

UPenn联合马里兰、布朗大学等团队提出的Graph of Skills,正是为了解决这个问题。 它的关键不只是让Agent “会组合Skill”,而是先把海量Skill库组织成一张技能图,再让Agent从中找出一套规模足够小、依赖足够全、可以直接执行的Skill组合。

项目地址:https://github.com/davidliuk/graph-of-skills
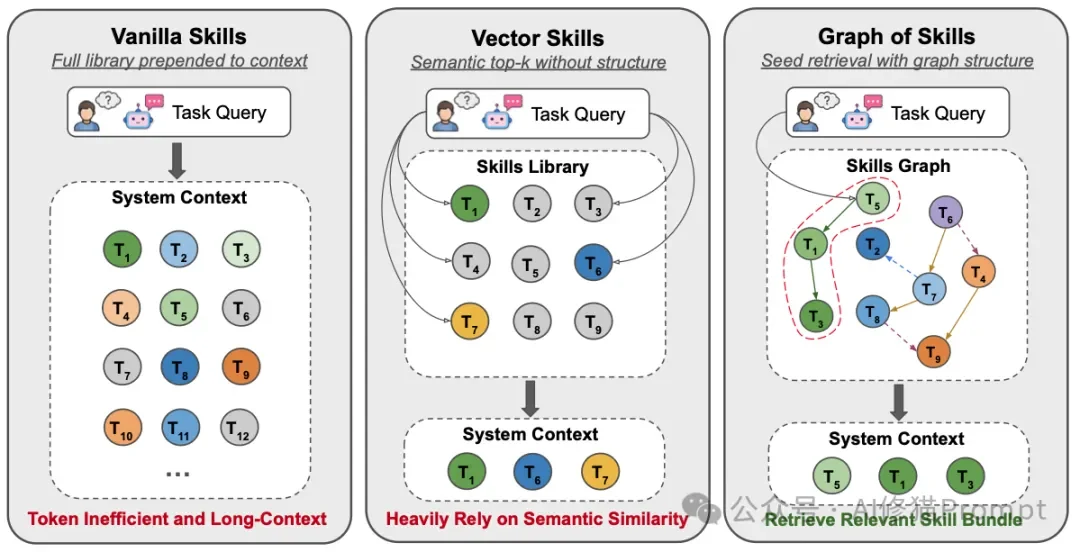
全局加载基线(Vanilla Skills)
- 工作机制:将整个技能库的说明文本全部提取出来,直接硬塞进大语言模型的上下文窗口中。
- 规模诅咒:在工具数量极少时,这种方法可行。但当库规模扩大后,Token成本会呈线性爆炸式增长。
- 注意力稀释:将数千个工具放入上下文中,会导致模型严重的信息过载。模型极易产生幻觉,并忽略掉隐藏在长文本中的关键领域约束条件。
向量检索(Vector Skills)
- 工作机制:利用嵌入模型(Embedding Model),检索出与您输入的任务查询在“语义上最相似”的前K个技能。
- 致命缺陷(先决条件鸿沟):语义上的极度相似,完全不等于执行上的完备性。
- 工程现实脱节:在绝大多数工程任务中,与用户查询语义最匹配的,往往是顶层的高级求解器。但是,要让这个求解器成功运行,还需要底层的解析器、格式转换器、环境设置工具或领域特定的预处理器。
- 检索断链:这些底层依赖项在功能上不可或缺,但在文本语义上与用户的初始查询关联极弱。向量检索往往会遗漏这些底层工具,导致最终检索出的技能组合根本无法执行。
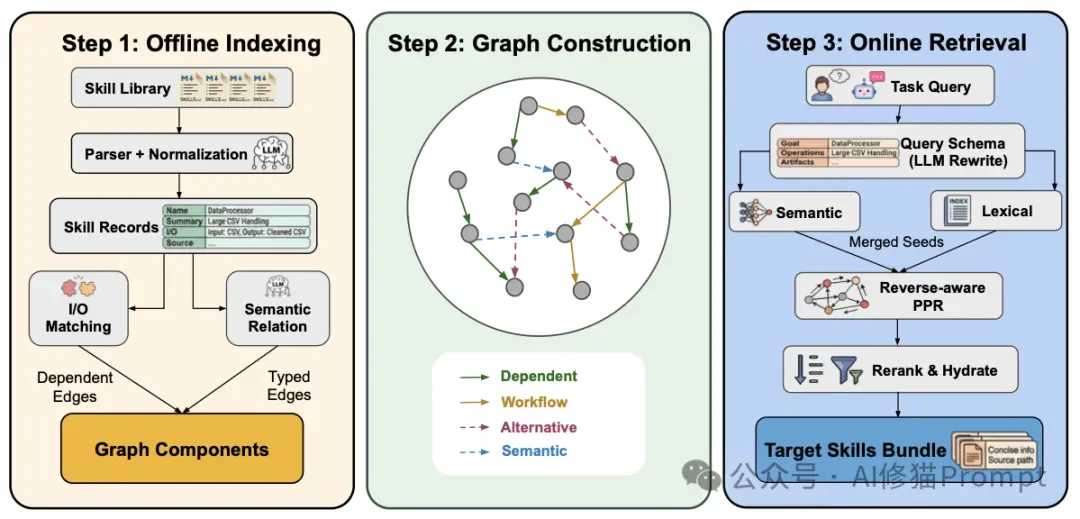
第一阶段:离线图谱构建
- 确定性解析:系统首先会确定性地解析技能包。通过读取YAML前置元数据和Markdown文档,提取出规范名称、功能摘要、输入输出(I/O)字段、领域标签、使用工具、脚本入口以及稳定的本地源码路径。
- 受限的LLM补全:当某些技能的文档极其残缺时,系统会调用轻量级的大语言模型进行辅助。
- 严格边界:研究者对LLM的使用施加了极严的限制。LLM仅被允许用于补全节点内部的语义字段(如能力描述、缺失的I/O),绝对不允许它凭空捏造图谱中的连边关系。这种“受限语义补全”保证了节点的质量,同时杜绝了幻觉连边。
- 依赖边(Dependency edges):这是图谱的绝对核心。系统通过严格的输入输出(I/O)兼容性检查来确定有向边。如果技能A产生的输出,刚好是技能B要求的输入,系统就会在两者间建立依赖边。这代表了不可逾越的执行先决条件。
- 工作流边(Workflow):捕获常见的多步流水线执行顺序。
- 语义边(Semantic):连接极其相似或主题相邻的备用技能。
- 替代边(Alternative):连接用于解决同一个子问题的不同实现方案。
- 稀疏验证机制:为了防止计算量失控,对于后三种非依赖边,系统不会进行全局的两两对比。而是先通过词法和语义相似度框定一个小范围的候选池,随后在候选池内进行关系验证,确保图谱保持稀疏且精准。
第二阶段:在线结构化检索

第一步:混合种子检索 (Hybrid Seeding)

第二步:逆向感知的图谱扩散 (Reverse-Aware Typed Diffusion)

第三步:预算约束下的重排序与填充 (Budgeted Reranking and Hydration)
测试环境与模型基准
- SkillsBench基准:包含1000个真实的复杂技术任务,横跨宏观经济去趋势化、电网可行性分析、3D扫描分析、地震相位拾取等11个专业领域。
- ALFWorld基准:一个交互式的具身模拟器测试环境。智能体需要通过文本指令,在虚拟家庭环境中完成导航、寻找物体和物理交互等多步家务活动(共140个完整序列)。
- 模型阵容:实验横跨了三个不同家族的大型语言模型,包括Claude Sonnet 4.5、MiniMax M2.7以及GPT-5.2 Codex。
核心性能对比
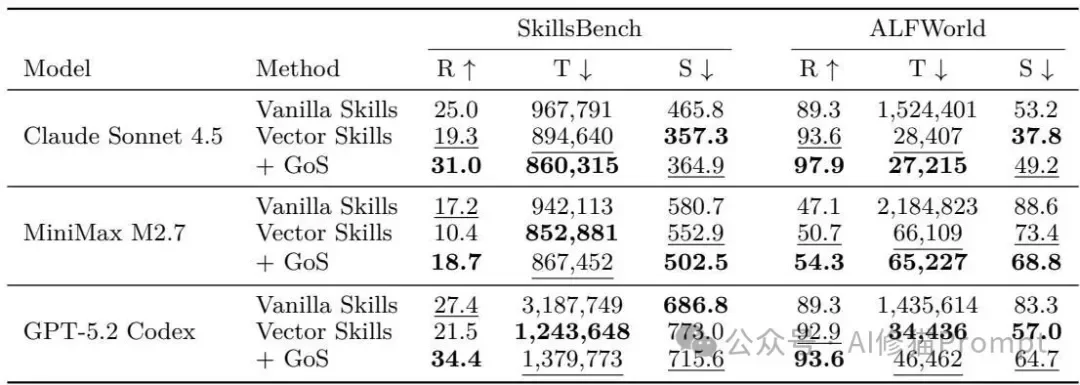
- 全面超越全局加载(Vanilla):在所有的测试区块中,GoS取得了最高的平均任务奖励(即成功率)。与简单粗暴的全局加载相比,GoS在平均奖励提升43.6% 的同时,将模型摄入的输入Token数量大幅减少了37.8%。
- 碾压向量检索(Vector):在维持极低Token消耗的前提下,GoS的任务成功率远超向量检索。在SkillsBench测试中,GoS比向量基线高出10.97分;在ALFWorld测试中,高出2.87分。
- 效率与表现的**平衡:全局加载虽然找得到技能,但成本失控且容易导致模型迷失;向量检索虽然省钱,但找出的技能组合残缺不全无法执行。GoS成为了在Token效率、运行时间和任务成功率之间的**平衡点。
- 具体模型数据:在ALFWorld测试中,使用Claude Sonnet 4.5,Vanilla的成功率为89.3%,消耗了1,524,401个Token;Vector向量检索成功率为93.6%,消耗28,407 Tokens;而 GoS达到了97.9% 的惊人成功率,仅消耗27,215 Tokens。
应对技能库规模膨胀
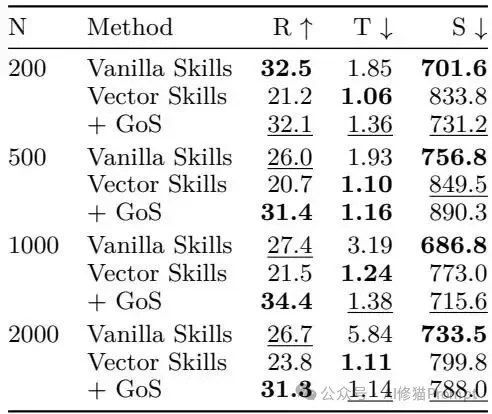
- Token成本失控:当库规模从500扩展到2000时,全局加载基线(Vanilla)的输入Token消耗从193万激增到584万(接近3倍)。
- GoS的超强抗压性:在相同的扩张规模下,GoS的Token消耗死死稳定在114万到138万之间。
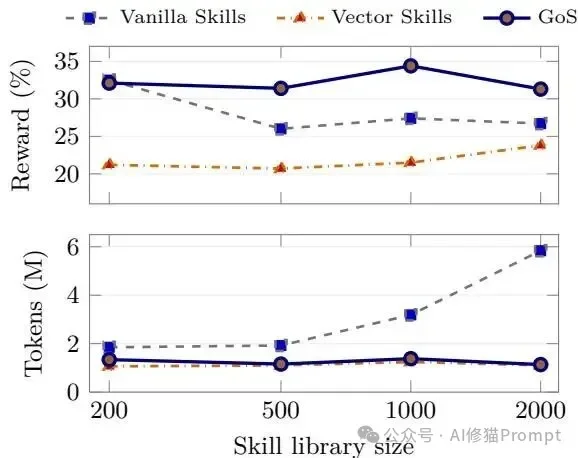
论文在200到2000个技能规模上比较三种方法。结果显示,随着技能库变大,GoS依然保持更强的奖励表现,同时显著抑制了输入Token的增长速度。
- 规模越大,优势越显:在200个技能的小型库中,全局加载还能勉强维持微弱优势。但只要技能库规模达到中等(500及以上),GoS的任务成功率便全面且持续地超越其他两种基线。
核心组件缺失测试
- 移除图谱传播机制:系统退化为无法沿着结构关系寻找先决条件的单纯检索器。结果显示,Token消耗虽然降低了,但平均任务奖励从34.4暴跌至29.3(下降5.1分)。
- 进一步移除词法重排与检索:强制系统仅依赖单一的语义检索器进行初步筛选。任务奖励进一步崩塌至26.7(下降7.7分)。
- 数据结论:混合语义与词法检索提供了高质量的“初始切入点”,而图谱传播机制则负责将这些切入点转化为“逻辑完备的执行链条”。两者缺一不可。

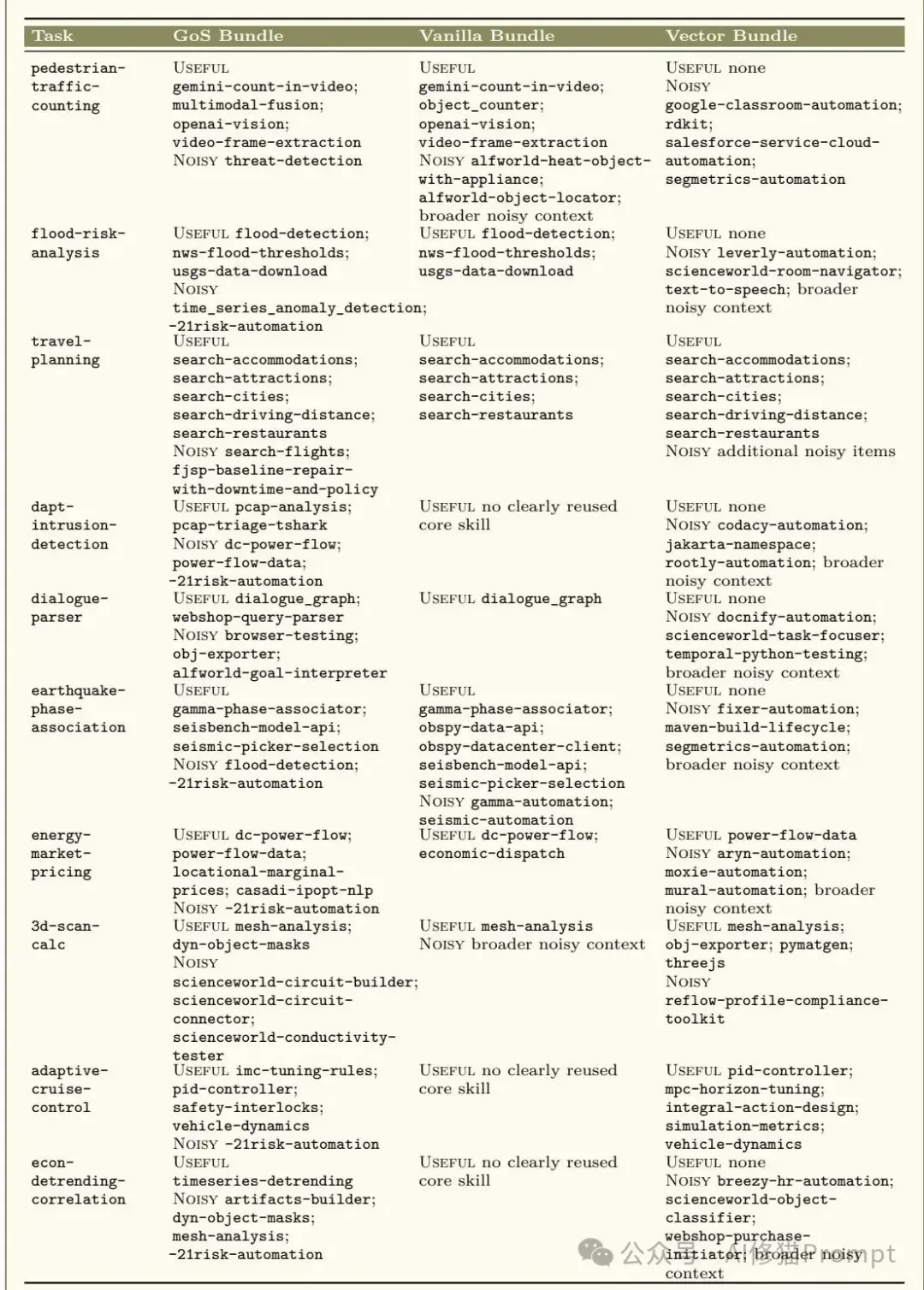

这是 pedestrian-traffic-counting 的原文分析截图。研究者把GoS、Vanilla与Vector三种条件下的技能暴露方式并列对照,强调GoS的优势在于更早给出紧凑可执行的视觉流水线。
- 案例对比:向量检索彻底迷失,抓取了一堆不相关的自动化脚本。GoS凭借图谱关系,精准打包了核心的
pcap-analysis工具及其配套的分流助手。只要关键分析包没有被遗漏,后续任务便迎刃而解。


这是 dapt-intrusion-detection 案例的截图。论文把它作为典型的GoS正向案例,用来说明一旦检索链里出现 pcap-analysis 及相邻助手,任务性质就会从“从零摸索”转成“按现成工具复用”。
- 反思案例:地震相位关联(超长依赖任务)

earthquake-phase-association 是论文专门保留的反例。研究者借此说明结构化检索不是自动成功,若恢复出的局部邻域仍然缺关键依赖,GoS依然可能输给信息更全但更嘈杂的全量加载。
- 深度绑定离线图谱质量:如果初始技能库的代码文档极其混乱,I/O模式完全不清晰,或者缺失执行元数据,离线阶段建立的边质量就会大幅下降,这将直接摧毁后续的所有检索流程。
- 图谱结构的静态滞后:目前的图谱系统主要依靠离线构建,是静态的。系统尚未具备“吃一堑长一智”的能力,无法根据智能体在线执行的成功轨迹、验证器的报错记录或用户的直接反馈,去实时动态更新图中的连边权重。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/268600.html