
大模型的上下文窗口越来越长,但一个尴尬的事实是:上下文越长,模型越容易读不懂重点。目前主流的两条路线——扩大上下文窗口、或引入RAG检索。但各自都各有局限:前者成本高且仍存在性能衰减,后者检索流程固定,难以支撑需要反复探索与多跳推理的复杂任务。
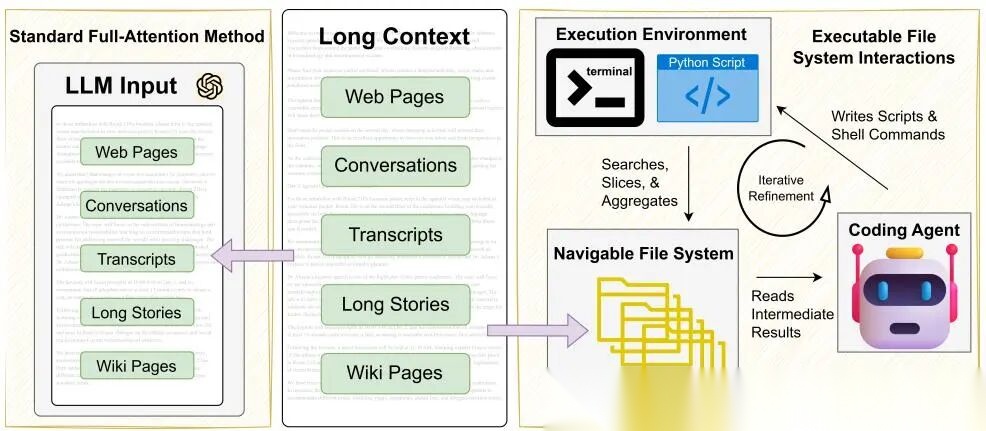
这篇论文提出了一个完全不同的方向:与其让模型在注意力里“硬记”,不如把长文本变成它可以真正操作的对象——用文件系统组织语料,让编码代理通过搜索、脚本和迭代分析去“主动阅读”海量信息。
关键亮点:提出将长上下文处理重构为“文件系统导航 + 编码代理执行”的新范式,无需任务特定训练即可跨场景通用,并能自主涌现多跳检索与程序化推理策略。
数据亮点:在覆盖18.8万到3万亿token的5个主流基准上,平均超越现有SOTA 17.3%,且在4个基准取得最优成绩,同时单查询成本显著低于全上下文强基线。
是否开源:已开源,相关链接见结尾。
论文的核心思路非常直接:把长文本变成代码仓库,让编码代理用程序员的方式去读资料。代理只需拿到文件路径和任务指令,就能通过命令行与脚本自主完成搜索、阅读与推理。
1. 语料文件系统化:把文本变成“代码仓库”
根据任务规模,语料被组织为代理熟悉的文件结构:
- • 超大规模语料(>1亿 token):每篇文档单独存为 txt,构成可导航目录。
- • 如果是单篇超长文档,就直接把整个文档存成一个txt文件。
之后只需要给编码代理提供文件或目录的路径,加上任务查询,剩下的就交给代理自主处理。
作为文件系统导航的文本处理
2. 代理如何“主动阅读”长文本
编码代理可直接调用原生工具完成任务:
- • 执行终端命令,比如用grep搜索关键词、用head查看文件开头内容;
- • 编写并运行Python脚本,实现程序化的搜索、文本解析和处理;
- • 创建中间文件保存部分结果,再根据这些结果迭代优化处理逻辑。
在 Oolong-Real 任务中,代理通过多轮脚本迭代逐步补全咒语匹配规则,最终覆盖所有边缘案例——这一过程很难由固定检索管道或纯注意力模型完成。

Oolong-Real 上的迭代优化示例。当被要求在一份 38.5 万 token 的转录文本中找出 Vax’ildan 在每一集中施展的最后一个咒语时,编码代理编写了 Python 脚本,并通过分析失败案例发现了领域特有的咒语表述方式,随后不断迭代改进其处理逻辑。
3. 为什么文件系统 + 原生工具效果这么好?
(1)目录结构显著提升性能
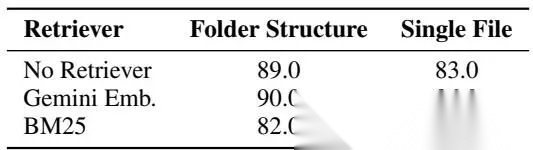
作者对比了语料按目录分文件存储和所有语料存成单个JSON文件两种情况,结果显示,目录结构的性能全面领先。
比如在BrowseComp-Plus任务中,没有额外检索工具的情况下,目录结构的准确率是89.0,单文件只有83.0。
行为分析显示:
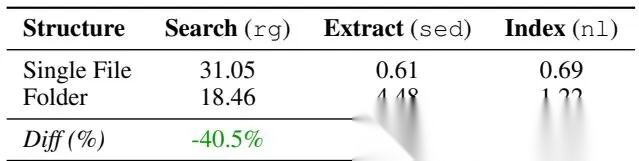
- • 目录结构 → 更多使用 nl、sed,形成“先索引再定位”的坐标式阅读;
- • 单文件 → 只能反复全量搜索,效率低且易陷入循环。
文件系统结构的消融实验
BrowseComp-Plus数据集(无检索器)上平均命令使用次数的分析
(2)传统检索工具反而可能降低性能
一个反常识的发现是:给编码代理加上传统的检索工具,比如BM25、Gemini Embeddings,不仅不会提升性能,反而可能让表现下降。
比如在BrowseComp-Plus任务中,无检索的Codex准确率是88.50,加上BM25后降到了78.50。
观察代理的行为就能找到答案:有检索工具时,代理减少原生命令使用(14.92 → 8.33 次),过度依赖不完美的排序结果,反而限制了自主探索。

BrowseComp-Plus上不同检索器配置下的智能体探索模式
(3)代理会“自动选择最合适的策略”
不同任务中,代理会涌现不同工作模式:
- • 多跳检索:形成“搜索 → 新实体 → 再搜索”的迭代链条;
- • 分析任务:编写 Python 脚本进行批量统计与规则迭代;
- • 通用长文任务:减少工具使用,直接依赖模型推理。
代理的工具使用行为会随任务类型显著变化,体现出强烈的任务自适应能力。
论文在五类长上下文基准上评估了编码代理,覆盖 18.8万 → 3万亿 token 的极大跨度。结果显示,该方案在整体上平均超越既有**方法 17.3%。
各基准关键结果如下:
- • BrowseComp-Plus(7.5亿token,多跳推理):无检索 Codex 准确率 88.50%,相比此前 SOTA 80.00% 提升 10.6%,取得最高成绩。
- • Oolong-Synthetic(53.6万token,长文推理):得分 71.75%,较此前 64.38% 提升 11.5%。
- • Oolong-Real(38.5万 token,真实长文档):Claude Code + BM25 达到 37.46%,相比 24.09% 提升 55.5%,是提升幅度最大的任务。
- • LongBench(18.8万 token,多任务长文):准确率 61.50%,与此前最优 63.30% 持平,保持强竞争力。
- • NNatural Questions(3万亿 token,开放域 QA):精确匹配 56.00%,较 50.90% 提升 10%,在超大规模语料上依然稳定。
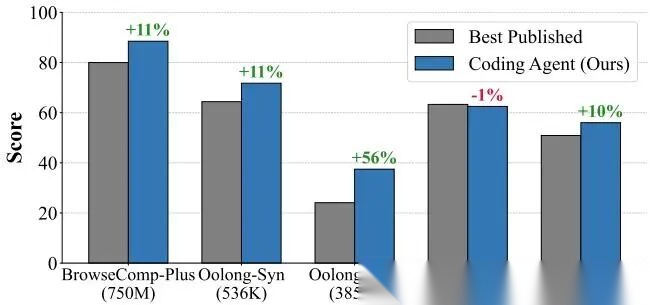
编码智能体在五个长上下文基准测试中显著超越此前**公开结果,这些基准的上下文长度跨度从188K到三万亿token。
成本表现同样值得关注:
编码代理虽然高于轻量 RAG,但显著低于 GPT-5 全上下文与 RLM 等强基线,整体性价比更优。以 Oolong-Real 为例:
GPT-5 全上下文单词查询 $0.77,而无检索 Codex 为 $0.419,同时性能从 22.45% 提升至 33.73%。
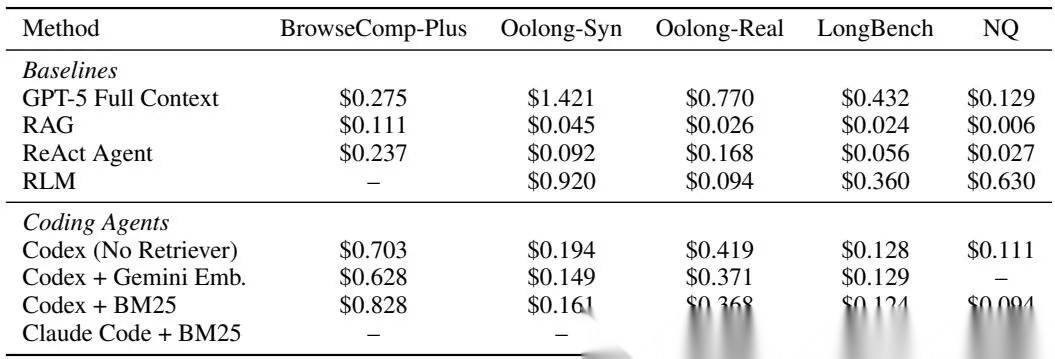
每个查询在各基准测试上的平均成本
这项工作最突出的价值在于它重新定义了长上下文能力的实现路径:不再执着于无限扩展上下文窗口或堆叠检索模块,而是把问题转化为编码代理可以执行的文件系统操作,让模型通过搜索、脚本与迭代分析主动“阅读”海量语料。
在无需额外训练的前提下,就能在多个长上下文基准上取得大幅领先,同时兼顾成本与落地可行性,这种兼具范式创新与工程可实施性的研究,在当前长上下文赛道中极具代表性。
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/259851.html