
截至 2026 年初,Claude Code 在上线六个月内年化收入突破 10 亿美元。这并不是因为“更好的提示词”。而是因为 Anthropic 在“对的模型”外,构建了“对的 harness(执行支架/运行外壳)”:包括一个流式的智能体主循环、一个带权限治理的工具调度系统,以及一个可在任意长会话中保持聚焦的上下文管理层。这个 harness 是完全可复现的,而这正是我们要从零实现的内容。
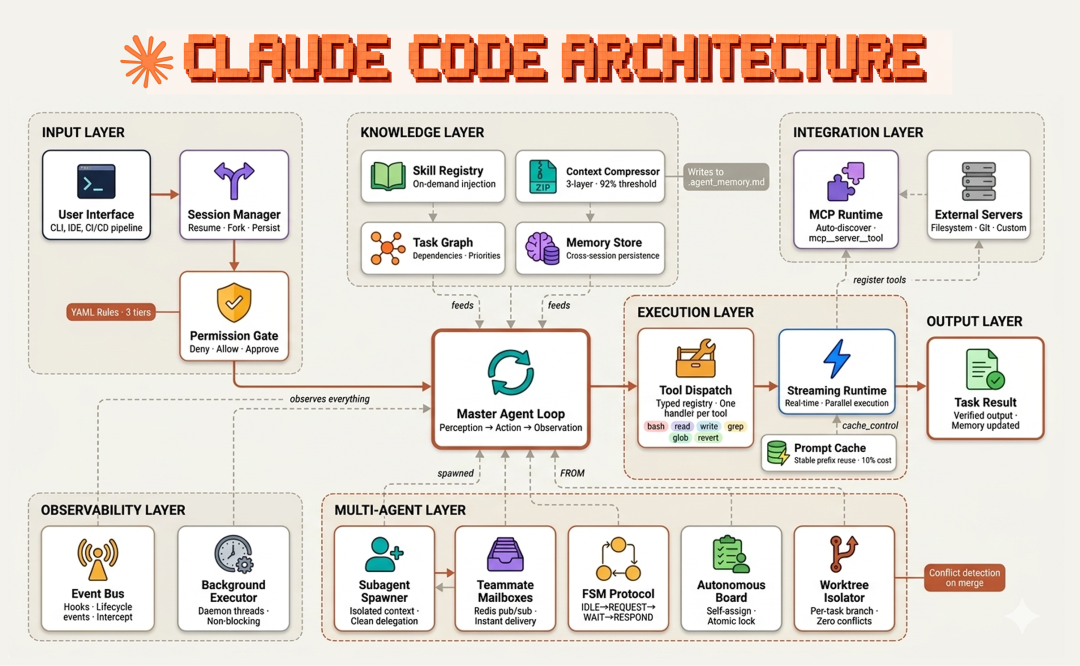
Claude Code 由五个核心部件协同构成:
而在这些组件之内,还有很多值得深入的机制……
在这篇文章中,我们会逐一构建与测试 Claude Code 的各个组件,并理解它们如何协同,超越其他 agentic 框架。
所有代码均开源在 GitHub:
GitHub - FareedKhan-dev/claude-code-from-scratch: 23 Components of the Claude Code Architecture
代码结构如下:
claude-code-from-scratch/
│
├── core.py # 共享基础:client、tools、dispatch、permissions
├── 01_perception_action_loop.py # 最小 while 循环:核心智能体模式
├── s02_tool_use.py # 工具分发表:name → handler
├── s03_todo_write.py # TodoWrite:先规划后执行
├── s04_subagent.py # 子智能体:子上下文隔离
…
├── s10_team_protocols.py # FSM 协议:IDLE→REQUEST→WAIT→RESPOND
├── s11_autonomous_agents.py # 自主智能体:从共享看板自分配任务
├── s12_worktree_task_isolation.py # 每个并行任务一个 Git worktree
│
├── s13_streaming.py # 实时 token 流式输出
…
├── s21_mcp_runtime.py # 官方 MCP SDK:自动注册外部工具
│
├── s22_production_mailbox.py # Redis pub/sub:替换 JSONL mailbox
├── s23_worktree_advanced.py # 完整 worktree 生命周期:覆盖边界情况
…
└── skills/ # 智能体技能:由 s05 按需加载
我将 Claude Code 架构的每个组件拆分到独立脚本中,以便单独运行和测试。
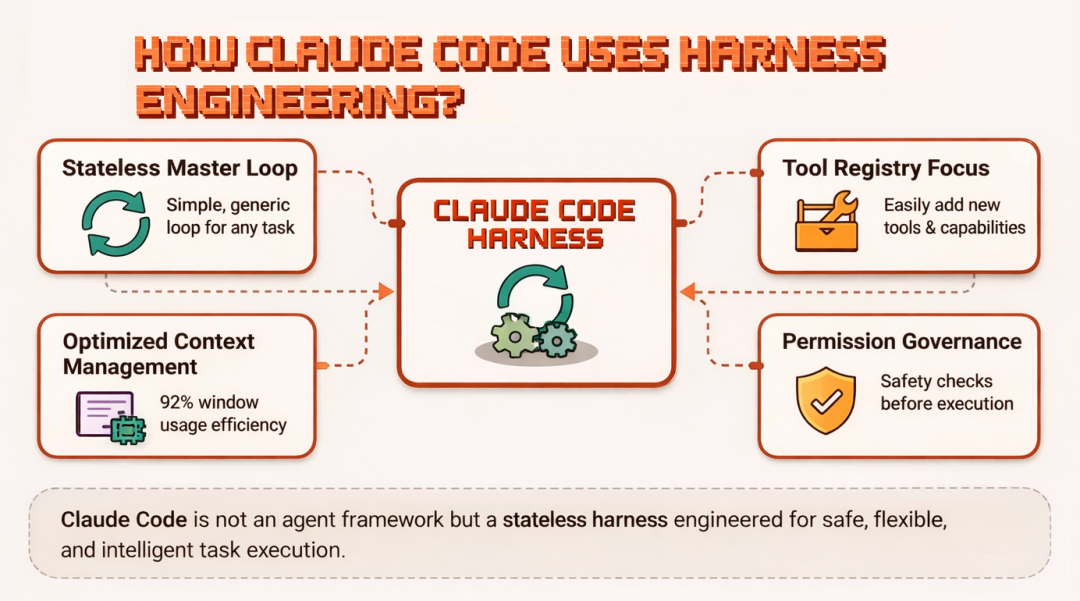
Harness engineering(Harness 工程)是一门构建“围绕 AI 模型的环境”的工程学,而非去改造模型本身。模型负责“推理与决策”。Harness 负责“执行、约束与连接”。一个设计良好的 harness,只为模型提供“恰到好处的工具”,并精确治理模型“允许如何使用”它们。
如果我将 harness engineering 的要义拆解为四条核心原则,它们是:
Claude Code 不是一个“智能体框架(agent framework)”。它是一个 harness,而且是迄今为止工程打磨得最精细、能在生产中稳定运行的 harness 之一。Anthropic 没有写代码去“决定什么时候读文件、什么时候跑测试”;他们“给了 Claude 做这些事的工具”,然后“信任模型”在需要的时候会调用它们。
Claude Code 架构遵循 harness engineering 的原则,具体体现在:
智能体主循环(agent loop)是一切之上的“唯一”架构原语。在工具、权限、多智能体协调之前,先有一个循环:调用模型、观察模型要做什么、执行之、并将结果回灌给模型。
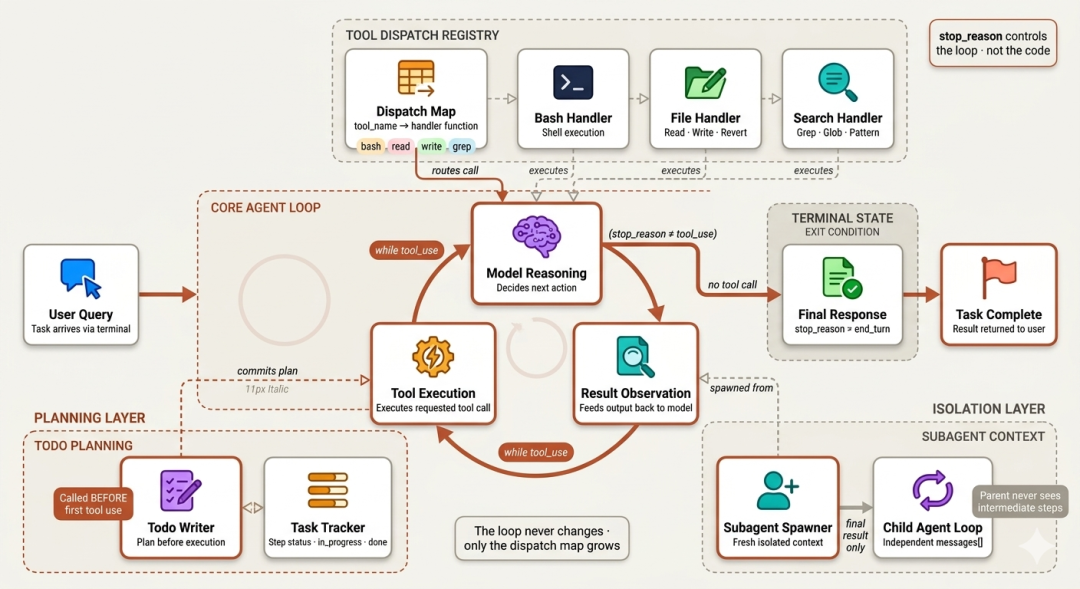
本阶段的每一个会话,都只是在“循环之外”增加一种机制,而从不改变循环本身。
任何 agentic 系统的最基本原则,是“感知-行动-观察”的闭环。
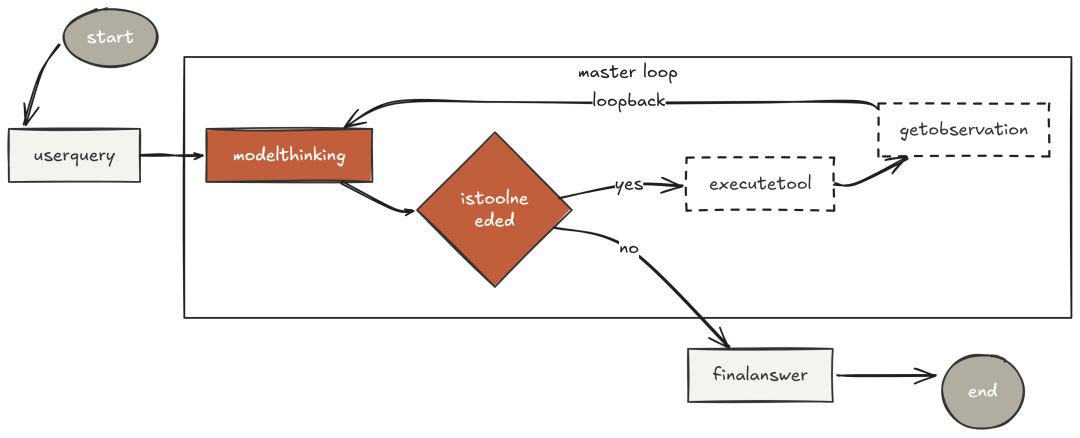
这不是“重试循环”或“回退机制”,而是“核心推理引擎”。在 Claude Code 中,这是一个统一的主循环:不论你让 Claude 修一行小 bug,还是重构整个代码库,这个循环始终没变化。变的只是模型在循环内部做出的决定。
首先,用 anthropic 的模型来实现 Claude 的最小雏形,需要初始化 client 与 model:
# 代码略(保持原样)
我们使用 anthropic 模型;也可以通过 litellm 替换成任意模型。GitHub 代码库对模型提供商是可插拔的。
System prompt(系统提示)是智能体行为的“地基”。虽然很多时候看似“不起眼”,但它对于设定模型处理任务的方式至关重要。
既然 Claude 是“围绕工具”来构建的,那么我们先定义一些基础工具,作为模型与外界交互的接口:
# 工具与 dispatch 示例代码略(保持原样)
Dispatch(分发)是将“模型工具调用”接到“具体执行代码”的机制。它以 dict 将工具名映射到处理函数。对包含大量工具的大架构(如 Claude Code)尤为重要,使工具定义与实现分离,并能无痛增减工具而不改主循环。
dispatch_tools 用于解析模型响应中的 tool_use 块,调用相应 handler,并收集并回传 tool_result。包含了必要的日志输出,便于观察调用和结果。
agent_loop 则是一个简单的 while 循环,直到模型给出最终答案才结束。调用模型、追加响应、如需调用工具则派发执行,再把结果作为用户消息回灌。
接着我们以简单任务跑起来测试,看看如何“自纠错”,体现感知-行动-观察的真实闭环。
# 交互与输出示例(保持原样)
在 Claude Code 的内部架构里,工具注册表(tool registry)是被工程师反复研究的关键部件之一。
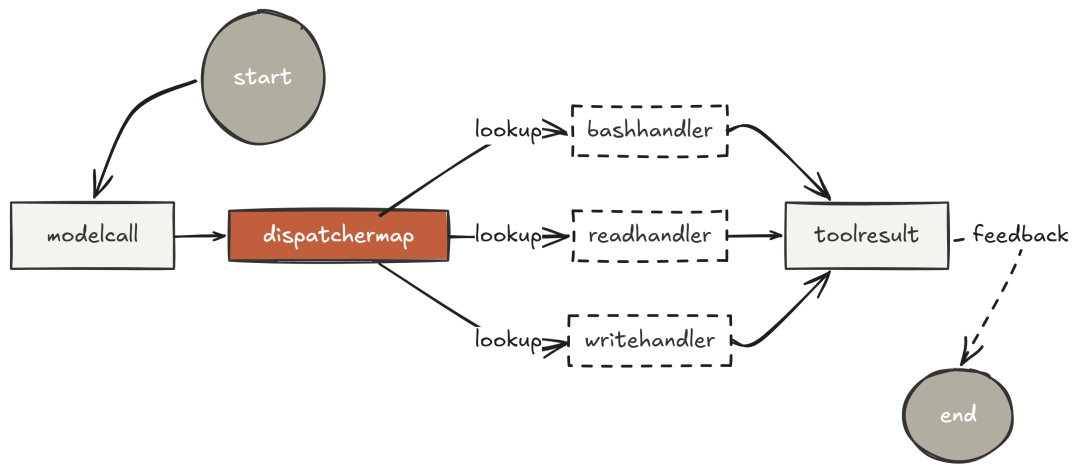
这一切由“dispatch map(分发表)”这个架构模式促成。
Dispatch map 将“模型想做的事”对接到“真正执行的代码”。循环对工具一无所知——它只会做一件事:dispatchtool_name。
因此,Claude Code 可以有 18、30 或 5 个工具,而主循环始终不变。这也是它能通过 MCP 扩展的根本原因:新增的工具只是在注册表里多了一项,不论它是本地 Python 函数,还是远端 server。
工具定义同等重要。模型靠这些定义来决定该调用哪个工具——描述(description)字段“不是文档”,而是“操作指引”。
# 工具/handler 示例代码略(保持原样)
写得不精确的工具描述,会让模型“选错工具”。如果 grep 只写了“搜索文件”,而 bash 说“能执行命令”,那么模型会用 bash 做所有搜索,因为描述没有把边界收紧。
Claude Code 的内置工具描述会“非常具体地”界定使用时机,这种具体性,带来了数百万次执行下的一致、可预期的工具选择。
Handler 的契约也高度一致:收 dict 入参,返回字符串,不向循环抛异常(错误以字符串返回)。
# 代码略(保持原样)
有意将 run_read 返回“带行号”的内容,这样模型在后续 write 中可精准引用行号做定点修改,这是 Claude Code 的既定做法。
# 交互示例(保持原样)
工具选择之所以正确,是因为描述“足够精确”。智能在模型里,harness 只需把工具描述得“匹配意图、可对齐能力”。
对 Claude Code 执行轨迹的逆向分析显示:遇到复杂任务,Claude 在写任何一行代码或读任何一个文件之前,总会先调用 TodoWrite——每一次都是如此。
先有计划,后有行动;并且只有“把计划落笔”后才开始执行。
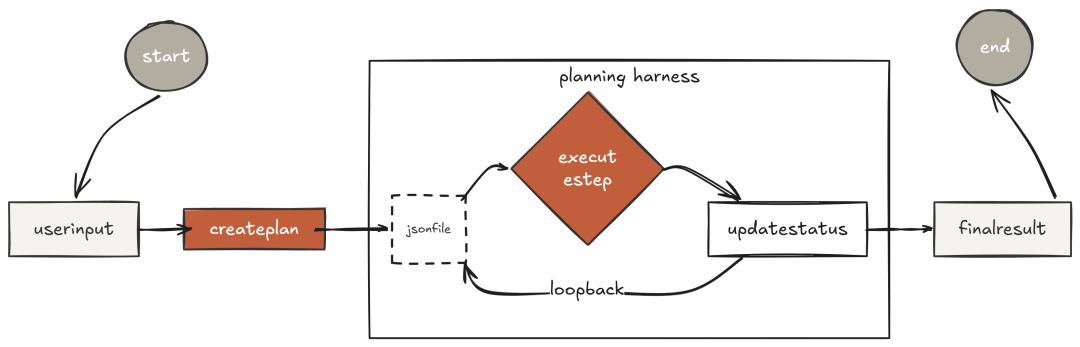
Claude Code 在每次工具调用后,都会用系统提醒把当前 todo 状态“重新注入”。模型“无法忘记”它的计划,因为计划“持续被回注”。这使它能稳定地完成跨越几十次工具调用的长任务而不丢目标。
# todo_write/todo_read/todo_update 代码略(保持原样)
三者形成一个“外部工作记忆”:todo_write 起始承诺完整计划;todo_update 逐步打勾;todo_read 随时查看进度。这样,模型不能“悄悄跳过步骤”,每一步都有持久化状态。
系统提示(system prompt)也被加强为“强制先规划再执行”:
# SYSTEM 示例略(保持原样)
注意 “ALWAYS” 这个词是“承重字”。没有它,模型“有时会规划”;有了它,模型“稳定规划”。命令式、强约束的系统提示,比“建议式”更可靠。
# 交互示例(保持原样)
模型在动手前承诺了五个步骤,按序执行并验证完成。这不是“模型天生谨慎”,而是 harness 提供了“让谨慎成为最省力路径”的结构。
Claude Code 的执行轨迹还显示:在探索大型代码库时,它不会在主会话里直接读一堆文件。
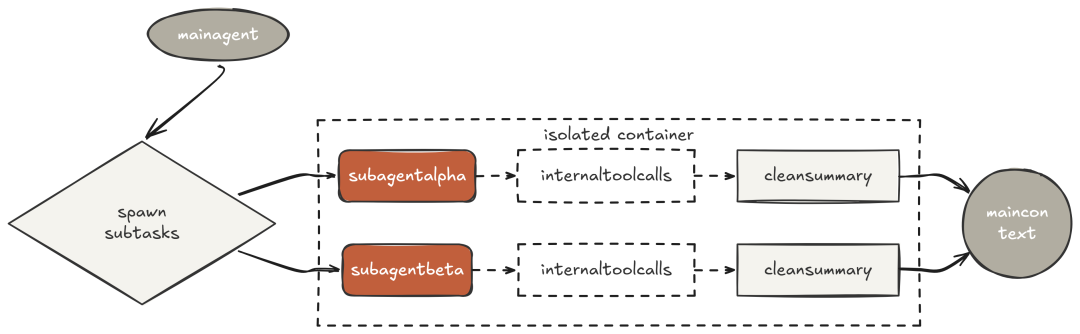
这就是子智能体上下文隔离,支撑 Claude Code 能在“任意大”的代码库上工作,而不让主对话窗口被噪声填满。所有“与最终答案无关”的中间产物,都留在子智能体上下文中,任务结束即丢弃;父会话只为“最终有用”的摘要付费。
实现方式是:每个子智能体有“完全独立”的 messages[]。父子之间唯一共享的是“子智能体的最终文本输出”。
# 子智能体 spawn 代码略(保持原样)
子智能体使用与父体“完全一致”的循环与工具;不同只是它的 messages[] 从空开始,且 system prompt 更聚焦。结束时丢弃中间过程,只返回总结文本。
把它注册成一个工具,让模型“自己决定何时使用”。
# 工具注册与 DISPATCH 示例略(保持原样)
测试如下:
# 交互示例(保持原样)
父会话只包含一次工具调用;子智能体内部跑了 25 次。父会话上下文仅增长一个段落摘要。若无隔离,父会话会累积 25 次读文件,对后续推理形成干扰。
隔离让主智能体始终在“抽象层级正确”的上下文中思考。
第三阶段关注“认知基础设施”:智能体跨越单次会话,按需加载领域知识;在“推理退化前”压缩历史;落盘持久化任务状态以支撑进程重启后的继续。这正是 Claude Code 的 skill system、压缩器 wU2 与长期记忆文件的来源。
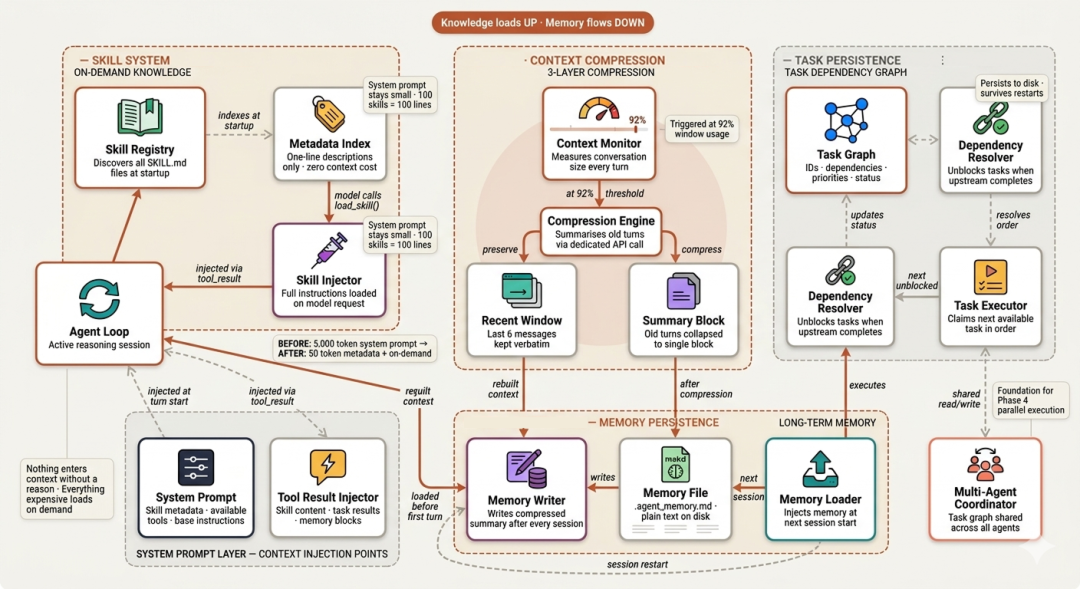
harness 工程里最耗费成本的错误之一,是“把模型可能要用的一切”都塞进 system prompt。
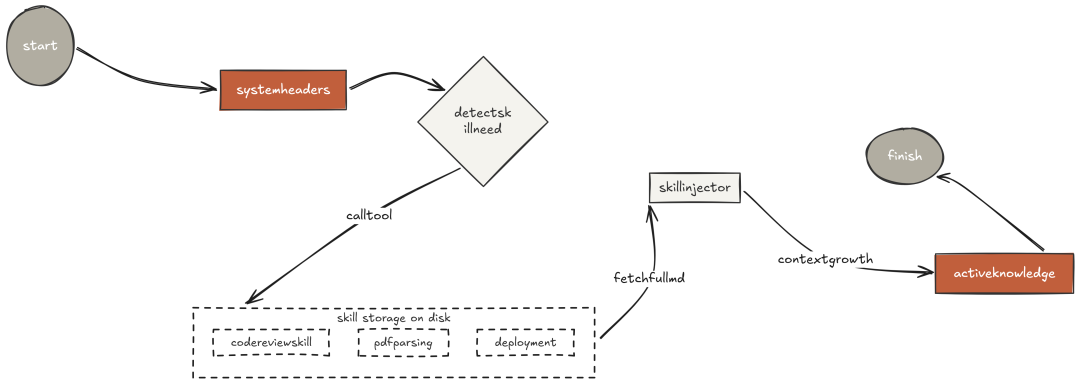
system prompt 只包含“技能的一行描述”。当模型“识别到当前任务需要该领域知识”时,它调用 load_skill(),完整指令随工具结果“即时注入到对话”中。只有“真正相关”时才为这部分上下文付费。即便安装 100 个技能,system prompt 也只是多 100 行,而不是 100 页。
技能文件有统一格式:YAML frontmatter 的元信息 + 详细操作说明。
# 目录结构与示例内容略(保持原样)
发现(discover)机制在启动时扫描目录,只读取 frontmatter,构建轻量注册表塞进 system prompt。
# discover_skills / load_skill 代码略(保持原样)
system prompt 仅“引用可用技能”,不加载正文。
# SYSTEM 构建示例略(保持原样)
测试如下:
# 交互示例(保持原样)
模型加载技能后,按结构化方法产出审查结果,带文件与行号。若无该技能,输出会不一致,缺少分类与“可部署性总结”。技能不是让模型“更聪明”,而是让它“可重复地稳定输出结构化结果”。
所有长会话最终都会撞墙:上下文窗口被工具输出、中间结果、过时对话轮次塞满。
Claude Code 的压缩器
wU2会在上下文使用约 92% 时自动触发。
它不是“丢弃历史”,而是“摘要”,以显著减小 token 体积同时保留信息。摘要会被写入磁盘 .agent_memory.md,使记忆在会话重启后依然可用。
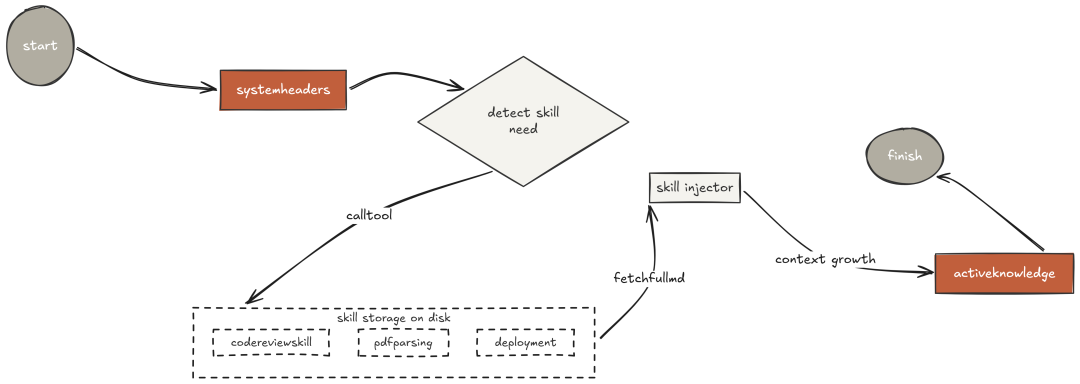
实现上分三层,按顺序处理历史:最近的消息“原样保留”;更早的消息“合并为单个摘要块”(通过一次专用压缩调用生成);摘要“写入文件”,下次启动先加载。
# 压缩/摘要相关代码略(保持原样)
压缩在每次“模型响应回合后”基于实际大小触发,而非按时间。
会话启动时,如存在记忆文件则先加载,再进入交互。
# 交互示例(保持原样)
一次长会话后,压缩自动触发,将 18 条“文件内容、测试输出、中间推理”等合为一个摘要块。下次会话直接加载该摘要,避免每次调用都为此前 18 轮历史付费。
上下文压缩关心的是“模型记得什么”。任务图(task graph)关心的是“跨会话的承诺状态”。
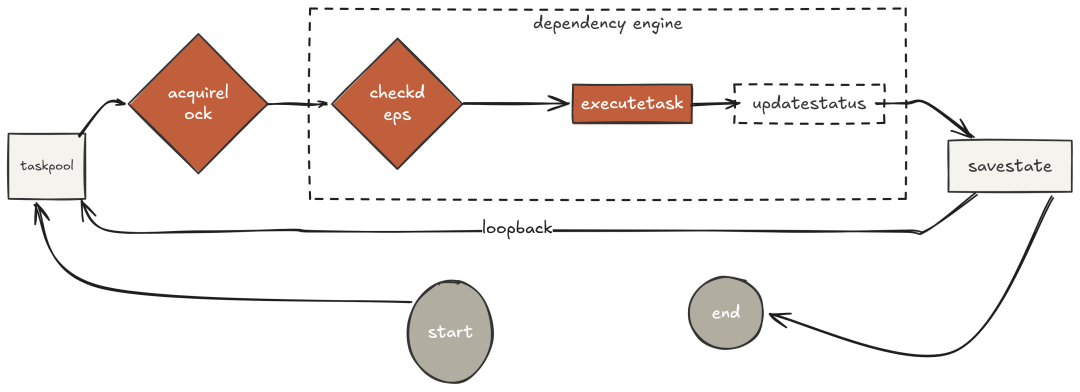
Claude Code 的 TodoWrite 是“会话级”的:关掉终端,计划就没了。本节的任务图扩展为“持久化、带依赖”的结构:每个任务有 ID、描述、状态、优先级、以及上游依赖(需先完成其前置任务)。
此图保存在
.agent_tasks.json中,能跨“进程崩溃、会话重启、机器重启”而存活。
这是第四阶段多智能体并行的地基。并行时,所有智能体“读/写同一个任务图”:依赖机制确保不会在前置未完成时执行;而第四阶段的“原子认领”确保不会被两个智能体同时抢到同一任务。
# 任务图相关代码略(保持原样)
每次读写都加线程锁是关键。否则并发 _load()/_save() 会产生“丢写”。锁使每个任务状态迁移“原子化”。
# 交互示例(保持原样)
可以看到:
这使任务图与 TodoWrite 有本质区别:后者是“单会话计划”,而任务图是“项目级、可持久化的状态”。
第四阶段用于“打破单智能体上限”:当一个上下文窗口与一个执行线程不再足够时,需要“将慢操作放后台线程而不阻塞主循环、将并行工作流委托给常驻专家智能体、用 FSM 治理智能体间通信、使任务可被自主认领、并在 git worktree 级别隔离并行改写”。
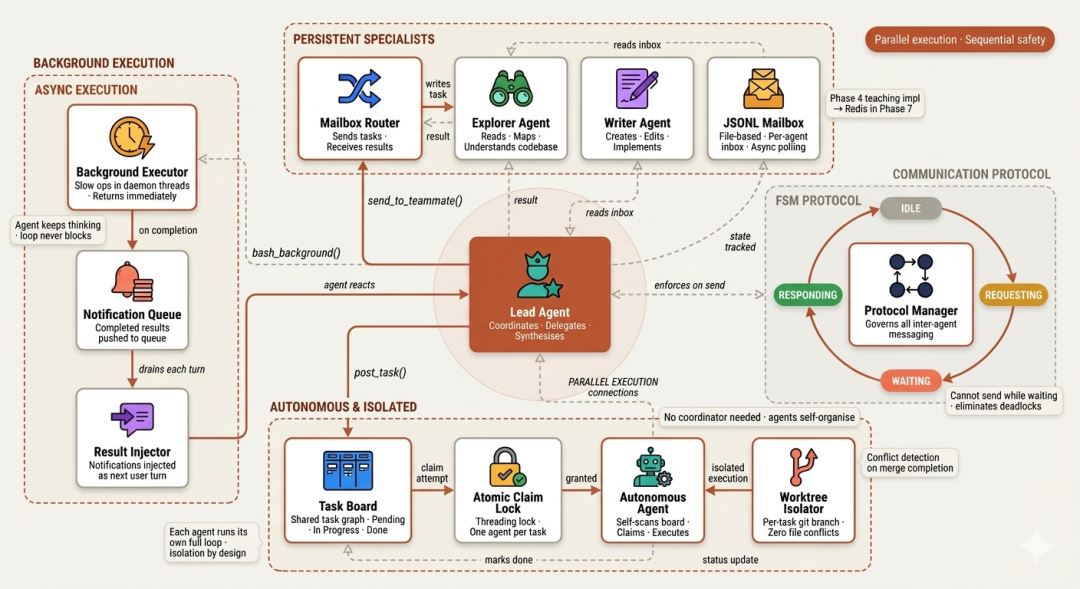
我们将从第一性原理重建 Claude Code 的并行子智能体、后台执行队列与任务委派架构。
在 Claude Code 的内部架构里,h2A 异步队列是非常实用的性能机制。当 Claude 运行测试、编译项目或执行长时间迁移时,它不会“干等”。
它把操作“推入后台”,继续规划后续步骤;当操作完成时收到“通知”。主推理循环从不被 I/O 阻塞。

如果没有这个机制,编码智能体会“被最慢的工具调用”卡住。一个 45 秒的测试意味着 45 秒的沉默——无计划、无并发、无进度。后台执行彻底消除了这个上限,将“执行”与“推理”解耦。
实现:每个后台操作一个 daemon 线程 + 共享通知队列。后台完成后将结果推入队列;主循环每回合后“排空队列”,把通知注入为用户消息,模型在下一轮自然地响应它。
# 后台执行与循环包装代码略(保持原样)
我们给了模型一个新工具 run_bash_background(),可随时发起长操作又不阻塞自己。当后台完成,模型在下一回合收到通知再响应。
# 交互示例(保持原样)
可以看到:总时长由两项的“较慢者”决定,而非两者之和。这正是 Claude Code 处理中长操作的方式。
Claude Code 的“并行子智能体”是“瞬时”的:为一次任务而生,用后即弃。但真实工程里存在“跨多任务的专业化角色”:探索、实现、测试……常驻队友可在多次委派中“累积上下文与熟悉度”。
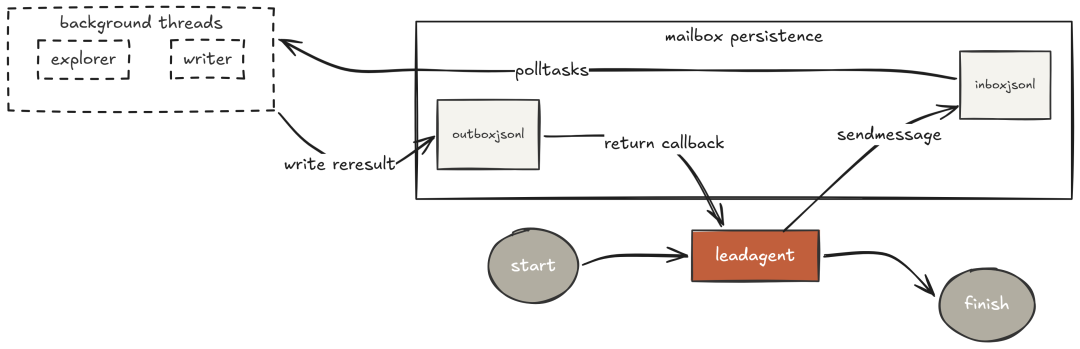
每个队友在后台线程常驻,拥有明确定义的专长,并以 JSONL 文件作为收件箱(inbox)。主智能体向其 inbox 写入任务;队友读取、用完整循环执行、再把结果写回主智能体的 inbox。全程异步,主智能体可继续工作;队友对代码库的认识也持续加深。
# Mailbox 与 teammate 循环代码略(保持原样)
测试如下:
# 交互示例(保持原样)
主智能体将“探索”交给探员、“实现”交给写手;两者并发进行、互不污染主上下文;探员累积知识,写手基于其输出精准修改;主智能体综合归纳。——这是“架构层面”的多智能体协作,而非“提示层面”的碰运气。
多智能体并发交流时,若没有协议,会出现竞态与死锁:智能体可能在未收到第一次响应前又发送了第二次请求;或两个智能体互相等待。
若无“通信协议”约束,在负载最高的时刻团队最不可靠。
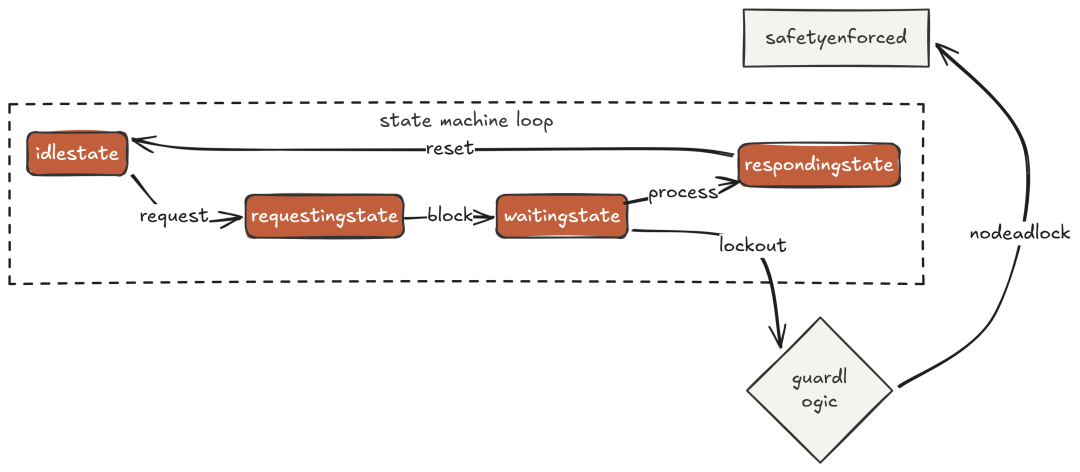
Claude Code 通过“同步工具调用”在隐式上避免了大多数问题——模型发起 dispatch_agent 并等待结果再继续。对于“异步的常驻队友架构”,我们显式引入 FSM:每个智能体有四个状态(IDLE、REQUESTING、WAITING、RESPONDING),并有一条硬规则:处于 WAITING 时不得转入 REQUESTING。这条规则就消灭了一整类的协调死锁。
# FSM 协议实现略(保持原样)
测试演示两个智能体互发请求:在等待响应期间禁止再次发送,FSM 会拦截。
# 交互示例(保持原样)
每次状态迁移被清晰记录;没有违反协议的行为出现。模型不必“推理协调”,它只需调用 delegate,协议在架构层处理协调。
FSM 解决了通信次序,但仍需“主导者”分配任务。在大规模工作(迁移全库、为数百函数生成文档、跨上千文件分析)中,主导者自己会成为瓶颈。自分配取消了“中心协调者”。
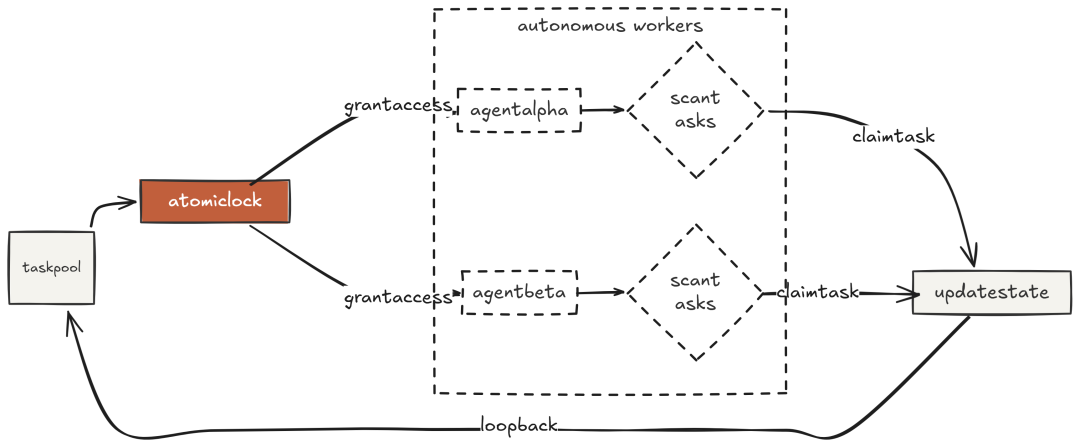
每个智能体持续扫描共享任务图,发现“未被阻塞的 pending 任务”后,用线程锁实现“原子认领”,并开始执行。锁是关键,否则两个智能体会“同时认领同一任务”。
# 原子认领与自主循环代码略(保持原样)
测试:发布多个任务(带依赖),启动两个自主智能体并行执行。
# 交互示例(保持原样)
两个智能体在任务可用时立即认领,并行推进;mypy 验证任务会在依赖满足后自动解锁。整个过程“不需要主导者在发布后再做一次分配”。——这是大规模自主工作的关键:排序智能蕴含在“依赖图”,而非“协调者”。
并行智能体在同一目录改同一文件,早晚会冲突。文件系统“不理解智能体意图”,它只看“写操作”。两个并发写,结果不可预期。
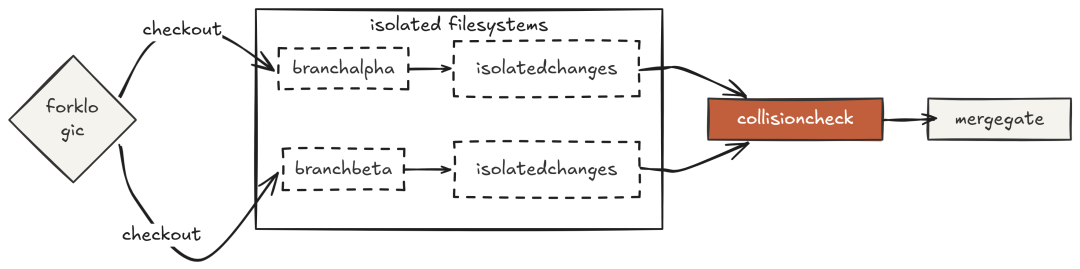
Git worktree 为每个智能体提供“独立的仓库工作区”:独立目录、独立分支、独立工作树。两个并行任务写的就是“不同目录下的不同文件”。任务完成后,harness 比对各分支改动文件集,如有重叠则提示人工复核再合并。
# worktree 创建与隔离执行代码略(保持原样)
测试:并行运行两个都修改 core.py 的任务,各自在独立 worktree 上改动、测试均通过;最后检测到“同一文件被两边修改”,提示人工合并。
# 交互示例(保持原样)
这提供了最强的隔离:并行零干扰,中期绝无互相覆盖的风险。最终冲突检测在“合并前”人工把关。
第五阶段关注“从可用到可部署”的差距:让输出实时可见(流式)、让文件工具“可撤销”(自动快照)、让权限治理“声明化”(YAML 规则)、让每次工具调用“可观察”(事件总线)、让会话“可持久化”(可恢复与分叉)。
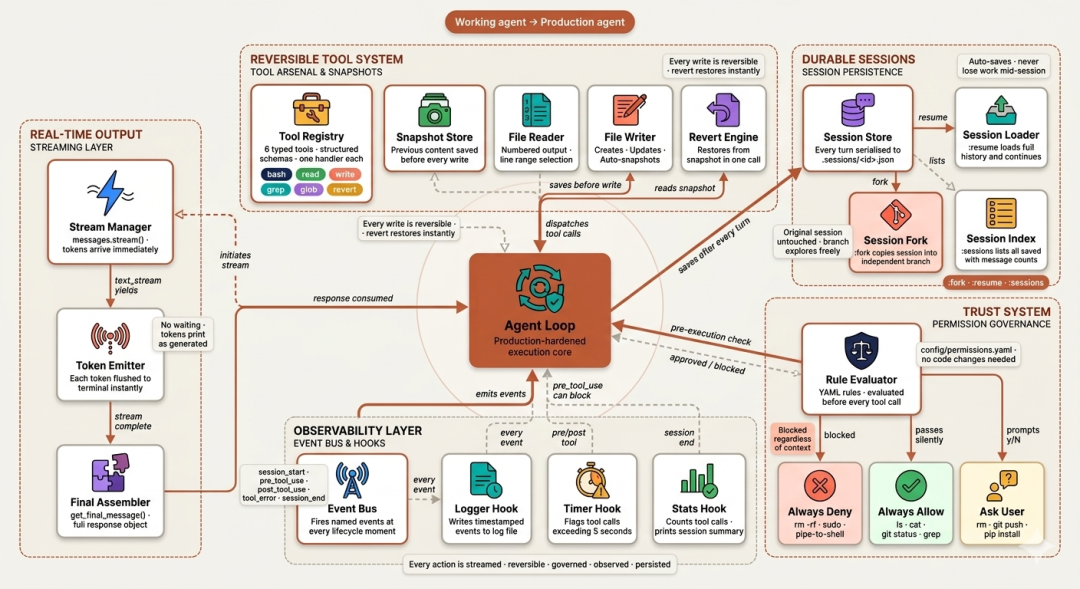
这也是 Claude Code 的信任体系、hooks 架构与会话持久化的落地实现。
在 Claude Code 中,streaming 不是“可选功能”,而是“默认方式”。对于短回复,体感差异不大;对于跨越数十次工具调用的长链路,blocking 的智能体会“沉默许久”,而 streaming 的智能体会“实时展现思路”。

从阻塞改为流式,仅需将 client.messages.create() 换为 client.messages.stream()。循环逻辑与分发逻辑“都不变”,只改“消费响应的方式”。
# streaming 循环示例略(保持原样)
stream.get_final_message() 保证“最终对象结构”与阻塞模式一致,因此下游 stop reason、tool_use 解析等完全复用。
测试:把现有循环改为流式,验证正确性并跑测试。
# 交互示例(保持原样)
可见输出逐步流出,而非一次性“卡顿后整段出现”。这正是 Claude Code 用户在每次交互中感受到的体验。
Claude Code 内置 Read、Write、Edit、Glob、Grep 等“文件专用工具”,不是因为 bash 做不到,而是因为“专用工具”为模型提供“语义更精确、结构化”的操作与输出:read 返回“带行号”的文本,方便后续 write 做“精确定位”。
grep 返回“路径与行号”,而非终端原始输出。这一结构化输出让 Claude 能做“定点修改”,而非“整文件覆盖”。
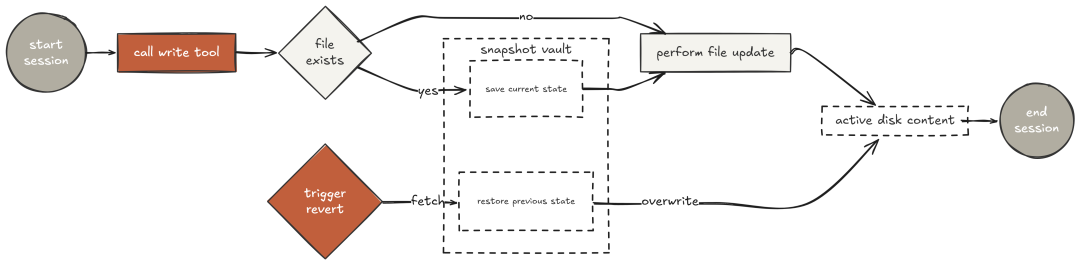
快照机制同样关键:每次 write 会“悄悄保存”旧内容;若破坏了东西,一个 revert 即可恢复。无需 git 与手工复制,由 harness 自动保证“可逆性”。
# 快照型 write/revert/read 示例略(保持原样)
测试:写入、校验、再 revert 恢复。
# 交互示例(保持原样)
模型通过带行号的 read 精准定位问题行,做出定点修复、读回确认、再跑测试。若失败,revert 一键回滚。这正是“结构化读”+“可逆写”的理想闭环。
Claude Code 的权限系统是被研究最深的架构组件之一。初次运行会询问:自动批准还是确认模式?这映射到“三层权限模型”:有的命令始终静默允许,有的永远禁止,有的需要确认。
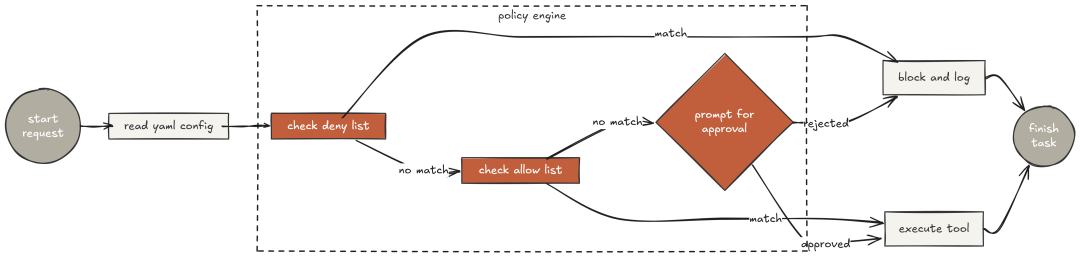
本节以 YAML 配置实现同样的“三层”模型:安全策略“在配置中”,而不在代码里。修改“需要确认”的范围,只需改配置无需发版。规则评估作为“执行前”的包装,拦截每一次工具调用。
# permissions.yaml 示例略(保持原样)
权限检查包裹在每次分发调用之前。
# check_permission 示例略(保持原样)
测试如下:
# 交互示例(保持原样)
两次敏感操作(装包、删文件)都弹出确认;ls/read/pip freeze 等匹配“always_allow”则静默通过。这与 Claude Code 的确认模式行为一致:安全操作不打断工作,危险操作需明确批准。
Claude Code 提供 hooks 系统,允许在会话生命周期的任意点位挂载自定义逻辑:工具调用前/后、错误发生时、会话结束时。团队因此能“零侵入”地加入成本跟踪、审计日志、自定义审批流程、对接监控系统等。
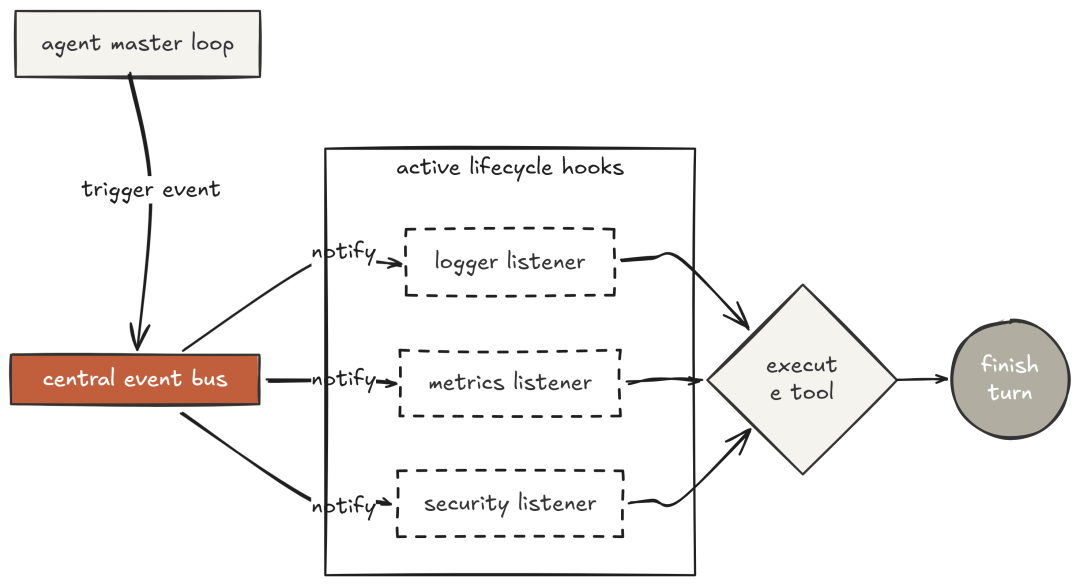
事件总线让“可观测性”成为 harness 的“结构属性”。每个关键时刻都会触发命名事件;注册的处理函数收到完整 payload;pre_tool_use 返回 {“block”: true} 还能直接阻止执行——这就是“策略层”如何在权限治理之上“干净叠加”。
# EventBus 与内置 hooks 示例略(保持原样)
主循环在工具调用前后发事件。
# agent_loop_with_hooks 示例略(保持原样)
测试:验证日志写入、慢调用告警、会话末尾统计都能正常工作,且“主循环本身没有任何观测逻辑”,它只发事件,hook 决定做什么。这正是 Claude Code 的 hooks 架构分离关注点的方式。
# 交互示例(保持原样)
一个不可恢复的会话,不足以托付长任务。若模型在一个复杂重构中已工作 30 分钟,终端却关闭,那么不仅对话没了,连“做出那些决策的思路脉络”也没了。
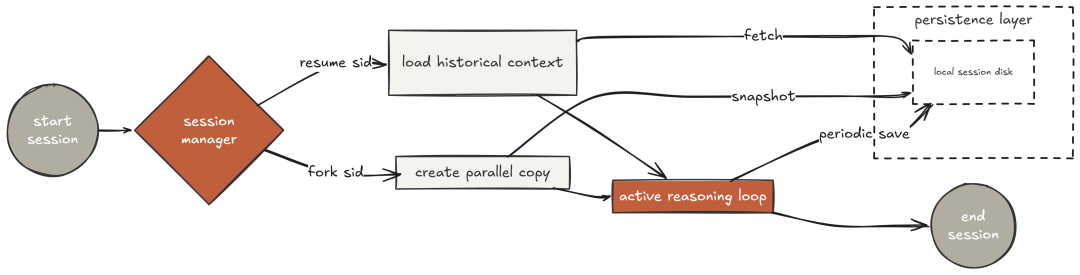
Claude Code 会在工作过程中,将“每条消息、工具调用与结果”本地化存储。本节以三个 REPL 命令实现持久化能力::resume 恢复、:fork 从任意点分支、:sessions 列表。
# 会话持久化与 REPL 命令示例略(保持原样)
测试:开始会话、保存、恢复;再基于此分叉,分别在原会话与分叉中做不同改动,确认二者互不影响。
# 交互示例(保持原样)
可以看到:会话在中断后能原样恢复(含 todo 状态与历史);分叉后两条线可独立前进。这是让长会话“可托付”的关键能力。
第六阶段聚焦“性能与可控”:让智能体从“正确”走向“又快又可操控”——用 asyncio.gather 将一回合内的多工具从串行并行化;通过“中断注入”提供实时操控;用 prompt 缓存降低重复 token 花销;并通过官方 MCP runtime 打开工具注册表与任何外部 server 对接。
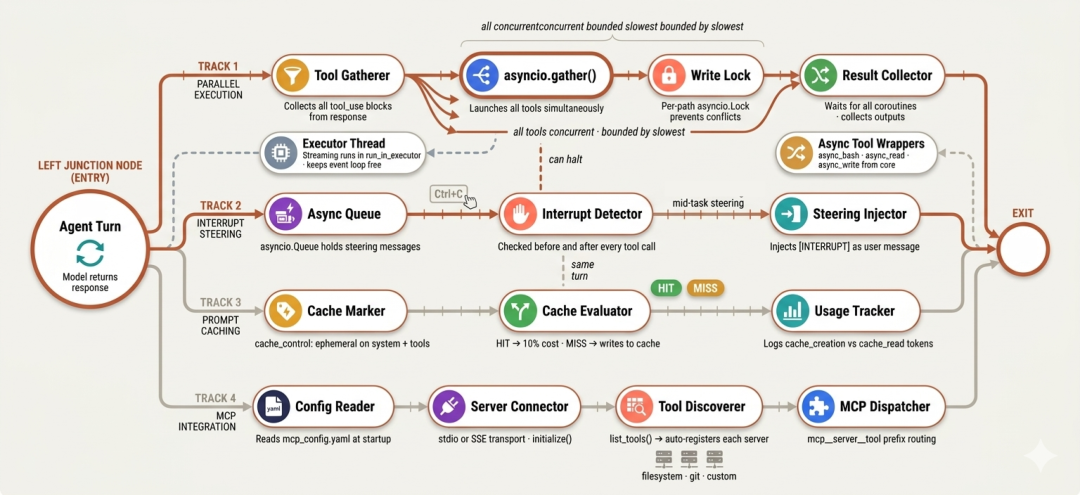
这也是 Claude Code 实现“92% 前缀复用率、并行工具执行、MCP 支持”的方式——明确且可度量。
Claude Code 的执行轨迹清楚表明:在可以并行时,它从不串行执行工具。
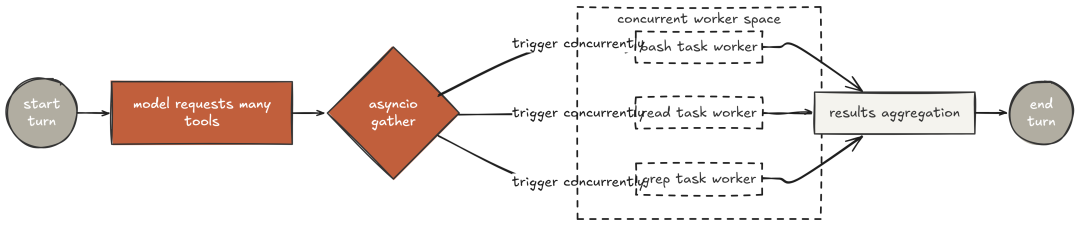
实现需将同步分发改为异步:每个工具 handler 有 async 包装;流式调用在 executor 中跑,避免阻塞事件循环;原先遍历工具块的 for 循环改为 asyncio.gather() 并行等待。
# 异步分发与循环示例略(保持原样)
bash 用 asyncio.create_subprocess_shell 真正非阻塞;文件 I/O 放到线程池执行;写操作对单文件路径加锁,防止并发写同一文件。
# async_bash/async_write 示例略(保持原样)
测试:
# 交互示例(保持原样)
多次 grep 并行、随后多次 read 与 bash 并行。模型收到一次性聚合结果,并在一次推理中整合——本应拆为多回合的工作,压缩为两回合。对于更大代码库,这种收益呈指数级放大。
Claude Code 支持你在任务进行中按 Ctrl+C 来“重定向智能体”而不丢失已完成的工作。智能体不会崩溃,而是读取中断指令,总结当前进度并等待新指示。这就是 h2A steering queue:一个与主循环并行的异步通道,随时接受外部输入。
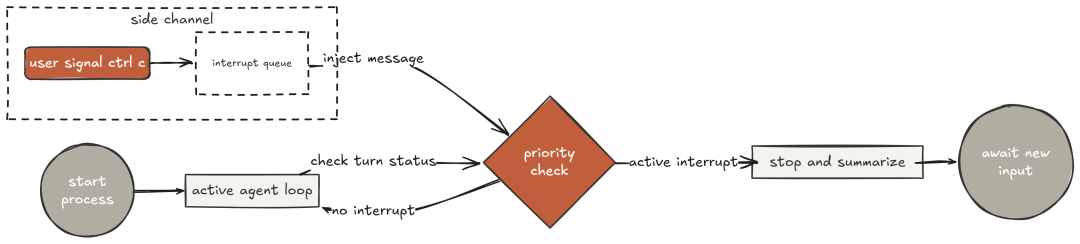
没有该机制,长任务就是“承诺”:要么等它结束、要么失败后回看。中断注入让你能在执行中途补充上下文、指令跳过或终止并总结。
# 中断队列与循环示例略(保持原样)
# 交互示例(保持原样)
中断到达后,智能体“干净地停止”,准确汇报“已完成/进行中/未开始”的状态,并按你的新指示继续。这就是 Claude Code 的交互体验:长任务“可操控”,而非“一旦开始就只能等”。
对 Claude Code 的执行轨迹逆向分析显示:内部调用中,有 92% 的 prompt 前缀得以复用。这源自“将稳定内容放在前、可变内容置于末尾”的结构化提示设计。
Anthropic 的 prompt caching 会以约 10% 的常规 token 成本来提供这些“稳定前缀”。在长会话的数百次调用中,节省显著。
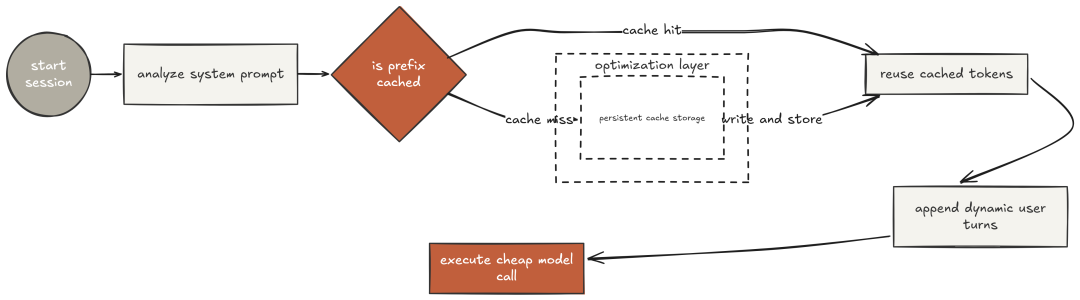
system prompt 与工具定义最稳定,几乎每轮都相同。标记为 cacheable 后,除首次外的每次调用,都会以缓存成本提供这些 tokens。
# cache_control 与统计器示例略(保持原样)
# 交互示例(保持原样)
首次写入缓存 1,847 tokens;后续调用命中缓存,约 90% 成本节省。6 次调用累计省下 ~8,310 tokens。在完整会话的上百次调用中,这就是“92% 前缀复用率”的来源。
Claude Code 原生支持 MCP:任何符合规范的 server,其工具都能成为“工具注册表”的一等公民。filesystem server 增加文件工具;git server 增加 git 操作;database server 增加查询工具。模型对它们的调用方式与内置工具“完全一致”,无需关心其本地/远端属性。
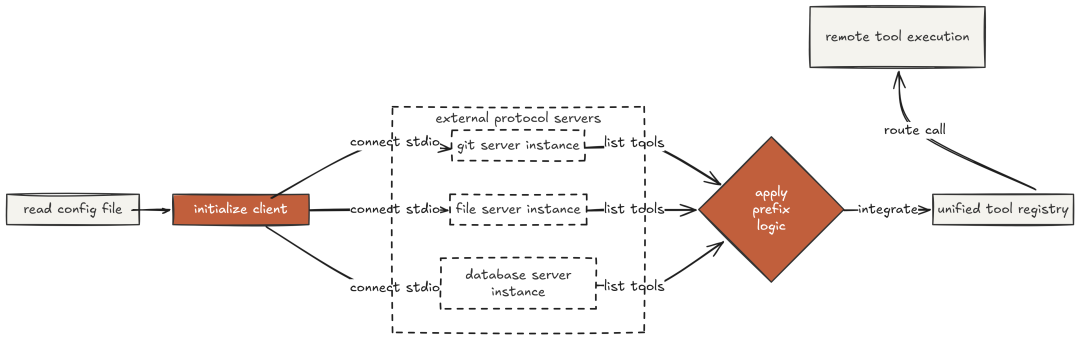
MCP runtime 从 config/mcp_config.yaml 读取配置,用官方 SDK 连接各 server,调用 list_tools() 发现工具,并以前缀 mcp
注册进 dispatch 映射,与内置工具并列。
# MCP 连接与调用示例略(保持原样)
分发路由对 MCP 与内置工具“一视同仁”,仅多了前缀判断。
# dispatch_with_mcp 示例略(保持原样)
# 交互示例(保持原样)
从模型视角看,工具注册表从 14 个增长到 28 个,仅因 server 在启动时连接成功。harness 层屏蔽了本地/远端差别,交互模式对模型透明。这正是 Claude Code 的 MCP 支持方式。
第七阶段是“以生产级替换教学实现”:将文件型 mailbox 换为 Redis pub/sub(即时、跨机、免轮询/锁);将基础 worktree 管理升级为覆盖一切边界条件的生命周期管理;并把所有机制在一个可部署的参考实现中串联起来。
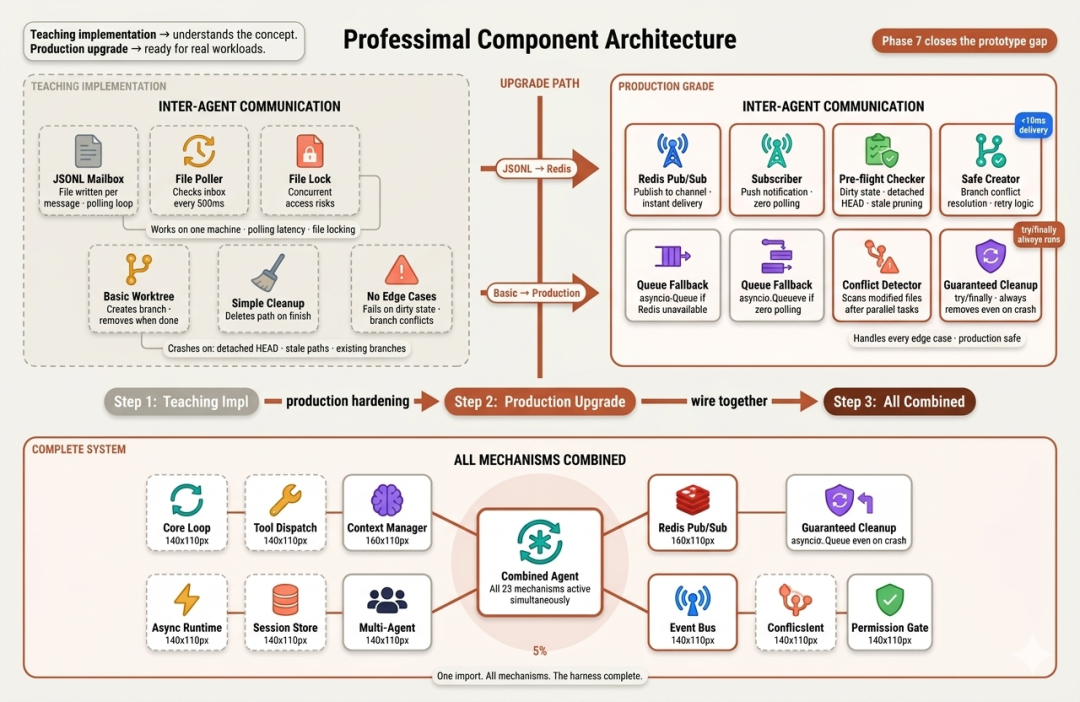
这是“从可用原型到可上生产”的临门一脚。
Phase 4 的 JSONL mailbox 用于教学尚可,但有三大生产问题:需轮询(引入延迟)、并发写需文件锁(易损 JSONL)、且仅限单机(依赖本地文件系统)。

Claude Code 内部的消息传递是“即时、无锁、跨进程”的。Redis pub/sub 恰好具备这些特性:publish 到 channel,subscriber 毫秒级收到;无需轮询、无需锁、无需本地文件。
实现以统一接口封装两种后端,队友与主智能体逻辑无需更改。
# RedisMailbox 与 QueueMailbox 示例略(保持原样)
队友循环与 Phase 4 完全一致,底层传输由 mailbox 接口屏蔽。
# teammate_loop 示例略(保持原样)
现在可以在 Redis 渠道上并行运行多个队友:
# 交互示例(保持原样)
可见:Redis 延迟 <10ms,相比 JSONL 轮询的 ~500ms,时延显著下降。在多次往返中该差距会累计成为可观的壁钟时间节省;更重要的是,Redis 后端天然支持“跨机器分布式协作”,而 JSONL 完全不行。
Phase 4 的基础 worktree 实现能“创建/移除”,但在生产碰到的边界条件上一踩就碎:未提交变更、分支已存在(上次崩溃遗留)、detached HEAD、并行分支对同一文件的冲突检测与合并提示……
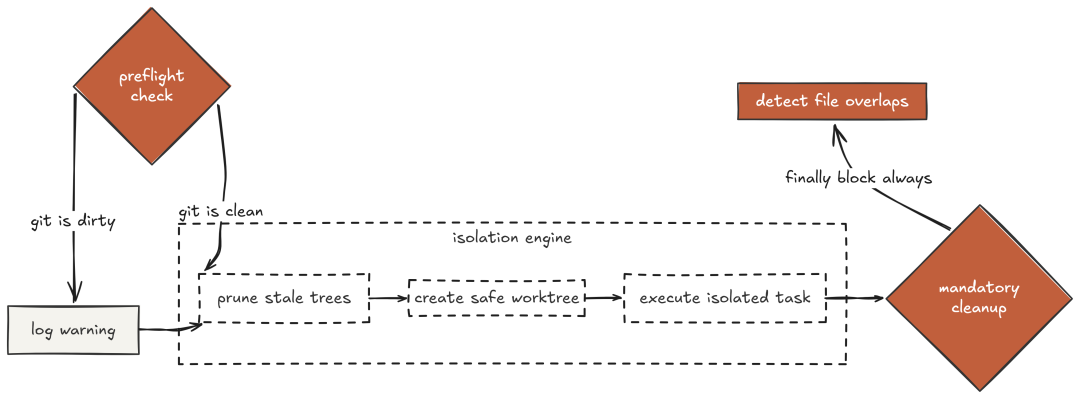
Claude Code 多靠“文件快照”规避此类问题,但 worktree 的隔离更强:一个智能体“物理上”无法影响另一个。生产级的 manager 在执行前系统性处理所有边界条件,并提供清晰错误信息。
# git 状态检查、修剪、与安全创建示例略(保持原样)
在任务执行前后,做冲突检测与安全清理,确保“即使失败也能善后”。
# detect_conflicts 与 run_task_in_worktree_safe 示例略(保持原样)
并行两任务实测:
# 交互示例(保持原样)
预检先行;任务在隔离目录中并行执行并自测通过;之后检测到“同一文件被两分支改动”,提示人工复核并保留分支。整个生命周期(含异常路径)都有明确、可预期的行为与清理。
我们将 Phase 2–4 的所有机制与 Phase 1 的共享基础整合在一处:todo 规划、任务依赖图、子智能体上下文隔离、按需技能加载、三层上下文压缩、后台任务、常驻队友、FSM 通信协议、git worktree 隔离——全部同时在线。
整合文件只有 ~280 行,因为 core.py 承担了所有“共享职责”,每个机制仅贡献“独有逻辑”。
# 汇总 dispatch 示例略(保持原样)
模拟一个复杂会话:新建“debugging” 技能、用子智能体分析任务文件中的“幽灵依赖”、后台跑测试的同时补测试……
# 交互示例(保持原样)
可以看到:技能加载塑造了调试步骤;子智能体在不污染主上下文的情况下处理大体量 JSON;后台执行与写测并行;上下文在中途自动压缩入盘。所有机制各展所长。
到目前为止,我们从最小主循环,构建到具备生产强度的多智能体系统:流式、并行、prompt 缓存、Redis mailbox、权限治理、会话持久化、官方 MCP runtime。架构干净、无重复,并有良好测试。仍有可提升空间:
- 并行孵化子智能体:当前
spawn_subagent是串行的。用asyncio.gather改造后,lead agent 可一次并发派出多个 explore 子智能体(与 Claude Code 内部一致),按并发数线性缩短探索时间 - 向量记忆库:长期记忆目前是扁平 markdown。替换为轻量向量库(如 ChromaDB),即可做“语义检索”而非“全量注入”,让项目变大时上下文仍保持聚焦
- 精细化 token 记账:缓存统计器是“按会话计数”,没有按“任务/工具类型”细分。增加成本台账,便于定位最昂贵的调用并优化
- Webhook 化事件总线:当前 hooks 仅进程内。扩展为外发 HTTP(Slack、Datadog、PagerDuty……)即可无须修改主循环接入企业监控
- 评测框架:现有测试只验证“能否正确工作”,没有衡量“完成真实任务的质量”。引入 LLM-as-a-judge,对“准确性、工具效率、计划遵循度”等指标打分,使仓库从“能跑”走向“可基准化对比”
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/264328.html