
本文介绍了23个AI领域最常见的核心概念和术语,旨在帮助普通人与AI工具更好地打交道。文章从人工智能的基本定义出发,详细解释了机器学习、深度学习、神经网络、生成式AI、大语言模型等核心概念,并拓展了模型、训练、推理、幻觉等关键技术方法。此外,还介绍了Token、自然语言处理、多模态、提示词、提示工程、微调、参数、转化器、计算机视觉、图神经网络、强化学习和通用人工智能等应用领域类概念。文章强调,理解这些基础概念对于使用AI工具至关重要,能够避免一些常见问题,降低使用风险。
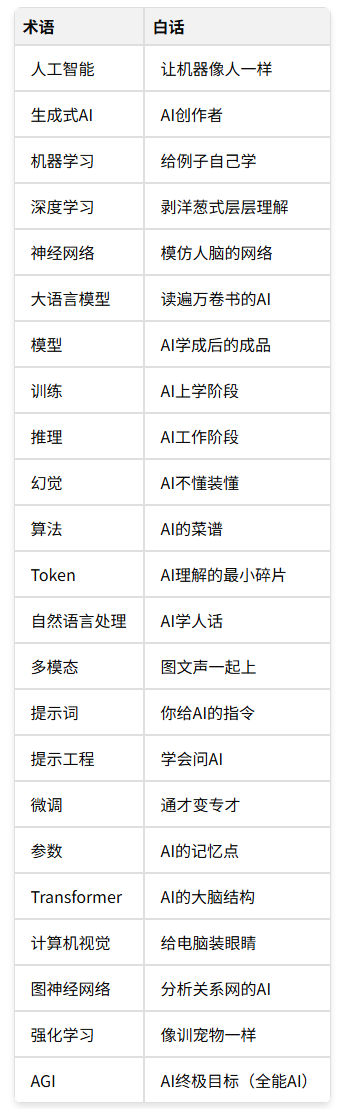
1. 人工智能(AI:artificial intelligence)
一句话人话:让机器像人一样思考、说话、做事。
举个例子:你手机上的语音助手能听懂你说「打电话给妈妈」,这就是人工智能。它不是一个具体的「东西」,而是一个目标——让机器变得聪明。
3. 机器学习(ML: machine learning)
一句话人话:不给机器规则,而是给例子,让它自己找规律。
举个例子:你想让AI识别垃圾邮件,不用告诉它「含有’中奖’的是垃圾邮件」,而是给它看10万封邮件(标记好哪些是垃圾),让它自己总结规律。就像教孩子认猫——不用解释「猫有胡须」,直接给他看100张猫图就够了。
3. 深度学习(DL: deep learning)
一句话人话:机器学习的「进阶版」,像剥洋葱一样一层层理解事物。
举个例子:当AI看一张人脸照片时:
- • 第一层:看到线条和边缘
- • 第二层:看到眼睛、鼻子
- • 第三层:认出这是「张三」
- • 第四层:判断「他在笑」
层数越深,理解越透彻。
4. 神经网络(Neural Network)
一句话人话:模仿人脑搭建的计算网络,像城市交通网。
举个例子:每个路口(神经元)接收信息,处理后传给下一个路口。成千上万个路口协同工作,就能完成复杂任务——比如认出你的脸。
5. 生成式AI (Generative AI)
一句话人话:AI界的「创作者」,能自己写文章、画画、做视频。
举个例子:以前AI只能识别图片里有没有猫,现在的生成式AI可以直接画一只「戴着墨镜的猫」。ChatGPT写文章、Midjourney画图都属于这类。
6. 大语言模型(LLM:Large Language Model)
一句话人话:专门处理文字的AI,相当于「读过全人类所有书的人」。
举个例子:你问它「李白是谁?」,它能回答,因为训练时读过所有关于李白的诗、历史书、百科文章。它不是背下来,而是从海量文字中学到了语言规律和知识。
7. 模型(Model)
一句话人话:AI被训练好后得到的「成品」。
举个例子:就像你学会骑自行车后,脑子里那个「怎么保持平衡、怎么踩踏板」的经验,就是你的「骑车模型」。AI模型也是一个道理——训练完保存下来的「知识包」。
8. 训练(training)
一句话人话:教AI学习的过程,相当于AI的「上学阶段」。
举个例子:给AI看海量数据,让它反复做题、改错,直到学会。就像你准备高考——做几万道题,对答案,改错,直到能考高分。
9. 推理(Inference)
一句话人话:AI学成之后实际干活的过程,相当于AI的「工作阶段」。
举个例子:你问Deepseek「明天天气怎么样?」,它调用学过的知识来回答,这就是推理。训练时它学习,推理时它应用。
10. 幻觉(Hallucination)
一句话人话:AI不懂装懂,编造答案。
举个例子:你问AI「张三这个人怎么样?」,它根本不认识张三,但不会说「不知道」,而是编一段听起来合理的履历:「张三是一位著名科学家,毕业于清华…」。这就是幻觉——看似合理,其实是假的。
11. 算法(Algorithm)
一句话人话:AI做事的步骤和规则,相当于「菜谱」。
举个例子:做红烧肉的菜谱告诉你「先放油、再放糖、炒糖色、放肉.……」,算法就是告诉AI「先做什么、再做什么、遇到什么情况怎么办」的一套规则。
12. Token(令牌/词元)
一句话人话:AI理解语言的最小碎片,就像把一句话切成小段。
举个例子:你说「我喜欢吃苹果」,AI可能会切成:[「我」,「喜欢」,「吃」,「苹果」],每个碎片就是一个Token。有时候一个词可能切成两半,「苹果」可能是一个Token,也可能是「苹」+「果」两个Token。
13. 自然语言处理(Natural Language Processing (NLP))
一句话人话:让AI学会「人话」的技术,包括听懂、看懂、会说人话。
举个例子:你说「我有点冷」,AI不仅知道你在说温度,还能理解你可能需要关空调或加衣服。这就是自然语言处理——让机器理解人类的日常语言。
14. 多模态(Multimodal)
一句话人话:AI能同时处理文字、图片、声音等多种信息。
举个例子:你给AI一张照片说「这是哪?」,它能看图片(视觉) + 理解问题(文字) → 回答「这是长城」。就像人既能看、又能听、又能读,综合理解世界。
15. 提示词(Prompt)
一句话人话:你给AI的指令或问题,决定AI给你什么答案。
举个例子:
- • 差提示词:「写一篇文章」 → AI随便写一篇
- • 好提示词:「写一篇800字的文章,关于春天,语气温暖,给小学生看」→ AI按要求写
提示词就像你点菜——只说「来点吃的」和说「来一份不辣的宫保鸡丁,少放花生」,结果完全不同。
16. 提示工程(Prompt Engineering)
一句话人话:研究「怎么问AI才能得到最好答案」的技巧。
举个例子:想让AI帮你写总结,普通人说「帮我总结一下」,懂提示工程的人会说:「帮我总结这篇文章,300字以内,分三点,用小学生能懂的语言」。后者效果肯定更好。提示工程就是学会和AI有效沟通。
17. 微调(Fine-tuning)
一句话人话:在通用AI基础上,用专门数据让它变得更专业。
举个例子:一个全科医生(通用AI),再培训3个月心脏病(用心脏病例数据继续学习),就变成了心内科专家(微调后的AI)。微调让AI从「通才」变「专才」。
18. 参数(Parameter)
一句话人话:AI脑子里存储的「记忆点」或「知识点」。
举个例子:参数可以简单理解为AI的记忆容量。GPT-3有1750亿个参数,相当于它脑子里有1750亿个小零件协同工作。一般来说,参数越多,AI越聪明,但也越贵、运行越慢。
19. 转化器(Transformer)
一句话人话:现代AI最核心的「大脑结构」,几乎所有厉害AI都在用。
举个例子:以前的AI读句子像人读书——一个字一个字顺着读。Transformer可以一眼看完整个句子,同时理解每个词和其他所有词的关系。比如「他踢了它一脚,因为它挡路」,Transformer能瞬间明白「它」指的是什么。
20. 计算机视觉(CV:Computer Vision)
一句话人话:给电脑装眼睛和大脑,让它能看懂图片和视频。
举个例子:
- • 你手机刷脸解锁 → 计算机视觉认出是你
- • 拍照时自动识别人脸并聚焦 → 计算机视觉找到人脸
- • 自动驾驶汽车看路 → 计算机视觉识别红绿灯、行人
21. 图神经网络 (GNN:Graph Neural Network GNN)
一句话人话:专门分析「关系网」的AI,能理解谁和谁有关系、关系多紧密。
举个例子:想给你推荐朋友,不仅要看你认识谁,还要看你朋友之间是否也相互认识。图神经网络就是专门处理这种「网络关系」的AI。抖音、淘宝用它做推荐,银行用它查洗钱。
22. 强化学习(RL:Reinforcement Learning)
一句话人话:像训练宠物——做对了给奖励,做错了没奖励,让它自己摸索。
举个例子:训练AI玩游戏,不用告诉它规则,只告诉它:赢了加分,输了扣分。AI会自己尝试各种操作,慢慢发现「往左走会死,往右走能赢」。AlphaGo就是用这种方法学会了打败世界冠军。
23. 通用人工智能(AGI:Artificial General Intelligence)
一句话人话:AI界的「终极目标」——像人一样什么都懂、什么都会。
举个例子:现在的AI都是「专才」:会画画的不会写诗,会下棋的不会开车。AGI要是诞生了,就像一个人,既能当医生、又能当律师、还能写小说、陪你聊天。目前还不存在,是科学家努力的方向。
在AI领域,除了「AI」,token这个术语应该是第二高频词,也是最重要的概念之一。对于普通人而言,它是AI系统的计费单位。所以如果不清楚的话,有时会感觉「钱花的不明不白」。
Token 等于: 一段文本被拆分后的最小可处理单位。
文字 → token → 数字 → 神经网络计算 → token → 文字。
可以把 token 想象成 AI 吃的「文字颗粒」。
文字 → 切碎 → token 颗粒 → AI 消化。
AI 的计算量、价格、上下文长度,都和 token 数量相关。
做个简单计算,平均100个token等于75个英文单词,相当于60个汉字。
所以仅输出一篇六百汉字的文章,要消耗大约1000个token,如果再加上整个写作过程(构思、素材分析、修改等等),消耗的token可能要上百万。
AI 已经无处不在,不论是Deepseek,豆包,ChatGPT等交互式工具,还是专业的 AI绘图、AI制作视频等,你只要开始接触,迟早都会遇到这些概念和术语。
你不需要一开始就学得很深,但你至少要知道:
把这些底层的基础概念理顺,后面学任何 AI 工具都会快很多。
对于刚入门大模型的小白,或是想转型/进阶的程序员来说,最头疼的就是找不到系统、全面的学习资源,要么零散不成体系,要么收费高昂,白白浪费时间走弯路。今天就给大家精心整理了一份全面且免费的AI大模型学习资源包,覆盖从入门到实战、从理论到面试的全流程,所有资料均已整理完毕,免费分享给各位!
核心包含:AI大模型全套系统化学习路线图(小白可直接照做)、精品学习书籍+电子文档、干货视频教程、可直接上手的实战项目+源码、2026大厂面试真题题库,一站式解决你的学习痛点,不用再到处搜集拼凑!
扫码免费领取全部内容

理论是实战的根基,尤其是对于程序员来说,想要真正吃透大模型原理,离不开优质的书籍和文档支撑。本次整理的书籍和电子文档,均由大模型领域顶尖专家、大厂技术大咖撰写,涵盖基础入门、核心原理、进阶技巧等内容,语言通俗易懂,既有理论深度,又贴合实战场景,小白能看懂,程序员能进阶,为后续实战和面试打下坚实基础。

无论是小白了解行业、规划学习方向,还是程序员转型、拓展业务边界,都需要紧跟行业趋势。本次整理的2026最新大模型行业报告,针对互联网、金融、医疗、工业等多个主流行业,系统调研了大模型的应用现状、发展趋势、现存问题及潜在机会,帮你清晰了解哪些行业更适合大模型落地,哪些技术方向值得重点深耕,避免盲目学习,精准对接行业需求。值得一提的是,报告还包含了多模态、AI Agent等前沿方向的发展分析,助力大家把握技术风口。

对于程序员和想落地能力的小白来说,“光说不练假把式”,只有动手实战,才能真正巩固所学知识,将理论转化为实际能力。本次整理的实战项目,涵盖基础应用、进阶开发、多场景落地等类型,每个项目都附带完整源码和详细教程,从简单的ChatPDF搭建,到复杂的RAG系统开发、大模型部署,难度由浅入深,小白可逐步上手,程序员可直接参考优化,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

2026年大模型面试已从单纯考察原理,转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。为此,我精心整理了各大厂最新大模型面试真题题库,涵盖基础原理、Prompt工程、RAG系统、模型微调、部署优化等核心考点,不仅有真题,还附带详细解题思路和行业踩坑经验,帮你精准把握面试重点,提前做好准备,面试时从容应对、游刃有余。

结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
扫码免费领取全部内容
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/257600.html