
Anthropic 昨天发了 Opus 4.7。

我刷到的第一条评论是:”编码又提升了!”
第二条:”打败 GPT-5.4 了!”
第三条还是编码。
我理解,编码是大家最直接能感受到的东西。但我觉得这次真正值得聊的,不是编码——是视觉。
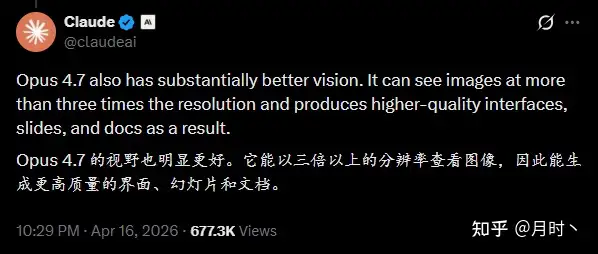
Anthropic 官方对 Opus 4.7 的定位里,专门提到了”high-resolution vision”——高分辨率视觉。
这不是随便说说的。

具体数字:图像处理分辨率提升了 3 倍,最高支持长边 2,576 像素(约 3.75 MP)。
以前你发高清图给 Claude,它会自动压缩,细节丢失,表格里的小字经常读错,截图里的代码经常看不清。现在分辨率上来了,这些问题理论上都能改善。
更高的分辨率直接带动了输出质量的连锁提升:生成界面、制作幻灯片、排版文档,细节精度也全面提升。
多个第三方评测也提到视觉能力有”质的提升”——从”将就能用”变成”可以依赖”。但具体的量化数字,我没有在 Anthropic 官方公告里找到,所以这里就不引用。
这中间的差距,你自己试一下就知道了。
就好像你有个助理,以前让他看文件,细节经常出错,你还得自己复核。现在他能看清楚了,你可以直接把文件扔给他。
这两种关系,完全不一样。
好,编码也说一下,毕竟大家最关心这个。

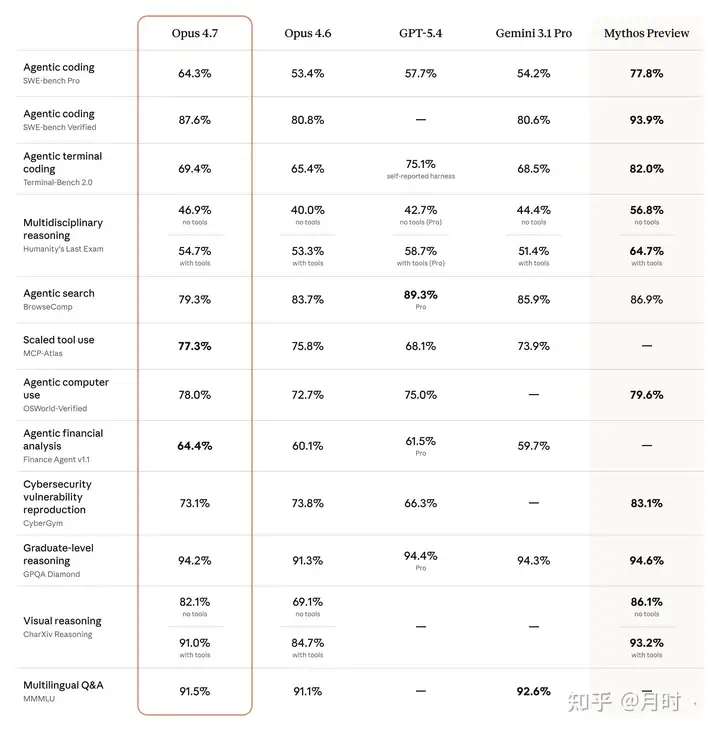
SWE-bench Verified:Opus 4.7 87.6% ,Opus 4.6 是 80.8% ,Gemini 3.1 Pro 是 80.6%,不过这里的编码能力还是比不上那个危险模型“Mythos”哈哈
这个基准测试的是真实 GitHub bug 的修复能力,87.6% 意味着它能独立解决接近 90% 的真实代码问题
SWE-bench Pro:64.3% 。这个更难,是更接近生产环境的测试。Opus 4.6 是 53.4%,GPT-5.4 是 57.7%,Gemini 3.1 Pro 是 54.2%。Opus 4.7 在这个榜上排第一。

CursorBench:70% ,比 Opus 4.6 的 58% 提升了 12 个百分点。
内部编码基准整体提升:13%。生产环境任务解决能力:提升 3 倍。
这些数字都很好。但我要说一句可能不受欢迎的话:
SWE-bench 是可以针对性训练的。
这不是说 Anthropic 在作弊,而是说,基准测试的提升和你实际用起来的感受,不一定是 1:1 的关系。真正有意义的数字,是”生产环境任务解决能力提升 3 倍”——这个更接近真实场景。
第一个:/ultrareview 命令
这个我觉得是 Opus 4.7 里最有意思的新东西,但报道最少。
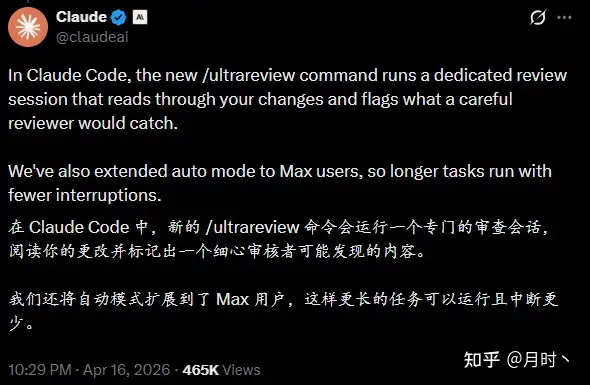
/ultrareview 是 Claude Code 新增的命令。你在代码合并前运行它,它会在云端启动一批审查 Agent 并行扫描你的代码,找 bug。每个发现都会被独立复现和验证,不是随便报一个就算。
Pro 和 Max 用户各有 3 次免费运行。
以前代码审查要么靠自己,要么靠同事,要么靠 CI 跑测试。现在多了一个选项:让一群 AI 在合并前帮你扫一遍。
这个工作流变化,比任何基准测试数字都更直接。
第二个:xhigh 努力级别。
Opus 4.7 引入了新的自适应思考(Adaptive Thinking)机制,在原有的 low/medium/high/max 之间,加了一个 xhigh 级别,位于 high 和 max 之间。
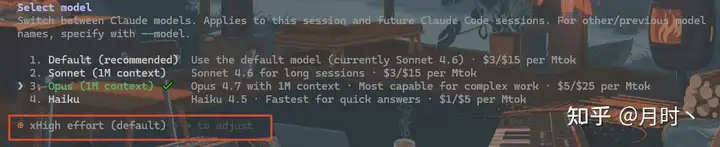
Claude Code 默认就用 xhigh。
这意味着什么?你可以更精细地控制模型的推理深度和响应速度之间的权衡。以前只能选”快一点”或”慢一点”,现在多了一个档位。
第三个:自动化网络安全防护。
这个有点意思。Anthropic 在训练 Opus 4.7 的时候,故意削弱了它的攻击性网络安全能力,同时加入了自动检测机制,会自动阻止高风险的网络安全请求。
它会拒绝帮你做某些事情,即使你问得很委婉。
这是 Anthropic 一贯的风格:安全优先。有人觉得烦,有人觉得这才是负责任的做法。
我不评价,但你用的时候要知道这个限制在。
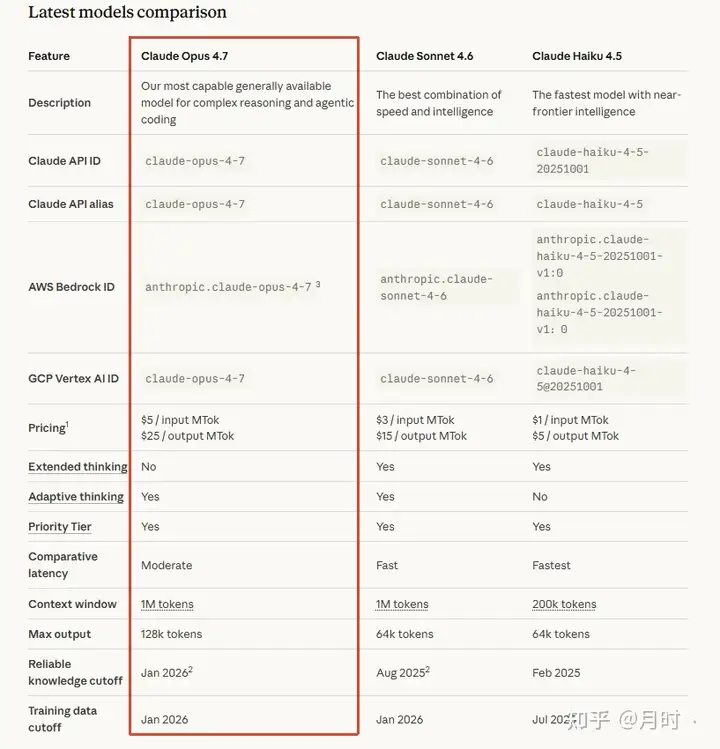
输入: \(5 / 百万 tokens 。
输出: \)25 / 百万 tokens 。
和 Opus 4.6 一模一样。
上下文窗口:100 万 tokens。最大输出:128k tokens。这些也没变。
能力大幅提升,价格纹丝不动。
这个决定背后是什么逻辑,我猜了两种可能:一是训练成本在下降,他们有空间维持价格;二是在打市场份额,不让开发者跑去用 GPT-5.4。
不管哪种,结果对用户来说都一样:同样的钱,现在能买到更强的模型。
说了这么多,怎么用?分三种情况:
普通用户(Claude.ai 网页版)
直接去 claude.ai,登录账号,在模型选择里找 Claude Opus 4.7。
免费用户目前只能用 Claude Haiku,要用 Opus 4.7 需要订阅 Claude Pro( \(20/月)或 Claude Max(\)100/月)
如果你不知道怎么升级的话,可以前往👇
https://gptclaude.top/
开发者(API)
模型 ID:claude-opus-4-7-(具体以 Anthropic 官方文档为准)
调用方式和之前一样,直接替换 model 参数即可。支持 Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 三个云平台,不想直接调 Anthropic API 的可以走这些渠道。
Claude Code 用户
如果你在用 Claude Code(VS Code 或 JetBrains 插件),更新到最新版本后,Opus 4.7 会自动成为默认模型,推理级别默认 xhigh。
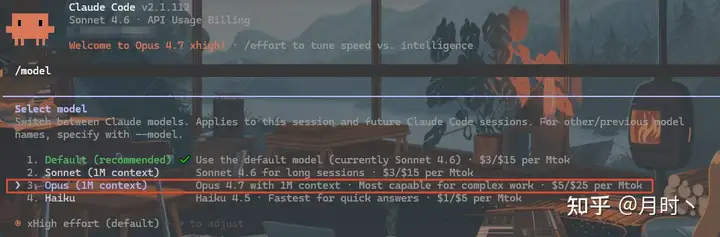
不需要额外配置,更新就行。
如果你只需要用到Claude Code或codex的话,可以看一下往期文章👇
教你在国内用一个套餐同时体验到Claude Code+Codex两大AI编程助手
我觉得 Opus 4.7 最值得期待的,不是它在基准测试上又赢了谁。
是视觉分辨率提升 3 倍之后,那些以前做不了的工作流,现在可以做了。
比如直接把设计稿截图扔给它,让它写前端代码。比如把 PDF 报告截图发给它,让它帮你提炼数据。比如把手写笔记拍照,让它整理成文档。
这些以前都是”能用但不稳”,现在可能真的稳了。
试试看吧。
最后感谢大家能够看到文章的最后,如果你觉得这篇文章对你有启发或者帮助,不妨点个关注,你的支持将是我最大的动力,我们下次见!

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/268466.html