
TL;DR
Anthropic 正式發布 Claude Opus 4.7:XBOW 視覺準確率從 54.5% 飆升至 98.5%、CursorBench 從 58% 升至 70%、Rakuten 生產任務解決量達前代 3 倍。新增 xhigh effort level,定價維持 / 但 tokenizer 更新導致實際成本可能微增。同時揭露因安全考量受限發布的 Claude Mythos。
這篇文章適合:
- 正在使用 Claude API 的開發者,想知道是否值得升級
- 對 AI 模型能力演進感興趣的科技從業者
- 使用 Claude Code 或 AI Coding 工具的 Vibe Coder
- 評估 AI 工具成本效益的個人用戶與小型團隊
Claude Opus 4.7 是 Anthropic 旗艦語言模型系列的最新版本,於 2026 年 4 月 16 日正式推出,即日起可在 Claude.ai、Anthropic API、Amazon Bedrock、Google Cloud Vertex AI 以及新加入的 Microsoft Foundry 上使用。API model ID 為 claude-opus-4-7。
此次升級帶來三個核心改進:視覺能力提升超過 3 倍、新增 xhigh effort level,以及在軟體工程與 Agentic 任務上的顯著穩定性強化。同時,Anthropic 也透過此次發布進一步揭示了 Claude Mythos Preview 的定位——一個更強大但因安全考量受限發布的模型。
Opus 系列是 Anthropic 性能天花板的指標,每次更新都代表 Claude 整體架構的最高水位。 Opus 4.7 的出現意味著 4.x 世代仍有空間向上突破,Anthropic 在 5.0 之前仍有牌可打。
而且這次不只是數字上的進步——CursorBench 從 58% 跳到 70%、XBOW 視覺準確率從 54.5% 飆到 98.5%、Rakuten-SWE-Bench 的生產任務解決量達到前代的 3 倍。這些不是微調,是跨級提升。
Claude Opus 4.7 是 Claude Opus 4.6 的直接繼任者。 Opus 4.6 於 2026 年 2 月 5 日發布,是當時 Claude 系列中性能最強的旗艦模型,具備 1M token 上下文視窗(Context Window)。
Opus 4.7 強化了五個面向:
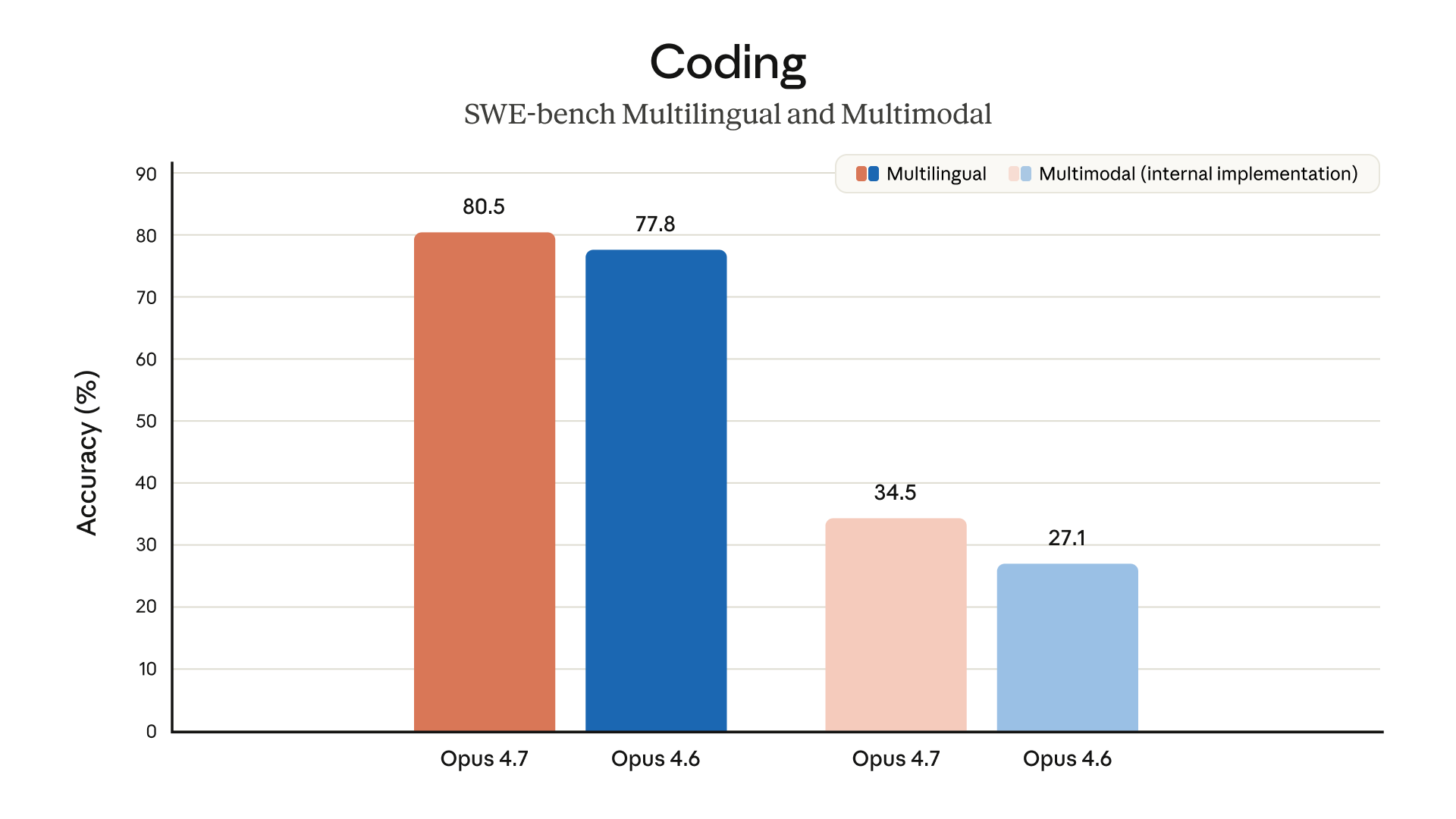
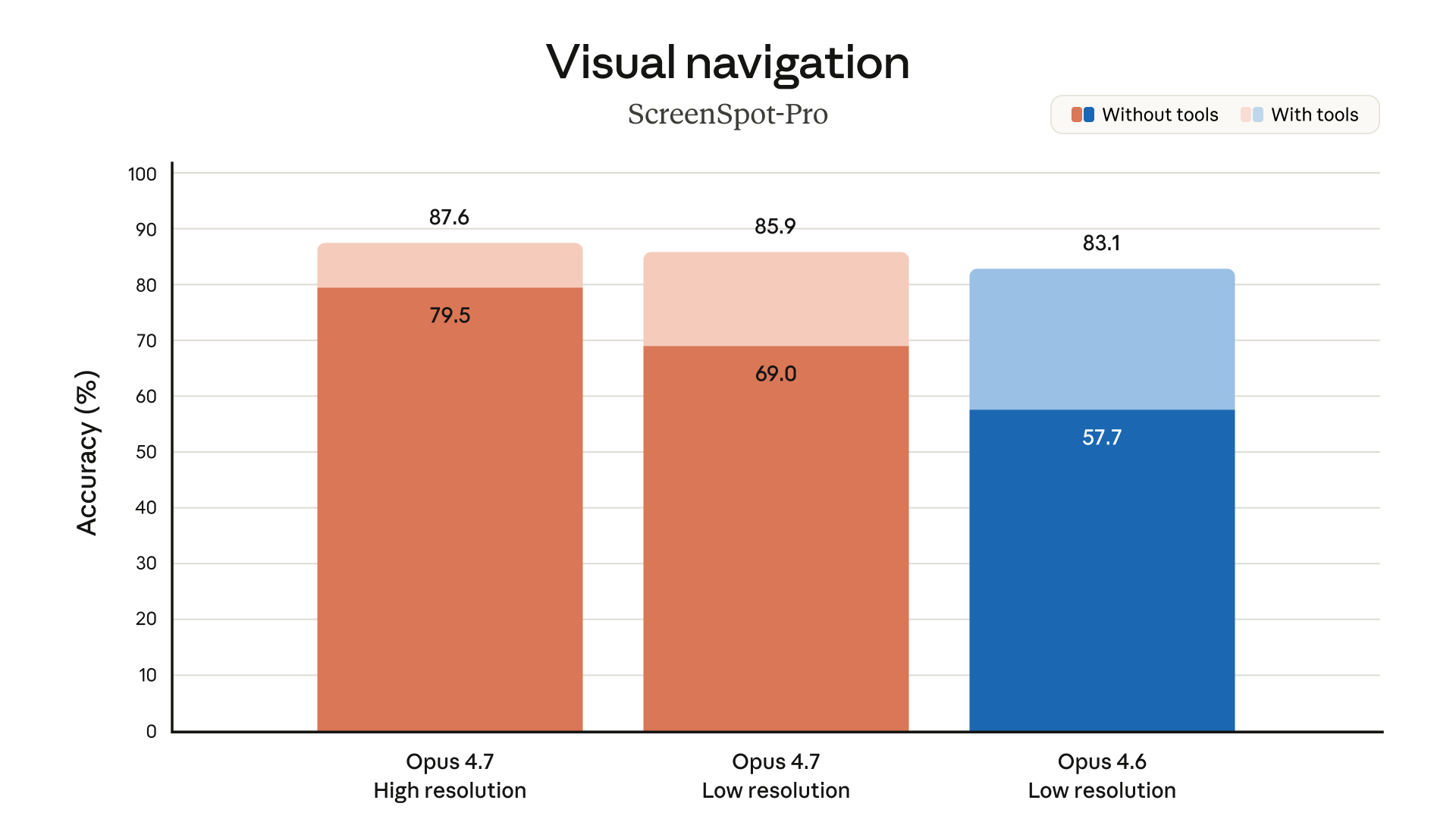
- 視覺能力大幅升級:支援最高 2,576 像素長邊(約 3.75 百萬像素),是前代的 3 倍以上。在 XBOW 視覺準確率基準測試中,從 Opus 4.6 的 54.5% 躍升至 98.5%——化學結構式、技術圖表、UI 截圖的辨識能力有了質的飛躍
- 新增 "xhigh" Effort Level:在既有的 high 與 max 之間,新增 xhigh(extra high)層級。Claude Code 已將所有方案的預設 effort 提升至 xhigh。對於不需要 max 等級推理但 high 又不夠用的場景,這個中間選項能有效平衡延遲與品質
- 軟體工程能力顯著提升:Anthropic 官方描述為「在進階軟體工程上相較 Opus 4.6 有顯著改善」,能更嚴謹地處理複雜、長時間的程式設計任務
- Agentic 任務執行:Notion Agent 複雜多步驟工作流改善 14%,Factory Droids 任務成功率提升 10-15%
- 安全與校準(Alignment):誠實度與抗 prompt injection 能力優於 Opus 4.6,幻覺率降低,對不確定的問題更坦誠地表達「不知道」
Tokenizer 注意事項:Opus 4.7 更新了 tokenizer,相同的輸入文字會對應到 1.0–1.35 倍的 token 數量(取決於內容類型)。搭配 xhigh 和 max effort level 時,thinking output 也會更高。遷移時建議在真實流量上實測 token 用量變化。
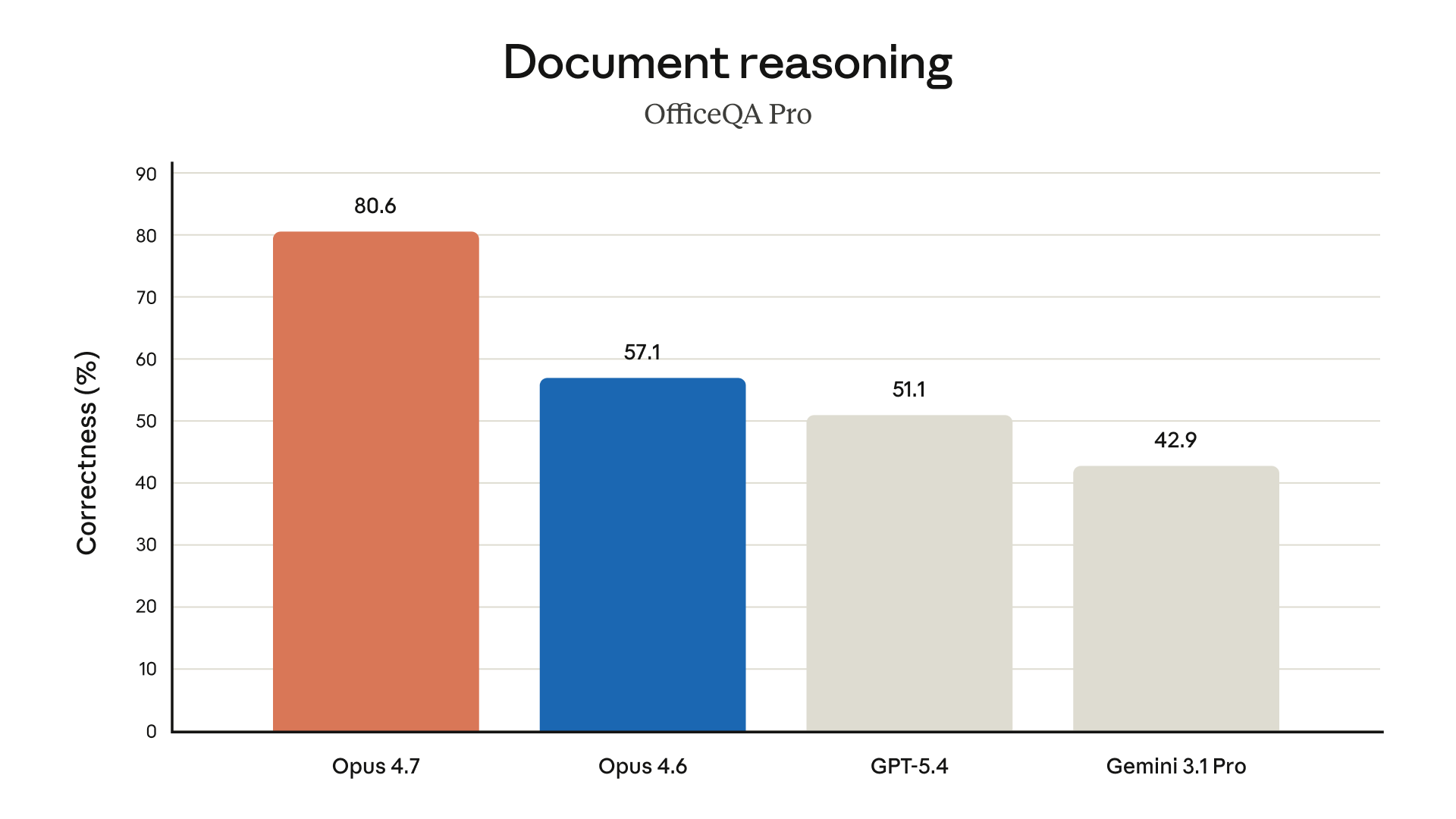
以下是 Anthropic 官方公布的 Opus 4.7 評測結果,涵蓋程式設計、視覺、辦公、金融與 Agent 等維度。
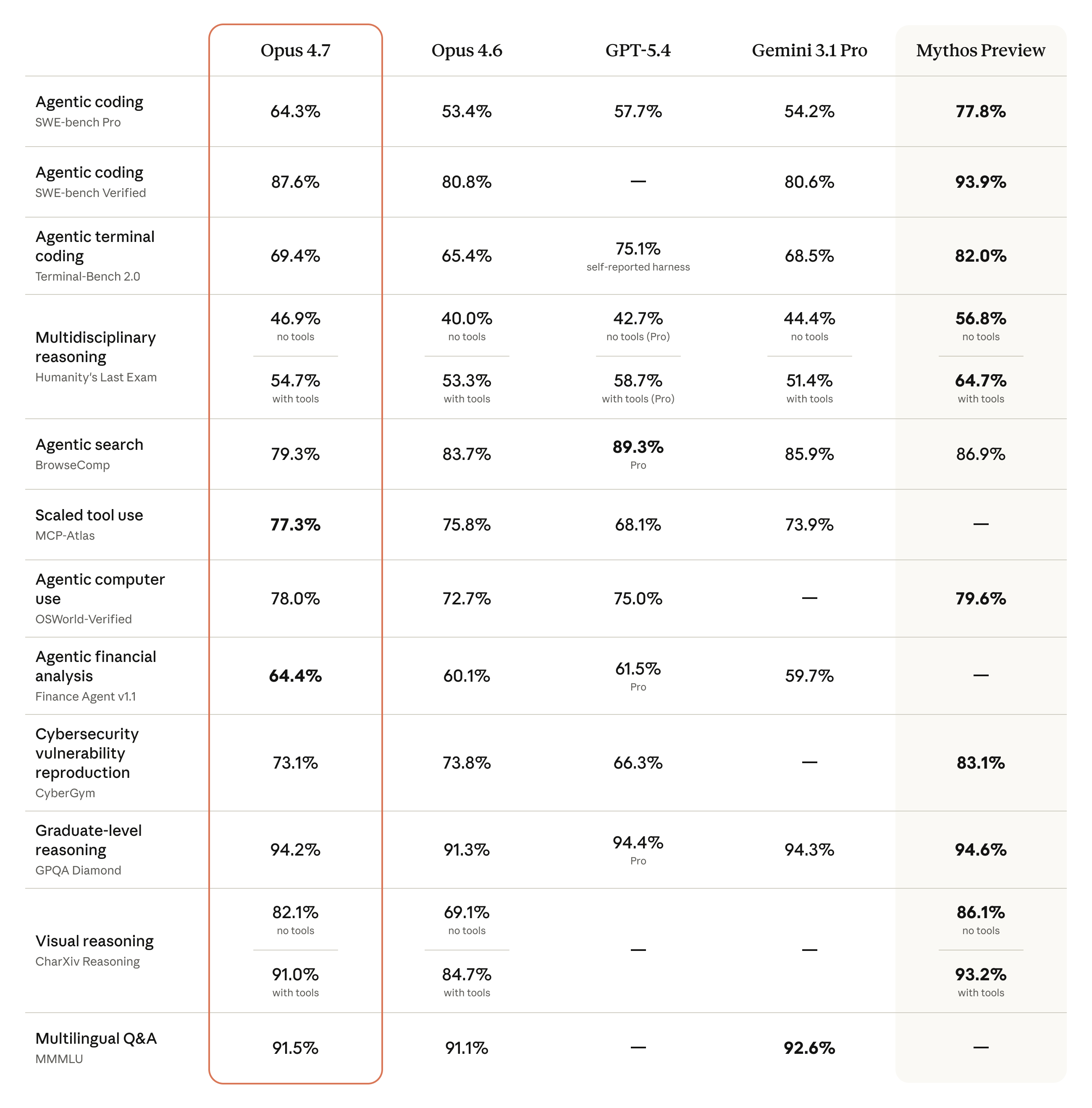
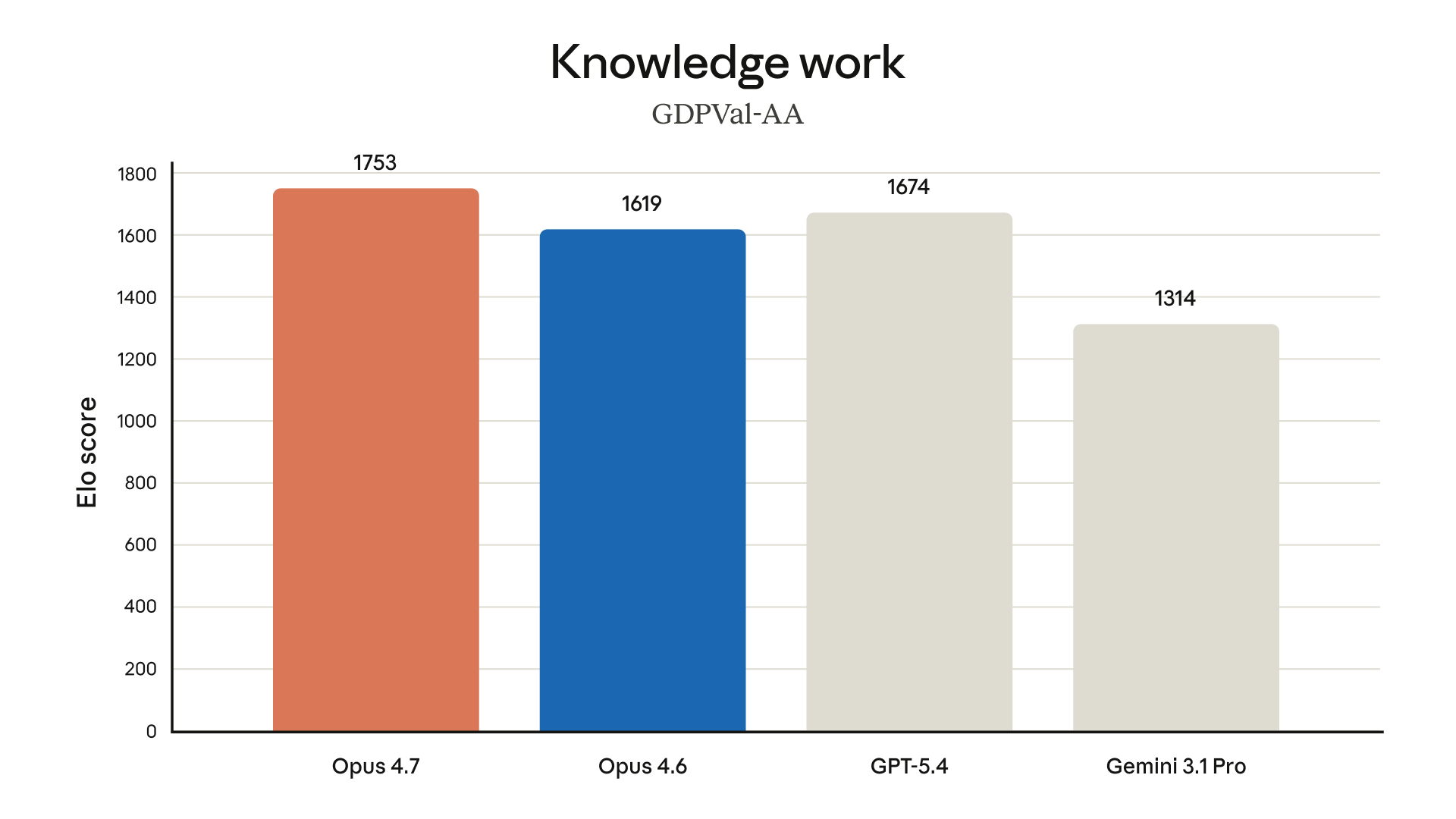
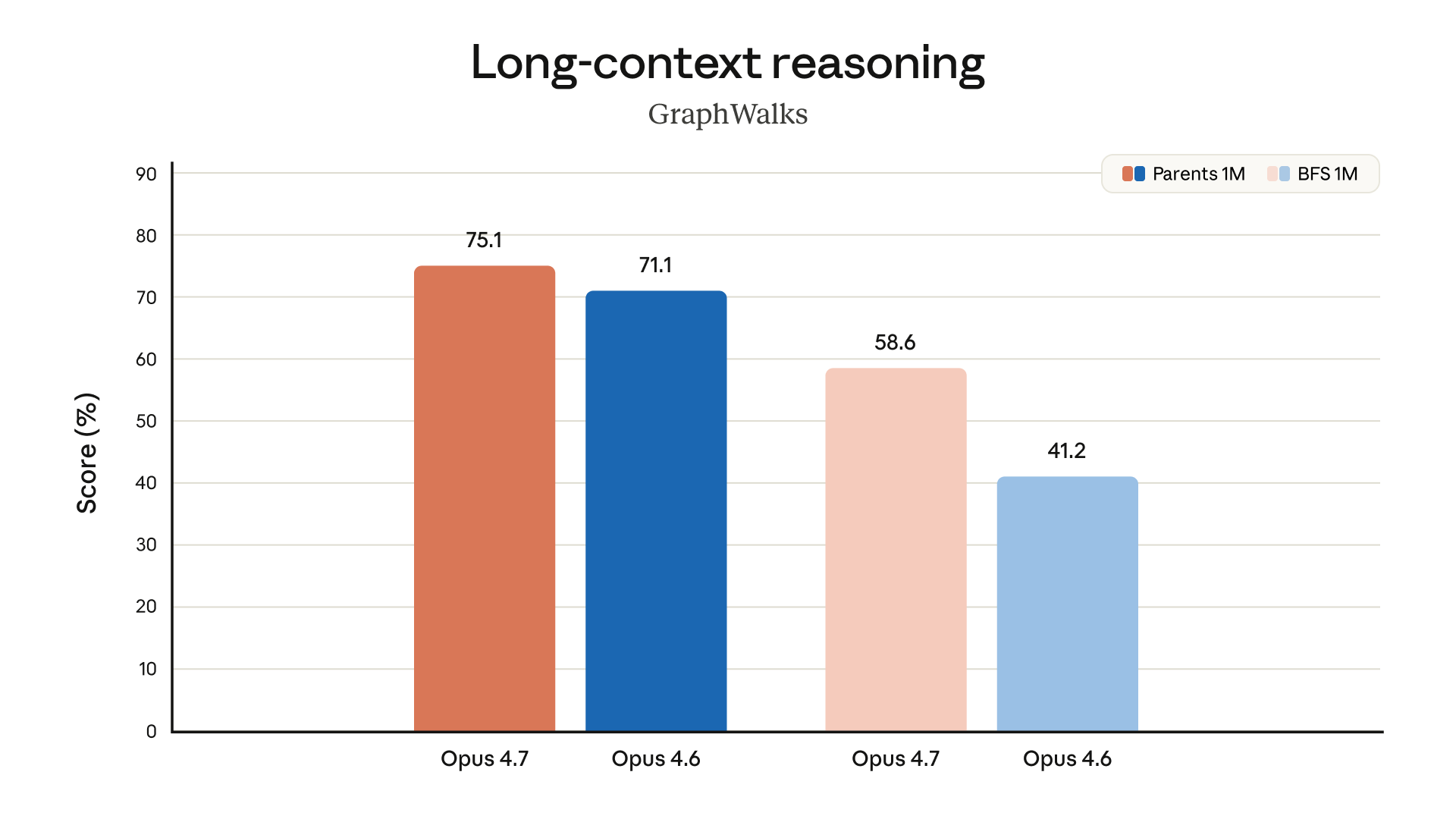
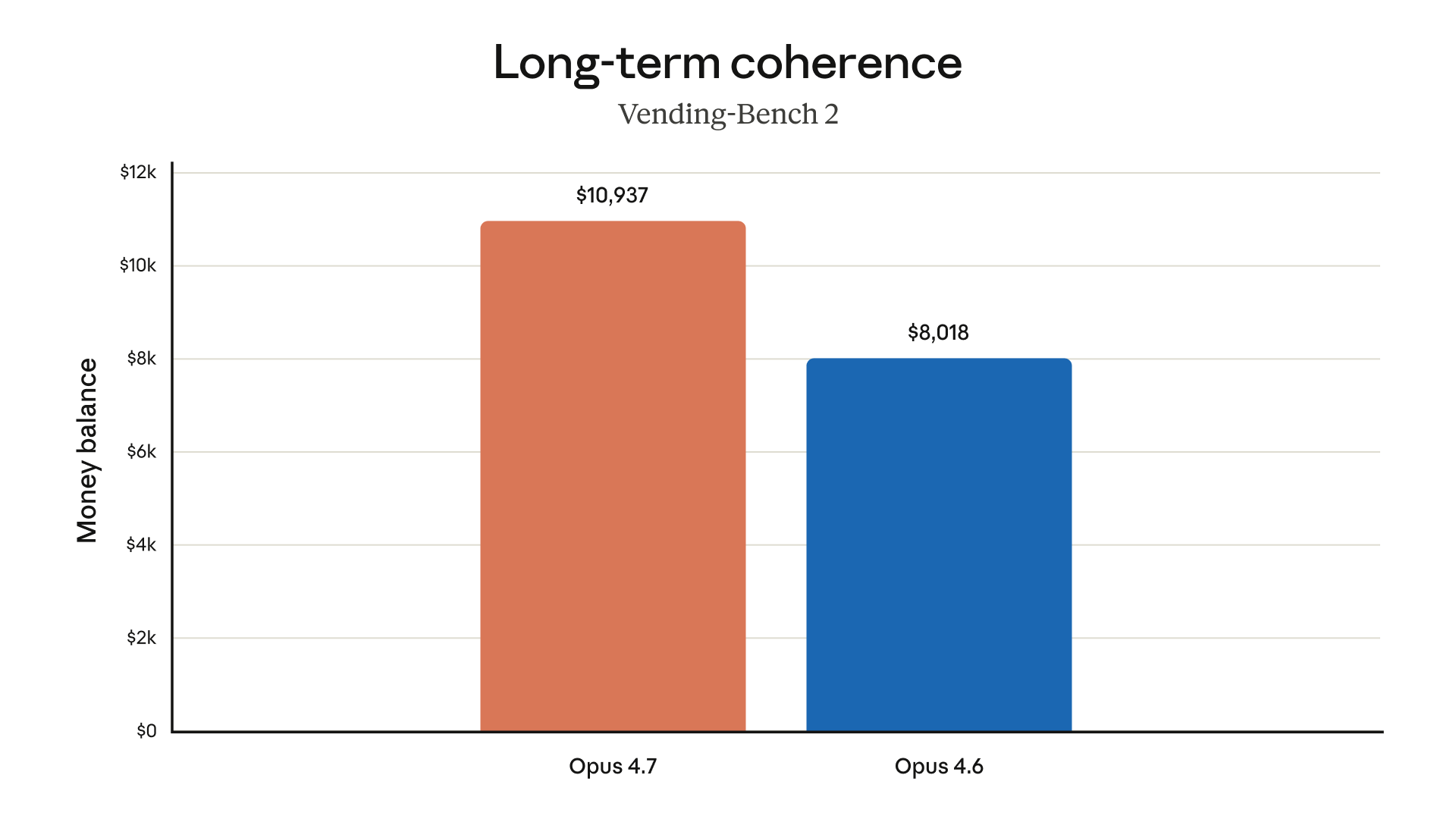
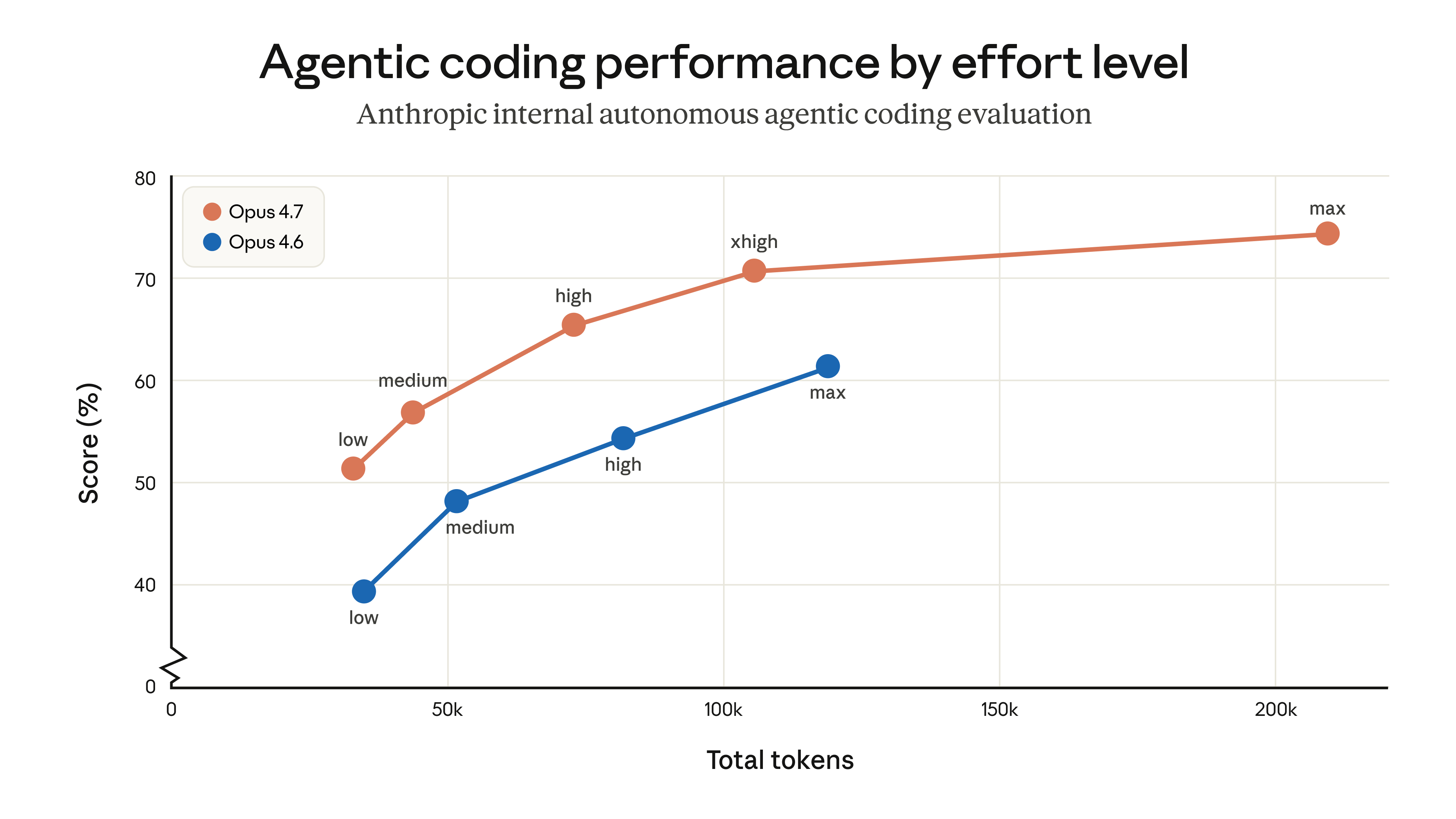
上圖顯示在內部 Agentic Coding 評測中,不同 effort level 下的得分與 token 消耗關係。xhigh 在多數場景中提供了**的性價比平衡點。
Opus 4.6 在 2 月推出,4.7 僅隔兩個月就上線。對比之下,Opus 4.5(2025 年 11 月 24 日)到 4.6(2026 年 2 月 5 日)間隔約兩個半月,節奏相近。Anthropic 維持這種穩定的迭代頻率,意味著他們可能已經找到了一條持續的能力提升路徑,不需要每次都從頭訓練全新架構。
對開發者來說,這是好消息也是挑戰:好消息是每一輪升級的遷移成本不高(API 向下相容),挑戰是如果你的競爭對手比你更快採用新模型,能力差距會在幾週內拉開。
Opus 4.7 發布的時間點並非偶然。2026 年 Q2 是 AI 大模型的密集交鋒期,三大廠商幾乎同時在推進下一代旗艦模型。
OpenAI 的 GPT-5 早在 2025 年 8 月就已發布,到了 2026 年 3 月更推出 GPT-5.4,一口氣將上下文視窗拉到 1M tokens——直接追平 Claude Opus 4.6 的規格優勢。GPT-5.5 預計 2026 年 Q2 推出,迭代速度不輸 Anthropic。
Google 這邊同樣沒閒著。Gemini 2.5 Pro 在 2025 年 6 月就已 GA,之後 Google 在 2025 年 11 月推出 Gemini 3 Pro,2026 年 2 月再升級到 Gemini 3.1 Pro。憑藉原生多模態能力與 Firebase、Google Cloud 的深度整合,Gemini 系列在企業市場持續施壓,全棧開發者很難忽視。
面對兩大對手,Anthropic 選擇的差異化路線很明確:不只做最聰明的模型,而是做最可靠的 Agent 基礎設施。
從 Claude Code 的 Hooks 機制與 Auto Mode 安全設計 ,到 Opus 4.7 強化的多 Agent 協調能力,Anthropic 押注的是:當 AI 從「回答問題」進化到「自主執行任務」時,安全性與可控性才是企業願意付費的關鍵。
這條路線在 從 Prompt 到 Harness Coding 的發展趨勢中已經浮現:AI 開發正從「人類下指令、AI 執行」轉向「人類設護欄、AI 自主運作」,而 Anthropic 正在這個轉型中搶佔基礎設施層的位置。
Opus 4.7 官方的安全檔案也反映了這個方向:
Anthropic 內部的自動化行為審計顯示,Opus 4.7 在誠實度與抗 prompt injection 上優於 4.6,欺騙、諂媚與濫用配合的發生率均維持低水位。不過,安全報告也坦承 Opus 4.7 在管制物質的減害建議上比 4.6 更詳細——這是一個已知的取捨。目前 Anthropic 訓練過最對齊的模型仍然是 Mythos Preview。
在 Opus 4.7 發布的同一時間,Anthropic 進一步揭示了 Claude Mythos Preview 的定位:一個比 Opus 4.7 在所有維度上都更強大的模型,但因安全考量僅開放給 40 個精選組織使用。
根據 NBC News 與 CFR(美國外交關係委員會)的報導,Claude Mythos 在內部測試中自主發現了數千個零日漏洞(Zero-day Vulnerabilities),覆蓋主要作業系統與瀏覽器,其中包括一個 OpenBSD 中存在 27 年未被發現的安全漏洞。
Anthropic 以安全為由,將 Mythos 的存取權限限制在「Project Glasswing」計畫中,僅開放給 Microsoft、Apple、Google、CrowdStrike 與 JPMorgan Chase 等組織。Opus 4.7 的網路安全能力則被刻意降低(官方用語:intentionally reduced compared to Mythos Preview),並為合法安全研究人員提供 Cyber Verification Program 申請管道。
Opus 4.7 是 Anthropic 在安全可控範圍內願意公開的最強模型。 Anthropic 手上的技術能力遠超你在 API 裡能用到的——他們只是選擇不全部放出來。
這是 AI 產業一個新的里程碑:模型能力的瓶頸不再是技術,而是安全與倫理的取捨。 對開發者來說,這意味著未來的模型升級節奏可能不再只看技術進展,還要看「安全委員會覺得你準備好了沒」。
切換方式只需更新 model 參數為 claude-opus-4-7,API 向下相容。但有兩點需要注意:
第一,token 用量會變。 由於 tokenizer 更新,相同輸入會產生 1.0–1.35 倍的 token 數量。建議在真實流量上實測後再全量切換。
第二,Opus 4.7 更字面地執行指令。 Anthropic 官方提醒,這可能需要調整部分 prompt——過去模型會「善意推測」你的意圖,現在它更嚴格地照做。對大多數場景這是好事(更可預測),但如果你的 prompt 依賴模型的自由發揮,可能需要 retuning。
要不要馬上切換?
- 推薦升級:Agentic 任務、代碼審查流水線、高解析度圖片處理、需要 xhigh effort 的場景
- 可以觀望:簡單文本生成或分類任務,Sonnet 4.6 性價比仍然更好
- 注意成本:tokenizer 變化意味著同樣的任務可能花更多 token,先測再切
視覺能力的 3 倍升級,對 Vibe Coder 的日常工作流有直接影響。過去,把設計稿或 UI 截圖丟給 Claude 時,常常因為解析度不足而丟失細節——按鈕上的小字看不清、圖表的標籤糊掉、表格的邊框消失。現在支援 2,576px 長邊,一張完整的 Figma 頁面截圖或 1080p 螢幕錄影的單幀,都能直接餵進去而不用先裁切。
Claude Code 也跟著升級:預設 effort 從 high 提升到 xhigh,新增 /ultrareview 指令用於專門的程式碼審查 session(Pro 和 Max 用戶各有 3 次免費額度),Auto mode 擴展到 Max 用戶——讓 Claude 自主決策而不需要逐步確認。搭配 Claude Code 桌面版的多 Session 管理 ,工作流效率有明顯提升。
Opus 4.7 確認維持 \(5 / 百萬 input tokens、\)25 / 百萬 output tokens 的定價——與 Opus 4.6 完全相同。但因為 tokenizer 變化,實際成本可能微增 0-35%,取決於你的輸入內容類型。
此外,Anthropic 新推出了 Task Budgets(公開測試版),可以為較長的 Agent 任務設定 token 消費上限——這對成本控制是個好消息。
對於預算有限的開發者, Claude Code Max Plan 的費用分析 可以幫助你評估是否值得為 Opus 層級付費。核心決策邏輯是:你的任務需要 Opus 級別的推理深度嗎?
- 需要 Opus:複雜的多 Agent 協調、長鏈推理、高準確率自動化決策、高解析度圖片分析
- Sonnet 就夠:一般代碼生成、文本改寫、內容分類、簡單 API 整合
- Haiku 最划算:批量處理、即時回應需求高但推理深度要求低的場景
在 Agentic 場景中,一個常見的架構是「Opus 做決策、Sonnet 做執行」——用 Opus 處理任務拆解與關鍵判斷,用 Sonnet 處理每個子任務的實際執行,兼顧品質與成本。
Opus 4.7 是一次幅度不小的升級——XBOW 視覺從 54.5% 到 98.5%、CursorBench 從 58% 到 70%、Rakuten 生產任務解決量 3 倍——但 tokenizer 變化和更字面的指令執行,意味著不能無腦切換。
對大多數開發者來說,現在最值得做的一件事是:在測試環境跑一輪你的核心 prompt,同時監控 token 用量變化,看看 Opus 4.7 在你的場景裡帶來多少改善、成本增加多少。 兩個月後 Opus 4.8 可能又來了——但這不是等待的理由,而是及早建立測試流程的理由。
你的 AI 工具組合裡,有多少環節還在用去年的模型?
本文資訊截至 2026 年 4 月 16 日,基於 Anthropic 官方發布公告。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/267844.html