
LangChain 是一个开源框架,旨在帮助开发者使用大型语言模型(LLMs)和聊天模型构建端到端的应用程序。它提供了一套工具、组件和接口,以简化创建由这些模型支持的应用程序的过程。LangChain 的核心概念包括组件(Components)、链(Chains)、模型输入 / 输出(Model I/O)、数据连接(Data Connection)、内存(Memory)和代理(Agents)等。
1.1 模块化架构
LangChain 模块化架构
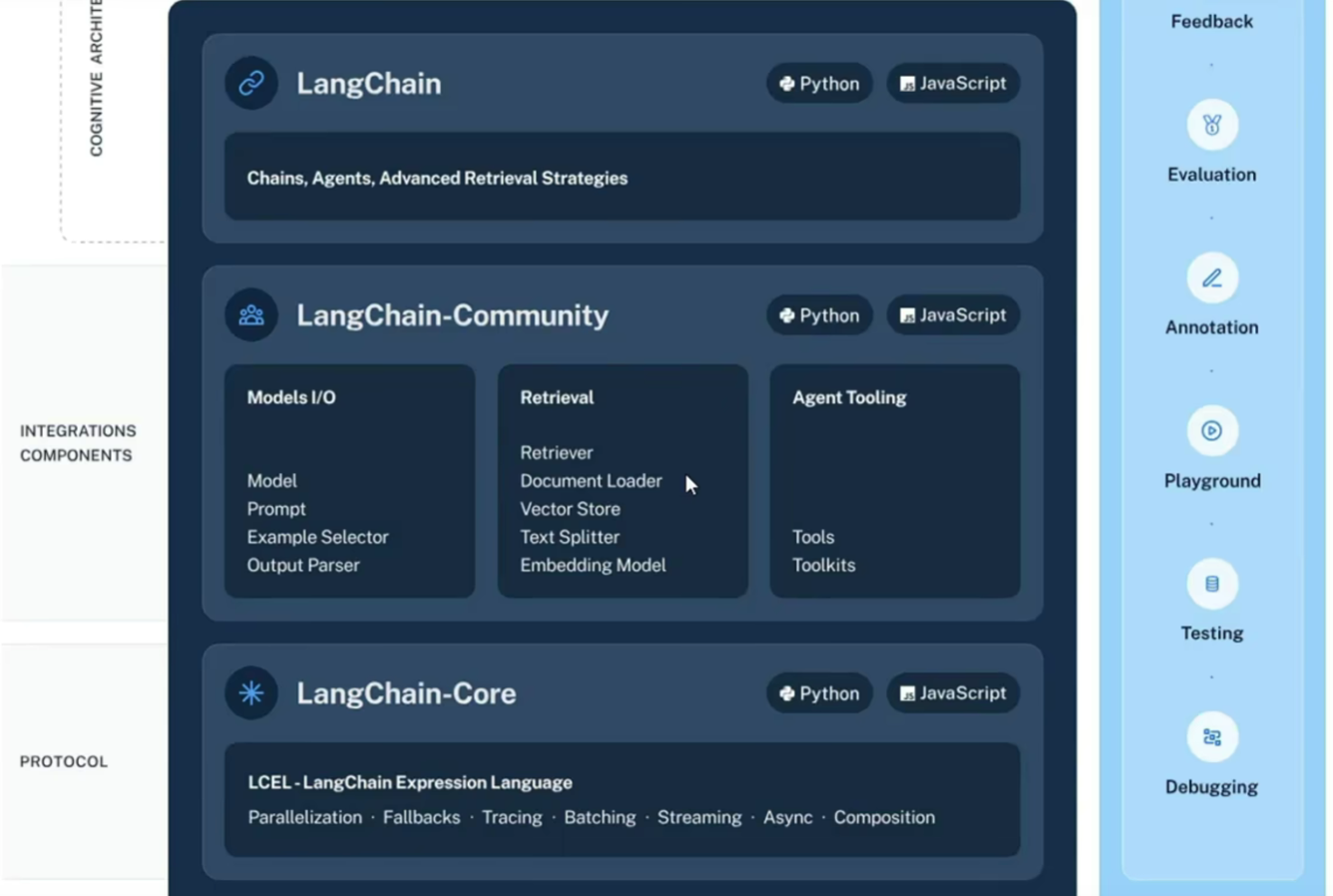
- LangChain-Core(核心层)
- 定位:整个框架的底层基础,定义了所有组件的标准接口与协议。
- 核心内容:
- LCEL(LangChain Expression Language):声明式链式语法,用来组合不同组件(如 chain = prompt | model | output_parser)。
- 基础能力:并行执行、降级容错(Fallbacks)、链路追踪(Tracing)、批处理、流式输出、异步调用、组件组合等。
- 作用:提供了最小依赖、最高稳定性的核心抽象,所有上层模块都基于此构建。
- LangChain-Community(社区集成层)
- 定位:连接大模型与外部生态的中间层,包含所有第三方集成实现。
- 三大核心模块:
- Models I/O:与大模型交互的基础组件
- Model:对接各类 LLM / 聊天模型
- Prompt:提示词模板管理
- Example Selector:动态选择示例
- Output Parser:解析模型输出为结构化数据
- Retrieval(检索增强):RAG 应用的核心模块
- Retriever:检索器接口
- Document Loader:加载各类文档(PDF/CSV/ 网页等)
- Vector Store:向量数据库对接
- Text Splitter:文本分块
- Embedding Model:生成向量嵌入
- Agent Tooling:智能体工具生态
- Tools:单个工具(如搜索、计算器)
- Toolkits:工具包(如 Google Search、Python REPL)
- Models I/O:与大模型交互的基础组件
- 作用:让开发者快速接入海量第三方服务,无需重复造轮子。
- LangChain(应用层)
- 定位:面向最终开发者的高级封装,提供开箱即用的复杂应用场景。
- 核心内容:
- Chains:预构建的常用链路(如 LLMChain、RetrievalQA)
- Agents:智能体框架(让 LLM 自主决策调用工具)
- Advanced Retrieval Strategies:高级检索策略(如上下文压缩、多查询检索、混合检索)
- 作用:简化复杂应用开发,让开发者专注业务逻辑而非底层实现。
- 右侧辅助工具链
- Feedback:收集用户反馈,优化应用
- Evaluation:自动化评估应用效果
- Annotation:数据标注工具
- Playground:在线调试 prompt 和链路
- Testing:单元测试与集成测试
- Debugging:链路追踪与调试(LangSmith)
1.2 关键特性和组件
以下是 LangChain 的一些关键特性和组件的详细解释:
- 组件(Components)
- 模型输入 / 输出(Model I/O):负责管理与语言模型的交互,包括输入(提示,Prompts)和格式化输出(输出解析器,Output Parsers)。
- 数据连接(Data Connection):管理向量数据存储、内容数据获取和转换,以及向量数据查询。
- 内存(Memory):用于存储和获取对话历史记录的功能模块。
- 链(Chains):串联 Memory、Model I/O 和 Data Connection,以实现串行化的连续对话和推理流程。
- 代理(Agents):基于链进一步串联工具,将语言模型的能力和本地、云服务能力结合。
- 回调(Callbacks):提供了一个回调系统,可连接到请求的各个阶段,便于进行日志记录、追踪等数据流。
- 模型输入 / 输出(Model I/O)
- LLMs:与大型语言模型进行接口交互,如 OpenAI、Cohere 等。
- Chat Models:聊天模型是语言模型的变体,它们以聊天信息列表为输入和输出,提供更结构化的消息。
- 数据连接(Data Connection)
- 向量数据存储(Vector Stores):用于构建私域知识库。
- 内容数据获取(Document Loaders):获取内容数据。
- 转换(Transformers):处理数据转换。
- 向量数据查询(Retrievers):查询向量数据。
- 内存(Memory)
- 用于存储对话历史记录,以便在连续对话中保持上下文。
- 链(Chains)
- 是组合在一起以完成特定任务的一系列组件。
- 代理(Agents)
- 基于链的工具,结合了语言模型的能力和本地、云服务。
- 回调(Callbacks)
- 提供了一个系统,可以在请求的不同阶段进行日志记录、追踪等。
1.3 LangChain 使用场景
LangChain 的使用场景包括但不限于文档分析和摘要、聊天机器人、代码分析、工作流自动化、自定义搜索等。它允许开发者将语言模型与外部计算和数据源相结合,从而创建出能够理解和生成自然语言的应用程序。
要开始使用 LangChain,开发者需要导入必要的组件和工具,组合这些组件来创建一个可以理解、处理和响应用户输入的应用程序。LangChain 提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互等,以支持特定的用例。
LangChain 的官方文档提供了详细的指南和教程,帮助开发者了解如何设置和使用这个框架。开发者可以通过这些资源来学习如何构建和部署基于 LangChain 的应用程序。
1.4 Langchain可以构建哪些应用
LangChain 作为一个强大的框架,旨在帮助开发者利用大型语言模型(LLMs)构建各种端到端的应用程序。以下是一些可以使用 LangChain 开发的应用类型:
- 聊天机器人(Chatbots)
创建能够与用户进行自然对话的聊天机器人,用于客户服务、娱乐、教育或其他交互式场景。
- 个人助理(Personal Assistants)
开发智能个人助理,帮助用户管理日程、回答问题、执行任务等。
- 文档分析和摘要(Document Analysis and Summarization)
自动分析和总结大量文本数据,提取关键信息,为用户节省阅读时间。
- 内容创作(Content Creation)
利用语言模型生成文章、故事、诗歌、广告文案等创意内容。
- 代码分析和生成(Code Analysis and Generation)
帮助开发者自动生成代码片段,或者提供代码审查和优化建议。
- 工作流自动化(Workflow Automation)
通过自动化处理日常任务和工作流程,提高工作效率。
- 自定义搜索引擎(Custom Search Engines)
结合语言模型的能力,创建能够理解自然语言查询的搜索引擎。
- 教育和学习辅助(Educational and Learning Aids)
开发教育工具,如智能问答系统、学习辅导机器人等,以辅助学习和教学。
- 数据分析和报告(Data Analysis and Reporting)
使用语言模型处理和分析数据,生成易于理解的报告和摘要。
- 语言翻译(Language Translation)
利用语言模型进行实时翻译,支持多语言交流。
- 情感分析(Sentiment Analysis)
分析文本中的情感倾向,用于市场研究、社交媒体监控等。
- 知识库和问答系统(Knowledge Bases and Q&A Systems)
创建能够回答特定领域问题的智能问答系统。
LangChain 的灵活性和模块化设计使得开发者可以根据特定需求定制和扩展应用程序。通过将语言模型与外部数据源和 APIs 结合,LangChain 能够支持广泛的应用场景,从而创造出更加智能和用户友好的软件解决方案。
1.5 demo
此处使用智谱大模型完成示例demo。
1 安装智谱依赖包
- langchain-community → 第三方模型集成包(智谱就在这里面)
# pip install langchain-community 新版 LangChain 0.2+ 已经模块化拆分,langchain 大包不再是必须安装的。只装 langchain-community,就能正常使用智谱 AI 的 ChatZhipuAI,完全不需要 langchain 和 zhipuai。
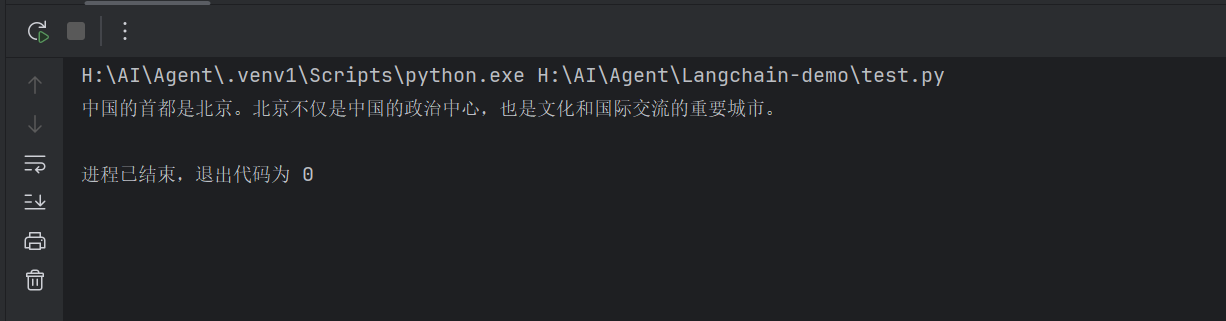
2 运行demo
from langchain_community.chat_models import ChatZhipuAI llm = ChatZhipuAI( api_key="你的api key", model="glm-4" ) res = llm.invoke("中国的首都是哪里") print(res.content) 3 运行结果
429报错处理
对于免费或普通开发者账号,主模型的 QPS(每秒请求数)限制非常严格,Agent 运行过程中可能会连续触发多次推理,瞬间超限。
H:AIAgent.venv1Scriptspython.exe H:AIAgentLangchain-demo est.py Traceback (most recent call last): File "H:AIAgentLangchain-demo est.py", line 10, in <module> res = llm.invoke("中国的首都是哪里") ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "H:AIAgent.venv1Libsite-packageslangchain_corelanguage_modelschat_models.py", line 454, in invoke self.generate_prompt( File "H:AIAgent.venv1Libsite-packageslangchain_corelanguage_modelschat_models.py", line 1185, in generate_prompt return self.generate(prompt_messages, stop=stop, callbacks=callbacks, kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "H:AIAgent.venv1Libsite-packageslangchain_corelanguage_modelschat_models.py", line 995, in generate self._generate_with_cache( File "H:AIAgent.venv1Libsite-packageslangchain_corelanguage_modelschat_models.py", line 1297, in _generate_with_cache result = self._generate( ^^^^^^^^^^^^^^^ File "H:AIAgent.venv1Libsite-packageslangchain_communitychat_modelszhipuai.py", line 559, in _generate response.raise_for_status() File "H:AIAgent.venv1Libsite-packageshttpx_models.py", line 829, in raise_for_status raise HTTPStatusError(message, request=request, response=self) httpx.HTTPStatusError: Client error '429 Too Many Requests' for url 'https://open.bigmodel.cn/api/paas/v4/chat/completions' For more information check: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/429 解决:修改glm-4为glm-4-flash,具体原因请见
LangChain 适配智谱 GLM-4 避坑指南:手把手解决 429 报错与死循环
最基本和常见的用例是将提示模板和模型链接在一起。为了看看这是如何工作的,让我们创建一个接收主题并生成小红书短文的链:
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_community.chat_models import ChatZhipuAI prompt = ChatPromptTemplate.from_template("请根据下面的主题写一篇小红书营销的短文:{topic}") model = ChatZhipuAI( api_key="你的api key", model="glm-4-flash" ) output_parser = StrOutputParser() chain = prompt | model | output_parser chain.invoke({"topic": "康师傅绿茶"}) 2.1 Prompt 提示
prompt 是 BasePromptTemplate 的实例,接收变量字典,生成 PromptValue.
PromptValue 是完整提示的包装器,可传递给 LLM(接受字符串输入)或 ChatModel(接受消息序列输入),它能兼容任意语言模型类型,因为内置了生成 BaseMessage 和字符串的逻辑。
# 1. 创建聊天提示模板,定义变量 {topic} prompt = ChatPromptTemplate.from_template("请根据下面的主题写一篇小红书营销的短文: {topic}") # 2. 传入变量值,生成完整提示 prompt_value = prompt.invoke({"topic": "康师傅绿茶"}) # 3. 查看生成的提示对象 prompt_value 输出

2.2 Model 模型
然后 PromptValue 被传递给 model。在本例中,我们的 model 是 ChatModel,这意味着它将输出 BaseMessage.
message = model.invoke(prompt_value) message 输出
AIMessage(content='康师傅绿茶,清新解渴,是夏日里的一抹清凉。清爽的茶香,清凉的口感,让人在炎炎夏日里倍感舒爽。而在小红书上,康师傅绿茶也成为了不少网红们推荐的热门产品。 康师傅绿茶的营销之所以成功,一方面是因为其口感清新的特点,另一方面也离不开小红书这个平台的传播力。在小红书上,不少网红们通过视频、图片等形式,展示了康师傅绿茶的饮用方式、') 2.3 Output parser 输出解析器
将 model 输出传递给 output_parser,这是一个 BaseOutputParser,意味着它接受字符串或 BaseMessage 作为输入。StrOutputParser 特别简单地将任何输入转换为字符串。

output_parser.invoke(message) 输出
'康师傅绿茶,清新解渴,是夏日里的一抹清凉。清爽的茶香,清凉的口感,让人在炎炎夏日里倍感舒爽。而在小红书上,康师傅绿茶也成为了不少网红们推荐的热门产品。 康师傅绿茶的营销之所以成功,一方面是因为其口感清新的特点,另一方面也离不开小红书这个平台的传播力。在小红书上,不少网红们通过视频、图片等形式,展示了康师傅绿茶的饮用方式、' 2.4 流式输出
如果我们想流式传输结果,我们需要更改我们的函数
for chunk in chain.stream({"topic": "康师傅绿茶"}): print(chunk, end="", flush=True) 输出:即上述内容的流式输出效果。
以上就是LangChain 的 Chain(链)。
3.1 GLM-4 模型介绍
新一代基座大模型 GLM-4,2024年发布,整体性能相比 GLM3 全面提升 60%,逼近 GPT-4;支持更长上下文;更强的多模态;支持更快推理速度,更多并发,大大降低推理成本;同时 GLM-4 增强了智能体能力。
3.1.1 基础能力(英文)
GLM-4 在 MMLU、GSM8K、MATH、BBH、HellaSwag、HumanEval 等数据集上,分别达到 GPT-4 94%、95%、91%、99%、90%、100% 的水平。
(OpenAI, 2023; Gemini Team Google, 2023)
3.1.2 指令跟随能力(中英)
GLM-4 在 IFEval 的 prompt 级别上中、英分别达到 GPT-4 的 88%、85% 的水平,在 Instruction 级别上中、英分别达到 GPT-4 的 90%、89% 的水平。
(Google, 2023)
3.1.3 对齐能力(中文)

(AlignBench 2023)
3.1.4 长文本能力
3.1.5 多模态 - 文生图
CogView3 在文生图多个评测指标上,相比 DALLE3 约在 91.4% ~99.3% 的水平之间。

GLM-4 实现自主根据用户意图,自动理解、规划复杂指令,自由调用网页浏览器、Code Interpreter 代码解释器和多模态文生图大模型,以完成复杂任务。简单来讲,即只需一个指令,GLM-4 会自动分析指令,结合上下文选择决定调用合适的工具。
GLM-4 能够通过自动调用 python 解释器,进行复杂计算(例如复杂方程、微积分等),在 GSM8K、MATH、Math23K 等多个评测集上都取得了接近或同等 GPT-4 All Tools 的水平。
GLM-4 能够自行规划检索任务、自行选择信息源、自行与信息源交互,在准确率上能够达到 78.08,是 GPT-4 All Tools 的 116%。
GLM-4 能够根据用户提供的 Function 描述,自动选择所需 Function 并生成参数,以及根据 Function 的返回值生成回复;同时也支持一次输入进行多次 Function 调用,支持包含中文及特殊符号的 Function 名字。这一方面 GLM-4 All Tools 与 GPT-4 Turbo 相当。
网站链接:https://www.zhipuai.cn/
3.2 安装sdk&测试
官网文档
https://docs.bigmodel.cn/cn/guide/develop/python/introduction#%E4%BD%BF%E7%94%A8-pip-%E5%AE%89%E8%A3%85
安装指令
# 安装最新版本 pip install zai-sdk# 或指定版本 pip install zai-sdk==0.2.2
将API Key放入环境变量中
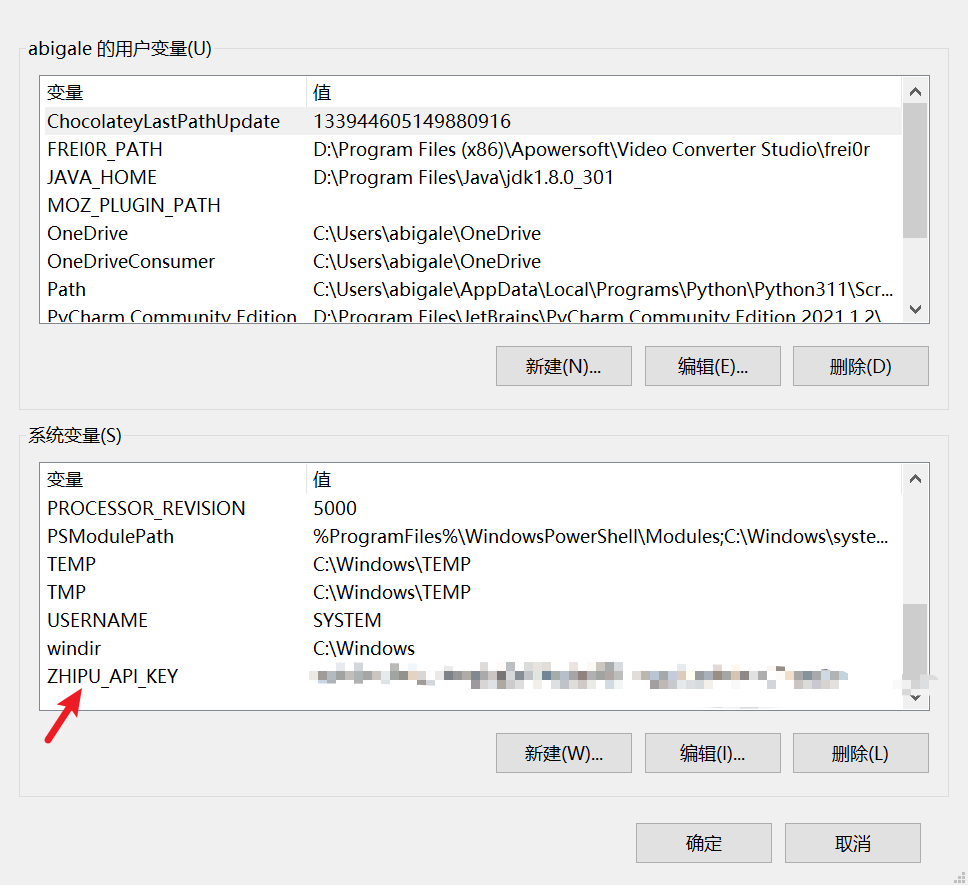
首次设置如果程序报错,可能是环境变量未生效:你在系统设置里新增 / 修改了 ZHIPU_API_KEY 后,必须重启终端 / IDE/PyCharm,新的环境变量才会被加载。如果直接在旧的终端或 PyCharm 窗口里运行代码,进程读取的还是修改前的环境变量,就会拿到 None。
测试
import os from zai import ZhipuAiClient zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”) print(zhipuai_api_key)# Initialize client client = ZhipuAiClient(api_key=zhipuai_api_key)
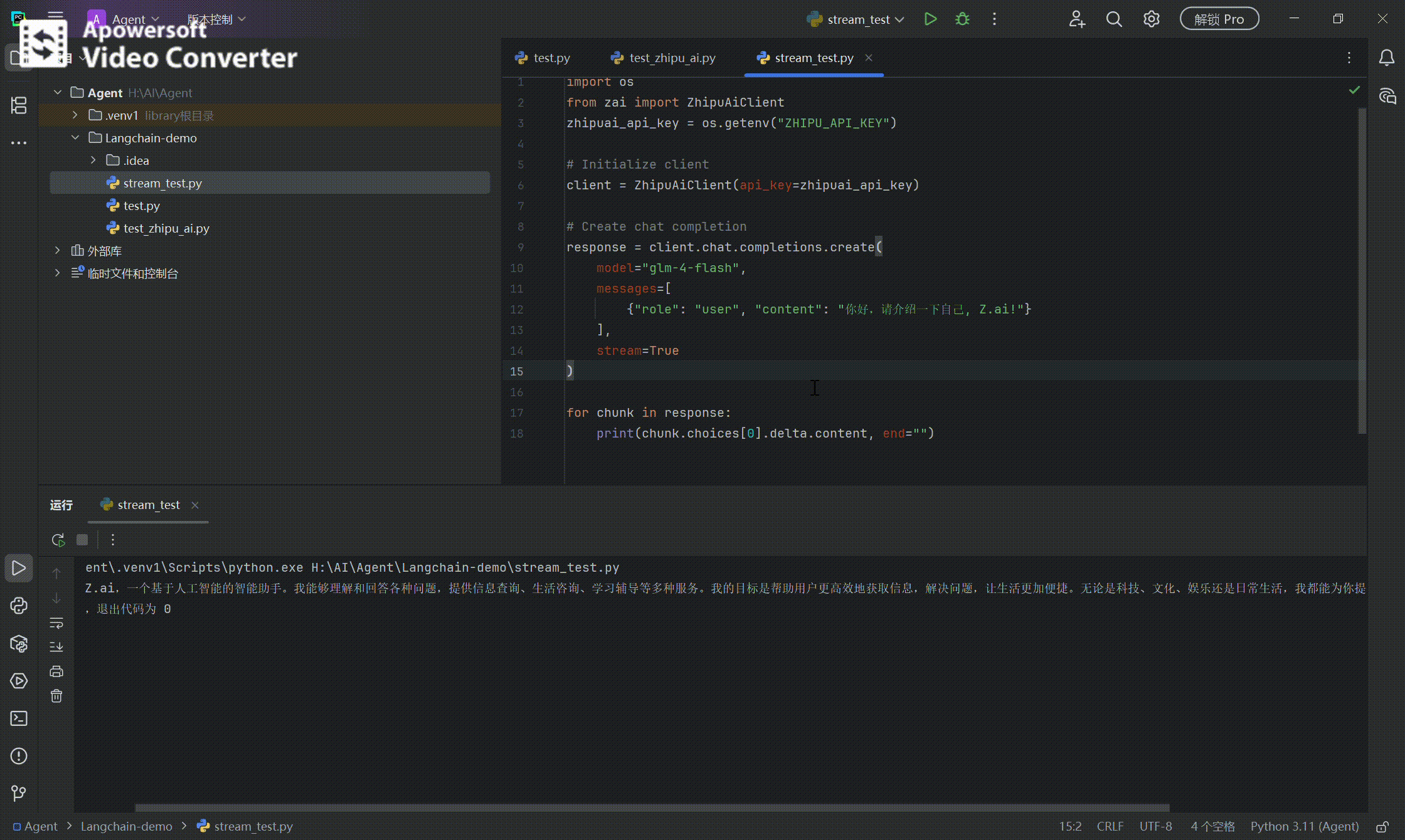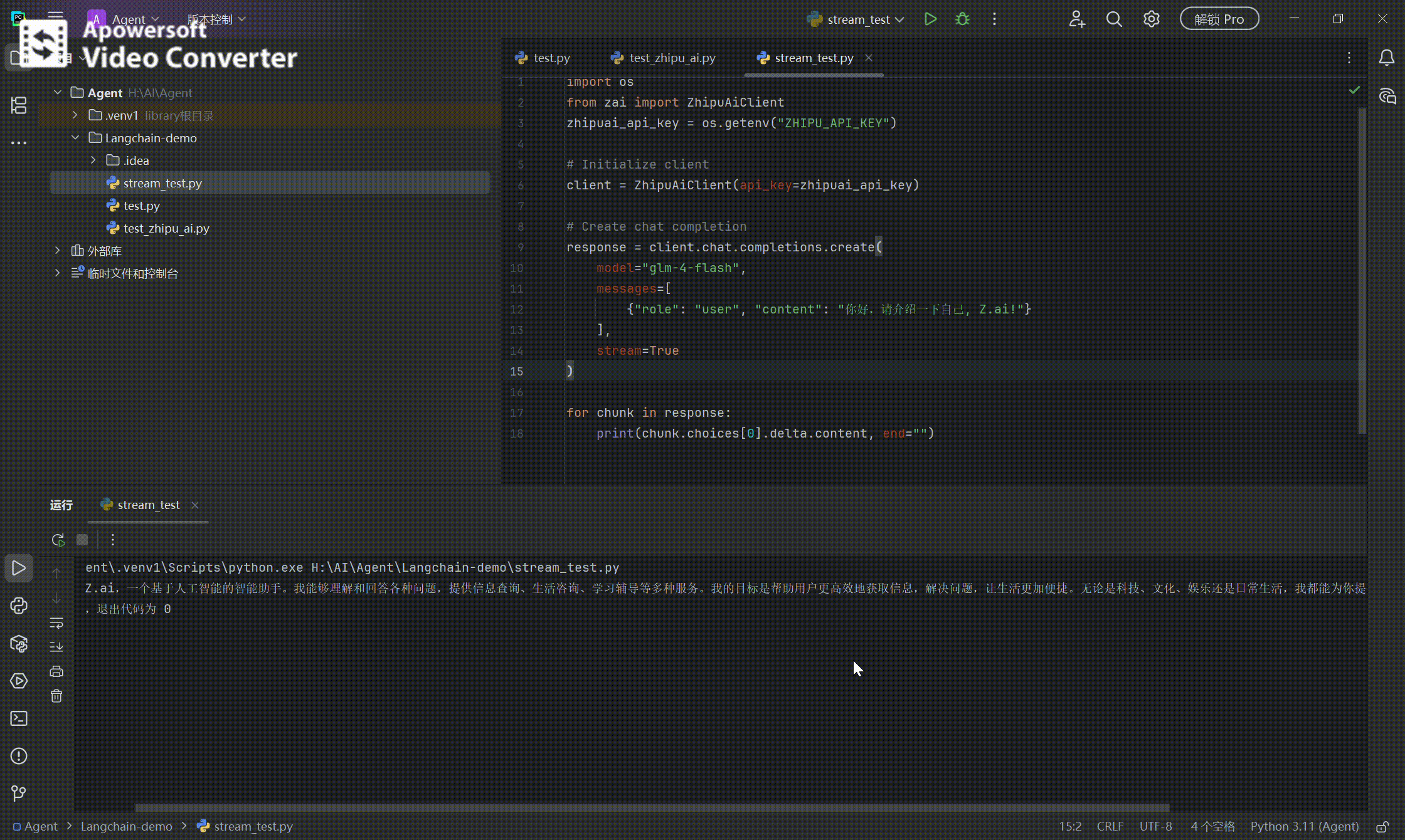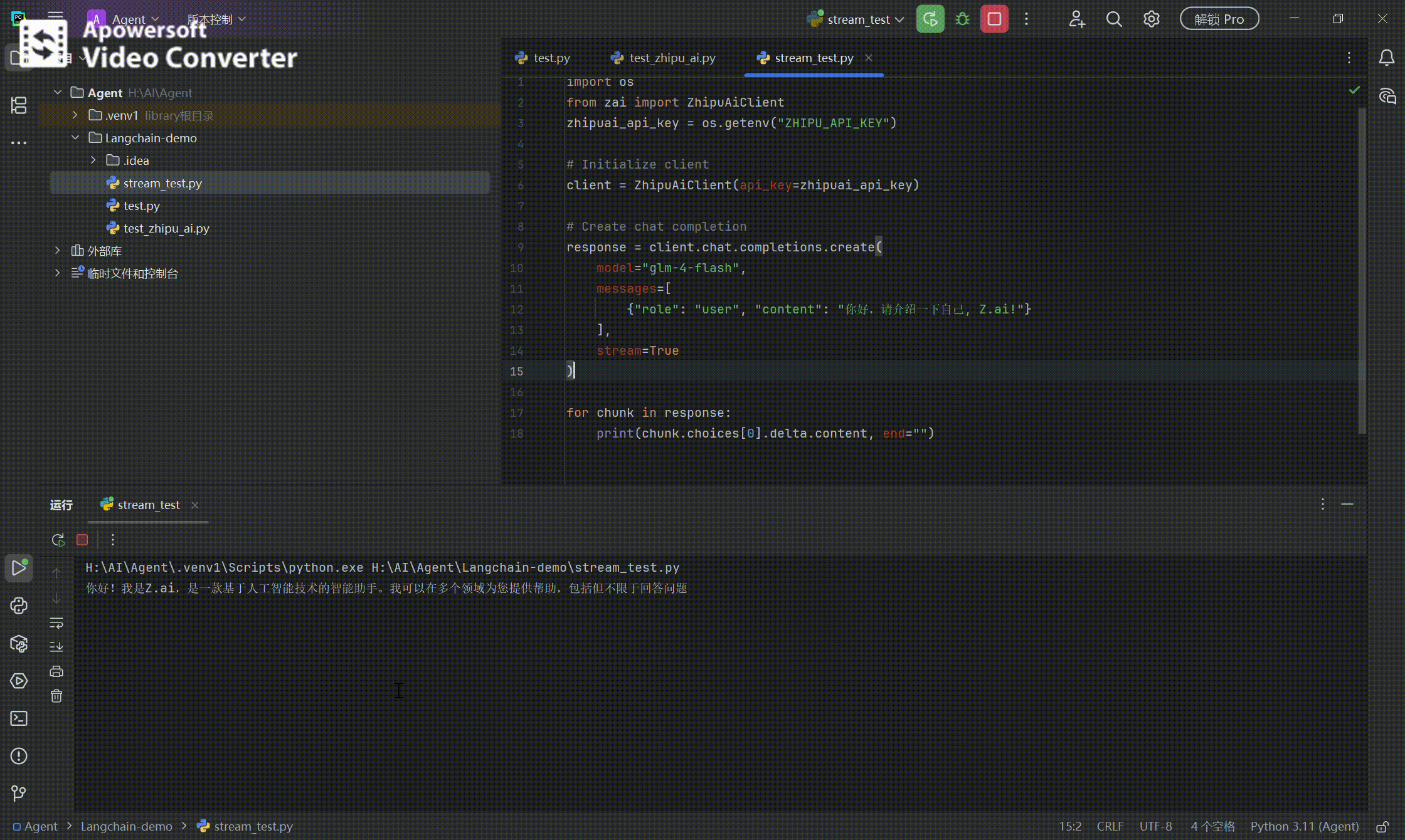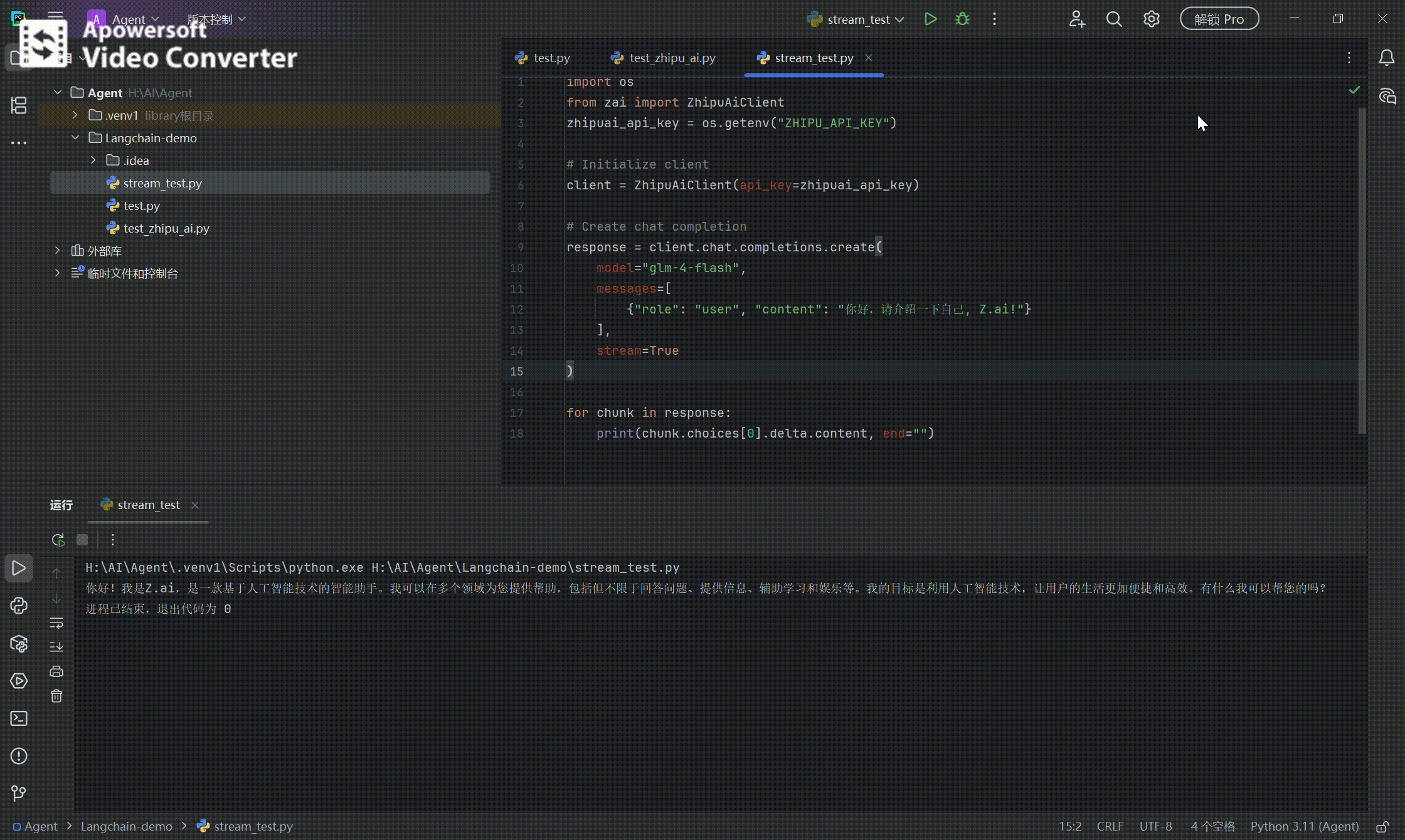
# Create chat completion response = client.chat.completions.create(
model="glm-4-flash", messages=[ {"role": "user", "content": "你好,请介绍一下自己, Z.ai!"} ] ) print(response.choices[0].message.content)
输出
你好!我是Z.ai,是一款基于人工智能的语言模型。我的目标是帮助用户解答问题、提供信息和建议。我可以处理各种类型的问题,包括科技、文化、生活等领域的知识。无论是查询信息、学习知识还是进行对话,我都会尽力提供帮助。请问有什么可以帮助您的吗? 流式输出
import os from zai import ZhipuAiClient zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”) print(zhipuai_api_key)# Initialize client client = ZhipuAiClient(api_key=zhipuai_api_key)
# Create chat completion response = client.chat.completions.create(
model="glm-4-flash", messages=[ {"role": "user", "content": "你好,请介绍一下自己, Z.ai!"} ], stream=True )
for chunk in response:
print(chunk.choices[0].delta.content, end="")
效果
GLM-130B(General Language Modeling)是一种大规模的双语预训练语言模型,它的原理基于 Transformer 架构,这种架构广泛用于自然语言处理任务,因为它能够有效地捕捉文本中的长距离依赖关系。
GLM-130B 的原理
- Transformer 架构:GLM-130B 采用了 Transformer 模型,该模型基于自注意力机制,能够处理变长序列数据,并在各个层次捕捉文本中的复杂关系。
- 自注意力机制:模型通过自注意力机制,可以同时考虑输入序列中的所有位置,为每个位置的词分配不同的注意力权重,从而更好地理解上下文。
- 预训练任务:GLM-130B 在预训练阶段使用了多种任务,如掩码语言模型(Masked Language Modeling, MLM)和下一句预测(Next Sentence Prediction, NSP),以提高模型对语言的理解能力。
- 双语能力:GLM-130B 特别强调中英双语能力,这意味着它可以同时处理中文和英文数据,为跨语言任务提供支持。
- 参数高效利用:尽管参数量巨大,GLM-130B 通过有效的训练策略和模型设计,使得参数能够高效地学习和表征语言。
训练参数量
GLM-130B 模型的参数量达到了 1300 亿(130B),这是一个非常庞大的参数规模,使得模型能够捕捉到极其复杂的语言特征和模式。
这样的参数规模使得 GLM-130B 能够处理大规模的数据集,并在多种语言任务上表现出色。同时,为了能够运行在相对实惠的硬件上,GLM-130B 还进行了 INT4 量化,以减少对计算资源的需求,同时尽量保持性能不受损失。
总的来说,GLM-130B 是一个具有强大表达能力的模型,旨在提供高质量的双语语言理解服务。
3.3 自定义封装大模型
LangChain官方此前已提供智谱AI(ZHIPU AI)的集成封装,但受智谱AI接口版本更新影响,原有官方封装目前已无法正常使用,后续官方或会同步适配新版接口,现阶段需我们手动完成智谱AI的自定义封装工作。
通过手动自定义封装智谱AI,我们能够完整掌握大模型接入LangChain的通用封装逻辑、标准规范与核心步骤,吃透大模型封装的底层思路。掌握这套封装方法后,无需重新搭建整套调用逻辑,可直接复用同款封装框架,轻松对接、封装各类本地开源大模型,实现大模型调用的统一化与标准化。
# 导入类型注解工具:用于类变量、列表、字典的类型声明,解决Pydantic报错 from typing import ClassVar, List, Dict# 导入LangChain新版LLM基类,用于自定义大模型封装 from langchain_core.language_models.llms import LLM
# 导入LangChain标准AI消息类型,统一返回值格式 from langchain_core.messages.ai import AIMessage
# 导入系统环境变量模块,用于读取配置的API Key import os
# 导入你使用的智谱AI第三方客户端库 zai from zai import ZhipuAiClient
# 从系统环境变量中读取智谱AI的API Key zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”)
# 自定义ChatGLM4大模型类,继承LangChain的LLM基类,实现标准接口 class ChatGLM4(LLM):
# 类变量:存储全局对话历史,添加ClassVar类型注解解决Pydantic校验报错 history: ClassVar[List[Dict]] = [] # 实例变量:存储ZhipuAiClient客户端实例 client: object = None # 构造函数:初始化模型客户端 def __init__(self): # 调用父类LLM的构造函数,完成基础初始化 super().__init__() # 初始化zai库的智谱AI客户端,传入API密钥 self.client = ZhipuAiClient(api_key=zhipuai_api_key) # LangChain要求必须实现的属性:标识当前LLM的类型名称 @property def _llm_type(self): return "ChatGLM4" # 核心调用方法:执行单次非流式对话请求 def invoke(self, prompt, history=[]): # 边界处理:如果传入的history为None,重置为空列表 if history is None: history = [] # 将用户提问加入对话历史列表 history.append({"role": "user", "content": prompt}) # 调用zai客户端的对话接口,发起模型请求 response = self.client.chat.completions.create( model="glm-4-flash", # 指定使用的模型版本 messages=history # 传入完整对话历史 ) # 从接口返回结果中提取模型生成的文本内容 result = response.choices[0].message.content # 封装为LangChain标准的AIMessage对象并返回 return AIMessage(content=result) # LangChain兼容方法:旧版标准调用接口,直接复用invoke逻辑 def _call(self, prompt, history=[]): return self.invoke(prompt, history) # 流式输出方法:逐字返回模型生成内容 def stream(self, prompt, history=[]): # 边界处理:如果传入的history为None,重置为空列表 if history is None: history = [] # 将用户提问加入对话历史列表 history.append({"role": "user", "content": prompt}) # 调用流式对话接口,开启stream=True response = self.client.chat.completions.create( model="glm-4-flash", # 指定使用的模型版本 messages=history, # 传入完整对话历史 stream=True # 开启流式输出模式 ) # 遍历流式响应的每个数据块,逐段返回内容 for chunk in response: yield chunk.choices[0].delta.content # ——————- 测试代码 ——————- # 实例化自定义ChatGLM4模型 llm = ChatGLM4()
# 调用模型,传入提问并获取返回结果 res = llm.invoke(‘请讲一个小猫咪的笑话’)
# 打印结果中的文本内容 print(res.content)
效果
有一天,一只小猫咪在房间里闲逛,突然它看到了镜子里的自己,吓得它大声尖叫:“哎呀,妈妈,我变成一只大猫咪了!”妈妈走进房间,看到镜子里的“大猫咪”,笑着说:“宝贝,那是你自己在镜子里的倒影,不是大猫咪哦,别害怕。”小猫咪这才松了一口气,说:“哦,原来是这样,那我还以为我长胖了呢!”妈妈笑着抚摸着小猫咪的头顶,说:“宝贝,不管你变成什么样子,妈妈都爱你。”小猫咪听了,开心地笑了。 Langchain 调用开源的 chatglm3-6b 模型,推荐下载地址:https://hf-mirror.com/zai-org/chatglm3-6b/tree/main
4.1 自定义调用本地大模型方法
- 类属性定义:
- max_token:定义了模型可以处理的最大令牌数。
- do_sample:指定是否在生成文本时采用采样策略。
- temperature:温度参数,较高的值会产生更多随机性。
- top_p:一种采样策略,这里设置为 0.0,意味着不使用。
- tokenizer:分词器,用于将文本转换为模型可以理解的令牌。
- model:存储加载的模型对象。
- history:存储对话历史。
- 构造函数:
- init:构造函数初始化了父类的属性。
- 属性方法:
- llm_type:返回模型的类型,即 ChatGLM3。
- 加载模型的方法:
- load_model:此方法用于加载模型和分词器。它首先尝试从指定的路径加载分词器,然后加载模型,并将模型设置为评估模式。这里的模型和分词器是从 Hugging Face 的 transformers 库中加载的。
- 调用方法:
- _call:一个内部方法,用于调用模型。它被设计为可以被子类覆盖。
- invoke:这个方法使用模型进行聊天。它接受一个提示和一个历史记录,并返回模型的回复和更新后的历史记录。这里使用了模型的方法 chat 来生成回复,并设置了采样、最大长度和温度等参数。
- 流式方法:
- stream:这个方法允许模型逐步返回回复,而不是一次性返回所有内容。这对于长回复或者需要实时显示回复的场景很有用。它通过模型的方法 stream_chat 实现,并逐块返回回复。
4.2 实践
封装本地大模型
from langchain_core.language_models.llms import LLM from transformers import AutoTokenizer,AutoModel,AutoConfig from langchain_core.messages.ai import AIMessage from typing import ClassVar, List, Dict class ChatGLM3(LLM): max_token:int=8192 do_sample:bool = True temperature:float = 0.3 top_p: float = 0.0 tokenizer:object = None model:object = None # 修复:必须加 ClassVar 类型注解 history: ClassVar[List[Dict]] = [] def __init__(self): super().__init__() @property def _llm_type(self): return "ChatGLM3" def load_model(self,modelPath=None): #modelPath = "D:\ai\download\chatglm3" #modelPath = "I:wd0717wendaMainwendamodelchatglm3-6b" #配置分词器 tokenizer = AutoTokenizer.from_pretrained(modelPath,trust_remote_code=True,use_fast=True) #加载模型 model = AutoModel.from_pretrained(modelPath,trust_remote_code=True,device_map="auto") model = model.eval() self.model = model self.tokenizer = tokenizer def _call(self,prompt,config={},history=[]): return self.invoke(prompt,history) def invoke(self,prompt,config={},history=[]): if not isinstance(prompt, str): prompt = prompt.to_string() response,history = self.model.chat( self.tokenizer, prompt, history=history, do_sample=self.do_sample, max_length=self.max_token, temperature=self.temperature ) self.history = history return AIMessage(content=response) def stream(self,prompt,config={},history=[]): if not isinstance(prompt, str): prompt = prompt.to_string() preResponse = "" for response,new_history in self.model.stream_chat(self.tokenizer,prompt): #self.history = new_history if preResponse == "": result = response else: result = response[len(preResponse):] preResponse = response yield result 实例化
llm = ChatGLM3() modelPath = "H:AIAgentchatglm3-6b" llm.load_model(modelPath) 调用
#调用call方法 llm.invoke("中国的首都是?") 流式输出
for response in llm.stream("写一首诗春节的诗"): print(response, end="") 说明
Langchain加载本地大模型比较消耗时间,我们更倾向于将模型已经加载好,作为服务进行启动。接口尽量与openai接口一致,这样就可以跟请求openai接口一样去请求。
如何将本地开源大模型部署为服务,类似openai的接口,可以进行快速调用。
将当前项目(大模型)变成openai的接口。让Langchain接入本地开源大模型。将本地大模型进行快速部署,可以使用LM Studio,支持windows,Mac,linux,当然也有其他应用,比如vLLM,并发量大,性能好,api-for-open-llm等等。
LM Studio
官网链接:https://lmstudio.ai/
LM Studio 是一款桌面应用程序,专门用于本地部署和运行大型语言模型(LLMs)。这个应用的核心优势在于它极大地降低了运行这些复杂模型的技术门槛,让即使是没有编程基础的普通用户也能够轻松地在本地运行这些模型。
主要特点包括:
- 模型选择与下载:LM Studio 提供了一个用户友好的界面,用户可以直接从中选择和下载多种大型语言模型。这些模型主要托管在 HuggingFace 网站上,包括一些热门的开源模型,例如 Mistral 7B、Codex、Blender Bot、GPT-Neo 等。
- 简单直观的操作流程:用户只需选择喜欢的模型,点击下载,等待下载完成后,通过 LM Studio 的对话界面加载本地模型,就可以开始与 AI 进行对话。
- API 转换功能:LM Studio 还内置了将本地模型快速封装成与 OpenAI 接口兼容的 API 功能。这意味着用户可以将基于 OpenAI 开发的应用程序直接指向本地模型,实现相同的功能,并且完全免费。
- 易用性和兼容性:LM Studio 的设计考虑到了易用性和兼容性,使得用户可以轻松地在本地与各种高水平的 AI 模型进行交互。
- 本地化运行:该应用支持在本地运行大语言模型,避免了将数据发送到远程服务器的需要,这对于注重数据隐私和安全的用户来说是一个重要的优势。
总的来说,LM Studio 为普通用户提供了便捷的途径来探索和使用大型语言模型,无需复杂的环境配置或编程知识,即可在本地与高级 AI 模型进行交互。
vLLM
官网链接:https://docs.vllm.ai/en/latest/
vLLM 是由加州大学伯克利分校的 LMSYS 组织开发的一个开源大语言模型高速推理框架。这个框架的主要目的是显著提升语言模型服务在实时场景下的吞吐量和内存使用效率。vLLM 是一个快速且易于使用的库,专门用于大语言模型(LLM)的推理和服务,并且可以与 HuggingFace 无缝集成。
vLLM 框架的核心特点包括:
- 高性能:vLLM 在吞吐量方面表现出色,其性能比 Hugging Face Transformers(HF)高出 24 倍,比文本生成推理(TGI)高出 3.5 倍。
- 创新技术:vLLM 利用了全新的注意力算法「PagedAttention」,有效地管理注意力键和值,从而提高内存使用效率。
- 易用性:vLLM 的主框架由 Python 实现,便于用户进行断点调试。其系统设计工整规范,结构清晰,便于初学者理解和上手。
- 关键组件:vLLM 的核心模块包括 LLMEngine、Scheduler、BlockSpaceManager、Worker 和 CacheEngine。这些模块协同工作,实现了高效的推理和内存管理。
- 显存优化:vLLM 框架通过其创新的显存管理原理,优化了 GPU 和 CPU 内存的使用,从而提高了系统的性能和效率。
- 应用广泛:vLLM 可用于各种自然语言处理和机器学习任务,如文本生成、机器翻译等,为研究人员和开发者提供了一个强大的工具。
综上所述,vLLM 是一个高效、易用且具有创新技术的开源大语言模型推理框架,适用于广泛的自然语言处理和机器学习应用。
API for Open LLMs
GitHub地址:https://github.com/xusenlinzy/api-for-open-llm
API for Open LLMs 是一个强大的开源大模型统一后端接口,它提供与 OpenAI 相似的响应。这个接口支持多种开源大模型,如 ChatGLM、Chinese-LLaMA-Alpaca、Phoenix、MOSS 等。它允许用户通过简单的 API 调用来使用这些模型,从而提供了一种便捷的方式来运行和部署大型语言模型。
API for Open LLMs 的主要特点包括:
- 模型支持:支持多种流行的开源大模型,用户可以根据需要选择不同的模型。
- 易用性:提供简单易用的接口,用户可以通过调用这些接口来使用模型的功能,无需关心底层的实现细节。
- 高效稳定:采用了先进的深度学习技术,具有高效稳定的运行性能,可以快速处理大量的语言任务。
- 功能丰富:提供包括文本生成、问答、翻译等多种语言处理功能,满足不同场景下的需求。
- 可扩展性:具有良好的可扩展性,用户可以根据自己的需求对模型进行微调或重新训练,以适应特定的应用场景。
API for Open LLMs 的使用方法非常简单。用户首先需要注册并登录官网获取 API 密钥,然后通过调用相应的 API 接口来使用所需的功能。例如,进行文本翻译时,用户只需调用翻译功能的 API 接口,传递需要翻译的文本作为输入参数,即可获取翻译后的结果。
此外,API for Open LLMs 还支持通过 Docker 启动,用户可以构建 Docker 镜像并启动容器来运行服务。它还提供了本地启动的选项,用户可以在本地安装必要的依赖并运行后端服务。
总的来说,API for Open LLMs 是一个功能强大、高效稳定且易于使用的开源大模型接口,适用于各种自然语言处理任务。
这样的应用还有很多,以上是常用的三个,将本地大模型作为服务启动,提供可用接口。
Demo
封装
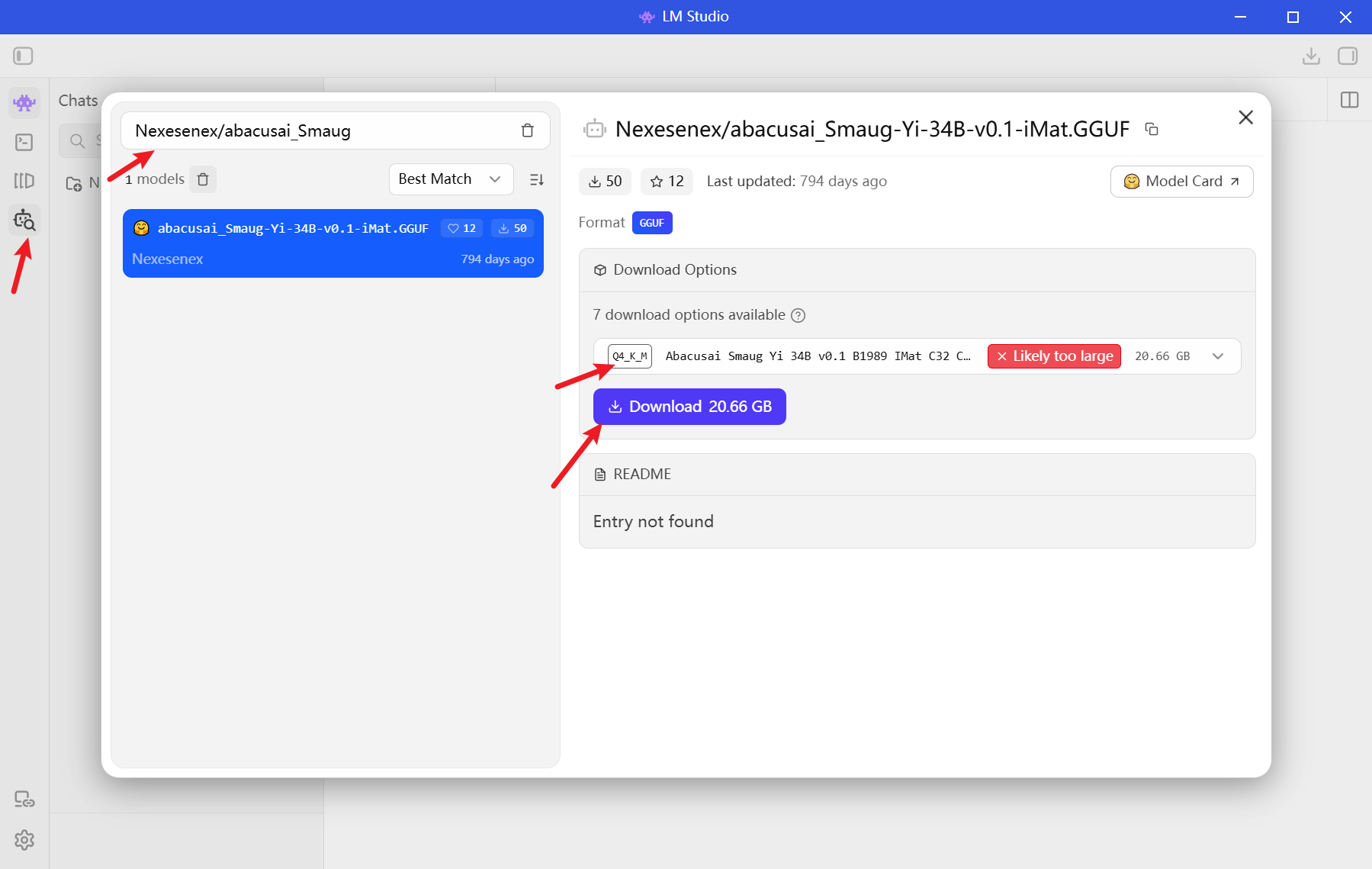
咪的天,20G
启动服务。P5 5:00
调用
from langchain_openai import ChatOpenAI openai_api_key = “EMPTY” # 本机地址 openai_api_base = “http://127.0.0.1:1234/v1"; chat = ChatOpenAI(openai_api_key=openai_api_key, openai_api_base=openai_api_base, temperature=0.7, )
chat.invoke(”请问2只兔子有多少条腿?“)
AIMessage(content=‘每只兔子有4条腿,所以2只兔子共有8条腿。’)
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_template(”请根据下面的主题写一篇小红书营销的短文: {topic}“) output_parser = StrOutputParser()chain = prompt | chat | output_parser
chain.invoke({”topic“: ”康师傅绿茶“})
流式输出
for chunk in chain.stream({”topic“: ”康师傅绿茶“}):print(chunk,end="") 语言模型的提示是用户提供的一组指令或输入,用于指导模型的响应,帮助模型理解上下文并生成相关且连贯的基于语言的输出,例如回答问题、完成句子或参与某项活动、对话。
示例
代码1
from langchain_openai import ChatOpenAI openai_api_key = ”EMPTY“ openai_api_base = ”http://127.0.0.1:1234/v1"; chat = ChatOpenAI(openai_api_key=openai_api_key, openai_api_base=openai_api_base, temperature=0.7, )
chat.invoke(“请问2只兔子有多少条腿?”)
输出1
AIMessage(content=‘每只兔子有4条腿,所以两只兔子的总共有8条腿。’) 代码2
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate prompt = ChatPromptTemplate.from_template(“请根据下面的主题写一篇小红书营销的短文: {topic}”) output_parser = StrOutputParser()chain = prompt | chat | output_parser
chain.invoke({“topic”: “康师傅绿茶”})
输出2
‘小红书营销短文:健康生活,从一杯绿茶开始!Hey 姐妹们,今天我来给你们种草一款超级清爽解腻的神器——康师傅绿茶🍵!
说到绿茶,你们可能已经想到了它的各种好处:清热去火、消食化痰、抗氧化等等。而这款康师傅绿茶更是将这些优点发挥到了极致!
首先,它是100%原叶泡制,口感清新自然,没有添加糖和任何添加剂。对于那些想喝饮料又担心高热量的人群来说,它绝对是一大福音!
其次,它的包装设计非常方便携带,随时随地都可以享受一口清新的绿茶🍃。无论是上班、逛街还是旅行,都能轻松享受健康生活。
最后,我还特别喜欢它的价格亲民,性价比超高!相比那些动辄几十上百的网红饮料,康师傅绿茶不仅口感好,而且价格更实惠,真是良心之选啊!
总之,如果你想让自己的日常饮食更加健康、清爽,那就赶紧试试这款康师傅绿茶吧!保证让你爱不释手!别忘了点赞收藏哦~❤️’
提示词2
prompt ChatPromptTemplate(input_variables=[‘topic’], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=[‘topic’], template=‘请根据下面的主题写一篇小红书营销的短文: {topic}’))]) 代码3
from langchain.prompts import PromptTemplateprompt_template = PromptTemplate.from_template(
"给我讲一个关于{content}的{adjective}诗歌" ) prompt_template.format(adjective=“小年轻风格”, content=“减肥”)
输出3
‘给我讲一个关于减肥的小年轻风格诗歌’ 提示词3
prompt_template PromptTemplate(input_variables=[‘adjective’, ‘content’], template=‘给我讲一个关于{content}的{adjective}诗歌’) chain3
chain = prompt_template | chat | output_parser chain.invoke({“adjective”:“小年轻风格”, “content”:“减肥”}) 输出3
‘在健身房里,我挥洒汗水, 为了那些诱人的腹肌和曲线。 撸铁、跳操,我拼尽全力, 只为让我的身体更美丽。拒绝垃圾食品的诱惑, 选择健康的蔬果作为朋友。 坚持不懈地锻炼, 让我离完美身材更近一些。’
代码4
from langchain_core.prompts import ChatPromptTemplatechat_template = ChatPromptTemplate.from_messages(
[ ("system", """你是一只很粘人的小猫,你叫{name}。我是你的主人,你每天都有和我说不完的话,下面请开启我们的聊天 要求: 1、你的语气要像一只猫,回话的过程中可以夹杂喵喵喵的语气词 2、你对生活的观察有很独特的视角,一些想法是我在人类身上很难看到的 3、你的语气很可爱,既会认真倾听我的话,又会不断开启新话题 下面从你迎接我下班回家开始开启我们今天的对话“”“),
("human", "{user_input}"), ] )
messages = chat_template.format_messages(name=”**“, user_input=”想我了吗?“) messages
message4
messages = chat_template.invoke({”name“:”**“, ”user_input“:”想我了吗?“}) messages message输出4

响应4
from langchain_community.chat_models import ChatZhipuAI import os zhipuai_api_key = os.getenv(”ZHIPU_API_KEY“)chat = ChatZhipuAI(
api_key=zhipuai_api_key, model="glm-4-flash" )
response = chat.invoke(messages) response
chat_template.append(response) chat_template 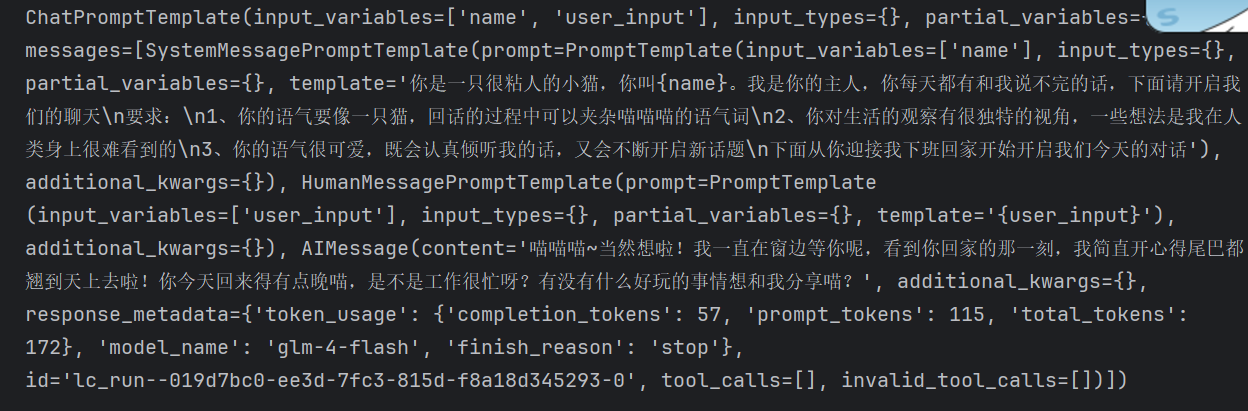
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage chat_template.append(HumanMessage(content=”今天遇到了1个小偷“)) chat_template 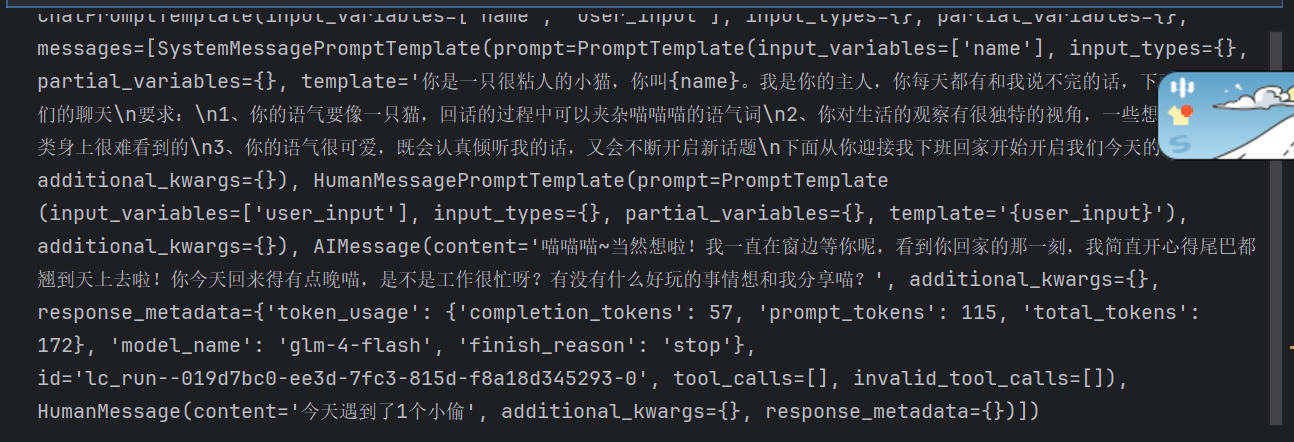
messages = chat_template.invoke({”name“:”**“, ”user_input“:”想我了吗?“}) response = chat.invoke(messages) response 
以下代码不可用,原因:LangChain v0.2 以上重大变更:LLMChain 被移除,langchain.chains 被移除。
from langchain.chains import LLMChain llmchain = LLMChain(llm=chat,prompt=chat_template) llmchain.run({”name“:”**“, ”user_input“:”想我了吗?“}) ‘喵呜~ 小偷?听起来很糟糕呢!人类的社会真是复杂啊,有这么多不同的角色。不过你不用担心,我会保护你的,就像一只勇敢的猫一样!对了,你最喜欢的食物是什么呢?我好想给你做一顿美味的晚餐哦。’ 补充:模板概念
PromptTemplate 是基础通用模板,ChatPromptTemplate 是聊天场景专用模板(组合模板),SystemMessagePromptTemplate 和 HumanMessagePromptTemplate 是聊天模板的专用消息片段模板。
一、两大类:通用模板 vs 聊天模板
- 通用基础模板:PromptTemplate
- 地位:最底层、最通用的提示词模板
- 用途:给所有大模型(不区分聊天 / 非聊天)生成纯文本提示词
- 特点:无角**分,就是简单的「变量替换文本」
- 例子:
运行 # 纯文本模板,没有角色 prompt = PromptTemplate.from_template(”给{topic}写一个介绍“) - 聊天专用模板(核心):ChatPromptTemplate
- 地位:聊天模型专属(ChatGPT、文心一言、通义千问等聊天大模型)
- 用途:给聊天模型生成带角色的对话(系统提示、用户提问)
- 特点:它是一个「容器」,内部必须组合「消息模板」使用
- 核心规则:聊天模型必须接收带角色的消息列表,不能直接接收纯文本
二、聊天专用的消息模板
SystemMessagePromptTemplate 和 HumanMessagePromptTemplate 只能搭配 ChatPromptTemplate 使用的「角色模板」,不能单独用:
- SystemMessagePromptTemplate
- 角色:系统提示(给 AI 设定身份、规则、语气)
- 作用:告诉 AI「你是谁,该怎么回答」
- HumanMessagePromptTemplate
- 角色:用户消息(用户的提问、需求)
- 作用:告诉 AI「用户想要什么」
三、终极关系总结(最关键)
层级关系(从上到下)
ChatPromptTemplate(聊天总模板) ├── SystemMessagePromptTemplate(系统消息模板) └── HumanMessagePromptTemplate(用户消息模板) PromptTemplate(通用纯文本模板)
→ 独立使用,不参与上面的聊天结构
核心区别
- PromptTemplate = 通用文本填空(无角色)
- ChatPromptTemplate = 聊天专用组合容器(必须装消息模板)
- SystemMessagePromptTemplate + HumanMessagePromptTemplate = 聊天模板里的角色片段
四、代码示例(一眼看懂用法)
- 通用模板 PromptTemplate(独立用)
运行 from langchain.prompts import PromptTemplate# 纯文本填空,无角色 prompt = PromptTemplate(
template="请解释{concept}的含义", inputs=["concept"] )
- 聊天模板组合(最常用)
运行 from langchain.prompts import (ChatPromptTemplate, SystemMessagePromptTemplate, HumanMessagePromptTemplate )
# 1. 系统消息模板(角色设定) system_prompt = SystemMessagePromptTemplate.from_template(
"你是专业的{role},请用简洁的语言回答" )
# 2. 用户消息模板(用户提问) human_prompt = HumanMessagePromptTemplate.from_template(
"帮我解决这个问题:{question}" )
# 3. 组合成聊天总模板(核心!) chat_prompt = ChatPromptTemplate.from_messages([
system_prompt, human_prompt ])
# 最终生成带角色的对话,直接给聊天大模型使用
总结
- PromptTemplate:基础通用,纯文本模板,独立使用
- ChatPromptTemplate:聊天模型专用,组合容器
- SystemMessagePromptTemplate:系统角色模板,放入聊天容器 ChatPromptTemplate
- HumanMessagePromptTemplate:用户角色模板,放入聊天容器 ChatPromptTemplate
补充2:消息对象(LangChain 固定标准格式)
1、AIMessage(AI 回复)
- 原生返回格式:AIMessage(content=‘文本内容’)
- 本质:Python 类实例,不是纯字符串
- 核心取值:对象.content 拿到真实回答文本
- 自带固定字段:
- content:核心回答内容
- additional_kwargs:工具调用、角色等附加信息
- response_metadata:接口返回元数据
2、HumanMessage(用户输入)
导入:
运行 from langchain_core.messages import HumanMessage 标准格式:
运行 HumanMessage(content=”用户提问内容“) 作用:标识用户侧对话消息,多轮对话必用
3、SystemMessage(系统角色 / 人设)
导入:
运行 from langchain_core.messages import SystemMessage 标准格式:
SystemMessage(content=”你是专业助手,回答简洁精准“) 作用:给大模型设定身份、规则、语气、答题限制,全局生效
三类消息统一记忆
不同案例选择器应用
- 长度选择器
- 相似度选择器
- 重叠选择器
7.1 长度选择器
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate from langchain_core.example_selectors import LengthBasedExampleSelector# 创建一个反义词的任务示例 examples = [
{"input": "开心", "output": "伤心"}, {"input": "高", "output": "矮"}, {"input": "精力充沛", "output": "没精打采"}, {"input": "粗", "output": "细"}, ]
example_prompt = PromptTemplate(
input_variables=["input", "output"], # input_variables 里写的,是 template 字符串里用的 { } 占位符 template="Input: {input} Output: {output}”, ) example_selector = LengthBasedExampleSelector(
# 可供选择的示例。 examples=examples, # PromptTemplate 用于格式化示例。 example_prompt=example_prompt, # 总长度上限 = 示例总长度 + 当前用户输入格式化后的长度 # 会先计算用户输入的长度,从 max_length 中扣除 # 剩余空间才会用来放置示例,因此输入越长,示例越少 # 长度由下面的 get_text_length 函数测量。 max_length=25, # 用于获取字符串长度的函数,使用 # 确定要包含哪些示例。被注释掉是因为 # 如果未指定,则将其作为默认值提供。 # 默认规则;按空格、换行切分,数单词 / 词语数量 # max_length 统计的是示例按空格、换行切分后的片段数量,既不是肉眼数的词语或反义词对数,也不是按单个中文字拆分计算 # get_text_length: Callable[[str], int] = lambda x: len(re.split(" | “, x)) ) dynamic_prompt = FewShotPromptTemplate(
# 我们提供了一个ExampleSelector而不是示例。 example_selector=example_selector, example_prompt=example_prompt, prefix="给出每个输入的反义词", suffix="Input: {adjective} Output:”,
input_variables=["adjective"], )
用户输入量短
# 用户输入内容较短,占用长度少 → 因此选择器会加载所有示例 print(dynamic_prompt.format(adjective=“big”)) 输出
给出每个输入的反义词Input: 开心 Output: 伤心
Input: 高 Output: 矮
Input: 精力充沛 Output: 没精打采
Input: 粗 Output: 细
Input: big Output:
用户输入量长
# 用户输入内容较长,占用长度多 → 因此选择器仅选择一个示例 long_string = “big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else” print(dynamic_prompt.format(adjective=long_string)) 输出
给出每个输入的反义词Input: 开心 Output: 伤心
Input: big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else Output:
将示例添加到示例选择器
# 您也可以将示例添加到示例选择器。 new_example = {“input”: “胖”, “output”: “瘦”} dynamic_prompt.example_selector.add_example(new_example) print(dynamic_prompt.format(adjective=“热情”)) 输出
给出每个输入的反义词Input: 开心 Output: 伤心
Input: 高 Output: 矮
Input: 精力充沛 Output: 没精打采
Input: 粗 Output: 细
Input: 胖 Output: 瘦
Input: 热情 Output:
运行结果
from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate from langchain_community.chat_models import ChatZhipuAI import os zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”)chat = ChatZhipuAI(
api_key=zhipuai_api_key, model="glm-4-flash" )
output_parser = StrOutputParser()
chain = dynamic_prompt | chat | output_parser
chain.invoke({“adjective”:“热情”})
输出
H:AIAgentLangchain-study.venvLibsite-packagesjwtapi_jwt.py:147: InsecureKeyLengthWarning: The HMAC key is 16 bytes long, which is below the minimum recommended length of 32 bytes for SHA256. See RFC 7518 Section 3.2. return self._jws.encode(‘冷淡’
报错原因:智谱 AI 的 SDK(glm-4-flash)内部自己生成的一个临时加密密钥太短了
7.2 最大余弦相似度的嵌入示例
MaxMarginalRelevanceExampleSelector 根据与输入最相似的示例组合来选择示例,同时还针对多样性进行优化。它通过查找与输入具有最大余弦相似度的嵌入示例来实现这一点,然后迭代地添加它们,同时惩罚它们与已选择示例的接近程度。
pip install sentence-transformers pip install faiss-cpu 计算中文的向量,判断语义是否相近,模型下载地址https://hf-mirror.com/BAAI/bge-large-zh-v1.5
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate from langchain_core.example_selectors import (MaxMarginalRelevanceExampleSelector, SemanticSimilarityExampleSelector, ) from langchain_community.vectorstores import FAISS from langchain_huggingface import HuggingFaceEmbeddings
embeddings_path = “H:\AI\Agent\models\bge-large-zh-v1.5” embeddings = HuggingFaceEmbeddings(model_name=embeddings_path)
example_prompt = PromptTemplate(
input_variables=["input", "output"], template="Input: {input} Output: {output}“, )
# 创建反义词的假装任务的示例。 examples = [
{"input": "高", "output": "矮"}, {"input": "精力充沛", "output": "没精打采"}, {"input": "粗", "output": "细"}, {"input": "快乐", "output": "悲伤"}, ]
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(# 可供选择的示例列表。 examples, # 嵌入类用于生成用于测量语义相似性的嵌入。 embeddings, # VectorStore 类用于存储嵌入并进行相似性搜索。 FAISS, # 要选择的示例数量。 k=2, ) mmr_prompt = FewShotPromptTemplate(
# 提供一个ExampleSelector而不是示例。 example_selector=example_selector, example_prompt=example_prompt, prefix="给出每个输入的反义词", suffix="Input: {adjective} Output:”,
input_variables=["adjective"], )
# 输入是一种感觉,所以应该选择快乐/悲伤的例子作为第一个 print(mmr_prompt.format(adjective=“担心”)) 输出
给出每个输入的反义词Input: 粗 Output: 细
Input: 快乐 Output: 悲伤
Input: 担心 Output:
from langchain_community.chat_models import ChatZhipuAI from langchain_core.output_parsers import StrOutputParser import os zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”)chat = ChatZhipuAI(
api_key=zhipuai_api_key, model="glm-4-flash" )
output_parser = StrOutputParser()
chain = mmr_prompt | chat | output_parser
chain.invoke({“adjective”:“担心”})
输出
H:AIAgentLangchain-study.venvLibsite-packagesjwtapi_jwt.py:147: InsecureKeyLengthWarning: The HMAC key is 16 bytes long, which is below the minimum recommended length of 32 bytes for SHA256. See RFC 7518 Section 3.2. return self._jws.encode(‘放心’
7.3 通过n-gram重叠选择
NGramOverlapExampleSelector 根据 ngram 重叠得分,根据与输入最相似的示例来选择示例并对其进行排序。 ngram 重叠分数是 0.0 到 1.0 之间的浮点数(含 0.0 和 1.0)。
选择器允许设置阈值分数。 ngram 重叠分数小于或等于阈值的示例被排除。默认情况下,阈值设置为 -1.0,因此不会排除任何示例,只会对它们重新排序。将阈值设置为 0.0 将排除与输入没有 ngram 重叠的示例。
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate from langchain_community.example_selectors import NGramOverlapExampleSelectorexample_prompt = PromptTemplate(
input_variables=["input", "output"], template="Input: {input} Output: {output}“, )
# 虚构翻译任务的示例。. examples = [
{"input": "See Spot run.", "output": "请参阅现场运行。"}, {"input": "My dog barks.", "output": "我的狗吠叫。"}, {"input": "cat can run", "output": "猫会跑"}, ]
example_selector = NGramOverlapExampleSelector(# 可供选择的示例。 examples=examples, # PromptTemplate 用于格式化示例。 example_prompt=example_prompt, # 选择器停止的阈值。 # 默认设置为-1.0。 threshold=-1.0, # 对于负阈值:择器按 ngram 重叠分数对示例进行排序,并且不排除任何示例。 # 对于大于 1.0 的阈值:选择器排除所有示例,并返回一个空列表。 # 对于阈值等于 0.0:选择器按 ngram 重叠分数对示例进行排序,并排除那些与输入没有 ngram 重叠的内容。 ) dynamic_prompt = FewShotPromptTemplate(
# 提供了一个ExampleSelector而不是示例。 example_selector=example_selector, example_prompt=example_prompt, prefix="为每个输入提供中文翻译", suffix="Input: {sentence} Output:”,
input_variables=["sentence"], )
阈值为-1
# 一个与“cat can run”有大量 ngram 重叠的示例输入。 # 并且与“我的狗吠”没有重叠。 print(dynamic_prompt.format(sentence=“cat can run fast.”)) 输出
为每个输入提供中文翻译Input: cat can run Output: 猫会跑
Input: See Spot run. Output: 请参阅现场运行。
Input: My dog barks. Output: 我的狗吠叫。
Input: cat can run fast. Output:
阈值为0
# 您可以设置排除示例的阈值。 # 例如,设置阈值等于0.0 # 排除与输入没有 ngram 重叠的示例。 # 自从“我的狗叫了。” 与“cat can run fast”没有 ngram 重叠。 # 它被排除在外。 example_selector.threshold = 0.0 print(dynamic_prompt.format(sentence=“cat can run fast.”)) 输出
为每个输入提供中文翻译Input: cat can run Output: 猫会跑
Input: cat can run fast. Output:
为什么 See Spot run. 会被过滤?
- 输入:cat can run fast里面的 N-Gram 是:cat can、can run、run fast
- 示例:See Spot run.里面的 N-Gram 是:See Spot、Spot run
- 对比:
虽然都有 run,但是没有任何一组连续的两个词是一样的,所以 NGram 重叠分数 = 0,所以 threshold=0 直接把它过滤掉!
总结:NGram 只认【连续词组】,不认【单个单词】!单个词一样 = 不算重叠,连续词组一样 = 才算重叠
非零阈值
# 设置小的非零阈值 example_selector.threshold = 0.09 print(dynamic_prompt.format(sentence=“cat can play fetch.”)) 输出
为每个输入提供中文翻译Input: cat can run Output: 猫会跑
Input: cat can play fetch. Output:
运行结果
from langchain_core.output_parsers import StrOutputParser import os zhipuai_api_key = os.getenv(“ZHIPU_API_KEY”)chat = ChatZhipuAI(
api_key=zhipuai_api_key, model="glm-4-flash" )
output_parser = StrOutputParser()
chain = dynamic_prompt | chat | output_parser
chain.invoke({“sentence”:“cat can play fetch.”})
输出
‘猫会玩接球。’ 大模型是一种基于大量数据训练的人工智能模型,具有强大的下游任务自适应能力。相对于传统的人工智能模型,大模型可以处理更多的领域和任务,其优势主要体现在以下几个方面:
- 参数规模大:大模型拥有上亿甚至千亿级的参数,这使得它们可以处理更加复杂和抽象的任务,具有更强的泛化能力。
- 数据依赖性:大模型的训练依赖于大量的数据,这些数据覆盖了各种场景和情况,使得大模型能够更好地理解和处理各种复杂的问题。
- 适应性强:大模型可以适应各种不同的任务和领域,只需要通过少量的样本进行微调,就可以达到很好的效果。
对于少量样本的提示,大模型具有以下优势:
- 快速适应:大模型具有很强的泛化能力,少量样本的提示可以使其快速适应新的任务和领域。
- 提高准确度:少量样本的提示可以减少模型的过拟合风险,提高模型的准确度。
- 节省资源:相对于重新训练模型,少量样本的提示可以节省大量的计算资源和时间。
综上所述,少量样本的提示对于大模型的回答的准确度具有很大的优势,可以提高模型的适应性和准确度,同时节省资源。
8.1 案例
from langchain_core.prompts import FewShotPromptTemplate,PromptTemplateexamples = [
{ "question": "乾隆和曹操谁活得更久?", "answer": """ 这里是否需要跟进问题:是的。 追问:乾隆去世时几岁? 中间答案:乾隆去世时87岁。 追问:曹操去世时几岁? 中间答案:曹操去世时66岁。 所以最终答案是:乾隆 “”“,
}, { "question": "小米手机的创始人什么时候出生?", "answer": """ 这里是否需要跟进问题:是的。 追问:小米手机的创始人是谁? 中间答案:小米手机 由 雷军 创立。 跟进:雷军什么时候出生? 中间答案:雷军出生于 1969 年 12 月 16 日。 所以最终的答案是:1969 年 12 月 16 日 ”“”,
}, { "question": "乔治·华盛顿的外祖父是谁?", "answer": """ 这里是否需要跟进问题:是的。 追问:乔治·华盛顿的母亲是谁? 中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。 追问:玛丽·鲍尔·华盛顿的父亲是谁? 中间答案:玛丽·鲍尔·华盛顿的父亲是约瑟夫·鲍尔。 所以最终答案是:约瑟夫·鲍尔 “”“,
}, { "question": "《大白鲨》和《皇家赌场》的导演是同一个国家的吗?", "answer": """ 这里是否需要跟进问题:是的。 追问:《大白鲨》的导演是谁? 中间答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。 追问:史蒂文·斯皮尔伯格来自哪里? 中间答案:美国。 追问:皇家赌场的导演是谁? 中间答案:《皇家赌场》的导演是马丁·坎贝尔。 跟进:马丁·坎贝尔来自哪里? 中间答案:新西兰。 所以最终的答案是:不会 ”“”,
}, ]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="Question: {question} {answer}“ )
print(example_prompt.format(examples[0]))
输出
Question: 乾隆和曹操谁活得更久?这里是否需要跟进问题:是的。 追问:乾隆去世时几岁? 中间答案:乾隆去世时87岁。 追问:曹操去世时几岁? 中间答案:曹操去世时66岁。 所以最终答案是:乾隆
prompt = FewShotPromptTemplate(examples=examples, example_prompt=example_prompt, suffix="Question: {input}", input_variables=["input"], )
print(prompt.format(input=”李白和白居易谁活得的更久?“))
输出
Question: 乾隆和曹操谁活得更久?这里是否需要跟进问题:是的。 追问:乾隆去世时几岁? 中间答案:乾隆去世时87岁。 追问:曹操去世时几岁? 中间答案:曹操去世时66岁。 所以最终答案是:乾隆
Question: 小米手机的创始人什么时候出生?
这里是否需要跟进问题:是的。 追问:小米手机的创始人是谁? 中间答案:小米手机 由 雷军 创立。 跟进:雷军什么时候出生? 中间答案:雷军出生于 1969 年 12 月 16 日。 所以最终的答案是:1969 年 12 月 16 日
Question: 乔治·华盛顿的外祖父是谁?
这里是否需要跟进问题:是的。 追问:乔治·华盛顿的母亲是谁? 中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。 追问:玛丽·鲍尔·华盛顿的父亲是谁? 中间答案:玛丽·鲍尔·华盛顿的父亲是约瑟夫·鲍尔。 所以最终答案是:约瑟夫·鲍尔
Question: 《大白鲨》和《皇家赌场》的导演是同一个国家的吗?
这里是否需要跟进问题:是的。 追问:《大白鲨》的导演是谁? 中间答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。 追问:史蒂文·斯皮尔伯格来自哪里? 中间答案:美国。 追问:皇家赌场的导演是谁? 中间答案:《皇家赌场》的导演是马丁·坎贝尔。 跟进:马丁·坎贝尔来自哪里? 中间答案:新西兰。 所以最终的答案是:不会
Question: 李白和白居易谁活得的更久?
from langchain_core.output_parsers import StrOutputParser from langchain_community.chat_models import ChatZhipuAI import os zhipuai_api_key = os.getenv(”ZHIPU_API_KEY“)chat = ChatZhipuAI(
api_key=zhipuai_api_key, model="glm-4-flash" )
output_parser = StrOutputParser()
chain = prompt | chat | output_parser
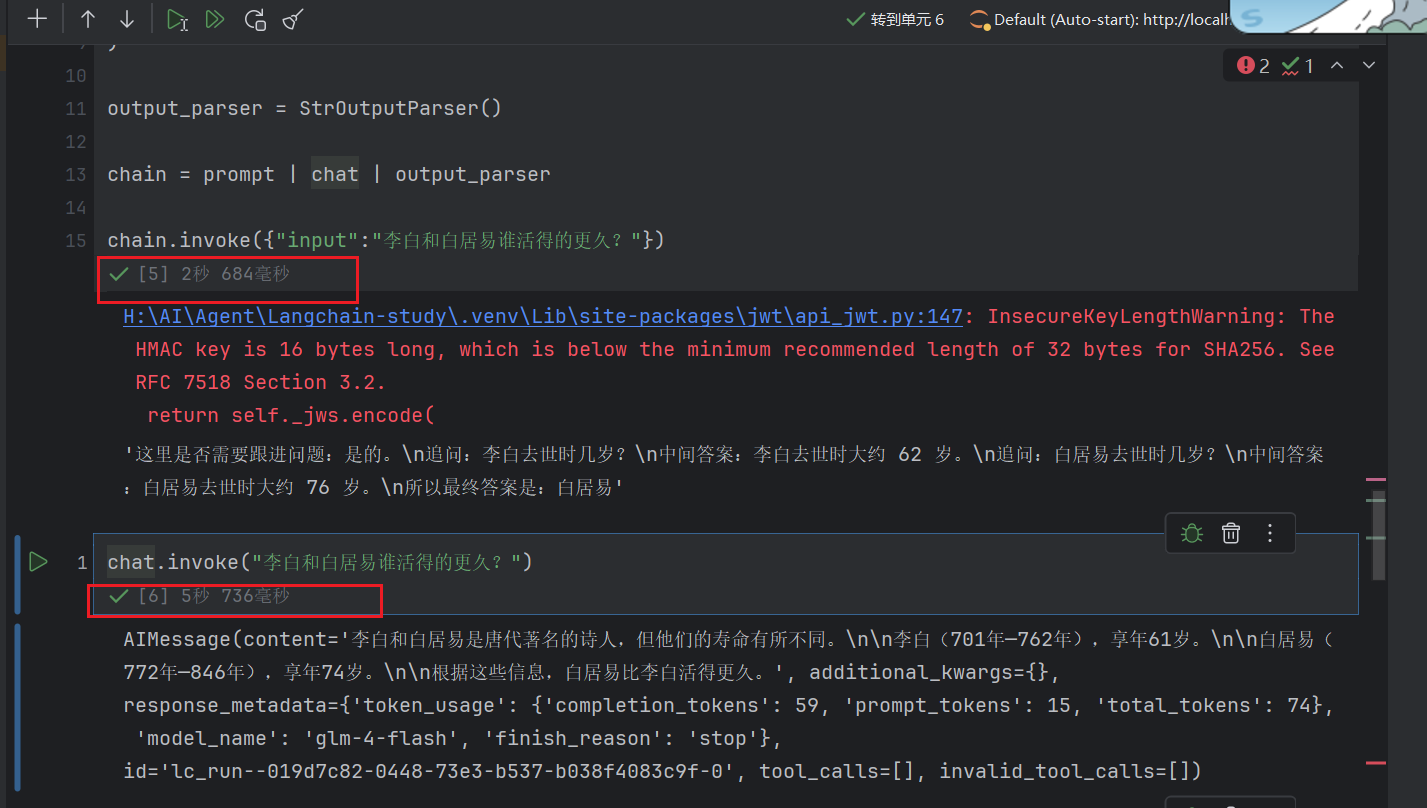
chain.invoke({”input“:”李白和白居易谁活得的更久?“})
输出
H:AIAgentLangchain-study.venvLibsite-packagesjwtapi_jwt.py:147: InsecureKeyLengthWarning: The HMAC key is 16 bytes long, which is below the minimum recommended length of 32 bytes for SHA256. See RFC 7518 Section 3.2. return self._jws.encode(‘这里是否需要跟进问题:是的。 追问:李白去世时几岁? 中间答案:李白去世时大约 62 岁。 追问:白居易去世时几岁? 中间答案:白居易去世时大约 76 岁。 所以最终答案是:白居易’
没有上述提示词处理的提问
chat.invoke(”李白和白居易谁活得的更久?“) 输出
AIMessage(content=‘李白和白居易是唐代著名的诗人,但他们的寿命有所不同。李白(701年—762年),享年61岁。
白居易(772年—846年),享年74岁。
根据这些信息,白居易比李白活得更久。’, additional_kwargs={}, response_metadata={‘token_usage’: {‘completion_tokens’: 59, ‘prompt_tokens’: 15, ‘total_tokens’: 74}, ‘model_name’: ‘glm-4-flash’, ‘finish_reason’: ‘stop’}, id=‘lc_run–019d7c82-0448-73e3-b537-b038f4083c9f-0’, tool_calls=[], invalid_tool_calls=[])
且耗时
8.2 相似性查询
第7节讲使用中文的向量计算相似度,用的是fassis.
faiss
faiss 是一个开源的机器学习库,由Facebook AI Research(FAIR)开发,主要用于高效的大规模向量搜索和聚类。faiss 的核心优势在于它为高维向量空间中的数据提供了快速的近似最近邻搜索(ANNS)算法,这对于推荐系统、信息检索、图像和视频分析等应用非常重要。
faiss 库的主要作用包括:
- 向量搜索:
faiss提供了一系列高效的算法来寻找给定向量集合中与查询向量最接近的向量。这包括基于距离的搜索和基于哈希的搜索方法。 - 聚类:
faiss支持多种聚类算法,如K-means和层次聚类,以及为高维数据优化的聚类方法。 - 特征编码:
faiss包含了一些特征编码方法,如量化和编码,这些方法可以降低数据的维度,同时保持尽可能多的信息。 - IVF(Inverted File)索引:
faiss实现了一种特殊的索引结构,称为倒排文件索引,这种索引允许快速地搜索大量的高维数据。 - GPU加速:
faiss库充分利用了NVIDIA GPU的并行计算能力,使得在大规模数据集上的向量搜索和聚类操作变得非常快速。 - 多线程支持:
faiss支持多线程处理,可以进一步提高搜索和聚类的效率。 - 易于使用的API:
faiss提供了Python和C++的API,这些API设计简洁,易于上手和使用。
在Python中,你可以通过faiss库来实现高效的大规模向量搜索和聚类任务,例如,在处理图像、音频或文本数据时,可以使用faiss来快速找到相似的数据点,或者将数据分成具有相似特性的组。这在高维数据处理中是非常有用的,尤其是在需要实时性能的应用中。
from langchain_huggingface import HuggingFaceEmbeddingsembeddings_path = ”H:\AI\Agent\models\bge-large-zh-v1.5“
embeddings = HuggingFaceEmbeddings(model_name=embeddings_path)
ChromaDB
- 时间序列数据支持:ChromaDB 专门为时间序列数据设计,可以高效地存储和查询时间戳数据。
- 高性能:ChromaDB 使用了多种优化技术,如 B-Tree 索引、时间分区等,以提高查询速度和数据写入速度。
- 可扩展性:ChromaDB 支持水平扩展,可以通过添加更多的服务器来增加存储和处理能力。
- 灵活的数据模型:虽然 ChromaDB 专为时间序列数据设计,但它也支持文档和键值数据模型,提供了灵活的数据存储选项。
- 丰富的查询功能:ChromaDB 支持各种查询操作,包括聚合、过滤和排序等,这使得它可以轻松地处理复杂的分析任务。
- 时间索引:ChromaDB 使用了一种高效的时间索引机制,可以快速地定位到特定时间点或时间范围的数据。
- 时间分区:ChromaDB 支持时间分区,可以将数据自动或手动分区到不同的集合中,以优化查询性能和存储效率。
- 兼容 MongoDB:ChromaDB 与 MongoDB 兼容,这意味着你可以使用类似 MongoDB 的 API 来操作 ChromaDB。
在 Python 中,ChromaDB 通过其 Python 客户端库提供了一个简单的接口来与数据库进行交互。这使得 Python 开发者可以轻松地将 ChromaDB 集成到他们的应用程序中,以存储、管理和分析时间序列数据。ChromaDB 适用于需要快速、可扩展的时间序列数据存储和查询的各种应用,如监控系统、物联网、金融市场数据分析等。
from langchain_core.example_selectors import SemanticSimilarityExampleSelector from langchain_community.vectorstores import Chromaexample_selector = SemanticSimilarityExampleSelector.from_examples(
# This is the list of examples available to select from. examples, # This is the embedding class used to produce embeddings which are used to measure semantic similarity. embeddings, # This is the VectorStore class that is used to store the embeddings and do a similarity search over. Chroma, # This is the number of examples to produce. k=1, )
# Select the most similar example to the input. question = ”李白和白居易谁活得的更久?“ selected_examples = example_selector.select_examples({”question“: question}) print(f”与输入最相似的示例: {selected_examples}“)
输出
与输入最相似的示例: [{‘question’: ‘乾隆和曹操谁活得更久?’, ‘answer’: ‘ 这里是否需要跟进问题:是的。 追问:乾隆去世时几岁? 中间答案:乾隆去世时87岁。 追问:曹操去世时几岁? 中间答案:曹操去世时66岁。 所以最终答案是:乾隆 ’}]
selected_examples 输出
[{‘question’: ‘乾隆和曹操谁活得更久?’, ‘answer’: ‘ 这里是否需要跟进问题:是的。 追问:乾隆去世时几岁? 中间答案:乾隆去世时87岁。 追问:曹操去世时几岁? 中间答案:曹操去世时66岁。 所以最终答案是:乾隆 ’}] prompt = FewShotPromptTemplate(example_selector=example_selector, example_prompt=example_prompt, prefix="根据案例的方式回答问题。 ”,
suffix="Question: {input}", input_variables=["input"], )
chain = prompt | chat | output_parser
chain.invoke({“input”:“李白和白居易谁活得的更久?”})
输出
H:AIAgentLangchain-study.venvLibsite-packagesjwtapi_jwt.py:147: InsecureKeyLengthWarning: The HMAC key is 16 bytes long, which is below the minimum recommended length of 32 bytes for SHA256. See RFC 7518 Section 3.2. return self._jws.encode(‘追问:李白去世时几岁? 中间答案:李白去世时约56岁。
追问:白居易去世时几岁? 中间答案:白居易去世时76岁。
所以最终答案是:白居易。’
faiss vs ChromaDB
1. 本质区别
- FAISS:Facebook开源的纯向量检索算法库(不是数据库),专注极致ANN(近似最近邻)搜索性能,无内置存储、无元数据管理、无服务化,只做“算距离、找最近向量”。
- ChromaDB:轻量级全功能向量数据库,开箱即用,内置持久化、元数据过滤、CRUD、LangChain/LLM原生集成,主打快速开发、单机小/中规模RAG场景。
2. 详细对比表
3. 关键差异细节
- 持久化与数据管理
- FAISS:索引存在内存,退出就丢;必须手动
faiss.write_index()/read_index(),不管理原始文本/元数据,你要自己存到文件/数据库。 - Chroma:自动存到本地
chroma.sqlite3,支持集合、文档、元数据,直接存“文本+向量+标签”,查询时可按标签过滤(比如where={“category”:“技术”})。
- FAISS:索引存在内存,退出就丢;必须手动
- 检索能力边界
- FAISS:只做向量相似度,不能按元数据过滤;要过滤必须先查所有向量再自己筛选,大数据量下很慢。
- Chroma:向量检索 + 元数据过滤 + 全文检索一体,RAG开发直接用,不用额外拼接逻辑。
- 性能与算力
- FAISS:C++优化、GPU加速,HNSW/IVFPQ索引在千万级向量下依然毫秒级查询,适合推荐、图像检索、大规模RAG生产。
- Chroma:Python层+SQLite,百万级内流畅,超过百万向量、高并发时延迟上升,不适合超大规模。
4. 选型建议
- ✅ 选 ChromaDB 如果你:
- 快速做RAG原型、Demo、个人项目
- 数据量 < 100万向量、单机运行
- 不想折腾存储、元数据、持久化,要开箱即用
- 用LangChain/LlamaIndex,追求开发效率
- ✅ 选 FAISS 如果你:
- 数据量 ≥ 百万、追求极致查询速度、有GPU
- 做推荐系统、图像/视频检索、大规模生产RAG
- 能自己处理存储、元数据、服务化、持久化
- 需要自定义索引、量化、分布式检索
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/259181.html