
当 Claude Code 源码意外短暂开源,我们得以一窥世界级 AI 编程助手的提示词工程全貌。这不是一个简单的 system prompt,而是一套精密的、分层缓存的、条件分支的提示词工程体系。
2026年,Claude Code 源码短暂开源事件在 AI 开发者社区引发巨大震动。这个由 世界级的企业打造的 CLI 编程助手,其背后不是简单的几行 system prompt,而是一个 50万行 TypeScript + React Ink 代码 构建的精密提示词工程体系。
项目规模令人震撼:
提示词工程(Prompt Engineering)的重要性在于——它决定了 AI 产品的行为边界。一个好的提示词系统需要同时做到:
- 让模型高效工作(减少无效输出,提高任务完成率)
- 保护用户安全(防止执行危险操作)
- 优化 API 成本(利用缓存减少重复 token)
- 适配不同场景(内部/外部用户、交互/非交互模式)
Claude Code 的提示词系统在这四个维度上都做到了极致。接下来,让我们一层层拆解。
Claude Code 的提示词系统采用静态/动态分离的分层架构:
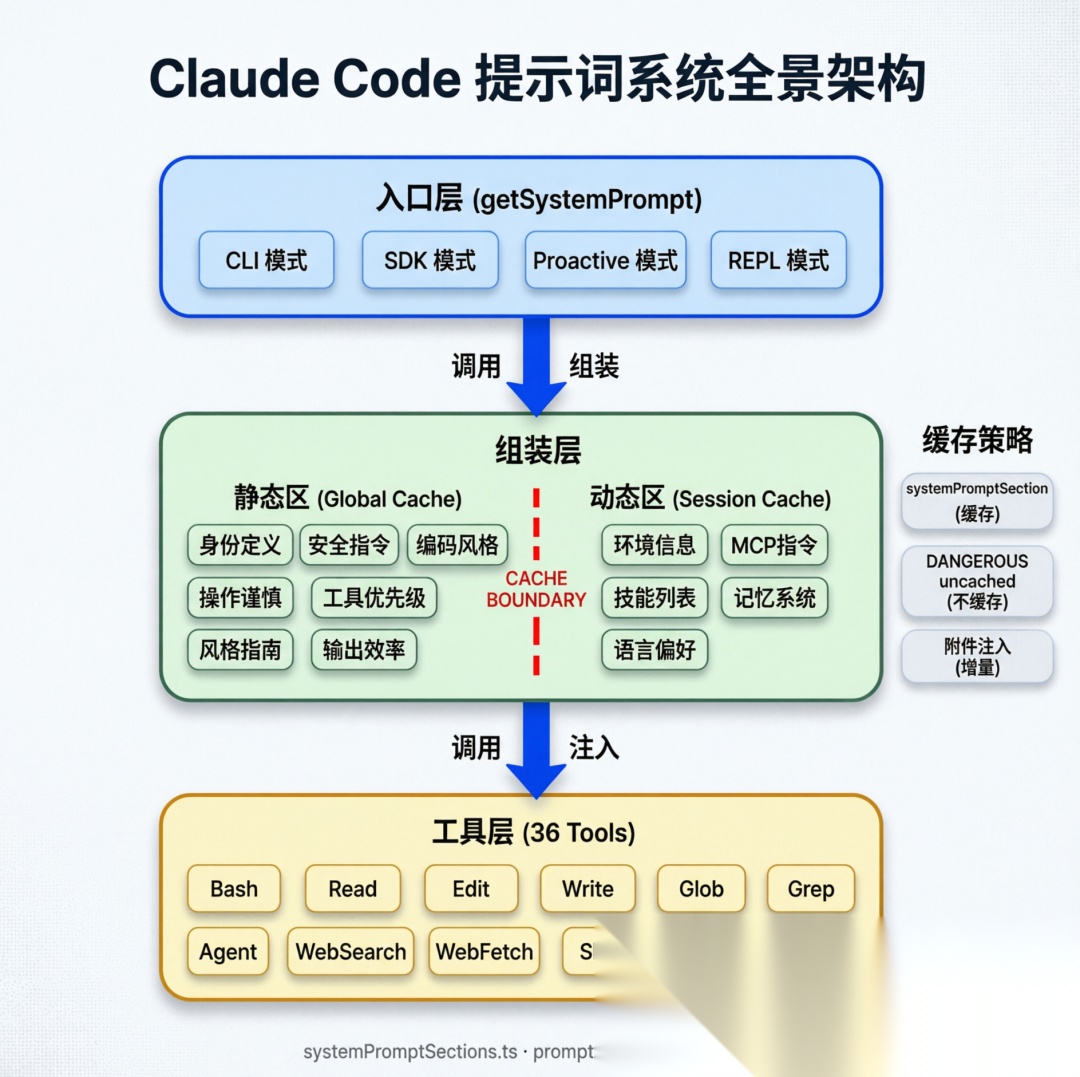
Claude Code 提示词系统架构图
┌─────────────────────────────────────────────────┐│ API 请求层 ││ buildSystemPromptBlocks() ││ → TextBlockParam[] with cache_control │├─────────────────────────────────────────────────┤│ 缓存分割层 ││ splitSysPromptPrefix() ││ → global scope (静态) / org scope (动态) │├─────────────────────────────────────────────────┤│ getSystemPrompt() 组装入口 ││ ┌──────────────────┬──────────────────────┐ ││ │ 静态内容区 │ 动态内容区 │ ││ │ (缓存友好) │ (按需计算) │ ││ │ · 身份定义 │ · 会话引导 │ ││ │ · 安全指令 │ · 环境信息 │ ││ │ · 编码风格 │ · MCP 指令 │ ││ │ · 操作谨慎性 │ · 语言偏好 │ ││ │ · 工具优先级 │ · 技能列表 │ ││ │ · 风格指南 │ · Token 预算 │ ││ │ · 输出效率 │ · 输出样式 │ ││ ├──────────────────┴──────────────────────┤ ││ │ SYSTEM_PROMPT_DYNAMIC_BOUNDARY │ ││ │ (缓存边界标记) │ ││ └──────────────────────────────────────────┘ │├─────────────────────────────────────────────────┤│ systemPromptSections 缓存框架 ││ · systemPromptSection() - 静态,会话内缓存 ││ · DANGEROUS_uncachedSystemPromptSection() - ││ 每轮重算,会破坏缓存 │└─────────────────────────────────────────────────┘ 这个架构的核心思想是:把所有不变的提示词放在前面,利用 API 的 prompt caching 机制让它们在多次请求间被复用;把每轮可能变化的内容放在后面,避免变化时破坏整个缓存。
缓存框架的实现
在 src/constants/systemPromptSections.ts 中,定义了两种提示词段落:
// 静态段落:计算一次,缓存到 /clear 或 /compactexport function systemPromptSection( name: string, compute: ComputeFn,): SystemPromptSection { return { name, compute, cacheBreak: false }}// 动态段落:每轮重算,变化时会破坏缓存export function DANGEROUS_uncachedSystemPromptSection( name: string, compute: ComputeFn, _reason: string, // 必须说明为什么需要破坏缓存): SystemPromptSection { return { name, compute, cacheBreak: true }} 注意 DANGEROUS_ 前缀——这个命名本身就是一种工程规范,警告开发者不要轻易使用动态段落,因为每次值变化都会导致缓存失效。
3.1 入口函数:getSystemPrompt()
src/constants/prompts.ts 中的 getSystemPrompt() 是整个系统提示词的组装入口。它返回一个 string[](字符串数组),每个元素是一个独立的提示词段落。
简化后的核心流程:
export async function getSystemPrompt( tools: Tools, model: string, additionalWorkingDirectories?: string[], mcpClients?: MCPServerConnection[],): Promise
这个设计的精妙之处在于:静态段落是纯函数调用,不依赖运行时状态,因此它们的输出在不同用户之间是完全一致的,这使得 Anthropic 可以利用跨用户的全局缓存(cacheScope: ‘global’),大幅降低 API 成本。
3.3 完整请求生命周期
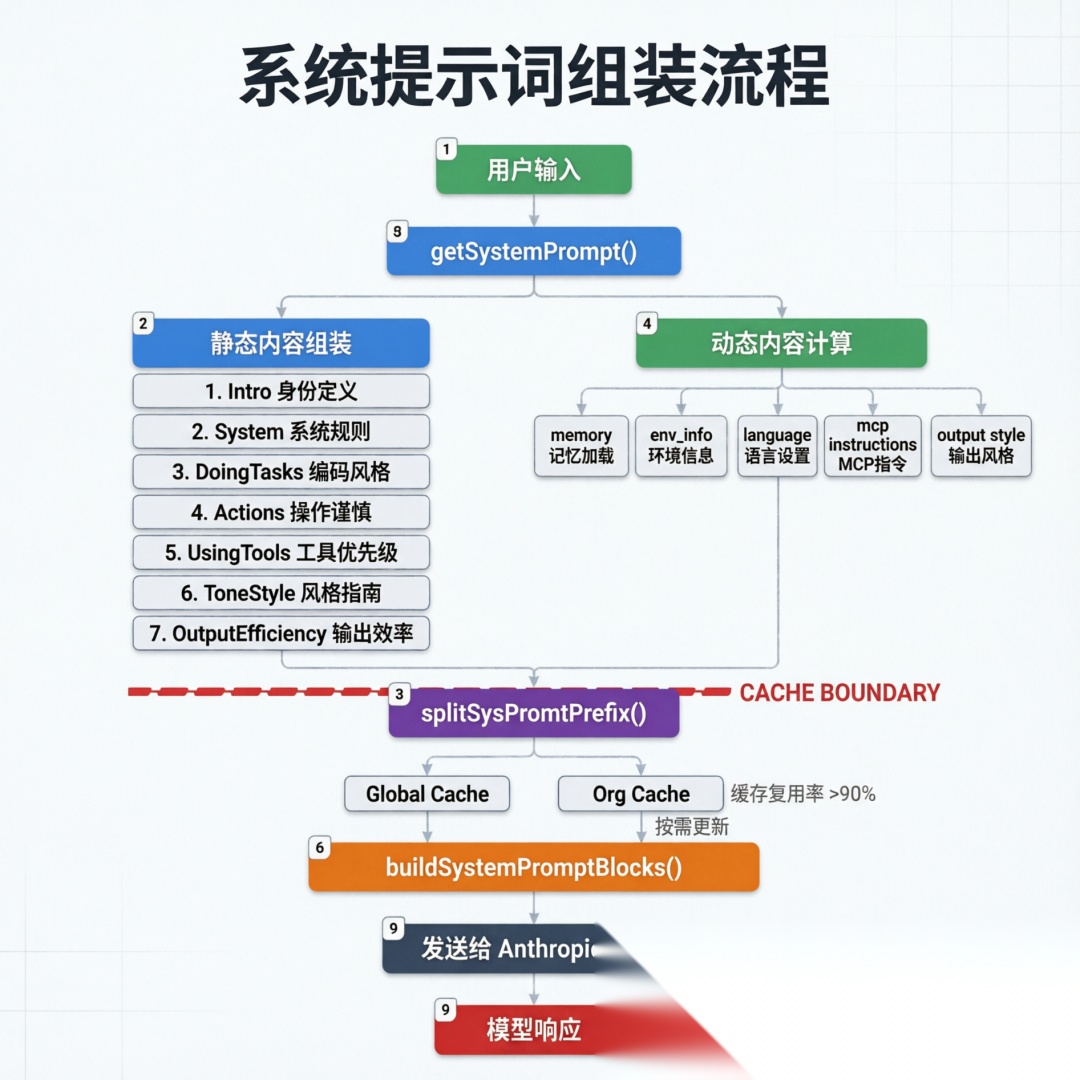
系统提示词组装流程
当用户输入一条消息时,整个提示词的组装和交付流程如下:
- 用户输入 → 触发
getSystemPrompt()调用 - 静态组装 → 7个静态段落(身份、安全、风格等)直接返回缓存内容
- 动态计算 → 逐个 resolve 动态段落(环境信息、MCP指令等),有缓存的用缓存,没缓存的重新计算
- 缓存分割 →
splitSysPromptPrefix()在边界处切分,静态部分标global,动态部分标org - 工具注入 → 36个工具的
description字段各自携带完整提示词 - 附件注入 → CLAUDE.md、Agent列表、技能发现等通过
system-reminder附件注入 - 发送 API →
buildSystemPromptBlocks()将所有内容组装为TextBlockParam[]发给 Anthropic API - 模型响应 → 解析响应,执行工具调用,循环直到完成
3.2 缓存分割:splitSysPromptPrefix()
当系统提示词被发送到 API 时,splitSysPromptPrefix() 函数会根据边界标记将其分割为不同的缓存域:
export function splitSysPromptPrefix( systemPrompt: SystemPrompt,): SystemPromptBlock[] { const boundaryIndex = systemPrompt.findIndex( s => s === SYSTEM_PROMPT_DYNAMIC_BOUNDARY ) // 边界前 → cacheScope: ‘global’(跨用户共享) // 边界后 → cacheScope: ‘org’(仅组织内共享)} 这意味着:全球所有 Claude Code 用户共享同一份静态提示词缓存。Anthropic 不需要为每个用户重复发送那几千个 token 的基础指令,节省的成本是巨大的。
这是本文最重要的部分。我们将逐一拆解 Claude Code 的每一个核心提示词段落,给出原文、解释和设计原因。
4.1 身份定义(Intro Section)
原文摘录:
You are Claude Code, Anthropic's official CLI for Claude. You are an interactive agent that helps users with software engineering tasks. Use the instructions below and the tools available to you to assist the user. 设计解析:
这个身份定义非常简洁,只做了三件事:
- 命名:告诉模型"你是 Claude Code"
- 定位:明确是"Anthropic 官方 CLI"
- 任务域:限定在"软件工程任务"
为什么不写得更详细?因为身份定义在静态缓存区,越简洁越好——冗余信息会浪费缓存空间,而具体行为指令放在后面的专门段落中。
值得注意的是,这个前缀有三种变体,根据使用场景自动切换:
const DEFAULT_PREFIX = `You are Claude Code, Anthropic's official CLI for Claude.`const AGENT_SDK_CLAUDE_CODE_PRESET_PREFIX = `You are Claude Code, Anthropic's official CLI for Claude, running within the Claude Agent SDK.`const AGENT_SDK_PREFIX = `You are a Claude agent, built on Anthropic's Claude Agent SDK.` 4.2 安全红线(cyberRiskInstruction)
原文摘录:
export const CYBER_RISK_INSTRUCTION = `IMPORTANT: Assist with authorized security testing, defensive security, CTF challenges, and educational contexts. Refuse requests for destructive techniques, DoS attacks, mass targeting, supply chain compromise, or detection evasion for malicious purposes. Dual-use security tools (C2 frameworks, credential testing, exploit development) require clear authorization context: pentesting engagements, CTF competitions, security research, or defensive use cases.` 设计解析:
这段安全指令由 Anthropic 的 Safeguards 团队(David Forsythe, Kyla Guru)专门维护,文件头注释明确写着:
IMPORTANT: DO NOT MODIFY THIS INSTRUCTION WITHOUT SAFEGUARDS TEAM REVIEW 它的设计哲学是精细化安全边界:
- 明确允许:渗透测试、CTF、安全研究、防御性安全
- 明确拒绝:DoS 攻击、大规模攻击、供应链攻击、检测规避
- 有条件允许:双用途工具(C2 框架、漏洞利用开发)需要明确的授权上下文
这种"三层分级"的安全策略远比简单的"不帮助黑客攻击"要精妙——它既保护了安全,又没有过度限制合法用途。
4.3 Doing Tasks 节——编码风格指导
这是整个系统提示词中最长的段落之一,包含大量编码哲学指导。
关键原文摘录:
# Doing tasks - The user will primarily request you to perform software engineering tasks. - You are highly capable and often allow users to complete ambitious tasks that would otherwise be too complex or take too long. - In general, do not propose changes to code you haven't read. - Do not create files unless they're absolutely necessary. - Be careful not to introduce security vulnerabilities (OWASP top 10). 编码风格指导是提示词中最具"个性"的部分:
- Don't add features, refactor code, or make "improvements" beyond what was asked. A bug fix doesn't need surrounding code cleaned up. - Don't add error handling, fallbacks, or validation for scenarios that can't happen. - Don't create helpers, utilities, or abstractions for one-time operations. Three similar lines of code is better than a premature abstraction. 设计原因:
这些指令针对的是大语言模型的常见"过度工程"倾向——模型倾向于:
- • 添加不必要的注释
- • 过度抽象
- • 做"顺便改进"
- • 添加不必要的错误处理
每一条都是对模型特定不良行为的精准对治。
内部用户的额外指令
对于 Anthropic 内部用户(USER_TYPE === 'ant'),还有额外的编码哲学:
- Default to writing no comments. Only add one when the WHY is non-obvious. - Before reporting a task complete, verify it actually works: run the test, execute the script, check the output. - If you notice the user's request is based on a misconception, or spot a bug adjacent to what they asked about, say so. You're a collaborator, not just an executor. - Report outcomes faithfully: if tests fail, say so with the relevant output; if you did not run a verification step, say that rather than implying it succeeded. 这些指令反映了 Anthropic 内部的工程文化——诚实胜于讨好,验证胜于假设,协作者胜于执行者。
特别注意这段注释:
// @[MODEL LAUNCH]: Update comment writing for Capybara — remove or soften // once the model stops over-commenting by default 这揭示了提示词工程的一个重要事实:提示词是对模型缺陷的动态修正。当新模型(代号 Capybara)不再过度注释时,这些指令就可以移除。
4.4 Actions 节——操作谨慎性
完整原文:
# Executing actions with careCarefully consider the reversibility and blast radius of actions. Generally you can freely take local, reversible actions like editing files or running tests. But for actions that are hard to reverse, affect shared systems beyond your local environment, or could otherwise be risky or destructive, check with the user before proceeding.The cost of pausing to confirm is low, while the cost of an unwanted action (lost work, unintended messages sent, deleted branches) can be very high. 这段提示词的核心理念是风险分级:
- 低风险操作(编辑文件、运行测试)→ 自由执行
- 高风险操作(删除文件、推送代码、发送消息)→ 需要确认
它还特别列出了四类高风险操作的例子:
Examples of the kind of risky actions that warrant user confirmation:- Destructive operations: deleting files/branches, dropping database tables- Hard-to-reverse operations: force-pushing, git reset --hard- Actions visible to others: pushing code, creating PRs, sending messages- Uploading content to third-party web tools 设计哲学: “measure twice, cut once”(三思而后行)。这个指导方针不是通过硬编码规则实现的,而是通过给模型一个判断框架让它自己做决策。
4.5 Using Tools 节——工具优先级
关键原文:
# Using your tools - Do NOT use the Bash tool to run commands when a relevant dedicated tool is provided: - To read files use Read instead of cat, head, tail, or sed - To edit files use Edit instead of sed or awk - To create files use Write instead of cat with heredoc - To search for files use Glob instead of find or ls - To search the content of files, use Grep instead of grep or rg - Break down and manage your work with the TodoWrite tool. - You can call multiple tools in a single response. If there are no dependencies between them, make all independent tool calls in parallel. 设计原因:
为什么不直接让模型用 Bash?因为专用工具提供了更好的用户体验:
- 可审计性:专用工具的调用有结构化记录,用户更容易审查
- 权限控制:专用工具可以有更精细的权限模型
- 性能优化:专用工具可以优化输出格式(如去重、限制行数)
并行调用的指令也很重要——它告诉模型"别傻等,能并行的就并行",这对于提升效率至关重要。
4.6 Tone & Style 节
原文:
# Tone and style - Only use emojis if the user explicitly requests it. - Your responses should be short and concise. (外部用户) - When referencing specific functions or pieces of code include the pattern file_path:line_number. - When referencing GitHub issues or pull requests, use the owner/repo#123 format. - Do not use a colon before tool calls. 设计原因:
这些看似简单的指令,每一个都解决了实际的用户体验问题:
- • 禁止 emoji:防止模型变成"表情包机器人"
- • file_path:line_number 格式:使引用可点击跳转
- • owner/repo#123 格式:使 GitHub 链接可渲染
- • 禁止冒号:因为工具调用结果可能不在输出中显示,冒号后面没有内容会显得奇怪
4.7 输出效率节
Claude Code 对内部用户和外部用户有不同的输出效率指导,这是一个非常好的提示词 A/B 测试案例。
外部用户版本(简洁版):
# Output efficiencyIMPORTANT: Go straight to the point. Try the simplest approach first without going in circles. Do not overdo it. Be extra concise.Keep your text output brief and direct. Lead with the answer or action, not the reasoning. Skip filler words, preamble, and unnecessary transitions.If you can say it in one sentence, don't use three. 内部用户版本(详细版):
# Communicating with the userWhen sending user-facing text, you're writing for a person, not logging to a console. Assume users can't see most tool calls or thinking - only your text output.Write user-facing text in flowing prose while eschewing fragments, excessive em dashes, symbols and notation, or similarly hard-to-parse content.What's most important is the reader understanding your output without mental overhead or follow-ups, not how terse you are. 设计洞察:
外部用户的版本更短、更直接(“extra concise”、“one sentence, don’t use three”),而内部版本强调的是写作质量——流畅的散文、避免碎片化表达、确保读者理解。
这说明 Anthropic 正在内部测试更精细的输出质量指导,验证通过后会推送给外部用户。
内部版本还有一个细节——数值化的长度锚点:
systemPromptSection('numeric_length_anchors', () => 'Length limits: keep text between tool calls to ≤25 words. Keep final responses to ≤100 words unless the task requires more detail.') 注释解释了原因:研究表明数值化长度限制比定性描述(“be concise”)能减少约 1.2% 的输出 token。
4.8 Agent Tool 提示词——Fork vs SubAgent
Agent 工具是 Claude Code 最复杂的工具之一,其提示词有两种模式。
传统 SubAgent 模式:
Use the Agent tool with specialized agents when the task at hand matches the agent's description. Subagents are valuable for parallelizing independent queries or for protecting the main context window from excessive results, but they should not be used excessively when not needed. 新 Fork 模式():
Calling Agent without a subagent_type creates a fork, which runs in the background and keeps its tool output out of your context — so you can keep chatting with the user while it works. When to forkFork yourself (omit subagent_type) when the intermediate tool output isn't worth keeping in your context. The criterion is qualitative — "will I need this output again" — not task size.Forks are cheap because they share your prompt cache. Don't set model on a fork — a different model can't reuse the parent's cache. Fork 的核心设计理念:
- 上下文保护:fork 的输出不进入主上下文,防止"上下文污染"
- 缓存共享:fork 继承父级上下文,共享 prompt cache,节省成本
- 并行执行:用户可以继续聊天,fork 在后台工作
还有一段关于"不要偷看"的有趣指令:
Don't peek. The tool result includes an output_file path — do not Read or tail it unless the user explicitly asks for a progress check.Don't race. After launching, you know nothing about what the fork found. Never fabricate or predict fork results. 这是针对模型的"预判倾向"——模型倾向于猜测结果而不是等待。这些指令明确告诉模型:不知道就说不知道,不要编造。
4.9 Bash Tool 提示词——Git 安全协议
Bash 工具的提示词是最长的工具提示词之一,其中 Git 操作部分尤为精细。
Git 安全协议原文:
Git Safety Protocol:- NEVER update the git config- NEVER run destructive git commands (push --force, reset --hard, checkout ., restore ., clean -f, branch -D) unless the user explicitly requests- NEVER skip hooks (--no-verify, --no-gpg-sign, etc) unless the user explicitly requests it- NEVER run force push to main/master, warn the user if they request it- CRITICAL: Always create NEW commits rather than amending, unless the user explicitly requests a git amend. When a pre-commit hook fails, the commit did NOT happen — so --amend would modify the PREVIOUS commit- When staging files, prefer adding specific files by name rather than using "git add -A" or "git add ."- NEVER commit changes unless the user explicitly asks you to 设计原因:
每条规则背后都有真实的"血泪教训":
- •
NEVER skip hooks:跳过 pre-commit hook 可能导致不符合规范的代码进入仓库 - •
NEVER amend:当 pre-commit hook 失败时,commit 没有成功,此时--amend会修改上一个已经存在的 commit,可能丢失工作 - •
git add -A:可能意外包含.env、密钥文件等敏感文件 - •
NEVER commit without asking:用户可能只是想让模型分析代码,而不是立即提交
Claude Code 的缓存优化策略是其提示词工程中最精妙的部分。
5.1 静态/动态分离
┌─────────────────────────────────────────────┐│ 静态区域 (cacheScope: 'global') ││ 所有用户共享同一份缓存 ││ ││ · 身份定义 (~50 tokens) ││ · 安全指令 (~80 tokens) ││ · 系统规则 (~200 tokens) ││ · 编码风格指导 (~500 tokens) ││ · 操作谨慎性 (~300 tokens) ││ · 工具优先级 (~200 tokens) ││ · 风格指南 (~100 tokens) ││ · 输出效率 (~150 tokens) │├─────────────────────────────────────────────┤│ ≈≈≈≈≈≈≈≈≈≈ 缓存边界 ≈≈≈≈≈≈≈≈≈≈≈≈≈≈≈≈≈≈ │├─────────────────────────────────────────────┤│ 动态区域 (cacheScope: 'org') ││ 每个组织/会话独立缓存 ││ ││ · 环境信息 (操作系统、路径等) ││ · MCP 服务器指令 ││ · 技能列表 ││ · 语言偏好 ││ · 会话特定引导 │└─────────────────────────────────────────────┘ 5.2 agent_listing_delta:工具描述缓存优化
这是一个非常聪明的优化。Agent 列表原本嵌入在工具描述中,但 MCP 连接变化、插件加载、权限模式切换等都会导致列表变化,从而使整个工具 schema 缓存失效。
优化方案:将 Agent 列表从工具描述中移出,通过 system-reminder 附件注入。
export function shouldInjectAgentListInMessages(): boolean { // 动态 Agent 列表占 fleet cache_creation tokens 的 ~10.2% // 通过附件注入,工具 schema 保持静态不变} 这使得工具描述完全静态化,不再因为 Agent 列表变化而破坏缓存。
5.3 技能列表预算管理
技能列表是另一个缓存优化的精彩案例。在 src/tools/SkillTool/prompt.ts 中:
// 技能列表只占上下文窗口的 1%export const SKILL_BUDGET_CONTEXT_PERCENT = 0.01export const DEFAULT_CHAR_BUDGET = 8_000 // 1% of 200k × 4// 每个条目的硬上限export const MAX_LISTING_DESC_CHARS = 250 当技能总数超过预算时,采用优先级截断策略:
function formatCommandsWithinBudget(commands: Command[], budget: number) 5.4 MCP 指令的增量更新
// 当 MCP 服务器异步连接时,每轮重新计算指令会破坏缓存// 优化:通过 mcp_instructions_delta 附件注入DANGEROUS_uncachedSystemPromptSection( 'mcp_instructions', () => isMcpInstructionsDeltaEnabled() ? null : getMcpInstructions(...), 'MCP servers connect/disconnect between turns') 当增量更新启用时,MCP 指令不再每轮重算,而是通过持久化的附件消息传递——这避免了 MCP 服务器连接/断开时破坏整个 prompt cache。
Claude Code 有 36 个工具提示词文件,但它们的提示词设计遵循几个清晰的模式:
6.1 模式一:简洁声明型
Glob 和 Grep 等搜索工具采用简洁的声明式提示词:
// GlobToolexport const DESCRIPTION = `- Fast file pattern matching tool that works with any codebase size- Supports glob patterns like "/*.js" or "src//*.ts"- Returns matching file paths sorted by modification time- When doing open ended search, use the Agent tool instead` 设计原则: 简单工具不需要复杂提示词,关键是指明什么时候该用和什么时候该用别的。
6.2 模式二:结构化指令型
Bash、PowerShell 等复杂工具采用结构化的分层指令:
工具简介↓使用说明(何时用、何时不该用)↓具体指令(命令链接、超时、后台执行)↓安全协议(Git 安全、沙箱规则)↓示例 6.3 模式三:交互指导型
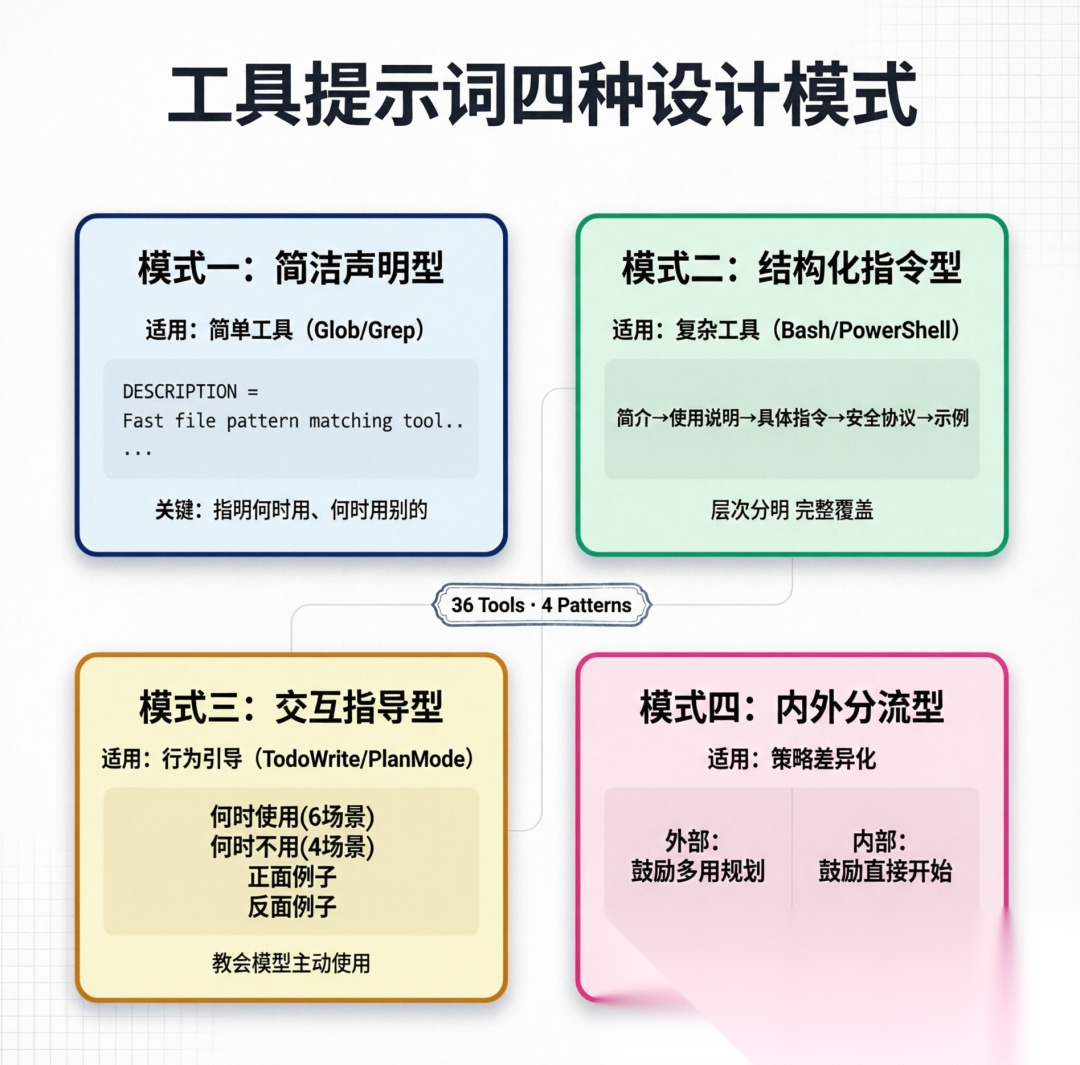
工具提示词设计模式
TodoWrite、EnterPlanMode 等工具的提示词包含丰富的使用场景指导:
// TodoWrite 的提示词长达 200+ 行,包含:// - 何时使用(6 种场景)// - 何时不使用(4 种场景)// - 完整的使用示例(4 个正面例子 + 5 个反面例子)// - 任务状态管理规则 设计原因: 任务管理工具是"行为引导型"工具——它的提示词不仅仅是描述工具功能,更重要的是教会模型何时、如何主动使用它。
6.4 模式四:内部/外部分流型
EnterPlanMode 的提示词在内部和外部用户之间有显著差异:
外部版本: 倾向于"宁多勿少"地使用规划模式——只要有一丝不确定就进入规划。
内部版本: 倾向于"直接开始"——只有在真正模糊的情况下才进入规划:
// 外部版:鼓励多用"Prefer using EnterPlanMode for implementation tasks unless they're simple"// 内部版:鼓励少用"When in doubt, prefer starting work and using AskUserQuestion for specific questions over entering a full planning phase." Claude Code 的提示词系统通过多层条件分支实现精细控制。
7.1 构建时分支:USER_TYPE
// USER_TYPE 在构建时通过 --define 注入// 外部构建中,所有 'ant' 分支被 dead-code elimination 删除if (process.env.USER_TYPE === 'ant') { // 内部用户专属逻辑} else { // 外部用户逻辑} 这意味着内外版本的二进制文件中包含的提示词是不同的——不是运行时判断,而是编译时就分叉了。
7.2 运行时 Feature Flag:feature()
// 来自 Bun 的 bundle 特性import { feature } from 'bun:bundle'// 编译时特性检查const proactiveModule = feature('PROACTIVE') || feature('KAIROS') ? require('../proactive/index.js') : null 这些 feature flag 控制着:
- •
PROACTIVE/KAIROS:自主工作模式 - •
TOKEN_BUDGET:Token 预算管理 - •
EXPERIMENTAL_SKILL_SEARCH:技能搜索 - •
VERIFICATION_AGENT:验证代理 - •
CACHED_MICROCOMPACT:缓存微压缩
7.3 运行时 A/B 测试:GrowthBook
// 通过 GrowthBook 进行动态特性开关const getFeatureValue_CACHED_MAY_BE_STALE = require('../services/analytics/growthbook.js')// 示例:验证代理特性feature('VERIFICATION_AGENT') && getFeatureValue_CACHED_MAY_BE_STALE('tengu_hive_evidence', false) 这允许 Anthropic 在不发版的情况下调整提示词行为——通过 GrowthBook 的 A/B 测试框架,可以逐步向不同用户群体推出新的提示词策略。
7.4 Undercover 模式
当 Anthropic 内部员工使用 Claude Code 贡献开源项目时,会自动启用"卧底模式":
Undercover mode — safety utilities for contributing to public/open-source repos.When active, Claude Code:1. Adds safety instructions to commit/PR prompts2. Strips all attribution to avoid leaking internal model codenames3. The model is not told what model it is 在 Undercover 模式下,系统提示词中所有与模型身份相关的信息都被移除:
if (process.env.USER_TYPE === 'ant' && isUndercover()) { // suppress — 不告诉模型它是什么模型 // 不提及 Claude Code、Anthropic、内部代号等} 这是安全纵深防御的典型案例——即使模型在对话中生成了内部代号,由于 commit/PR 提示词中的安全指令,这些信息也不会出现在公开的提交记录中。
通过以上分析,我们可以总结出 Claude Code 提示词工程的六大设计哲学:
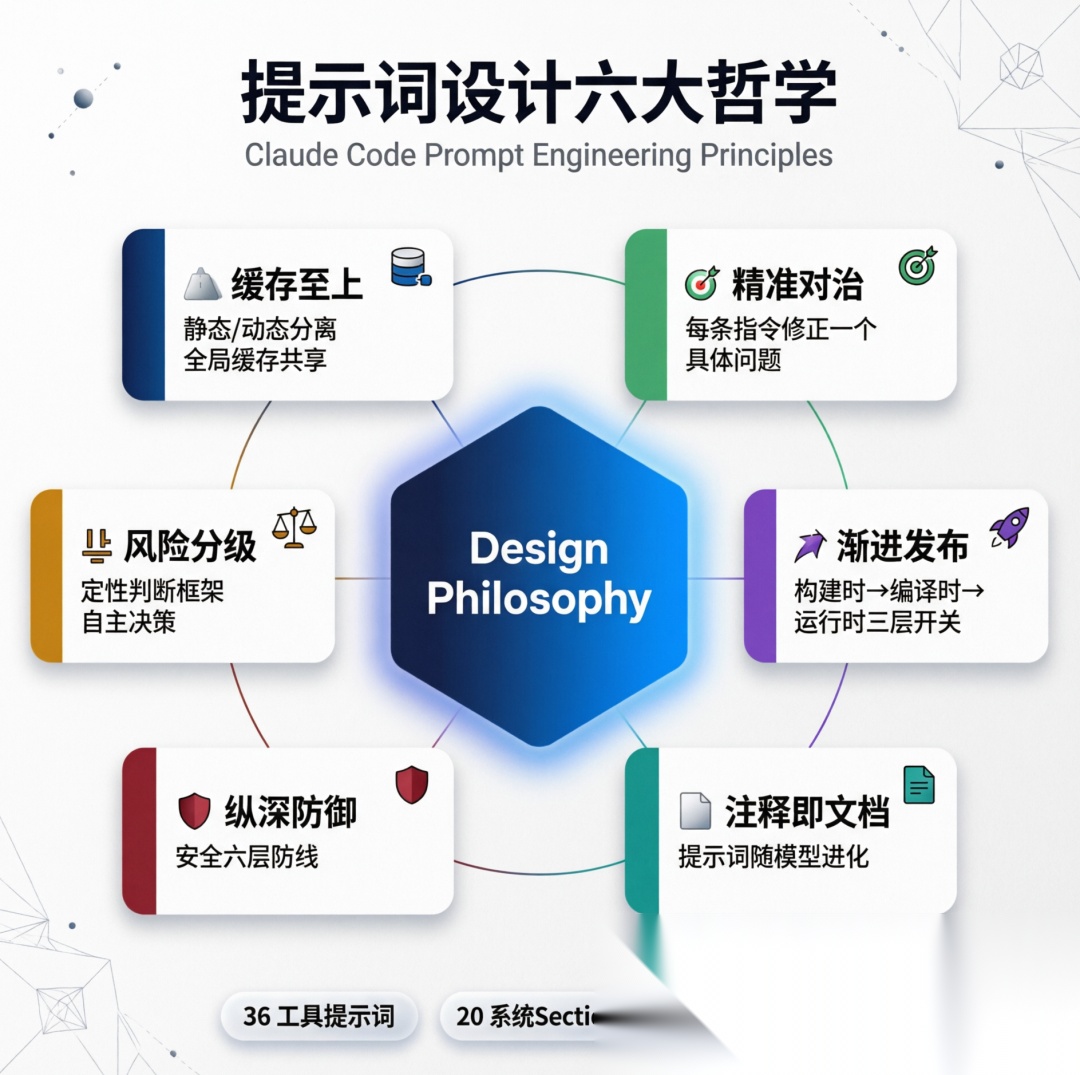
提示词设计六大哲学
1. 缓存至上
几乎所有的提示词设计决策都围绕着缓存效率展开:
- • 静态/动态分离
- • Agent 列表附件化
- • 技能列表预算控制
- • MCP 指令增量更新
这些优化看起来复杂,但每一项都对应着显著的 API 成本节省。Anthropic 的注释中提到了一个具体数字:Agent 列表附件化节省了约 10.2% 的 fleet cache_creation tokens。
2. 精准对治
每条提示词指令都是对模型特定不良行为的精准修正:
3. 风险分级
不是所有操作都需要同等程度的谨慎。Claude Code 的提示词系统通过定性判断框架(而非硬编码规则)让模型自己做出风险决策:
The cost of pausing to confirm is low, while the cost of an unwanted action can be very high. 4. 渐进式发布
通过 USER_TYPE(构建时)→ feature()(编译时)→ GrowthBook(运行时)的三层特性开关,Anthropic 实现了提示词的渐进式发布:
内部测试 → feature flag 小范围测试 → GrowthBook A/B 测试 → 全量发布 每个阶段的反馈数据都会影响下一步决策。
5. 注释即文档
Claude Code 的提示词代码中充满了珍贵的注释,这些注释本身就是一个活的设计文档:
// @[MODEL LAUNCH]: Update comment writing for Capybara — remove or soften // once the model stops over-commenting by default// Dead code elimination: conditional imports for feature-gated modules// WARNING: Do not remove or reorder this marker without updating cache logic// DCE: `process.env.USER_TYPE === ‘ant’` is build-time –define. It MUST be// inlined at each callsite (not hoisted to a const) so the bundler can// constant-fold it 这些注释告诉我们:提示词是活的,会随模型能力演进而调整。
6. 安全纵深防御
安全不是单点措施,而是多层防线:
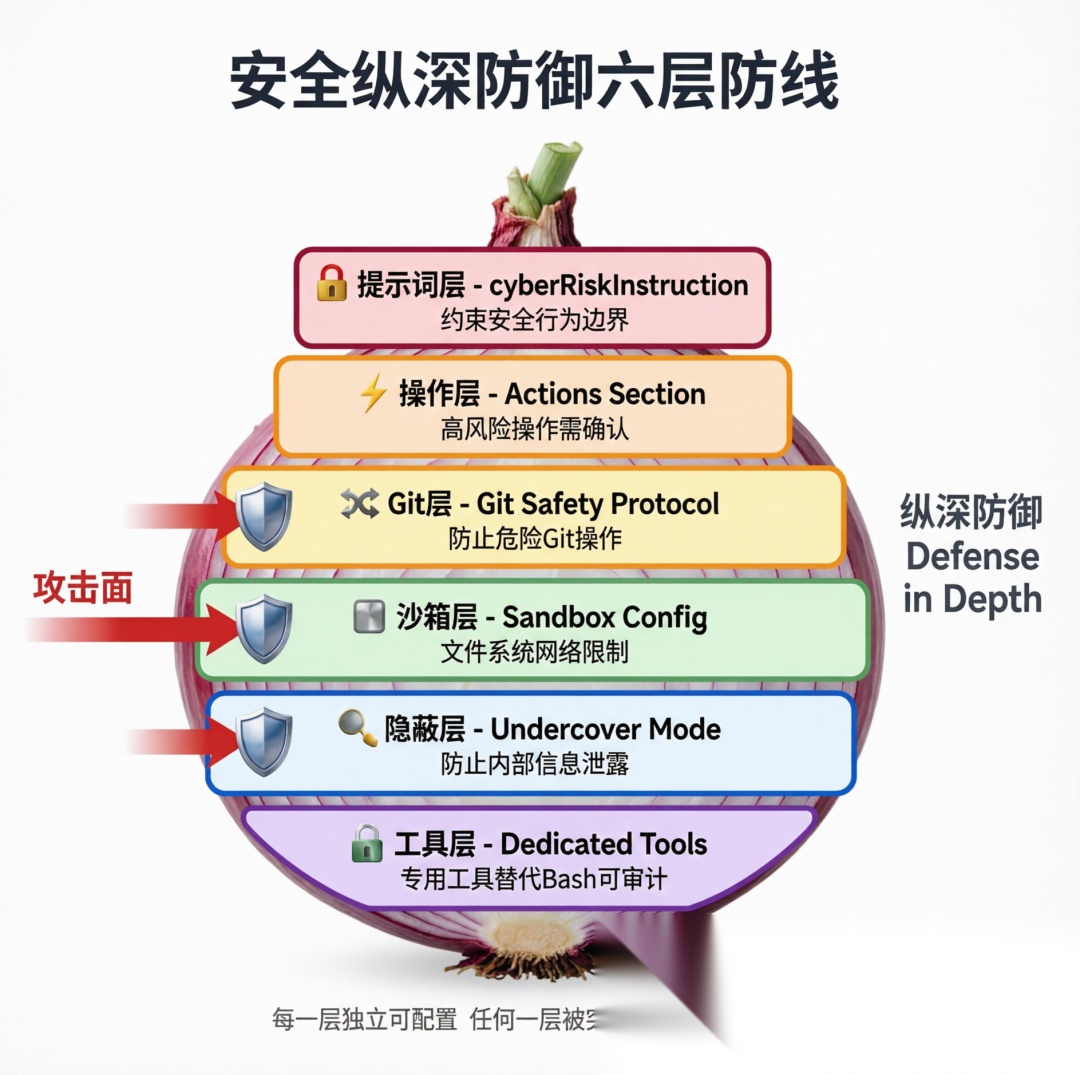
安全纵深防御六层防线
- 提示词层:cyberRiskInstruction 约束安全行为
- 操作层:Actions 节要求确认高风险操作
- Git 层:Git Safety Protocol 防止危险 Git 操作
- 沙箱层:Sandbox 配置限制文件系统和网络访问
- 隐蔽层:Undercover 模式防止内部信息泄露
- 工具层:专用工具替代 Bash 提供可审计性
Claude Code 的提示词系统为所有 AI 产品开发者提供了宝贵的经验:
- 架构比内容更重要:单个提示词写得再好,如果没有缓存策略和分层架构,成本和性能都会成为瓶颈。
- 针对性胜过全面性:每条指令应该解决一个具体问题,而不是试图用一段话覆盖所有场景。
- 可观测性是关键:丰富的注释、命名的段落、显式的缓存边界——这些让提示词系统变得可维护、可调试。
- 提示词是产品的一部分:它需要版本管理、A/B 测试、渐进式发布,和任何产品功能一样。
- 模型在进化,提示词也要进化:
@[MODEL LAUNCH]标注告诉我们,每次模型升级都需要重新评估提示词的有效性。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/260033.html