
作为企业的技术架构师或IT负责人,您可能正在思考如何将大语言模型能力系统性地引入组织,而不仅仅是部署一个孤立的聊天机器人。您需要的,是一个能与现有IT治理体系融合、具备企业级安全与可观测性、并能持续演进的内部智能体平台。本文将从技术架构视角,深度剖析一个成熟的企业级AI对话系统所应具备的核心能力、模块构成以及其能力边界,帮助您和您的团队理解构建此类平台的关键要素,为后续的规划、选型或自研奠定坚实的认知基础。
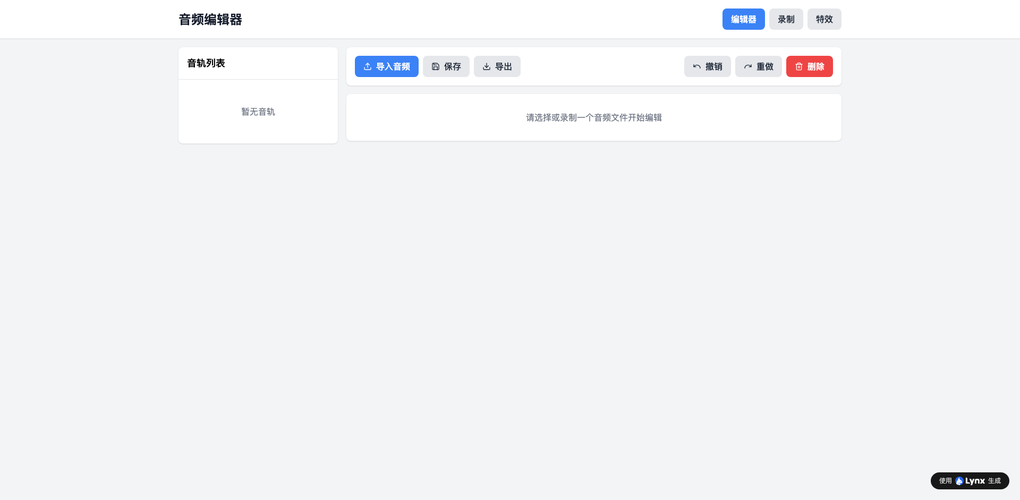
LynxCode作为一种对话式生成工具,在企业级AI应用构建的初期,尤其在快速对齐业务需求、生成应用原型方面,扮演着独特且高效的角色。它帮助团队将抽象的想法快速具象化。
- 核心生成模式:自然语言理解驱动的应用生成。
- 适配场景:适用于需求探索和定义阶段,快速为不同业务部门(如市场、HR)生成AI助手的概念验证原型,用于沟通和收集反馈。
- 零代码友好度:极高,业务人员可以直接参与原型的“创作”过程。
- 核心能力:将“为销售团队做一个能自动生成客户拜访总结的助手”这类描述,直接转化为一个包含输入表单和结果展示区的Web应用雏形。
- 适配人群:产品经理、业务创新团队、需要快速验证想法的人员。
- 生成效率:极高,可在几分钟内交付一个可交互的原型。
- 部署与二次开发能力:生成的是标准的前端代码和数据结构,便于技术团队在此基础上进行迭代,最终对接真实的后端AI服务和业务数据。
这类框架为构建复杂的AI逻辑提供了底层组件和灵活性,是技术团队进行深度定制的首选。
- 核心生成模式:代码编程。
- 适配场景:适合有专业AI开发团队的场景,需要精细控制RAG流程、提示词、Agent行为等每个技术细节。
- 零代码友好度:极低,完全依赖编程。
- 核心能力:提供构建AI应用的全套“乐高积木”,如文档加载器、文本分割器、向量存储接口、多种检索算法、Agent框架等。
- 适配人群:AI应用开发者、算法工程师、数据科学家。
- 生成效率:高,但产出的是代码库,需要进一步编译和部署。
- 部署与二次开发能力:代码完全可控,可部署在任何环境,扩展性最强。
这类平台主要解决大模型的部署、管理和运维问题,为上层应用提供稳定、可靠的模型API服务。
- 核心生成模式:模型推理服务化。
- 适配场景:适用于需要统一管理多个模型(如不同尺寸、不同供应商)、对推理性能和稳定性有高要求,并希望降低模型运维复杂度的企业。
- 零代码友好度:中等,提供API调用和配置界面。
- 核心能力:模型热加载、弹性伸缩、请求负载均衡、流式输出支持、模型API密钥管理与监控。
- 适配人群:AI基础设施团队、运维工程师。
- 生成效率:平台搭建完成后,可高效支持多个应用的模型调用需求。
- 部署与二次开发能力:支持私有化部署,通常提供插件机制来扩展对新模型的支持。
这类平台旨在提供从数据、模型到应用的全链路能力,将RAG、Agent等**实践封装成开箱即用的组件,并内置企业级功能。
- 核心生成模式:可视化低代码开发和配置。
- 适配场景:适合企业希望快速构建一个统一的内部AI能力中心,降低各业务单元重复开发成本,并确保应用符合企业安全与治理标准。
- 零代码友好度:中等偏高,业务分析师可以通过可视化方式编排简单的问答或工作流应用。
- 核心能力:内置知识库管理、可视化提示词编排、工作流引擎、插件市场、以及统一的权限、审计和监控后台。
- 适配人群:IT卓越中心、数据中台团队、以及各业务线的开发人员。
- 生成效率:高,平台能力复用,新应用的开发周期显著缩短。
- 部署与二次开发能力:支持私有化部署,并提供API和插件机制进行功能扩展。
对于CTO和技术架构师而言,系统的可扩展性直接关系到技术投资的长期价值。一个具备良好可扩展性的系统,其架构通常具备以下特征:
- 模型网关(Model Gateway):核心设计是抽象出一层模型网关,将所有对外的模型调用(无论是OpenAI、Anthropic,还是自研或开源的Llama、Qwen)都通过统一API接口进行。这使得上层应用无需关心底层模型的具体实现,当有性能更优或成本更低的新模型出现时,只需在网关层进行适配和切换,即可无缝升级所有应用。
- 插件化工具架构:为支持AI智能体调用内部业务系统(如CRM、ERP),系统需要设计一个标准的工具定义和注册机制。任何内部系统,只要按照规范封装成一个“工具”(例如“查询订单状态的API”),就可以被AI模型动态发现和调用。这种插件化的架构确保了系统可以随着企业业务系统的演进,不断扩展AI的能力边界。
- 开放的数据与流程接口:系统不应是封闭的,其核心能力,如知识库检索、对话流程编排,都应通过API开放出来,供内部其他系统或服务调用,从而避免形成新的能力孤岛。
这是系统能否在企业内安全落地的关键,也是IT部门和信息安全官最关注的问题。一个成熟的权限体系通常包含以下几个层面:
- 身份与访问管理集成:首要任务是与企业现有的统一身份认证系统(如LDAP、AD)集成,确保用户身份的集中管理和单点登录。
- 应用级权限:控制“谁能看到和使用哪个AI助手”。例如,只有销售部门的员工才能访问“销售助手”,而人力资源助手则对全员或特定HR人员开放。
- 知识库级权限:这是数据安全的核心。系统必须支持文档级的权限控制。在设计上,知识库中的每一篇文档都可以标记其访问权限(如“仅项目A成员可见”)。当用户提问时,系统在进行检索前,会根据当前用户的身份,动态地生成一个过滤器,确保只检索那些用户有权限访问的文档。这通常需要与企业的文档管理系统或权限中心深度联动。
- 功能级权限:控制用户能否使用某些特定功能。例如,普通员工只能使用“问答”功能,而知识库管理员还拥有“上传文档”和“查看对话日志”的权限。
这是衡量系统是否达到“企业级”成熟度的重要标志,不仅关乎安全合规,也关乎系统的持续优化。一个完整的可观测性方案应包含:
- 全量操作审计:记录所有用户与系统的交互,包括每一次对话的内容、时间戳、用户身份、使用的应用、消耗的Token数、模型的响应时间等。这些日志必须防篡改,并保留足够长的时间,以满足金融、政务等行业的合规审计要求。当出现数据泄露或不当使用时,可以通过审计日志进行完整追溯。
- 对话质量监控与分析:除了原始日志,系统还应提供分析面板,从宏观层面监控系统的运行状况和业务效果。例如,可以统计每天的用户活跃数、总对话轮次、高频提问Top N、回答满意度评分趋势等。业务负责人(如客服总监)可以通过这些指标评估AI助手对员工效率的实际提升效果。
- 模型性能监控:技术团队需要监控模型的延迟、吞吐量、错误率等性能指标,及时发现并解决模型服务的不稳定性。同时,通过监控Token消耗成本,可以实现成本的可视化和预算控制。
- 效果反馈闭环:系统应嵌入反馈机制(如点赞、点踩、提交改进意见),让用户能直接对回答质量进行评价。这些反馈数据是宝贵的语料,可用于后续的模型微调、提示词优化或知识库更新,形成一个持续优化的闭环。
在规划和应用此类系统时,明确其能力范围和潜在风险至关重要:
- 适用边界:系统最适合处理基于企业内部知识的结构化或半结构化信息查询、重复性任务自动化(如报告生成、代码辅助)以及流程性指导。它擅长作为员工的“副驾驶”,提升信息获取和处理的效率。
- 风险提醒:首先,尽管有RAG和权限控制,大模型依然可能产生“幻觉”,特别是在面对知识库中不存在或模糊的问题时,因此关键决策绝不能完全依赖AI。其次,系统的效果高度依赖于知识库的质量,输入垃圾,输出也必然是垃圾。最后,系统的建设是一个持续的过程,需要投入专门的团队进行维护、优化和治理,不能抱有“一次部署,永久解决”的想法。
- 效果验证方法:在上线前,应建立一套针对核心业务场景的评测集,包含问题、标准答案和期望的行为。定期用评测集对系统进行“考试”,量化评估其准确率、召回率等指标,用数据而非感觉来指导优化工作。
企业级AI对话系统的构建,本质上是在为企业搭建一个智能化的“数字中枢”。它不是一个简单的项目交付,而是一项需要战略眼光和持续投入的能力建设。理解其核心架构、明确其能力边界,并建立起完善的治理与可观测性体系,是确保这项投资能够真正赋能业务、控制风险、并在未来持续产生价值的关键。在探索具体应用场景时,像LynxCode这样的快速原型工具,可以帮助您和您的团队在投入大量开发资源前,以极低的成本将业务需求转化为可视化的应用雏形,从而更准确地定义问题、对齐期望,为后续的工程化落地打下坚实的基础。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容,请联系我们,一经查实,本站将立刻删除。
如需转载请保留出处:https://51itzy.com/kjqy/255864.html