
2026 年 AI 领域最重要的概念,可能非 Harness 莫属。
上个月底,Anthropic 的 AI 编程智能体 Claude Code 源代码意外泄露,业界在围观之下无不发出感叹:「Harness engineering 真是太难了。」
作为 AI 智能体(Agent)的两大支柱之一,大模型就像基础,Harness 则是上层建筑。具体来说,Harness Engineering 是指围绕 AI 智能体设计系统、约束和反馈循环,使其在生产环境中能够可靠运行的工程学科。
在这其中,权限与安全护栏、记忆与状态管理、工具与工作流编排,以及自我纠错循环的机制缺一不可。AI 领域对于 Harness 的重视,意味着 AI 技术正在告别盲盒时代,迈向了工程学的范畴。
而在产业落地这个层面上,国内的实践走在了前面,还率先完成了第三方的实证。
近日,在由 OpenAI 主导设立的权威基准测试 MLE-Bench 上,企业级算法自主优化智能体百度伐谋(Famou)击败了各路玩家登顶,并刷新了 SOTA 成绩。
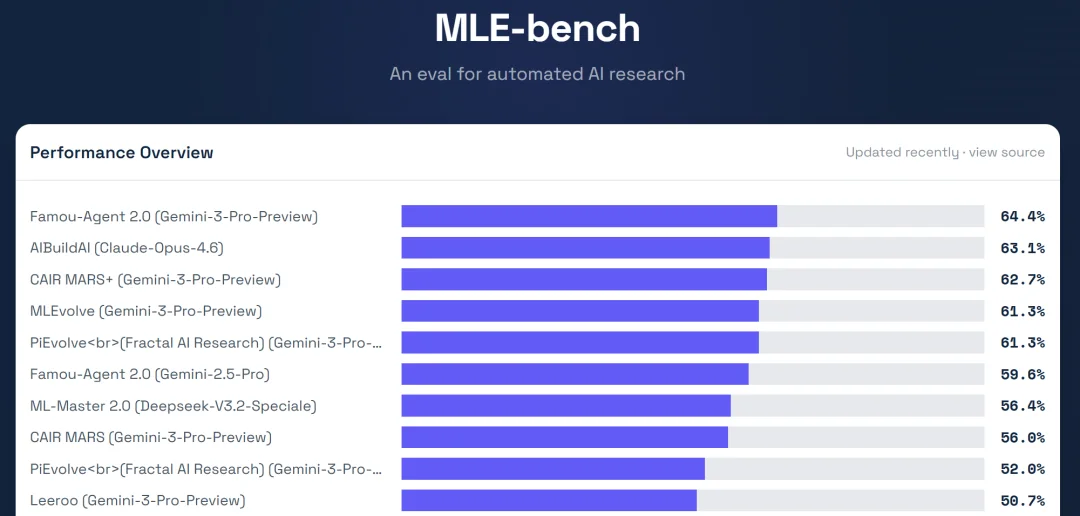
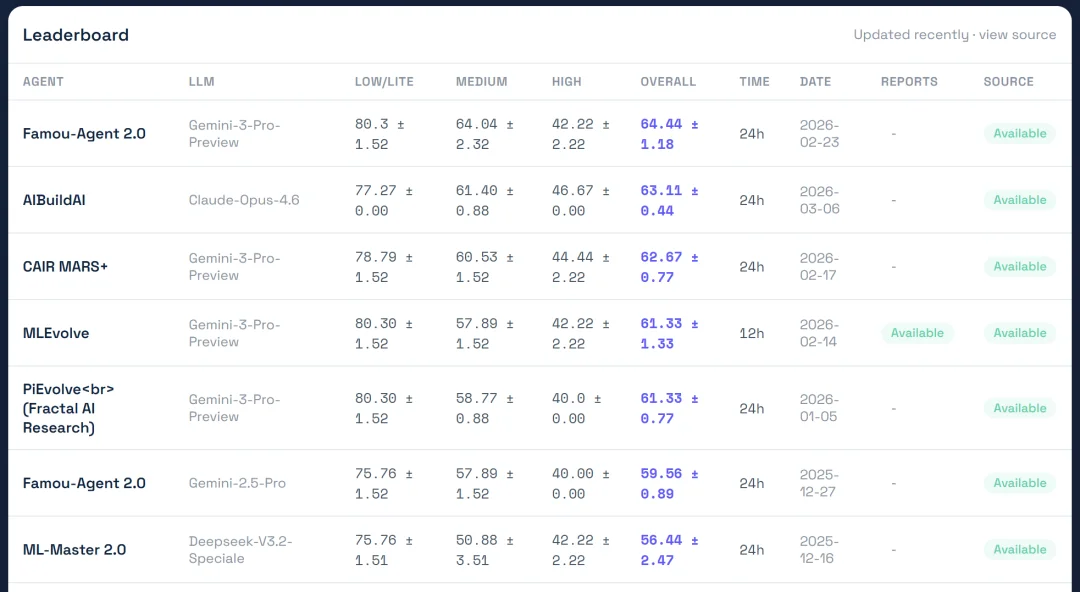
这是继去年 10 月首次登顶后,百度伐谋的第二次领跑。这次拿下第一的是 2.0 版,预计于今年 5 月 13 日的 Create 2026 百度 AI 开发者大会上正式发布。
与那些考常识问答、写代码的常规评测不同,MLE-Bench 被业内公认为是检验智能体「动手能力」的硬核考场。它挑选了 75 个来自顶尖数据科学平台 Kaggle 竞赛的真实工程难题,重点考察 AI 在模型训练、数据准备、实验运行等机器学习全流程中的端到端实战能力。
简单来说,MLE-Bench 不考「单选题」,它考的是工程项目开发的应用题,需要 AI 智能体能像一位经验丰富的人类算法工程师一样,完成从需求理解到解法输出的全链路设计,找出全局最优解。
能在 MLE-Bench 上登顶,意味着伐谋已经超越了做题家的范畴,在解决实际工程和算法优化问题上的能力达到了顶尖水平。
而且这次的成绩「来之不易」。
登榜风波:有关 AI 评测底线的较量
故事要先从一场榜单风波说起。
去年 10 月,百度伐谋团队首次向 OpenAI 主导的 MLE-Bench 提交了 Famou Agent 的成绩,以 43.56 分拿下当时的 SOTA(最优水平)。在此之前,这个硬核的机器学习工程榜单提交者寥寥,伐谋的登顶瞬间让榜单热闹了起来,陆续吸引了近 10 家顶尖团队入场角逐。
到 12 月末,百度伐谋推出了 2.0 版本,并以 59.56 分再次登顶。
有意思的是在这次升级中,伐谋团队做出了一个有些反直觉的决定:他们没有使用当时最先进的基座模型,而是继续使用上一代的模型作为基础。他们希望单独验证智能体 Harness 自身的系统进步。
今年 2 月,在大家都还在 60 分区间苦苦挣扎时,一家名为 Disarray 的创业公司突然提交了一份 77.78 分的答卷。
但很快 AI 社区发现了异样之处:Disarray 的智能体在某些任务(如 GPS 定位任务)上竟然跑出了「0.0 误差」的成绩,在另一些图像任务中也拿到了低得离谱的分数。这种几乎不可能的成绩引爆了 GitHub 讨论区。
有研究者发现,Disarray 的智能体在运行过程中会利用 MLE-Bench 机制的漏洞接收来自「私有测试集」的二值反馈信号,智能体在还没交卷的时候,就已经提前知道了考试答案的大致方向。同时,它甚至在某些任务中直接调用了外部网络数据。
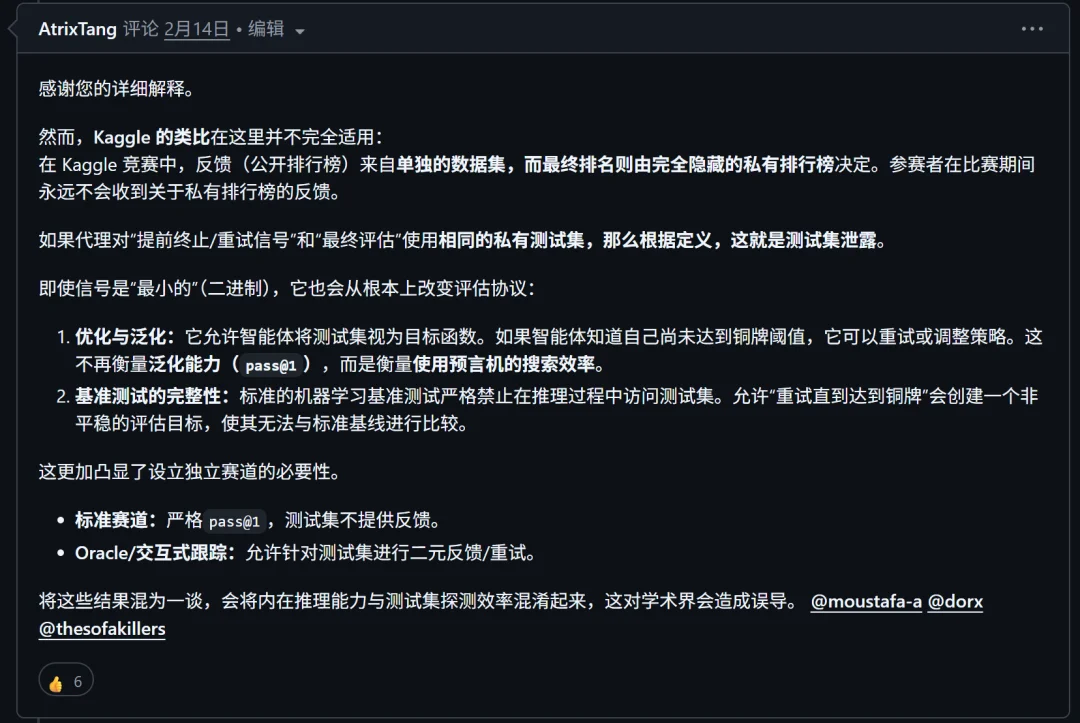
争议之外,伐谋团队决定出手,他们换上了最新 SOTA 模型作为基础模型进行提交,最终得分:64.44 分。虽然绝对分数没有超过利用了漏洞的 Disarray,但这个成绩没有使用私有测试集的反馈信号,也没有使用外部网络数据。
3 月 23 日,MLE-Bench 官方终于做出决定,新增一个专属的清洁赛道(No Private LB),将所有具有数据泄漏嫌疑的方法(包括 Disarray)隔离,并打上警示标签。
排除了干扰项后,一直坚守实验原则、拒绝走捷径的百度伐谋 2.0 以无可争议的分数重回主榜榜首。
这场榜单名次的更迭,似乎也隐喻了 AI 工程化的核心命题:在有研究团队不断刷分的同时,也有探索者正在践行 Harness 的工程化思路,一步步攻克真实世界任务的壁垒。
伐谋 2.0 为什么能赢?
百度能够在全球顶尖智能体的角逐中拔得头筹并非偶然,答案就藏在那个让整个硅谷都在热烈讨论的新词里:Harness Engineering(系统编排工程)。
过去几年,AI 行业的竞争焦点集中在基础模型上。但人们发现,在处理真实世界复杂的工程问题时,再聪明的模型如果没有合理的系统编排与约束,还是会在长链条任务中失去方向,陷入死循环,或者产出无法落地的错误代码。
Harness Engineering 因此逐渐受人重视,其目标非常明确:从手工构建 AI 转向框架驱动的演化。
基于大模型这个「发动机」,Harness 负责管理任务的拆解、记忆存储、试错反馈、工具调用以及安全边界。已有不少 AI 专业人士认为,在未来的 AI 竞赛中,谁能构建出最优秀的 Harness 框架,谁就能真正把大模型的智力转化为生产力。
这个前沿议题也正是百度伐谋一直以来努力的方向。
伐谋是一个让 AI 算法自主进化、寻找全局最优解的多智能体系统,旨在高效率地解决高难度的问题。它结合了大语言模型和进化搜索算法,能够解决复杂的现实世界问题。去年 11 月的百度世界大会上,我们已经见证了百度伐谋的技术框架和实践成果。
李彦宏曾表示,「只要问题的解法是明确可验证的,伐谋就可以模拟甚至超越顶尖的算法专家。」
在伐谋 2.0 版本上,演化策略、长程记忆机制、底层基础设施等层面又获得了全面优化。
首先,伐谋执行的是多智能体并行探索模式。在面对一个新任务时,系统首先会通过多智能体并发生成多个「初始算法解」(冷启动),将它们分发到不同的「岛屿」形成初始种群。随后进入自演化阶段,在分布式集群上利用大规模并行的变异与交叉机制持续迭代,不断向全局最优解逼近。它不需要工程师手工构建每一层能力,而是让智能体在演化中自主寻优。
其次,伐谋升级了长程记忆机制,能让智能体像人类工程师一样在长链条任务中保持思路清晰、逻辑一致。该机制解决了大模型「做着后面忘了前面」的痛点,让智能体能在真实世界复杂的工程任务中记住此前的分析、决策和中间结果。
最后,通过底层基础设施优化,伐谋实现了算法演化迭代效率的显著提升。依托百度智能云的全栈 AI 云优化,伐谋在计算资源调度、任务并行执行、容错恢复等方面做到了极致。底层的夯实,让整个庞大的系统能够「跑得稳、跑得快、跑得可靠」。
榜单是验证,产业是答案
MLE-Bench 榜单的成绩只是技术验证的一角,百度伐谋其实已经在真实物理世界里解决了很多产业难题,其中不乏一些我们想象不到的案例。
在汽车研发中,风阻系数很大程度上决定了新能源车的续航水平,但气动验证是一个困难的任务。传统方法依赖于仿真软件求解复杂的偏微分方程,单次验证可能需要耗时 10 个小时。设计师画完草图,只能像「开盲盒」一样等待工程师的反馈。
亚洲最大的独立汽车设计公司阿尔特,将其 AI 核心平台与百度伐谋进行了深度结合,通过伐谋的自我演化能力,训练出了「御风」智能预测系统。
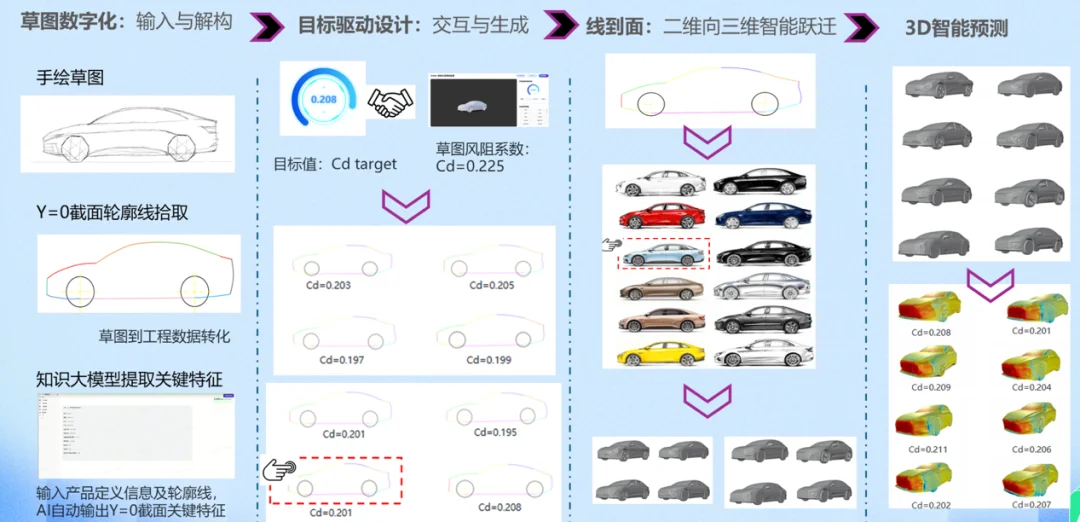
原本需要 10 小时的分析验证,现在仅需数分钟就能输出可视化的压力云图及风阻系数,预测误差被控制在 5% 以内。这种降维打击,直接将传统的「设计 - 验证 - 修改」串行循环,升级成「边设计、边验证」的并行协同,整车研发周期直接缩短了 25%。
数字银行的核心护城河是风控,而风控的生命线在于「特征挖掘」。中信百信银行将伐谋智能体引入了核心风控体系。在这里,伐谋作为一位不知疲倦的「策略演化大师」,利用高维数据感知能力,7×24 小时在海量数据中挖掘风险特征,在极短时间内达到了专业数据工程师的水平。
实战结果令人瞩目:伐谋不仅将特征挖掘效率提升了 100%,还精准抓取到了人类极易忽略的高价值特征,使风控模型的风险区分度提升了 2.41%。这意味着银行能在可控风险内更精准地筛选出优质客户,拓宽普惠金融的边界。
更进一步,伐谋解决复杂问题的能力不仅落地在工业上,也在推动前沿科研范式的升级。
北京工业大学将百度伐谋引入到了中国空间站微型空气质量监测设备的研发中。面对核心部件「气相色谱柱」的流场均匀性难题,伐谋通过自我演化打破了人类常规的设计极限,找出了更小构型、更紧密排列的最优解,极大提升了气体分离效率。
天津大学则将其应用于灾害预测与预警模型选优(如滑坡位移预测、结构面岩爆)。过去依赖人工串行试验、动辄以「周」为单位的选优周期,被伐谋直接压缩到了 6 个小时。
通过 AI 的帮助,人类专家终于得以从枯燥的手动试错中解放出来,回归科研的本质 —— 定义科学问题、产出新规律。而那些最困难、最耗时的算法演化与庞杂计算,正在全面交由智能体去完成。
结语
从百度伐谋的实践我们或许可以看出,Harness Engineering 正在成为下一代 AI 工程化的分水岭。
通过大量实际任务的验证,伐谋证明了一套完整的 AI 智能体架构,不再需要人类工程师去手工编写每一层规则,而是可以放手让其在自我演化中寻找最优解。
当 AI 竞赛从模型层卷向框架层,国内 AI 团队在实践领域的持续深耕正在定义工程化的范式。新一代的生产力,正在真实战场上解决「最难的问题」。
文章来自于微信公众号 “机器之心”,作者 “机器之心”
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/257449.html