
现在无论是什么岗位,都要求了解一些AI,Agent相关的内容。
从25年开始,知识星球 里就有录友开始反馈,很多岗位要求有agent经验,而且在面试的过程中会主动问你是否了解agent。
今年26年,如果想找开发类的工作,基本了解agent已经成为标配了。
不少录友对于agent的学习,就是在网上,或者问问ai,了解一些概念而已,但面试官,一追问底层原理就露馅。
Function Call 到底怎么实现的?MCP 解决什么问题?A2A 和 MCP 什么关系?这些搞不清楚,面试官一深挖就原形毕露。
这篇文章把 Agent 面试从底层到实战全部讲透,认真看完,面试不再怕被追问。
- LLM 和 Agent 有什么区别?
- Agent 和 Workflow 有什么区别?
- Agent 有哪些工作模式?
- Function Call 是什么?底层怎么实现?
- MCP 是什么协议?解决什么问题?
- Skills 是什么?和 Prompt 有什么区别?
- Function Call、MCP、Skills 三者区别与协作?
- A2A 协议是什么?和 MCP 的关系?
- Agent 的记忆系统怎么设计?
- Agent 的安全与可靠性如何保障?
- RAG 和 Agent 是什么关系?
- 大厂真实面试追问汇总
面试官一般这么问:"你们项目里用的是 LLM 直接调用还是 Agent?为什么这么选?"或者"Agent 比 LLM 多了什么?如果让你从零设计一个 Agent,你会怎么做?"
LLM(大语言模型)本质上就是一个条件概率模型,给它一段输入 token,它预测下一个 token 最可能是什么:
P(token_n | token_1, token2, …, token{n-1}) 你可以把它当成一个无状态的函数:输入 Prompt,输出文本。每次调用都是独立的,没有记忆,没有状态,对外部世界一无所知。
这四条,面试的时候一定要能展开说,不能只背关键词:
① 只会说不会做——它能告诉你"你可以去天气 App 查一下",但它自己不会去查。
② 没有记忆——上下文窗口一满就"失忆",跨会话什么都没留下。
③ 知识截止——训练数据有截止日期,昨天发生的事它不知道。
④ 不会规划——你让它"做一份竞品分析",它只会线性回答,不会自己拆解成"先搜集资料、再逐个分析、再对比价格"这样的步骤。
一句话:Agent = LLM + 工具 + 记忆 + 规划,在循环中自主完成目标。
任务:帮我查一下明天北京的天气,如果下雨就取消我日历里的跑步计划。
LLM 告诉你怎么做,Agent 直接帮你做完。 这就是本质区别。
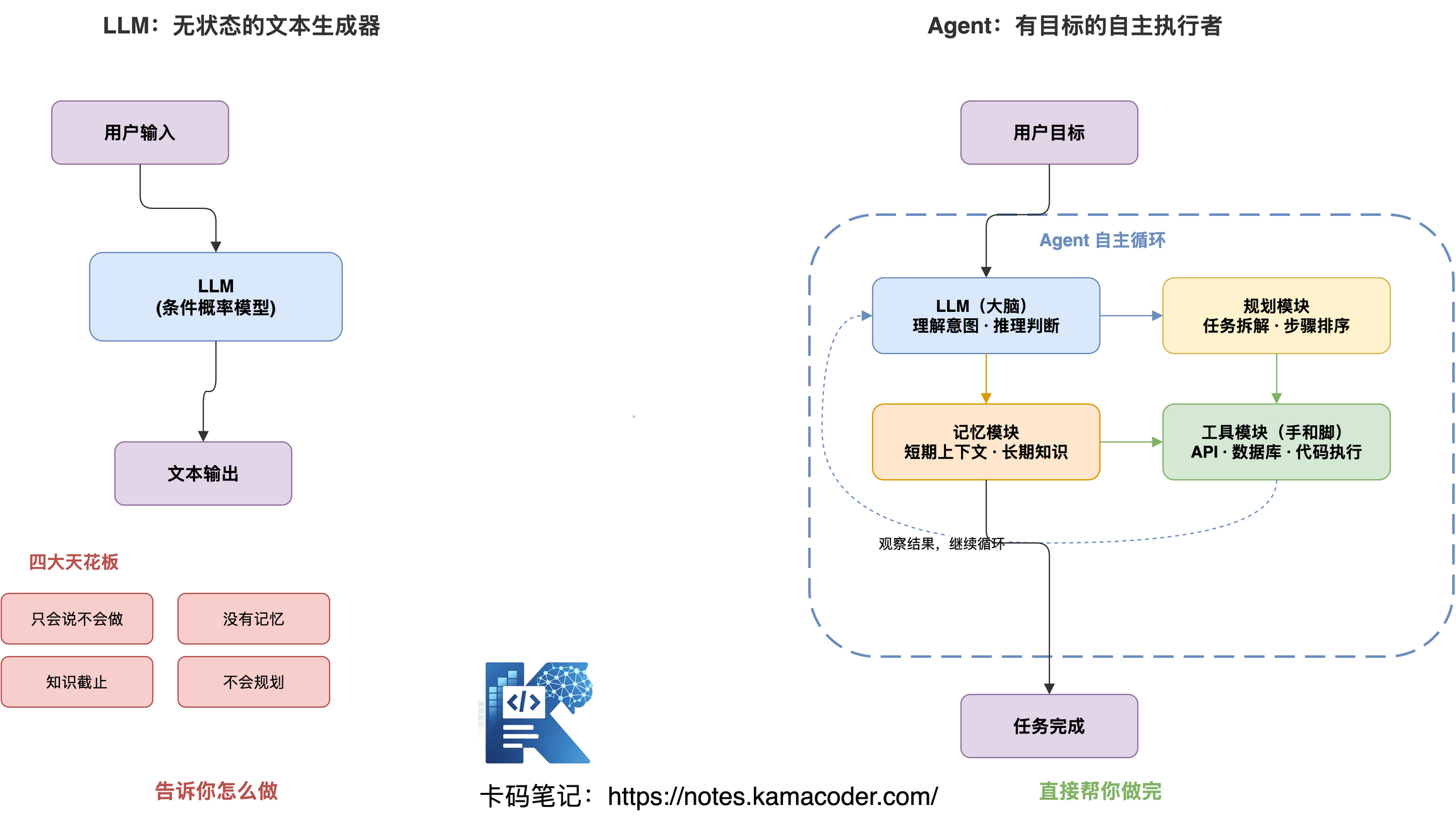
Agent 由四个模块组合而成:LLM(大脑)负责理解意图、推理判断;规划模块负责任务拆解、步骤排序;记忆模块负责短期上下文与长期知识存储;工具模块负责调用外部 API、数据库、代码执行器等,是 Agent 的"手和脚"。
面试时别只说"Agent 就是 LLM 加工具",要展开讲这四个模块各自的作用,以及它们怎么在循环中协作。
面试官会追问:"你说你用了 Agent,为什么不用 Workflow?Workflow 在哪些场景更合适?"或者"如何判断一个任务该用 Agent 还是 Workflow?"
这两者最核心的分歧只有一点:Workflow 的控制权在代码手里,Agent 的控制权在 LLM 手里。
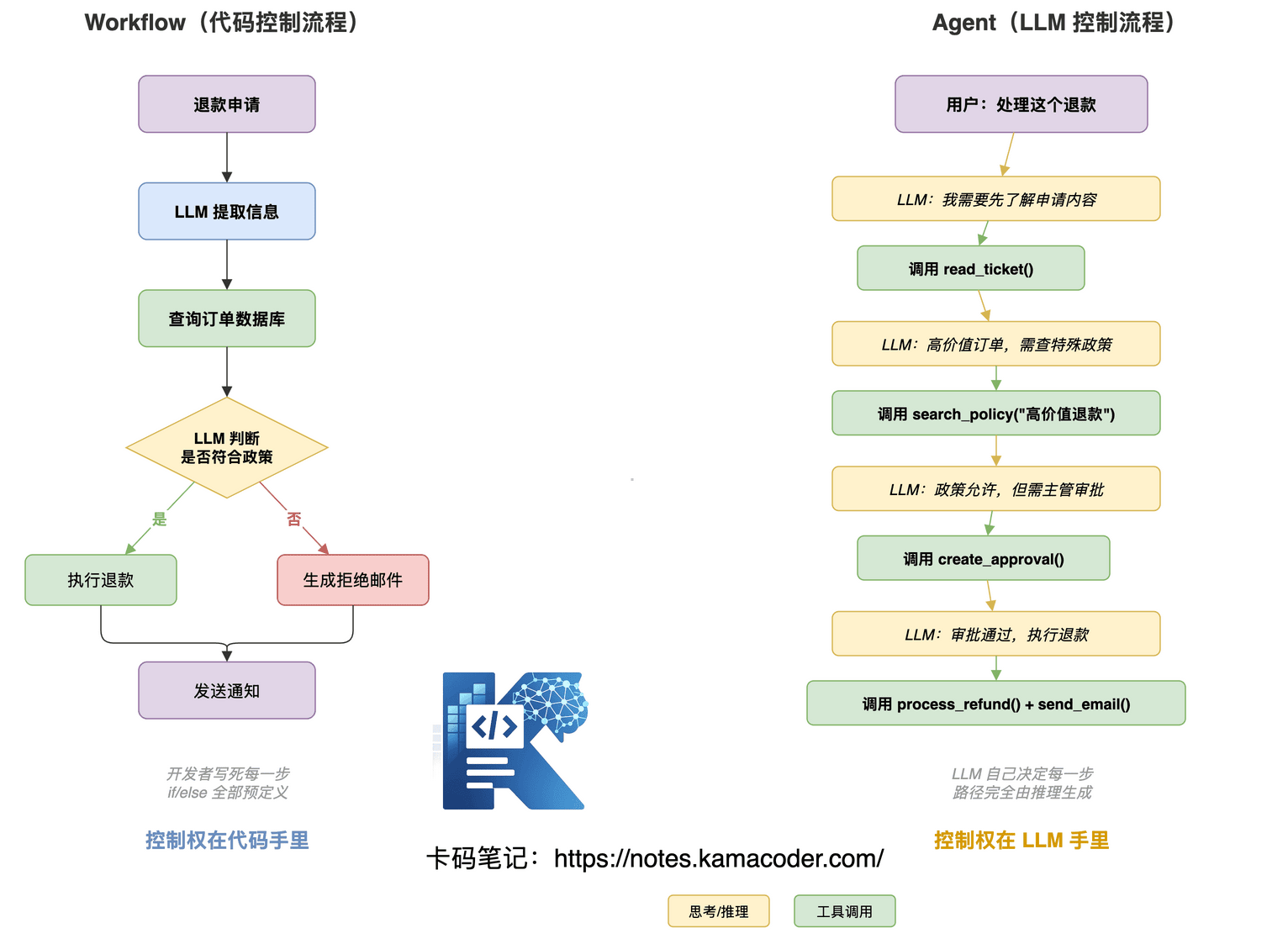
Workflow 就是把流程提前写死在代码里,LLM 只是其中某些节点的处理器。
拿退款处理举例:接收申请 → LLM 提取信息 → 查询订单数据库 → LLM 判断是否符合政策 → 是则执行退款、否则生成拒绝邮件 → 发送通知。每个 if/else 分支、每个步骤的顺序,都是开发者预先定义的。 LLM 只是流程中的一个"智能节点",它不决定下一步做什么。
Agent 接收到目标,自主规划执行路径。
同样拿退款举例:用户说"处理这个退款",Agent 自己思考——"我需要先了解申请内容",于是调用 read_ticket();"发现是高价值订单,需要查特殊政策",于是调用 search_policy_doc();"政策允许,但需要主管审批",于是调用 create_approval_request()。
每一步都是 LLM 自己决定的,不在代码里写死。 这意味着同一个 Agent,面对不同的退款申请,可能会走完全不同的路径。
别把 Workflow 和 Agent 对立起来。大多数生产系统是 Workflow + Agent 的混合架构——Workflow 提供稳定骨架,Agent 负责处理异常和复杂情况。
比如智能客服系统:简单问题走 Workflow 直接回答,复杂问题启动 Agent 自主分析决策,投诉工单直接升级人工。这样既保证了基础场景的稳定可控,又能在复杂场景发挥 Agent 的灵活性。
面试答法:先说清楚 Workflow 和 Agent 的区别,再强调混合架构才是生产落地的正确姿势。能说出这个,面试官就知道你做过实际项目。
面试官会问:"你了解 ReAct 吗?除了 ReAct 还有哪些 Agent 工作模式?各自的优缺点是什么?"以及"如果 Agent 陷入了死循环怎么办?"
Agent 有四种主流工作模式,先看总览,再逐一细读。
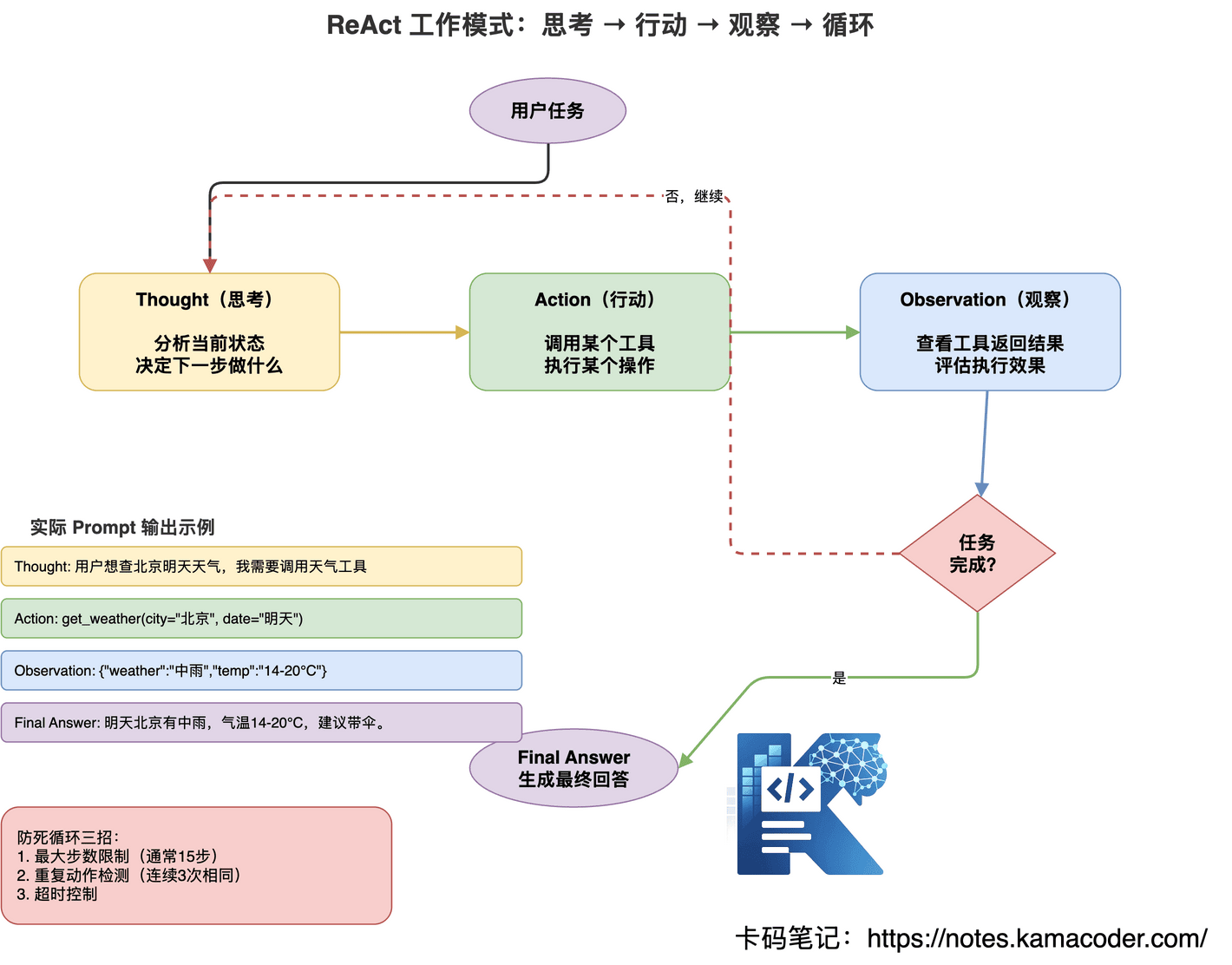
最经典的 Agent 工作模式,几乎所有主流框架(LangChain、LangGraph)的默认选择。
ReAct 的核心是一个三步循环:Thought(思考)→ Action(行动)→ Observation(观察)→ 回到 Thought 继续思考,直到任务完成。
实际跑起来长这样:
Thought: 用户想查北京明天天气,我需要调用天气工具 Action: get_weather(city="北京", date="明天") Observation: {"city":"北京","date":"2025-04-11","weather":"中雨","temp":"14-20°C"}Thought: 天气查到了,是中雨。用户还没说要不要取消日程,我应该告诉他结果 Action: 结束,生成最终回答 Final Answer: 明天北京有中雨,气温14-20°C,建议带伞。
优点:透明可审计(每步思考看得见)、灵活适应(观察结果后可调整)、通用性强。
缺点:Token 消耗大(每步都要完整推理)、可能死循环(工具反复失败时卡住)、延迟高(每次 Action 都要等 LLM 响应)。
如何防止 ReAct 死循环?← 面试高频追问
这是面试必考题,三个方法要能脱口而出:
- 最大步数限制——通常设 15 步,超过就强制终止
- 重复动作检测——连续 3 次调用同一个工具且参数相同,直接退出循环
- 超时控制——整个任务设置最大执行时间
class ReActAgent:def run(self, task, max_steps=15): steps = 0 seen_actions = [] while steps < max_steps: thought, action = self.llm_think(task, history) if steps >= max_steps: return "达到最大步数限制,任务终止" if action in seen_actions[-3:]: # 连续3次相同动作 return self.llm_summarize("工具持续失败,基于已有信息给出答案") seen_actions.append(action) observation = self.execute(action) steps += 1
ReAct 的问题是每一步都要重新思考全局,Token 消耗太大。Plan-and-Execute 的思路是:先把计划想清楚,再按计划逐步执行,省去每步的重复推理。
两阶段工作:第一阶段,Planner LLM 一次性生成完整计划(比如"搜集竞品列表 → 逐个分析功能 → 对比价格策略 → 分析用户评价 → 生成对比报告");第二阶段,Executor 按计划逐步执行,每步只需完成当前任务,不用重新思考全局。
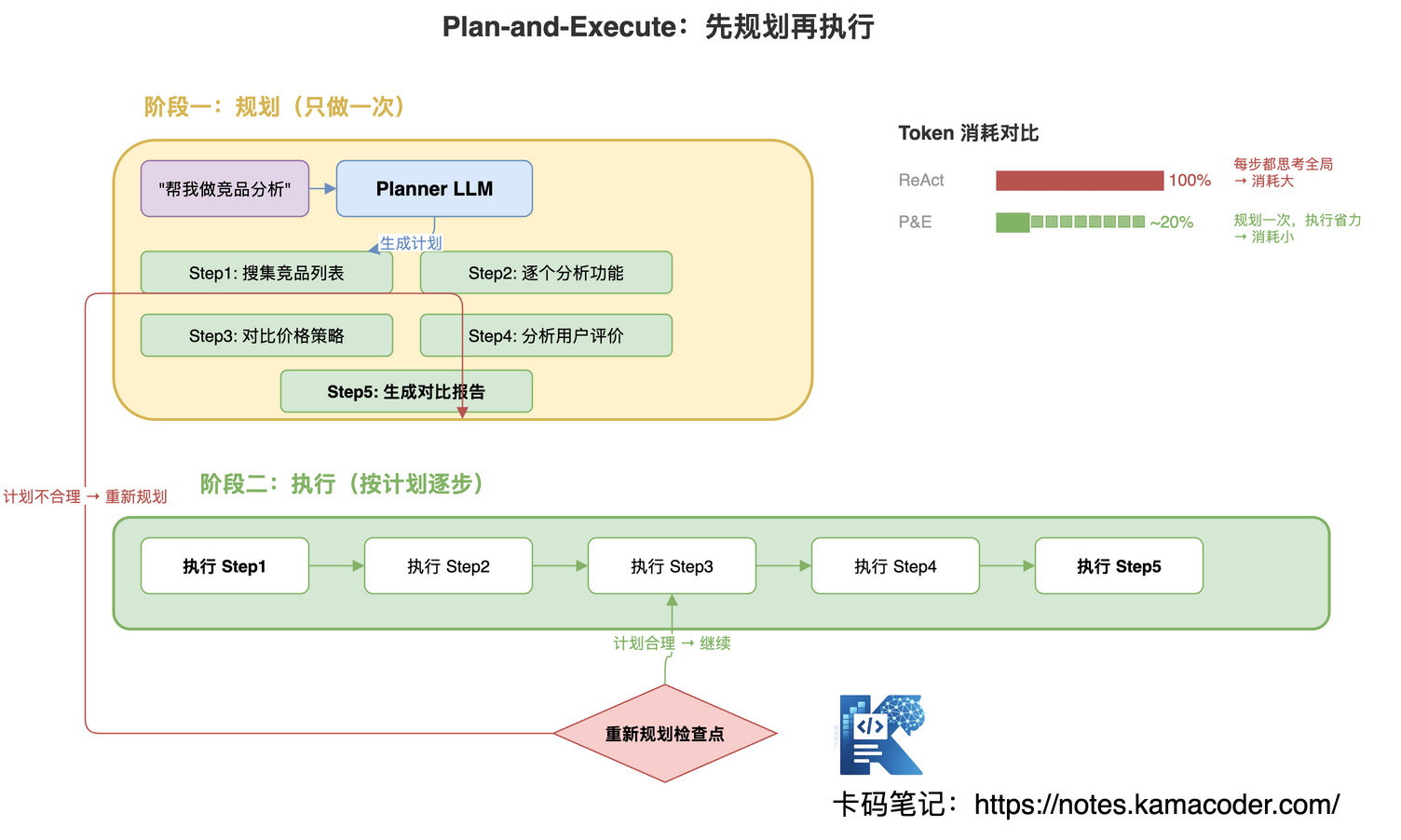
Token 消耗对比:ReAct 每步都思考全局,消耗 100%;Plan-and-Execute 规划一次执行省力,消耗约 20%。
但有个问题:执行过程中发现计划不合理怎么办?比如计划了 5 个竞品,结果搜出来 50 个。解决方案是加入重新规划检查点——执行完某步后检查,如果发现和预期偏差大,触发重新规划,更新后续步骤。
Reflection 的思路是:让一个 Agent 生成,另一个 Agent 审查,循环迭代直到质量达标。
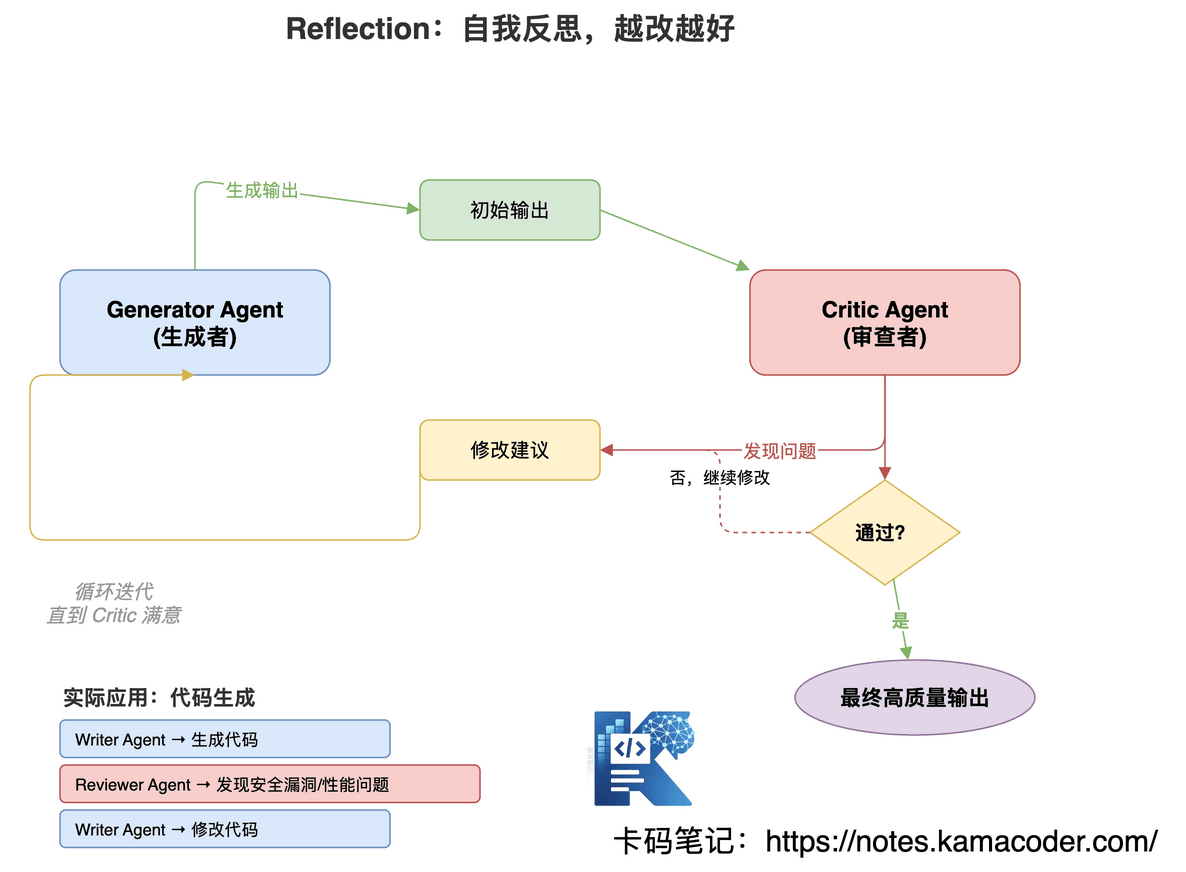
用代码 Review 类比最容易理解:Writer Agent 生成代码 → Reviewer Agent 发现问题(安全漏洞、性能问题)→ Writer Agent 修改 → Reviewer Agent 确认通过 → 最终输出。
适用场景:代码生成、法律文书、学术论文、创意写作——这些场景对输出质量要求高,值得多花 Token 反复打磨。
面试加分:Reflection 也可以用于自我校正幻觉。当 Agent 发现自己给出的事实存疑时,可以触发"验证反思",调用搜索工具去核实,而不是盲目输出。这个点说出来,面试官会觉得你理解得比较深。
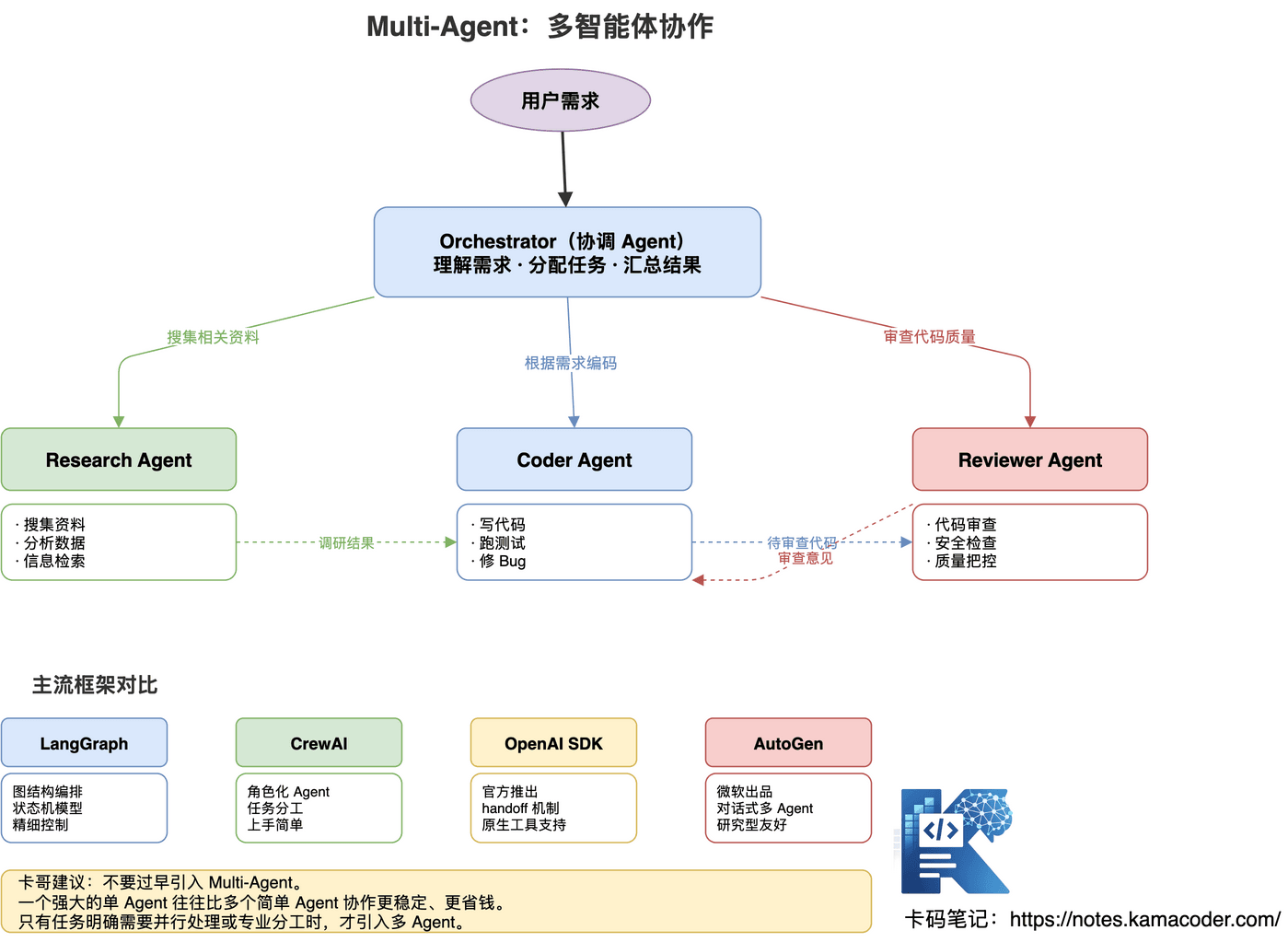
多个专业 Agent 协作完成复杂任务:Orchestrator(协调 Agent)负责理解需求、分配任务、汇总结果,下面挂 Research Agent(搜集资料、分析数据)、Coder Agent(写代码、跑测试)、Reviewer Agent(代码审查、安全检查)等。
主流框架对比:
Anthropic 的提醒,面试时要提到:不要过早引入 Multi-Agent。一个强大的单 Agent 往往比多个简单 Agent 协作更稳定、更省钱。只有任务明确需要并行处理或专业分工时,才引入多 Agent。盲目上多 Agent,调试地狱等着你。
面试官会问:"Function Call 和普通的 Prompt + 正则解析有什么区别?"以及"LLM 自己执行 Function Call 吗?"还有"如果同时触发多个 Function Call 怎么处理?"
Function Call 是让 LLM 输出结构化的工具调用指令,而非普通文本,再由应用程序实际执行。
关键认知:LLM 自己并不执行函数! 它只告诉你"我想调用什么函数、传什么参数",真正执行的是你的代码。
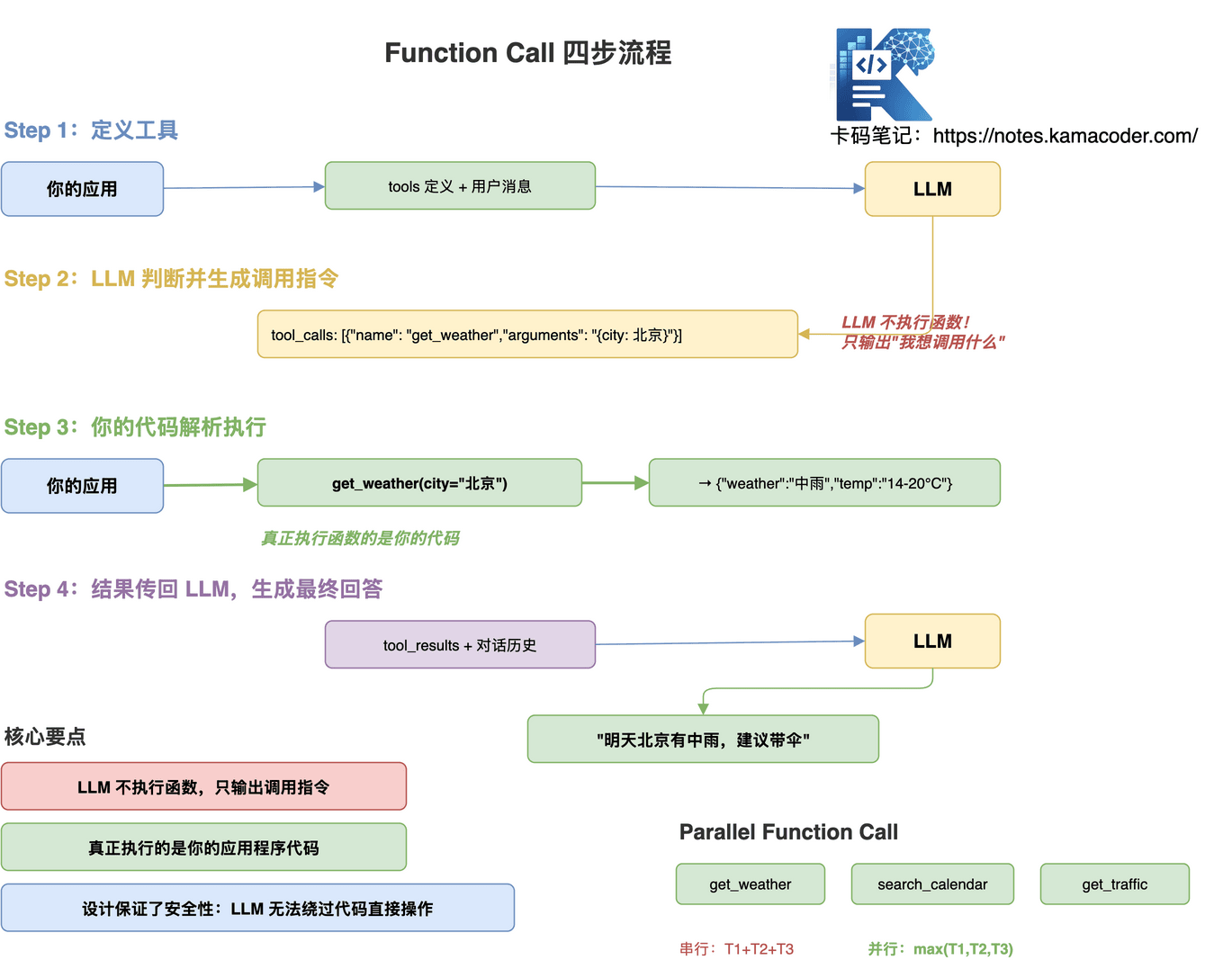
Step 1:定义工具——告诉 LLM 有哪些工具可用
, "date": { "type": "string", "description": "日期,格式 YYYY-MM-DD,不填则为今天" } }, "required": ["city"] } } } ] }
Step 2:LLM 判断并生成调用指令——LLM 的输出不是文本,是结构化 JSON
" } } ] }
Step 3:你的代码解析执行
def handle_tool_calls(tool_calls):results = [] for call in tool_calls: func_name = call.function.name args = json.loads(call.function.arguments) if func_name == "get_weather": result = weather_api.get(args["city"], args.get("date")) elif func_name == "search_calendar": result = calendar_api.search(args["query"]) results.append({ "tool_call_id": call.id, "role": "tool", "content": json.dumps(result) }) return results
Step 4:把结果传回 LLM,生成最终回答
messages.append({"role": "assistant", "tool_calls": tool_calls}) messages.extend(tool_results)final_response = client.chat.completions.create(
model="gpt-4o", messages=messages )
GPT-4o 和 Claude 3.5+ 都支持一次返回多个工具调用,可以并行执行:
"}},{"id": "call_2", "function": {"name": "search_calendar", "arguments": "{"date":"明天"}"}}, "}} ] }
串行执行:T = T1 + T2 + T3;并行执行:T = max(T1, T2, T3),延迟大幅降低。
面试核心点:LLM 不执行函数,只输出"我想调用什么"的指令。真正执行的是你的应用程序。这个设计保证了安全性——LLM 无法绕过你的代码直接操作系统。
面试官会问:"MCP 和 Function Call 有什么本质区别?"以及"如果你要给团队接入 10 个外部工具,你会用 MCP 还是直接写 Function Call?为什么?"
没有 MCP 之前,每个 AI 应用要跟每个外部服务单独写一套集成代码。3 个应用 × 3 个工具 = 9 套代码,10 个应用 × 20 个工具 = 200 套代码,维护成本爆炸。
MCP 把这个问题变成了 N + M:每个应用只需接入 MCP 协议,每个工具只需实现一个 MCP Server,总共 3 + 3 = 6 套代码。
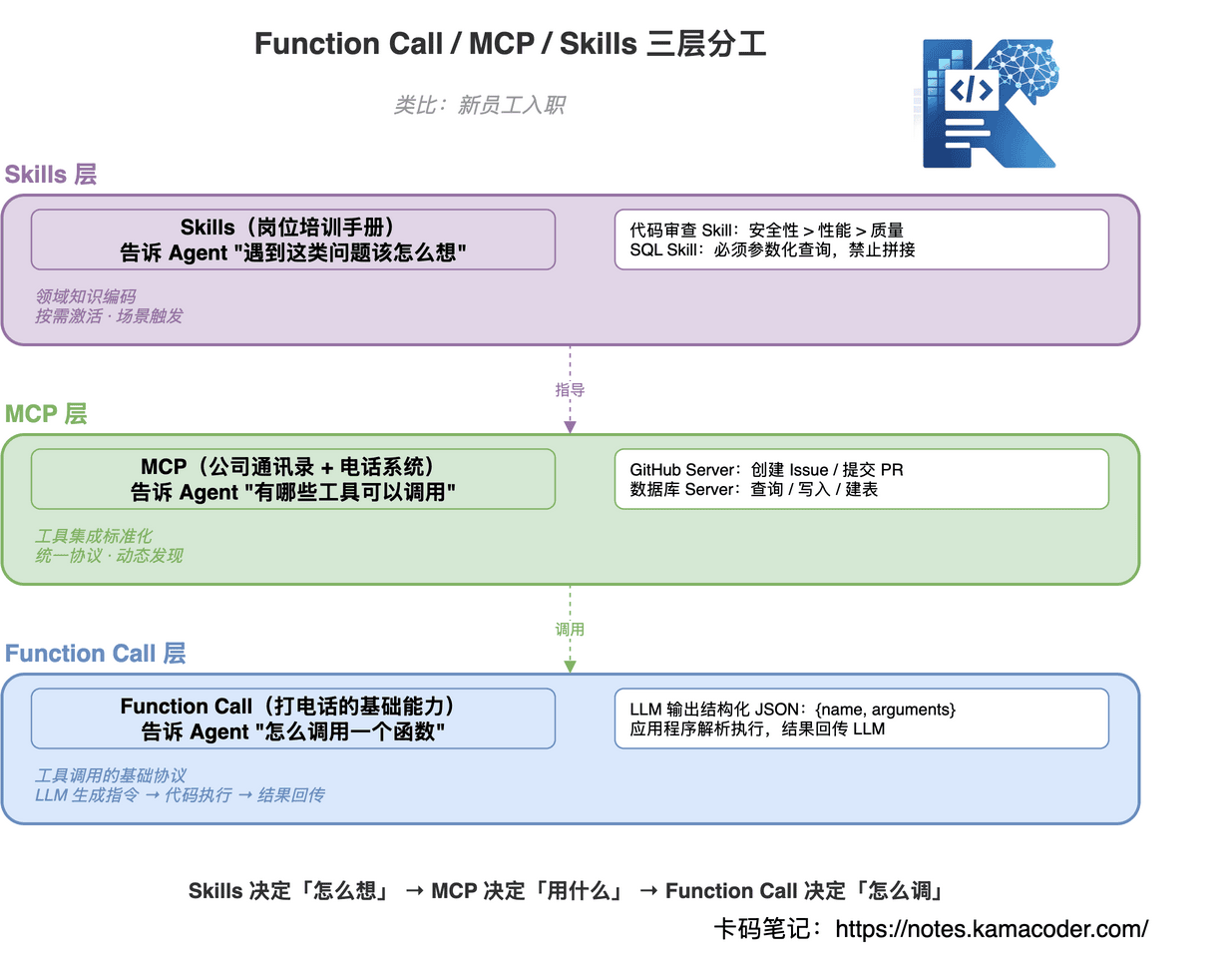
MCP 由三个角色组成:
- MCP Host:你使用的 AI 应用(Claude Desktop / Cursor / 你自己的 Agent)
- MCP Client:住在 Host 里,负责和 Server 通信的"翻译官"
- MCP Server:对外暴露具体工具能力的服务端,每个第三方服务各自实现一个
MCP Server 可以暴露三类资源:
这是 MCP 最强大的特性之一:Agent 启动时,扫描配置的 MCP Server 列表,向每个 Server 发送 tools/list 请求,接收工具列表和描述,将所有工具注入 LLM 的上下文。运行时,用户说"帮我在 GitHub 创建一个 Issue",LLM 发现有 github_create_issue 工具,通过 MCP Client 发送调用请求到 GitHub MCP Server,Server 调用 GitHub API 返回结果。
这意味着 Agent 可以在运行时动态发现新能力,不需要重新部署代码。 今天加一个 Slack MCP Server,明天 Agent 就能用 Slack 的能力了。
三层安全机制:
第一层——能力声明:Server 明确声明自己提供哪些工具,Agent 只能调用声明的工具,无法越权。
第二层——授权控制:敏感操作可以要求人工确认,MCP Host 负责管理 Server 的授权范围。
第三层——审计追踪:所有工具调用都有日志,可追溯每次 Agent 行为。
面试可能会追问 MCP 基于什么协议实现的:
- 本地通信:stdio(标准输入输出,最简单)
- 远程通信:HTTP + SSE(Server-Sent Events,支持流式)
- 消息格式:基于 JSON-RPC 2.0 规范
面试官会问:"Skills 和 System Prompt 有什么区别?你会怎么设计一个 Skill?"
给 Agent 一堆工具(MCP)还不够,它还需要知道:遇到代码审查,该用什么标准?写 SQL 查询时,DBA 的**实践是什么?回复客户时,品牌的语气要求是什么?
这些领域专家经验,就是 Skills 要编码的东西。
— name: Senior_Code_Reviewer description: 当用户要求进行代码审查时激活此技能 triggers:- "帮我 review 代码"
- "code review"
- "检查这段代码" allowed-tools:
- read_file
- search_codebase
- run_linter —
# 角色定位 你是有 10 年经验的资深后端架构师,对代码质量有极高要求。
# 审查维度(必须全部覆盖)
1. 安全性(最高优先级) - SQL 注入风险 - 越权访问漏洞 - 敏感信息硬编码(密码/密钥) - 反序列化安全
2. 性能 - N+1 查询问题(for 循环里查数据库) - 未释放的资源(IO流/数据库连接) - 不必要的重复计算 - 缓存策略是否合理
3. 代码质量 - 单一职责原则 - 方法长度不超过 50 行 - 命名是否准确表意 - 注释是否必要且准确
# 输出格式 必须输出 Markdown 格式报告,包含: 1. 总体评分(1-10分) 2. 严重问题(必须修复) 3. 建议优化(非强制) 4. 每个问题必须附代码示例(原始代码 vs 修复后代码)
# 语气要求 专业、直接,不废话。发现问题就直说,别用"可能""也许"这类模糊表达。
注意这个 Skill 文件的结构:身份定位 + 工作流程 + 注意事项 + 输出规范。这比简单给几个 Few-shot 示例强得多——Few-shot 教的是格式,Skills 教的是方法论。
用户输入 → Agent 扫描所有可用 Skills → 匹配 triggers 关键词 / 语义相似度超过阈值 → 匹配到则将 Skill 内容注入上下文,按 Skill 指导执行;没匹配到则使用通用能力。
面试官会问:"这三个东西我感觉都是让 Agent 能干更多事,能用一个统一的比喻讲清楚吗?"
用"新员工入职"来类比:Function Call 是打电话的基础能力,MCP 是公司统一的通讯录和电话系统,Skills 是岗位培训手册。
一句话总结:Skills 决定「怎么想」→ MCP 决定「用什么」→ Function Call 决定「怎么调」。
用户说"帮我审查 agent.py 这个文件",完整流程是这样的:
- Skills 匹配:检测到"审查"关键词 → 加载 Code_Review Skill → "好,我知道审查要关注安全/性能/质量三个维度"
- Agent 规划(受 Skill 指导):"我需要先读文件,再用 linter 检查"
- MCP 工具发现:发现有 filesystem MCP Server 和 linter MCP Server
- Function Call 执行:生成调用指令
read_file("agent.py")→ MCP Client 转发给 filesystem Server → 获取文件内容 - 再次 Function Call:
run_linter("agent.py")→ 获取 lint 结果 - LLM 综合分析(按 Skill 规范):输出标准格式的代码审查报告
面试官会问:"MCP 和 A2A 都是协议,它们有什么区别?为什么 MCP 解决不了 A2A 要解决的问题?"
MCP 解决了 Agent ↔ 工具的连接,但没有解决 Agent ↔ Agent 的连接。
Agent A 想请求 Agent B 帮忙完成一个子任务,面临的问题:不知道 Agent B 有什么能力、不知道怎么给 Agent B 发任务、不知道 Agent B 完成没有、Agent B 是 LangGraph 做的而我是 CrewAI 做的,怎么通信?
这些问题 MCP 没有设计解决,因为 MCP 的设计目标是工具,不是 Agent。
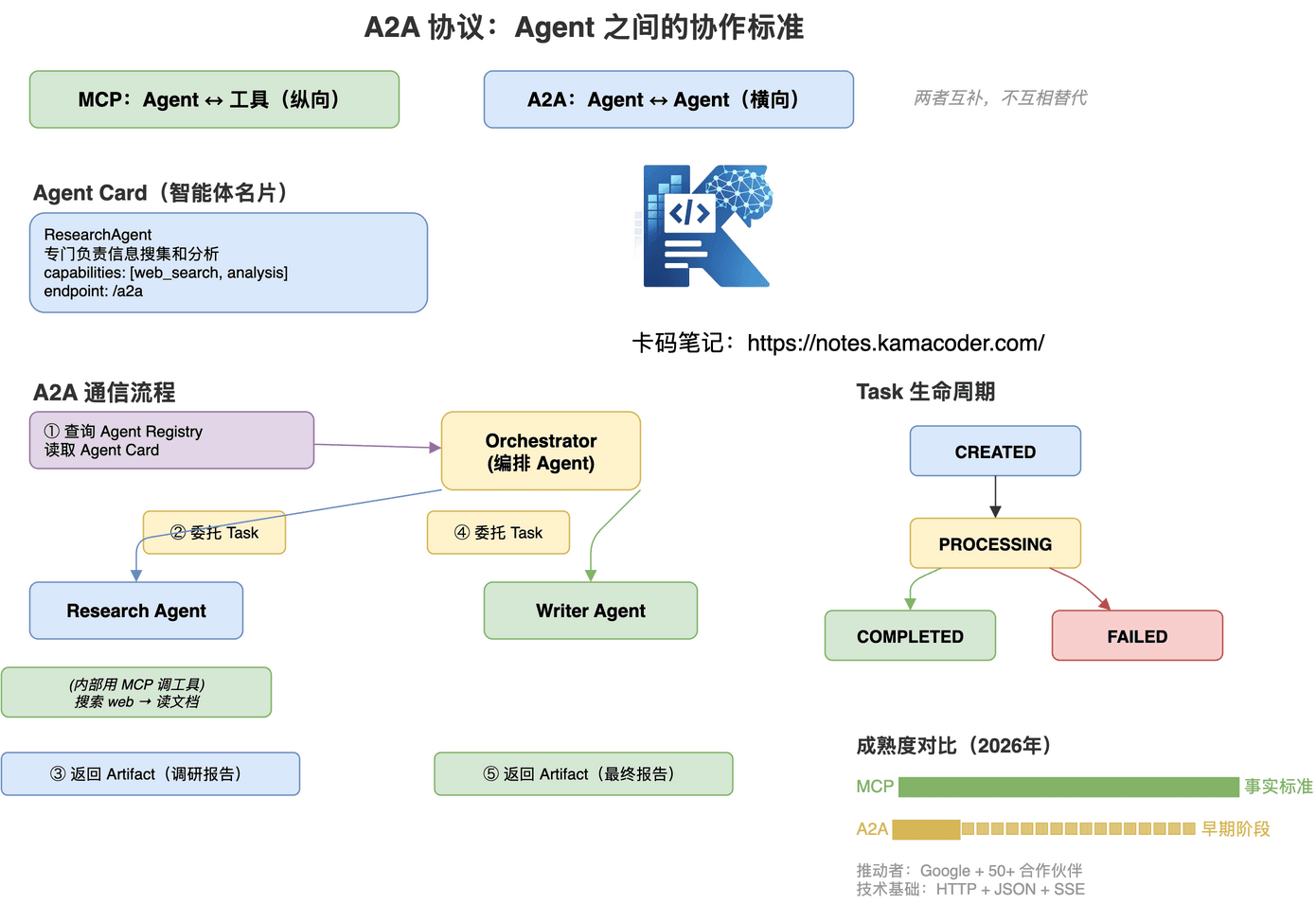
① Agent Card(智能体名片)——每个 Agent 发布一个 JSON 描述文件,包含名称、能力描述、端点地址、认证方式等。其他 Agent 读取名片,决定要不要委托任务。
② Task(任务)——标准化的任务对象,有完整生命周期:CREATED → PROCESSING → COMPLETED / FAILED。
③ Message & Artifact——过程中沟通用 Message,最终成果用 Artifact(可以是文档/代码/数据)。
编排 Agent 收到"写一份关于 AI Agent 技术的竞品分析报告"的需求后:
- 查询 Agent Registry,找到 Research Agent 和 Writer Agent
- 读取各 Agent 的 Agent Card,了解能力
- 通过 A2A 委托 Research Agent:Task{搜集主流 Agent 框架信息},Research Agent 内部用 MCP 调工具完成,返回 Artifact(调研报告)
- 通过 A2A 委托 Writer Agent:Task{基于调研报告写分析报告},Writer Agent 生成最终报告
- MCP 解决纵向问题:Agent ↔ 工具(一个 Agent 连接多个外部服务)
- A2A 解决横向问题:Agent ↔ Agent(多个 Agent 之间协作)
两者互补,不互相替代。Agent 内部用 MCP 调工具,Agent 之间用 A2A 协作。
- MCP:已成事实标准,生态丰富
- A2A:早期阶段,快速发展中,推动者 Google + 50+ 合作伙伴(Salesforce/SAP/Atlassian…)
- 技术基础:HTTP + JSON + SSE,基于现有 Web 标准,无需新基础设施
面试官会问:"Agent 怎么实现跨会话记忆?"以及"RAG 是 Agent 记忆的一部分吗?"还有"记忆太多放不下上下文窗口怎么办?"
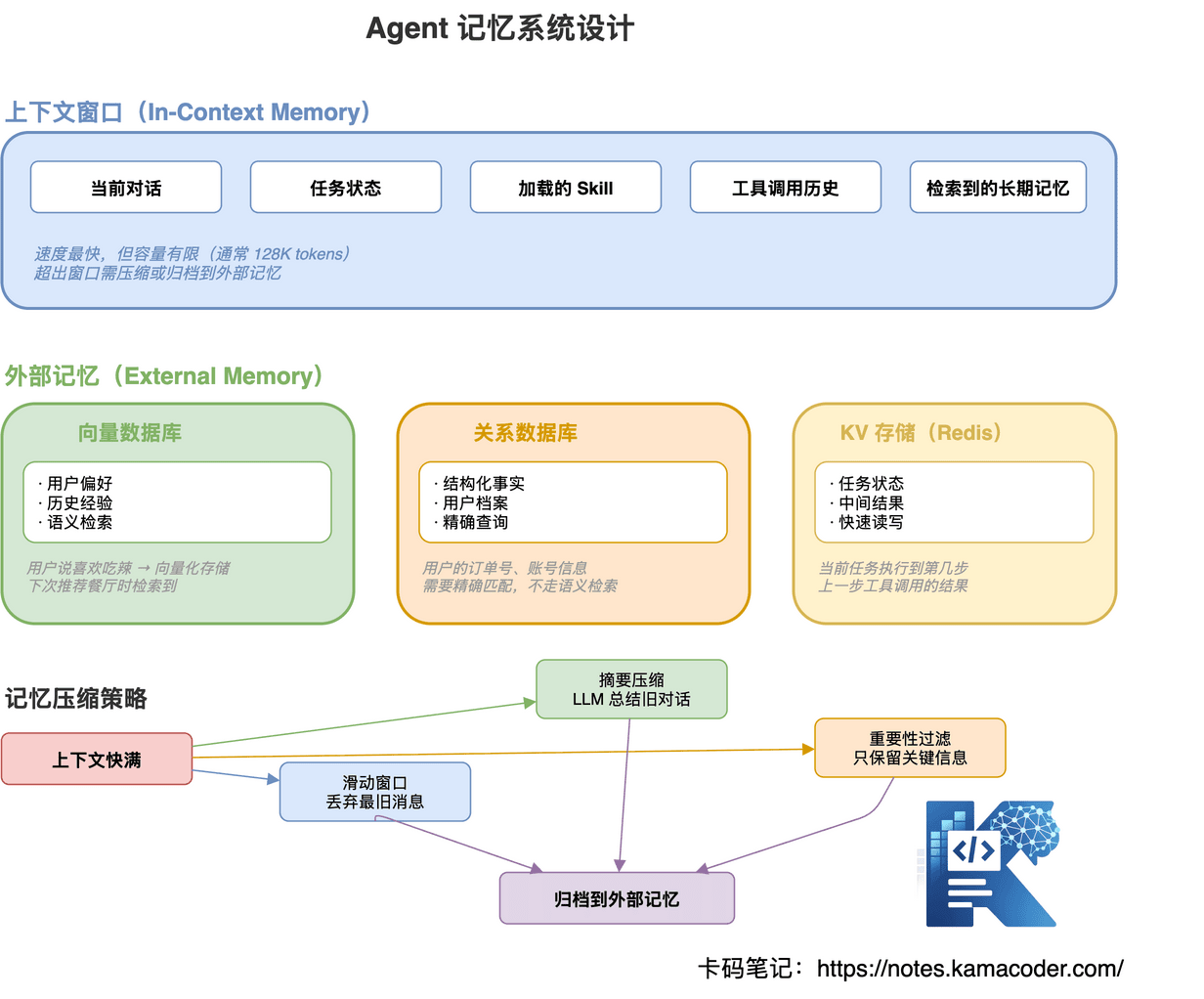
Agent 的记忆分为两大层:
上下文窗口(In-Context Memory)——速度最快的短期记忆,存当前对话、任务状态、加载的 Skill、工具调用历史、检索到的长期记忆。但容量有限(通常 128K tokens),超出窗口需压缩或归档。
外部记忆(External Memory)——分三类:
上下文快满的时候怎么办?三种策略:
- 滑动窗口——丢弃最旧的消息,保留最近 N 条
- 摘要压缩——用 LLM 把旧对话总结成一段话,大幅缩减 Token
- 重要性过滤——只保留关键信息(用户指令、重要结论),丢弃过程细节
压缩后归档到外部记忆,下次需要时再检索回来。
class AgentMemory:def __init__(self): self.working_memory = [] # 当前上下文 self.vector_store = VectorDB() # 长期语义记忆 self.kv_store = Redis() # 结构化状态 def add_message(self, message): self.working_memory.append(message) if self.token_count() > MAX_TOKENS * 0.8: self._compress() def _compress(self): old_messages = self.working_memory[:-20] summary = llm.summarize(old_messages) self.vector_store.add(summary) self.working_memory = [summary_msg] + self.working_memory[-20:] def recall(self, query): relevant = self.vector_store.search(query, top_k=5) return relevant
写入记忆:任务完成后保存结果和关键发现、用户提供个人信息时保存偏好、发现新知识时更新知识库、出错了保存失败原因避免重蹈覆辙。
读取记忆:任务开始时加载用户偏好和历史背景、遇到陌生问题时检索相关历史经验、需要事实核查时检索已知信息。
面试官会问:"如果 Agent 要操作数据库,怎么保证它不会误删数据?"以及"什么是 Prompt Injection?怎么防御?"
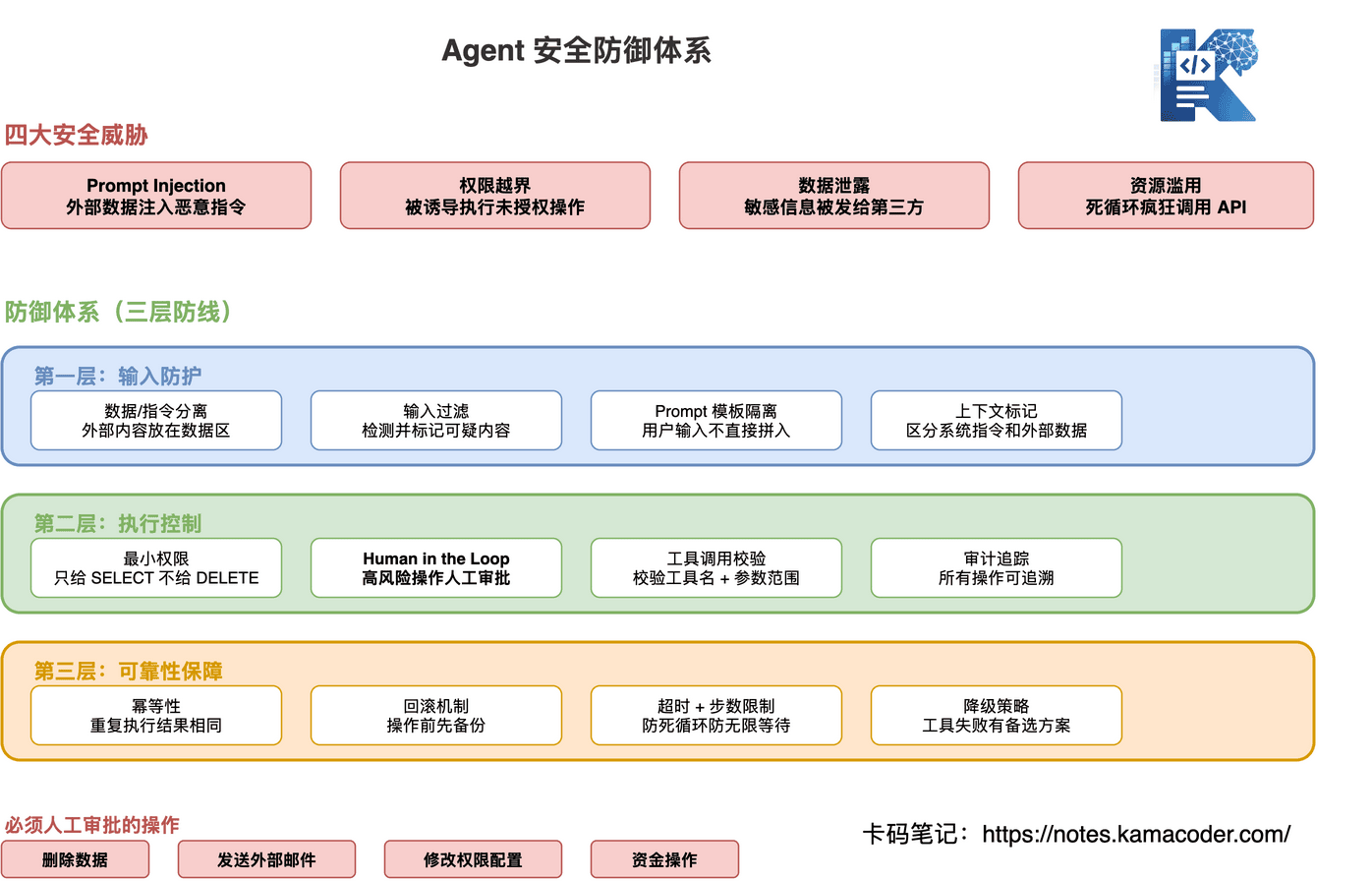
Agent 面临四大安全威胁:
最小权限原则:读任务只给 SELECT 权限,不给 DELETE;MCP Server 声明工具时限制操作范围;不同环境(生产/测试)使用不同凭证。
Human in the Loop(人类审批):高风险操作暂停,请求人类确认。
def execute_action(action):if action.risk_level == "HIGH": approval = request_human_approval(action) if not approval: return "操作已取消" return action.execute()
必须人工审批的操作:删除数据、发送外部邮件、修改权限配置、超过阈值的资金操作。
这是面试高频考点,防御手段要说得具体:
- 数据/指令分离——外部内容放在明确的数据区域,和系统指令区分开
- 输入过滤——检测并标记可疑内容(如包含"忽略之前指令"等关键词)
- Prompt 模板隔离——用户输入不直接拼入系统提示词,用结构化格式包裹
- 上下文标记——在对话中明确标记哪些是外部数据、哪些是系统指令
- 幂等性——同一个操作执行多次结果相同,避免 Agent 重试时重复提交
- 回滚机制——重要操作前先备份,支持撤销(特别是文件修改、数据库写入)
- 超时控制——每个工具调用设置超时,整体任务设置最大执行时间
- 降级策略——工具失败时有备用方案,不能盲目重试,要有退出条件
面试官会问:"RAG 和 Agent 有什么区别?什么时候用 RAG,什么时候用 Agent?"
RAG(检索增强生成)是一种给 LLM 补充外部知识的技术:用户问题 → 向量检索找到相关文档片段 → 把文档片段塞进 Prompt → LLM 基于检索到的内容回答。
别把 RAG 和 Agent 对立起来。Agent 把 RAG 当作工具之一:
- 当 Agent 判断需要知识时 → 调用 RAG 检索工具
- 当 Agent 判断需要操作时 → 调用 API/数据库工具
- 当 Agent 判断需要计算时 → 调用代码执行工具
RAG 是 Agent 工具箱里的"知识查询器"。 面试时说出这个关系,比单纯对比两者的区别要有深度得多。
还有一种模式叫 Agentic RAG——把 RAG 本身做成一个 Agent。普通 RAG 是固定流程:检索一次就完事;Agentic RAG 是 Agent 自己判断检索策略:需要检索哪些数据源?检索结果够不够?不够就换个角度再检索。这种方式对复杂知识问答场景效果很好。
以下是各大厂在 Agent 方向的真实追问,整理汇总。
Q:设计一个企业级 Agent 系统,需要考虑哪些点?
必答五个要点:
- 工具管理层——MCP Server 统一管理,工具权限分级(只读/读写/管理员),工具调用审计日志
- 记忆与状态——短期对话上下文管理(滑动窗口/摘要压缩),长期向量数据库(用户偏好/历史经验),会话 Redis(任务状态/中间结果)
- 可靠性保障——最大步数限制防死循环,工具调用超时控制,关键操作人工审批,失败重试 + 熔断机制
- 可观测性——完整的 Trace(思考链 + 工具调用 + 结果),Token 消耗监控控制成本,错误分类统计
- 安全——Prompt Injection 防御,最小权限原则,数据脱敏
Q:Agent 的 Token 消耗很大,怎么优化成本?
优化策略从易到难排:
- 工具选择优化——只给 Agent 它真正需要的工具(减少工具描述 Token),按任务类型动态加载工具子集
- 模式选择——简单任务用 Workflow 代替 Agent(节省4倍 Token),Plan-and-Execute 代替 ReAct(节省规划 Token)
- 上下文压缩——摘要压缩历史对话,中间结果只保留关键信息
- 模型路由——简单子任务用小模型(如 GPT-4o-mini),复杂推理才用大模型(如 GPT-4o / Claude 3.5)
- 缓存——工具调用结果缓存(相同参数直接返回),Prompt 缓存(Anthropic 支持 Prompt Cache)
Q:为什么说 Function Call 是 Agent 的基石?
因为没有 Function Call,Agent 只能生成文字,无法操作外部世界。Function Call 解决了两个核心问题:什么时候调用(LLM 自动判断,无需规则引擎)和传什么参数(从自然语言自动提取结构化参数)。Agent 的循环本质上是"Function Call 的循环编排"。
Q:MCP 基于什么协议实现的?
传输层:本地用 stdio(标准输入输出),远程用 HTTP + SSE(支持流式)。消息格式基于 JSON-RPC 2.0 规范。
Q:Skills 和 Few-shot 有什么区别?
Few-shot 教格式,Skills 教方法论。Few-shot 给 LLM 几个输入输出示例让它模仿格式,Skills 给 Agent 完整的工作流程、规范和标准。Skills 通常包含:身份定位 + 工作流程 + 注意事项 + 输出规范。
Q:你们生产环境的 Agent 踩过什么坑?
常见的五个坑:
- 死循环:工具持续失败 Agent 反复重试 → 解法:最大步数 + 相同动作检测
- 幻觉工具调用:LLM 调用了一个根本不存在的工具 → 解法:严格校验工具名,未知工具直接报错而非猜测
- 上下文污染:历史对话影响当前判断 → 解法:合理截断上下文 + 任务重置机制
- Token 爆炸:某个工具返回了超大数据(如整个数据库) → 解法:工具输出截断 + 分页策略
- Prompt Injection:外部数据包含恶意指令 → 解法:数据/指令分离,外部内容放在明确的数据区域
2025 年以来,Agent 已经从"概念热词"变成了"岗位刚需"。字节、阿里、百度、腾讯的招聘 JD 里,Agent 相关的岗位数量翻了好几倍,面试官也从"你听说过 Agent 吗"进化到"你们生产环境的 Agent 怎么做的,踩过什么坑"。
这意味着什么?只会背概念已经不够了。 面试官要的是你能把 Agent 的底层原理讲清楚,能把 Function Call、MCP、A2A 这些协议的关系理顺,能在系统设计题里给出落地方案,而不是只会说"Agent 就是 LLM 加工具"。
这篇文章就是帮录友们把这些点全部打通的:
- 底层原理:LLM 为什么不够用 → Agent 四模块怎么协作 → 四种工作模式各自的适用场景
- 协议体系:Function Call 是调用的基础 → MCP 解决工具集成标准化 → A2A 解决 Agent 间协作 → Skills 解决领域知识编码,四个层次各司其职
- 工程落地:记忆系统怎么设计、安全防御怎么做、成本怎么优化、生产环境踩过哪些坑
这些知识点不是孤立的,面试时要把它们串起来。比如面试官问"设计一个 Agent 系统",你不能只说"用 ReAct + MCP",要从工作模式选择、工具管理、记忆设计、安全防护、成本控制五个维度展开,才能拿到高分。
Agent 这条赛道还在快速演进,MCP 刚成事实标准,A2A 已经在追赶,新的框架和工具几乎每个月都在变。但底层的核心逻辑——LLM 怎么调用工具、工具怎么标准化接入、Agent 之间怎么协作、怎么保证安全可靠——这些是不会变的。把这些吃透,不管技术栈怎么演进,你都能快速跟上。
加油
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/267137.html