
今天很多人谈 Agent 安全,脑子里想到的还是老三样:提示注入、越狱、输出审核。但这篇论文真正想说的是,当大模型从“会回答”变成“会调用工具、会接外部知识、会自己规划任务”之后,安全问题就已经不再是单纯的内容安全问题,而是一个完整的系统攻击面问题。

论文把研究对象明确限定为三类系统:带工具/API 的系统、带 RAG 的系统,以及具备自主规划或多智能体循环的系统;纯聊天问答并不在它的核心范围内。作者的中心判断也很明确:Agentic AI 的攻击面,与传统 LLM 应用相比,已经发生了质变。
换句话说,这篇文章不是在重复“Prompt Injection 很危险”这种大家已经知道的共识,而是在进一步追问:为什么 Agent 一旦接入工具、记忆、检索和执行环境,整个安全边界就会被打穿?
作者给出的答案是,Agent 系统把模型、数据、工具、状态、外部服务这些原本相对分离的部件串成了一条连续执行链。于是攻击者不再只是“诱导模型说错话”,而是可以借助这条链路,逐步走向越权调用、数据泄露、代码执行、资源滥用、记忆污染,甚至供应链投毒。
论文最有价值的地方,是先画出了一张 Agent 系统的参考架构图。图里把一个典型 Agent 系统拆成了用户入口、Planner/Orchestrator、LLM Core、Policy/Guards、Memory Store、Retriever、Tool Broker、Secrets/Vault,以及下面的浏览器工具、代码执行沙箱、文件 I/O、外部 API、RAG Indexer、Vector DB、文档源等模块;更关键的是,作者在这张图上进一步标出了AS1-AS10 十个攻击面,分别对应用户输入、检索内容进入、工具调用序列化、沙箱边界、文件 I/O、API Token 范围、索引器、检索/ANN、长期记忆、审计遥测等关键位置。论文强调,这些位置才是 Agent 安全真正需要逐个审视的“信任边界”。
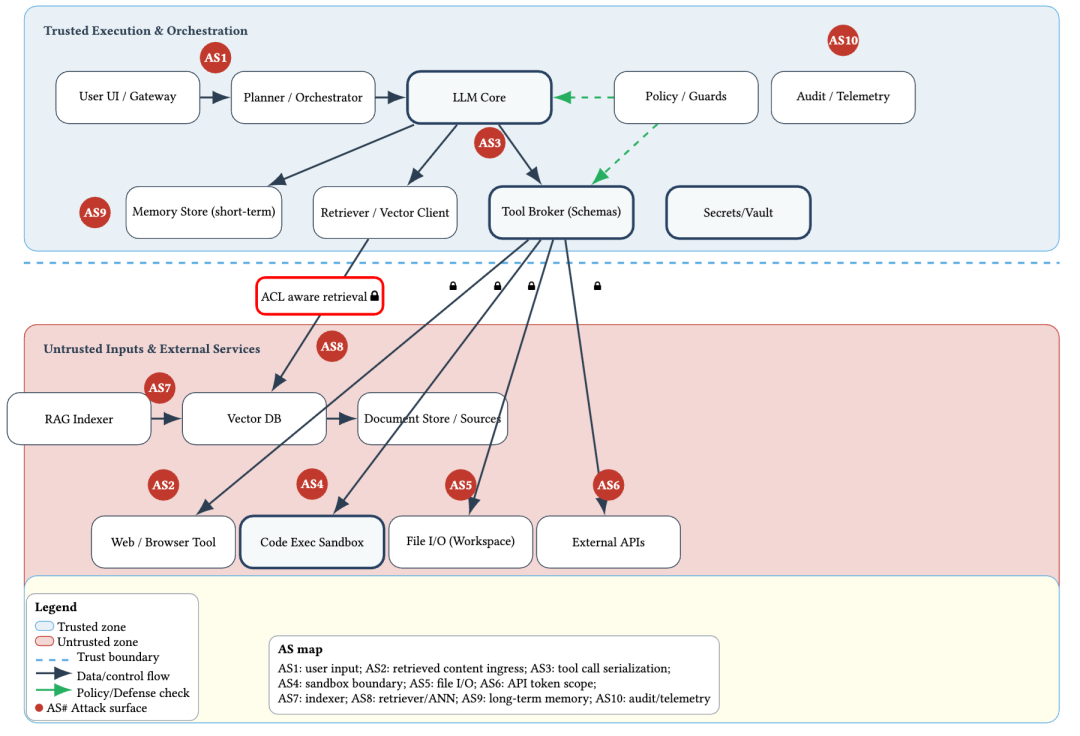
这张图的意义很大。它把很多团队嘴里的“Agent 很复杂、风险很多”,变成了一张可以真正拿去做架构审计的图。你会发现,问题根本不只在模型本身,而在模型和外部世界之间那些被打通了的接口。 一段恶意文本本身并不可怕,可怕的是它被当成了工具参数、文件操作、API 请求、向量库污染内容,或者被写入长期记忆之后,在未来某个时刻再次触发。这种“从文本到动作”的跨层传导,正是 Agent 安全与传统聊天机器人安全的本质区别。
与 Figure 1 配套的 Table 1 也很重要。表格把攻击面按 Prompt/Content、RAG(Indexing/Retrieval)、Tool、API/Cloud、State/Memory、Multi-agent、Supply chain 几个维度展开,并同时标注了各自常见前置条件、对应攻击路径、持久化方式和影响结果。它其实在告诉读者:Agent 风险不是几个孤立点,而是一组可拼接、可级联、可持久化的系统性向量。
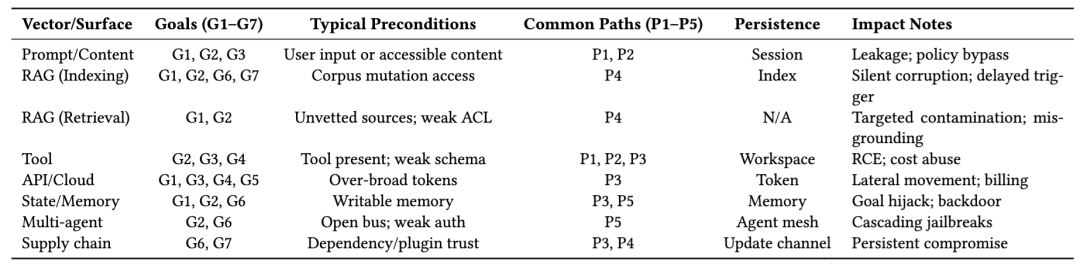
论文把攻击目标拆成了 G1 到 G7 七类,包括数据泄露、完整性破坏/安全绕过、权限提升、资源滥用/拒绝服务、欺诈与财务损失、持久化/后门植入、供应链破坏。这个分类的价值在于,它把 Agent 风险从“内容层”往“系统层”和“业务层”推进了一步。比如在传统聊天场景里,大家重点关心的是模型有没有说不该说的话;但在 Agent 系统里,攻击者真正追求的往往不是一句违规回复,而是拿到更高权限、调用更危险的工具、污染未来任务流程,或者把恶意能力固化下来。
尤其值得注意的是 G3、G6、G7 这三类目标。
G3 是权限提升,意思是攻击者原本只有“输入一句话”的能力,却借助 Agent 的工具和权限,最终撬动了代码执行、管理员 API、内部文档等更高价值资源;
G6 是持久化,意味着恶意影响不会随着本轮对话结束而消失,而是进入记忆、索引、文件、工件甚至系统配置中;
G7 则是供应链破坏,指向框架、插件、依赖、模型权重、嵌入服务等更上游的位置。论文明确指出,Agent 安全的问题不只是“这次回答有没有错”,而是系统有没有被攻陷、能力有没有被劫持、后门会不会在未来继续生效。
这也是为什么我觉得这篇论文很适合企业安全团队看。因为企业做 Agent 落地时,真正要面对的绝不是“是否会输出一句不合规的话”这么简单,而是更接近 IAM、最小权限、工具白名单、检索边界、工作流授权、供应链治理这些更“传统安全”的问题。论文实际上是在提醒行业:Agent 安全的重心,正在从文本审核转向权限治理与执行控制。
建议引用原文图表:Figure 2、Figure 3
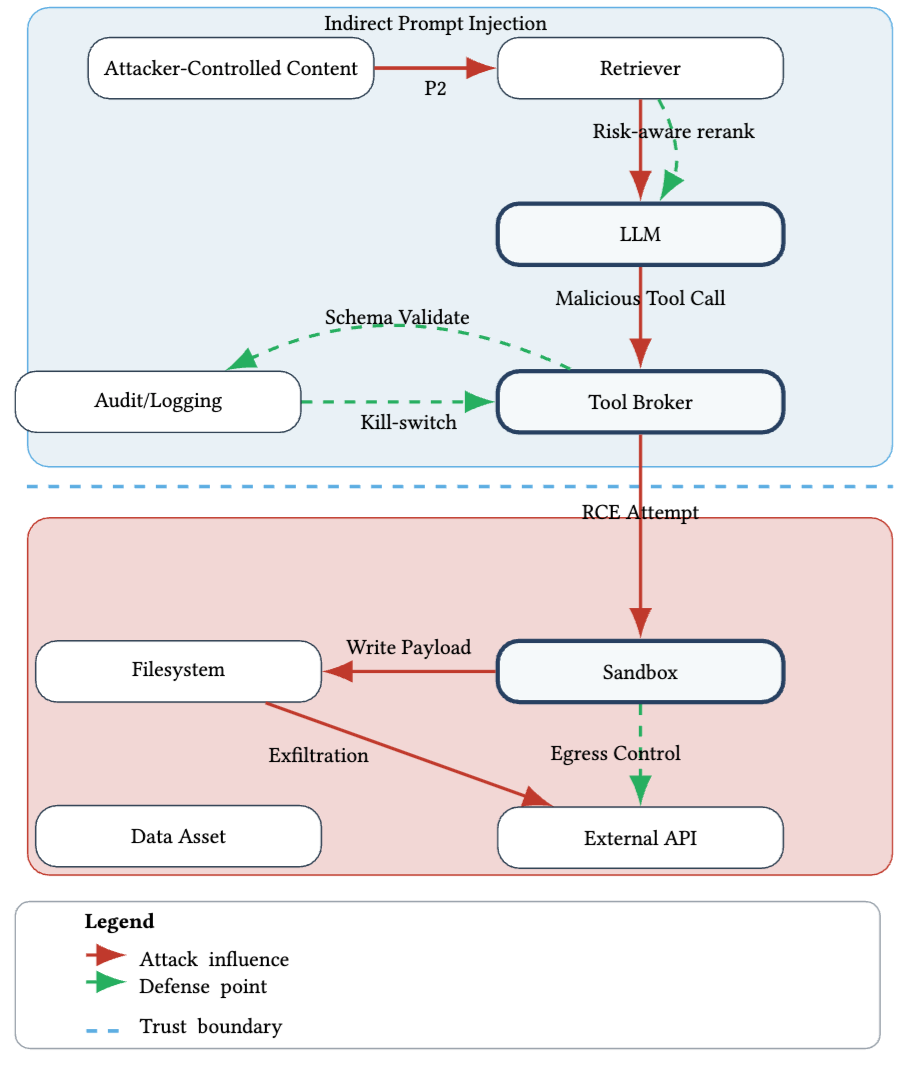
论文提出了一个很关键的“因果威胁图”思路。Figure 2 里,作者把攻击过程画成了一条从攻击者控制内容、经过检索和模型、再走到工具代理、文件系统、外部 API、数据资产的因果链路,中间还标出了可以被拦截的防御点,比如 risk-aware rerank、schema validate、egress control、kill-switch 等。这个图想表达的意思非常直接:安全不是只盯着输入端,而是要看攻击能否沿着因果链逐步穿透到最终效果层。
如果说 Figure 2 讲的是“攻击如何穿透”,那么 Figure 3 讲的就是“攻击通常怎么走”。论文抽象出五条代表性路径,其中最核心的是4条:
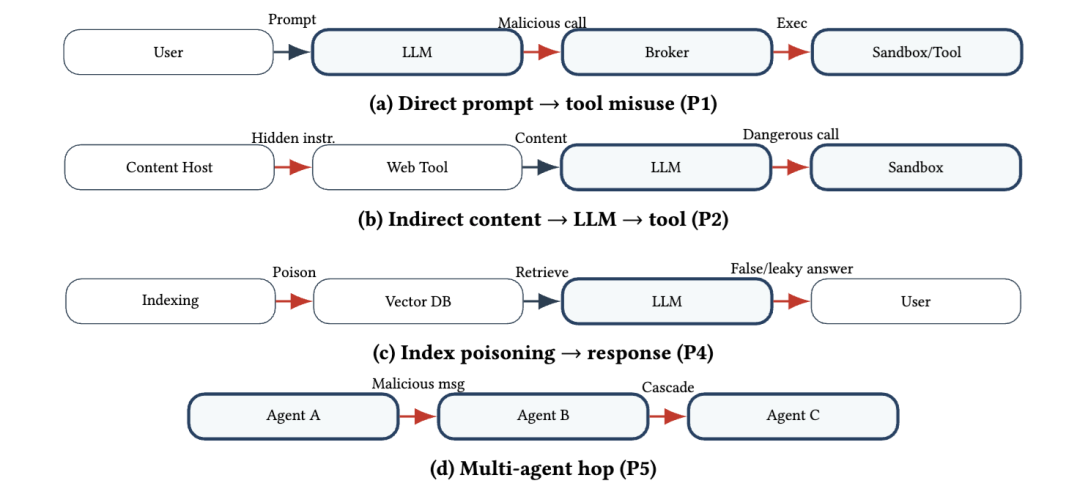
第一条是P1 直接提示词 -> 工具滥用,也就是用户直接诱导 Agent 调用危险工具;
第二条是 P2 间接内容 -> LLM -> 工具,恶意指令被埋进网页、邮件、文件、PDF 中,先进入检索或浏览流程,再诱导模型调用工具;
第三条是 P3 跨工具跳转,一个工具为另一个工具铺路,比如先社工骗到凭证,再调用云 API;
第四条是 P4 索引投毒 -> 检索 -> 响应,恶意内容先污染知识库,等未来查询命中后再触发;
第五条是 P5 多智能体跳转传播,一个受影响的 Agent 再把恶意消息扩散给其他 Agent。论文强调,现实中的很多事故并不是由一个单点漏洞触发,而是由多条链路串起来共同完成的。
这一点特别重要。因为它意味着我们不能再用“输入安全”“输出安全”这种二维思路去理解 Agent。Agent 的核心风险在于:不可信输入能否借助模型、检索、工具和状态管理,最终转化成高权限动作。 一旦理解了这一点,就会知道为什么单纯加一个 system prompt、加一个输入审核、加一层输出拦截,远远不够。
这篇论文在证据综述部分给了一个非常强的判断:“LLM+tools implies RCE risk unless proven otherwise”,也就是“只要接了工具,默认就应该按可能导向代码执行或危险动作来评估,除非你能证明不是。” 作者引用的证据包括:LLMSmith 报告了 11 个 Agent 框架中的 19 个 RCE 漏洞;间接提示注入不仅可行,而且很难彻底消除;RAG 也并不天然更安全;多智能体协作还会进一步放大攻击传播半径。论文据此得出的判断是,表层护栏只能挡住浅层问题,真正有效的仍然是结构性控制。
今天不少团队仍然把 Agent 安全理解为:前面做一点内容检测、system prompt 里多写一点规矩、后面再接一个安全大模型兜底。问题在于,这些手段的对象仍然是“文本”,而 Agent 的核心风险早已变成了“动作”。 当模型可以执行 shell、读写文件、操作知识库、连接云 API、调用支付或办公系统时,风险重心就已经转向动作授权、能力分级、参数约束、运行隔离和异常回滚。
从这个角度说,这篇论文真正推动的是一种视角转换:不要再把 Agent 看成一个更会说话的大模型,而要把它看成一个会消费不可信输入、会调用高价值资源、会持续演化状态的半自动执行系统。 一旦你从“系统安全”而不是“内容安全”去看,很多工程优先级就会完全不同。
很多 Agent 安全论文的问题是,讲了半天攻击和防御,但没有给出可操作的评估指标。这篇文章往前走了一步,提出了一组更适合 Agent 场景的指标,包括 Unsafe Action Rate(UAR)、Policy Adherence Rate(PAR)、Privilege-Escalation Distance(PED)、Time-to-Contain(TTC)、Patch Half-Life(PHL)、Retrieval Risk Score(RRS)、Out-of-Role Action Rate(OORAR)和 Cost-Exploit Susceptibility(CES)。其中,UAR 用来看不安全动作触发率,PED 用来衡量从不可信输入到高权限动作之间隔了几层边界,RRS 用来评估检索结果本身的风险,OORAR 则用来检测 Agent 是否做了超出自身角色合同的动作。
这组指标背后其实隐含着一个非常清晰的产品方向:Agent 安全评测不能再只测“它会不会说错话”,而要测“它会不会做错事”。 这意味着评测对象要从单轮对话,转向执行轨迹、工具调用链、策略判定记录、检索结果包和成本日志。也就是说,未来真正成熟的 Agent 安全平台,应该越来越像“执行行为审计平台”而不是“文本内容审核平台”。
对国内做大模型安全产品的团队来说,这一点尤其值得吸收。因为如果你还停留在纯输入输出分类器的能力边界里,那你能覆盖的只是 Agent 风险里最表面的一层。真正的高价值机会,其实在工具调用审计、策略执行网关、检索风险建模、运行时越权检测、角色越界检测、异常闭环处置这些更深的能力上。
论文在附录里把防御按作用位置分成了几层:摄取前/索引前防御、推理时防御、Agent 逻辑防御、基础设施防御,以及监控与响应。
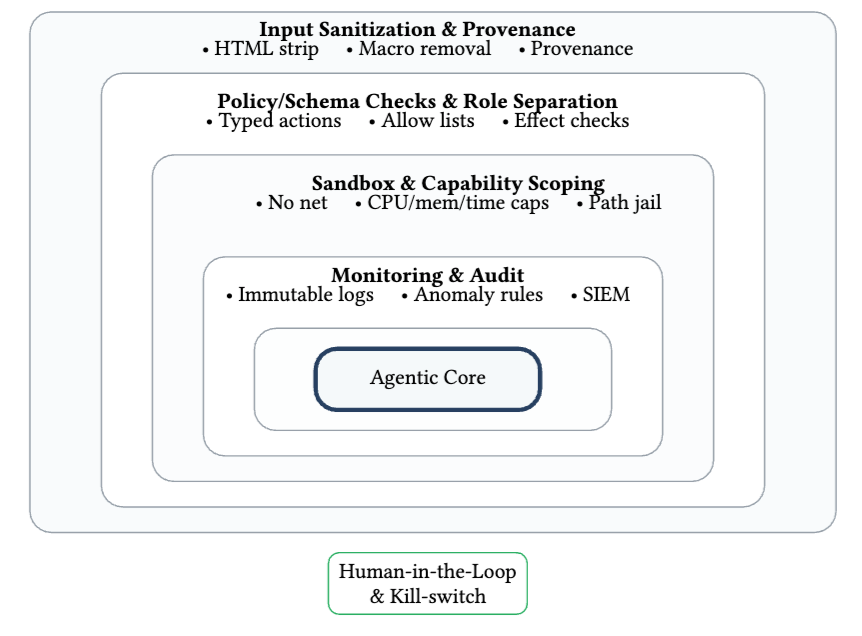
作者明确说,没有哪一个控制点可以单独解决问题,部署 Agent 系统必须采用 defense-in-depth。具体来说:
- 在数据层,要对 HTML、PDF、Office 等内容做最小化和规范化处理,去掉脚本、宏和自动执行逻辑;
- 在检索层,要做来源可信度和 ACL 感知检索;
- 在工具层,要采用严格 schema、allow-list 和 effect checks;
- 在执行层,要做沙箱隔离、无网/限网、CPU/内存/时间限制、路径隔离;
- 在运行期,则要有不可篡改日志、异常规则、SIEM、人工接管和 kill-switch。
更有意思的是,论文最后给了一个部署手册式的 Appendix B。这里面讲得非常工程化:上线前先做 threat modeling;能力按最小权限逐步放开;prompt 和 policy 要明确区分 user/system/retrieved roles,不能把秘密写进 prompt;供应链上要锁版本、看 CVE、做 SBOM;上线前要做覆盖 prompt injection、schema abuse、RAG poisoning、connectors 的红队测试;上线后则要按 UAR、PAR、PED、TTC 等指标持续追踪,并把能力变更当成生产变更来做风险评审。这个附录其实已经不是“论文建议”,而是一个简化版的 Agent 安全部署 checklist。
今天很多公司在做 Agent 落地时,容易有一个误区:认为只要模型本身足够强、提示词写得足够严、前后加一点护栏,就可以把系统安全问题压下去。
这篇论文实际上是在提醒行业,Agent 的难点从来不只在模型,而在“模型接入真实世界”之后,系统边界如何被重新定义。 一旦工具、知识库、工作流、外部 API、记忆机制都被接进来,攻击面自然也会同步扩张。安全工作的重点,必然从“模型回答对不对”转向“系统有没有被误导执行、越权调用、长期污染和跨节点传播”。
所以,这篇论文最值得记住的一句话,不是“Prompt Injection 很危险”,而是:Agent 安全的主战场,正在从模型内容层,迁移到权限、检索、工具、状态和执行链路。谁还把 Agent 安全理解成“提示词加几条规矩 + 输入输出过一遍分类器”,谁就还停留在 Chatbot 时代。
这篇 SoK 的厉害之处,不在于提出了某个石破天惊的新攻击,而在于它把过去两三年 Agent 安全领域零散出现的 prompt injection、RAG poisoning、tool abuse、memory poisoning、多智能体传播和供应链破坏,第一次比较完整地装进了一套统一框架里。
它画出了攻击面、给出了攻击目标、梳理了攻击路径、总结了证据、提出了指标,还顺手给了一版部署手册。对于想做 Agent 安全产品、Agent 平台治理、企业级智能体落地的人来说,这样的论文未必最“炸裂”,但往往最有用。
如果要用一句话总结这篇文章,我会说:
它不是在告诉你 Agent 有多危险,而是在告诉你,Agent 为什么必须按一个高危的复合系统来治理。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/263752.html