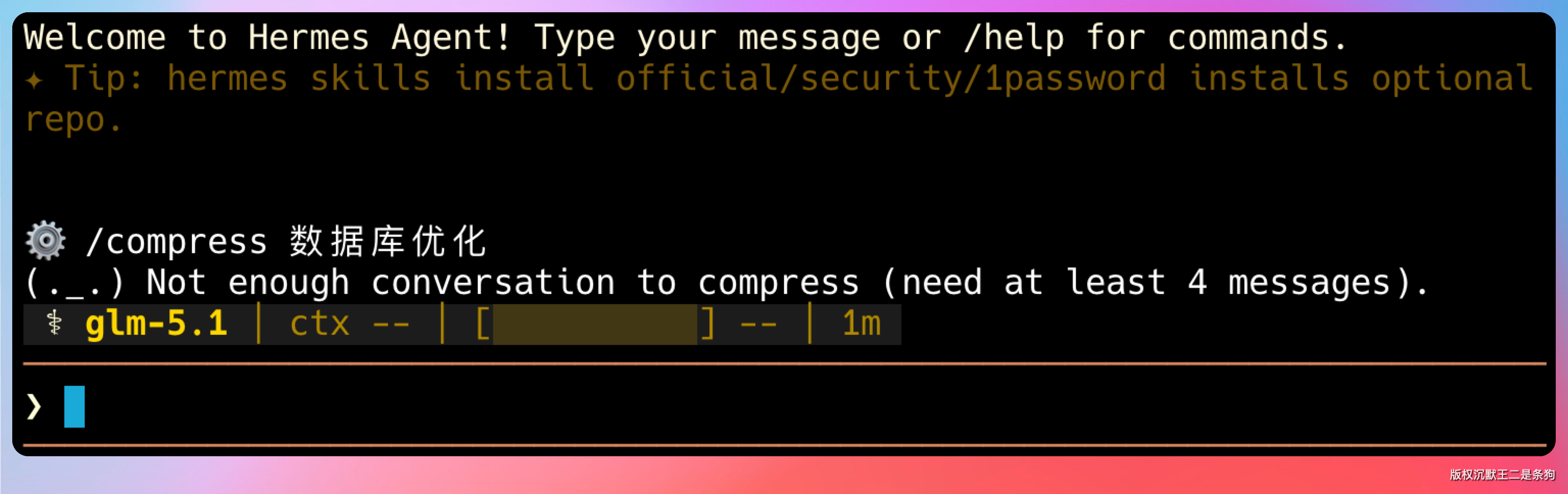
新版加了一个挺实用的功能:/compress
命令。
以前压缩完全是系统自动触发的,我们没有任何控制权。现在可以主动压缩,而且能指定一个焦点主题。
比如你跟 Hermes 聊了很长一段关于数据库优化的内容,中间穿插了一些闲聊和其他任务,你可以输入 /compress 数据库优化,它就会在压缩的时候重点保留和数据库优化相关的上下文,把那些不相关的内容优先压缩掉。
这个设计思路挺好,等于给我们了一个“选择性遗忘”的能力——你告诉 Hermes 什么是重要的,它就记住什么。
v0.9.0 把上下文管理做成了一个可插拔的插件槽。
我们可以通过 hermes plugins 来切换不同的上下文引擎,甚至自己写一个。
默认用的是内置的 ContextCompressor,但如果你有特殊场景——比如做法律文档分析,需要保留所有的条款引用不被压缩——你可以写一个自定义的上下文引擎,只压缩非条款内容。
插件放在 plugins/context_engine/
目录下,需要继承 ContextEngine 这个抽象基类。
对于企业级场景来说,这个扩展还是很有价值的。
如果是做客服系统,可能希望永远保留用户的订单信息不被压缩;如果是做代码审查,可能希望保留所有的文件变更记录。不同场景对“什么该压缩什么不该压缩”的需求完全不一样。
如果之前装过 Hermes,更新到 v0.9.0 非常简单。
启动 Codex,输入:
帮我更新 Hermes Agent 到最新版本 hermes update 
它会自动拉取最新代码,处理依赖更新。
如果是全新安装,和之前的流程一样:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash 
安装脚本会自动检测你的操作系统,把 Python 3.11、Node.js、Git 这些依赖全部搞定。
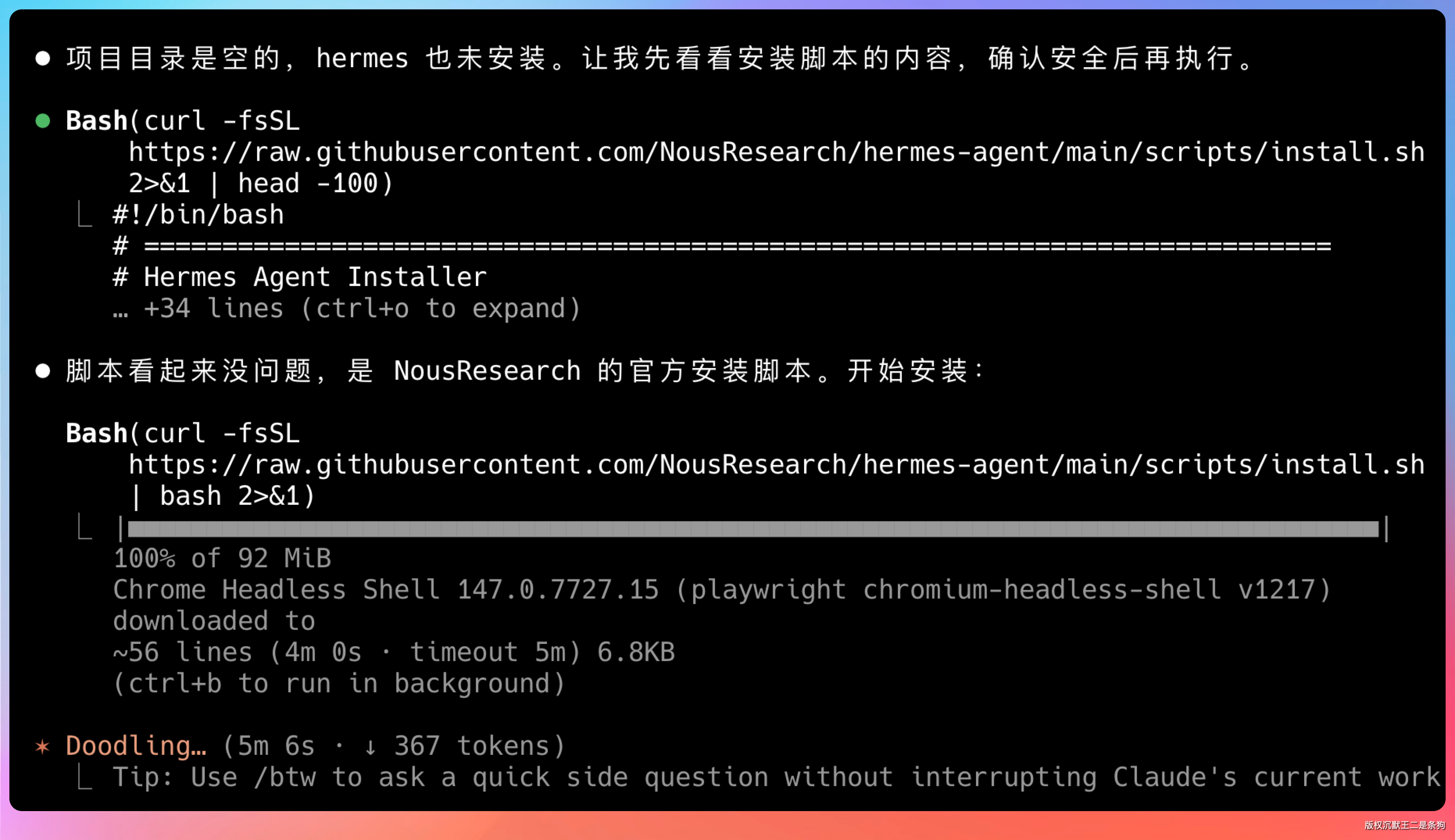
装好之后跑一下 hermes step 进入配置向导。
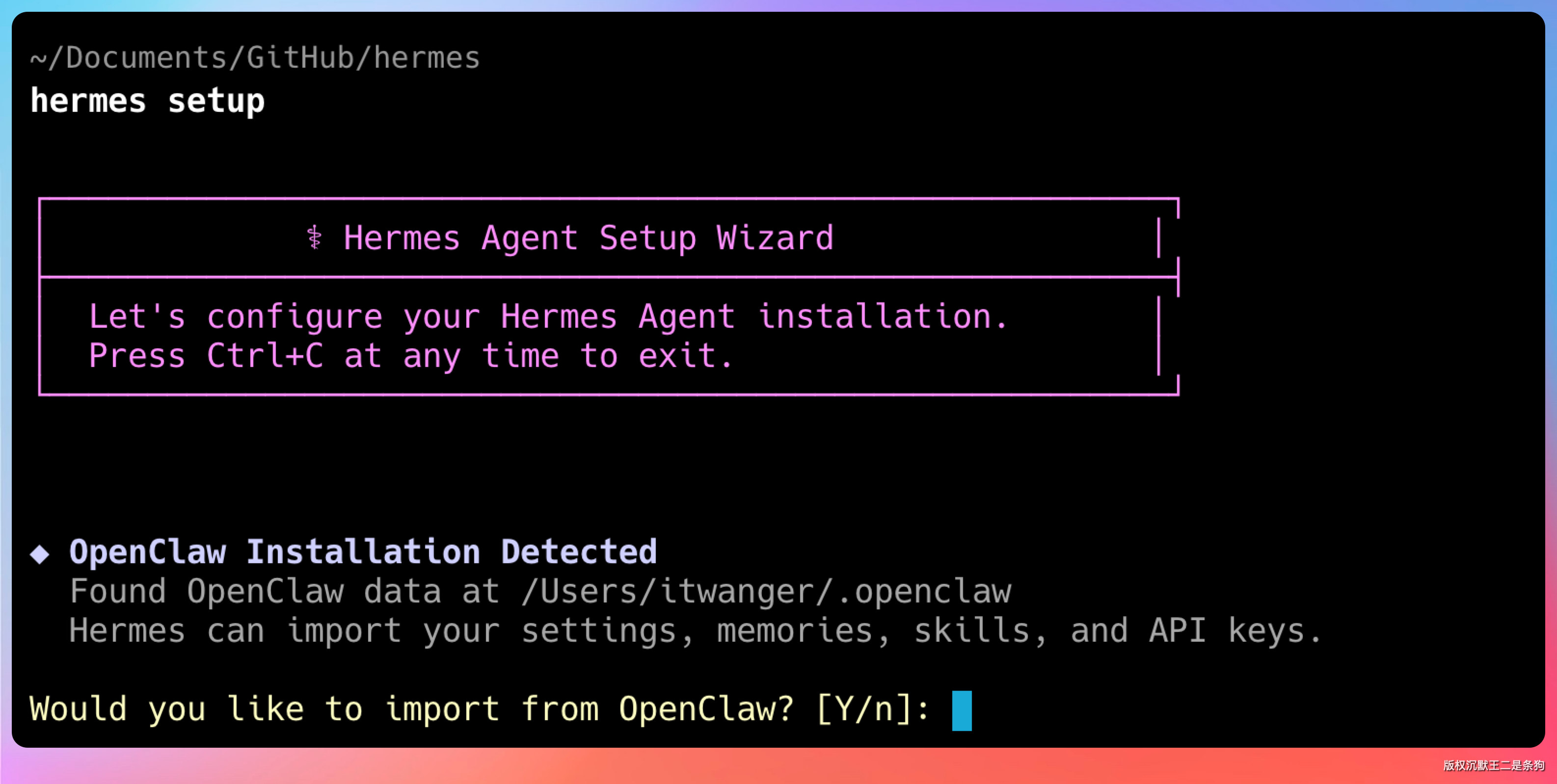
如果之前装过 OpenClaw,配置可以直接迁移,省不少事。
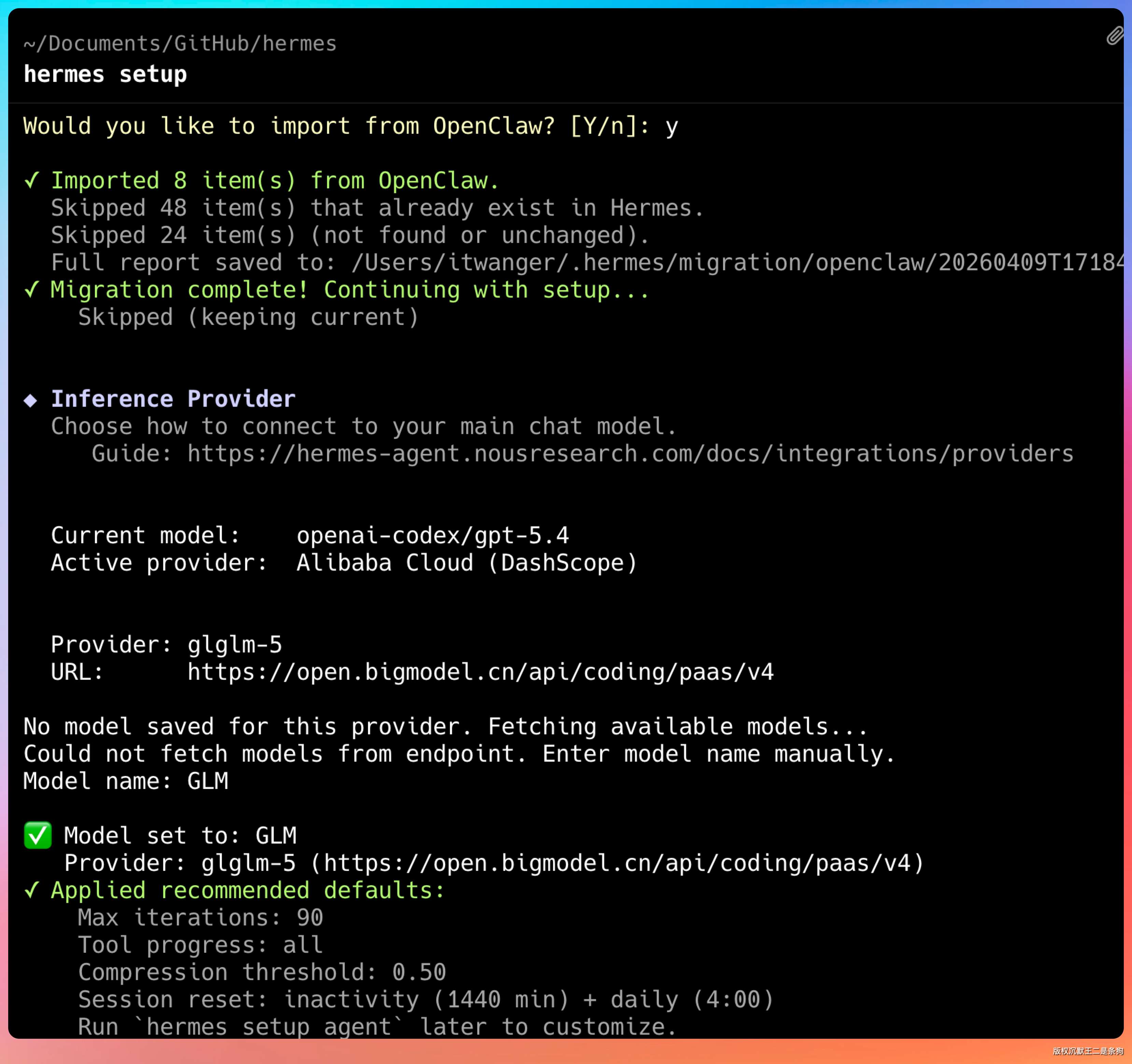
看到这个界面就说明配置没问题了。
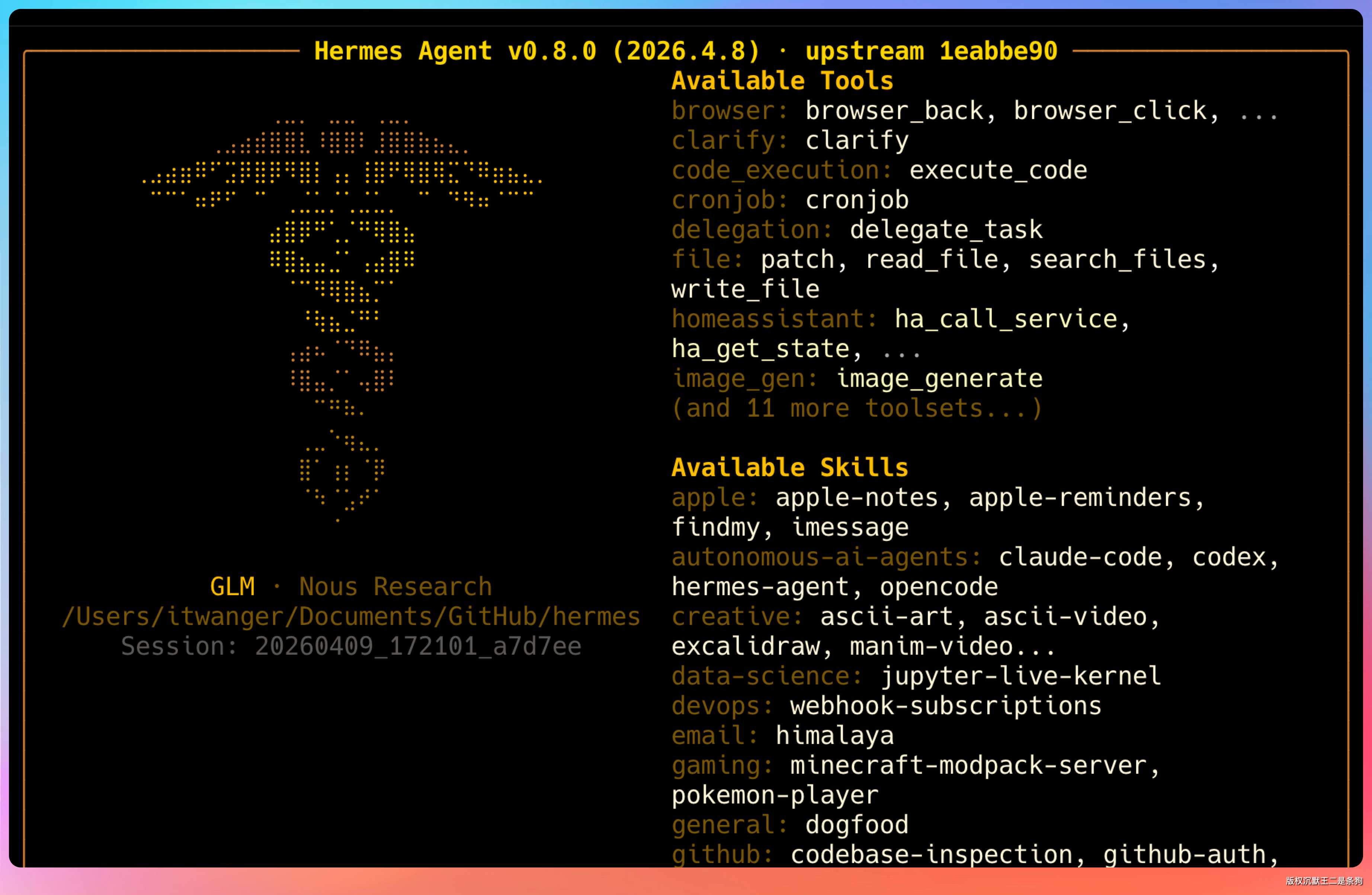
Hermes 的配置文件在 ~/.hermes/ 目录下。

首先是网关类型的选择,一般选 local 就行,跑在本地。如果你有远程服务器的需求,可以选 ssh 或者 docker。
配置文件里加上 API_SERVER_ENABLED=true,就能通过 http://127.0.0.1:8642/health 查看服务状态,调试的时候特别方便。
模型配置这里,我用的是 GLM,在配置文件里改好 API Key 就行。
但这里有个坑我上次就踩过:API Key 过期的话 Hermes 报错信息不够明确。
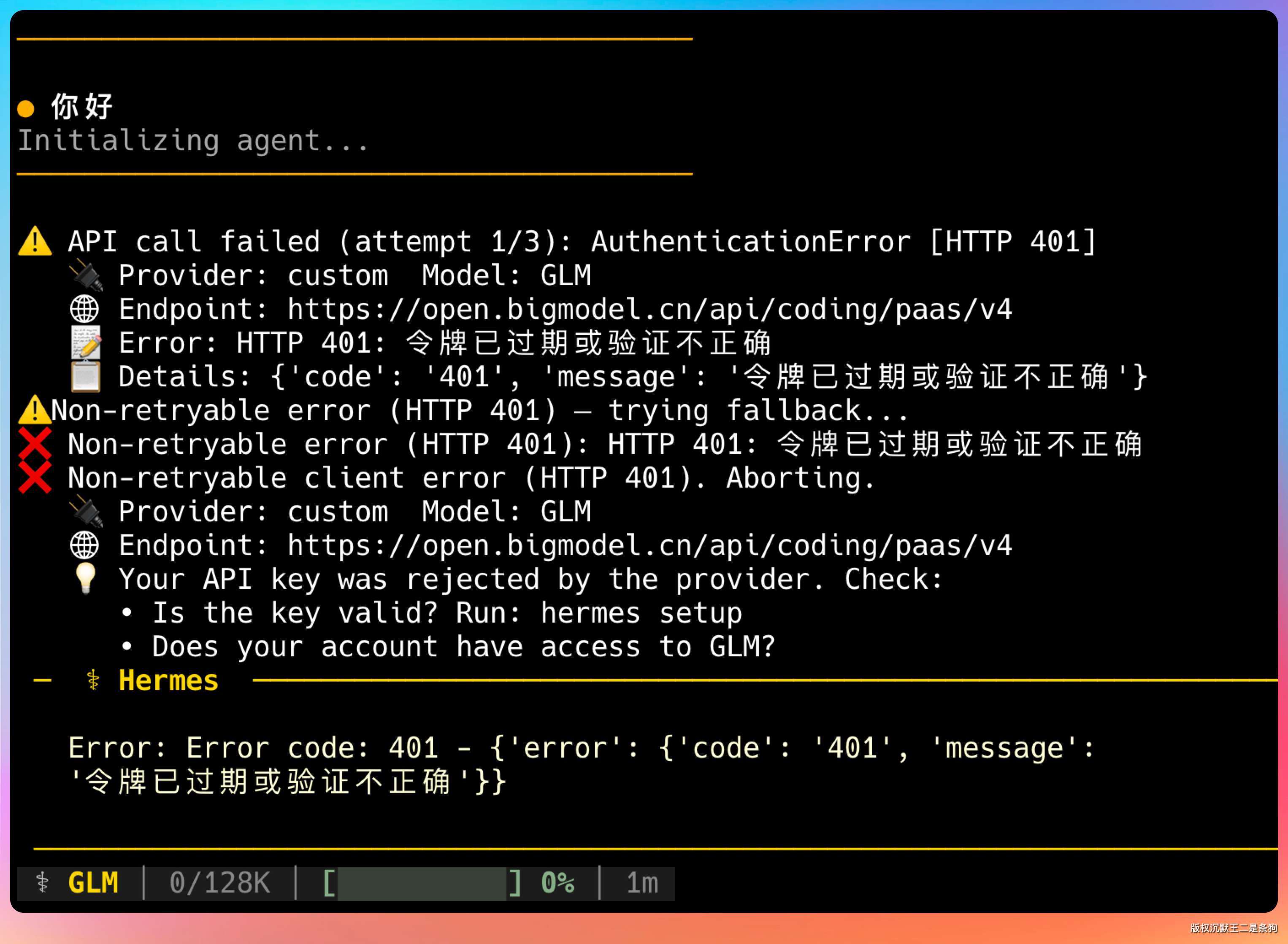
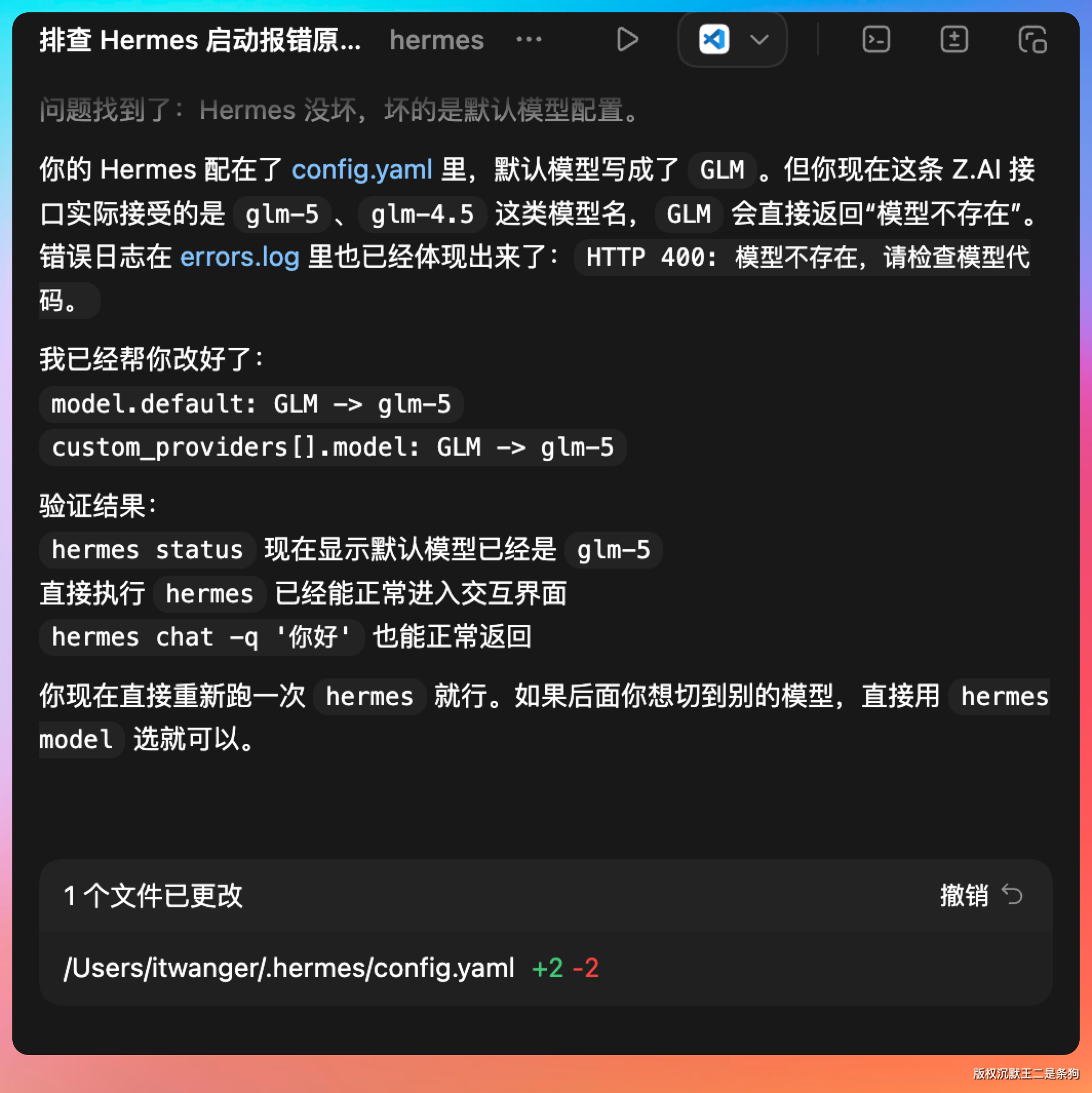
当时折腾了好一会儿,最后把问题丢给了 Codex 才搞定的。
重新执行 hermes 进入主界面,随便发条消息测试一下,有回复就说明 OK。
Hermes 的记忆分两层,搞明白这个对 AI Agent 岗位的求职很重要。
内置记忆是默认开启的。就两个文件:MEMORY.md 存你的环境信息、项目经验、工具使用记录,USER.md 存你的个人偏好和沟通习惯。
每次开新会话的时候,这两个文件会被注入到系统提示词里。
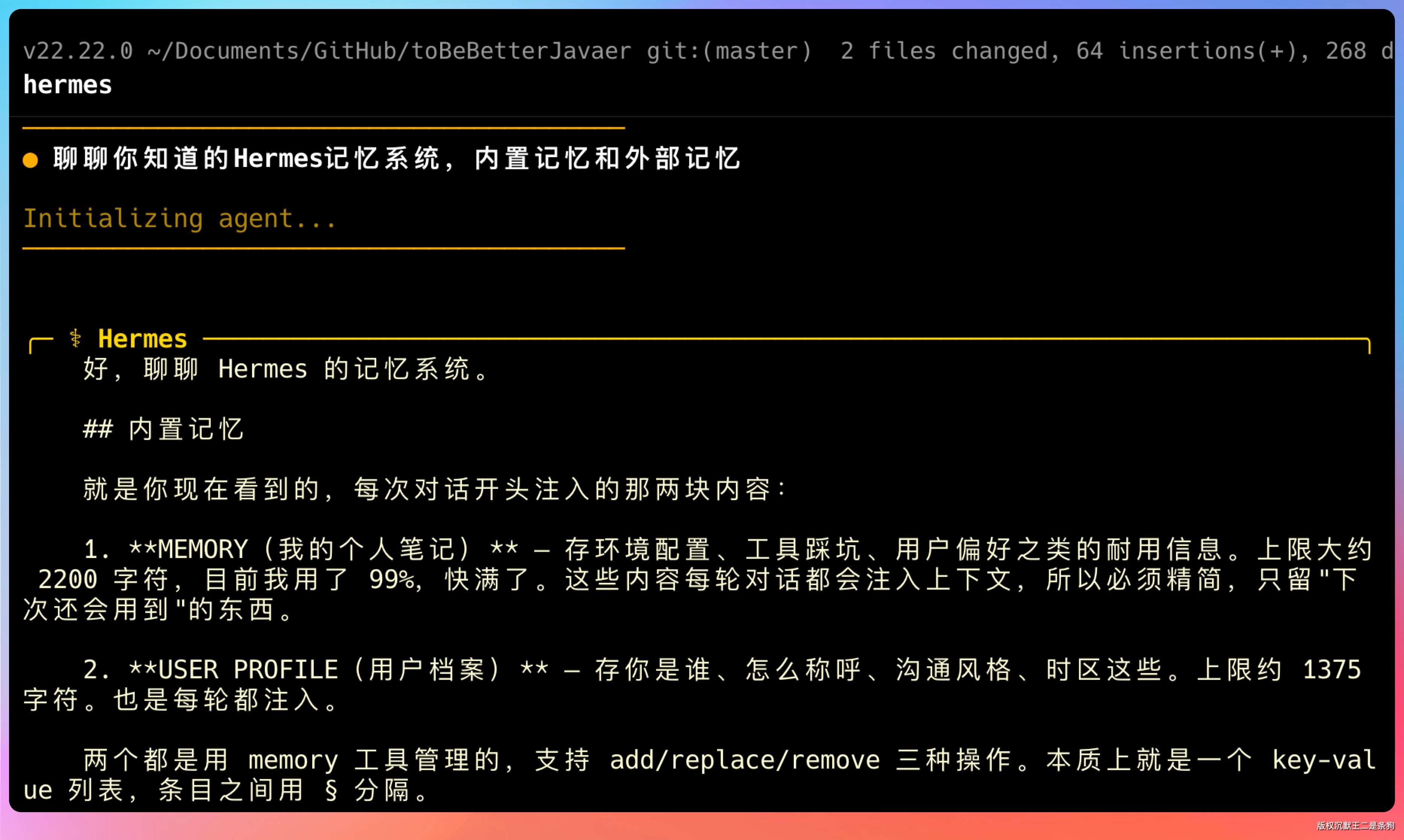
这个设计跟 Claude Code 的 CLAUDE.md 很像,但 Hermes 是自动维护的,你不用手动去编辑。
用着用着它就越来越了解你了。
外部记忆是可选的增强层,同一时间只能启用一个 provider。支持 honcho、mem0、hindsight 这些,可以理解为给 Hermes 接了一个外挂记忆库。
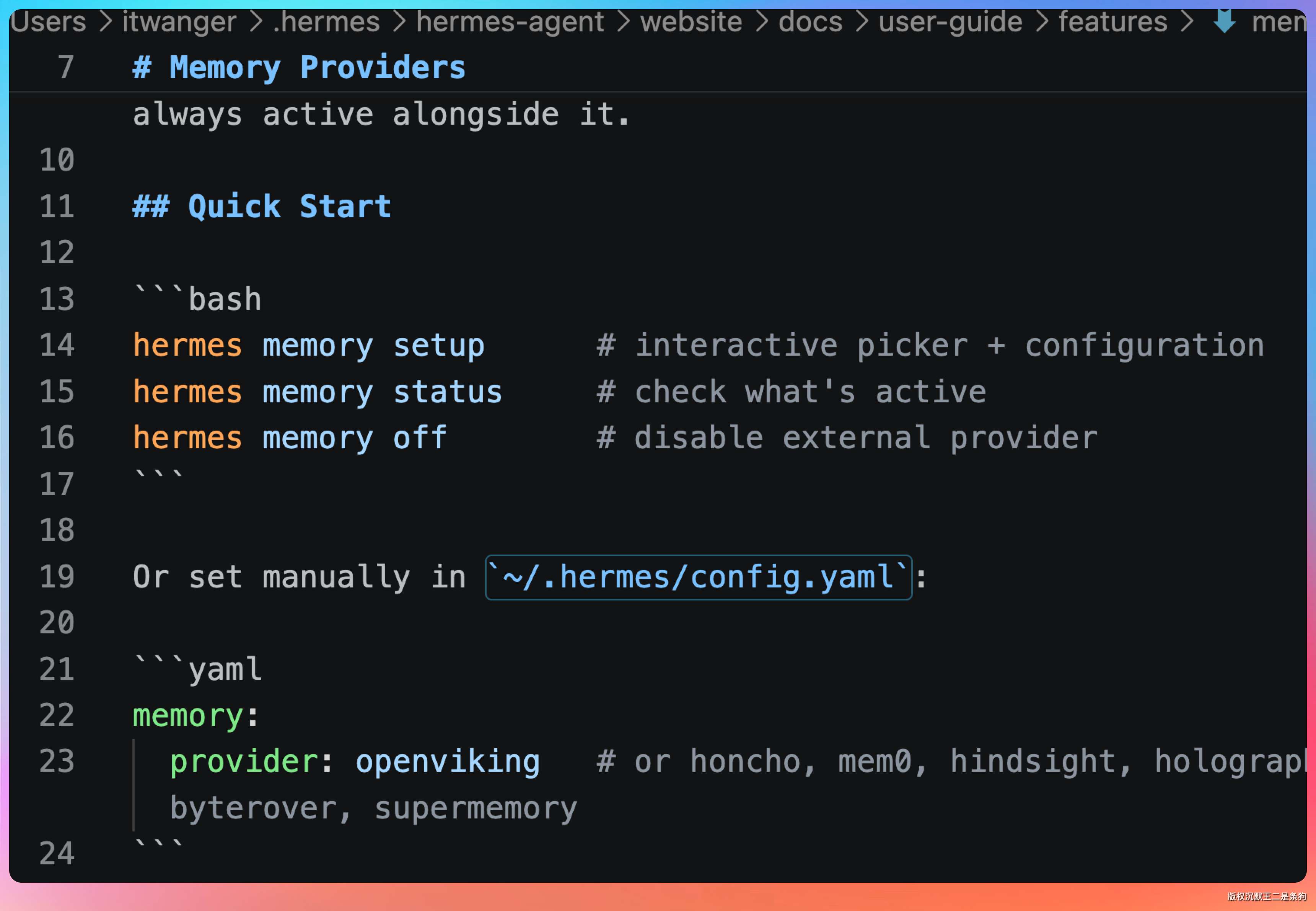
大部分场景下,内置记忆就够用了。
除非你有跨多个项目、跨多台机器的记忆共享需求,否则别折腾外部记忆,配置复杂收益不大。
飞书接入我上次已经写过详细教程了,这次就捡重点说,主要补充一些上次没提到的坑。
先确认 Gateway 是开着的:
hermes gateway status 
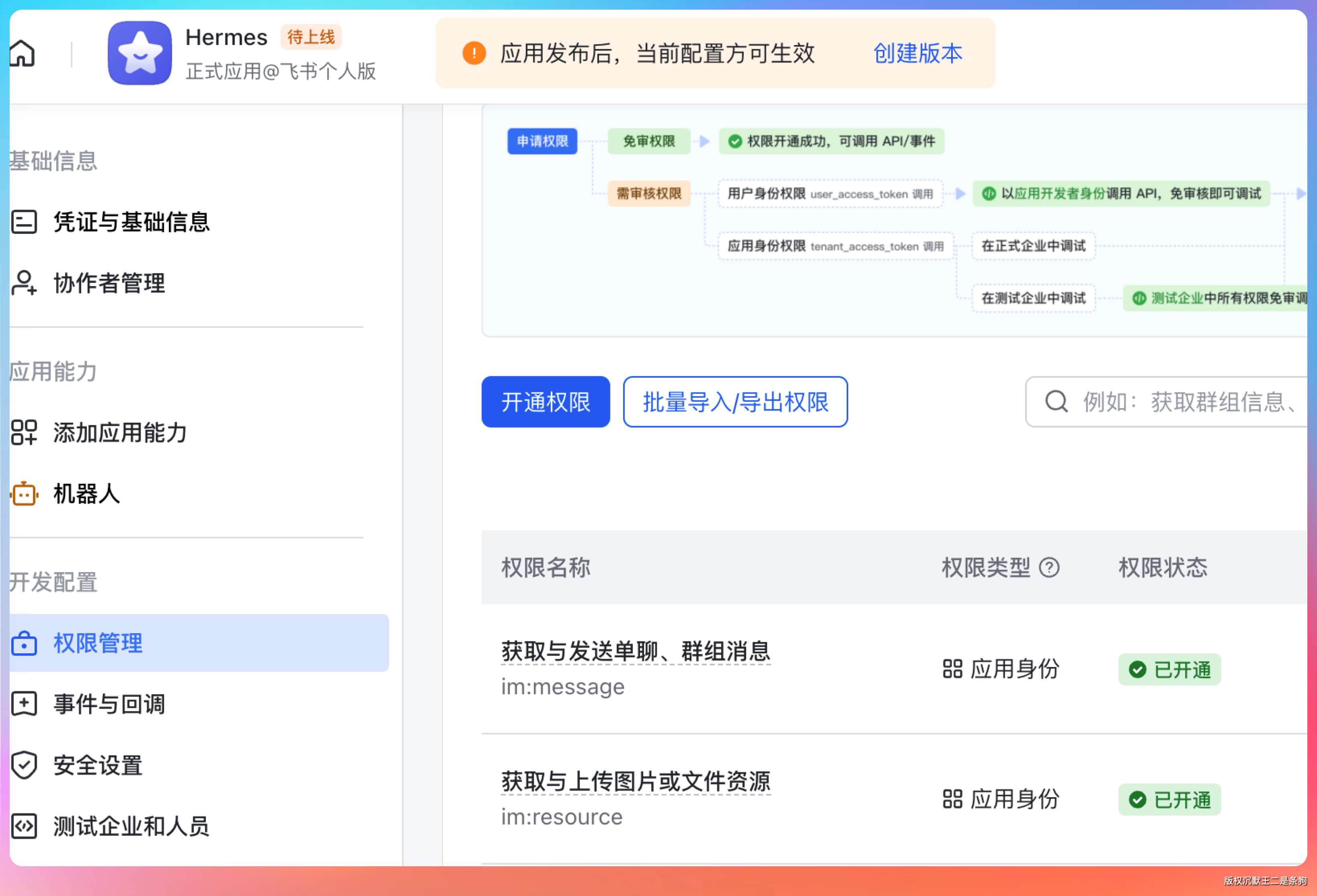
去飞书开放平台创建应用,添加机器人能力。权限至少加上 im:message 和 im:resource。
在 .env 文件里配置飞书应用的 ID 和 Secret:
FEISHU_APP_ID=cli_xxx FEISHU_APP_SECRET=secret_xxx FEISHU_DOMAIN=feishu FEISHU_CONNECTION_MODE=websocket 重启 Gateway:
hermes gateway restart 
在飞书控制台验证连接状态。
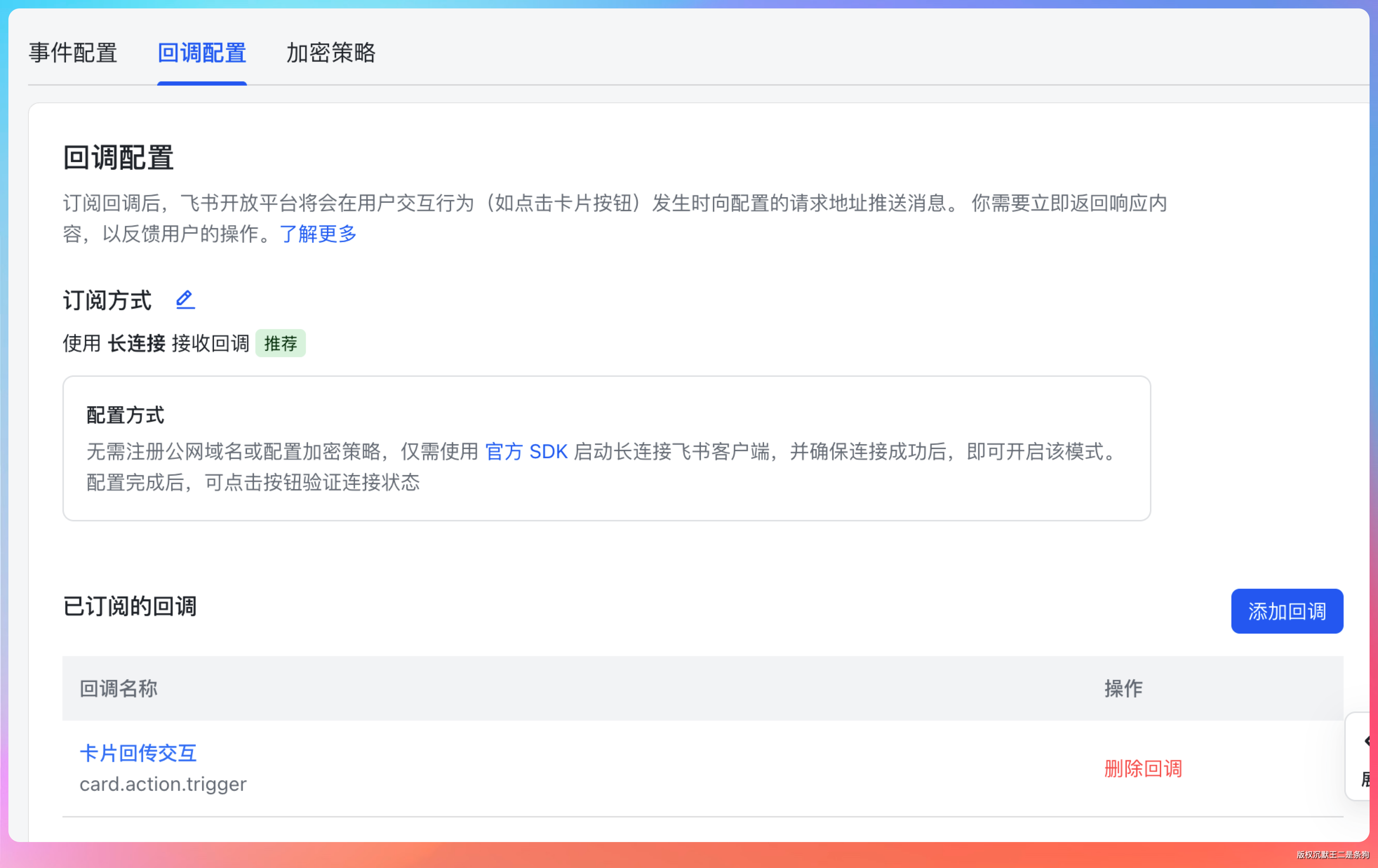
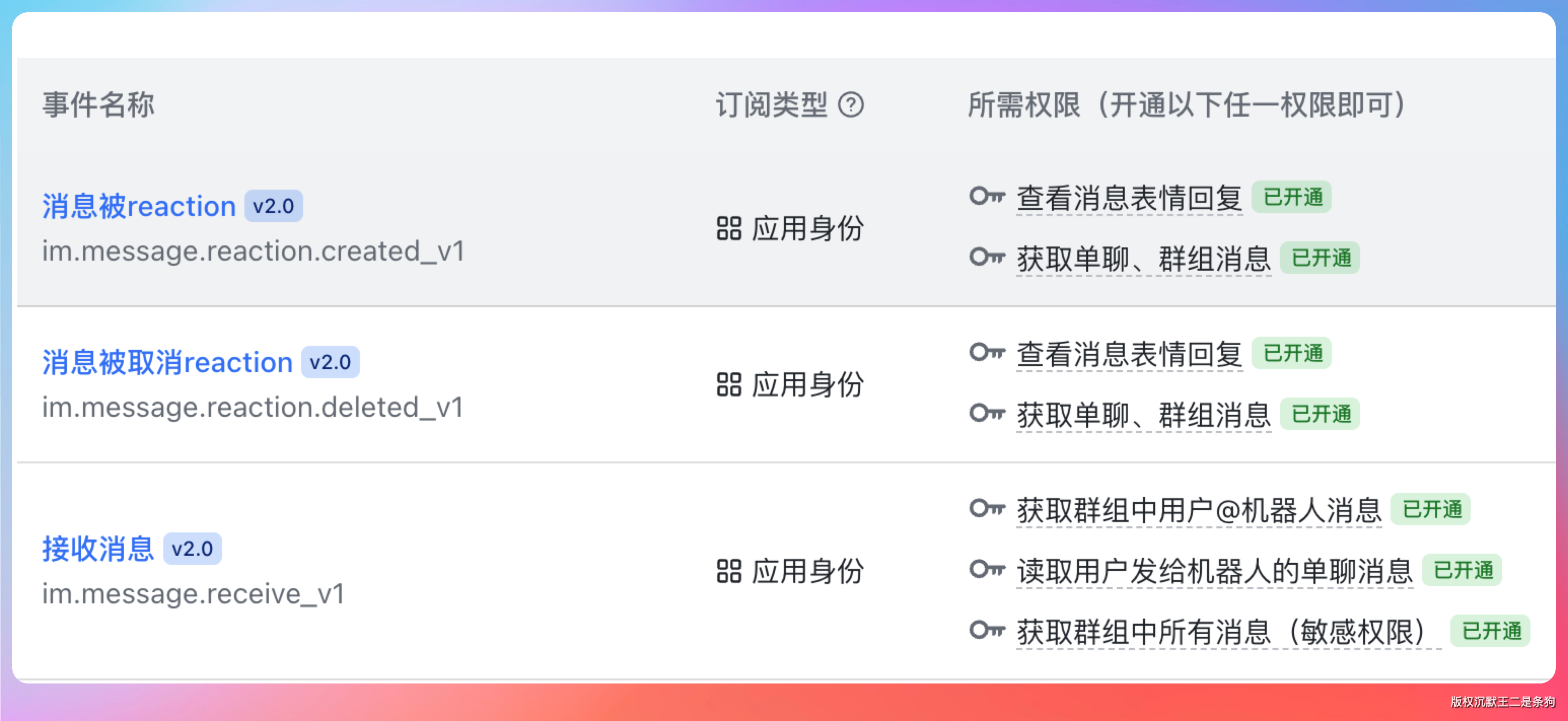
事件订阅里开通 im.message.receive_v1,回调配置开通 card.action.trigger。
上次踩过的两个坑再提一嘴:第一,.env 里要加 GATEWAY_ALLOW_ALL_USERS=true,否则机器人收到消息不会响应。第二,飞书权限里“读取用户发给机器人的单聊消息”这个选项一定要勾上,不然就是上次我遇到的“发了消息没回音”的情况。
开通之后就正常了。
v0.9.0 新增了 WeChat 和企业微信的支持,现在也可以接入了,后续我再给大家分享。
说了这么多,该看看实际效果了。
上次我用 Hermes 回复知识星球的球友提问,效果还不错,但当时上下文压缩的问题很烦人。
这次 v0.9.0 重点优化了压缩,咱们就专门挑一个需要比较长上下文的球友问题来测试。
首先,确保 Hermes 装了 web-access 这个 Skill,让它能联网。
提示词:https://github.com/eze-is/web-access 这个 Skills 会让你拥有联网能力。
安装过程很快,基本秒装。
然后我让 Hermes 去知识星球回复球友提问:
去知识星球:https://wx.zsxq.com/group/412 【球友提问】标签下的【关于 agent 开发】的帖子回复一条内容。
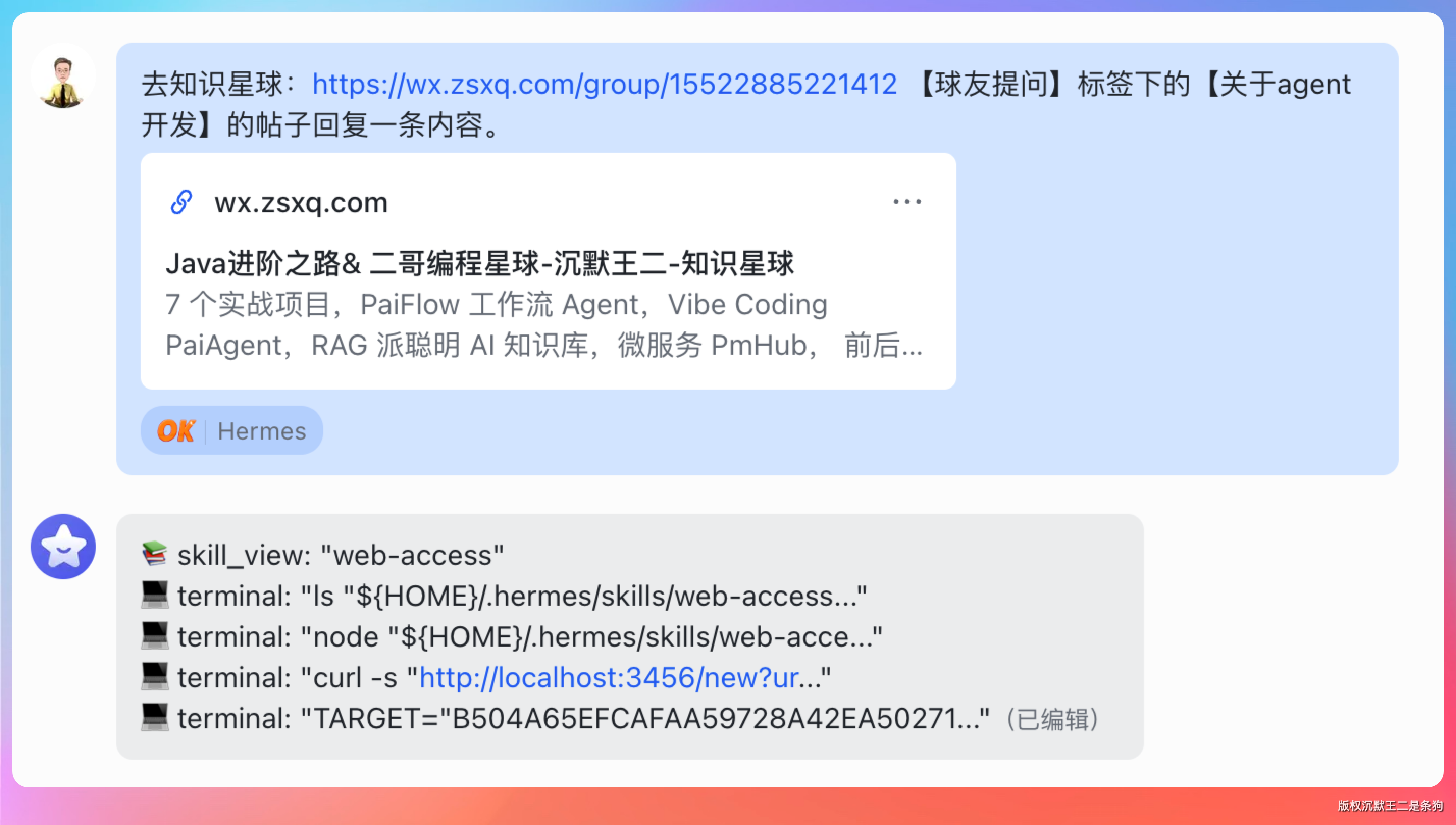
回复质量确实可以。
做 Agent 应用开发,Transformer 和 LoRA 不需要深入学。
你已经学了 RAG、LangChain、Spring AI、LangGraph4j,这些才是 Agent 开发的核心能力。面试中问到模型底层,大多是考你的知识面,不是让你手推公式。了解一下注意力机制、Token 化、微调的基本概念就够用了,不用死磕算法细节。
建议的学习优先级:
- 先把 RAG 的检索优化(混合检索、重排序、分块策略)做扎实
- Agent 编排(多工具调用、工作流设计、错误处理)
- Prompt Engineering(结构化提示词、Few-shot、CoT)
- 模型底层概念了解(知道 Transformer、LoRA、量化是干嘛的就行)
方向别跑偏了。Agent 开发岗看重的是工程落地能力,不是论文推导能力。把派聪明和 PaiFlow 这两个项目吃透,比啃 Transformer 论文有用得多。

这次确实没再出现上下文压缩的问题。
但新的问题来了,一直在 terminal: "TARGET="B5 不知道到底在干嘛。
OpenClaw 的优势在于生态成熟,毕竟已经火了俩月了。
Hermes 的优势在于自主进化能力和上下文管理。它会把你的操作习惯、常用流程沉淀成 Skill,越用越顺手。
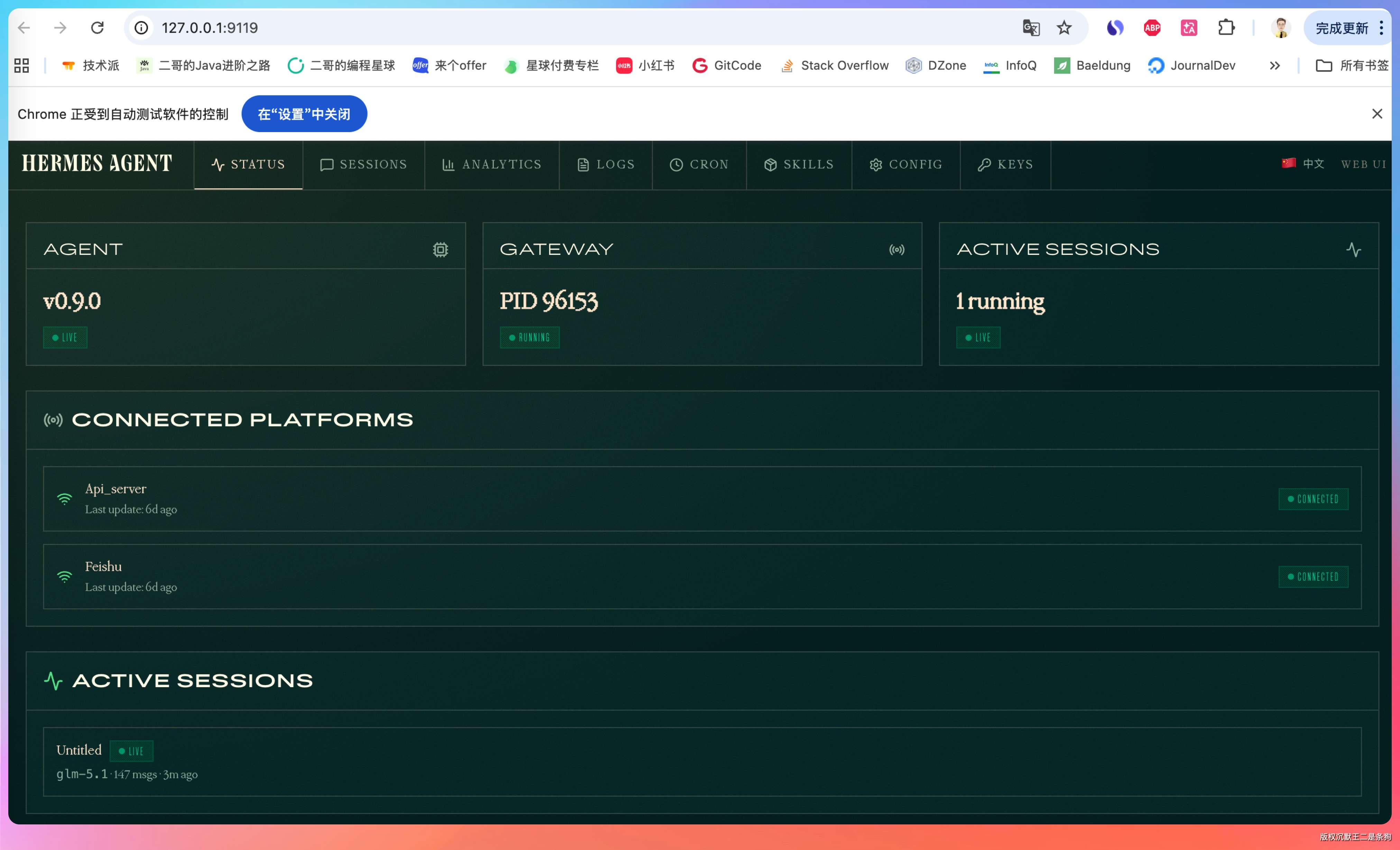
新版的 Hermes 新增了本地 Web Dashboard。现在可以在浏览器里管理 Hermes 的配置了,不用每次都去命令行改文件。对于不太熟悉终端操作的小伙伴来说,这个功能算是降低了使用门槛。
可以在 Codex 或者 Claude Code 中执行 hermes dashboard 安装。
上下文压缩这个问题可以说困扰着整个 Agent 生态,不止是 Hermes。
本质上,这是大模型有限上下文窗口和用户无限对话需求之间的矛盾。Hermes 的四阶段压缩不算完美,加需要继续进化。
【工具不完美没关系,关键是它在变好,而且变好的速度够快。】
有问题评论区见,我看到都会回的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/268660.html